A forma mais rápida de federar dados SAP HANA em tempo real no Databricks usando Spark JDBC
O recente anúncio da SAP de uma parceria estratégica com a Databricks gerou grande entusiasmo entre os clientes SAP. A Databricks, especialista em dados e IA, apresenta uma oportunidade atraente para alavancar capacidades de análise e ML/IA integrando o SAP HANA com a Databricks. Dado o imenso interesse nessa colaboração, estamos entusiasmados em iniciar uma série de posts aprofundados.
Em muitos cenários de clientes, um sistema SAP HANA serve como a entidade principal para a base de dados de vários sistemas de origem, incluindo SAP CRM, SAP ERP/ECC, SAP BW. Agora, surge a empolgante possibilidade de integrar perfeitamente este robusto sistema auxiliar analítico SAP HANA com a Databricks, aprimorando ainda mais as capacidades de dados da organização. Ao conectar o SAP HANA (com licença HANA Enterprise Edition) com a Databricks, as empresas podem aproveitar as capacidades avançadas de análise e machine learning (como MLflow, AutoML, MLOps) da Databricks, ao mesmo tempo em que utilizam os dados ricos e consolidados armazenados no SAP HANA. Essa integração abre um mundo de possibilidades para as organizações extraírem insights valiosos e impulsionarem a tomada de decisões baseada em dados em seus sistemas SAP.
Existem várias abordagens disponíveis para federar tabelas, visualizações SQL e visualizações de cálculo do SAP HANA na Databricks. No entanto, a maneira mais rápida é usar o SparkJDBC. A vantagem mais significativa é que o SparkJDBC suporta conexões JDBC paralelas dos nós de trabalho do Spark ao endpoint HANA remoto.
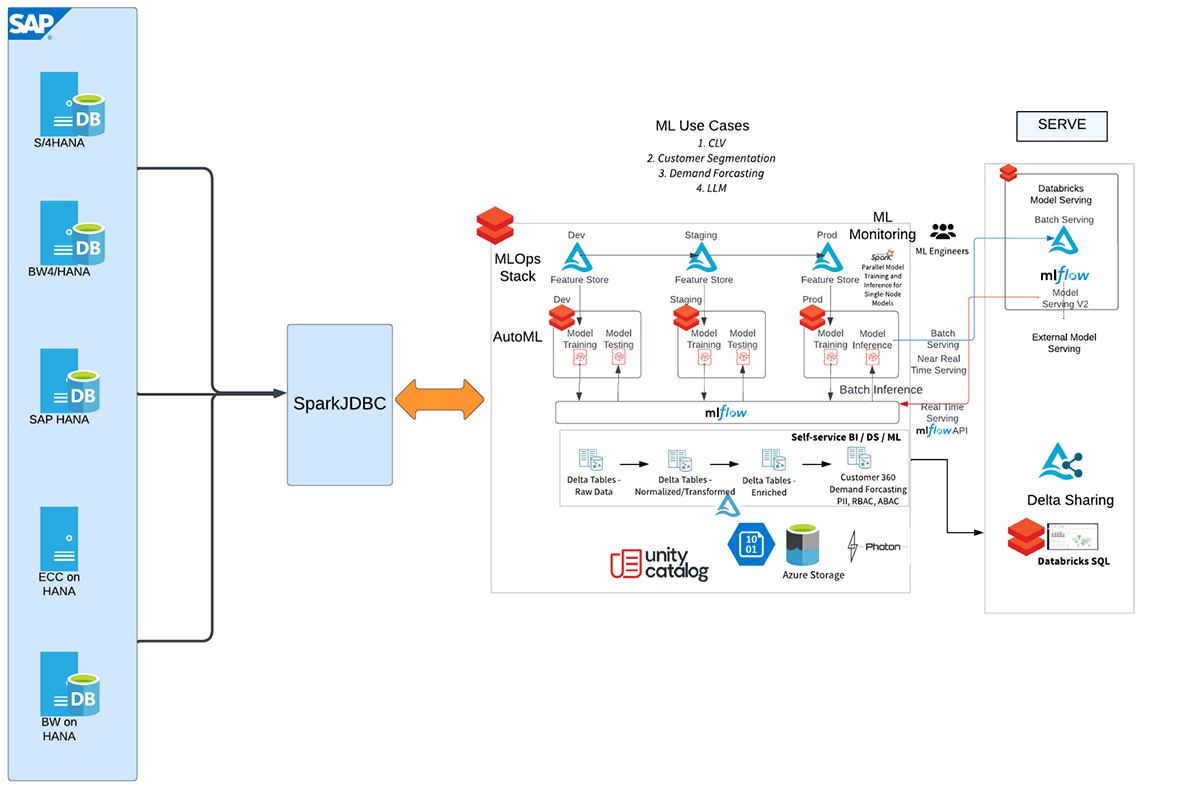
Vamos começar com a integração SAP HANA e Databricks
Primeiro, o SAP HANA 2.0 foi instalado na nuvem Azure e testamos a integração com a Databricks.
Informações do SAP HANA instalado no Azure:
| versão | 2.00.061.00.1644229038 |
| branch | fa/hana2sp06 |
| Sistema Operacional | SUSE Linux Enterprise Server 15 SP1 |
Aqui está o fluxo de trabalho de alto nível descrevendo as diferentes etapas desta integração.
Consulte o notebook anexado para obter instruções mais detalhadas para extrair dados das visualizações de cálculo e tabelas do SAP HANA para a Databricks usando SparkJDBC.

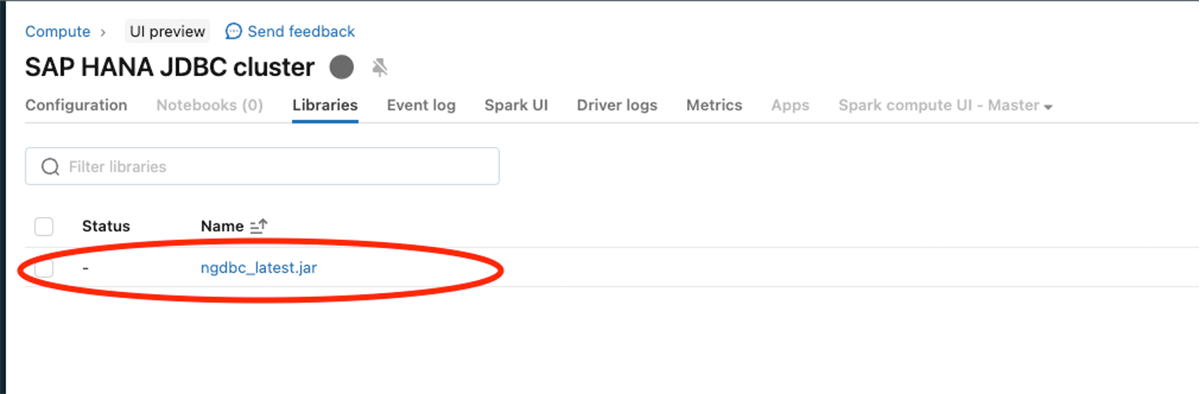
Configure o JAR JDBC do SAP HANA (ngdbc.jar) conforme mostrado na imagem abaixo
Após a realização das etapas acima, execute uma leitura spark usando o servidor SAP HANA e a porta JDBC.
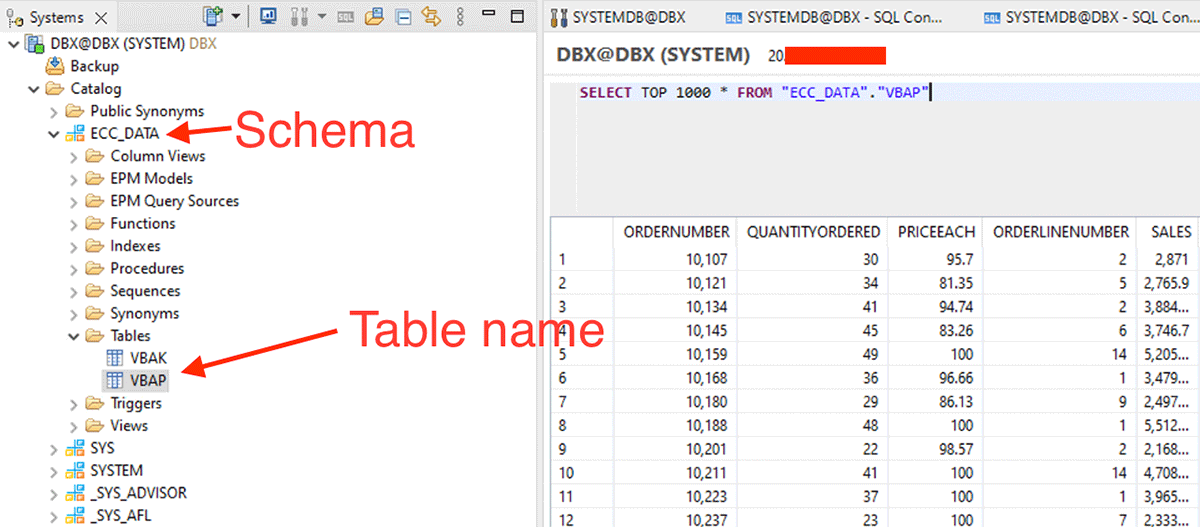
Comece a criar os dataframes usando o mostrado abaixo com esquema e nome da tabela.
Além disso, podemos fazer um filtro pushdown passando instruções SQL na opção dbtable.
Para obter dados da Visualização de Cálculo, precisamos fazer o seguinte:
Por exemplo, esta visualização de cálculo XS-classic foi criada no esquema interno "_SYS_BIC".
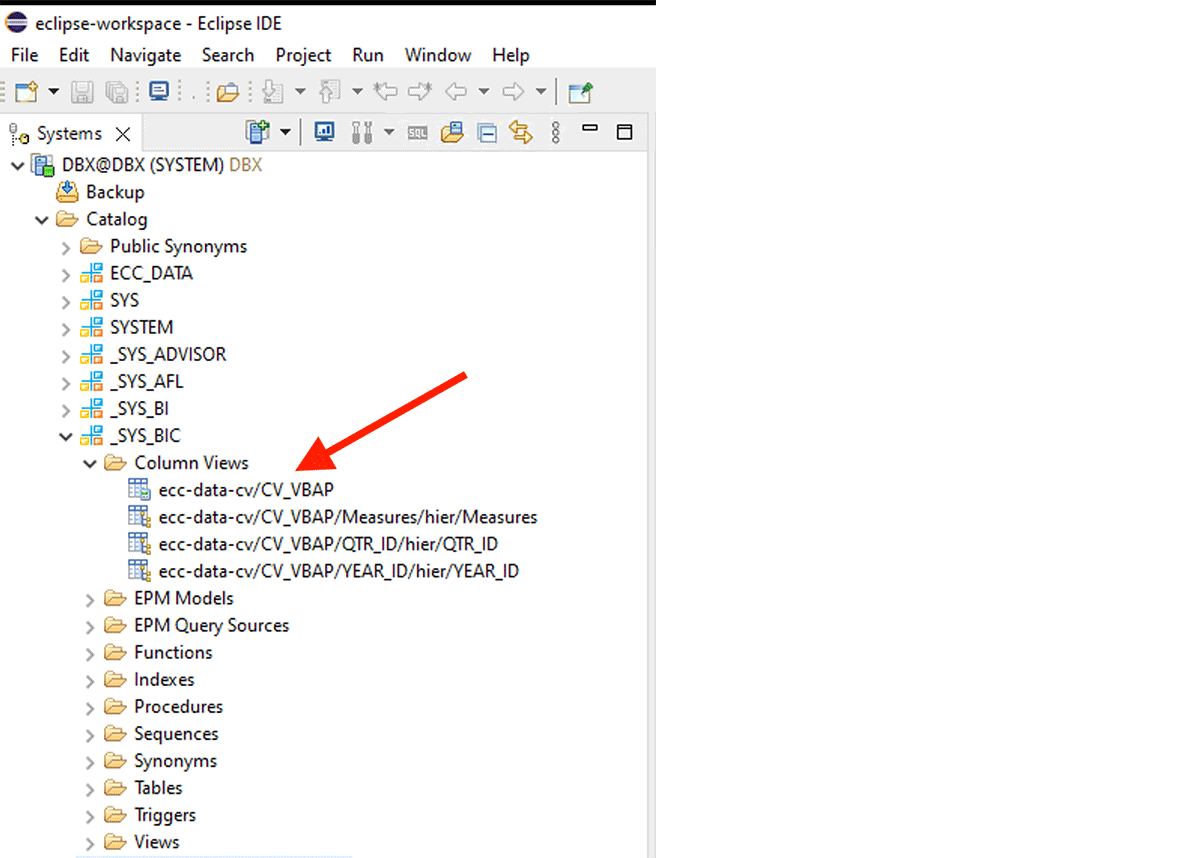
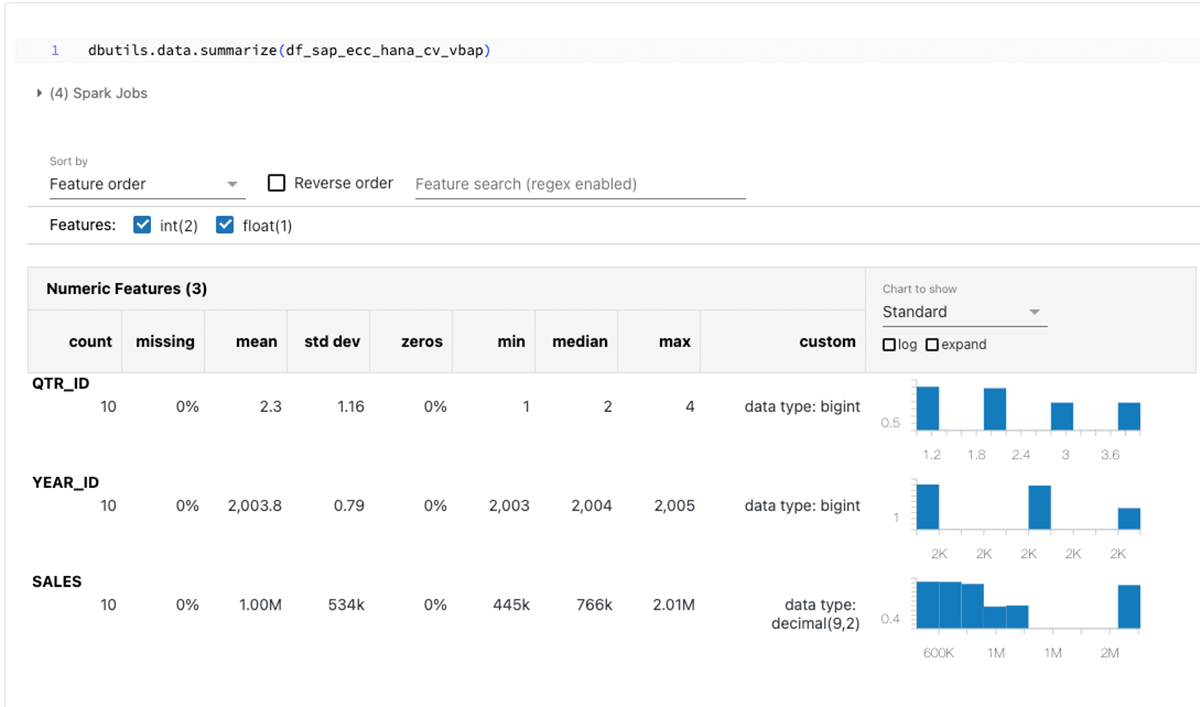
Este trecho de código cria um dataframe PySpark chamado "df_sap_ecc_hana_cv_vbap" e o popula a partir de uma Visualização de Cálculo do sistema SAP HANA (neste caso, CV_VBAP).
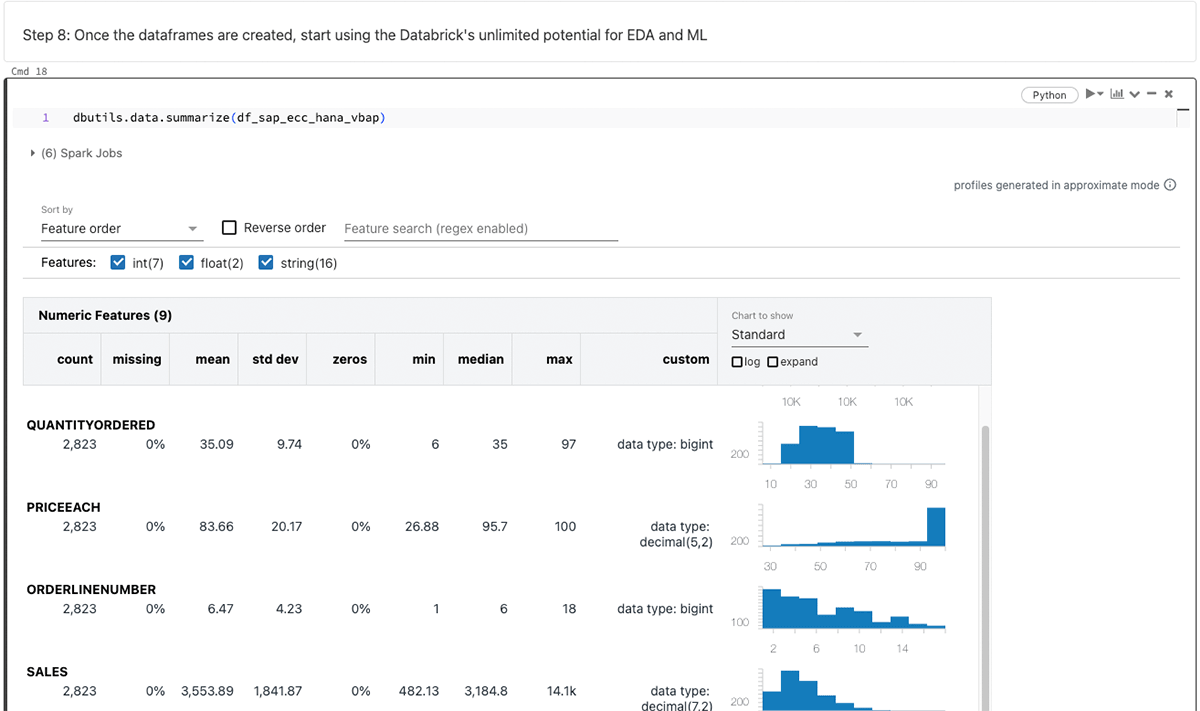
Após gerar o dataframe PySpark, aproveite as infinitas capacidades da Databricks para análise exploratória de dados (EDA) e machine learning/inteligência artificial (ML/IA).
Resumindo os dataframes acima:
O foco deste post gira em torno do SparkJDBC para SAP HANA, mas vale notar que métodos alternativos como FedML, hdbcli e hana_ml estão disponíveis para fins semelhantes.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.