Ajuste Fino Eficiente com LoRA: Um Guia para Seleção Ótima de Parâmetros para Modelos de Linguagem Grandes
Com o rápido avanço das técnicas baseadas em redes neurais e a pesquisa em Modelos de Linguagem Grandes (LLMs), as empresas estão cada vez mais interessadas em aplicações de IA para geração de valor. Elas empregam várias abordagens de machine learning, tanto generativas quanto não generativas, para resolver desafios relacionados a texto, como classificação, sumarização, tarefas de sequência a sequência e geração de texto controlada. As organizações podem optar por APIs de terceiros, mas o ajuste fino de modelos com dados proprietários oferece resultados específicos do domínio e pertinentes, permitindo soluções econômicas e independentes, implantáveis em diferentes ambientes de forma segura.
Garantir a utilização eficiente de recursos e a relação custo-benefício é crucial ao escolher uma estratégia de ajuste fino. Este blog explora a que é, possivelmente, a variante mais popular e eficaz de tais métodos eficientes de parâmetros, a Adaptação de Baixo Rank (LoRA), com ênfase particular em QLoRA (uma variante ainda mais eficiente da LoRA). A abordagem aqui será pegar um modelo de linguagem grande aberto e ajustá-lo para gerar descrições fictícias de produtos quando solicitado com um nome de produto e uma categoria. O modelo escolhido para este exercício é OpenLLaMA-3b-v2, um modelo de linguagem grande aberto com uma licença permissiva (Apache 2.0), e o conjunto de dados escolhido é Red Dot Design Award Product Descriptions, ambos podem ser baixados do HuggingFace Hub nos links fornecidos.
Ajuste Fino, LoRA e QLoRA
No domínio dos modelos de linguagem, o ajuste fino de um modelo de linguagem existente para realizar uma tarefa específica em dados específicos é uma prática comum. Isso envolve adicionar uma cabeça específica da tarefa, se necessário, e atualizar os pesos da rede neural por meio de retropropagação durante o processo de treinamento. É importante notar a distinção entre este processo de ajuste fino e o treinamento do zero. Neste último cenário, os pesos do modelo são inicializados aleatoriamente, enquanto no ajuste fino, os pesos já estão otimizados até certo ponto durante a fase de pré-treinamento. A decisão de quais pesos otimizar ou atualizar, e quais manter congelados, depende da técnica escolhida.
O ajuste fino completo envolve a otimização ou treinamento de todas as camadas da rede neural. Embora essa abordagem geralmente produza os melhores resultados, ela também é a mais intensiva em recursos e demorada.
Felizmente, existem abordagens eficientes em parâmetros para o ajuste fino que se mostraram eficazes. Embora a maioria dessas abordagens tenha apresentado desempenho inferior, a Adaptação de Baixo Rank (LoRA) quebrou essa tendência, superando até mesmo o ajuste fino completo em alguns casos, como consequência de evitar o esquecimento catastrófico (um fenômeno que ocorre quando o conhecimento do modelo pré-treinado é perdido durante o processo de ajuste fino).
LoRA é um método de ajuste fino aprimorado onde, em vez de ajustar todos os pesos que compõem a matriz de pesos do modelo de linguagem grande pré-treinado, duas matrizes menores que aproximam essa matriz maior são ajustadas. Essas matrizes constituem o adaptador LoRA. Este adaptador ajustado é então carregado no modelo pré-treinado e usado para inferência.
QLoRA é uma versão ainda mais eficiente em termos de memória da LoRA, onde o modelo pré-treinado é carregado na memória da GPU como pesos quantizados de 4 bits (em comparação com 8 bits no caso da LoRA), preservando eficácia semelhante à LoRA. Investigar este método, comparar os dois métodos quando necessário e descobrir a melhor combinação de hiperparâmetros QLoRA para alcançar desempenho ideal com o tempo de treinamento mais rápido será o foco aqui.
LoRA é implementado na biblioteca Hugging Face Parameter Efficient Fine-Tuning (PEFT), oferecendo facilidade de uso e QLoRA pode ser aproveitado usando bitsandbytes e PEFT juntos. A biblioteca HuggingFace Transformer Reinforcement Learning (TRL) oferece um treinador conveniente para ajuste fino supervisionado com integração perfeita para LoRA. Essas três bibliotecas fornecerão as ferramentas necessárias para ajustar o modelo pré-treinado escolhido para gerar descrições de produtos coerentes e convincentes quando solicitado com uma instrução indicando os atributos desejados.
Preparando os dados para ajuste fino supervisionado
Para investigar a eficácia do QLoRA para ajustar um modelo para seguir instruções, é essencial transformar os dados em um formato adequado para ajuste fino supervisionado. O ajuste fino supervisionado, em essência, treina ainda mais um modelo pré-treinado para gerar texto condicionado a um prompt fornecido. É supervisionado no sentido de que o modelo é ajustado em um conjunto de dados que possui pares de prompt-resposta formatados de maneira consistente.
Uma observação de exemplo do nosso conjunto de dados escolhido no hub Hugging Face se parece com o seguinte:
|
produto |
categoria |
descrição |
texto |
|
"Biamp Rack Products" |
"Digital Audio Processors" |
"“Alto valor de reconhecimento, estética uniforme e escalabilidade prática – isso foi impressionantemente alcançado com a linguagem de marca Biamp…” |
"Nome do Produto: Biamp Rack Products; Categoria do Produto: Digital Audio Processors; Descrição do Produto: “Alto valor de reconhecimento, estética uniforme e escalabilidade prática – isso foi impressionantemente alcançado com a linguagem de marca Biamp…”
|
Por mais útil que seja este conjunto de dados, ele não está bem formatado para o ajuste fino de um modelo de linguagem para seguir instruções da maneira descrita acima.
O trecho de código a seguir carrega o conjunto de dados do hub Hugging Face na memória, transforma os campos necessários em uma string formatada de forma consistente representando o prompt e insere a resposta (ou seja, a descrição) imediatamente depois. Este formato é conhecido como o 'formato Alpaca' em círculos de pesquisa de modelos de linguagem grandes, pois foi o formato usado para ajustar o modelo LLaMA original da Meta para resultar no modelo Alpaca, um dos primeiros modelos de linguagem grandes de instrução amplamente distribuídos (embora não licenciado para uso comercial).
Os prompts resultantes são então carregados em um conjunto de dados Hugging Face para ajuste fino supervisionado. Cada prompt desse tipo tem o seguinte formato.
Para facilitar a experimentação rápida, cada exercício de fine-tuning será feito em um subconjunto de 5000 observações desses dados.
Testando o desempenho do modelo antes do fine-tuning
Antes de qualquer fine-tuning, é uma boa ideia verificar como o modelo se comporta sem nenhum fine-tuning para obter uma linha de base do desempenho do modelo pré-treinado.
O modelo pode ser carregado em 8 bits da seguinte forma e solicitado com o formato especificado no cartão do modelo no Hugging Face.
A saída obtida não é exatamente o que queremos.
A primeira parte do resultado é, na verdade, satisfatória, mas o resto é mais uma bagunça divagante.
Da mesma forma, se o modelo for solicitado com o texto de entrada no 'formato Alpaca', como discutido anteriormente, espera-se que a saída seja igualmente subótima:
E, de fato, é:
O modelo faz o que foi treinado para fazer: prevê o próximo token mais provável. O objetivo do fine-tuning supervisionado neste contexto é gerar o texto desejado de maneira controlável. Observe que nos experimentos subsequentes, embora o QLoRA utilize um modelo carregado em 4 bits com os pesos congelados, o processo de inferência para examinar a qualidade da saída é feito uma vez que o modelo tenha sido carregado em 8 bits, como mostrado acima, para consistência.
Os Botões Ajustáveis
Ao usar PEFT para treinar um modelo com LoRA ou QLoRA (observe que, como mencionado anteriormente, a principal diferença entre os dois é que, neste último, os modelos pré-treinados são congelados em 4 bits durante o processo de fine-tuning), os hiperparâmetros do processo de adaptação de baixo rank podem ser definidos em uma configuração LoRA, como mostrado abaixo:
Dois desses hiperparâmetros, r e target_modules, são empiricamente mostrados como afetando significativamente a qualidade da adaptação e serão o foco dos testes a seguir. Os outros hiperparâmetros são mantidos constantes nos valores indicados acima por simplicidade.
r representa o rank das matrizes de baixo rank aprendidas durante o processo de fine-tuning. À medida que esse valor aumenta, o número de parâmetros necessários para serem atualizados durante a adaptação de baixo rank aumenta. Intuitivamente, um r menor pode levar a um processo de treinamento mais rápido e menos intensivo em computação, mas pode afetar a qualidade do modelo produzido. No entanto, aumentar r além de um certo valor pode não gerar nenhum aumento perceptível na qualidade da saída do modelo. Como o valor de r afeta a qualidade da adaptação (fine-tuning) será testado em breve.
Ao fazer fine-tuning com LoRA, é possível direcionar módulos específicos na arquitetura do modelo. O processo de adaptação terá como alvo esses módulos e aplicará as matrizes de atualização a eles. Semelhante à situação com "r", direcionar mais módulos durante a adaptação LoRA resulta em maior tempo de treinamento e maior demanda por recursos de computação. Assim, é uma prática comum direcionar apenas os blocos de atenção do transformador. No entanto, trabalhos recentes, como mostrado no artigo QLoRA de Dettmers et al., sugere que direcionar todas as camadas lineares resulta em melhor qualidade de adaptação. Isso também será explorado aqui.
Os nomes das camadas lineares do modelo podem ser convenientemente adicionados a uma lista com o seguinte trecho de código:
Ajustando o fine-tuning com LoRA
A experiência do desenvolvedor de fazer fine-tuning de grandes modelos de linguagem em geral melhorou dramaticamente no último ano ou mais. A mais recente abstração de alto nível do Hugging Face é a classe SFTTrainer na biblioteca TRL. Para realizar QLoRA, tudo o que é necessário é o seguinte:
1. Carregue o modelo na memória da GPU em 4 bits (bitsandbytes habilita este processo).
2. Defina a configuração LoRA conforme discutido acima.
3. Defina os splits de treinamento e teste dos dados de instrução preparados em objetos Hugging Face Dataset.
4. Defina os argumentos de treinamento. Estes incluem o número de épocas, tamanho do lote e outros hiperparâmetros de treinamento que serão mantidos constantes durante este exercício.
5. Passe esses argumentos para uma instância de SFTTrainer.
Essas etapas são claramente indicadas no arquivo fonte no repositório associado a este blog.
A lógica de treinamento real é bem abstraída da seguinte forma:
Se o MLFlow autologging estiver habilitado no workspace Databricks, o que é altamente recomendado, todos os parâmetros e métricas de treinamento são rastreados e registrados automaticamente com o servidor de rastreamento MLFlow. Essa funcionalidade é inestimável no monitoramento de tarefas de treinamento de longa duração. Nem é preciso dizer que o processo de fine-tuning é realizado usando um cluster de computação (neste caso, um único nó com uma única GPU A100) criado usando o mais recente Databricks Machine runtime com suporte a GPU.
Combinação de Hiperparâmetros #1: QLoRA com r=8 e direcionando “q_proj”, “v_proj”
A primeira combinação de hiperparâmetros QLoRA tentada é r=8 e visa apenas os blocos de atenção, especificamente “q_proj” e “v_proj” para adaptação.
Os seguintes trechos de código fornecem o número de parâmetros treináveis:
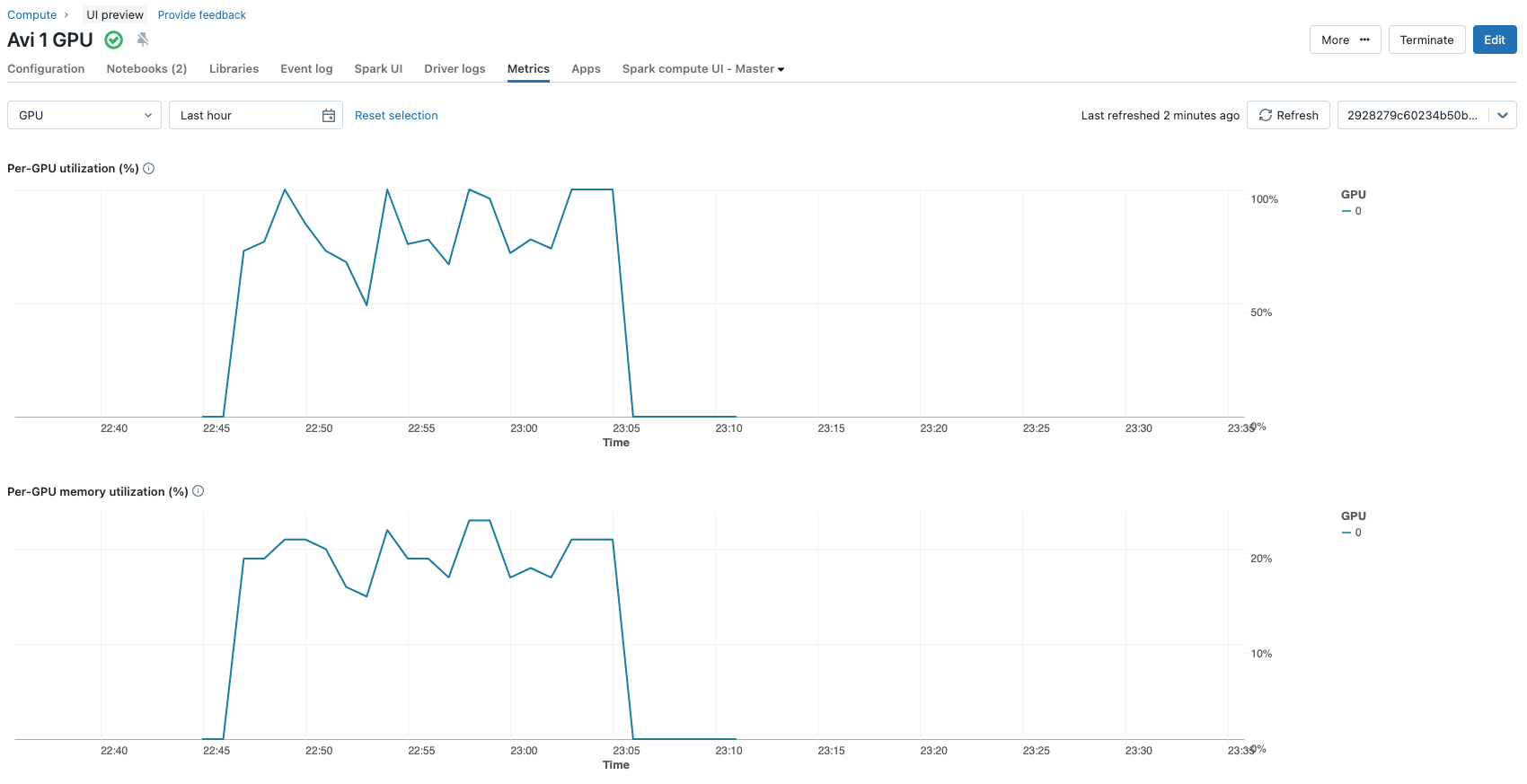
Essas escolhas resultam em 2.662.400 parâmetros sendo atualizados durante o processo de fine-tuning (~2,6 milhões) de um total de ~3,2 bilhões de parâmetros que o modelo consiste. Isso é menos de 0,1% dos parâmetros do modelo. Todo o processo de fine-tuning em uma única Nvidia A100 com 80 GB de GPU por 3 épocas leva apenas cerca de 12 minutos. As métricas de utilização da GPU podem ser visualizadas convenientemente na aba de métricas das configurações do cluster.
Ao final do processo de treinamento, o modelo fine-tuned é obtido carregando os pesos do adaptador para o modelo pré-treinado da seguinte forma:
Este modelo agora pode ser usado para inferência como qualquer outro modelo.
Avaliação Qualitativa
Alguns pares de exemplos de prompt-resposta são listados abaixo
Prompt (passado para o modelo no formato Alpaca, não mostrado por concisão aqui):
Crie uma descrição detalhada para o seguinte produto: Corelogic Smooth Mouse, pertencente à categoria: Mouse Óptico
Resposta:
Prompt:
Crie uma descrição detalhada para o seguinte produto: Hoover Lightspeed, pertencente à categoria: Aspirador de Pó sem Fio
Resposta:
O modelo foi claramente adaptado para gerar descrições mais consistentes. No entanto, a resposta ao primeiro prompt sobre o mouse óptico é bastante curta e a seguinte frase “O aspirador de pó está equipado com um recipiente de pó que pode ser esvaziado através de um recipiente de pó” é logicamente falha.
Combinação de Hiperparâmetros #2: QLoRA com r=16 e visando todas as camadas lineares
Certamente, as coisas podem ser melhoradas aqui. Vale a pena explorar o aumento do rank das matrizes de baixo rank aprendidas durante a adaptação para 16, ou seja, dobrar o valor de r para 16 e manter todo o resto igual. Isso dobra o número de parâmetros treináveis para 5.324.800 (~5,3 milhões).
Avaliação Qualitativa
A qualidade da saída, no entanto, permanece inalterada para os mesmos prompts exatos.
Prompt:
Crie uma descrição detalhada para o seguinte produto: Corelogic Smooth Mouse, pertencente à categoria: Mouse Óptico
Resposta:
Prompt:
Crie uma descrição detalhada para o seguinte produto: Hoover Lightspeed, pertencente à categoria: Aspirador de Pó sem Fio
Resposta:
A mesma falta de detalhe e falhas lógicas onde detalhes estão disponíveis persiste. Se este modelo fine-tuned for usado para geração de descrição de produtos em um cenário do mundo real, esta não é uma saída aceitável.
Combinação de Hiperparâmetros #3: QLoRA com r=8 e visando todas as camadas lineares
Dado que dobrar r não resulta aparentemente em nenhum aumento perceptível na qualidade da saída, vale a pena mudar o outro botão importante. Ou seja, visar todas as camadas lineares em vez de apenas os blocos de atenção. Aqui, os hiperparâmetros LoRA são r=8 e target_layers são 'q_proj','k_proj','v_proj','o_proj','gate_proj','down_proj','up_proj' e 'lm_head'. Isso aumenta o número de parâmetros atualizados para 12.994.560 e aumenta o tempo de treinamento para aproximadamente 15,5 minutos.
Avaliação Qualitativa
A solicitação do modelo com os mesmos prompts produz os seguintes resultados:
Prompt:
Crie uma descrição detalhada para o seguinte produto: Corelogic Smooth Mouse, pertencente à categoria: Mouse Óptico
Resposta:
Prompt:
Crie uma descrição detalhada para o seguinte produto: Hoover Lightspeed, pertencente à categoria: Aspirador de Pó sem Fio
Resposta:
Agora é possível ver uma descrição um tanto mais longa e coerente do mouse óptico fictício e não há falhas lógicas na descrição do aspirador de pó. As descrições dos produtos não são apenas lógicas, mas relevantes. Apenas como um lembrete, esses resultados de qualidade relativamente alta são obtidos pelo fine-tuning de menos de 1% dos pesos do modelo com um conjunto de dados total de 5000 pares de prompt-descrição formatados de maneira consistente.
Combinação de Hiperparâmetros #4: LoRA com r=8 e visando todas as camadas lineares do transformer
Também vale a pena explorar se a qualidade da saída do modelo melhora se o modelo pré-treinado for congelado em 8 bits em vez de 4 bits. Em outras palavras, replicando o processo exato de fine-tuning usando LoRA em vez de QLoRA. Aqui, os hiperparâmetros LoRA são mantidos os mesmos de antes, na nova configuração ótima encontrada, ou seja, r=8 e visando todas as camadas lineares do transformer durante o processo de adaptação.
Avaliação Qualitativa
Os resultados para os dois prompts usados em todo o artigo são os seguintes:
Prompt:
Crie uma descrição detalhada para o seguinte produto: Corelogic Smooth Mouse, pertencente à categoria: Mouse Óptico
Resposta:
Prompt:
Crie uma descrição detalhada para o seguinte produto: Hoover Lightspeed, pertencente à categoria: Aspirador de Pó sem Fio
Resposta:
Novamente, não há muita melhoria na qualidade do texto de saída.
Principais Observações
Com base no conjunto de testes acima, e em evidências adicionais detalhadas na excelente publicação que apresenta o QLoRA, pode-se deduzir que o valor de r (o rank das matrizes atualizadas durante a adaptação) não melhora a qualidade da adaptação além de um certo ponto. A maior melhoria é observada ao visar todas as camadas lineares no processo de adaptação, em oposição a apenas os blocos de atenção, como comumente documentado na literatura técnica detalhando LoRA e QLoRA. Os testes executados acima e outras evidências empíricas sugerem que o QLoRA, de fato, não sofre de nenhuma redução perceptível na qualidade do texto gerado, em comparação com o LoRA.
Considerações Adicionais para usar adaptadores LoRA na implantação
É importante otimizar o uso de adaptadores e entender as limitações da técnica. O tamanho do adaptador LoRA obtido por meio de finetuning é tipicamente de apenas alguns megabytes, enquanto o modelo base pré-treinado pode ter vários gigabytes em memória e em disco. Durante a inferência, tanto o adaptador quanto o LLM pré-treinado precisam ser carregados, de modo que o requisito de memória permaneça semelhante.
Além disso, se os pesos do LLM pré-treinado e do adaptador não forem mesclados, haverá um leve aumento na latência de inferência. Felizmente, com a biblioteca PEFT, o processo de mesclagem dos pesos com o adaptador pode ser feito com uma única linha de código, como mostrado aqui:
A figura abaixo descreve o processo, desde o finetuning de um adaptador até a implantação do modelo.

Embora o padrão de adaptador ofereça benefícios significativos, a mesclagem de adaptadores não é uma solução universal. Uma vantagem do padrão de adaptador é a capacidade de implantar um único modelo pré-treinado grande com adaptadores específicos para tarefas. Isso permite uma inferência eficiente, utilizando o modelo pré-treinado como base para diferentes tarefas. No entanto, a mesclagem de pesos torna essa abordagem impossível. A decisão de mesclar pesos depende do caso de uso específico e da latência de inferência aceitável. Não obstante, LoRA/QLoRA continua sendo um método altamente eficaz para finetuning com parâmetros eficientes e é amplamente utilizado.
Conclusão
Low Rank Adaptation é uma técnica poderosa de finetuning que pode gerar ótimos resultados se usada com a configuraç�ão correta. A escolha do valor correto de rank e das camadas da arquitetura da rede neural a serem direcionadas durante a adaptação pode decidir a qualidade da saída do modelo finetunado. QLoRA resulta em economia de memória adicional, preservando a qualidade da adaptação. Mesmo quando o finetuning é realizado, existem várias considerações importantes de engenharia para garantir que o modelo adaptado seja implantado da maneira correta.
Em resumo, uma tabela concisa indicando as diferentes combinações de parâmetros LoRA tentados, a qualidade do texto de saída e o número de parâmetros atualizados ao fazer finetuning do OpenLLaMA-3b-v2 por 3 épocas em 5000 observações em um único A100 é mostrada abaixo.
|
r |
target_modules |
Pesos do modelo base |
Qualidade da saída |
Número de parâmetros atualizados (em milhões) |
|
8 |
Blocos de atenção |
4 |
baixa |
2.662 |
|
16 |
Blocos de atenção |
4 |
baixa |
5.324 |
|
8 |
Todas as camadas lineares |
4 |
alta |
12.995 |
|
8 |
Todas as camadas lineares |
8 |
alta |
12.995 |
Experimente no Databricks! Clone o repositório GitHub associado ao blog no Databricks Repo para começar. Exemplos mais detalhados para fazer finetuning de modelos no Databricks estão disponíveis aqui.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.