The Convergence of Open Table Formats and Open Catalogs: Catalog Commits is Generally Available
Catalog Commits is the next evolution of the open lakehouse
by Benjamin Mathew, Michelle Leon, Lukas Rupprecht and Ryan Johnson
Catalog Commits take a big step forward in unifying the lakehouse by aligning Delta with Iceberg’s catalog-oriented model. With Catalog Commits, catalogs become the system of coordination for Delta tables, brokering table discovery, access, and state across engines.
Today, we are excited to announce the General Availability of Catalog Commits for UC managed tables. This is a major platform upgrade that expands UC managed tables’ interoperability, strengthens UC’s governance capabilities, and unlocks new features including multi-statement, multi-table transactions.
In this blog, we will cover…
- How Delta and Unity Catalog are co-evolving
- The problems that Catalog Commits solve
- How Catalog Commits work
- How to enable Catalog Commits on Unity Catalog managed tables
The evolutions of Delta Lake and Unity Catalog
When Delta Lake was created, the lakehouse first needed reliable transactions on open cloud storage. At the time, catalogs were not designed to coordinate modern data workloads, so Delta made a revolutionary architectural choice: it brought ACID guarantees directly to data lake filesystems. This foundation made the lakehouse possible.
As the lakehouse became the system of record for more teams, engines, and AI workloads, the need for unified governance across these different assets became critical. Unity Catalog provided that missing governance layer: a single place to discover, secure, audit, and coordinate access to data and AI assets across clouds, formats, and engines.
Together, Delta Lake and Unity Catalog formed the foundation of the modern lakehouse. However, they operated side by side - Delta managing transactional state at the storage layer, and Unity Catalog governing access at the catalog layer. This architecture was sufficient early on, but as organizations scaled across more engines and workloads, this design led to new coordination challenges.
Today’s challenges coordinating across tables and catalogs
Delta’s original filesystem-oriented architecture was powerful for bringing transactions to data lakes, but it was not designed for a world where the catalog must consistently coordinate table identity, access, and state across many engines. As organizations place greater demands on their data, the lack of catalog coordination exposed three persistent challenges:
- The "split-brain" problem: external engines writing to Delta tables directly in object storage cause catalog metadata, like schemas, to silently diverge from the actual table state.
- Multi-engine, multi-agent access sprawl: every engine, tool, and agent can access tables differently, resulting in fragmented table discovery, inconsistent auditing, and no standardized enforcement of row or column-level controls across systems.
- Multi-table transaction coordination: open lakehouse architectures historically have not supported atomic writes spanning multiple tables, so organizations were forced to maintain legacy data warehouses specifically for transactional workloads.
Challenge #1: “Split brain” problem – keeping governing catalogs and tables in sync
Today, catalogs are not on the read or write path for Delta engines. So if an engine such as Apache Flink wants to make a schema change to a table by directly writing to the storage layer, the catalog is left unaware of those changes, creating a “split-brain” state where the catalog metadata and the actual table state diverge. This can cause silent metadata drift and downstream pipeline failures.
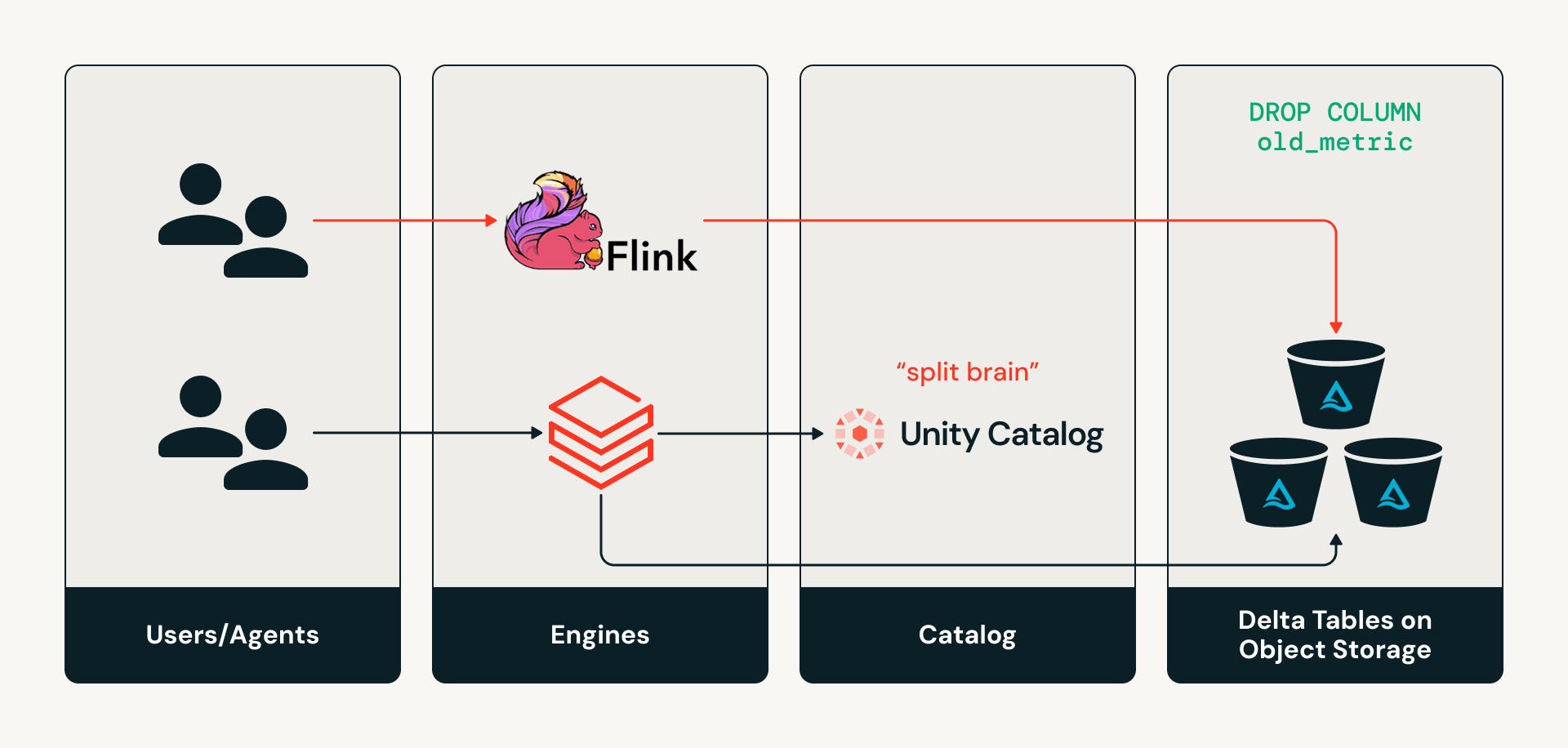
Challenge #2: Multi-engine, multi-agent access sprawl
Modern organizations use many engines and tools to analyze data, build pipelines, and power AI. Historically, these systems have accessed data directly from object storage using static paths. This tightly couples workloads to physical storage, making tables difficult to discover. Additionally, because each engine reads Delta tables directly from the storage layer, which usually only supports coarse-grained permissions, it’s very challenging to enforce consistent row/column-level governance across all engines. Likewise, auditing data access remains fragmented because there is no consistent access layer to capture activity across engines, so admins may have an inconsistent view of how data is actually used.
Organizations need a central place for discovering, governing, and auditing their data. This need is becoming even more urgent as AI agents emerge as a primary consumer of enterprise data.
Challenge #3: Coordinating transactions across multiple tables
Data warehousing workloads often require multi-table transactions, such as atomically updating sales and inventory tables so that downstream readers always see a consistent view. However, Delta Lake’s historical filesystem-oriented design limited transactions to individual tables. As a result, even though many organizations want to consolidate on the lakehouse architecture, they’ve had to maintain legacy data warehouses specifically for these workloads.
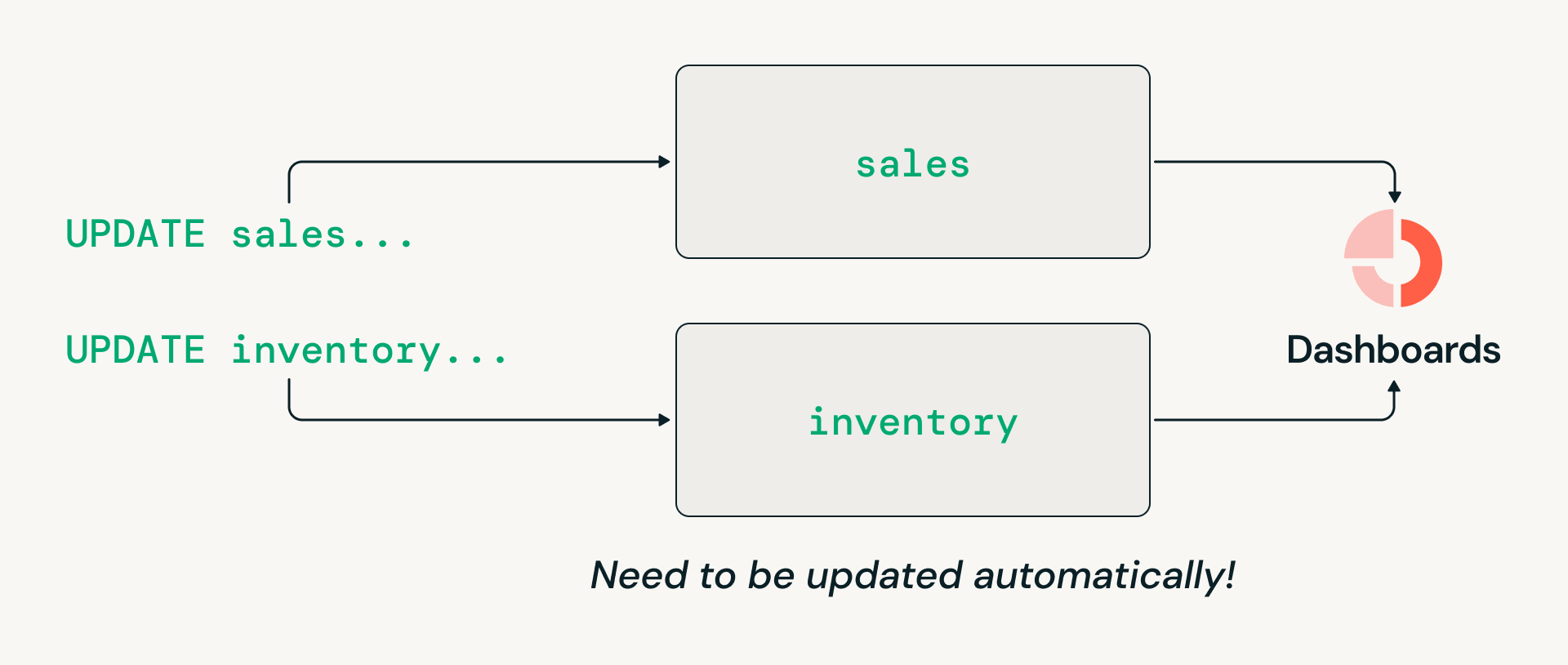
Catalog Commits is the next evolution of the open lakehouse
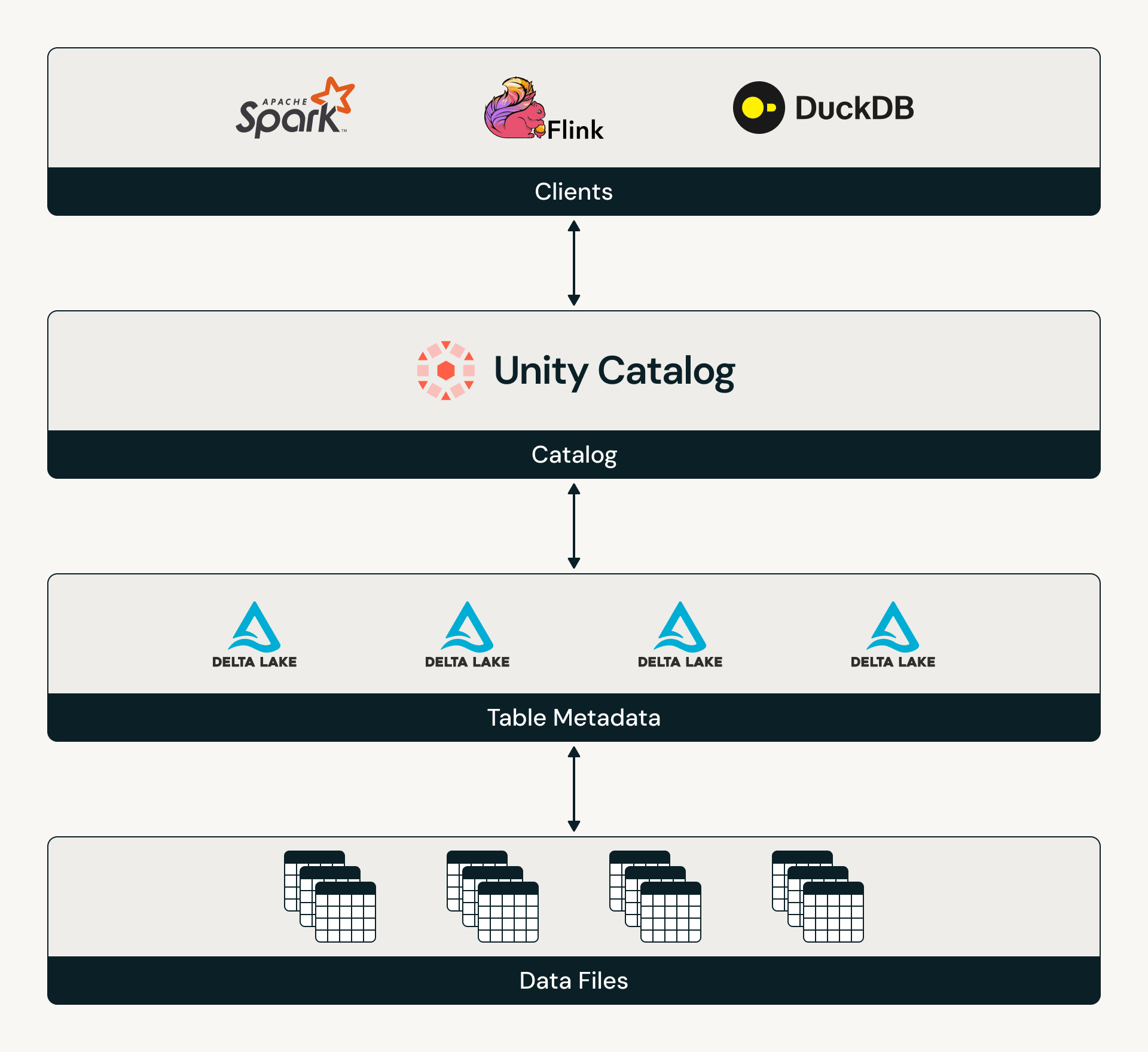
Catalog Commits is the open standard for Delta tables to integrate with a catalog, making the catalog responsible for coordinating table access and tracking the latest table state. Now that both Delta and Iceberg are catalog-oriented, customers can rely on their tables having a standardized model of table discovery and governance. To learn more about the Catalog Commits specification, read the Delta protocol and see Unity Catalog’s reference implementation of Catalog Commits.
On Databricks, Catalog Commits can be enabled on UC managed Delta tables. Once enabled, Unity Catalog brokers all table accesses, creating a consistent discovery and authorization model for any engine. This enables organizations to truly centralize governance over their estates.
Catalog Commits solves longstanding split-brain, multi-engine sprawl, and multi-table coordination challenges.
1. Eliminating the split-brain problem: Table state and the catalog stay in sync because all engines access tables through the same APIs, eliminating any risk of silent metadata drift.
Unlocks external engines writing to Unity Catalog managed Delta tables
"Historically, streaming data into a governed lakehouse meant reconciling catalog metadata out of band and hoping nothing drifted. Catalog Commits removes that gap entirely. With StreamNative’s native Kafka service - powered by Ursa for Kafka’s diskless, leaderless architecture - data is streamed and committed directly through Unity Catalog, so every record lands as a governed row that’s instantly queryable by any engine."—Sijie Guo, Co-Founder & CEO, StreamNative
2. Solving multi-engine access sprawl: With every engine and agent going through standardized catalog APIs to resolve tables, organizations no longer need to hardcode storage paths or manage coarse filesystem-level permissions.
Unlocks consistent and enhanced governance over all engines
3. Enables traditional warehousing workloads on the lakehouse: The Databricks engine and Unity Catalog can coordinate atomic writes that span multiple tables. This brings multi-table ACID semantics to the lakehouse, unlocking traditional data warehousing workloads.
Unlocks performing multi-table transactions on Databricks
“Transactions, combined with all of the new SQL features like SQL Scripting and Stored Procedures, enable us to confidently migrate our most critical warehousing workloads to Databricks. These workloads underpin essential analytics across our business, and having robust transactional guarantees on the lakehouse is a game-changer.” —Gal Doron, Head of Data, AnyClip
On top of that, enabling Catalog Commits on UC managed tables also unlocks:
- Holistic auditability: Unity Catalog centralizes table metadata and access policies, allowing teams to inspect permissions and table ownership through a consistent catalog interface rather than relying solely on low-level storage logs.
- Automated table optimizations: Unity Catalog leverages its visibility into all table accesses to optimally layout organizations’ data for their specific query patterns, via Liquid Clustering and Predictive Optimization.
- Foundations for better performance: Unity Catalog can directly inform engines of table-level metadata without the engine needing to fetch metadata from cloud storage, removing a major source of metadata latency.
Together, these capabilities make UC managed tables with Catalog Commits the most open, governed, and performant foundation for the modern lakehouse.
Enable Catalog Commits on your tables today
Catalog Commits on Databricks is Generally Available today! By enabling Catalog Commits on Unity Catalog managed tables, the following features are unlocked:
- Upgraded interoperability: External engine writes to UC managed Delta tables
- Stronger governance: Unlocks consistent and enhanced governance over all engines
- New features: Multi-statement, multi-table transactions
Databricks products that read or write to UC managed tables, from ingestion to gold-level consumption, now support Catalog Commits. These include Streaming Tables, Delta Sharing, Zerobus, Lakeflow Connect, AI Gateway, MLflow, and Lakeflow Job Triggers. Likewise, Catalog Commits is currently supported by engines across the ecosystem including Delta Spark, Delta Flink, Starburst Trino, DuckDB, and StreamNative.
It’s also easy for any engine to support Catalog Commits by integrating with Delta Kernel, a shared library of APIs that abstracts away protocol-level details. Delta Kernel makes it easy for connectors to support the latest Delta features with simple version upgrades.
Creating a UC managed Delta table with Catalog Commits enabled is easy. Using Databricks Runtime 16.4+, run:
To upgrade an existing UC managed Delta table to enable Catalog Commits, use Databricks Runtime 18.0+ and run:
Get started with Catalog Commits and join us at the Data and AI Summit to learn more about our work building the open lakehouse!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.