Governança em escala empresarial: migrando do Hive Metastore para o Unity Catalog
Aprenda a migrar cargas de trabalho complexas e de grande escala do Hive Metastore para o Unity Catalog, aproveitando a governança de dados e as otimizações de desempenho sem interrupções.
por Josh Bae e Dhaval Bagadia
- As organizações prosperam com agilidade e tomada de decisões orientada por dados, mas os metastores do Hive legados criam lacunas de governança, acesso isolado e gargalos operacionais que dificultam a agilidade e a conformidade.
- A migração para o Unity Catalog fornece governança unificada, permitindo que as empresas escalem com segurança as cargas de trabalho de análise de dados e IA.
- Este guia apresenta estratégias práticas para gerenciar a complexidade e minimizar a interrupção durante a transição.
Complexidades do cenário de dados
À medida que as empresas continuam a expandir suas capacidades digitais e de dados, a complexidade da infraestrutura de dados aumenta, e o valor sustentado depende de informações oportunas, confiáveis e acessíveis. No entanto, muitas ainda dependem de metastores legados do Hive (HMS), que não foram projetados para as necessidades modernas de governança em grande escala além dos limites de um único workspace.
O HMS não possui, por princípio, rastreamento de linhagem, governança em múltiplos workspaces e controles de segurança modernos. Por exemplo, usuários que dependem de um HMS legado por workspace do Databricks enfrentam políticas duplicadas e visibilidade fragmentada entre ambientes de workspace, enquanto os usuários que usam um HMS externo correm o risco de montagens configuradas incorretamente que podem expor dados confidenciais acidentalmente a todos os usuários do workspace. À medida que as equipes se tornam mais distribuídas e o uso de dados se acelera, essas limitações dificultam a agilidade e a conformidade, acabando por minar a confiança na tomada de decisões orientada por dados.
O Unity Catalog (UC) aborda esses desafios ao introduzir um modelo de governança unificado para todos os ativos de dados e IA na Databricks Data Intelligence Platform. Com controles de acesso refinados, rastreamento de linhagem centralizado e suporte para múltiplos workspaces, o Unity Catalog fornece a base que as organizações precisam para escalar com segurança e operar com mais eficiência — recursos que são simplesmente impossíveis com a arquitetura HMS.
Por que isso é importante agora
O momento para esta orientação de migração é crucial — nos últimos anos, nosso entendimento do que é necessário para migrar para o Unity Catalog e nossas ferramentas evoluíram. Este blog resume nossa metodologia e melhores práticas mais recentes, representando técnicas testadas em campo e lições do mundo real aprendidas de inúmeras migrações para o Unity Catalog em diversos ambientes empresariais. As organizações agora têm acesso a abordagens comprovadas que reduzem significativamente o risco e a complexidade da implementação.
Este blog fornece orientações para migrar de metastores HMS legados por workspace do Databricks (conhecidos como HMS interno) e HMS externos (como o AWS Glue) e inclui os seguintes tópicos:
- Avalie modelos de governança que suportam autonomia sem sacrificar o controle
- Projete e execute uma arquitetura escalável que minimize o risco e a interrupção
- Operacionalizar a governança para dar suporte ao acesso seguro e self-service aos dados
- Crie novas cargas de trabalho usando o Unity Catalog antes de migrar os ativos de dados
- Minimizar a interrupção durante a migração e o período de transição
Principais considerações de arquitetura
Migrar do HMS para o Unity Catalog apresenta às organizações a oportunidade de modernizar sua arquitetura de dados; no entanto, para aproveitar todo o valor do Unity Catalog, é necessário tomar decisões de design intencionais desde o início. Essas decisões de arquitetura devem estar alinhadas ao ritmo de inovação de uma organização, ao modelo de propriedade de domínio e às necessidades de acesso a dados entre equipes.
Embora os princípios gerais permaneçam os mesmos, certas ferramentas e abordagens de migração podem funcionar de maneira diferente dependendo do tipo de metastore. Devido a essas diferenças, é crucial avaliar a compatibilidade das ferramentas e os requisitos de migração no contexto da sua arquitetura atual. Com esse entendimento, podemos examinar o design do metastore — a base do modelo de governança do Unity Catalog e um primeiro passo fundamental para moldar como catálogos, esquemas e permissões serão organizados para escalabilidade e conformidade a longo prazo.
Design do metastore
Como o contêiner de nível superior para metadados no Unity Catalog, o metastore é a base do modelo de governança. Ele ancora a estrutura de controle de acesso da conta, definindo catálogos como a unidade principal de isolamento de dados e o mecanismo central para delimitar o acesso entre domínios de negócios. O metastore do Unity Catalog é hospedado como um serviço multilocatário no plano de controle do Databricks e atua como o registro oficial para catálogos, esquemas, tabelas, visualizações e permissões. Devido ao seu papel central, o design do metastore é uma etapa inicial crítica e deve levar em conta os requisitos de governança de dados, o isolamento de cargas de trabalho e a escalabilidade a longo prazo.
Esta seção se concentra nos princípios de design do metastore. Os detalhes técnicos sobre o provisionamento de um metastore do Unity Catalog com Infraestrutura como Código (IaC) são abordados mais adiante em “Implantação automatizada com Infraestrutura como Código (IaC)”.
Para obter informações sobre os conceitos do Unity Catalog, incluindo metastores, armazenamento gerenciado e controles de acesso, consulte O que é o Unity Catalog? (AWS | Azure | GCP)
{kind=link}
O Unity Catalog oferece suporte a um metastore por região, mas fornece vários mecanismos para impor o isolamento lógico e físico entre domínios de dados. Isso torna uma estratégia de metastore único viável para a maioria das organizações, mesmo para aquelas com ambientes complexos ou altamente segmentados.
Na prática, a maioria das equipes adota um único metastore e impõe limites usando catálogos e esquemas, em vez de provisionar vários metastores, a menos que o isolamento regional estrito seja um requisito regulatório ou de conformidade.
Para obter orientações sobre como compartilhar dados entre regiões ou plataformas de nuvem, consulte Compartilhamento entre regiões e plataformas (AWS | Azure | GCP).
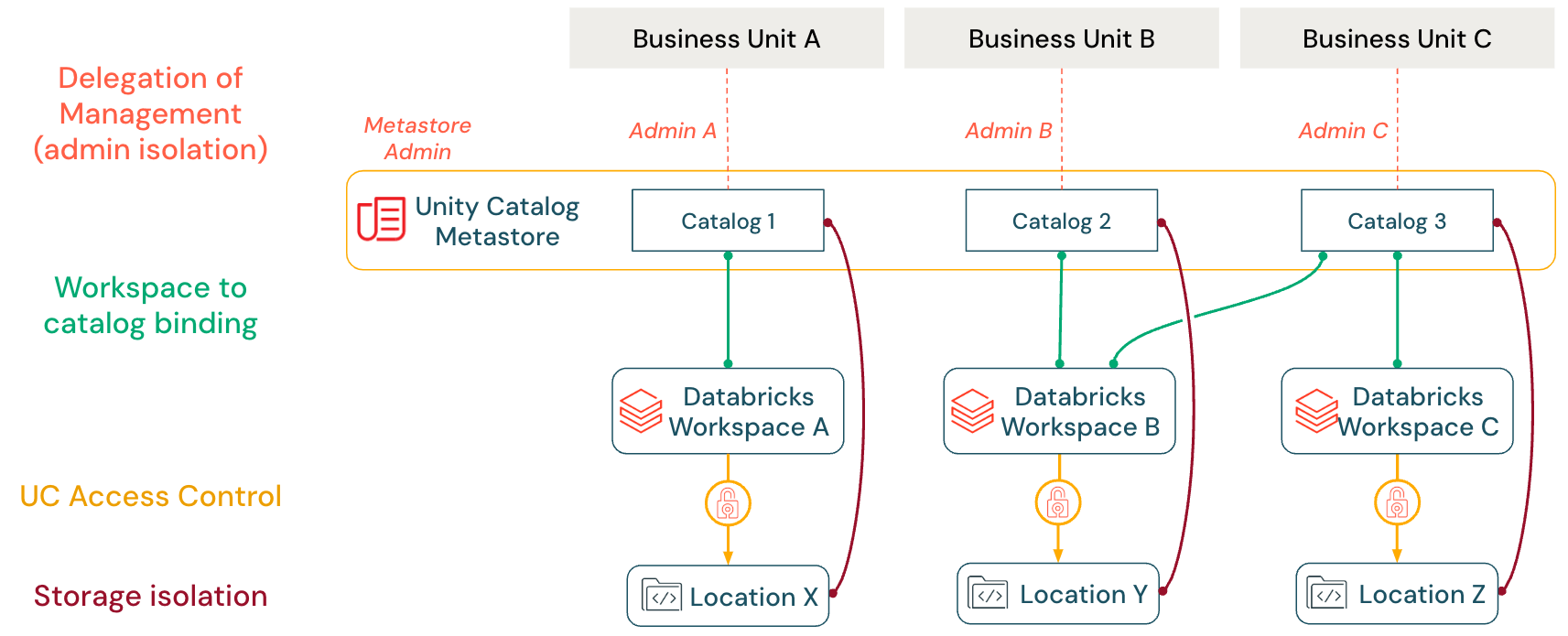
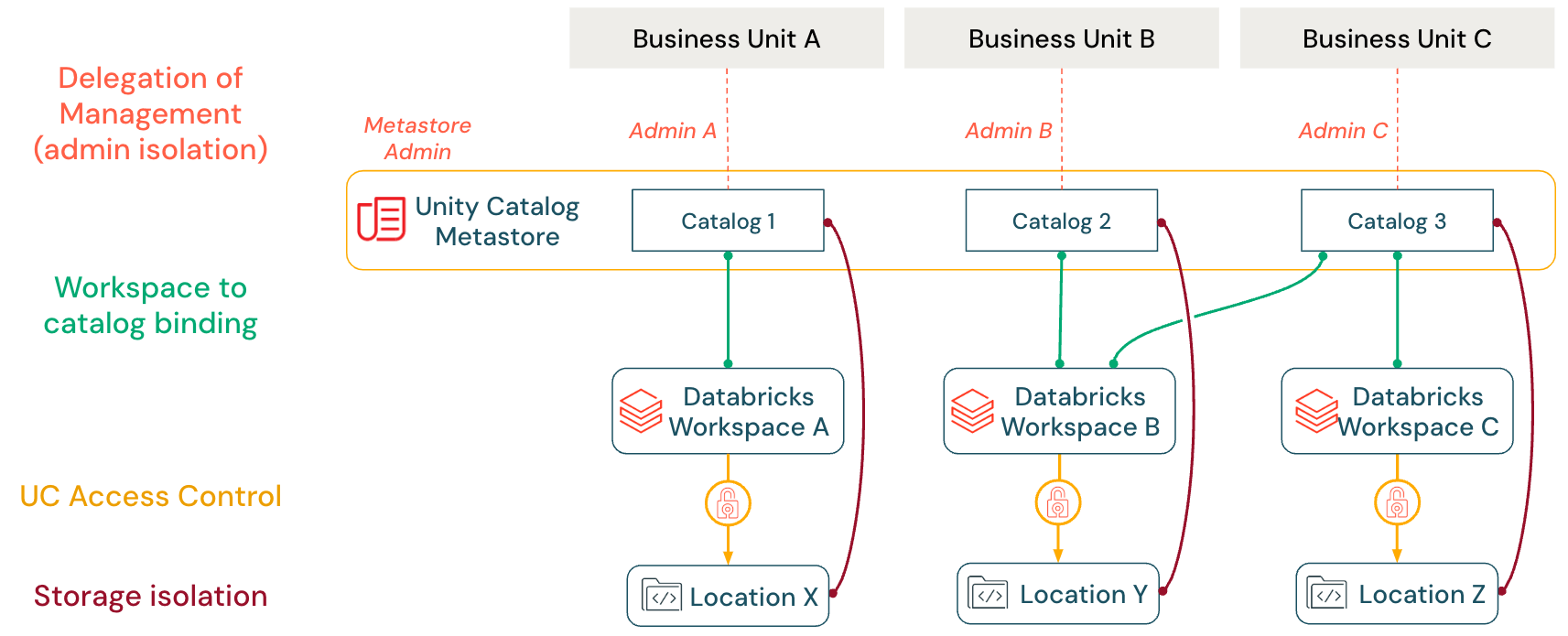
Principais mecanismos de isolamento
O Unity Catalog oferece quatro mecanismos de isolamento principais que funcionam em conjunto para impor limites de dados e permitir a governança descentralizada em uma arquitetura de metastore único:
| Recurso | Finalidade |
|---|---|
| Delegação de gerenciamento | Transferir a propriedade e o controle administrativo de catálogos, esquemas e tabelas para equipes específicas do domínio por meio do modelo de propriedade de objetos do Unity Catalog |
| Vinculação de catálogo ao workspace | Restringir o acesso ao catálogo a workspaces específicos, garantindo a separação de ambientes entre cargas de trabalho de desenvolvimento e produção |
| Controle de acesso refinado | Aplicar permissões hierárquicas, filtros de linha e máscaras de coluna para impor requisitos de segurança de dados precisos no nível da tabela e da coluna |
| Isolamento de armazenamento | Mapear catálogos para contêineres de armazenamento em nuvem dedicados por meio de locais de armazenamento gerenciado, proporcionando separação física dos ativos de dados |
Delegação de gerenciamento (isolamento do administrador)
O modelo de propriedade de objetos no Unity Catalog atribui a cada catálogo, esquema e tabela um único proprietário, permitindo a delegação controlada. Os proprietários de objetos ou administradores do metastore podem conceder o privilégio MANAGE a outras entidades de segurança (por exemplo, um usuário, uma entidade de serviço ou um grupo de contas). Isso permite que eles renomeiem, descartem ou modifiquem permissões em objetos sem conceder privilégios de acesso a dados, como SELECT ou MODIFY.
Essa separação de funções oferece suporte à administração descentralizada. As equipes podem gerenciar seus ativos de dados, enquanto os administradores do metastore mantêm a autoridade para transferir a propriedade, recuperar o acesso e impor a governança em todo o ambiente. Recomenda-se atribuir a propriedade ou o privilégio MANAGE a grupos em vez de indivíduos para garantir a continuidade e reduzir a sobrecarga administrativa.
Para obter mais informações sobre o modelo de propriedade de objetos e o gerenciamento de privilégios para ativos governados pelo UC, consulte Gerenciar a propriedade de objetos do Unity Catalog (AWS | Azure | GCP).
Vinculação de workspace a catálogo
O Unity Catalog permite limitações precisas sobre quais workspaces podem acessar quais catálogos usando a vinculação de catálogo ao workspace (AWS | Azure | GCP). Por exemplo, um catálogo de dados de produção pode ser vinculado exclusivamente a um workspace específico, impedindo que os usuários alterem os dados em workspaces de desenvolvedor. Nesse exemplo, a vinculação de catálogo ao workspace não impede totalmente o acesso a um determinado catálogo por outros workspaces. Por exemplo, os administradores do metastore ou os proprietários do catálogo podem especificar acesso somente leitura aos dados de produção para usuários em um workspace de desenvolvedor, permitindo que testem conforme necessário (um único catálogo pode ser compartilhado em vários workspaces). Esse recurso garante que os limites do workspace sejam mantidos para domínios de dados, independentemente dos privilégios no nível do usuário.
Controle de acesso do Unity Catalog
O Unity Catalog permite o controle de acesso refinado e hierárquico baseado em função (RBAC), permitindo que os administradores concedam permissões precisas (no nível de metastore, catálogo, esquema ou tabela) a usuários, grupos ou entidades de serviço. O acesso é gerenciado por meio de comandos SQL ou da UI e CLI do Databricks, o que simplifica a restrição do acesso aos dados e a aplicação de uma governança de dados e privacidade robustas.
O controle de acesso no Unity Catalog é baseado em quatro modelos complementares que funcionam em conjunto:
- Restrições no nível do workspace: limitam onde os usuários podem acessar os dados, vinculando objetos a workspaces específicos.
- Privilégios e propriedade: definem quem pode acessar o quê, concedendo privilégios sobre objetos protegíveis e gerenciando a propriedade de objetos.
- Controle de acesso baseado em atributos (Beta): governam quais dados os usuários podem acessar usando tags e políticas flexíveis e centralizadas que avaliam dinamicamente os atributos de usuário, recurso ou ambiente.
- Filtragem e mascaramento no nível da tabela: controlam quais dados os usuários podem ver dentro das tabelas com filtros no nível da linha e máscaras de coluna, aplicados diretamente aos dados.
Consulte Controle de acesso no Unity Catalog (AWS | Azure | GCP) para obter mais informações.
Isolamento de armazenamento
Embora os metastores forneçam isolamento regional, o isolamento de dados geralmente é alcançado no nível do catálogo. O Databricks recomenda atribuir a cada catálogo seu próprio contêiner de armazenamento gerenciado (por exemplo, um bucket S3, um contêiner ADLS ou um bucket GCS dedicado) para aplicar isso. Qualquer nova tabela ou volume gerenciado nesse catálogo é gravado em seu contêiner atribuído por padrão. Na prática, uma empresa pode dar a cada equipe ou ambiente seu próprio catálogo (por exemplo, vendas_prod, marketing_dev) com um bucket de nuvem separado. Essa abordagem garante que os dados de cada equipe permaneçam fisicamente isolados, ao mesmo tempo que simplifica a governança. Políticas que incorporam criptografia e gerenciamento do ciclo de vida dos dados podem ser aplicadas no nível do contêiner para atender aos requisitos de conformidade.
Além disso, o Unity Catalog usa duas construções principais para governar o acesso a dados externos:
- Uma credencial de armazenamento encapsula a identidade da nuvem (como uma função IAM, uma entidade de serviço do Azure ou uma conta de serviço do GCP) usada para acessar o armazenamento de objetos
- Um local externo vincula essa credencial a um caminho ou contêiner de nuvem específico. Somente usuários com privilégios em um local externo podem ler ou gravar dados nesse caminho.
Eles também podem ser vinculados a workspaces específicos, garantindo que apenas usuários privilegiados possam acessar caminhos de dados confidenciais.
Para obter mais informações, consulte Conectar-se ao armazenamento de objetos na nuvem usando o Unity Catalog (AWS | Azure | GCP).
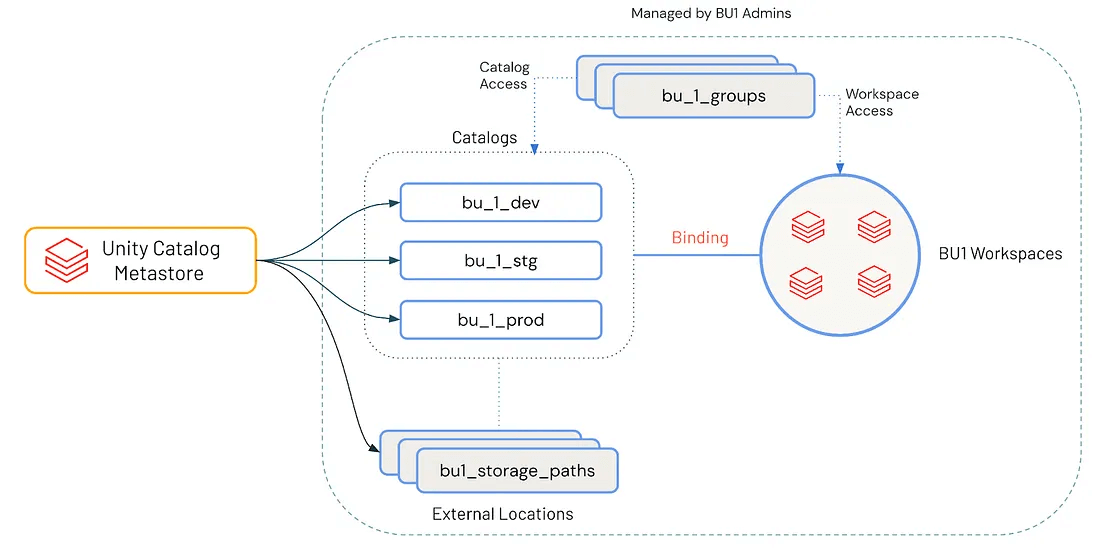
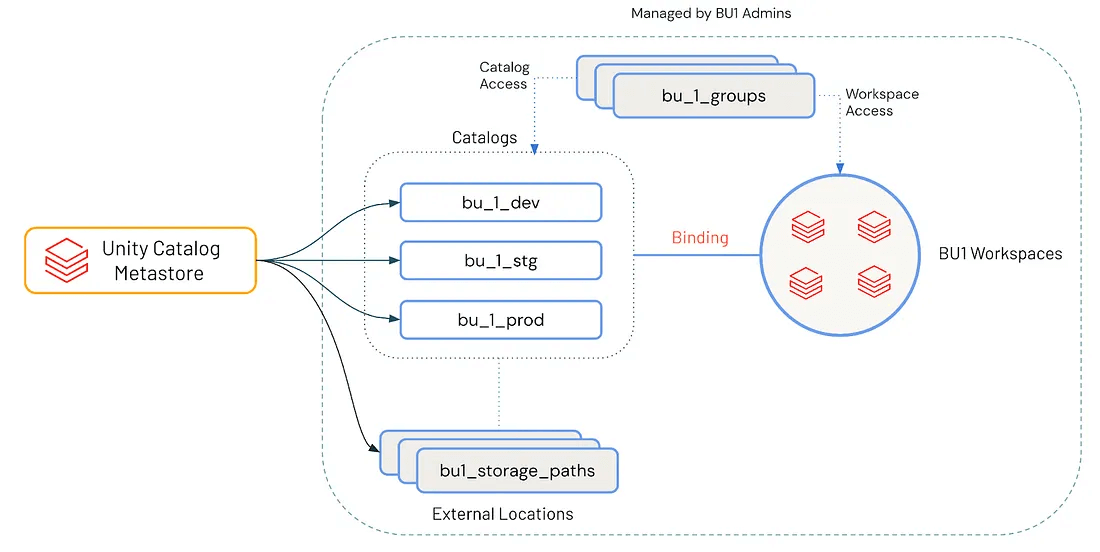
Design de catálogo
Com um metastore bem planejado, a atenção se volta para o design do catálogo, onde as decisões de governança começam a se alinhar com o uso diário dos dados. Enquanto o metastore estabelece o plano de controle de acesso global, os catálogos atuam como o mecanismo principal para a separação lógica e a propriedade de dados baseada em domínio.
Cada catálogo normalmente corresponde a uma unidade de negócios (BU), domínio funcional ou limite de projeto. Esse mapeamento dá às equipes autonomia sobre seus dados, mantendo o alinhamento com os padrões de governança. Um design de catálogo bem pensado reduz a complexidade de acesso e ajuda a garantir que você possa escalar com segurança à medida que as necessidades evoluem.
{kind=link}
Uma estratégia de catalogação eficaz reflete os limites do domínio de negócios e os estágios do ciclo de vida do software. Um padrão escalável e amplamente adotado é:
<business unit>_<environment> → finance_dev, sales_stg, datascience_prod
Essa convenção permite:
- Propriedade clara: cada catálogo é mapeado para uma BU ou domínio, gerenciado por uma equipe dedicada
- Isolamento de ambiente: os produtos de dados são desenvolvidos, validados e promovidos por meio de estágios controlados (desenvolvimento → homologação → produção)
- Granularidade de políticas: controles de acesso, criptografia e políticas de retenção podem ser aplicados no nível do catálogo
Com essa estrutura, as equipes podem gerenciar o ciclo de vida completo dos produtos de dados, mantendo os ambientes isolados. Os desenvolvedores podem testar alterações, realizar revisões por pares e promover ativos progressivamente antes do lançamento em produção.
Para organizações com requisitos rigorosos de segurança ou conformidade, o isolamento de ambiente geralmente se estende além dos limites lógicos. Nesses casos, cada ambiente pode ser apoiado por cont�êineres de armazenamento separados, redes na nuvem (VPCs/VNets) ou até mesmo workspaces distintos do Databricks.
Ao alinhar o Unity Catalog para refletir a segmentação de negócios e ambiente, as organizações podem alcançar consistência na governança, otimizar os fluxos de trabalho de aprovação e implantação e escalar suas iniciativas de dados com confiança. Essa abordagem estabelece um equilíbrio entre a autonomia da equipe e a inovação segura, por um lado, e o rigor da governança centralizada e da rastreabilidade, por outro.
Para obter orientação adicional, consulte as Práticas recomendadas do Unity Catalog (AWS | Azure | GCP).
Modelo de governança: propriedade centralizada versus distribuída
Enquanto o design do catálogo define os limites estruturais para domínios e ambientes de dados, o modelo de governança estabelece quem tem autoridade para tomar decisões dentro desses limites. A escolha entre um modelo de governança centralizado e um distribuído (ou federado) molda como as políticas são aplicadas, como as equipes podem se adaptar às mudanças e como as iniciativas de dados são escaladas em toda a organização.
Simplificando, os catálogos definem onde reside a propriedade dos dados, enquanto o modelo de governança define como e quem governa essa propriedade.
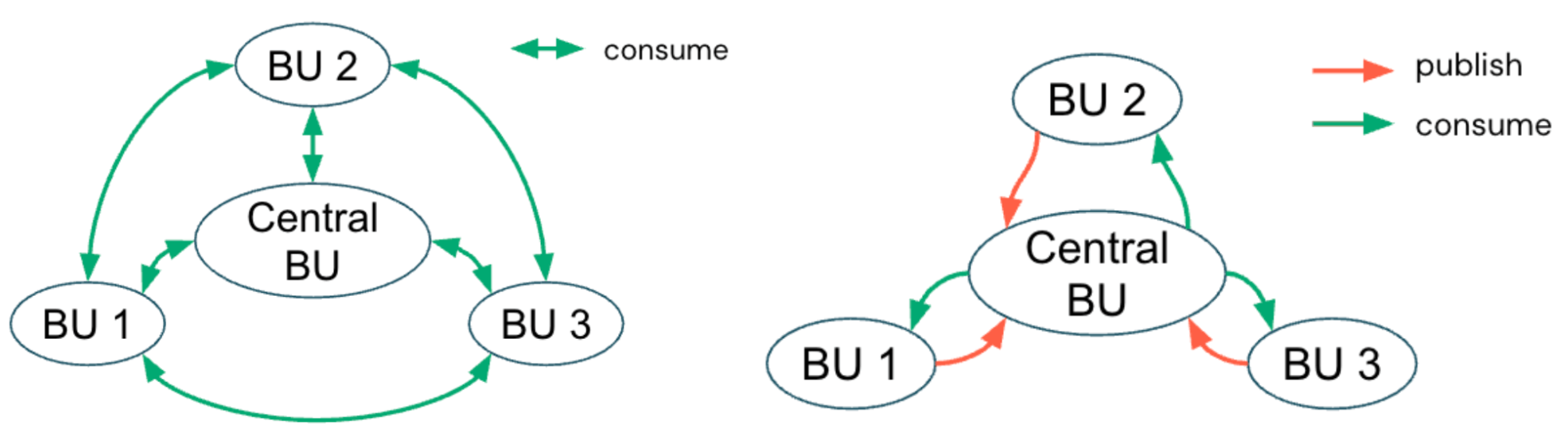
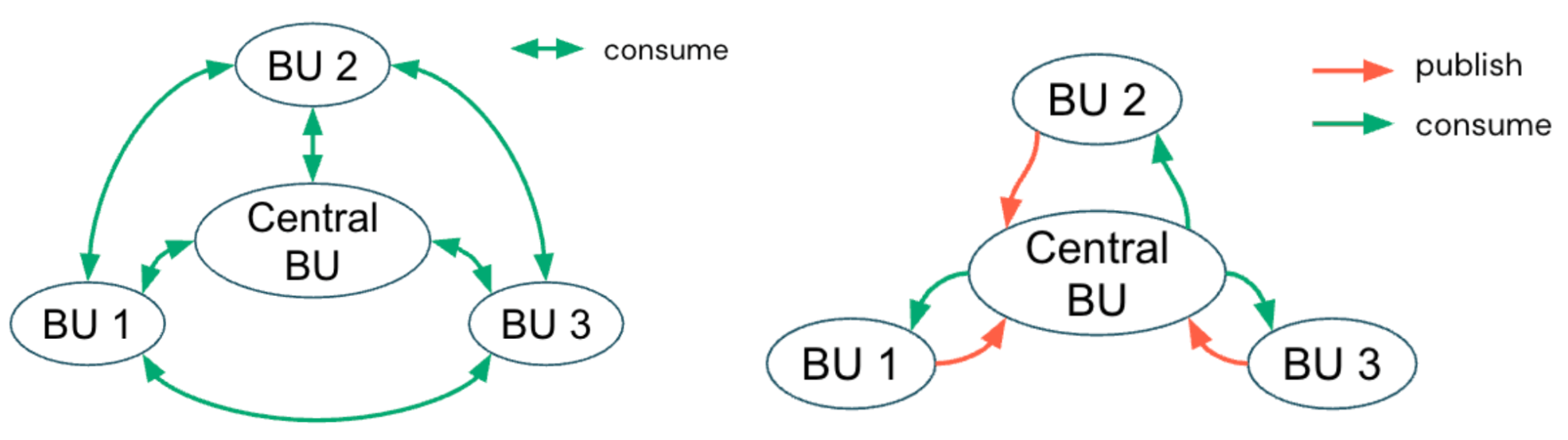{kind=link}
Modelo centralizado
Em um modelo de governança centralizado, uma plataforma dedicada ou uma equipe de governança de dados gerencia o metastore do Unity Catalog e impõe limites de acesso por meio de catálogos. A equipe define os catálogos como contêineres alinhados a BU ou domínio e configura as vinculações de workspace a catálogo para separar o uso de desenvolvimento e produção. Eles também aplicam permissões refinadas nos níveis de catálogo, esquema e tabela.
Essa equipe central também faz a curadoria de conjuntos de dados compartilhados e mantém os padrões de conformidade, qualidade e metadados em todos os domínios, garantindo políticas consistentes em toda a organização. Esse modelo simplifica a conformidade e a auditoria, especialmente para organizações em setores regulamentados ou aquelas com ambientes de dados rigidamente controlados.
Por exemplo, algumas organizações globais de manufatura que adotam um modelo de governança centralizado conseguem otimizar a comunicação entre regiões, aplicar padrões de qualidade consistentes e otimizar os custos operacionais em todas as suas cadeias de suprimentos.
Modelo distribuído
Por outro lado, um modelo de governança distribuído (ou federado) descentraliza o controle ao capacitar BUs individuais a ter propriedade de seus catálogos e produtos de dados de ponta a ponta. Embora uma equipe de plataforma central possa governar a infraestrutura, as barreiras de segurança e a arquitetura compatível, cada equipe de domínio gerencia de forma independente as permissões de seu catálogo, a qualidade dos dados e os fluxos de trabalho de publicação. Esse modelo promove a responsabilidade e a agilidade do domínio, alinhando-se aos princípios de Data Mesh, em que os dados são tratados como um produto e a colaboração ocorre entre equipes autônomas dentro de uma estrutura de governança comum.
Uma abordagem distribuída escala bem à medida que os patrimônios de dados crescem, já que a propriedade é distribuída. Cada equipe é diretamente responsável pela qualidade, linhagem e documentação de seus dados, o que promove uma maior responsabilidade e acelera a entrega de produtos de dados confiáveis para a organização em geral.
Este modelo específico geralmente é adequado para organizações com um portfólio de negócios diversificado que exige conformidade localizada ou operações que abrangem várias regiões com diferentes requisitos regulatórios.
Qual deles devo escolher?
A maioria das organizações considera prático começar com um modelo de governança centralizado usando o Unity Catalog, pois ele oferece políticas consistentes, conformidade simplificada e supervisão unificada de todos os ativos de dados. Um modelo de governança distribuído deve ser considerado por organizações com restrições específicas que tornam a centralização impraticável — como organizações com BUs altamente autônomas, cargas de trabalho de dados especializadas ou requisitos regulatórios que variam entre regiões podem achar a centralização muito rígida.
Em última análise, a escolha depende de fatores como estrutura organizacional, requisitos regulatórios, maturidade dos dados e necessidades de colaboração. Abaixo está um resumo rápido dos pontos fortes e das desvantagens de cada abordagem para ajudar a orientar sua decisão:
| Aspecto | Governança centralizada | Governança distribuída |
|---|---|---|
| Controle e conformidade | O forte controle centralizado simplifica a auditoria e a conformidade regulatória. | Requer barreiras de segurança claras, mas oferece flexibilidade; a equipe central gerencia as barreiras de segurança, não o acesso aos dados. |
| Velocidade e agilidade | Mais lento devido a gargalos de aprovação e fluxos de trabalho centralizados. | Inovação mais rápida, pois as BUs são proprietárias do ciclo de vida dos dados e do gerenciamento de acesso. |
| Propriedade e responsabilidade | A equipe central é responsável pela qualidade dos dados e pela consistência dos metadados. | As equipes de domínio são proprietárias da qualidade dos dados, da documentação e da publicação, promovendo a responsabilidade. |
| Complexidade e escala | Mais fácil de gerenciar inicialmente, mas pode se tornar um gargalo em escala. | Escala bem com data estates em crescimento, mas requer políticas maduras e monitoramento. |
| Colaboração | A colaboração é controlada por meio de vinculações de catálogo ao workspace gerenciadas centralmente. | Colaboração habilitada por políticas compartilhadas; as equipes operam com autonomia dentro dos limites do catálogo. |
| Ideal para | Organizações que têm um grupo central para tomar decisões de governança oficiais. | Organizações com equipes de domínio autônomas que seguem seus próprios processos. |
Independentemente da abordagem, a governança eficaz requer um mapeamento claro da propriedade para os catálogos, controles de acesso robustos e mecanismos para uma colaboração transparente. Isso garante que a segurança e a inovação possam prosperar à medida que seu ambiente do Unity Catalog escala.
Detalhamento da solução técnica
Com a base conceitual de governança e arquitetura estabelecida, o foco muda para os esforços práticos de engenharia envolvidos na migração de seus ativos de dados reais para o UC. Embora as etapas de alto nível (consulte Visão geral das etapas de upgrade [AWS | Azure | GCP]) descrevam o que precisa ser feito, a execução técnica geralmente envolve navegar por dependências complexas, minimizar o tempo de inatividade e acomodar os fluxos de trabalho existentes. As migrações do mundo real raramente seguem um caminho único e, como resultado, as equipes devem adaptar sua abordagem com base em seu data estate atual, restrições operacionais e prioridades de negócios.
Para ajudar a lidar com essas complexidades, as seções a seguir aprofundam três considerações técnicas críticas para organizações de dados modernas: descoberta de dados pré-migração para entender os ativos e as dependências atuais, implantação automatizada usando Infraestrutura como Código (IaC) e estratégias de migração em fases para permitir a adoção incremental.
1. Descoberta de dados pré-migração
Antes de migrar as tabelas do Hive e atualizar as cargas de trabalho, as equipes devem entender seus ambientes de dados existentes. Essa fase de descoberta define o escopo da migração, identifica áreas de risco e ajuda a evitar regressões ou interrupções de serviço.
Isso envolve mapear tabelas, exibições, trabalhos, permissões e equipes ativas no HMS para determinar o que precisa ser convertido para o Unity Catalog. Para grandes organizações com vários workspaces e grandes volumes de dados, o rastreamento manual da propriedade de dados, dos controles de acesso e das dependências de trabalho rapidamente se torna insustentável.
Descoberta de dados com UCX
Para resolver esse problema, o Databricks Labs desenvolveu o UCX (AWS | Azure | GCP), uma ferramenta de código aberto que automatiza a descoberta de dados, a avaliação de prontidão e o planejamento da migração. Uma vez implantado, o UCX verifica os workspaces HMS legados, inventaria os ativos relevantes e gera um relatório detalhado para orientar os esforços de migração. O relatório de avaliação do UCX fornece uma métrica de “prontidão” com base no número total de ativos verificados e categoriza os resultados para ajudar a priorizar a remediação.
Ao analisar a saída do UCX, as organizações devem olhar além das contagens brutas e das pontuações de prontidão para tomar decisões informadas, como:
- Reduzir o escopo da migração identificando e excluindo tabelas obsoletas ou redundantes
- Verificar sinais de atividade, como a hora do último acesso ou a hora da última atualização, para separar as cargas de trabalho críticas dos dados não utilizados
- Racionalizar ativos para consolidar esquemas sobrepostos ou padronizar a nomenclatura antes da migração
- Priorizar dependências onde pipelines downstream, dashboards de BI ou requisitos regulatórios ditam o que deve ser movido primeiro
Por meio desse processo de descoberta automatizado, as organizações ganham valor ao:
- Entender o escopo completo das BUs, equipes e seus produtos de dados
- Mapear controles de acesso e dependências entre usuários, grupos e ativos
- Identificar tabelas e exibições usadas ativamente em comparação com as candidatas a arquivamento
- Priorizar fluxos de trabalho legados críticos enquanto outros são descontinuados
Para organizações que gerenciam de poucos a centenas de workspaces do Databricks, o UCX reduz o esforço de engenharia, automatizando a descoberta e esclarecendo o escopo da migração. Ele minimiza o erro humano e identifica lacunas de compatibilidade e dependências ocultas, garantindo que as cargas de trabalho atendam aos padrões de governança antes da migração.
Para uma introdução ao UCX, consulte Use os utilitários do UCX para atualizar seu workspace para o Unity Catalog (AWS | Azure | GCP).
2. Implantação automatizada com infraestrutura como código (IaC)
Depois que a descoberta de dados fornecer uma imagem abrangente dos ativos, dependências e padrões de acesso existentes, o próximo desafio será provisionar um ambiente do Unity Catalog que os suporte. Embora essa implantação de ambiente possa ser feita manualmente pelo console da conta (com os privilégios de administrador adequados), é altamente recomendável aproveitar o provedor Terraform do Databricks para evitar erros ou inconsistências de configuração manual.
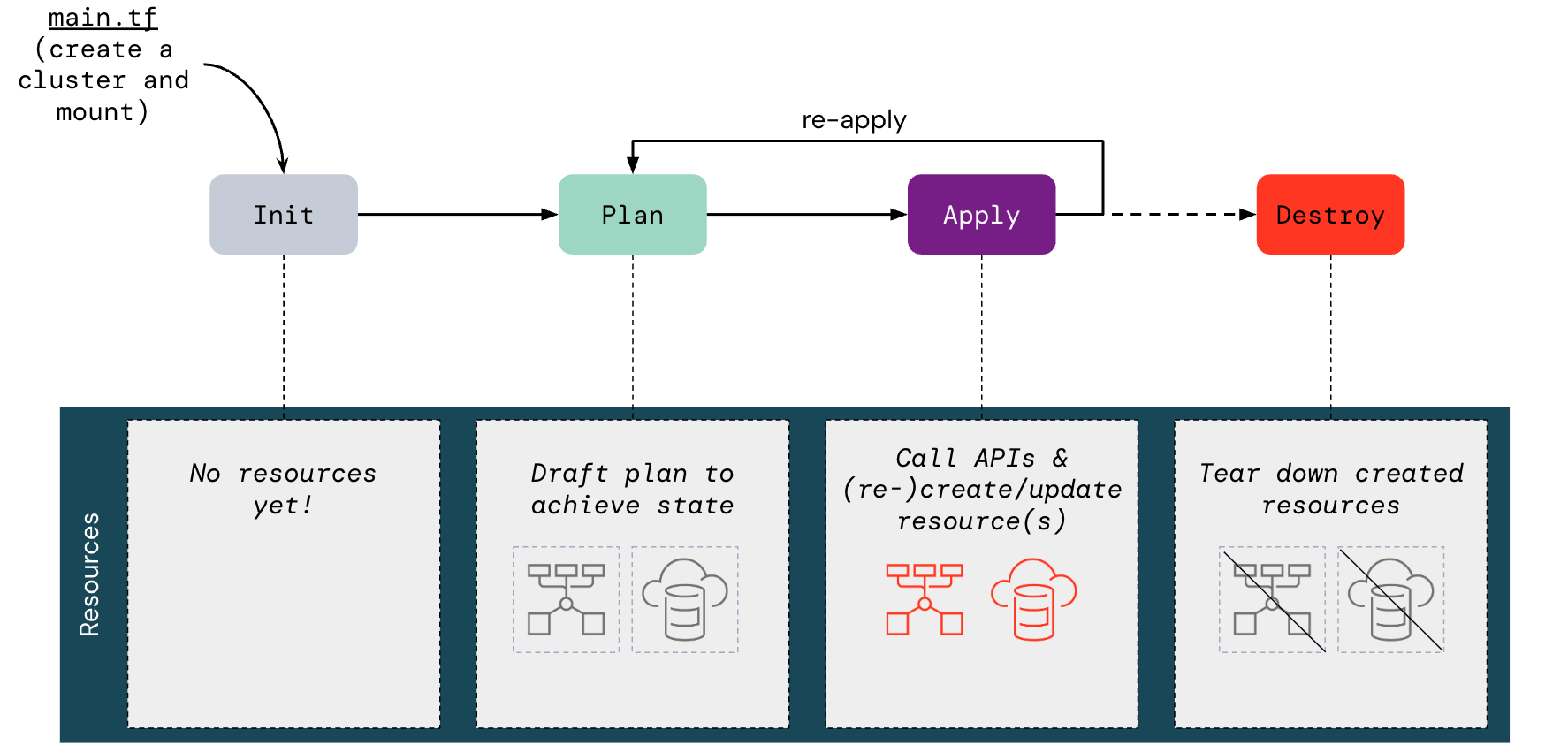
{kind=link}
Usando o Terraform, as equipes podem automatizar a criação e a configuração de recursos do Unity Catalog em qualquer plataforma de nuvem compatível, tornando o processo de migração reproduzível e auditável. Por exemplo, embora um administrador de conta do Databricks possa criar manualmente um metastore do Unity Catalog (AWS | Azure | GCP) pelo console da conta, essa pessoa também poderia usar o Terraform provisionando programaticamente o recurso databricks_metastore. Da mesma forma, eles poderiam usá-lo para definir catálogos e esquemas no metastore, aplicar configurações de armazenamento gerenciado e definir privilégios de acesso. Usando essa abordagem mais robusta de IaC, toda a configuração do Unity Catalog pode ser totalmente automatizada com alguns scripts (por exemplo, Terraform + APIs REST) e modelada para ser replicada em todas as BUs da organização, permitindo o provisionamento manual zero.
Para obter o guia completo de como criar seu módulo Terraform personalizado para implantação, consulte Automatizar a configuração do Unity Catalog usando o Terraform (AWS | Azure | GCP).
Nas migrações do Unity Catalog, essa abordagem provou ser especialmente poderosa na criação da infraestrutura necessária para que as equipes possam:
- Garantir que os padrões de governança sejam aplicados de forma consistente em todos os ambientes
- Minimizar o risco de configuração incorreta durante a migração
- Habilitar a entrega contínua da infraestrutura de governança para expansão futura
3. Estratégias de migração
Com um inventário completo de ativos do HMS e workspaces habilitados para o Unity Catalog provisionados via IaC, o foco muda da configuração para a migração controlada e de baixo risco da carga de trabalho. As organizações podem escolher uma estratégia alinhada à sua complexidade, estrutura e tolerância a riscos, que vai desde projetos-piloto simples até transformações em toda a empresa.
Embora a maioria das organizações se beneficie de começar com uma abordagem de adoção incremental, a expansão para além dos projetos-piloto iniciais requer um planejamento cuidadoso e uma execução estruturada. As organizações que planejam e executam uma migração abrangente do Unity Catalog podem entrar em contato com a equipe da conta Databricks e/ou com o Delivery Solutions Architect (DSA) para obter assistência na migração e acesso a metodologias de migração especializadas.
Adoção incremental com uma abordagem piloto
Para a maioria dos ambientes de produção, uma migração “big-bang” raramente é prática. Em vez disso, o Databricks recomenda começar com uma migração piloto: uma BU ou equipe representativa cujas cargas de trabalho espelham padrões organizacionais comuns, têm limites de dados claros e incluem stakeholders engajados. Essa fase piloto valida ferramentas, processos e controles de governança em um ambiente controlado, ajudando as equipes a descobrir casos extremos, refinar o sequenciamento da implantação e melhorar as estimativas de esforço. Os insights obtidos reduzem a incerteza e o risco para migrações subsequentes.
A partir daí, as organizações podem escalar para a adoção total em fases, mantendo a estabilidade da plataforma, aumentando a confiança dos stakeholders e permitindo um progresso previsível — vantagens difíceis de alcançar com um lift-and-shift completo.
O Databricks recomenda duas abordagens incrementais diferentes para mover cargas de trabalho do HMS para o Unity Catalog.
Opção A: Migração pipeline a pipeline
Essa abordagem envolve a migração de um pipeline por vez, abrangendo suas tabelas, trabalhos, dashboards e dependências associados, para o Unity Catalog antes de prosseguir para o próximo pipeline. Ao encapsular toda a linhagem de dados e o caminho consumidor-produtor de um único pipeline, esse método localiza o risco e aproveita as lições aprendidas para migrações subsequentes. As equipes se beneficiam da oportunidade de testar, validar e ajustar cada transição para o Unity Catalog isoladamente, resultando em melhoria contínua e redução da interrupção em toda a plataforma.
Opção B: Migração camada por camada (Gold �→ Silver → Bronze)
A estratégia camada por camada, enraizada na arquitetura medalhão, recomenda o avanço da migração do Unity Catalog por meio de camadas distintas — Gold (resultados analíticos voltados para o usuário), Silver (conjuntos de dados limpos e com dados duplicados removidos) e Bronze (dados brutos ingeridos). Ao contrário da tradição bottom-up em algumas práticas de engenharia de dados, o Databricks geralmente recomenda começar com a camada Gold, que inclui dashboards, ativos de BI e tabelas de alta visibilidade. Isso reduz o impacto nos negócios e evita interrupções downstream de alterações em camadas inferiores, enquanto mantém a continuidade para os consumidores de análise.
Sequência de migração para a opção B:
- Primeiro a camada Gold: migre primeiro as tabelas gold para o Unity Catalog e, em seguida, realinhe dashboards críticos, ferramentas de BI e consultas ad hoc para apontar para suas substituições no Unity Catalog. Esses ativos são frequentemente os mais visíveis e, quando migrados primeiro, minimizam o risco para as operações de negócios.
- Em seguida, a camada Silver: com os consumidores gold validados no Unity Catalog, atualize os trabalhos de transformação e as tabelas que os fornecem — normalmente a camada silver. Esta etapa abrange processos mais amplos de limpeza e conformidade de dados.
- Por último, a camada Bronze: conclua o ciclo migrando trabalhos de ingestão externa e tabelas de aterrissagem brutas para o Unity Catalog. Depois que a ingestão upstream for unificada, a linhagem de toda a pilha de dados será colocada sob a governança do Unity Catalog.
O Databricks aconselha aumentar as estratégias de migração acima com práticas operacionais disciplinadas. Por exemplo, anote tabelas legadas do HMS referenciando suas contrapartes do Unity Catalog para ajudar os usuários a fazer a transição sem problemas e evitar confusão. Antes de desativar quaisquer tabelas ou trabalhos legados, teste rigorosamente todas as dependências downstream no Unity Catalog para garantir fluxos de trabalho ininterruptos. Além disso, a comunicação consistente deve ser mantida, e a coordenação deve ser gerenciada com os stakeholders ao atualizar os controles de acesso do workspace ou reatribuir funções para ativos agora governados pelo Unity Catalog.
A próxima seção compara dois caminhos de migração comuns (soft versus hard) que complementam a abordagem incremental.
Caminhos de migração: “Soft” versus “Hard”
Dentro do nosso framework definido, existem dois padrões de migração distintos: a migração soft por meio da federação do HMS, que permite o acesso aos recursos avançados de governança do Unity Catalog em ativos federados, mantendo o HMS intacto (evitando a interrupção da carga de trabalho legada), e a migração hard, que envolve a transferência completa de metadados e dados do HMS para o Unity Catalog, mas requer um planejamento e uma coordenação mais extensos entre equipes e sistemas.
Migração soft via federação do HMS
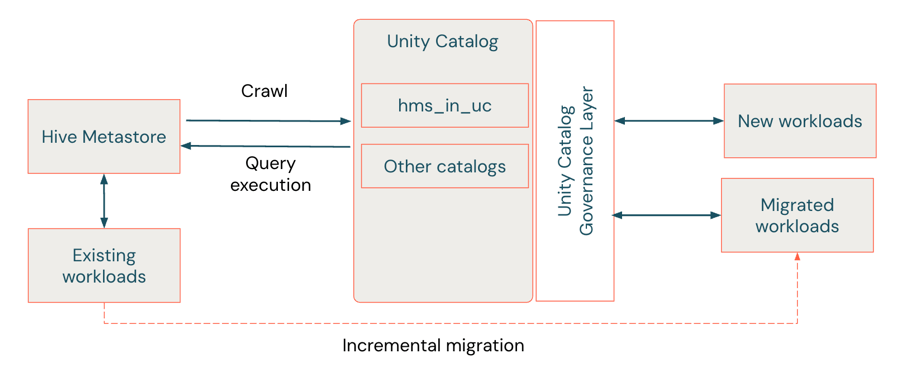
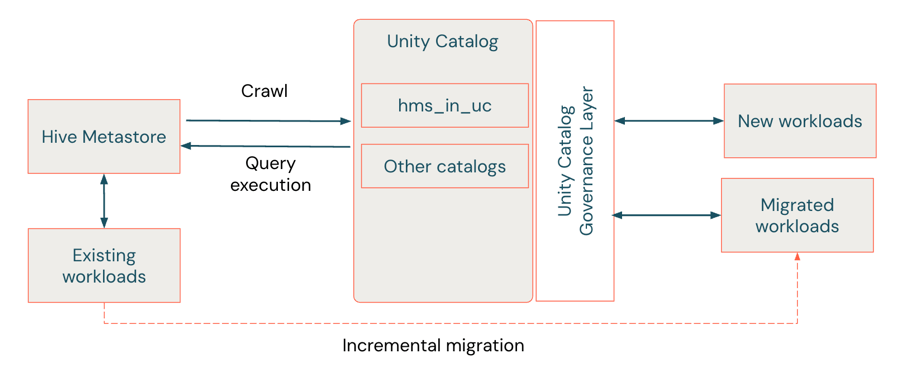{kind=link}
A migração soft é considerada uma abordagem híbrida que atua como uma “ponte de migração”, permitindo que as equipes adotem os recursos de governança do Unity Catalog enquanto mantêm o HMS legado intacto. A federação do metastore do Hive (AWS | Azure | GCP) permite a migração incremental com interrupção mínima — não são necessárias movimentações de dados ou alterações de código imediatas. O Unity Catalog cria um catálogo estrangeiro que espelha os metadados do HMS, permitindo que as cargas de trabalho sejam executadas em ambos os sistemas. Dessa forma, as tabelas estrangeiras neste HMS federado fornecem uma forma de compatibilidade retroativa, permitindo que as cargas de trabalho continuem a usar a semântica exclusiva do Hive — o namespace legado de dois níveis (schema.table). Isso permite que eles se beneficiem da governança, da auditoria e dos controles de acesso do Unity Catalog enquanto mantêm a compatibilidade com o namespace de três níveis (catalog.schema.table).
A forma como você gerencia e interage com os dados federados no Unity Catalog depende se o seu HMS é interno ou externo. Os conectores de federação suportam acesso de leitura e escrita para tabelas em instâncias HMS internas dentro de workspaces do Databricks, enquanto as tabelas externas do HMS e do AWS Glue são somente de leitura. Em todos os casos, você pode montar catálogos HMS inteiros (internos ou externos) ou AWS Glue como catálogos externos no Unity Catalog, onde eles aparecem como objetos nativos. Os metadados da tabela são sincronizados automaticamente com o HMS à medida que as alterações ocorrem. Para o HMS interno, quaisquer novas tabelas ou atualizações feitas no catálogo estrangeiro são gravadas de volta no HMS, mantendo a interoperabilidade perfeita entre os dois ambientes.
Embora a migração suave via federação do HMS ofereça um caminho de baixa interrupção para adotar o Unity Catalog, as organizações que pretendem desativar totalmente o HMS devem, eventualmente, realizar uma migração definitiva dos ativos federados. Embora seja possível automatizar a migração definitiva de ativos federados, o código que lê e/ou grava nesses ativos precisará ser apontado para o novo ativo do Unity Catalog.
Além disso, o UCX oferece ferramentas de CLI para habilitar a federação do HMS (como uma alternativa ao processo de migração de tabelas):
Para obter instruções sobre como configurar a federação do HMS para um HMS de workspace legado, um HMS externo ou um metastore do AWS Glue, consulte Como usar a federação do Hive metastore durante a migração para o Unity Catalog? (AWS | Azure | GCP).
Migração definitiva
Uma migração definitiva é um upgrade completo do HMS para o Unity Catalog, convertendo os metadados (e dados para tabelas gerenciadas) das tabelas para o novo metastore. Essa abordagem combina ferramentas como o SYNC (ou o Assistente de Upgrade) para tabelas externas e o CREATE TABLE CLONE (CTAS) para tabelas gerenciadas. Cada método tem seu próprio conjunto de requisitos e limitações.
Para organizações com grandes volumes de dados no HMS que precisam ser migrados, o Databricks recomenda os fluxos de trabalho de migração de tabelas automatizados do UCX (em vez dos métodos manuais listados abaixo) para a maioria dos cenários de migração de tabelas. Consulte Migrar objetos de dados do Hive metastore para determinar qual fluxo de trabalho do UCX executar e obter mais contexto para a migração de tabelas.
Fazer upgrade de tabelas externas
O upgrade de tabelas externas pode ser feito com o comando SYNC ou o Assistente de Upgrade. Eles executam operações somente de metadados — nenhum dado é copiado ou movido.
- SYNC: um comando SQL que transfere os metadados da tabela do HMS para o Unity Catalog e adiciona propriedades de controle de volta à tabela do HMS. Ele pode ser aplicado no nível da tabela ou do esquema, dando às equipes que priorizam o SQL um controle granular sobre o que migrar e quando.
- Assistente de Upgrade: uma interface do Catalog Explorer que encapsula a funcionalidade do SYNC em um fluxo de trabalho visual. É ideal para migrações de esquemas em massa, em que a simplicidade de apontar e clicar acelera a adoção.
Como as tabelas do HMS e do Unity Catalog fazem referência ao mesmo armazenamento em nuvem, as configurações híbridas podem ser executadas durante a transição. Os SYNCs agendados mantêm os metadados alinhados em ambos os sistemas até que a migração seja concluída.
Fazer upgrade de tabelas gerenciadas
As tabelas gerenciadas exigem movimentação de dados porque residem em um local de armazenamento gerenciado (consulte O que é um local de armazenamento gerenciado? [AWS | Azure | GCP]). Como resultado, o upgrade delas deve ser feito com o CREATE TABLE CLONE ou o CREATE TABLE AS SELECT (CTAS).
- CREATE TABLE CLONE (Deep Clone): este método copia dados e metadados diretamente para a camada de armazenamento. Ele preserva automaticamente o particionamento, o formato, os invariantes, a nulidade e outros metadados. Ele também é executado mais rápido que o CTAS porque evita um ciclo de leitura/gravação de computação intensiva.
- CREATE TABLE AS SELECT (CTAS): útil quando as tabelas gerenciadas do Hive não atendem aos requisitos de clonagem (por exemplo, formato Delta). O CTAS recria tabelas a partir de resultados de consulta, permitindo migração seletiva ou transformações durante o processo.
O CLONE é altamente recomendado para migrações de tabelas gerenciadas, enquanto o CTAS oferece flexibilidade quando as tabelas de origem exigem ajustes.
Fazer upgrade de views
As visualizações devem ser recriadas manualmente assim que todas as tabelas referenciadas forem migradas. Use as instruções CREATE VIEW que fazem referência às versões do Unity Catalog das tabelas, seguindo o namespace de três níveis (catalogo.esquema.tabela).
Para obter mais detalhes sobre as várias opções para migrar tabelas e visualizações, consulte Atualizar tabelas e visualizações do Hive para o Unity Catalog (AWS | Azure | GCP).
Desativando o acesso ao HMS
Depois que todos os ativos do HMS forem migrados para o Unity Catalog ou o HMS for federado como um catálogo federado no Unity Catalog, é essencial desativar o acesso direto ao HMS legado para garantir a adoção em toda a organização da governança de dados centralizada. Esta etapa garante que consultas, cargas de trabalho e descoberta de dados futuras estejam sujeitas exclusivamente aos controles de acesso do Unity Catalog, eliminando a necessidade de estruturas de governança paralelas e impedindo o uso não autorizado.
O Databricks recomenda desativar o acesso direto ao HMS para todos os clusters e cargas de trabalho de uma só vez para aplicar uma governança uniforme e encerrar possíveis rotas de desvio. Para organizações que preferem uma implementação em fases, a aplicação também pode ser feita em cada cluster de computação individualmente, definindo uma configuração do Spark, o que permite uma implementação incremental conforme necessário (consulte Desativar o acesso ao metastore do Hive usado pelo seu workspace do Databricks [AWS | Azure | GCP]).
Para entender as ramificações de desativar o metastore legado, consulte O que acontece quando você desativa o metastore legado? (AWS | Azure | GCP).
Exemplo do mundo real
Um varejista global que usa o Databricks operando em grande escala — gerenciando milhares de tabelas e notebooks — enfrentou desafios significativos na governança de dados e na colaboração multifuncional. Os dados estavam isolados em vários ambientes de armazenamento legados, complicando o gerenciamento de permissões, obscurecendo a visibilidade de acesso e dificultando a execução de análises em toda a empresa. As BUs muitas vezes não confiavam nos dados, e a visibilidade limitada dos ativos tornava o escopo inicial da migração especialmente assustador.
Guiada pelos princípios fundamentais descritos neste blog, a organização começou definindo sua arquitetura de destino: um Data Mesh federado projetado para equilibrar a governança centralizada com a autonomia no nível do domínio (“Modelo de governança: propriedade centralizada versus distribuída”). Usando o kit de ferramentas de migração UCX do Databricks Labs, eles realizaram um inventário completo de ativos, identificando cargas de trabalho inativas ou que não estavam em execução em computação compatível com o Unity Catalog (“1. Descoberta de dados pré-migração”). Essa percepção permitiu que eles priorizassem casos de uso de negócios de alto valor, adotassem uma abordagem de migração piloto e em escala e sequenciassem os fluxos de trabalho com base nas dependências e no impacto downstream (“3. Estratégias de migração”). A migração foi executada em fases, empregando o SYNC para tabelas externas e o DEEP CLONE para tabelas gerenciadas. Na ausência da federação do HMS, que não estava disponível na época, eles implementaram uma estratégia de sincronização bidirecional para permitir a migração incremental com o mínimo de interrupção operacional (“Migração suave via federação do HMS”).
Após a migração, a organização estabeleceu uma governança centralizada por meio do Unity Catalog, mantendo uma arquitetura federada que capacitou os domínios de negócios a gerenciar seus próprios dados e análises. As capacidades integradas de auditoria e linhagem de dados aumentaram a transparência e a confiança, enquanto o descomissionamento de código e padrões legados reduziu a dívida técnica e otimizou as operações. Ao abstrair o armazenamento físico e simplificar o acesso, a organização promoveu uma cultura em que as equipes de negócios podiam descobrir, acessar e analisar dados confiáveis, avançando em sua transformação para um negócio mais orientado a dados e IA.
Principais conclusões
- A governança escalonável é essencial: À medida que as organizações orientadas por dados crescem, os metastores legados como o HMS têm dificuldades para dar suporte às necessidades modernas de governança. O Unity Catalog oferece governança unificada com controles de acesso refinados, rastreamento de linhagem e suporte a múltiplos workspaces, que são essenciais para manter a confiança e a conformidade em ambientes complexos de análise e IA.
- Arquitetura de governança modular: o Unity Catalog oferece suporte à governança centralizada e distribuída (federada). Modelos centralizados simplificam a conformidade e a auditoria para setores regulamentados, enquanto modelos distribuídos concedem às BUs a propriedade sobre seus dados, acelerando a inovação sem sacrificar as proteções.
- O design do metastore e do catálogo é importante: Um design cuidadoso do metastore e do catálogo forma a base para uma governança escalonável. Uma estratégia de metastore único com isolamento baseado em catálogo (combinada com convenções de nomenclatura consistentes e limites de armazenamento) simplifica as permissões, promove a autonomia e permite a colaboração segura.
- Migração automatizada e consciente dos riscos: A combinação da descoberta pré-migração com a infraestrutura como código (IaC) garante uma configuração consistente do Unity Catalog, reduz os erros manuais e acelera a implantação. A adoção incremental, começando com um piloto representativo, minimiza a interrupção enquanto gera confiança e a adesão das partes interessadas.
- Caminhos de migração flexíveis: A migração suave via federação do HMS permite a adoção em fases da governança do Unity Catalog sem alterações imediatas no código, enquanto a migração total oferece todos os benefícios do Unity Catalog e facilita a desativação completa do HMS. A escolha do caminho certo depende da tolerância ao risco operacional, das dependências e dos objetivos de modernização.
Conclusão
A migração do Hive Metastore para o Unity Catalog é uma etapa fundamental e necessária para as empresas que buscam governança unificada e escalável e operações de dados otimizadas para desbloquear a verdadeira inteligência de dados. O sucesso depende do alinhamento dos modelos de governança com as prioridades organizacionais — seja o controle centralizado para conformidade ou a propriedade distribuída para agilidade no nível da equipe. Ao combinar implantação automatizada, descoberta completa pré-migração e adoção em fases, as organizações podem minimizar interrupções, garantindo a continuidade de cargas de trabalho de missão crítica. A arquitetura flexível e modular do Unity Catalog permite colaboração segura, análise self-service e conformidade abrangente, estabelecendo uma base para a transformação digital sustentada e vantagem competitiva orientada a dados.
Próximas etapas & Recursos
Para iniciar uma migração para o Unity Catalog de forma eficaz, aplique as estratégias descritas acima e consulte a documentação oficial do Databricks para obter orientações detalhadas e atualizadas.
Rastreador de migração do Unity Catalog
Este rastreador oferece um modelo estruturado para gerenciar sua migração para o Unity Catalog, com links integrados para documentação e ferramentas e campos de status para acompanhar os marcos à medida que são concluídos.
Rastreador de migração: Github
Primeiros passos com o Unity Catalog
Para criar uma base de conhecimento sobre o Unity Catalog, aproveite os seguintes cursos interativos e individualizados da Databricks Academy (requer login com sua conta Databricks ou e-mail):
- Introdução ao Unity Catalog
- Administração de dados no Databricks
- Controle de acesso a dados no Unity Catalog
- Recursos de computação & Unity Catalog
- Padrões & Melhores práticas do Unity Catalog
Aprendendo com cenários do mundo real
Obtenha insights práticos de histórias de sucesso de clientes e sessões técnicas aprofundadas apresentadas no Data + AI Summit 2025:
- Liderado pelo Databricks:
- Mergulho profundo no Unity Catalog: guia do profissional para melhores práticas e padrões - Data + AI Summit 2025 | Databricks
- Atualizações do Unity Catalog simplificadas. Guia passo a passo para o Databricks Labs UCX - Data + AI Summit 2025
- Desmistificando a atualização para o Unity Catalog — Desafios, design e execução - Data + AI Summit 2025 | Databricks (com a Celebal Technologies)
- Histórias de clientes:
- A transformação do Schiphol Group para o Unity Catalog - Data + AI Summit 2025 | Databricks (Schiphol Group e Databricks)
- História de uma migração para o Unity Catalog (UC): usando o UCX na 7-Eleven para reorientar uma migração complexa para o UC - Data + AI Summit 2025 | Databricks (7-Eleven e Databricks)
- Desbloqueando o potencial empresarial: principais insights da implantação do Unity Catalog em escala pela P&G - Data + AI Summit 2025 | Databricks (P&G)
DSA: orientação especializada em migração
Os Delivery Solutions Architects (DSAs) do Databricks desempenham um papel fundamental na orientação de organizações durante as migrações para o Unity Catalog. Atuando como consultores estratégicos, os DSAs dão suporte ao design de planos de execução exclusivos para a organização, alinham os esforços de migração com as metas de negócios e ajudam a identificar riscos potenciais antes que eles afetem a entrega. Ao colaborar de perto com equipes de engenharia de dados, proprietários de plataformas e partes interessadas executivas, os DSAs garantem que cada estágio da migração, desde a definição do escopo e a avaliação do workspace até a implantação e a validação, seja centrado em soluções personalizadas e em um tempo de retorno mais rápido. Para explorar como um DSA pode dar suporte à sua jornada de migração para o Unity Catalog com planejamento personalizado e supervisão especializada, entre em contato com sua equipe de contas do Databricks.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.