A Convergência de Formatos Abertos de Tabela e Catálogos Abertos: Catalog Commits está Geralmente Disponível
O Catalog Commits é a próxima evolução do lakehouse aberto
por Benjamin Mathew, Michelle Leon, Lukas Rupprecht e Ryan Johnson
Catalog Commits dão um grande passo para unificar o lakehouse, alinhando o Delta com o modelo orientado a catálogo do Iceberg. Com Catalog Commits, os catálogos se tornam o sistema de coordenação para tabelas Delta, intermediando a descoberta, o acesso e o estado das tabelas entre os motores.
Hoje, temos o prazer de anunciar a Disponibilidade Geral dos Catalog Commits para tabelas gerenciadas do UC. Esta é uma atualização importante da plataforma que expande a interoperabilidade das tabelas gerenciadas do UC, fortalece as capacidades de governança do UC e desbloqueia novos recursos, incluindo transações multi-statement e multi-tabela.
Neste blog, abordaremos…
- Como Delta e Unity Catalog estão coevoluindo
- Os problemas que Catalog Commits resolve
- Como Catalog Commits funciona
- Como habilitar Catalog Commits em tabelas gerenciadas do Unity Catalog
A evolução do Delta Lake e do Unity Catalog
Quando o Delta Lake foi criado, o lakehouse primeiro precisava de transações confiáveis em armazenamento em nuvem aberto. Na época, os catálogos não foram projetados para coordenar cargas de trabalho de dados modernas, então o Delta fez uma escolha arquitetônica revolucionária: ele trouxe garantias ACID diretamente para os sistemas de arquivos do data lake. Essa base tornou o lakehouse possível.
À medida que o lakehouse se tornou o sistema de registro para mais equipes, motores e cargas de trabalho de IA, a necessidade de governança unificada em todos esses diferentes ativos tornou-se crítica. O Unity Catalog forneceu essa camada de governança ausente: um único local para descobrir, proteger, auditar e coordenar o acesso a dados e ativos de IA em nuvens, formatos e motores.
Juntos, Delta Lake e Unity Catalog formaram a base do lakehouse moderno. No entanto, eles operavam lado a lado - o Delta gerenciando o estado transacional na camada de armazenamento e o Unity Catalog governando o acesso na camada de catálogo. Essa arquitetura foi suficiente no início, mas à medida que as organizações escalaram para mais motores e cargas de trabalho, esse design levou a novos desafios de coordenação.
Desafios atuais de coordenação entre tabelas e catálogos
A arquitetura original orientada a sistemas de arquivos do Delta foi poderosa para trazer transações para data lakes, mas não foi projetada para um mundo onde o catálogo deve coordenar consistentemente a identidade, o acesso e o estado das tabelas em muitos motores. À medida que as organizações colocam demandas maiores em seus dados, a falta de coordenação de catálogo expôs três desafios persistentes:
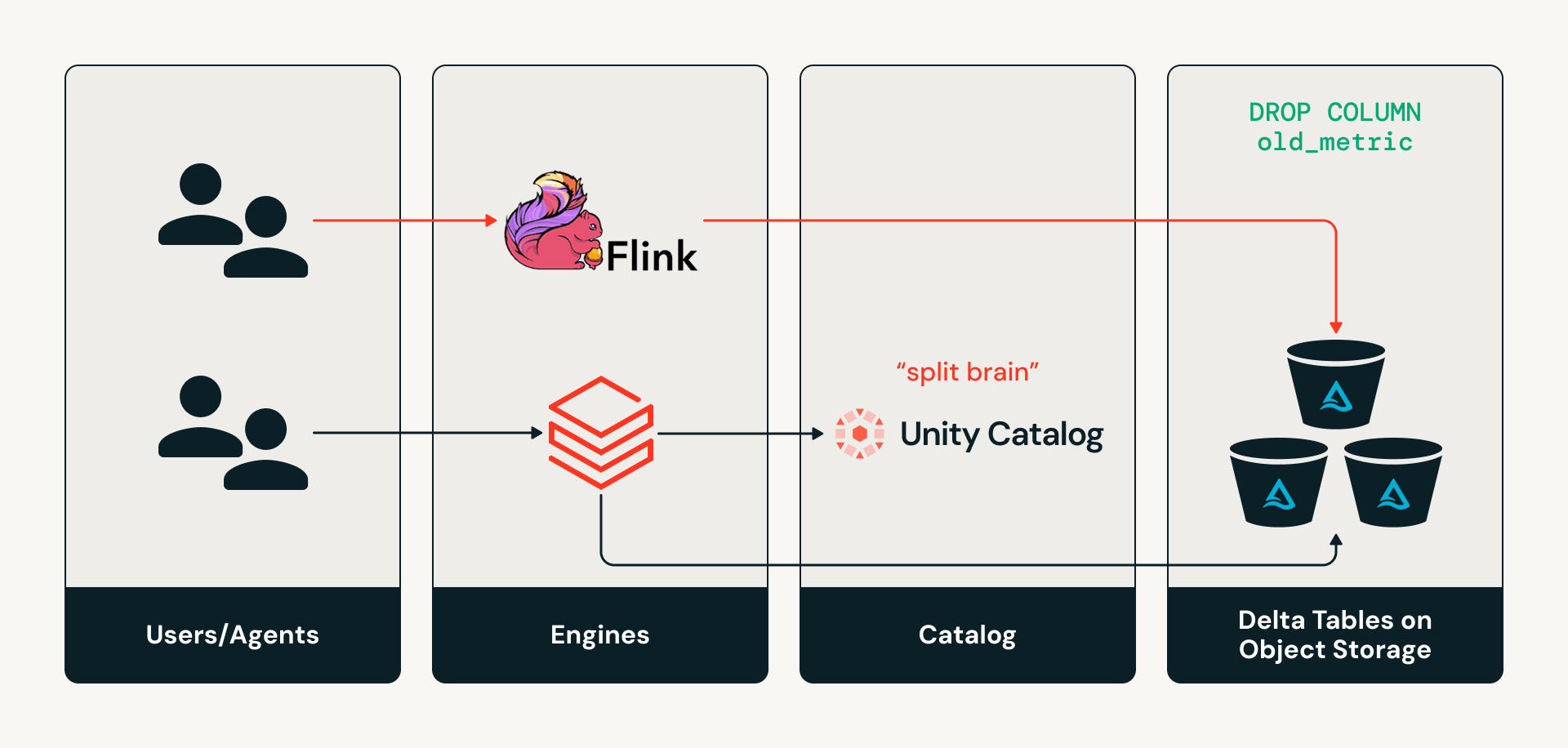
- O problema de "cérebro dividido": motores externos gravando em tabelas Delta diretamente no armazenamento de objetos fazem com que metadados do catálogo, como esquemas, divirjam silenciosamente do estado real da tabela.
- Expansão de acesso multi-motor e multi-agente: cada motor, ferramenta e agente pode acessar tabelas de maneiras diferentes, resultando em descoberta de tabelas fragmentada, auditoria inconsistente e nenhuma aplicação padronizada de controles de linha ou coluna entre os sistemas.
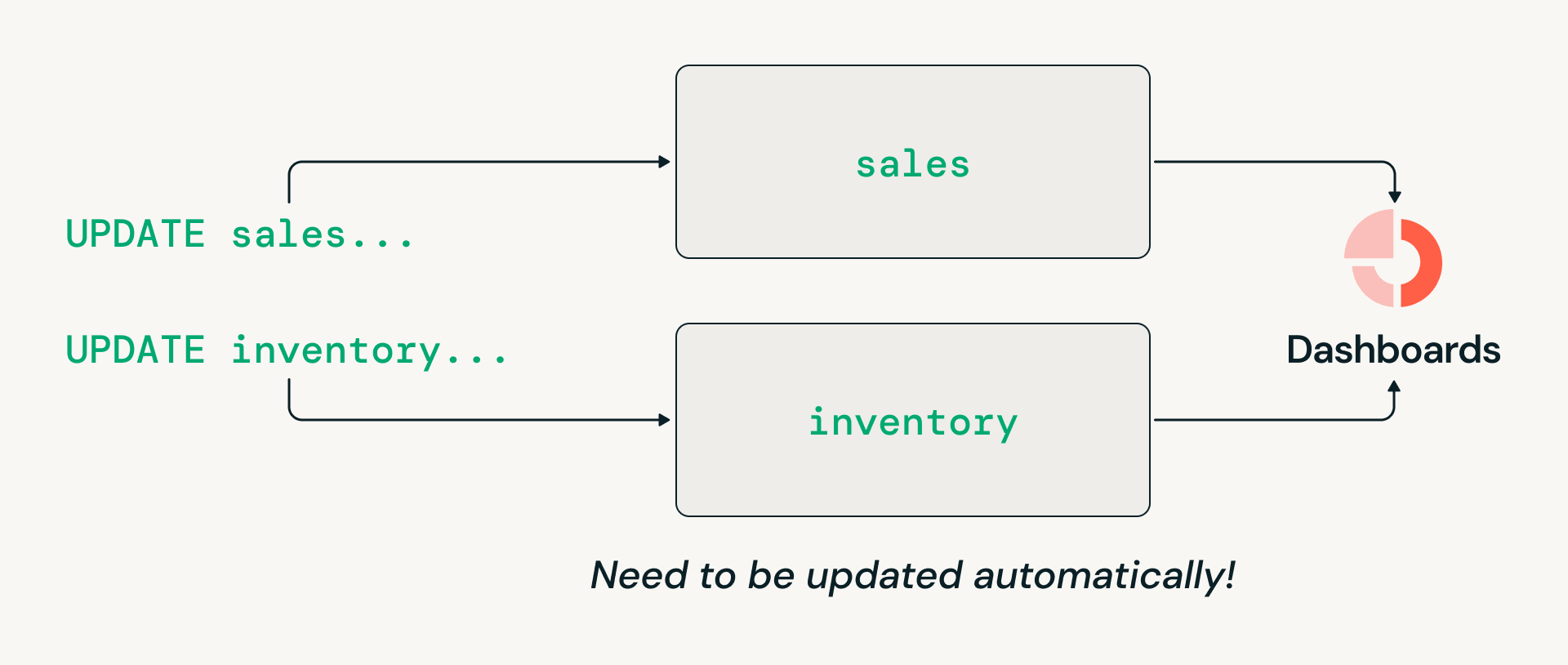
- Coordenação de transações multi-tabela: arquiteturas de lakehouse abertas historicamente não suportaram gravações atômicas que abrangem várias tabelas, então as organizações foram forçadas a manter data warehouses legados especificamente para cargas de trabalho transacionais.
Desafio #1: Problema de “cérebro dividido” – mantendo catálogos e tabelas de governança sincronizados
Hoje, os catálogos não estão no caminho de leitura ou gravação para motores Delta. Portanto, se um motor como Apache Flink quiser fazer uma alteração de esquema em uma tabela gravando diretamente na camada de armazenamento, o catálogo ficará ciente dessas alterações, criando um estado de “cérebro dividido” onde os metadados do catálogo e o estado real da tabela divergem. Isso pode causar desvio silencioso de metadados e falhas em pipelines downstream.
Desafio #2: Expansão de acesso multi-motor e multi-agente
Organizações modernas usam muitos motores e ferramentas para analisar dados, construir pipelines e potencializar a IA. Historicamente, esses sistemas acessaram dados diretamente do armazenamento de objetos usando caminhos estáticos. Isso acopla firmemente as cargas de trabalho ao armazenamento físico, tornando as tabelas difíceis de descobrir. Além disso, como cada motor lê tabelas Delta diretamente da camada de armazenamento, que geralmente suporta apenas permissões de alto nível, é muito desafiador impor governança consistente em nível de linha/coluna em todos os motores. Da mesma forma, auditar o acesso a dados permanece fragmentado porque não há uma camada de acesso consistente para capturar atividades entre os motores, então os administradores podem ter uma visão inconsistente de como os dados são realmente usados.
As organizações precisam de um local central para descobrir, governar e auditar seus dados. Essa necessidade está se tornando ainda mais urgente à medida que os agentes de IA emergem como um consumidor primário de dados corporativos.
Desafio #3: Coordenação de transações em várias tabelas
Cargas de trabalho de data warehousing frequentemente exigem transações multi-tabela, como atualizar atomicamente vendas e estoque para que leitores downstream sempre vejam uma visão consistente. No entanto, o design histórico orientado a sistemas de arquivos do Delta Lake limitava as transações a tabelas individuais. Como resultado, embora muitas organizações queiram consolidar na arquitetura do lakehouse, elas tiveram que manter data warehouses legados especificamente para essas cargas de trabalho.
Catalog Commits é a próxima evolução do lakehouse aberto
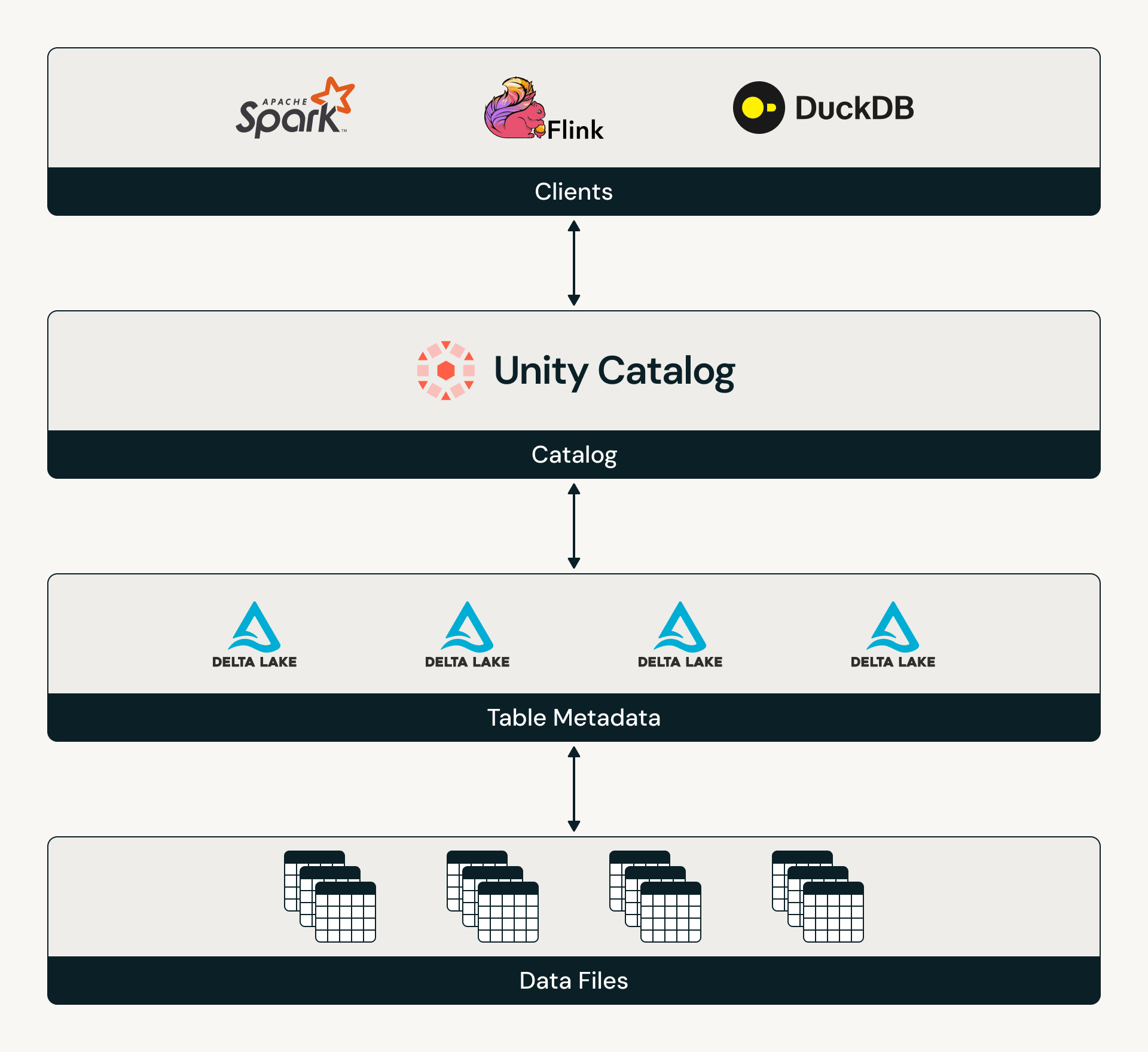
Catalog Commits é o padrão aberto para tabelas Delta se integrarem a um catálogo, tornando o catálogo responsável por coordenar o acesso às tabelas e rastrear o estado mais recente da tabela. Agora que tanto Delta quanto Iceberg são orientados a catálogo, os clientes podem confiar que suas tabelas terão um modelo padronizado de descoberta e governança de tabelas. Para saber mais sobre a especificação Catalog Commits, leia o protocolo Delta e veja a implementação de referência do Unity Catalog para Catalog Commits.
No Databricks, Catalog Commits podem ser habilitados em tabelas Delta gerenciadas pelo UC. Uma vez habilitado, o Unity Catalog intermedia todos os acessos às tabelas, criando um modelo consistente de descoberta e autorização para qualquer motor. Isso permite que as organizações centralizem verdadeiramente a governança sobre seus ambientes.
Catalog Commits resolve desafios de longa data de cérebro dividido, expansão multi-motor e coordenação multi-tabela.
1. Eliminando o problema de cérebro dividido: O estado da tabela e o catálogo permanecem sincronizados porque todos os motores acessam as tabelas por meio das mesmas APIs, eliminando qualquer risco de desvio silencioso de metadados.
Desbloqueia motores externos gravando em tabelas Delta gerenciadas pelo Unity Catalog
"Historicamente, transmitir dados para um lakehouse governado significava reconciliar metadados do catálogo fora de banda e torcer para que nada divergisse. Catalog Commits remove completamente essa lacuna. Com o serviço Kafka nativo da StreamNative - alimentado pelo Ursa para a arquitetura sem disco e sem líder do Kafka - os dados são transmitidos e confirmados diretamente através do Unity Catalog, de modo que cada registro chegue como uma linha governada que é instantaneamente consultável por qualquer motor."—Sijie Guo, Co-fundador e CEO, StreamNative
2. Resolvendo a expansão de acesso multi-motor: Com cada motor e agente passando por APIs de catálogo padronizadas para resolver tabelas, as organizações não precisam mais codificar caminhos de armazenamento ou gerenciar permissões de nível de sistema de arquivos de alto nível.
Desbloqueia governança consistente e aprimorada em todos os motores
3. Habilita cargas de trabalho tradicionais de data warehousing no lakehouse: O motor Databricks e o Unity Catalog podem coordenar gravações atômicas que abrangem várias tabelas. Isso traz semântica ACID multi-tabela para o lakehouse, desbloqueando cargas de trabalho tradicionais de data warehousing.
Desbloqueia a execução de transações multi-tabela no Databricks
“Transações, combinadas com todos os novos recursos SQL como SQL Scripting e Stored Procedures, nos permitem migrar com confiança nossas cargas de trabalho de data warehousing mais críticas para o Databricks. Essas cargas de trabalho sustentam análises essenciais em nossos negócios, e ter garantias transacionais robustas no lakehouse é um divisor de águas.” —Gal Doron, Head of Data, AnyClip
Além disso, habilitar Catalog Commits em tabelas gerenciadas pelo UC também desbloqueia:
- Auditoria holística: O Unity Catalog centraliza metadados de tabelas e políticas de acesso, permitindo que as equipes inspecionem permissões e propriedade de tabelas por meio de uma interface de catálogo consistente, em vez de depender apenas de logs de armazenamento de baixo nível.
- Otimizações automatizadas de tabelas: O Unity Catalog aproveita sua visibilidade em todos os acessos a tabelas para organizar otimamente os dados das organizações de acordo com seus padrões de consulta específicos, por meio de Liquid Clustering e Predictive Optimization.
- Bases para melhor desempenho: O Unity Catalog pode informar diretamente os motores sobre metadados em nível de tabela sem que o motor precise buscar metadados do armazenamento em nuvem, removendo uma fonte significativa de latência de metadados.
Juntas, essas funcionalidades tornam as tabelas gerenciadas pelo UC com Catalog Commits a base mais aberta, governada e performática para o lakehouse moderno.
Habilite Catalog Commits em suas tabelas hoje mesmo
Catalog Commits no Databricks está em Disponibilidade Geral hoje! Ao habilitar Catalog Commits em tabelas gerenciadas pelo Unity Catalog, os seguintes recursos são desbloqueados:
- Interoperabilidade aprimorada: Gravações de motores externos em tabelas Delta gerenciadas pelo UC
- Governança mais forte: Desbloqueia governança consistente e aprimorada sobre todos os motores
- Novos recursos: Transações multi-instrução e multi-tabela
Os produtos Databricks que leem ou escrevem em tabelas gerenciadas pelo UC, desde a ingestão até o consumo gold, agora suportam Catalog Commits. Isso inclui Streaming Tables, Delta Sharing, Zerobus, Lakeflow Connect, AI Gateway, MLflow e Lakeflow Job Triggers. Da mesma forma, Catalog Commits é atualmente suportado por motores em todo o ecossistema, incluindo Delta Spark, Delta Flink, Starburst Trino, DuckDB e StreamNative.
Também é fácil para qualquer motor suportar Catalog Commits integrando-se ao Delta Kernel, uma biblioteca compartilhada de APIs que abstrai os detalhes do protocolo. O Delta Kernel facilita para os conectores suportarem os recursos mais recentes do Delta com simples atualizações de versão.
Criar uma tabela Delta gerenciada pelo UC com Catalog Commits habilitado é fácil. Usando Databricks Runtime 16.4+, execute:
Para atualizar uma tabela Delta gerenciada pelo UC existente para habilitar Catalog Commits, use Databricks Runtime 18.0+ e execute:
Comece com Catalog Commits e junte-se a nós no Data and AI Summit para saber mais sobre nosso trabalho na construção do open lakehouse!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.