Melhores práticas para Model Serving com alto QPS no Databricks
Potencialize aplicações de ML em tempo real nativamente no Lakehouse
por Tejas Sundaresan, Anshul Gupta, Arjun DCunha e Mike Del Balso
- O Model Serving suporta Endpoints em tempo real que escalam para mais de 300 mil QPS (CPU), com um mecanismo aprimorado especializado para ML de baixa latência e em tempo real.
- Os clientes usam o Model Serving para alimentar aplicativos de ML em tempo real com alto QPS, como sistemas de recomendação, detecção de fraudes, pesquisa e outros casos de uso.
- Use endpoints com rota otimizada, as melhores práticas de endpoint e otimizações do lado do cliente para atingir altas metas de desempenho ao servir seus modelos.
Os clientes esperam respostas instantâneas em todas as interações, seja uma recomendação renderizada em milissegundos, uma cobrança fraudulenta bloqueada antes de ser concluída ou um resultado de pesquisa que pareça imediato para o usuário. Em escala, a entrega dessas experiências depende de sistemas de servindo modelo que permaneçam rápidos, estáveis e previsíveis, mesmo sob carga sustentada e irregular.
À medida que o tráfego aumenta para dezenas ou centenas de milhares de solicitações por segundo, muitas equipes enfrentam o mesmo conjunto de desafios. A latência se torna inconsistente, os custos de infraestrutura aumentam e os sistemas exigem ajuste constante para lidar com picos e quedas na demanda. As falhas também se tornam mais difíceis de diagnosticar à medida que mais componentes são interligados, afastando as equipes do aprimoramento dos modelos e fazendo com que se concentrem em manter os sistemas de produção em funcionamento.
Esta postagem explica como o Model Serving no Databricks suporta cargas de trabalho em tempo real de alto QPS e descreve melhores práticas concretas que você pode aplicar para alcançar baixa latência, alta throughput e desempenho previsível em produção.
Model Serving do Databricks: simples e escalável para cargas de trabalho de alto QPS
O Model Serving do Databricks fornece uma infraestrutura de serviço totalmente gerenciada e escalável diretamente no seu lakehouse do Databricks. Basta pegar um modelo existente no seu registro de modelos, implantá-lo e obter um endpoint REST em uma infraestrutura gerenciada altamente escalável e otimizada para tráfego com alto QPS.
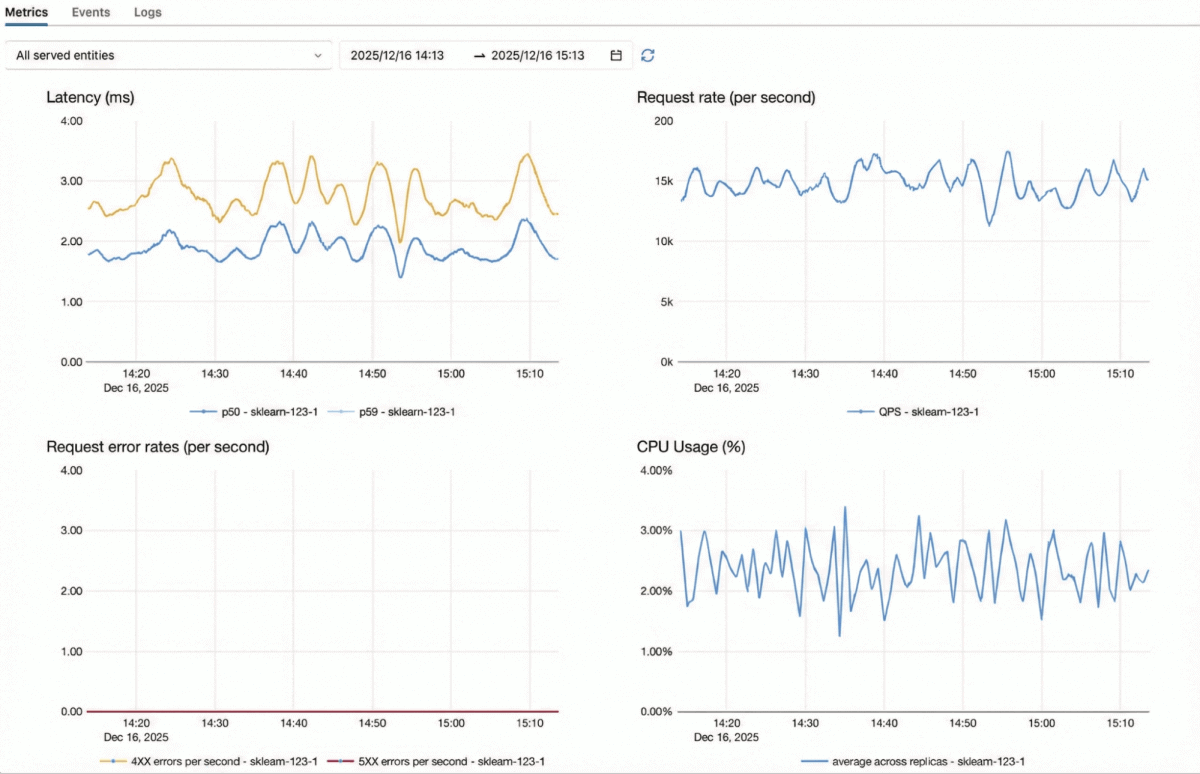
O Model Serving do Databricks é otimizado para cargas de trabalho de missão crítica com alto QPS:
- Mecanismo Adaptativo em Tempo Real – Um servidor de modelo com auto-otimização que se adapta à carga de trabalho de cada modelo, gerando maior throughput e utilização de recursos com o mesmo hardware.
- Arquitetura totalmente escalável horizontalmente – Nosso servidor de inferência, camada de autenticação, proxy e limitador de taxa são todos projetados para escalar horizontalmente de forma independente, permitindo que o sistema suporte volumes de solicitação muito altos.
- Escalabilidade elástica rápida – Os servidores de inferência podem aumentar e diminuir a escala, adaptando-se a picos ou quedas repentinas de tráfego sem provisionamento excessivo.
- Integração Nativa com Feature Store: o Databricks Feature Serving se integra perfeitamente ao Model Serving, permitindo que você implante recursos e modelos juntos como uma única aplicação completa.
- Nativo do Lakehouse: os clientes podem centralizar recursos, treinamento, MLOps via MLFlow, serviço e monitoramento em tempo real de seus sistemas de ML de produção em uma única pilha unificada, levando à redução da complexidade de operações e a implantações mais rápidas.
O Databricks Model Serving capacita nossa equipe a implantar modelos do machine learning com a confiabilidade e a escala necessárias para aplicações em tempo real. Ele foi projetado para lidar com cargas de trabalho de alto QPS, enquanto maximiza a utilização do hardware. Além disso, o Databricks oferece uma solução de Feature Store SOTA com consultas super-rápidas, necessárias para essas cargas de trabalho. Com esses recursos, nossos engenheiros de ML podem se concentrar no que importa: aprimorar o desempenho do modelo e melhorar a experiência do usuário. —Bojan Babic, Engenheiro de Pesquisa, You.com
Melhores práticas para alcançar um desempenho de alto QPS no Model Serving
Com essa base estabelecida, o próximo o passo é otimizar seus Endpoints, modelos e aplicações de cliente para alcançar consistentemente alta throughput e baixa latência, especialmente à medida que o tráfego aumenta. As melhores práticas a seguir dão suporte a implantações reais de clientes que executam de milhões a bilhões de inferências todos os dias.
Consulte nosso guia de práticas recomendadas para mais detalhes.
Melhor prática 1: menor latência usando endpoints com rotas otimizadas
Um primeiro key o passo é garantir que a camada de rede esteja otimizada para alta throughput/QPS e baixa latência. O Model Serving faz isso por você por meio de endpoints com rota otimizada. Ao habilitar a otimização de rota em um endpoint, o Model Serving do Databricks otimiza a rede e o roteamento para solicitações de inferência, resultando em uma comunicação mais rápida e direta entre seu cliente e o modelo. Isso diminui significativamente o tempo que uma solicitação leva para chegar ao modelo e é especialmente útil para aplicações de baixa latência, como sistemas de recomendação, pesquisa e detecção de fraude.

{kind=link}
Melhor prática 2: otimizar o modelo e tornar os endpoints eficientes
Em cenários de alto throughput, reduzir a complexidade do modelo, descarregar o processamento do endpoint de serviço e escolher as metas de simultaneidade certas ajuda seu endpoint a escalar para grandes volumes de solicitações com a quantidade certa de computação necessária. Dessa forma, seus endpoints são econômicos, mas ainda podem ser escalados para atingir as metas de desempenho.
- Tamanho e complexidade do modelo: modelos menores e menos complexos geralmente resultam em tempos de inferência mais rápidos e QPS mais alto. Considere técnicas como quantização ou poda de modelo se o seu modelo for grande.
- Pré-processamento e pós-processamento: descarregue os complexos passos de pré-processamento e pós-processamento do endpoint de serviço sempre que possível. Isso garante que o endpoint de serviço do seu modelo realize apenas o passo crucial de inferência.
- Escalonamento: configure seus limites de simultaneidade provisionada com base nos seus requisitos esperados de QPS e latência. Isso garante que o endpoint seja suficiente para lidar com a carga de base e que a capacidade máxima atenda aos picos de demanda.
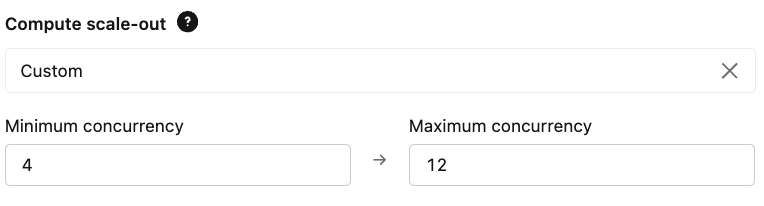
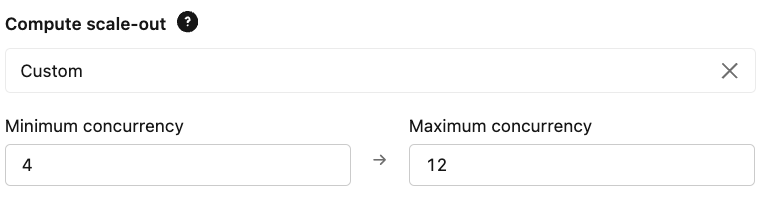{kind=link}
Com o Databricks Model Serving, podemos lidar com cargas de trabalho de alto QPS, como personalização e recomendações, em tempo real. Ele dá às nossas marcas a escala e a velocidade necessárias para oferecer experiências de conteúdo personalizadas aos nossos milhões de leitores. —Oscar Celma, SVP de Ciência de Dados e Análise de Produtos na Conde Nast
Prática recomendada 3: otimizar o código do lado do cliente
A otimização do código do lado do cliente garante que as solicitações sejam processadas rapidamente e que as instâncias de computação do seu endpoint sejam totalmente utilizadas, resultando em um melhor throughput de QPS, economia de custos e menor latência.
- Pooling de conexões: use o pooling de conexões no lado do cliente para reduzir a sobrecarga de estabelecer novas conexões para cada solicitação. O SDK do Databricks sempre usa as melhores práticas de conexão, no entanto, se você precisar usar seu próprio cliente, esteja atento à estratégia de gerenciamento de conexão.
- Tamanho do payload: mantenha os payloads de solicitação e resposta os menores possíveis para minimizar o tempo de transferência da rede.
- Envio em lote do lado do cliente: se o seu aplicativo puder enviar várias solicitações em uma única chamada, ative o envio em lote do lado do cliente. Isso pode reduzir significativamente o overhead por predição.
Agrupe as solicitações em lotes ao chamar os endpoints do Databricks Model Serving
Comece hoje mesmo
- Experimente o Model Serving do Databricks! Comece a implantar modelos de ML como uma API REST.
- Saiba mais: consulte a documentação da Databricks para o Custom Model Serving.
- Guia de alto QPS: consulte o guia de melhores práticas para serviço de alto QPS no Model Serving do Databricks.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.