Desacoplado por Design: Pesquisa Vetorial em Escala de Bilhões
por Zero Qu, Erik Lindgren, Sheng Zhan, Ankit Vij, Sergei Tsarev e Dima Kotlyarov
Introdução
A busca vetorial se tornou uma infraestrutura fundamental para aplicações de IA — desde a busca no produto e sistemas de recomendação até a resolução de entidades e a geração aumentada por recuperação. Mas à medida que os datasets crescem de milhões para bilhões de vetores, os sistemas construídos para atendê-los começam a falhar de maneiras dispendiosas: os custos de memória disparam, a ingestão paralisa o serviço e o dimensionamento exige a replicação de tudo.
Na Databricks, encontramos esses limites com nossa oferta original de pesquisa vetorial, então voltamos aos princípios básicos e a redesenhamos do zero. Hoje, o Databricks AI Search oferece duas opções de implantação: endpoints padrão, que mantêm vetores de precisão total inteiramente na memória para uma latência de dezenas de milissegundos, e endpoints otimizados para armazenamento, que separam o armazenamento da computação para servir bilhões de vetores por uma fração do custo — com latências de consulta na casa das centenas de milissegundos, uma troca deliberada para cargas de trabalho onde o custo e a escala são mais importantes do que os tempos de resposta de poucos milissegundos.
Storage Optimized AI Search foi moldado por três decisões de engenharia principais:
- Separe o armazenamento do compute. Os índices de vetores residem no armazenamento de objetos na nuvem e são carregados na memória apenas para servir às consultas. A ingestão é executada em clusters Spark efêmeros e serverless, completamente isolada do caminho da consulta.
- Crie algoritmos de indexação distribuída no Spark. Em vez de depender de bibliotecas de indexação de máquina única, desenvolvemos a nossa própria — clustering distribuído, compressão de vetores e disposição de dados alinhado à partição — como Jobs Spark nativos que escalam linearmente com o tamanho do cluster.
- Servir queries a partir de um mecanismo Rust com uma arquitetura de Runtime duplo. Um mecanismo de consulta desenvolvido especificamente usa pools de threads separados para E/S assíncrona e computação de vetores vinculada à CPU, para que nenhum deles sufoque o outro.
O resultado: índices de bilhões de vetores criados em menos de 8 horas, indexação 20x mais rápida e custos de serviço até 7x menores.
Este post é a história de engenharia de como o construímos.
O problema com os bancos de dados de vetores tradicionais
Os Limites do Acoplamento Forte
Muitos bancos de dados vetoriais de produção — incluindo nossa Pesquisa Vetorial Padrão — seguem uma arquitetura shared-nothing emprestada da pesquisa de palavras-chave distribuída. Cada nó possui um fragmento aleatório do dataset e mantém um grafo HNSW (Hierarchical Navigable Small World) independente em memória sobre vetores de precisão total. O HNSW oferece excelente qualidade de pesquisa, mas o próprio gráfico deve residir totalmente na memória, tornando-o um dos componentes mais caros para escalar. Este design oferece baixa latência e suporta atualizações transacionais. Funciona bem até centenas de milhões de vetores.
Em bilhões, ele se desfaz.
O problema central é o acoplamento. O índice, os dados brutos e o compute que os atende estão todos vinculados ao mesmo nó. Escalar significa replicar tudo: mais vetores exigem mais memória, o que exige mais nós, cada um carregando uma cópia completa do índice e dos dados de seu shard. Não há como escalar o armazenamento independentemente do compute.
O acoplamento se estende à ingestão. A criação do índice ocorre dentro do próprio mecanismo de busca — os mesmos recursos de computação que lidam com as consultas também lidam com a reorganização de dados, recriação de índices e compactação. Sob cargas de trabalho com muita escrita, a latência da query se degrada. Sob cargas de trabalho com muitas queries, a ingestão fica extremamente lenta. Pior: cada alteração de dados (um upsert, uma exclusão, uma compactação) aciona a recriação de subíndices, gastando ciclos de CPU em manutenção em vez de atender a consultas.
Índices Residentes em Memória São Caros
Essa permanência na memória é o que torna a arquitetura rápida — e o que a torna cara. Com 768 dimensões e floats de 32 bits, 100 milhões de vetores consomem aproximadamente 286 GiB de RAM, apenas para os vetores, antes de qualquer sobrecarga do índice. Um bilhão de vetores exigiria terabytes. Diferentemente do armazenamento em disco ou de objetos, onde o custo por gigabyte é insignificante, a memória é o recurso mais caro da stack. Cada vetor adicionado aumenta diretamente o custo da RAM.
O sharding aleatório agrava o problema. Como os vetores são distribuídos sem levar em conta a similaridade semântica, cada query deve ser dispersa para todos os shards e coletar os resultados, independentemente da relevância de cada shard. CPU, sobrecarga de rede e latência de cauda aumentam com a contagem de fragmentos. Adicionar vetores significa adicionar shards, e cada novo shard carrega seu próprio índice residente na memória.
Desacoplado por concepção
A resposta não é otimizar dentro desta arquitetura, mas sim quebrar o próprio acoplamento.
A Busca de Vetores Otimizada para Armazenamento começa de uma única premissa: todos os dados residem no armazenamento de objetos na nuvem, e os nós de consulta são stateless. Isso divide o sistema em dois limites: armazenamento da compute, para que os nós de query não possuam dados; ingestão do serviço, para que as compilações de índice nunca concorram com as live queries, e dá origem a uma arquitetura de três camadas:
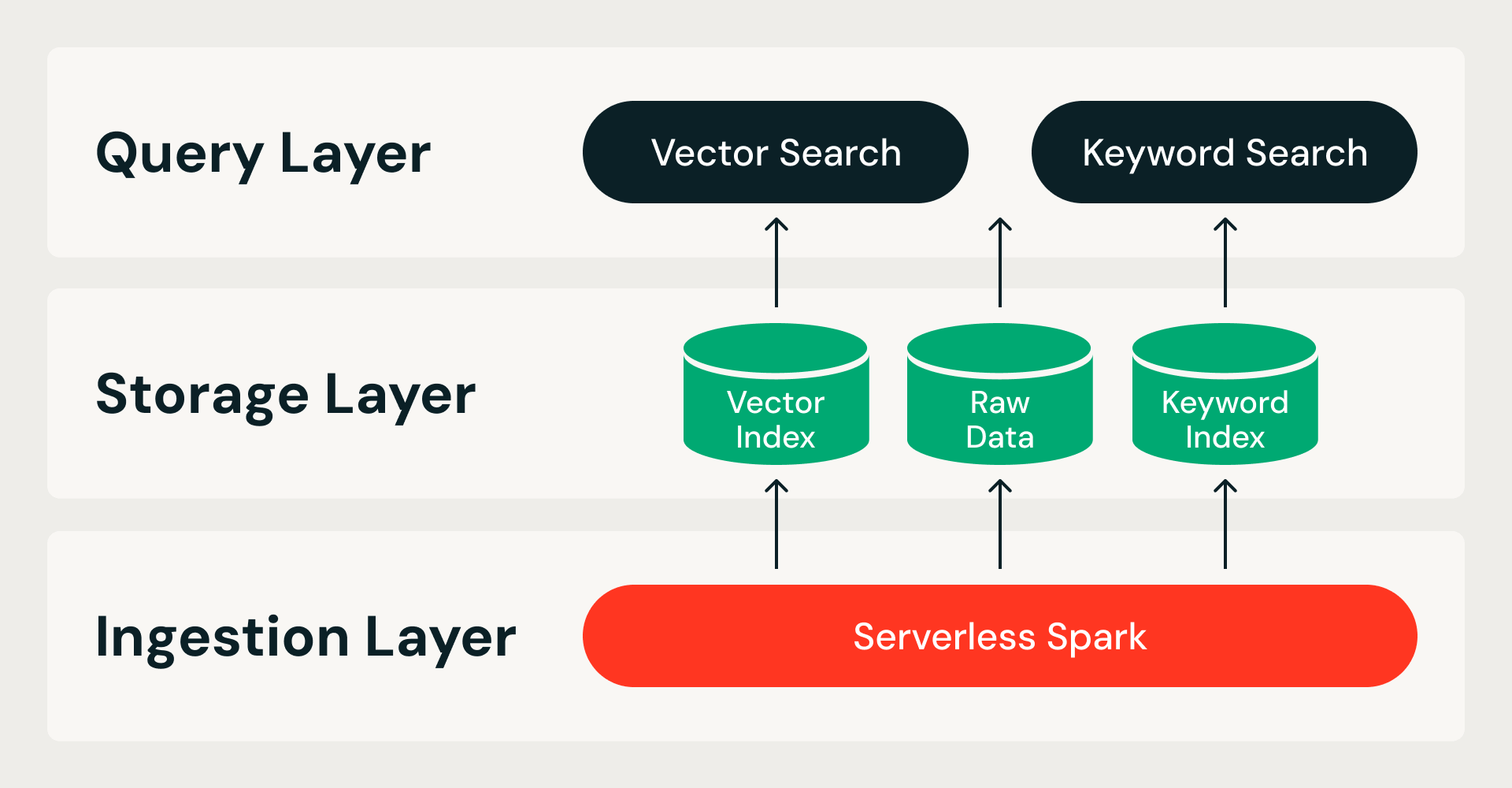
- Camada de ingestão. Um pipeline distribuído no Serverless Spark lida com toda a criação de índices, desde os dados brutos até o índice finalizado. Cada execução é idempotente e pode ser repetida.
- Camada de armazenamento. Um formato de armazenamento personalizado e nativo cloud serve como o sistema de registro. Ele combina um formato de arquivo colunar para dados brutos e índices de vetores com um formato de índice invertido para pesquisa por palavra-chave — tudo sob transações ACID com fragmentos de dados imutáveis.
- Query layer. Dois serviços stateless lidam com as leituras. O serviço de busca vetorial mantém um índice compactado na memória e busca dados de precisão total do armazenamento de objetos sob demanda. A busca por palavra-chave serve índices invertidos para filtragem de metadados e busca por palavra-chave. Ambos os serviços escalam de forma independente, então os recursos podem ser ajustados para corresponder à carga de trabalho.
Uma estrutura de índice para armazenamento de objetos
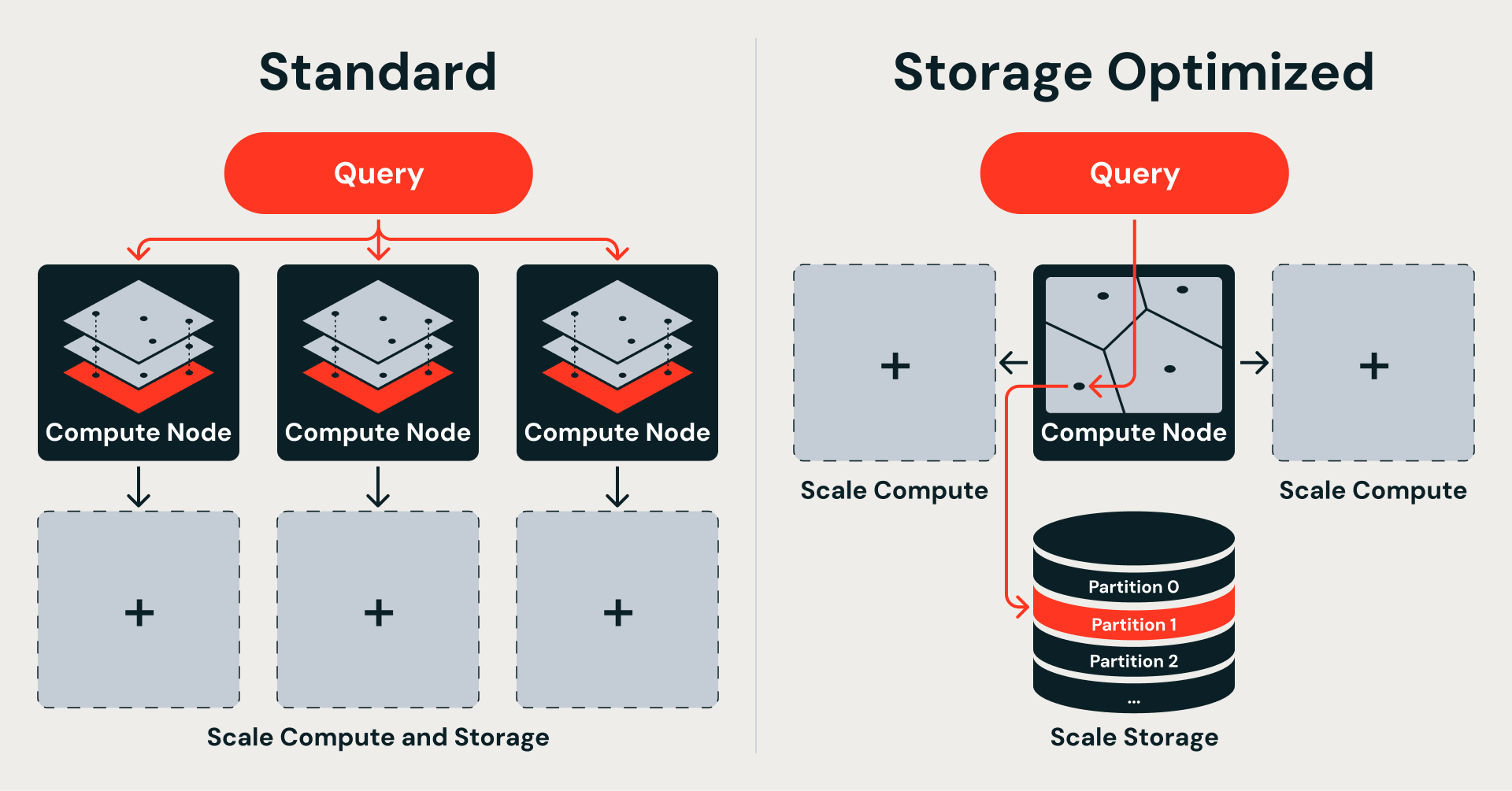
Se os dados residem no armazenamento de objetos, o índice deve ser particionável — o query engine precisa buscar apenas as fatias relevantes, e não carregar a estrutura inteira na memória.
Gráficos HNSW não têm essa propriedade. Cada salto de busca pode ir para qualquer lugar no gráfico, então a estrutura completa precisa residir na memória para atender a uma única query. Não há uma maneira natural de dividir um gráfico HNSW em fragmentos que mapeiem para arquivos de armazenamento de objetos.
O IVF (Índice de Arquivo Invertido) adota uma abordagem diferente: ele agrupa vetores por proximidade em torno de centroides aprendidos e pesquisa apenas os clusters mais próximos no momento da query. Cada cluster é mapeado diretamente para um fragmento de dados no armazenamento de objetos — que pode ser buscado de forma independente, sem carregar o resto do índice.
Essa escolha de algoritmo decorre diretamente de onde os dados residem. A Busca Vetorial Padrão mantém o índice completo em memória para maior velocidade, o que vincula o armazenamento e o compute. A otimização para armazenamento move os dados para o armazenamento de objetos para escala, o que os libera, mas exige um índice que se decompõe em partições autônomas e recuperáveis. O IVF fornece exatamente isso:
Indexação vetorial distribuída no Spark
O IVF nos dá a estrutura de índice correta para armazenamento separado. O desafio de engenharia é construí-lo em grande escala. A maioria das bibliotecas de indexação de vetores — FAISS, ScaNN, Annoy — pressupõe que todos os seus dados cabem em uma única máquina. Isso funciona com dezenas de milhões de vetores. Com um bilhão de vetores e embeddings de 768 dimensões, você tem terabytes de dados brutos de ponto flutuante antes mesmo de começar a construir um índice. Nenhuma máquina única lida com isso de forma eficiente e, mesmo que lidasse, seu tempo de ingestão se tornaria um gargalo serial que cresce a cada nova linha.
Precisávamos de uma indexação que escalasse horizontalmente. Então, implementamos todos os algoritmos de indexação do zero — K-means distribuído, Quantização de Produto e disposição de dados alinhada à partição — como Jobs PySpark nativos executados em clusters Spark serverless efêmeros. Nenhuma biblioteca de indexação de máquina única no caminho crítico. Adicionar mais executores reduz linearmente o tempo dos passos mais caros.
O Pipeline de Ingestão
Cada execução de ingestão é executada como um gráfico acíclico direcionado de estágios, encapsulada em uma transação ACID.
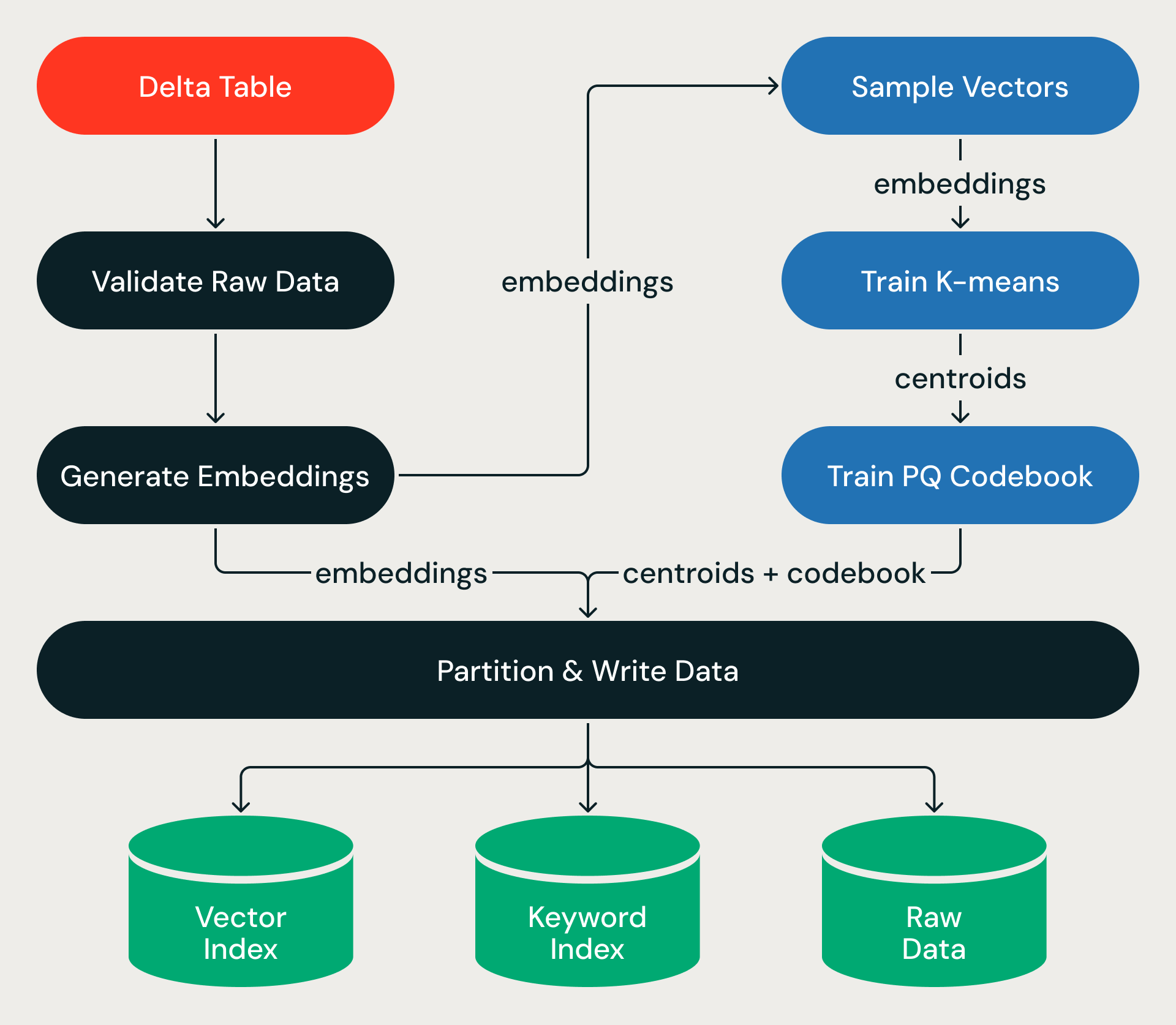
O pipeline começa a partir de uma Delta Table de origem. Para índices baseados em texto de origem (em vez de vetores pré-computados), após validar os dados de origem, o pipeline chama o Databricks Model Serving para gerar embeddings de vetor para linhas novas ou atualizadas, transformando bilhões de registros de texto em vetores de alta dimensão em grande escala.
A partir daí, o pipeline ensina com uma pequena amostra — aprendendo a estrutura do espaço vetorial — e, em seguida, aplica essa estrutura ao dataset completo, atribuindo cada vetor a uma partição, compactando-o e gravando os resultados no armazenamento de objetos. O treinamento é barato; a passagem pelo dataset completo, que embaralha terabytes de dados entre executores, é onde o tempo de relógio é gasto.
K-means: particionamento em grande escala
A clusterização K-means particiona o espaço vetorial em regiões — as partições IVF que permitem que as queries pesquisem uma fração dos dados em vez de todos eles. Para um dataset de um bilhão de linhas, criamos aproximadamente 32 mil partições. A questão é: como executar o K-means nesta escala quando as implementações padrão pressupõem que todos os dados cabem em uma única máquina?
Você o constrói do zero no Spark.
Nossa implementação usa um modelo híbrido: o Spark lida com a movimentação de dados distribuídos, enquanto o JAX — uma biblioteca de computação numérica com álgebra linear acelerada por hardware — lida com a matemática dentro de cada executor. Cada iteração do K-means é um pipeline do Spark de três etapas:
- Atribuir — cada executor calcula as distâncias de seus lotes locais de vetores para todos os centroides atuais, encontrando os clusters mais próximos de cada vetor.
- Embaralhar — o Spark reparticiona os dados por ID de centroide, colocalizando todos os vetores atribuídos ao mesmo cluster.
- Agregar — cada executor computa novas posições de centroides a partir de seus vetores colocalizados.
A computação da distância é o loop crítico. O JAX o compila em uma �única operação de matriz em lote por executor — computando a matriz de distância completa lote por centroide de uma só vez, em vez de iterar sobre vetores individuais.
O treinamento é executado em uma amostra, não no dataset completo. Para um bilhão de linhas, são aproximadamente 8 milhões de vetores (~0,8% dos dados). Isso não é arbitrário: o custo do K-means por iteração é O(n × k × d), onde n é o tamanho da amostra, k o número de clusters e d a dimensão. Definir n e k como proporcionais a √N torna o custo total de treinamento O(N × d), linear em relação ao tamanho do dataset, independentemente da escala.
Essa escolha também é estatisticamente bem fundamentada: a teoria de coreset mostra que amostras O(k) são suficientes para clusterização k-means de alta qualidade em dados bem distribuídos, e como k escala com √N, o tamanho da nossa amostra é comprovadamente adequado. O treinamento é concluído em poucas iterações e salva os centroides como checkpoints no armazenamento de objetos para as etapas posteriores do pipeline.
Quantização de Produto: Compressão de Memória de 64x
O K-means nos dá partições grosseiras. A Quantização de Produto (PQ) compacta os vetores para que possamos pesquisar dentro deles em grande escala. A ideia: dividir cada vetor de 768 dimensões em 48 subvetores de 16 dimensões cada e substituir cada subvetor por um único byte que aponte para a entrada mais próxima em um codebook aprendido. Um vetor de 3.072 bytes se torna 48 bytes — uma taxa de compactação de 64x. Para um bilhão de vetores de 768 dimensões, isso reduz quase 3 TiB de dados brutos para cerca de 45 GiB.
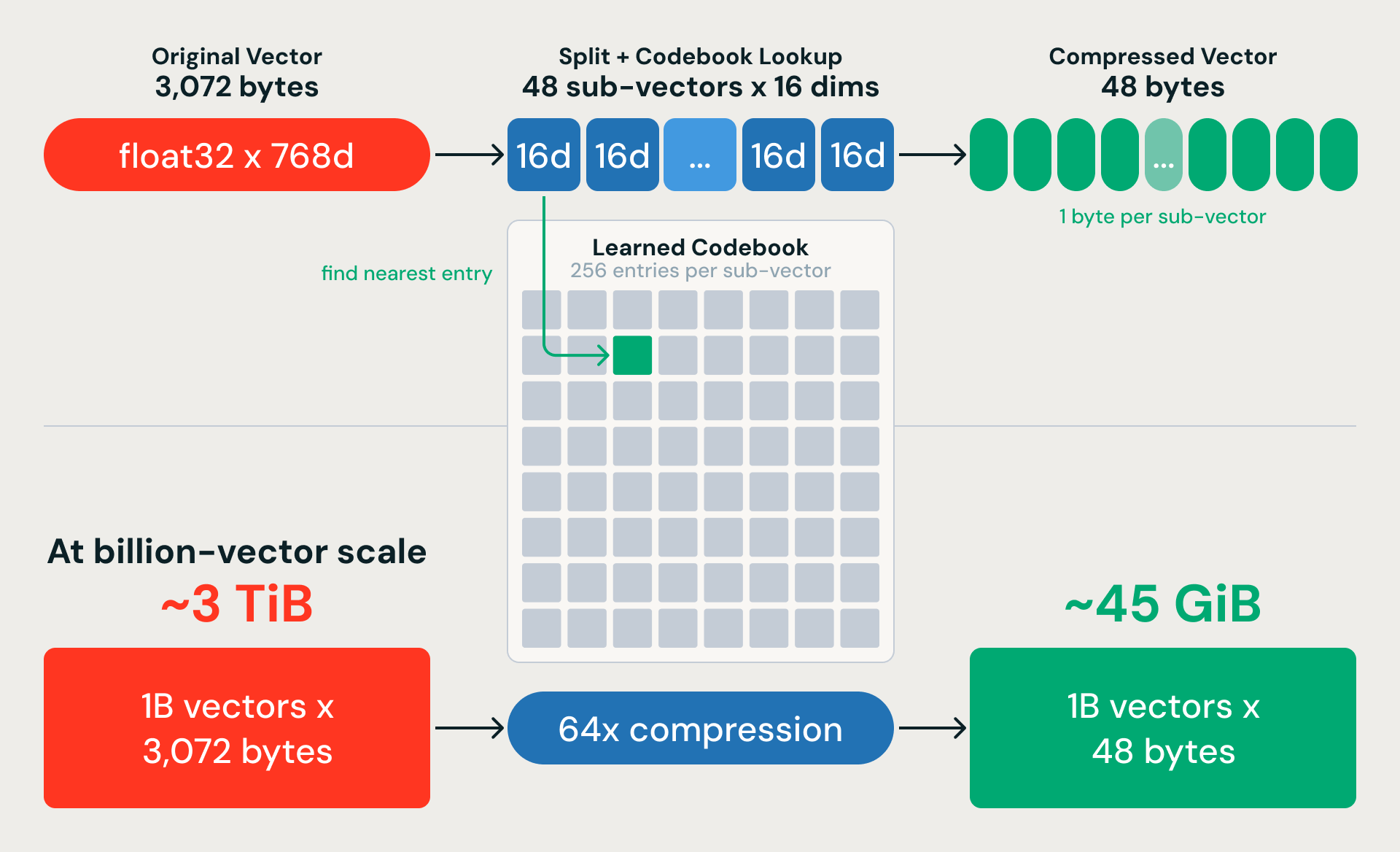
A compactação tem perdas, mas uma escolha fundamental de design recupera a maior parte da precisão: treinamos o PQ em vetores residuais (a diferença entre cada embedding e seu centroide K-means mais próximo) em vez dos embeddings brutos. O K-means captura a estrutura em grande escala; o PQ só precisa codificar a variação detalhada dentro de cada partição.
Do Treinamento ao Armazenamento
Com os centroides e os codebooks PQ treinados na amostra, o pipeline agora processa cada linha, atribuindo a cada vetor um ID de partição (seu centroide mais próximo) e um código PQ compactado. Para um conjunto de dados de um bilhão de linhas, este é o estágio mais intensivo em dados do pipeline: um job do Spark de conjunto de dados completo que calcula distâncias e codificações em todos os executores.
Depois vem o shuffle. O pipeline reparticiona todo o conjunto de dados por ID de partição, colocalizando fisicamente vetores da mesma partição IVF nos mesmos fragmentos de dados no armazenamento de objetos. Isso é caro — terabytes de dados se movem entre executores — mas é o que torna as queries rápidas. Sem a colocalização, sondar uma única partição IVF espalharia as leituras por milhares de arquivos. Com ele, a mesma sonda atinge um punhado de fragmentos contíguos.
A escrita produz três saídas, cada uma otimizada para um caminho de consulta diferente:
- Índice de Vetor — códigos PQ compactados e metadados de partição, escritos em um formato que o mecanismo de consulta carrega na memória para pesquisa de rede neurais artificiais (ANN) rápida.
- Índice de palavras-chave — arquivos de índice invertido para filtragem de metadados e pesquisa híbrida de palavras-chave.
- Dados Brutos — embeddings de precisão total armazenados em um formato colunar otimizado tanto para varreduras sequenciais quanto para acesso aleatório, buscados sob demanda durante a reclassificação.
Todos os três são escritos como fragmentos imutáveis: uma vez escritos, nunca modificados. Quando a escrita é concluída, um manifesto de versão publica atomicamente o novo índice. Este é o contrato entre a ingestão e o serviço: um conjunto de fragmentos de dados imutáveis e alinhados à partição no armazenamento de objetos, prontos para o mecanismo de query ler diretamente.
Ingestão em escala
O Storage Optimized suporta índices de mais de um bilhão de vetores com 768 dimensões — um grande avanço em relação ao Standard AI Search, que tem um limite de 320 milhões de vetores.
Como a ingestão é executada em clusters Spark efêmeros, totalmente desacoplada do serviço, o dimensionamento é uma questão de adicionar executores. Na prática, isso se traduz em melhorias de ordem de magnitude nas construções de índice de produção:

Com o índice gravado e publicado atomicamente no armazenamento de objetos, a próxima pergunta é: como servir queries com base nele com rapidez suficiente para produção?
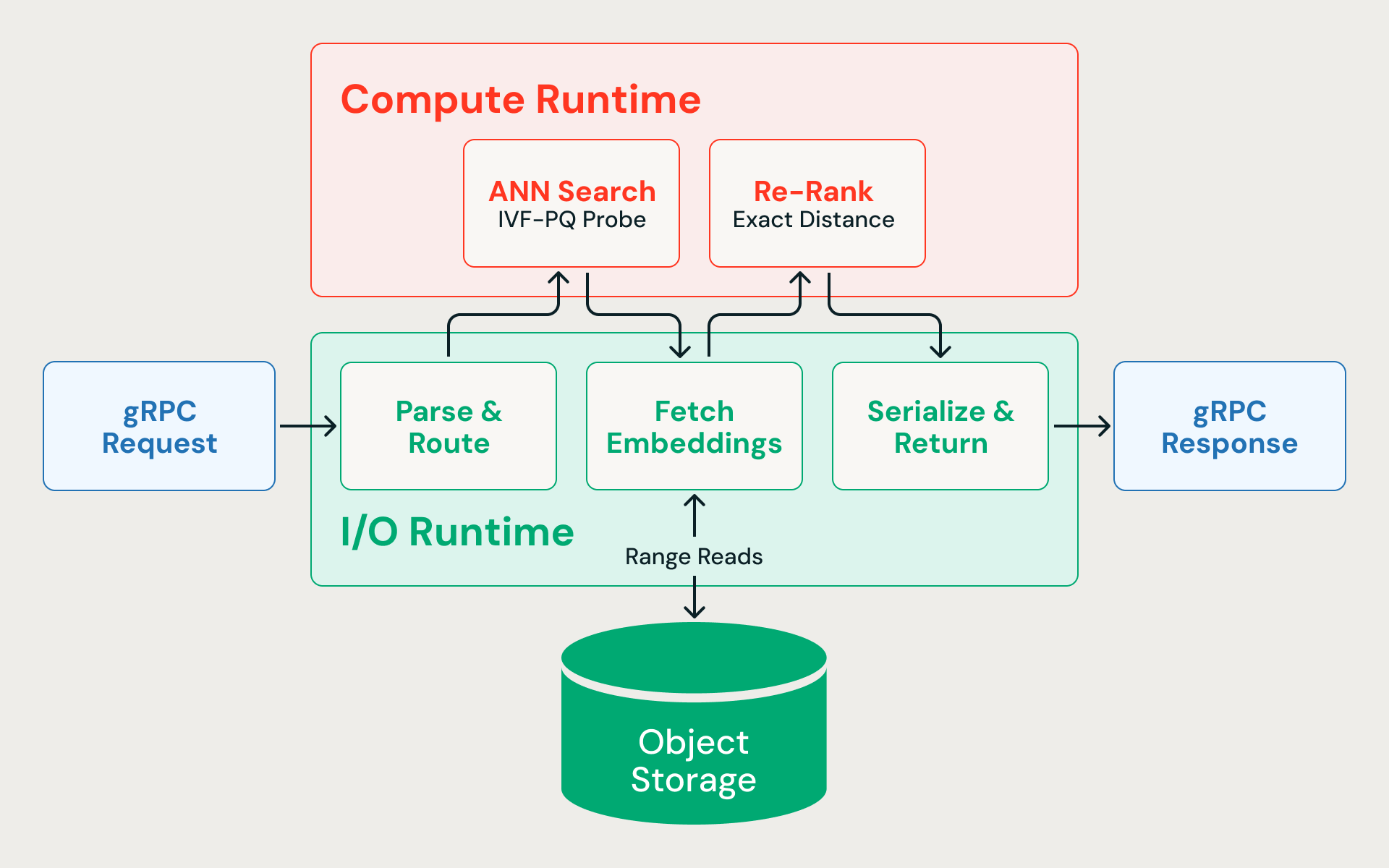
Um Mecanismo de query para Armazenamento de Objetos
Separar o armazenamento da computação resolve o problema de custo. Mas isso introduz um novo problema: cada query agora envolve idas e vindas na rede para o armazenamento de objetos. O índice compactado (pequeno o suficiente para caber na memória) é carregado na startup, mas os embeddings de precisão total permanecem no armazenamento de blobs e são buscados sob demanda ou servidos de um cache de disco local. A camada de serviço precisa ser rápida o suficiente para que a movimentação de dados para fora do nó não comprometa a latência da consulta.
Anatomia de uma query
Veja o que acontece quando uma pesquisa de vizinho mais próximo chega ao mecanismo:
- Analisar e rotear (E/S). A solicitação gRPC chega ao runtime de E/S assíncrono, é desserializada e roteada para o índice correto.
- Pesquisa rede neurais artificiais (ANN) (CPU). O vetor de query é comparado com os centroides de cluster do IVF para identificar as partições mais relevantes. Apenas essas partições são sondadas, escaneando vetores compactados para compute distâncias aproximadas. A pesquisa busca deliberadamente mais candidatos que o necessário — por exemplo, buscando 400 quando o solicitante pede 10 — porque as distâncias quantizadas são aproximadas, e uma rede inicial mais ampla melhora o recall final após a reclassificação.
- Buscar vetores de precisão total (E/S). Leituras de intervalo de bytes concorrentes buscam os embeddings brutos de cada candidato no armazenamento em cloud. Como o pipeline de ingestão colocaliza linhas da mesma partição IVF no mesmo fragmento de dados, essas leituras são podadas por partição — acessando um pequeno número de arquivos, em vez de acessar aleatoriamente todo o dataset. Este passo domina a latência de ponta a ponta.
- Reclassificação (CPU). Os embeddings de precisão total são pontuados usando o cálculo de distância exata, recuperando a precisão perdida na compressão.
- Serializar e retornar (E/S). Os resultados top-N finais são serializados com seus metadados associados e enviados de volta ao chamador.
Toda query alterna entre E/S assíncrona e computação vinculada à CPU. Se os cálculos de distância bloquearem o Runtime assíncrono, as leituras de armazenamento pendentes se acumulam e a latência dispara.
Dois Runtimes
A solução é nunca deixá-los competir pelos mesmos threads. O mecanismo de query — escrito em Rust para latência previsível sem pausas do GC — divide a execução em dois pools de threads dedicados: um para E/S assíncrona e outro para matemática de vetores vinculada à CPU. Nenhuma carga de trabalho pode sufocar a outra.
O runtime de I/O é executado no executor assíncrono Tokio e lida com a análise de solicitações gRPC, leituras de intervalo do armazenamento de blobs, comunicação entre serviços e serialização de respostas. Como as leituras de armazenamento são o gargalo de latência, este Runtime precisa manter centenas de solicitações concorrentes em andamento sem bloqueio.
O compute Runtime executa cálculos de distância vetorial, sondagem de partição e reclassificação em seu próprio pool de threads. Um subconjunto de núcleos de CPU é explicitamente reservado para o Runtime de E/S — a compute nunca pode consumir a máquina inteira.
Agrupamento de leitura
Além do isolamento de threads, o próprio caminho de E/S exigiu ajuste. A criação de perfis iniciais revelou que o mecanismo estava emitindo muitas pequenas leituras de intervalo de vetor único para o armazenamento de objetos. Cada chamada acarreta uma sobrecarga por solicitação e variabilidade de latência — com caudas longas atingindo centenas de milissegundos — de modo que muitas solicitações minúsculas significavam alta variância de latência por query.
A correção foi o agrupamento de leitura: em vez de emitir uma leitura de intervalo por vetor, a camada de armazenamento classifica as solicitações de intervalo de bytes pendentes por deslocamento de arquivo e merge as que se enquadram em uma janela de tamanho de bloco configurável em uma única leitura. Menos solicitações, porém maiores, significam menos sobrecarga por chamada, mas cada leitura mesclada também busca bytes de que a consulta não precisa: amplificação de leitura. O trade-off exigiu um ajuste empírico.
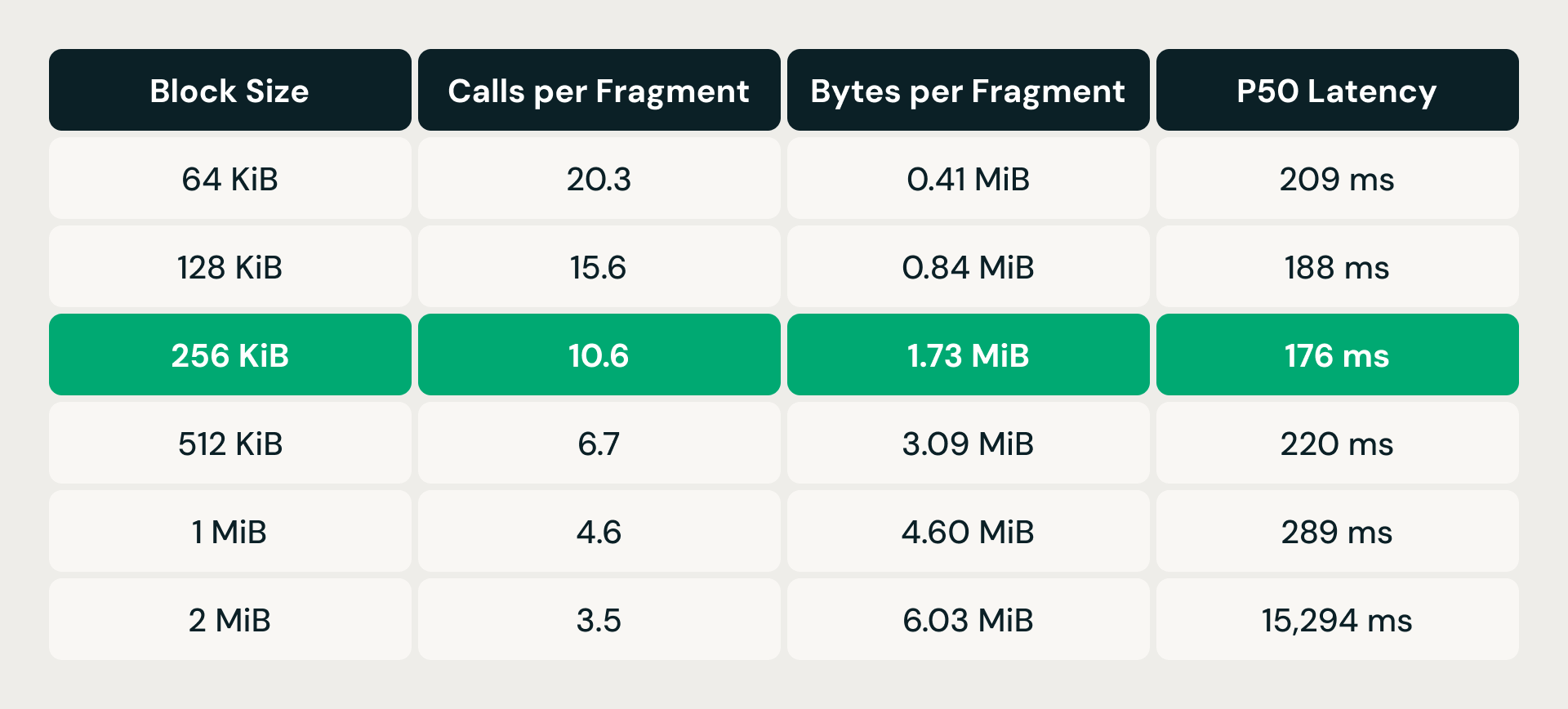
Com 64 KiB, cada fragmento de dados exigia mais de 20 chamadas de armazenamento, mas buscava menos de meio megabyte. A sobrecarga por solicitação dominava. Dobrar o tamanho do bloco reduziu constantemente a contagem de chamadas, e a latência melhorou até 256 KiB. Mas, passado esse ponto, a amplificação de leitura prevaleceu: com 512 KiB, a latência subiu novamente acima da linha de base de 64 KiB, apesar do número muito menor de chamadas. Com 2 MiB, ela explodiu para mais de 15 segundos. O ponto ideal de 256 KiB reduziu as chamadas aproximadamente pela metade, mantendo a amplificação de leitura abaixo de 2 MiB por fragmento e entregando a menor latência p50 de qualquer configuração testada.
Juntando tudo
Tudo nesta arquitetura troca a latência de query por escala e custo. Com 768 dimensões e os 10 melhores resultados, o recall — a fração de vizinhos mais próximos verdadeiros retornados — permanece acima de 94% com 10 milhões de vetores, acima de 91% com 100 milhões e se mantém em 90% mesmo em um bilhão: o passo de reclassificação, que busca vetores de precisão total do armazenamento de objetos e recalcula as distâncias exatas, recupera a precisão que os códigos compactados sozinhos perderiam em escala. Esse round-trip de reclassificação também é o que domina o tempo de query — as queries retornam em cerca de 300 milissegundos com 10 milhões de vetores e aproximadamente 500 milissegundos com um bilhão, em comparação com 20 a 50 milissegundos nos endpoints Padrão, que mantêm tudo na memória.
O que você obtém por esses milissegundos extras: a construção de índices na escala de um bilhão de vetores é concluída em menos de 8 horas, 20x mais rápido do que o Padrão em grandes datasets. A quantização de produto compacta o espaço ocupado na memória em mais de uma ordem de magnitude, a ingestão é executada em clusters Spark efêmeros que liberam recursos após cada build, e a dissociação do armazenamento do serviço significa que nenhum dos lados é superprovisionado. O resultado é um custo até 7x menor para os clientes na mesma escala.
Para muitas cargas de trabalho — pesquisa semântica, pipelines de recomendação, geração aumentada por recuperação — essa troca favorece claramente a escala e o custo. Os estágios pós-recuperação (ranqueamento, filtragem, geração de LLM) geralmente dominam o tempo de ponta a ponta, tornando a diferença entre 40 e 400 milissegundos invisível para o usuário final. Para o serviço sensível à latência, onde cada milissegundo importa, o Standard AI Search continua sendo a melhor ferramenta. As duas opções são complementares — ferramentas diferentes para cargas de trabalho diferentes.
O Que Aprendemos
Construir um sistema de busca vetorial do zero — em vez de otimizar o que já tínhamos — nos forçou a fazer um conjunto de apostas que só valem a pena em conjunto.
A separação entre armazenamento e computação só funciona se o mecanismo de consulta for rápido o suficiente. Mover os dados para fora do nó economiza dinheiro, mas adiciona E/S a cada consulta — sejam round-trips de rede para o armazenamento de objetos ou leituras de um cache de disco local. O mecanismo Rust de runtime duplo existe especificamente para absorver essa latência: a E/S assíncrona mantém centenas de leituras em andamento enquanto as threads da CPU lidam com o cálculo da distância sem bloqueio. Sem esse mecanismo, a arquitetura entregaria armazenamento barato e queries lentas — o que não é uma troca atraente.
A indexação distribuída só funciona se o formato do índice a suportar. Construir K-means e PQ no Spark nos dá escala horizontal para a ingestão, mas a saída tem que ser algo que o mecanismo de query possa servir diretamente do armazenamento de objetos, sem um passo de reconstrução. O formato de armazenamento personalizado — fragmentos de dados imutáveis, manifestos de transação separados, semântica ACID no armazenamento em nuvem — fecha esse ciclo. A ingestão grava diretamente no formato que o mecanismo de consulta lê.
A compactação é a alavanca econômica. A Quantização de Produto não apenas reduz o custo de memória. Ela muda a viabilidade da arquitetura. Sem este nível de compactação, armazenar códigos quantizados na memória para um bilhão de vetores ainda exigiria terabytes de RAM, e a vantagem de custo sobre a Busca Vetorial Padrão desapareceria. O PQ torna possível manter a fase de busca de rede neurais artificiais (ANN) em memória, enquanto envia todo o resto para o armazenamento de objetos.
Estas não são otimizações independentes. Remova qualquer um deles, e o sistema custará caro demais, será compilado muito lentamente ou atenderá às solicitações de forma lenta demais para ser prático.
Conclusão
Os problemas difíceis à frente decorrem diretamente desses trade-offs. Levar o desempenho das queries adiante — respostas mais rápidas, maior throughput, melhor concorrência — por meio de cache mais inteligente, armazenamento em camadas e representações em memória mais densas. Tornar as atualizações quase em tempo real em escala de bilhões. Ir além da distância vetorial bruta como o sinal de classificação final, em direção a uma classificação aprendida e de múltiplos estágios que combina similaridade de vetor, relevância de palavra-chave e contexto de domínio em resultados que não são apenas os mais próximos, mas os mais úteis.
Acreditamos que a próxima geração de produtos de IA será construída em uma infraestrutura que ainda não foi inventada — e que os engenheiros que construírem essa infraestrutura moldarão o que a IA pode fazer. Se você quer ser um deles, venha construir conosco!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.