Construindo, Melhorando e Implantando Sistemas RAG de Grafo de Conhecimento no Databricks
por Andrea Santurbano, Chandhana Padmanabhan, Jiayi Wu e Dan Pechi
- Visão Geral do GraphRAG: O blog explora como sistemas de geração aumentada por recuperação (RAG) podem ser aprimorados com bancos de dados de grafos como o Neo4j, permitindo saídas de IA mais precisas ao capturar relacionamentos semânticos entre entidades em dados estruturados.
- Casos de Uso e Benefícios: O GraphRAG pode ser aplicado em cibersegurança para detecção de ameaças, bem como em setores como manufatura para manutenção preditiva e gerenciamento da cadeia de suprimentos, fornecendo insights mais profundos de conjuntos de dados complexos.
- Implementação no Databricks: O blog descreve como construir e implantar um sistema GraphRAG no Databricks usando Neo4j, demonstrando a integração de LLMs, Delta Tables e o Agent Bricks Custom Agents para implantação ponta a ponta.
Entendendo o GraphRAG
O que é um Grafo de Conhecimento?
Para entender por que alguém pode usar um Grafo de Conhecimento (KG) em vez de outra representação de dados estruturados, é importante reconhecer seu foco em relacionamentos explícitos entre entidades — como empresas, pessoas, maquinário ou clientes — e seus atributos ou características associados. Diferente de embeddings ou busca vetorial, que priorizam a similaridade em espaços de alta dimensionalidade, um Grafo de Conhecimento se destaca na representação das conexões semânticas e do contexto entre pontos de dados. Uma unidade básica de um grafo de conhecimento é um fato. Fatos podem ser representados como um triplet nas seguintes formas:
- HRT: <head, relation, tail>
- SPO: <subject, predicate, object>
Dois exemplos simples de KG são mostrados abaixo. O exemplo da esquerda de um fato poderia ser <Andrea, ama, Irene>. Você pode ver que o KG é nada mais que uma coleção de múltiplos fatos como esse. Mas, como você pode notar, grafos têm semântica, pois o exemplo da esquerda NÃO descreve um relacionamento romântico entre duas pessoas, enquanto o exemplo da direita DESCREVE um relacionamento romântico entre duas pessoas.

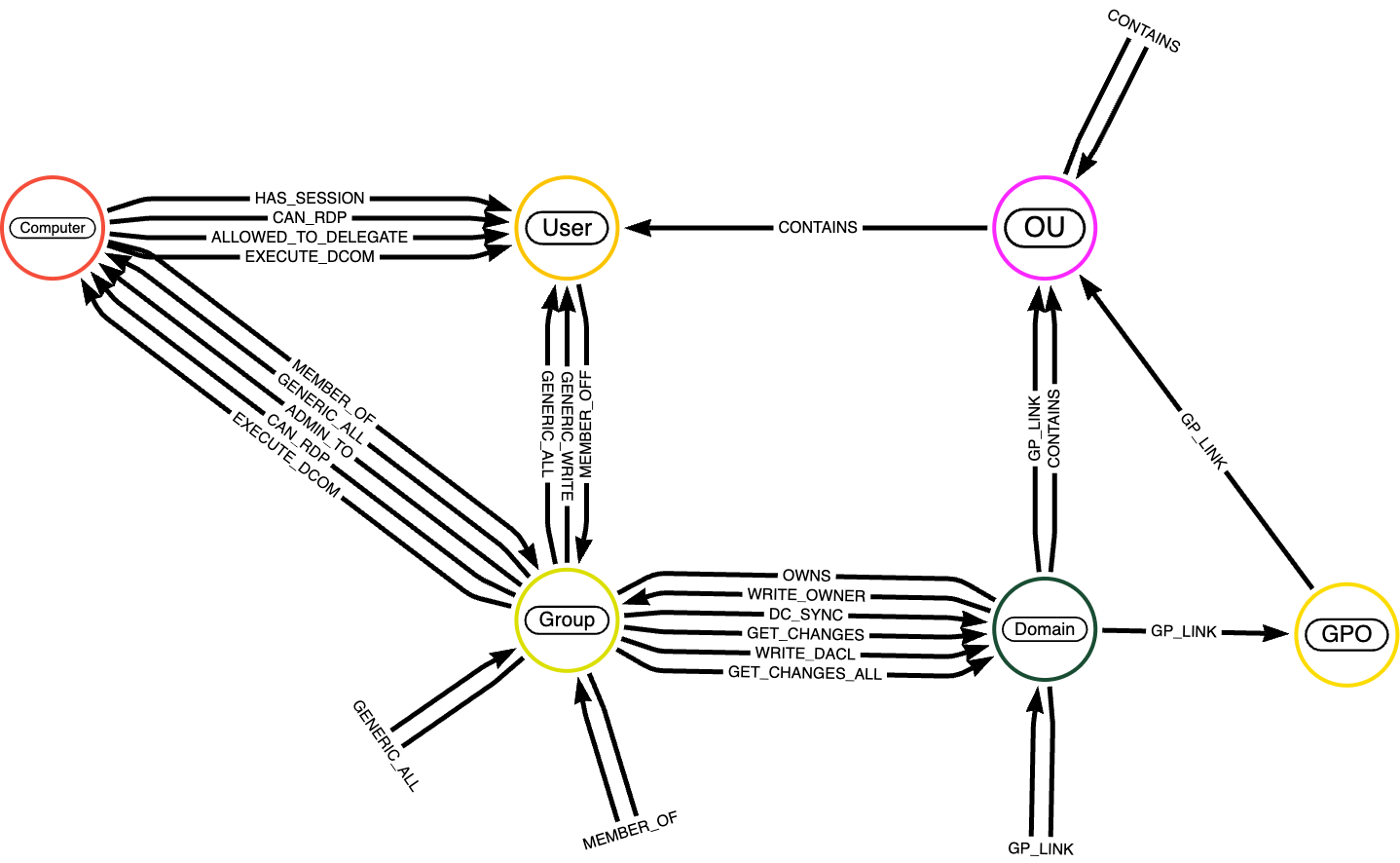
Agora que você entende a importância da semântica em Grafos de Conhecimento, vamos apresentar o conjunto de dados que usaremos nos próximos exemplos de código: o conjunto de dados BloodHound. BloodHound é um conjunto de dados especializado projetado para analisar relacionamentos e interações em ambientes do Active Directory. Ele é amplamente utilizado para auditoria de segurança, análise de caminhos de ataque e para obter insights sobre vulnerabilidades potenciais em estruturas de rede.
Nós no conjunto de dados BloodHound representam entidades em um ambiente do Active Directory. Estes tipicamente incluem:
- Usuários: representa contas de usuário individuais no domínio.
- Grupos: representa grupos de segurança ou distribuição que agregam usuários ou outros grupos para atribuição de permissões.
- Computadores: representa máquinas individuais na rede (estações de trabalho ou servidores).
- Domínios: representa o domínio do Active Directory que organiza e gerencia usuários, computadores e grupos.
- Unidades Organizacionais (OUs): representa contêineres usados para estruturar e gerenciar objetos como usuários ou grupos.
- GPOs (Group Policy Objects): representa políticas aplicadas a usuários e computadores dentro do domínio.
Uma descrição detalhada das entidades de nós está disponível aqui. Relacionamentos no grafo definem interações, associações e permissões entre nós; uma descrição completa das arestas está disponível aqui.
Quando escolher GraphRAG em vez de RAG Tradicional
A principal vantagem do GraphRAG sobre o RAG padrão reside em sua capacidade de realizar correspondência exata durante a etapa de recuperação. Isso é possível, em parte, por preservar explicitamente a semântica de consultas em linguagem natural em linguagens de consulta de grafo downstream. Enquanto técnicas de recuperação densa baseadas em similaridade de cosseno se destacam em capturar semânticas imprecisas e recuperar informações relacionadas mesmo quando a consulta não é uma correspondência exata, existem casos em que a precisão é crítica. Isso torna o GraphRAG particularmente valioso em domínios onde a ambiguidade é inaceitável, como em conformidade, áreas jurídicas ou conjuntos de dados altamente curados.
Dito isso, as duas abordagens não são mutuamente exclusivas e são frequentemente combinadas para alavancar seus respectivos pontos fortes. A recuperação densa pode lançar uma rede ampla para relevância semântica, enquanto o grafo de conhecimento refina os resultados com correspondências exatas ou raciocínio sobre relacionamentos.
Quando escolher RAG Tradicional em vez de GraphRAG
Embora o GraphRAG tenha vantagens únicas, ele também apresenta desafios. Um obstáculo chave é definir o problema corretamente — nem todos os dados ou casos de uso são adequados para um Grafo de Conhecimento. Se a tarefa envolve texto altamente não estruturado ou não requer relacionamentos explícitos, a complexidade adicional pode não valer a pena, levando a ineficiências e resultados subótimos.
Outro desafio é estruturar e manter o Grafo de Conhecimento. Projetar um esquema eficaz requer planejamento cuidadoso para equilibrar detalhe e complexidade. Um design de esquema ruim pode impactar o desempenho e a escalabilidade, enquanto a manutenção contínua exige recursos e expertise.
Desempenho em tempo real é outra limitação. Bancos de dados de grafos como Neo4j podem ter dificuldades com consultas em tempo real em conjuntos de dados grandes ou frequentemente atualizados devido a travessias complexas e consultas multi-hop, tornando-os mais lentos que sistemas de recuperação densa. Nesses casos, uma abordagem híbrida — usando recuperação densa para velocidade e refinamento de grafo para análise pós-consulta — pode fornecer uma solução mais prática.
GraphDB e embeddings
Bancos de dados de Grafos como Neo4j frequentemente também fornecem capacidades de busca vetorial via índices HNSW. A diferença aqui é como eles usam esse índice para fornecer melhores resultados em comparação com bancos de dados vetoriais. Quando você executa uma consulta, Neo4j usa o índice HNSW para identificar os embeddings mais próximos com base em medidas como similaridade de cosseno ou distância Euclidiana. Esta etapa é crucial para encontrar um ponto de partida em seus dados que se alinhe semanticamente com a consulta, aproveitando as semânticas implícitas fornecidas pela busca vetorial.
O que diferencia os bancos de dados de grafos é sua capacidade de combinar essa recuperação inicial baseada em vetores com suas poderosas capacidades de travessia. Após encontrar o ponto de entrada usando o índice HNSW, Neo4j aproveita as semânticas explícitas definidas pelos relacionamentos no grafo de conhecimento. Esses relacionamentos permitem que o banco de dados atravesse o grafo e colete contexto adicional, descobrindo conexões significativas entre os nós. Essa combinação de semânticas implícitas de embeddings e semânticas explícitas de relacionamentos de grafos permite que os bancos de dados de grafos forneçam respostas mais precisas e ricas em contexto do que qualquer uma das abordagens conseguiria sozinha.
GraphRAG de Ponta a Ponta no Databricks
GraphRAG é um ótimo exemplo de Sistemas de IA Compostos em ação, onde múltiplos componentes de IA trabalham juntos para tornar a recuperação mais inteligente e consciente do contexto. Nesta seção, daremos uma olhada geral em como tudo se encaixa.
Arquitetura GraphRAG
Abaixo está um diagrama de arquitetura demonstrando como as perguntas em linguagem natural de um analista podem recuperar informações de um grafo de conhecimento Neo4j.
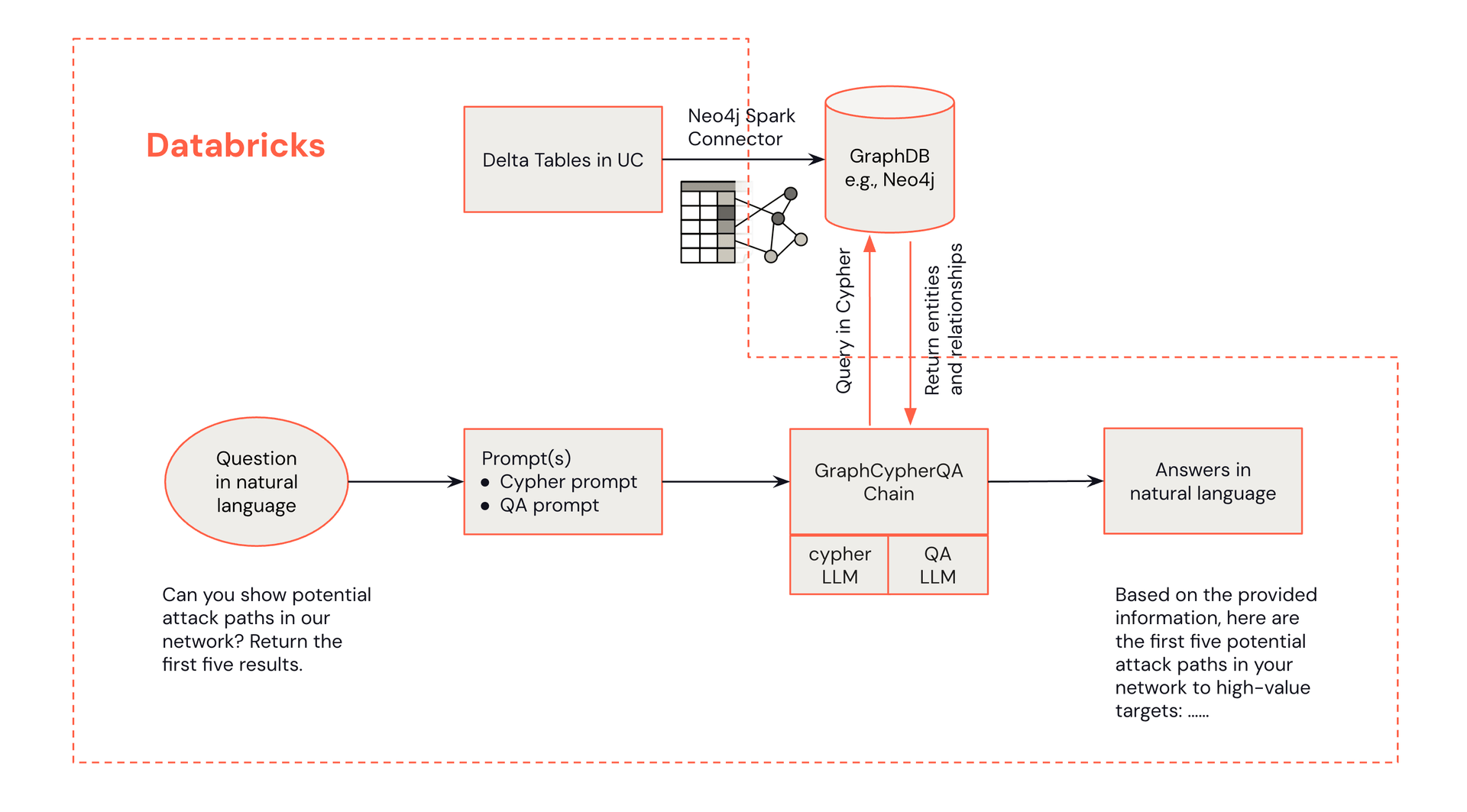
A arquitetura para detecção de ameaças com GraphRAG combina os pontos fortes do Databricks e Neo4j:
- Interface do Analista do Centro de Operações de Segurança (SOC): Analistas interagem com o sistema através do Databricks, iniciando consultas e recebendo recomendações de alertas.
- Processamento no Databricks: O Databricks lida com o processamento de dados, integração de LLM e serve como o hub central para a solução.
- Grafo de Conhecimento Neo4j: Neo4j armazena e gerencia o grafo de conhecimento de cibersegurança, permitindo consultas complexas de relacionamento.
Visão Geral da Implementação
Para este blog, estamos pulando os detalhes do código — confira o repositório do GitHub para a implementação completa. Vamos percorrer as etapas chave para construir e implantar um agente GraphRAG.
- Construir um Grafo de Conhecimento a partir de Tabelas Delta: No notebook, discutimos cenários sobre dados estruturados e não estruturados. O Conector Spark Neo4j fornece um meio muito simples de transformar dados no Unity Catalog em entidades de grafo (nós/relacionamentos).
- Implantar LLMs para Consulta Cypher e QA: GraphRAG requer LLMs para geração de consulta e sumarização. Demonstramos como implantar gpt-4o, llama-3.x, um modelo text2cypher ajustado do HuggingFace e servi-los usando um endpoint de throughput provisionado.
- Criar e Testar Cadeia GraphRAG: Demonstramos como usar diferentes LLMs para Cypher e LLMs de QA e prompts via GraphCypherQAChain. Isso nos permite ajustar ainda mais com resultados de rastreamento de caixa de vidro usando MLflow Tracing.
- Implante o Agente com o Agent Bricks Custom Agents: Use o Agent Bricks Custom Agents e o MLflow para implantar o agente. No notebook, o processo inclui o registro do modelo, seu registro no Unity Catalog, sua implantação em um endpoint de serviço e o lançamento de um aplicativo de revisão para bate-papo.

Conclusão
GraphRAG é uma abordagem poderosa, porém altamente personalizável, para construir agentes que entregam resultados de IA mais determinísticos e contextualmente relevantes. No entanto, seu design é específico para cada caso, exigindo arquitetura cuidadosa e ajuste específico para o problema. Ao integrar grafos de conhecimento com a infraestrutura escalável e as ferramentas da Databricks, você pode construir sistemas de IA Composta de ponta a ponta que combinam perfeitamente dados estruturados e não estruturados para gerar insights acionáveis com um entendimento contextual mais profundo.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.