Delta UniForm: um formato universal para interoperabilidade de lakehouse
por Bilal Obeidat, Sirui Sun, Adam Wasserman, Susan Pierce, Fred Liu, Ryan Johnson e Himanshu Raja
Atualização: O BigQuery agora oferece suporte nativo ao Delta Lake por meio do BigLake. Confira a documentação para mais informações.
Um dos principais desafios que as organizações enfrentam ao adotar o data lakehouse aberto é a seleção do formato ideal para seus dados. Entre as opções disponíveis, Linux Foundation Delta Lake, Apache Iceberg e Apache Hudi são excelentes formatos de armazenamento que permitem a democratização e interoperabilidade dos dados. Qualquer um desses formatos é melhor do que colocar seus dados em um formato proprietário. No entanto, escolher um único formato de armazenamento para padronizar pode ser uma tarefa assustadora, o que pode resultar em fadiga de decisão e medo de consequências irreversíveis.
Delta UniForm (abreviação de Delta Lake Universal Format) oferece uma unificação simples, fácil de implementar e contínua de formatos de tabela sem criar cópias de dados ou silos adicionais. Neste blog, abordaremos o seguinte:
- Uma introdução ao Delta UniForm e seus benefícios
- Leitura do Delta UniForm como tabelas Iceberg usando
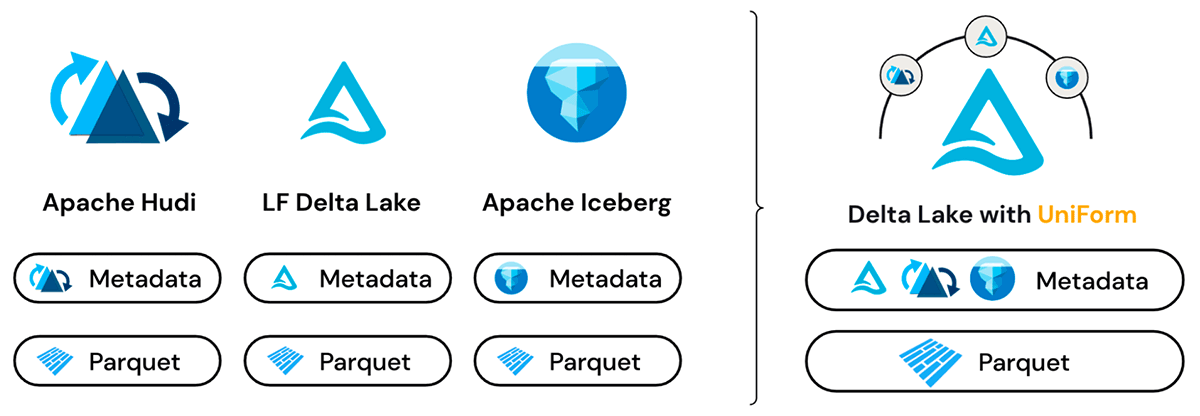
Múltiplos formatos, cópia única de dados
O Delta UniForm aproveita o fato de que Delta Lake, Iceberg e Hudi são construídos sobre arquivos de dados Apache Parquet. A principal diferença entre os formatos está na camada de metadados, e mesmo assim, as diferenças são sutis. Os metadados para os três formatos servem ao mesmo propósito e contêm conjuntos de informações sobrepostos.
Antes do lançamento do Delta UniForm, as maneiras de alternar entre formatos de tabela abertos eram baseadas em cópia ou conversão e forneciam apenas uma visão pontual dos dados. Em contraste, o Delta UniForm resolve as necessidades de interoperabilidade de forma mais elegante, fornecendo uma visão ao vivo dos dados para todos os leitores, independentemente do formato.
Por baixo dos panos, o Delta UniForm funciona gerando automaticamente os metadados para Iceberg e Hudi ao lado do Delta Lake - tudo contra uma única cópia dos dados Parquet. Como resultado, as equipes podem usar a ferramenta mais adequada para cada carga de trabalho de dados e todas operam em uma única fonte de dados, com perfeita interoperabilidade entre os três ecossistemas diferentes.
Configuração rápida, sobrecarga mínima
O Delta UniForm é extremamente fácil de configurar e, uma vez ativado, funciona de forma contínua e automática.
Para começar, vamos criar uma tabela Delta UniForm para gerar metadados Iceberg:
Com as tabelas Delta UniForm, os metadados para os formatos adicionais são criados automaticamente na criação da tabela e atualizados sempre que a tabela é modificada. Isso significa que não há necessidade de comandos de atualização manual ou de executar computação desnecessária para traduzir formatos de tabela. Por exemplo, vamos escrever uma linha nesta tabela:
Este comando aciona um commit do Delta Lake, que então gera automática e assincronamente os metadados Iceberg para esta tabela. Ao fazer isso, o Delta UniForm garante que os pipelines de dados não sejam interrompidos, permitindo acesso contínuo às informações mais atualizadas para todos os leitores.
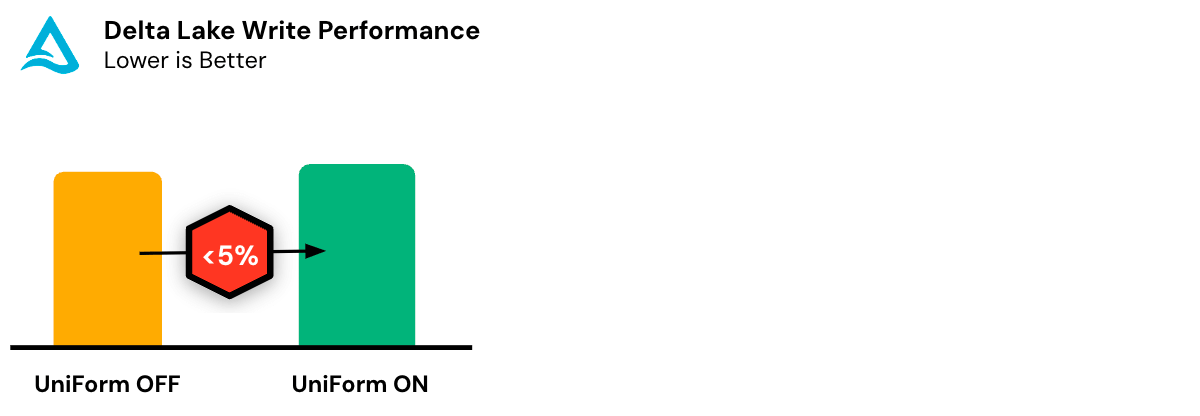
O Delta UniForm tem sobrecarga de desempenho e recursos insignificante, garantindo a utilização ideal dos recursos computacionais. Mesmo para tabelas em escala de petabytes, os metadados são tipicamente uma pequena fração do tamanho do arquivo de dados. Além disso, o Delta UniForm é capaz de gerar metadados incrementalmente, com escopo apenas para as alterações desde o último commit.
Leitura do Delta UniForm como Iceberg
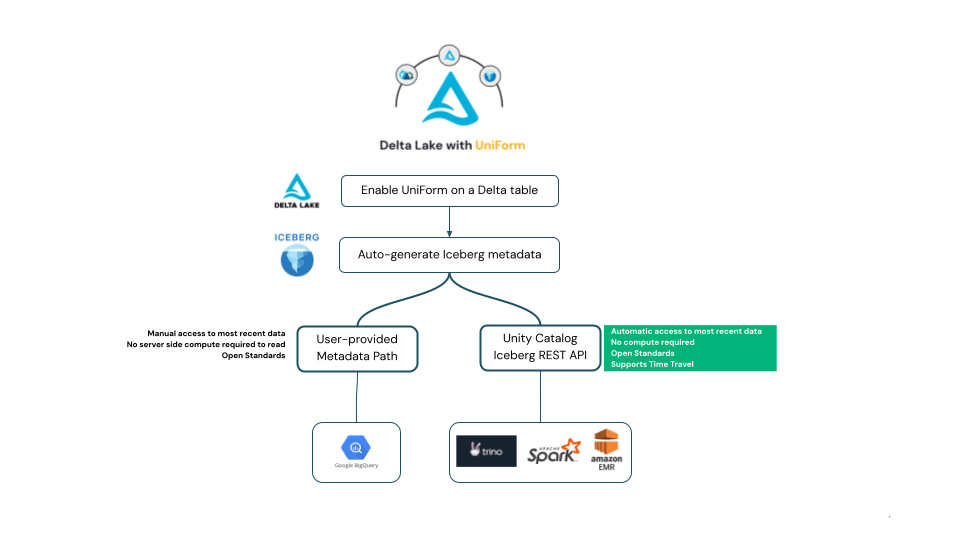
O Delta UniForm gera metadados Iceberg de acordo com a especificação Apache Iceberg, o que significa que quando os dados são gravados em uma tabela Delta UniForm, a tabela pode ser lida como Iceberg por qualquer cliente no ecossistema Iceberg que adere à especificação de código aberto Iceberg.
De acordo com a especificação Iceberg, os clientes leitores devem descobrir quais metadados Iceberg representam a versão mais recente e atualizada da tabela Iceberg. Em todo o ecossistema Iceberg, vimos clientes adotarem duas abordagens diferentes para isso, ambas suportadas pelo UniForm. Explicaremos as diferenças aqui e, em seguida, forneceremos exemplos na próxima seção.
Alguns leitores Iceberg exigem que os usuários forneçam o caminho para um arquivo de metadados que representa o último snapshot da tabela Iceberg. Essa abordagem pode ser complicada para os clientes, pois exige que os usuários forneçam caminhos de arquivo de metadados atualizados toda vez que a tabela muda.
Como alternativa, a comunidade Iceberg recomenda o uso da API REST de catálogo. O cliente se comunica com o catálogo para obter o estado mais recente da tabela, permitindo que os usuários leiam o estado mais recente de uma tabela Iceberg sem atualizações manuais ou preocupações com caminhos de metadados.
O Unity Catalog agora implementa a API REST aberta de Catálogo Iceberg de acordo com a especificação Apache Iceberg. Isso está alinhado com o compromisso do Unity Catalog de dar suporte a APIs abertas e se baseia no impulso do suporte à API HMS do Unity Catalog. A API REST Iceberg do Unity Catalog oferece acesso aberto a tabelas UniForm no formato Iceberg sem nenhum custo para computação Databricks, permitindo interoperabilidade e suporte de atualização automática para acessar os dados mais recentes. Como subproduto, isso deve permitir que outros catálogos federem para o Unity Catalog e suportem tabelas Delta UniForm.
As bibliotecas de cliente Apache Iceberg vêm pré-empacotadas com a capacidade de interagir com a API REST de Catálogo Iceberg - o que significa que qualquer cliente que implemente totalmente o padrão Apache Iceberg e tenha suporte para configurar endpoints de catálogo poderá acessar facilmente o Catálogo REST API Iceberg do Unity Catalog e recuperar os metadados mais recentes de suas tabelas. Isso elimina a tarefa de gerenciar metadados de tabela.
Na próxima seção, veremos exemplos do suporte do Delta UniForm para as abordagens de caminho de metadados e API REST de Catálogo Iceberg.
Exemplo: ler Delta Lake como Iceberg no BigQuery fornecendo a localização dos metadados
Ao ler Iceberg em um catálogo existente, o BigQuery exige que você forneça um ponteiro para o arquivo JSON que representa o último snapshot Iceberg (documentação do BigQuery), como o seguinte:
No BigQuery:
O Delta UniForm com Unity Catalog facilita a localização do caminho do arquivo de metadados Iceberg necessário. O Unity Catalog expõe várias propriedades de tabela Delta Lake, incluindo este caminho. Você pode recuperar a localização dos metadados para sua tabela Delta UniForm via UI ou API.
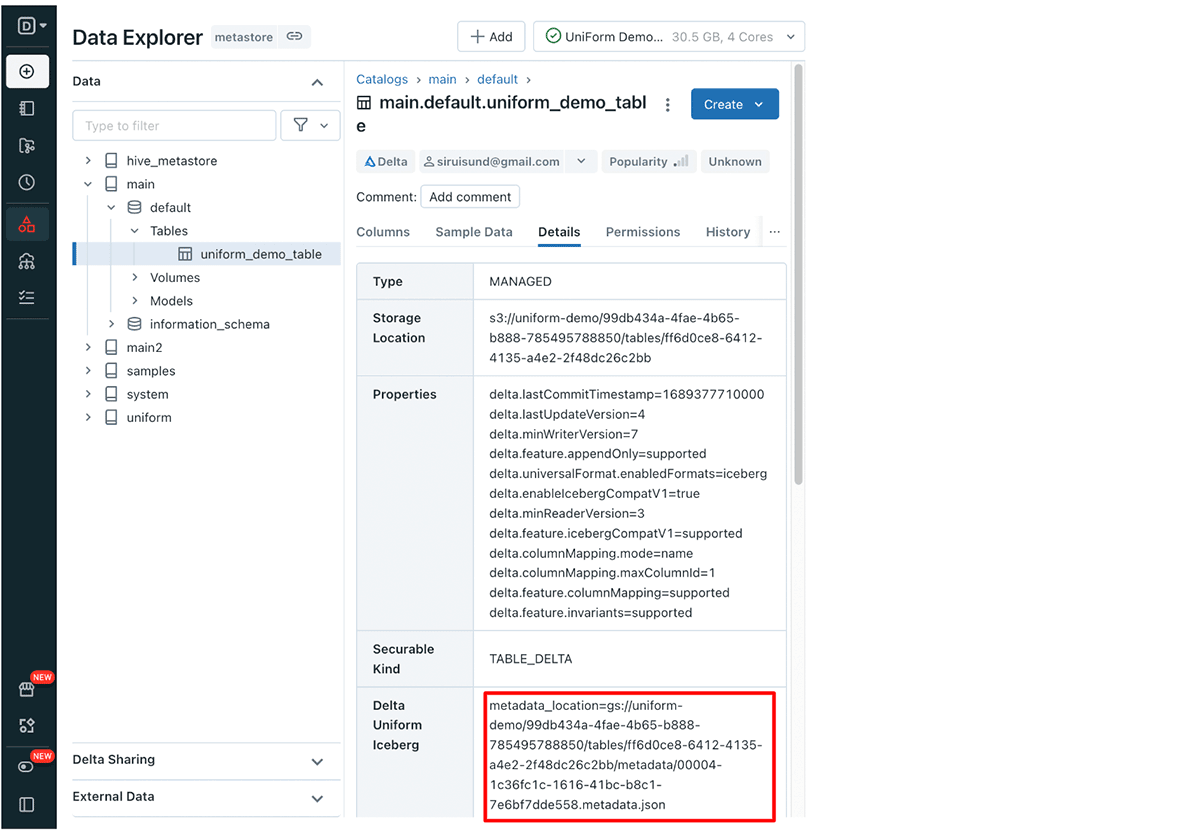
Recuperando o caminho de metadados Iceberg do Delta UniForm via UI:
Navegue até sua tabela Delta UniForm no Databricks Data Explorer, clique na guia Detalhes. Aqui, você encontrará a linha Delta UniForm Iceberg contendo o caminho dos metadados.
No Databricks:
Recuperando a localização dos metadados Iceberg do Delta UniForm via API:
De uma ferramenta de sua escolha, envie a seguinte solicitação GET para recuperar a localização dos metadados Iceberg de sua tabela Delta UniForm.
O campo delta_uniform_iceberg.metadata_location na resposta contém a localização dos metadados para o último snapshot Iceberg.
Basta colar o local da interface do usuário ou dos métodos de API descritos acima no comando BigQuery mencionado, e o BigQuery lerá o snapshot como Iceberg.
Se sua tabela for atualizada, você precisará fornecer ao BigQuery o local de metadados atualizado para ler os dados mais recentes. Para casos de uso em produção, você deve adicionar uma etapa em seu pipeline de ingestão que atualize o BigQuery com o(s) caminho(s) de metadados Iceberg mais recente(s) toda vez que você gravar na tabela Delta UniForm. Observe que a necessidade de atualizações de caminho de metadados é uma limitação geral dessa abordagem e não é específica do UniForm.
Exemplo: Ler Delta Lake como Iceberg no Trino via REST Catalog API
Vamos agora ler a mesma tabela Delta UniForm que criamos anteriormente através do Trino usando a Iceberg REST Catalog API do Unity Catalog.
Observação: Uniform não é necessário para ler tabelas Delta com Trino, pois o Trino suporta tabelas Delta diretamente. Isso é apenas para ilustrar como o Uniform expande ainda mais a interoperabilidade no ecossistema de código aberto.
Após configurar o Trino, você pode ajustar as propriedades do Iceberg atualizando o arquivo etc/catalog/iceberg.properties para configurar o Trino para usar o endpoint do catálogo da Iceberg REST API do Unity Catalog:
Onde:
- UNITY_CATALOG_ICEBERG_URL - a URL do endpoint da Iceberg REST API do Unity Catalog - ela tem o formato: https://{DATABRICKS_WORKSPACE_URL}/api/2.1/unity-catalog/iceberg
- DATABRICKS_WORKSPACE_URL - a URL do seu workspace Databricks, que pode ser encontrada navegando até seu workspace Databricks em um navegador web; ela tem o formato: mydatabricksworkspace.cloud.databricks.com/?o=1231231231231231
- PERSONAL_ACCESS_TOKEN - um Token de Acesso Pessoal Databricks que pode ser gerado em um workspace Databricks de acordo com estas instruções
Depois que seu arquivo de propriedades estiver configurado, você pode executar o Trino CLI e emitir uma consulta Iceberg para a tabela Delta UniForm:
Como o Trino implementa a Apache Iceberg REST Catalog API, não criamos nenhuma tabela externa, nem precisamos fornecer o caminho para os arquivos de metadados Iceberg mais recentes. O Trino busca automaticamente os metadados Iceberg mais recentes do UC e, em seguida, lê os dados mais recentes na tabela Delta UniForm.
É importante notar que, da perspectiva do Trino, nada específico do Delta UniForm está acontecendo aqui. Ele está lendo uma tabela Iceberg, cujos metadados foram gerados de acordo com a especificação, e recuperando esses metadados com uma chamada padrão de API REST para um catálogo Iceberg.
Esta é a simplicidade do Delta UniForm. Para escritores e leitores do Delta Lake, a tabela Delta UniForm é uma tabela Delta Lake. Para leitores Iceberg, a tabela Delta UniForm é uma tabela Iceberg - tudo em um único conjunto de arquivos de dados sem cópias desnecessárias de dados e tabelas.
Impacto do Delta UniForm
Ao longo de sua Preview, já ajudamos muitos clientes a acelerar a interoperabilidade do open data lakehouse com o Delta UniForm. As organizações podem gravar uma vez no Delta Lake e, em seguida, acessar esses dados de qualquer forma, alcançando desempenho ideal, custo-benefício e flexibilidade de dados em várias cargas de trabalho, como ETL, BI e IA - tudo sem o fardo de migrações caras e complexas.
"Na Instacart, nossa visão é ter um data lakehouse aberto com uma única cópia de dados que seja interoperável com todas as plataformas de computação. O Delta UniForm é fundamental para esse objetivo. Com o Delta UniForm, podemos gerar tabelas de forma rápida e fácil que podem ser lidas como Delta Lake ou Iceberg, desbloqueando a interoperabilidade com todas as ferramentas em nosso ecossistema." —Doug Hyde, engenheiro de software sênior na Instacart, compartilhou sua experiência com o Delta UniForm
A missão da Databricks é ajudar as equipes de dados a resolver os problemas mais difíceis do mundo, e isso começa com a capacidade de usar a ferramenta certa para o trabalho certo sem ter que fazer cópias de seus dados. Estamos animados com as melhorias na interoperabilidade que o Delta UniForm traz e continuaremos a investir nessa área nos próximos anos.
O Delta UniForm está disponível como parte do release candidate de preview para Delta Lake 3.0. Clientes Databricks também podem experimentar o Delta UniForm com a versão 13.2 do Databricks Runtime ou o canal de preview do Databricks SQL 2023.35.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.