Construindo um framework de análise de testes A/B para jogos mobile no Databricks
Como a HARDlight escalou a análise de experimentos com modelagem estatística automatizada, insights governados, um dashboard de atualização diária e resumos gerados por LLM.
por Sanjay Ashok, Jack Holdsworth, Tingting Wan, Joel Dias, Richard Carr e Monika Kolodziejczyk
- De dados a decisões: como a Sega HARDlight automatizou a análise de testes A/B no Databricks por meio de ingestão padronizada de experimentos, modelagem estatística e publicação de resultados — reduzindo fluxos de trabalho manuais e permitindo um aumento de 2x na capacidade mensal de experimentação sem aumento de pessoal.
- Insights para todos os públicos: monitoramento com atualização diária com um resumo de LLM no topo e métricas progressivamente granulares, diagnósticos e ações recomendadas que democratizam o acesso a insights acionáveis em toda a organização.
- Confiança por meio da transparência: inferência estatística consistente e visualizações de IA/BI acessíveis ajudaram as equipes a entender os resultados, gerar confiança e adotar uma abordagem científica compartilhada para a experimentação.
Introdução
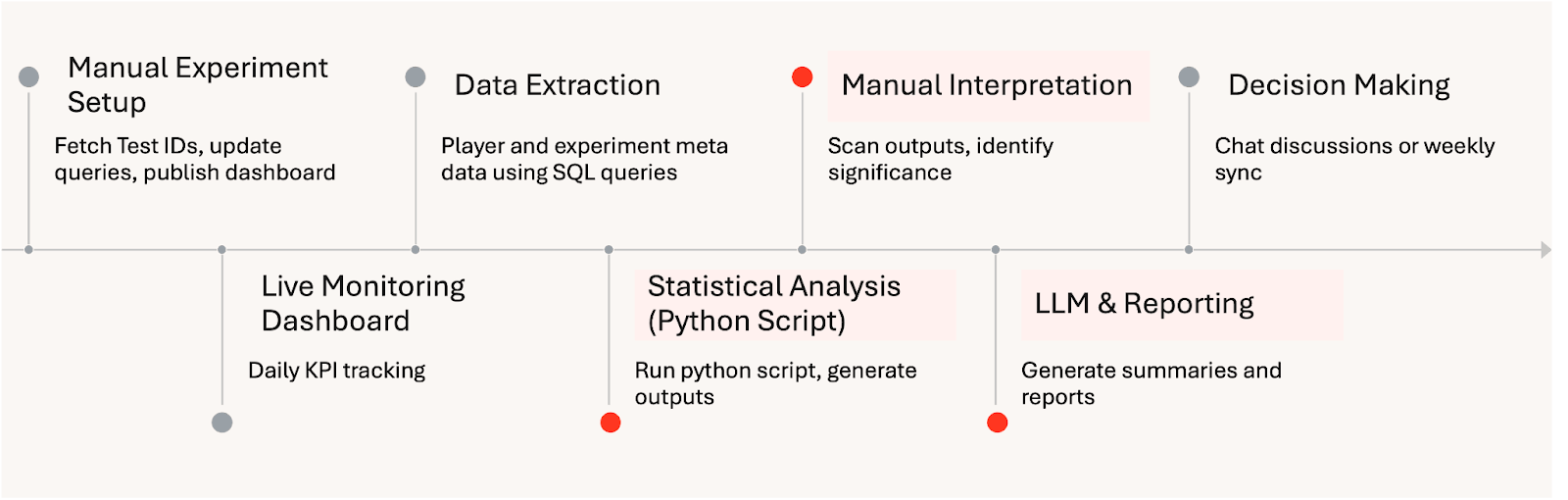
Estúdios de jogos mobile dependem de experimentação contínua para refinar a jogabilidade, a monetização e as operações ao vivo. À medida que a experimentação escala, a análise muitas vezes se torna o fator limitante. Os resultados são frequentemente reunidos manualmente, as abordagens estatísticas variam por analista e os insights chegam dias após o surgimento de sinais importantes. Com o tempo, isso cria atrito: iteração mais lenta, conclusões inconsistentes e diminuição da confiança nos testes A/B como uma ferramenta de decisão confiável.
O Desafio
Na HARDlight, o desafio não era apenas a velocidade, mas a confiança. Abordagens diferentes levavam a interpretações diferentes, dificultando o alinhamento e enfraquecendo a confiança na experimentação como uma ferramenta científica de decisão. Alguns stakeholders precisavam de um status diário simples, outros queriam entender o comportamento do jogador ou o impacto nos negócios, e um grupo menor exigia validação profunda de alavancas específicas do jogo. Os dashboards e relatórios existentes lutavam para atender a esse espectro completo de necessidades de forma eficaz. Para que a experimentação escalasse, a HARDlight precisava de uma maneira de padronizar a inferência, tornar os resultados acessíveis em diferentes níveis de profundidade e reconstruir a confiança nos testes A/B como um processo científico compartilhado de tomada de decisão.
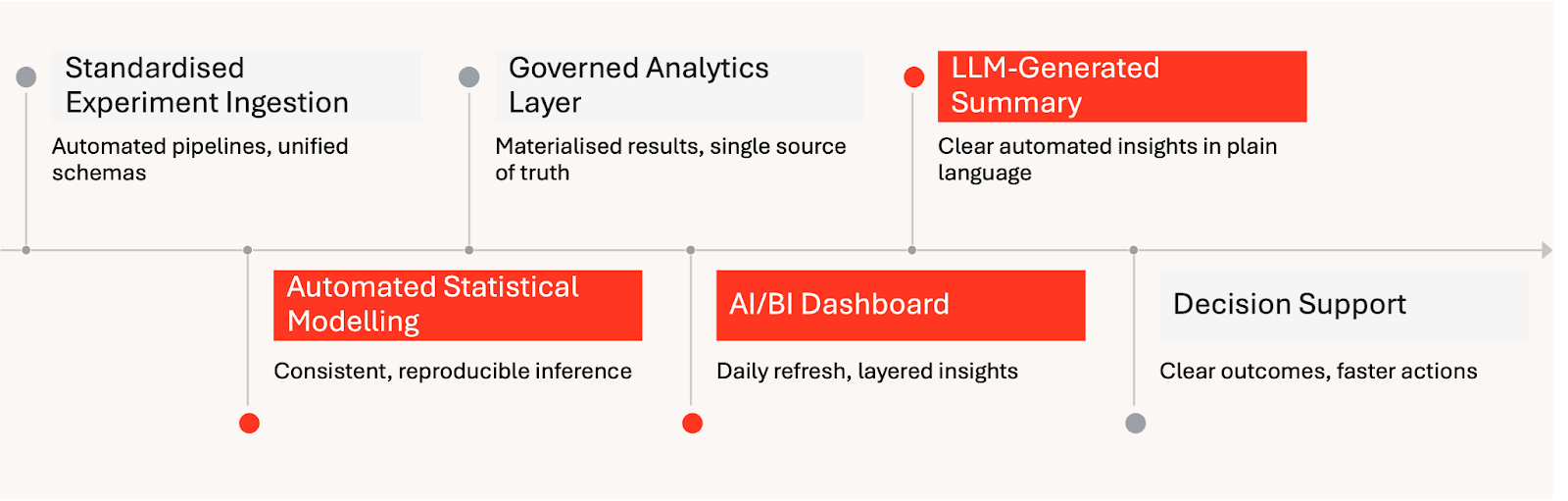
Para resolver isso, a HARDlight construiu um framework de análise de testes A/B nativo do Databricks que automatiza o caminho dos dados do experimento para insights prontos para decisão. A análise estatística foi realizada a montante de forma repetível e transparente, e o Databricks AI/BI apresentou os resultados por meio de uma experiência de atualização diária que começou com um resumo gerado por LLM e permite uma exploração mais profunda com visualizações progressivamente granulares. Ao final de cada experimento, os resultados foram congelados e preservados, garantindo que as decisões, o contexto e os aprendizados permaneçam disponíveis muito depois que o teste for concluído.
A Solução: Testes A/B Automatizados no Databricks
O framework da HARDlight automatiza a experimentação desde a ingestão até o suporte à decisão. Dentro do Databricks, as definições de experimento e a telemetria são padronizadas, a modelagem estatística é aplicada de forma consistente e os resultados são publicados em um dashboard em camadas que é atualizado diariamente durante a janela de execução. Um resumo de LLM no topo fornece uma visão acessível do status do experimento, enquanto seções mais profundas expõem KPIs, diagnósticos e ações recomendadas para usuários especialistas.
A escolha do Databricks permite governança e repetibilidade entre equipes. O Unity Catalog fornece um plano de controle único para permissões e linhagem de ativos de experimentos; Spark Declarative Pipelines orquestra pipelines confiáveis para ingestão e transformações de experimentos; e MLflow suporta rastreamento de experimentos e empacotamento de modelos para análise reproduzível. Juntas, essas capacidades mantêm os dados e a análise governados, consistentes e fáceis de operar no Lakehouse.
Uma inovação chave é o "dashboard congelado" ao final da execução. Em vez de rolar para a próxima atualização, o framework preserva o snapshot final e as decisões tomadas, juntamente com as ações recomendadas. Isso institucionaliza os aprendizados de experimentos anteriores e permite que os stakeholders revisitem os resultados sem ambiguidade.
Arquitetura Técnica
O framework de experimentação é construído como um sistema nativo do Databricks que separa o processamento de dados, a inferência estatística e o consumo, mantendo todas as saídas governadas e reproduzíveis por padrão. Este design garante que o rigor analítico escale sem aumentar a sobrecarga operacional ou fragmentar a interpretação entre equipes.
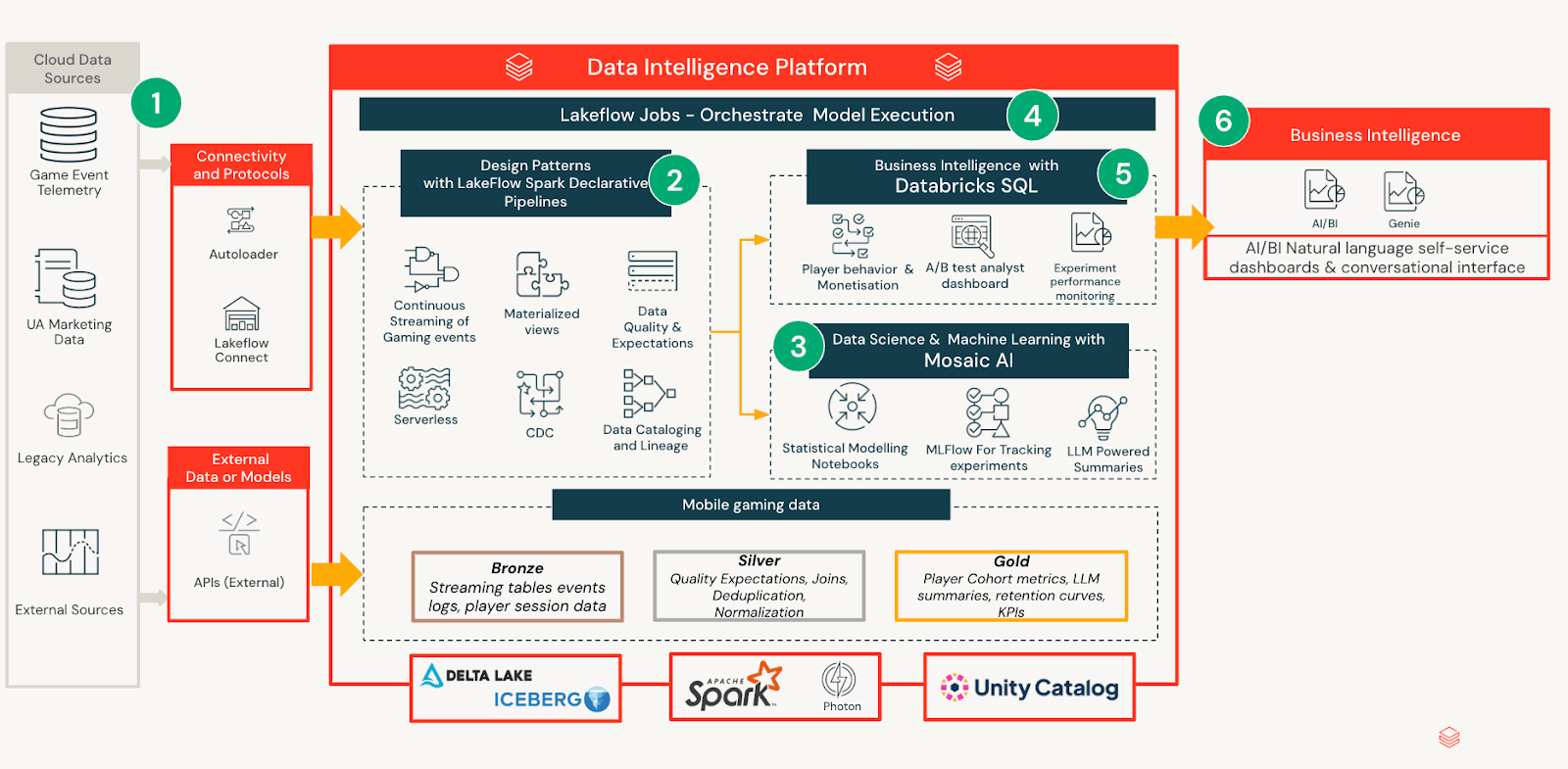
Ingestão e Modelagem de Dados
Definições de experimentos, telemetria de jogadores e métricas de resultados são ingeridas de pipelines internos e curadas em tabelas governadas com esquemas consistentes. Essa padronização permite que analistas e equipes de produto raciocinem sobre experimentos de forma consistente, independentemente do design ou duração do teste. Notebooks são usados para computar modelos estatísticos que calculam estimativas de efeito, incertezas e impactos em nível de segmento ao longo do tempo. Em vez de incorporar a lógica em dashboards ou relatórios, todas as saídas analíticas são materializadas em um modelo unificado de análise de experimentos. Isso cria uma camada semântica estável na qual os consumidores downstream podem confiar sem reexecutar a análise ou reinterpretar os resultados.
Entrega de Insights com IA/BI
Acima dessa camada de análise governada, o Databricks AI/BI fornece uma interface acessível para consumir resultados de experimentos. Cada atualização diária gera um resumo conciso de LLM voltado para stakeholders não técnicos, traduzindo saídas estatísticas validadas em linguagem natural. O dashboard usa divulgação progressiva: os usuários podem parar no resumo quando satisfeitos, ou explorar camadas mais profundas de métricas, diagnósticos e análise de segmentos à medida que sua curiosidade aumenta. Essa experiência em camadas permite uma varredura rápida, mantendo a profundidade analítica disponível para validação por especialistas.

Ciclo de Vida e Persistência de Experimentos
Durante a fase ativa, o dashboard é atualizado diariamente para que as equipes possam acompanhar a trajetória e reagir a sinais. Ao final, o dashboard é congelado para preservar resultados, decisões e ações recomendadas. Esse ciclo de vida cria um registro auditável que acelera a integração e reduz a duplicação de análises em experimentos futuros.
Camadas do Dashboard Explicadas
O dashboard foi projetado para guiar os usuários pelos resultados de um experimento em uma sequência clara e deliberada. Começa com simplicidade e gradualmente revela mais detalhes para aqueles interessados em explorar mais a fundo. Cada seção aborda uma pergunta diferente, e é totalmente aceitável parar assim que o leitor obtiver as informações necessárias.
Resumo do experimento gerado por LLM: No topo do dashboard está um resumo gerado por LLM. Enquanto um experimento está ativo, ele oferece uma visão simples e de alto nível de como as coisas estão indo, destacando sinais iniciais sem tirar conclusões precipitadas.
Assim que o experimento é concluído, o resumo muda de função. Ele se torna uma explicação clara do que aconteceu, destacando as métricas que se moveram com alta confiança, em ordem de prioridade e em linguagem clara. O objetivo é ajudar as equipes a entender rapidamente o resultado e por que ele é importante.
Resultados confirmados e impacto estatístico: Para públicos mais técnicos, a próxima seção apresenta uma visão estruturada de resultados estatisticamente significativos. Métricas chave como valor de vida do jogador (LTV) e retenção são listadas ao lado de tamanhos de efeito e níveis de confiança, facilitando a validação de conclusões sem mergulhar na análise bruta.
Impacto previsto no valor de vida: O dashboard então mostra o impacto estimado no valor de vida do jogador para os grupos de controle e variante. Incertezas e margens de erro são mostradas explicitamente, reforçando que estas são estimativas informadas, não previsões absolutas.
Impacto da receita por fonte: Os resultados são divididos por fluxo de receita, incluindo anúncios, compras no aplicativo e receita total. Isso ajuda as equipes a entender se as mudanças são amplas ou impulsionadas por canais de monetização específicos.
Engajamento e comportamento do jogador: Além da receita, métricas de engajamento como retenção e comportamento de sessão são apresentadas para garantir que os ganhos de negócios sejam considerados juntamente com a experiência do jogador e a saúde a longo prazo.
Análise em nível de segmento: A segmentação é central para como a HARDlight projeta e avalia experimentos. Esta seção mostra como diferentes segmentos de jogadores respondem a uma mudança, seja definida por retenção, progressão ou outros traços comportamentais. Ajuda as equipes a confirmar que experiências direcionadas funcionam como pretendido, sem prejudicar outras partes da base de jogadores.
Mecânicas de monetização e economia do jogo: Camadas mais profundas exploram como os experimentos afetam os sistemas do jogo, incluindo desempenho de anúncios por local, desempenho de compras no aplicativo por categoria de produto e mudanças nos fluxos de moeda dura e mole entre fontes e destinos.
Loops de jogabilidade principal e apêndices: No nível mais profundo, gráficos e tabelas detalhados cobrem mecânicas de jogabilidade como corridas, personagens e itens, juntamente com recursos visuais estatísticos de apoio. Esta camada é destinada a usuários especialistas que desejam transparência total ou precisam reutilizar insights em trabalhos futuros.
Juntas, essas camadas permitem que os insights se desdobrem naturalmente. As equipes podem agir rapidamente quando a resposta é clara, ou aprofundar-se quando surgem perguntas, tudo isso trabalhando a partir da mesma fonte de dados governada e confiável.
Essa estrutura é possibilitada pelo Databricks AI/BI, que permite que saídas analíticas complexas sejam apresentadas de forma limpa sem incorporar código personalizado ou fluxos de trabalho exclusivos para analistas em dashboards. Resultados estatísticos, projeções e análises em nível de segmento são computados a montante em notebooks e materializados em tabelas governadas, enquanto o AI/BI fornece uma camada de apresentação flexível por cima. Isso elimina a necessidade de executar Python dentro de dashboards, simplifica a manutenção e torna viável para uma equipe enxuta iterar e evoluir o sistema ao longo do tempo.
Igualmente importante, o AI/BI permite atender a públicos muito diferentes a partir dos mesmos dados subjacentes. Resumos narrativos, resultados tabulares, gráficos e diagnósticos profundos podem coexistir sem duplicar a lógica ou fragmentar a interpretação. Essa foi uma mudança chave em relação às abordagens anteriores, onde as limitações das ferramentas forçavam compromissos entre profundidade analítica, acessibilidade e sustentabilidade.
Impacto e Resultados
A estrutura mudou fundamentalmente a forma como a experimentação opera na HARDlight. Ao automatizar a análise e padronizar a inferência estatística, a equipe de dados reduziu o esforço manual em mais de oito horas por semana. Ao padronizar as execuções de experimentos com Databricks Workflows, a equipe eliminou grande parte do trabalho manual de configuração anteriormente necessário para cada análise. Isso economiza aproximadamente um dia por experimento e permitiu um aumento direcionado de duas vezes na capacidade mensal de testes A/B sem aumentar o quadro de funcionários.
Fluxo de Trabalho de Análise Manual de Experimentos:
Entrega Automatizada de Insights de Experimentos no Databricks:
Além dos ganhos de eficiência, o sistema melhorou a consistência e a confiança nos resultados. O arquivo de dashboard congelado agora atua como uma fonte de verdade durável para experimentos concluídos, reduzindo análises repetidas e facilitando para as equipes revisitarem decisões passadas com contexto completo. Isso reduziu significativamente a sobrecarga de manutenção do conhecimento histórico entre as equipes.
Talvez o mais importante, a estrutura mudou a forma como os insights são consumidos em todo o estúdio. Com múltiplos experimentos rodando em paralelo, as equipes agora recebem atualizações diárias habilitadas por IA/BI que substituem a agregação e interpretação manual de vários dias. O Genie será habilitado diretamente no dashboard, permitindo que os usuários façam perguntas sobre o que estão vendo e explorem os resultados com suas próprias palavras, sem precisar entender o modelo de dados subjacente. Juntos, resumos claros, métricas governadas, saídas estatísticas transparentes e acesso conversacional ajudaram a construir confiança entre as equipes de produto, LiveOps e engenharia, reforçando a experimentação como uma forma de trabalho científica e compartilhada.
Próximos Passos
A HARDlight planeja estender a estrutura com um aplicativo de previsão, expandindo-a de análises descritivas e inferenciais para orientação prospectiva. A visão mais ampla é a experimentação preditiva e otimização de ciclo fechado — usando o Lakehouse para automatizar mais do ciclo de hipótese à implantação, enquanto preserva a governança e a consistência com Unity Catalog, Spark Declarative Pipelines e MLflow. Essa abordagem focada em dashboards pode ter um impacto significativo para outros estúdios com necessidades semelhantes, adicionando resumos de LLM sobre métricas governadas e diagnósticos para escalar a experimentação com confiança no Databricks.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.