DSPy no Databricks
Um Framework para Programar RAG e Outros Sistemas de IA Compostos
Os modelos de linguagem grandes (LLMs) geraram interesse na interação eficaz entre humanos e IA por meio da otimização de técnicas de prompting. “Engenharia de prompt” é uma metodologia crescente para adaptar as saídas do modelo, enquanto técnicas avançadas como Geração Aumentada por Recuperação (RAG) aprimoram as capacidades generativas dos LLMs buscando e respondendo com informações relevantes.
DSPy, desenvolvido pelo Stanford NLP Group, surgiu como um framework para construir sistemas de IA compostos por meio de “programação, não prompting, de modelos fundacionais.” O DSPy agora oferece suporte a integrações com endpoints de desenvolvedor Databricks para Model Serving e AI Search.
Engenharia de IA Composta
Essas técnicas de prompting sinalizam uma mudança em direção a “pipelines de prompting” complexos onde os desenvolvedores de IA incorporam LLMs, modelos de recuperação (RMs) e outros componentes ao desenvolver sistemas de IA compostos.
Programação, não Prompting: DSPy
O DSPy otimiza o desempenho de sistemas impulsionados por IA compondo chamadas de LLM juntamente com outras ferramentas computacionais em direção a métricas de tarefas downstream. Diferente da tradicional “engenharia de prompt”, o DSPy automatiza o ajuste de prompts traduzindo assinaturas de linguagem natural definidas pelo usuário em instruções completas e exemplos few-shot. Espelhando a otimização de pipeline de ponta a ponta como no PyTorch, o DSPy permite que os usuários definam e componham sistemas de IA camada por camada enquanto otimizam para o objetivo desejado.
Programas em DSPy têm dois métodos principais:
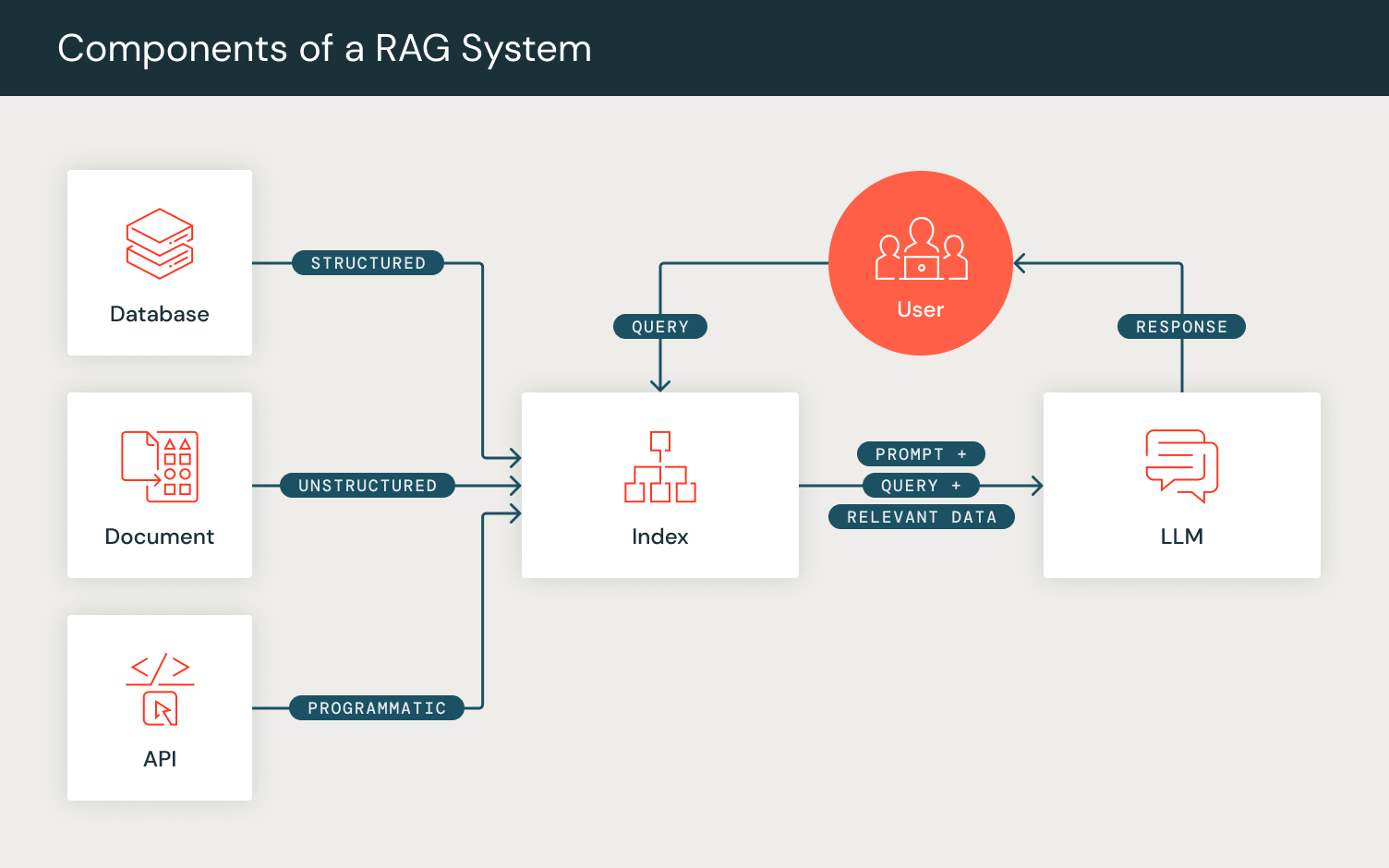
- Inicialização: Usuários podem definir os componentes de seus pipelines de prompting como camadas DSPy. Por exemplo, para considerar as etapas envolvidas em RAG, definimos uma camada de recuperação e uma camada de geração.
- Definimos uma camada de recuperação `dspy.Retrieve` que usa o RM configurado pelo usuário para recuperar um conjunto de passagens/documentos relevantes para uma consulta de busca inserida.
- Em seguida, inicializamos nossa camada de geração, para a qual usamos o módulo `dspy.Predict`, que internamente prepara o prompt para geração. Para configurar essa camada de geração, definimos nossa tarefa RAG em um formato de assinatura de linguagem natural, especificado por um conjunto de campos de entrada (“contexto, consulta”) e o campo de saída esperado (“resposta”). Este módulo então formata internamente o prompt para corresponder a essa formatação definida e, em seguida, retorna a geração do LM configurado pelo usuário.
- Forward: Semelhante às passagens forward do PyTorch, a função forward do programa DSPy permite a composição pelo usuário da lógica do pipeline de prompting. Usando as camadas que inicializamos, configuramos o fluxo computacional do RAG recuperando um conjunto de passagens dada uma consulta e, em seguida, usando essas passagens como contexto junto com a consulta para gerar uma resposta, emitindo a saída esperada em um objeto de dicionário DSPy.
Vamos dar uma olhada no RAG em ação usando o programa DSPy e a geração do DBRX.
Para este exemplo, usamos uma pergunta de amostra do Conjunto de Dados HotPotQA, que inclui perguntas que exigem várias etapas para deduzir a resposta correta.
Vamos primeiro configurar nosso LM e RM em DSPy. O DSPy oferece uma variedade de integrações de modelos de linguagem e recuperação, e os usuários podem definir esses parâmetros para garantir que qualquer programa definido em DSPy seja executado através dessas configurações.
Vamos agora declarar nosso programa RAG DSPy definido e simplesmente passar a pergunta como entrada.
Durante a etapa de recuperação, a query é passada para a camada self.retrieve, que retorna as 3 principais passagens relevantes, que são formatadas internamente da seguinte forma:
Com essas passagens recuperadas, podemos passá-las junto com nossa consulta para o módulo dspy.Predict self.generate_answer, correspondendo aos campos de entrada da assinatura de linguagem natural “contexto, consulta”. Isso aplica internamente alguma formatação e formulação básicas, e permite que você direcione o modelo com sua descrição exata da tarefa sem precisar fazer engenharia de prompt no LLM.
Uma vez declarada a formatação, os campos de entrada “contexto” e “consulta” são preenchidos e o prompt final é enviado para o DBRX:
DBRX gera uma resposta que é preenchida no campo Resposta:, e podemos observar essa geração de prompt chamando:
Isso retorna a última geração de prompt do LM com a resposta gerada “Steve Yzerman”, que é a resposta correta!
DSPy tem sido amplamente utilizado em várias tarefas de modelo de linguagem, como fine-tuning, aprendizado in-contexto, extração de informação, auto-refinamento e muitos outros. Essa abordagem automatizada supera o prompting few-shot padrão com demonstrações escritas por humanos em até 46% para GPT-3.5 e 65% para Llama2-13b-chat em tarefas de linguagem natural como RAG multi-hop e benchmarks de matemática como GSM8K.
DSPy no Databricks
O DSPy agora suporta integrações com endpoints de desenvolvedor do Databricks para Serviço de Modelos e Busca Vetorial. Os usuários podem configurar APIs de modelos de fundação hospedados pelo Databricks através do SDK da OpenAI usando dspy.Databricks. Isso garante que os usuários possam avaliar seus pipelines DSPy de ponta a ponta em modelos hospedados pelo Databricks. Atualmente, isso suporta modelos nos Endpoints de Serviço de Modelos: chat (DBRX Instruct, Mixtral-8x7B Instruct, Llama 2 70B Chat), completion (MPT 7B Instruct) e embedding (BGE Large (En)).
Modelos de Chat
Modelos de Completion
Modelos de Embedding
Modelos de Recuperação/Busca Vetorial
Além disso, os usuários podem configurar modelos de recuperação através da Busca Vetorial do Databricks. Após a criação de um índice e endpoint de Busca Vetorial, os usuários podem especificar os parâmetros de RM correspondentes através de dspy.DatabricksRM:
Os usuários podem configurar isso globalmente definindo o LM e o RM para os endpoints Databricks correspondentes e executando programas DSPy.
Com esta integração, os usuários podem construir e avaliar aplicações DSPy de ponta a ponta, como RAG, usando endpoints Databricks!
Confira o repositório oficial do DSPy no GitHub, a documentação e o Discord para saber mais sobre como transformar tarefas de IA generativa em pipelines DSPy versáteis com Databricks!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.