Databricks em Databricks: Escalando a Confiabilidade de Banco de Dados
por Xiaotong Jiang
- De Reativo para Proativo: Siga nossa jornada de combate a incidentes para um mecanismo de pontuação baseado em Integração Contínua que dá um sinal antecipado da eficiência do banco de dados no ciclo de desenvolvimento.
- Scorecard de Uso do Banco de Dados: Veja a interface unificada que proporciona aos proprietários uma visão de 360 graus das consultas, esquemas, dados e tráfego - aplicando as melhores práticas em escala em milhares de bancos de dados.
- Databricks na Databricks: Veja como aproveitamos as Tabelas Delta, pipelines DLT e painéis de controle IA/BI dentro do Databricks para instrumentar, armazenar e analisar cada consulta OLTP em escala.
Resumo: Engenheiros da Databricks, ao utilizar ferramentas de análise de big data como os produtos Databricks, passaram de uma monitorização reativa para um mecanismo de pontuação proativo para impulsionar as melhores práticas de base de dados. Isso melhorou significativamente a eficiência do uso de base de dados, identificando e resolvendo consultas e definições de esquema problemáticas antes do impacto ao cliente. Por exemplo, um banco de dados suportou um aumento de tráfego 4X consumindo menos recursos (CPU, memória e disco) devido à eficiência do banco de dados otimizado impulsionada pelo mecanismo de pontuação.
Na Databricks, nossos produtos dependem de milhares de bancos de dados em várias nuvens, regiões e motores de banco de dados, suportando diversos casos de uso, como metadados de contas de usuário, agendamento de tarefas e governança de dados. Esses bancos de dados possibilitam transações confiáveis (por exemplo, atualizações atômicas nas permissões do usuário) e buscas rápidas (por exemplo, recuperação de conversas do Genie). No entanto, essa escala e variedade, combinadas com uma arquitetura multi-tenant onde as cargas de trabalho do cliente são gerenciadas eficientemente em uma infraestrutura compartilhada, criam desafios de confiabilidade significativos. Consultas ineficientes ou esquemas subótimos podem causar picos de latência ou contenção de bloqueio, impactando muitos usuários.
Neste post de blog, oferecemos uma exploração aprofundada de como nossa equipe de engenharia na Databricks adotou uma mentalidade orientada a dados para transformar nossa abordagem e alcançar a confiabilidade do banco de dados. Começaremos com os métodos tradicionais de monitoramento reativo que usamos e suas limitações. Em seguida, discutiremos como introduzimos a rastreabilidade de consultas do lado do cliente, onde os logs de consulta são ingeridos em Tabelas Delta e nos permitem fazer agregações flexíveis para obter insights sobre o uso do banco de dados durante incidentes. A partir daí, mergulharemos no Query Scorer proativo integrado ao nosso pipeline de Integração Contínua (CI) para detectar problemas antecipadamente. Os padrões de consulta identificados pelo CI são exportados como JSON e processados em notebooks, e trabalhos do Spark juntam tudo para calcular métricas em escala (lembre-se, as métricas abrangem milhares de bancos de dados e dezenas de milhares de consultas). Finalmente, descreveremos como todas essas peças se unem em um Scorecard de Uso de Banco de Dados unificado em nossos painéis de controle de AI/BI que guia as equipes para as melhores práticas. Ao longo disso, o tema é uma mudança de combate reactivo para aplicação proativa. Nossa jornada não apenas melhora a confiabilidade de nossa própria plataforma - ela também mostra como outras equipes podem usar as ferramentas de análise para implementar um pipeline "Scorecard" semelhante para monitorar e otimizar seus próprios sistemas. Embora tenhamos escolhido a Databricks pela sua integração perfeita com a nossa infraestrutura, essa estratégia é adaptável a qualquer plataforma robusta de análise.
Abordagem Reativa Original - Métricas do lado do servidor
Nos primeiros dias, a nossa abordagem aos problemas de base de dados era em grande parte reativa. Quando ocorreu um incidente no banco de dados, as principais ferramentas que usamos foram o Percona Monitoring and Management e o mysqld-exporter, ambos baseados no MySQL Performance Schema. Isso nos proporcionava insights dentro do servidor de banco de dados: poderíamos ver coisas como as consultas de maior duração, o número de linhas examinadas por diferentes operações, bloqueios mantidos e o uso de CPU.
Este monitoramento centrado no servidor foi inestimável, mas apresentava limitações significativas. Faltava o contexto do cliente: o banco de dados informava qual consulta era problemática, mas não tanto sobre quem ou o que a desencadeou. Um pico de carga pode aparecer como alta utilização de CPU e um aumento na contagem de execução de uma determinada instrução SQL. Mas sem informações adicionais, só sabíamos o sintoma (por exemplo, "A consulta Q teve um aumento de carga de 20%"), não a causa raiz ("Que inquilino ou funcionalidade está de repente emitindo a consulta Q com mais frequência?"). A investigação muitas vezes envolvia suposições e verificação cruzada de logs de vários serviços para correlacionar horários e encontrar a origem da consulta ofensiva. Isso pode ser demorado durante um incidente ativo.
Abordagem Reativa Aprimorada - Rastreamento da consulta do cliente
Para lidar com os pontos cegos do monitoramento do lado do servidor, introduzimos o rastreamento de consultas do lado do cliente. A ideia é simples, mas poderosa: sempre que uma aplicação (cliente de base de dados) na nossa plataforma envia uma consulta SQL para a base de dados, nós a marcamos e registramos com contexto adicional como ID do inquilino, nome do serviço ou API e ID do pedido. Ao propagar essas dimensões personalizadas junto com cada consulta, obtemos uma visão holística que conecta a perspectiva do banco de dados com a perspectiva do aplicativo.
Como isso ajuda na prática? Imagine que observamos pelas métricas da base de dados que "Consulta Z" está de repente lenta ou consumindo muitos recursos. Com o rastreamento do cliente, podemos imediatamente perguntar: Qual cliente ou tenant é responsável pela Consulta Z? Como nossas aplicações anexam identificadores, podemos descobrir, por exemplo, que a área de trabalho do Tenant A está emitindo a Consulta Z com uma carga X. Isso transforma uma observação vaga ("o banco de dados está sob alta carga") em uma visão acionável ("O inquilino A, através de uma API específica, está causando a carga"). Com esse conhecimento, os engenheiros de plantão podem triar rapidamente - talvez limitando a taxa de solicitações desse inquilino.
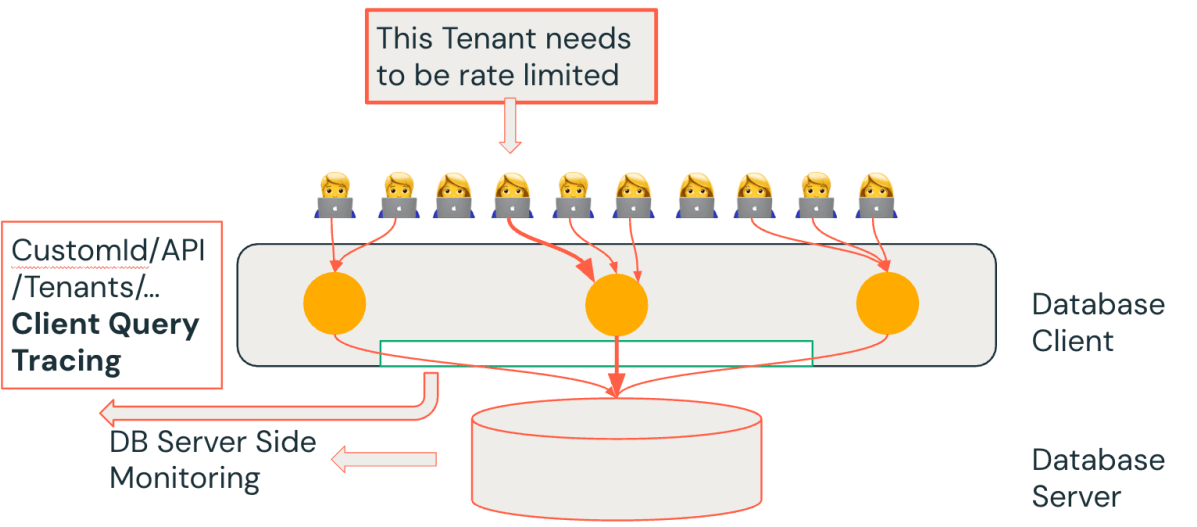
Descobrimos que o rastreamento de consultas do cliente nos salvou de vários desafios difíceis onde antes dependíamos apenas de métricas globais de banco de dados e tínhamos que especular a causa raiz. Agora, a combinação de dados do lado do servidor e do cliente responde a perguntas críticas em minutos: Qual inquilino ou recurso causou o pico na QPS da consulta? Quem está usando mais tempo de base de dados? Uma determinada chamada de API é responsável por uma quantidade desproporcional de carga ou erros? Agregando métricas nessas dimensões personalizadas, poderíamos detectar padrões como um único cliente monopolizando recursos ou uma nova funcionalidade emitindo consultas inerentemente caras.
Esse contexto adicional não apenas ajuda durante os incidentes, mas também alimenta os painéis de uso e o planejamento de capacidade. Podemos rastrear quais tenants ou cargas de trabalho estão mais sobrecarregados em um banco de dados e atribuir proativamente recursos ou isolamento conforme necessário (por exemplo, migrar um usuário particularmente pesado para sua própria instância de banco de dados). Em suma, a instrumentação no nível do aplicativo nos proporcionou uma nova dimensão de observabilidade que complementa as métricas tradicionais de banco de dados.
No entanto, mesmo com diagnósticos mais rápidos, ainda estávamos muitas vezes reagindo a problemas depois que eles ocorreram. O próximo passo lógico em nossa jornada era prevenir que essas questões chegassem à produção em primeiro lugar.
Abordagem Proativa: Pontuação de Consulta/Esquema em CI
Assim como as ferramentas de análise estática podem detectar bugs de código ou violações de estilo antes do código ser mesclado, percebemos que também poderíamos analisar proativamente os padrões de consulta e esquema do SQL. Isso levou ao desenvolvimento de um Query Scorer integrado ao nosso pipeline CI pré-merge.
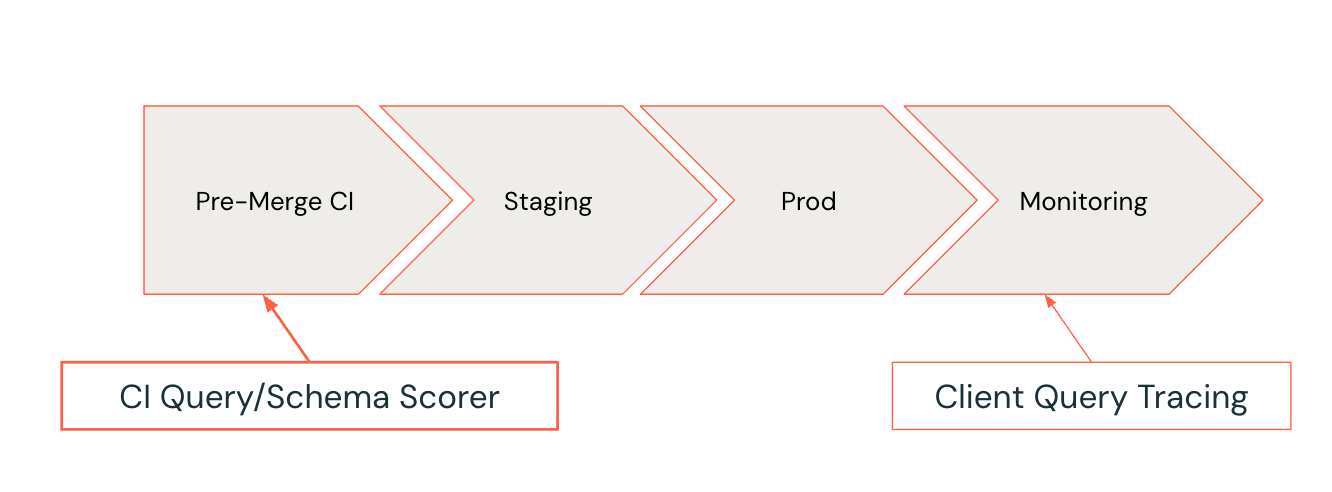
Desenvolva o Ciclo de Vida para Consulta SQL; O Scorer sinaliza anti-padrões no início do ciclo de desenvolvimento, onde são mais fáceis de corrigir.
Sempre que um desenvolvedor abre uma solicitação de pull que inclui atualizações nas consultas ou esquemas do SQL, o Avaliador de Consultas e Esquemas entra em ação. Ele avalia as alterações propostas contra um conjunto de regras de melhores práticas e anti-padrões conhecidos. Se anti-padrões forem sinalizados, o sistema CI pode falhar no teste e fornecer sugestões de correções acionáveis.
Que tipos de anti-padrões de consulta e esquema procuramos? Com o tempo, construímos uma biblioteca de anti-padrões baseada em incidentes anteriores e conhecimento geral de SQL. Alguns exemplos-chave incluem:
- Planos de execução imprevisíveis: Consultas que poderiam usar diferentes índices ou planos dependendo da distribuição de dados ou dos caprichos do otimizador. São bombas-relógio - podem funcionar bem em testes, mas comportam-se patologicamente sob certas condições.
- Consultas ineficientes: Consultas que digitalizam muito mais dados do que o necessário, como varreduras de tabelas completas em tabelas grandes, índices faltantes ou índices não seletivos. Ou as consultas excessivamente complexas com subconsultas profundamente aninhadas podem estressar o otimizador.
- DML irrestrito: operações DELETE ou UPDATE sem cláusula WHERE ou aquelas que poderiam bloquear tabelas inteiras.
- Design de Esquema Ruim: Tabelas sem chaves primárias, com índices excessivos/duplicados, ou usando colunas BLOB/TEXT de tamanho excessivo, que causa dados duplicados, escritas lentas ou desempenho degradado.
Um exemplo de consulta SQL "Bomba Relógio"
| Query SQL | Definição de tabela |
DELETE FROM t WHERE t.B = ? AND t.C = ?; | CREATE TABLE t ( A INT PRIMARY KEY, B INT, C INT, KEY idx_b (B), KEY idx_c (C) ); |
Chamamos este anti-padrão de consulta de padrão "Vários Candidatos a Índice". Isso surge quando a cláusula WHERE de uma consulta pode ser satisfeita por mais de um índice (idx_b e idx_c), oferecendo ao otimizador de consulta vários caminhos válidos para execução. Por exemplo, a partir do exemplo acima, tanto idx_b quanto idx_c poderiam ser usados para satisfazer a cláusula WHERE. Que índice o MySQL usará? Isso depende da estimativa do otimizador de consultas de qual caminho é mais barato - uma decisão que pode variar conforme a distribuição de dados muda ou se as estatísticas do índice ficam desatualizadas.
O perigo é que um caminho de índice pode ser significativamente mais custoso que o outro, mas o otimizador pode subestimar e escolher o errado.
Nós realmente tivemos um incidente onde o otimizador selecionou um índice subótimo, o que resultou no bloqueio de uma tabela inteira de mais de 100 milhões de linhas durante uma exclusão.
Nosso Avaliador de Consultas bloquearia consultas que não são estáveis. Se uma consulta pode usar vários índices e não há um plano claro e consistente, ela é marcada como perigosa. Nestes casos, solicitamos que os desenvolvedores apliquem explicitamente um índice conhecido como seguro utilizando uma cláusula FORCE INDEX , ou restruturem a consulta para um comportamento mais determinístico.
Ao impor essas regras no início do ciclo de desenvolvimento, reduzimos significativamente a introdução de novas armadilhas de banco de dados. Os engenheiros recebem feedback imediato em seus pedidos de pull se eles introduzem consultas que podem prejudicar a saúde do banco de dados - e com o tempo, eles aprendem e internalizam essas melhores práticas.
Quadro de Resultados unificado do Uso do Banco de Dados: Uma visão Holística
Capturar anti-padrões estáticos é poderoso, mas a confiabilidade do banco de dados é uma propriedade holística. Não são apenas as consultas individuais que importam - isso também é influenciado pelos padrões de tráfego, volume de dados e evolução do esquema. Para resolver isso, desenvolvemos um Scorecard Unificado de Uso de Banco de Dados que quantifica um conjunto mais amplo de boas práticas.

Nossa filosofia de preencher o jarro de eficiência do banco de dados - As rochas são tarefas Grandes e Importantes, a areia é tarefas pequenas e menos importantes e os seixos são as tarefas intermediárias.
Como calculamos essa pontuação? Integramos dados de todas as etapas do ciclo de vida de uma consulta:
- Estágio CI (Pré-Fusão): Ingerimos todas as consultas/esquema e seus Anti Padrões na tabela delta
- Fase de Produção: Usando rastreamento de consultas do lado do cliente e métricas do lado do servidor, um pipeline de Delta Live Tables (DLT) coleta dados de desempenho em tempo real - como latências de consulta, linhas verificadas versus retornadas, e taxas de sucesso/falha.
Todas essas informações são consolidadas em um Painel de AI/BI no logfood central.
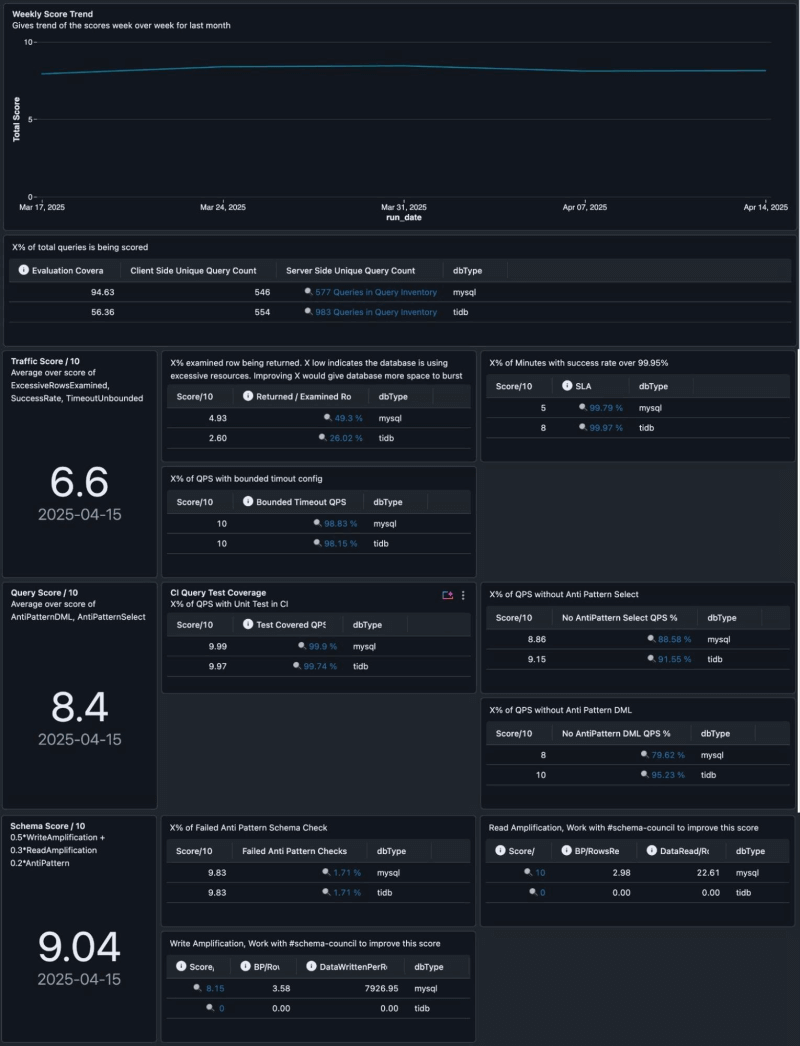
Exemplo de Scorecard de Uso de BD para um serviço. Os fatores contribuintes incluem Excesso de Linhas Examinadas, SLA, Tempo Limite, Cobertura de Teste Unitário, Anti Padrões, Amplificação de Leitura/Escrita.
Principais Conclusões
Nossa jornada para melhorar a confiabilidade do banco de dados SQL OLTP na Databricks oferece lições valiosas para a escalabilidade de produtos de alto desempenho:
- Mudança de Reativo para Proativo: Saindo da reatividade impulsionada por incidentes, estamos nos transformando para melhorar proativamente as melhores práticas de banco de dados usando o Scorecard de uso do Banco de Dados, que tornou as melhores práticas de banco de dados mensuráveis e acionáveis.
- Aplicar Melhores Práticas mais cedo no Ciclo de Desenvolvimento: Ao integrar o Avaliador de Consultas no início do loop de desenvolvimento, reduzimos o custo e o esforço de corrigir anti-padrões, como varreduras completas de tabelas ou planos instáveis, permitindo que os desenvolvedores resolvam problemas de forma eficiente durante a codificação.
- Utilize a análise para obter insights: Ao aproveitar os produtos Databricks, como Tabelas Delta, Pipelines DLT e Dashboards AI/BI, o scorecard de uso do banco de dados capacita equipes a otimizar milhares de instâncias de banco de dados e suportar desenvolvedores de maneira eficaz. O produto Databricks nos ajuda a acelerar nosso processo e a solução também é adaptável a outras plataformas orientadas a dados.
Este artigo foi adaptado de uma palestra que apresentamos na SREcon25 Americas 2025 (Os slides e a gravação estarão disponíveis aqui). Tivemos a honra de compartilhar nossa experiência com a comunidade, e estamos animados em trazer esses insights para um público mais amplo aqui.
Se você tem paixão por resolver desafios de confiabilidade de banco de dados, explore oportunidades de carreira na Databricks (https://www.databricks.com/company/careers/open-positions).
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.