Proteção contra Exfiltração de Dados com Azure Databricks
Saiba em detalhes como configurar uma arquitetura segura do Azure Databricks para proteger contra exfiltração de dados
Última atualização em: 30 de outubro de 2025
Leitura Essencial
Antes de começar, certifique-se de que você está familiarizado com estes tópicos
- Arquitetura de Computação Serverless do Azure Databricks Arquitetura
- Terminologia chave do Databricks
- O que é o Azure Private Link (PL) de Front-end e Back-end?
- Requisitos de workspace com Private Link habilitado
- O que são Políticas de Service Endpoint para workspaces Azure?
- Lista de Acesso IP do controlador de entrada
- Conectividade Segura de Cluster
- Redes do Databricks
- Unity Catalog
A Plataforma Lakehouse do Azure Databricks oferece um conjunto unificado de ferramentas para construir, implantar, compartilhar e manter soluções de dados de nível empresarial em escala. O Databricks se integra ao armazenamento em nuvem e à segurança em sua conta de nuvem, e gerencia e implanta a infraestrutura de nuvem em seu nome.
O objetivo principal deste artigo é mitigar os seguintes riscos:
- Acesso a dados de um navegador na internet ou de uma rede não autorizada usando o aplicativo web Databricks.
- Acesso a dados de um cliente na internet ou de uma rede não autorizada usando a API do Databricks.
- Acesso a dados de um cliente na internet ou de uma rede não autorizada usando Azure Private Link ou Service Endpoints.
- Uma carga de trabalho comprometida no cluster Azure Databricks gravando dados em um recurso de armazenamento não autorizado no Azure ou na internet.
O Azure Databricks é um serviço de primeira parte e suporta as ferramentas e serviços nativos do Azure que ajudam a proteger dados em trânsito e em repouso. O Azure Databricks suporta controles de segurança de rede, como rotas definidas pelo usuário, regras de firewall e Network Security Groups.
Além dos objetivos técnicos para este blog, também queremos ter certeza de que os conceitos que estamos apresentando consideram:
- Simplicidade, qualquer projeto de segurança deve ser bem compreendido e mantido, e se encaixar nas habilidades de sua organização. Uma solução de segurança que é implementada e não totalmente compreendida pode ser inadvertidamente comprometida.
- O custo operacional da solução deve ser sempre levado em consideração. Se um projeto de segurança for abandonado porque o custo é muito alto - então a solução não foi eficaz. A segurança deve ser consciente em termos de custo e sustentável.
Apontaremos áreas de economia de custos ou preocupações de custos, juntamente com a tentativa de esclarecer por que e como as coisas funcionam sempre que pudermos.
Antes de começarmos, vamos dar uma olhada rápida na arquitetura de implantação do Azure Databricks aqui:
O Azure Databricks é estruturado para facilitar a colaboração segura entre equipes, enquanto gerencia muitos serviços de back-end, permitindo que você se concentre em ciência de dados, análise de dados e engenharia de dados.
O Azure Databricks é estruturado em torno de dois componentes principais: o plano de controle e o plano de computação.
Plano de Controle:
O plano de controle do Azure Databricks, gerenciado pelo Databricks em sua própria conta Azure, atua como a inteligência central da plataforma. Ele fornece serviços de back-end para autenticação de usuário, orquestração de cluster e jobs, e gerenciamento de workspace, oferecendo a interface web e os endpoints de API para interação do serviço.
Embora orquestre o ciclo de vida dos recursos de computação, ele não processa dados diretamente. Em vez disso, o plano de controle direciona o processamento de dados para o plano de computação separado, que opera dentro da assinatura Azure do cliente ou no tenant do Databricks para implantações serverless. Comandos de notebook e muitas outras configurações de workspace são armazenados no plano de controle e criptografados em repouso.
Plano de Computação:
O plano de computação é responsável por processar seus dados. O tipo específico de computação usado, serverless ou clássico, depende dos recursos de computação escolhidos e da configuração do workspace. Tanto a computação serverless quanto a clássica compartilham alguns recursos, como o armazenamento padrão do workspace (dbfs) e identidades gerenciadas que estão vinculadas ao seu tenant Azure.
Computação Serverless
Para computação serverless, os recursos operam dentro de um plano de computação no Azure, gerenciado pelo Databricks. O Azure Databricks gerencia quase toda a infraestrutura subjacente, incluindo provisionamento, escalonamento e manutenção. Essa abordagem oferece:
- Operações Simplificadas: Os usuários podem se concentrar em tarefas de engenharia de dados e ciência de dados sem a necessidade de gerenciar clusters ou máquinas virtuais.
- Eficiência de Custo: Os usuários são cobrados apenas pelos recursos de computação ativamente consumidos durante a execução da carga de trabalho, eliminando custos associados a clusters ociosos.
Recursos serverless estão disponíveis conforme necessário, reduzindo custos de tempo ocioso. Eles também rodam dentro de um limite de rede seguro na conta do Azure Databricks, com múltiplas camadas de segurança e controles de rede.
Computação Clássica do Azure Databricks
Com a computação clássica do Azure Databricks, os recursos estão localizados dentro do seu tenant do Azure Cloud. Isso fornece computação gerenciada pelo cliente, onde os clusters Databricks rodam em recursos dentro da sua assinatura Azure, não no tenant Databricks. Isso oferece:
- Isolamento Natural: As operações ocorrem dentro da sua própria assinatura Azure e rede virtual.
- Conexões Seguras: Permite conexões seguras a outros serviços Azure através de endpoints de serviço ou endpoints privados que você gerencia e controla.
Nota Importante: Clusters clássicos, incluindo warehouses SQL clássicos, podem ter tempos de inicialização mais longos em comparação com opções serverless devido à necessidade de provisionar recursos da sua assinatura Azure.
Implantação de Workspace Databricks Apenas Serverless (novo): Workspaces apenas serverless são workspaces que só podem executar computação serverless. Não há computação clássica, então todos os recursos do sistema são gerenciados pelo Azure Databricks, que cuida de toda a infraestrutura subjacente, incluindo o armazenamento padrão do workspace.
Arquitetura de Alto Nível
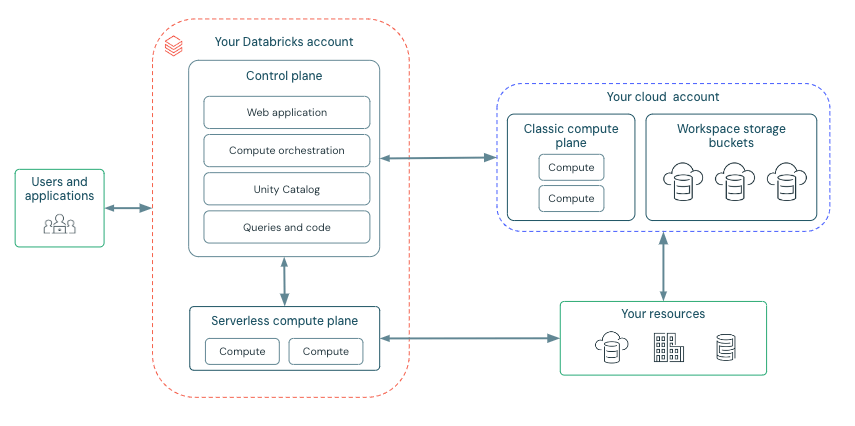
Caminho de Comunicação de Rede
Vamos entender o caminho de comunicação que gostaríamos de proteger. O Azure Databricks pode ser consumido por usuários e aplicações de várias maneiras, como mostrado abaixo:
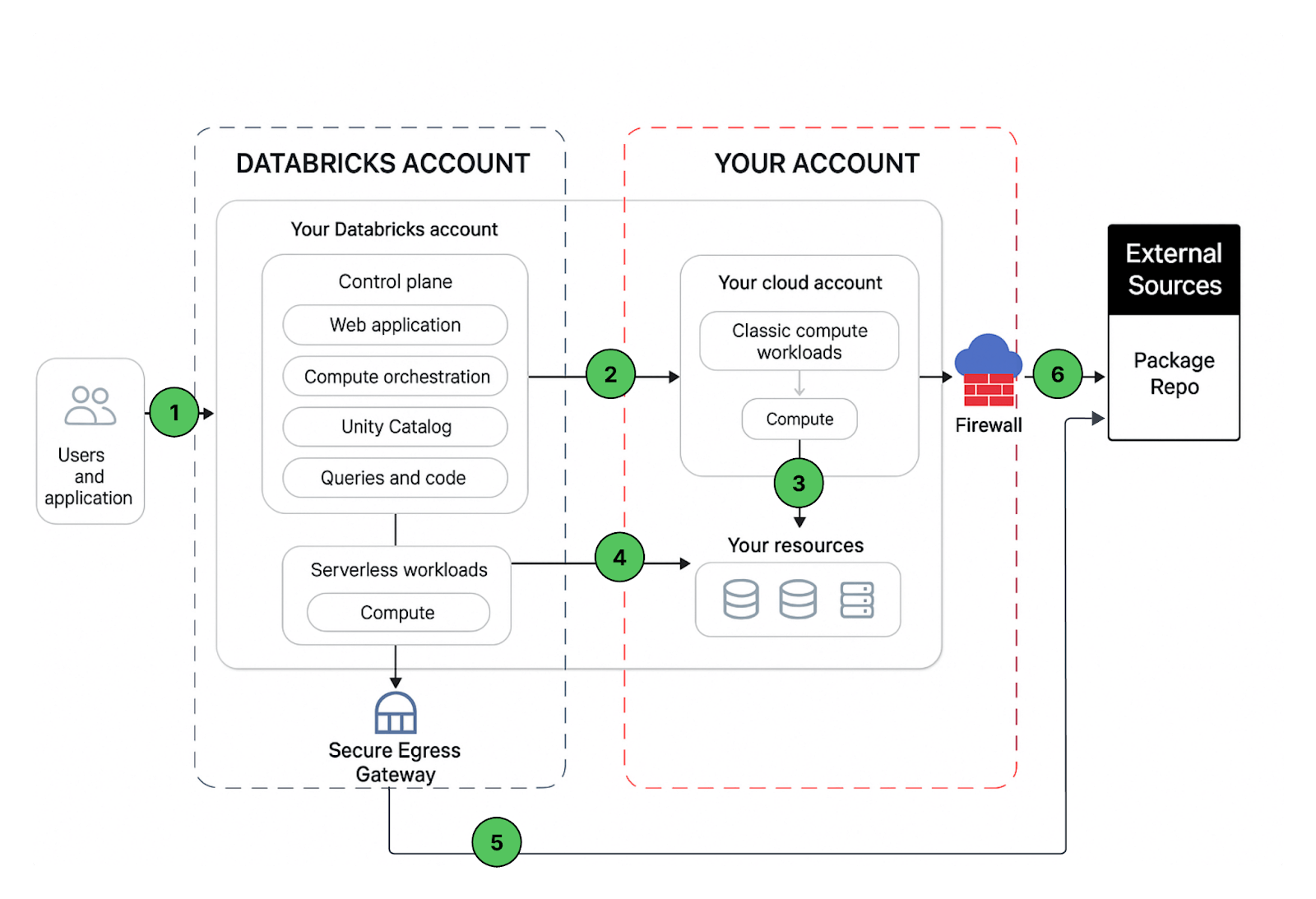
Uma implantação de workspace Databricks inclui os seguintes caminhos de rede que você pode proteger:
- Usuário ou Aplicações para o aplicativo web Azure Databricks, também conhecido como workspace, ou APIs REST do Databricks
- Rede virtual de computação clássica do Azure Databricks para o serviço do plano de controle do Azure Databricks. Isso inclui o relay de conectividade segura de cluster e a conexão do workspace para os endpoints da API REST.
- Plano de computação clássico para seus serviços de armazenamento (ex: ADLS gen2, banco de dados SQL)
- Plano de computação serverless para seus serviços de armazenamento (ex: ADLS gen2, banco de dados SQL)
- Egress seguro do plano de computação serverless via políticas de rede (firewall de egress) para fontes de dados externas, por exemplo, repositórios de pacotes como pypi ou maven
- Egress seguro do plano de computação clássico via firewall de egress para fontes de dados externas, por exemplo, repositórios de pacotes como pypi ou maven (pode ser qualquer appliance de egress rodando no Azure, ex: Palo Alto)
Da perspectiva do usuário final, o item 1 requer controles de entrada (ingress), e os itens 2 a 6 requerem controles de saída (egress).
Neste artigo, nosso foco é proteger o tráfego de saída das suas cargas de trabalho Databricks, fornecer ao leitor orientação prescritiva sobre a arquitetura de implantação proposta e, enquanto estamos nisso, compartilharemos melhores práticas para proteger também o tráfego de entrada (usuário/cliente para Databricks).
Opções de Implantação de Workspace
Existem várias opções disponíveis para criar um workspace seguro do Azure Databricks que seja acessível de conexões on-premise ou VPN (sem acesso à internet). Como uma prática recomendada, sugerimos proteger o acesso ao workspace usando endpoints privados (Private Link), seja com uma implantação padrão ou simplificada. A opção recomendada é a implantação padrão. O workspace pode ser implantado via Portal do Azure ou templates ARM tudo em um ou usando templates Terraform da Arquitetura de Referência de Segurança (SRA), que permite a implantação de workspaces Databricks e infraestrutura de nuvem configurada com as melhores práticas de segurança.
Private Link Front-End vs. Back-End: Private Link Front-End, também conhecido como conexão do usuário ao workspace. Private Link Back-End, também conhecido como conexão do plano de computação ao plano de controle:
Implantação padrão (recomendada): Para segurança aprimorada, o Databricks recomenda que você use um endpoint privado separado para suas conexões front-end (cliente) a partir de uma VNet de trânsito separada. Você pode implementar conexões Private Link front-end e back-end ou apenas a conexão back-end. Use uma VNet separada para encapsular o acesso do usuário, separada da VNet que você usa para seus recursos de computação no plano de dados Clássico. Crie endpoints Private Link separados para acesso back-end e front-end. Siga as instruções em Habilitar Azure Private Link como uma implantação padrão.
Considerações adicionais são necessárias para acesso a armazenamento, mensagens e metadados do plano de computação, pois esses serviços não podem ser acessados via endpoint privado back-end.
Contas de armazenamento gerenciadas pelo sistema (apenas plano de computação clássico): Essas contas de armazenamento são necessárias para inicializar e monitorar clusters Databricks. Essas contas de armazenamento estão no tenant do Databricks e precisam ser permitidas via políticas de endpoint de serviço (recomendado); alternativas seriam usar tags de serviço de armazenamento, que tendem a ser muito amplas e facilitam a exfiltração de dados, ou listagem individual de FQDN ou endereços IP (não recomendado):
- Artefato: Imagens do Databricks Runtime somente leitura > 11 GB / nó do cluster
- Logging: Mensagens pesadas de leitura/escrita, incluindo logging de auditoria.
- Tabelas do Sistema: Auditoria somente leitura, dados do UC e do sistema.
Armazenamento padrão do workspace (DBFS): Sistema de arquivos distribuído comum usado para espaço temporário, serviços, resultados temporários de SQL (busca na nuvem), drivers. Pode ser protegido via endpoints privados usando o recurso DBFS privado para computação clássica e endpoint de serviço ou endpoint privado para computação serverless.
Mensagens: (Event Hub, apenas plano de computação clássico) Este é um recurso acessível publicamente usado para rastreamento de linhagem e outras mensagens leves. Pode ser permitido via tag de serviço EventHub no UDR e/ou Firewall.
Metadados: (SQL, apenas plano de computação clássico): Este é um recurso acessível publicamente usado para tráfego legado do Hive metastore.
Acesso à conta de armazenamento do usuário: Contas ALDS e Blob Storage usadas para dados do cliente, em oposição a dados do sistema.
Recursos de primeira parte: Cosmos DB, Azure SQL, DataFactory etc…
Recursos externos: S3, BigQuery, Snowflake etc…
Arquitetura de Proteção de Exfiltração de Dados de Alto Nível
Recomendamos uma arquitetura de referência hub e spoke. Neste modelo, a rede virtual do hub hospeda a infraestrutura compartilhada necessária para conectar a fontes validadas e, opcionalmente, a ambientes on-premise. As redes virtuais spoke se conectam ao hub e contêm workspaces isolados do Azure Databricks para diferentes unidades de negócios ou equipes.
Essa arquitetura hub-and-spoke permite a criação de múltiplas VNets spoke adaptadas para vários propósitos e equipes. O isolamento também pode ser alcançado criando sub-redes separadas para diferentes equipes dentro de uma única VNet grande. Nesses casos, você pode estabelecer múltiplos workspaces isolados do Azure Databricks, cada um em seu par de sub-redes, e implantar o Azure Firewall em uma sub-rede separada dentro da mesma VNet.
Pré-requisitos
| Item | Detalhes |
|---|---|
| Rede Virtual |
|
| Sub-redes | Três sub-redes: Host (Pública), Container (Privada) e Sub-rede de endpoint privado (para abrigar endpoints privados para armazenamento, DBFS e outros serviços do Azure que você possa usar) |
| Tabelas de Rota | Canalizar o tráfego de saída das Sub-redes Databricks para o dispositivo de rede, Internet ou fontes de dados On-prem |
| Azure Firewall | Inspecionar qualquer tráfego de saída e tomar ações de acordo com as políticas de permitir/negar |
| Zonas DNS Privadas | Fornecer serviço DNS confiável e seguro para gerenciar e resolver nomes de domínio em uma rede virtual (pode ser criado automaticamente como parte da implantação se não estiver disponível) |
| Políticas de Endpoint de Serviço | Políticas para permitir o acesso a quaisquer contas de armazenamento que não sejam de endpoint privado, incluindo armazenamento do sistema para a conta de armazenamento do workspace (dbfs), armazenamento de artefatos e logs, e tabelas do sistema. |
| Azure Key Vault | Armazena a CMK para criptografar DBFS, Disco Gerenciado e Serviços Gerenciados. |
| Conector de Acesso do Azure Databricks | Necessário se o Unity Catalog estiver habilitado. Para conectar identidades gerenciadas a uma conta do Azure Databricks para fins de acesso a dados registrados no Unity Catalog |
| Lista de serviços do Azure Databricks para permitir na lista do Firewall | Por favor, siga esta documentação pública e faça uma lista de todos os IPs e nomes de domínio relevantes para sua implantação do databricks |
Arquitetura de Implantação
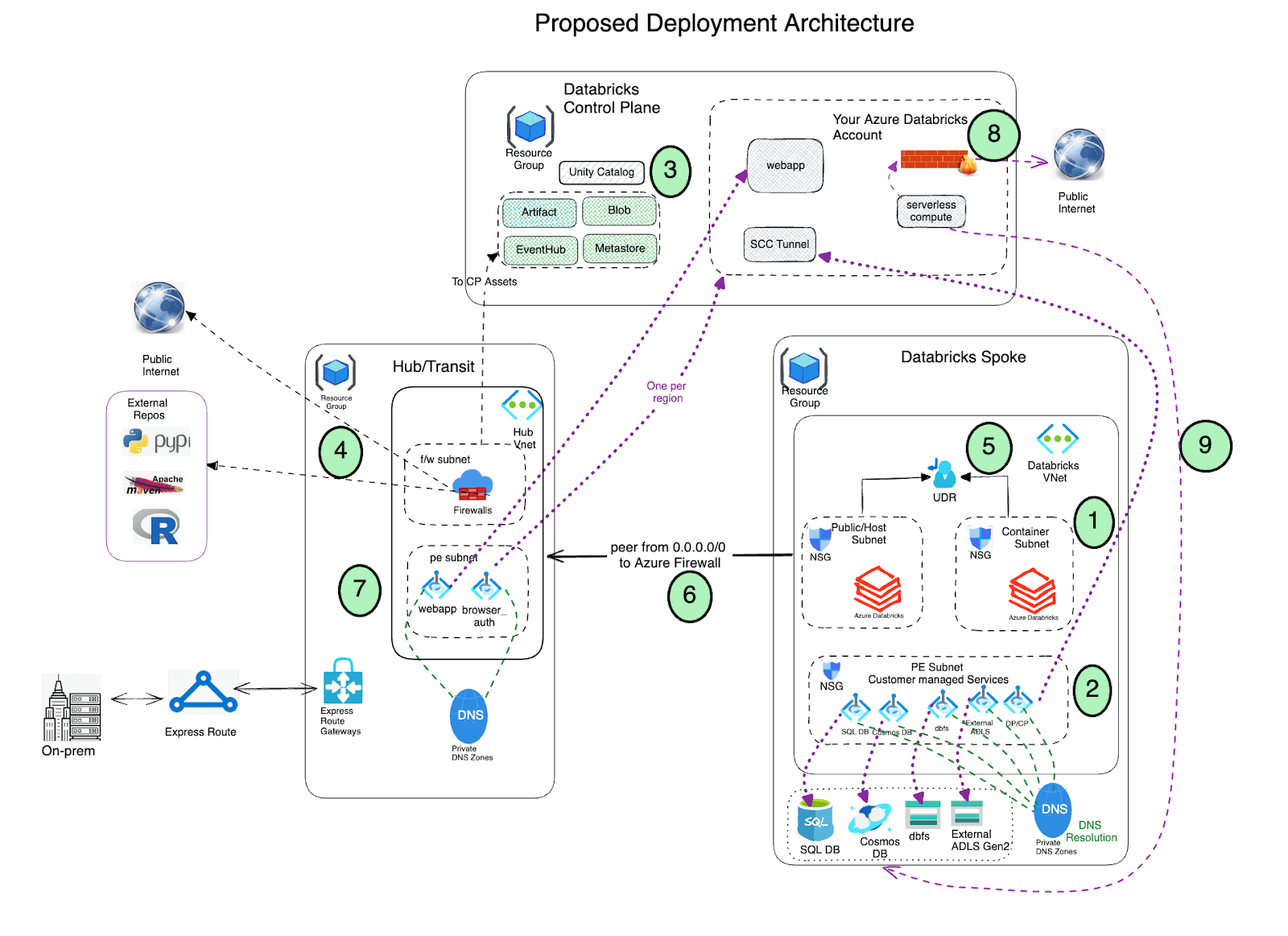
- Implante o Azure Databricks com conectividade de cluster segura (SCC) habilitada em uma rede virtual spoke usando injeção de VNet e Private Link.
- A rede virtual deve incluir duas sub-redes dedicadas a cada workspace do Azure Databricks: uma sub-rede privada e uma sub-rede pública (sinta-se à vontade para usar uma nomenclatura diferente). Observe que existe uma relação um-para-um entre essas sub-redes e um workspace do Azure Databricks. Você não pode compartilhar vários workspaces em um mesmo par de sub-redes e deve usar um novo par de sub-redes para cada workspace diferente.
- O Azure Databricks cria um blob de armazenamento padrão (também conhecido como armazenamento raiz) durante o processo de implantação, que é usado para armazenar logs e telemetria. Embora o acesso público esteja habilitado neste armazenamento, a Atribuição de Negação criada neste armazenamento proíbe qualquer acesso externo direto ao armazenamento; ele só pode ser acessado através do workspace Databricks. As implantações do Azure Databricks agora suportam conectividade privada para a conta de armazenamento padrão do workspace (DBFS).
- Importante: Como uma prática recomendada, NÃO é recomendado armazenar nenhum dado de aplicativo no contêiner raiz (DBFS) de armazenamento. O acesso ao contêiner raiz do DBFS agora pode ser desabilitado e, em vez disso, recomendamos o uso de volumes do Unity Catalog. Os volumes do Unity Catalog oferecem governança e segurança modernas sobre o armazenamento raiz do DBFS.
- Configure Private Link endpoints para seus Azure Data Services (contas de armazenamento, Eventhub, bancos de dados SQL etc.) em uma sub-rede separada dentro da rede virtual do spoke do Azure Databricks. Isso garantiria que todos os dados de carga de trabalho sejam acessados de forma segura pela rede principal do Azure com proteção de exfiltração de dados padrão implementada (consulte este blog para mais detalhes). Além disso, em geral, é totalmente aceitável implantar esses endpoints em outra rede virtual que seja emparelhada com aquela que hospeda o workspace do Azure Databricks. Observe que os Private Endpoints geram custos adicionais e é aceitável usar (com base nas políticas de segurança da sua organização) Service Endpoints em vez de Private Endpoints para acessar os Azure Data services, especificamente usando Service Endpoint Policies para acesso seguro à conta de armazenamento
- Utilize o Azure Databricks Unity Catalog para uma solução de governança unificada.
Implante o Azure Firewall (ou outra Network Virtual Appliance) em uma rede virtual de hub. Com o Azure Firewall, você pode configurar:
- Regras de aplicativo que definem nomes de domínio totalmente qualificados (FQDNs) acessíveis através do firewall. É altamente recomendável usar Regras de aplicativo para os recursos do plano de controle do Azure Databricks control plane, por exemplo, plano de controle, aplicativo web e relay SCC.
- Regras de rede que definem endereço IP, porta e protocolo para endpoints que não podem ser configurados usando FQDNs. Parte do tráfego necessário do Azure Databricks precisa ser incluída na lista de permissões usando as regras de rede.
Se você usar um appliance de firewall de terceiros em vez do Azure Firewall, isso também funciona. No entanto, observe que cada produto tem suas próprias nuances e é melhor envolver as equipes de suporte de produto e segurança de rede relevantes para solucionar quaisquer problemas pertinentes.
- O AzureDatabricks Service Tag não é necessário se private endpoints estiverem habilitados para o workspace.
- Ao usar Service Endpoint Policies, não há necessidade de regras de rede para as contas de armazenamento gerenciadas pelo Databricks (artefato, log e tabelas do sistema) no firewall. Além disso, nenhuma tag de serviço de armazenamento é necessária ou recomendada.
- O Azure Databricks também faz chamadas adicionais para o serviço NTP, CDN, Cloudflare, drivers de GPU e storages externos para conjuntos de dados de demonstração que precisam ser incluídos na lista de permissões adequadamente.
O tráfego de rede não local das sub-redes do plano de computação do Databricks deve ser roteado através de um appliance de saída, como o Azure Firewall, usando uma rota definida pelo usuário (por exemplo, uma rota padrão 0.0.0.0/0). Isso garante que todo o tráfego de saída seja inspecionado. No entanto, a saída para o plano de controle, utilizando private endpoints, contornará essas tabelas de rota e appliances de saída. Outros componentes do plano de controle, como SQL, Event Hubs e armazenamento, serão, no entanto, roteados através do seu appliance de saída.
- Para contas de armazenamento de serviço do Databricks (artefato, log e tabelas do sistema), você pode considerar a opção de contornar seu appliance de saída (NVA ou firewall) para evitar possíveis estrangulamentos e reduzir os custos de transferência de dados. O acesso ao armazenamento de artefatos sozinho pode representar até 11 GB baixados por nó do cluster. Recomendamos o uso de service endpoints para armazenamento em conjunto com Service Endpoint Policies. Essas políticas garantem que o workspace só possa acessar as contas de armazenamento designadas de artefatos, logs e tabelas do sistema incluídas em sua política anexada através de sua sub-rede. Service Endpoint Policies também são compatíveis com outros acessos a contas de armazenamento que não utilizam private link. Com service endpoint policies, nenhuma tag de serviço de armazenamento é necessária ou recomendada.
- Alternativamente, o tráfego de saída para ativos do Plano de Controle pode ser roteado diretamente para a internet adicionando regras de Service tag à tabela de rota, contornando o firewall. Isso pode ajudar a evitar estrangulamentos e custos adicionais de transferência de dados associados a Network Virtual Appliances.
Consideração Importante: Observe que isso permitirá a saída para contas e serviços de armazenamento em toda a região, não apenas para aqueles que você pretende alcançar. Este é um fator crítico a ser considerado cuidadosamente ao projetar sua arquitetura de segurança.
- Configure virtual network peering entre as redes virtuais spoke do Azure Databricks e hub do Azure Firewall.
- Implante Private endpoints para o Front end e autenticação de navegador (para SSO) na Vnet do Hub (sub-rede de private endpoint)
- Configure as políticas de rede de computação serverless para governar o tráfego de rede de saída. Observe que Serverless compute está vinculado à sua Conta do Azure Databricks
- Configure o Network Connectivity Config (NCC) do Azure Databricks para estabelecer uma conexão segura entre seus recursos de computação serverless e seus serviços de armazenamento Azure (como ADLS Gen2 e SQL Database) usando Azure Private Link.
Perguntas Comuns com Arquitetura de Proteção contra Exfiltração de Dados
Posso usar service endpoints para proteger a saída de dados para Azure Data Services?
Sim, Service Endpoints fornecem conectividade segura e direta a serviços Azure de propriedade e gerenciados por clientes (por exemplo, ADLS gen2, Azure KeyVault ou eventhub) através de uma rota otimizada na rede principal do Azure. Service Endpoints podem ser usados para proteger a conectividade a recursos externos do Azure apenas para sua rede virtual.
Posso usar service endpoint policies com serviços de armazenamento gerenciados pelo Databricks?
Sim, Service Endpoint Policies estão disponíveis em preview público a partir de 01/10/2025. Veja: Configurar políticas de service endpoint de rede virtual do Azure para acesso a armazenamento de computação clássica
Posso usar um Network Virtual Appliance (NVA) diferente do Azure Firewall?
Sim, você pode usar um NVA de terceiros, desde que as regras de tráfego de rede sejam configuradas conforme discutido neste artigo. Observe que testamos essa configuração apenas com o Azure Firewall, embora alguns de nossos clientes usem outros appliances de terceiros. O ideal é implantar o appliance na nuvem em vez de tê-los on-premises.
Posso ter uma sub-rede de firewall na mesma rede virtual que o Azure Databricks?
Sim, você pode. De acordo com a arquitetura de referência do Azure, é aconselhável usar uma topologia de rede virtual hub-spoke para planejar melhor o futuro. Caso opte por criar a sub-rede do Azure Firewall na mesma rede virtual que as sub-redes do workspace do Azure Databricks, você não precisará configurar o virtual network peering, conforme discutido na Etapa 6 acima.
Posso filtrar o tráfego IP do SCC Relay do plano de controle do Azure Databricks através do Azure Firewall?
Sim, você pode, mas gostaríamos que você mantivesse estes pontos em mente:
- Ao usar private endpoints para o plano de controle do Databricks, o tráfego entre os clusters do Azure Databricks (plano de dados) e o serviço SCC Relay permanece privado na Rede Azure e não flui pela internet pública. Este é principalmente tráfego de gerenciamento para garantir que o workspace do Azure Databricks esteja funcionando corretamente.
- Ao usar acesso que não seja private link ao plano de controle do Databricks, os intervalos de CIDR do SCC Relay e da WebUI são cobertos pelo service tag AzureDatabricks. Para outros tipos de firewall/NVA, consulte a versão mais recente de Endereços IP e domínios para serviços e ativos do Azure Databricks. Recomendamos fortemente o uso de um FQDN de regra de aplicativo para o túnel SCC em suas configurações de regra de firewall.
- O serviço SCC Relay e o plano de dados precisam ter comunicação de rede estável e confiável. Ter um firewall ou um appliance virtual entre eles introduz um único ponto de falha, por exemplo, em caso de qualquer reconfiguração incorreta de regras de firewall ou tempo de inatividade programado, o que pode resultar em atrasos excessivos na inicialização do cluster (problema transitório de firewall) ou na impossibilidade de criar novos clusters, ou afetar o agendamento e a execução de jobs.
Posso analisar o tráfego aceito ou bloqueado pelo Azure Firewall?
Sim, recomendamos o uso de Logs e Métricas do Azure Firewall para essa necessidade.
Posso atualizar um workspace não NPIP existente (implantação gerenciada do Databricks) para um workspace habilitado para NPIP ou PL?
Sim, a implantação gerenciada do Databricks pode ser atualizada para um workspace injetado em VNet.
Por que precisamos de duas sub-redes por workspace?
Um workspace requer duas sub-redes, popularmente conhecidas como sub-rede "host" (também conhecida como "pública") e "container" (também conhecida como "privada"). Cada sub-rede fornece um endereço IP para o host (Azure VM) e para o container (o runtime do Databricks, também conhecido como dbr) que é executado dentro da VM.
A sub-rede pública ou host possui IPs públicos?
Não, quando você cria um workspace usando conectividade segura de cluster, também conhecida como SCC, nenhuma das sub-redes do Databricks possui endereços IP públicos. É apenas que o nome padrão da sub-rede host é public-subnet. SCC garante que nenhum tráfego de rede de fora da sua rede entre, por exemplo, via SSH, em uma das instâncias de computação do workspace do Databricks.
É possível redimensionar/alterar os tamanhos das sub-redes após a implantação?
Sim, é possível redimensionar ou alterar os tamanhos das sub-redes após a implantação. Também é possível alterar a rede virtual ou alterar os nomes das sub-redes (preview pública com restrições). Entre em contato com o suporte do Azure e abra um caso de suporte para redimensionar as sub-redes.
É possível trocar/alterar Redes Virtuais após a implantação?
Sim, consulte a documentação pública.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.