Tipos de nós flexíveis agora estão em disponibilidade geral
Melhore a confiabilidade da inicialização de clusters e reduza os custos de compute com o fallback automático de instâncias
por Kelsey Ge, Andrew Bagshaw, Tianyi Zhang, Vedaant Shah, Rishan Girish e Hugh March
- Proteja as cargas de trabalho contra erros de capacidade: Quando seu tipo de VM preferencial não está disponível, o Databricks recorre automaticamente a alternativas compatíveis para que os clusters ainda possam iniciar.
- Obtenha flexibilidade no estilo Fleet em qualquer nuvem: os tipos de nós flexíveis trazem fallback automático de tipo de instância para Azure, GCP e AWS. Aproveite uma ativação mais simples, de "1 clique", para todo o workspace, com visibilidade clara dos recursos adquiridos e ordem de fallback opcionalmente configurável.
- Reduza os gastos sem sacrificar a confiabilidade: priorize instâncias Spot com desconto quando disponíveis e recorra ao fallback somente quando necessário para manter o sucesso da inicialização.
Garantir capacidade de computação específica pode ser desafiador, especialmente durante períodos de alto tráfego (e alta pressão). Engenheiros de dados e administradores de plataforma conhecem bem a frustração da capacidade insuficiente, ou erros de "stockout", que ocorrem quando a inicialização de um cluster falha porque um provedor de nuvem não consegue atender a uma solicitação de um tipo de instância específico.
Por exemplo:
AWS_INSUFFICIENT_INSTANCE_CAPACITY_FAILURECLOUD_PROVIDER_RESOURCE_STOCKOUTno Azure, ouGCP_INSUFFICIENT_CAPACITY,
Esses erros interrompem workloads críticos, especialmente durante períodos críticos para os negócios, quando o tempo de atividade é mais importante.
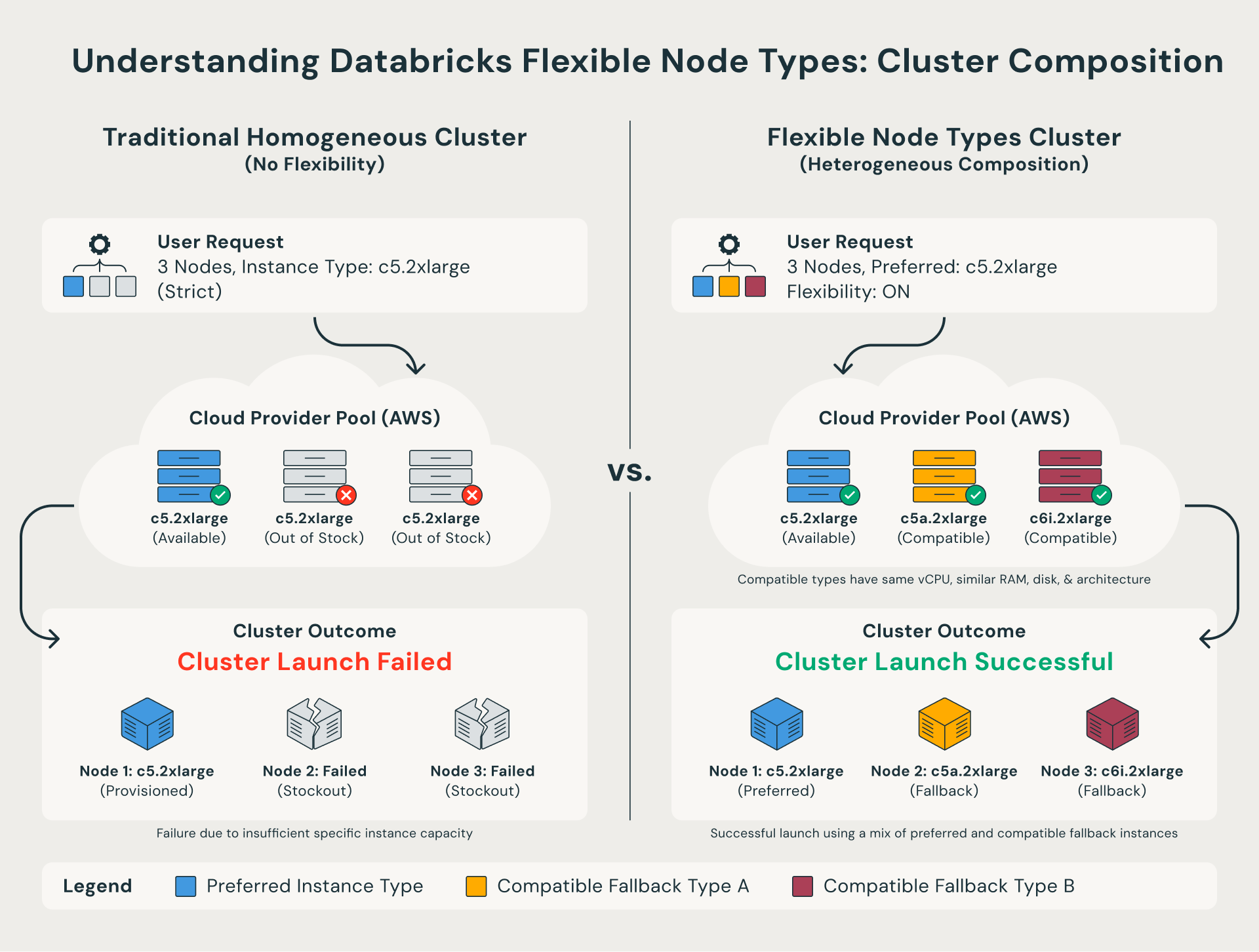
O que são Tipos de Nós Flexíveis?
Tradicionalmente, os clusters do Databricks exigiam que cada nó fosse do tipo de instância exato especificado na sua configuração. Se esse tipo específico não estivesse disponível, o lançamento do cluster falharia.
Os tipos de nós flexíveis removem essa restrição. Quando um tipo de instância preferencial não está disponível, o Databricks recorre automaticamente a uma alternativa compatível que compartilha a mesma forma de compute. Em outras palavras, o cluster é iniciado com sucesso usando uma combinação de tipos de instância semelhantes, em vez de falhar completamente.
Para equipes que precisam de um controle mais rigoroso, elas também podem definir uma lista de fallback personalizada através da API, incluindo quais tipos de instância tentar e em que ordem.
Principais benefícios
Menos falhas de inicialização de cluster durante o pico de demanda
Os tipos de nós flexíveis reduzem a frequência e a gravidade das falhas relacionadas à capacidade. Quando um provedor de nuvem não consegue fornecer o tipo de instância preferencial, o Databricks recorre automaticamente a alternativas compatíveis, permitindo que os clusters sejam iniciados em vez de apresentarem erro.
Uso otimizado de instâncias Spot
Para clusters configurados com Spot-com-fallback, os tipos de nós flexíveis tentam adquirir capacidade Spot em toda a lista de fallback antes de reverter para instâncias On-Demand. Isso aumenta a porção do cluster executando em Spot, ajudando a diminuir os custos de compute enquanto ainda prioriza inicializações bem-sucedidas.
Visibilidade clara e controle preciso
As equipes podem inspecionar exatamente quais tipos de nó são adquiridos usando a tabela do sistema node_timeline. Além disso, uma ordem de fallback personalizada pode ser definida pela API, permitindo um controle preciso sobre o comportamento de custo e desempenho.
Início rápido
Os administradores do workspace podem habilitar facilmente o recurso nas configurações de administrador (Documentação: AWS, Azure, GCP). A partir daí, o recurso se aplica imediatamente a todas as novas inicializações de cluster. Clusters de longa duração adotarão o recurso na próxima reinicialização, e futuros clusters de job criados para jobs existentes utilizarão automaticamente o recurso.
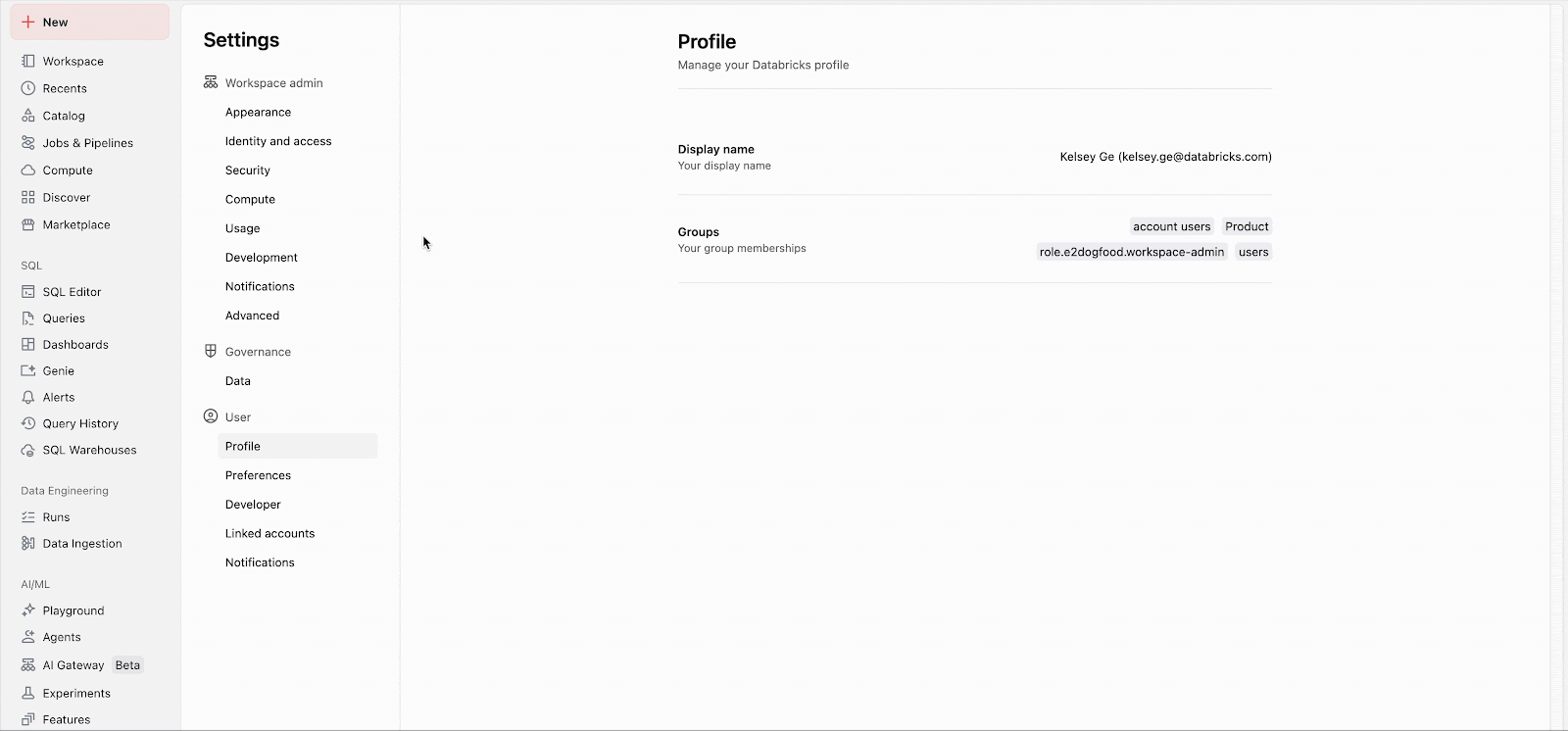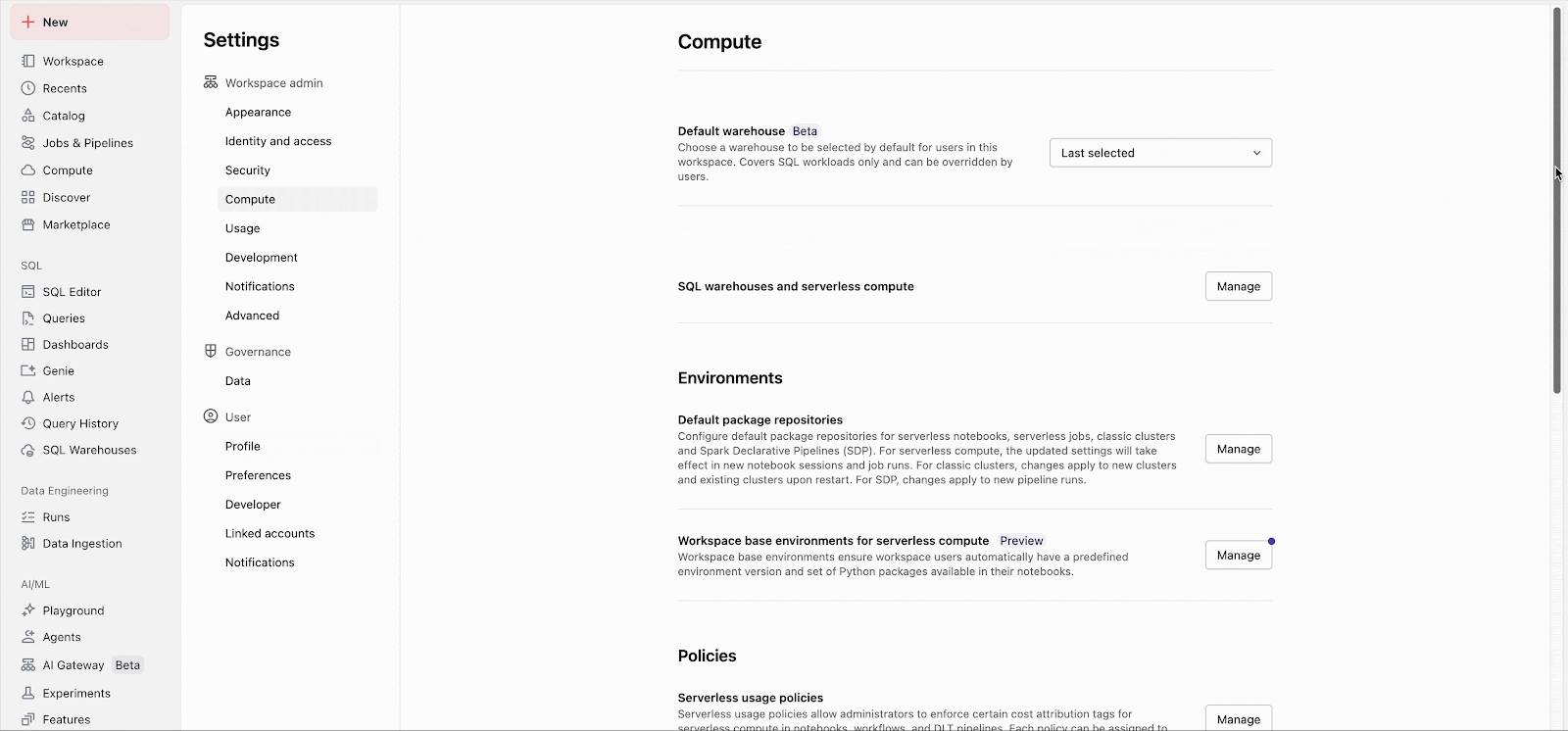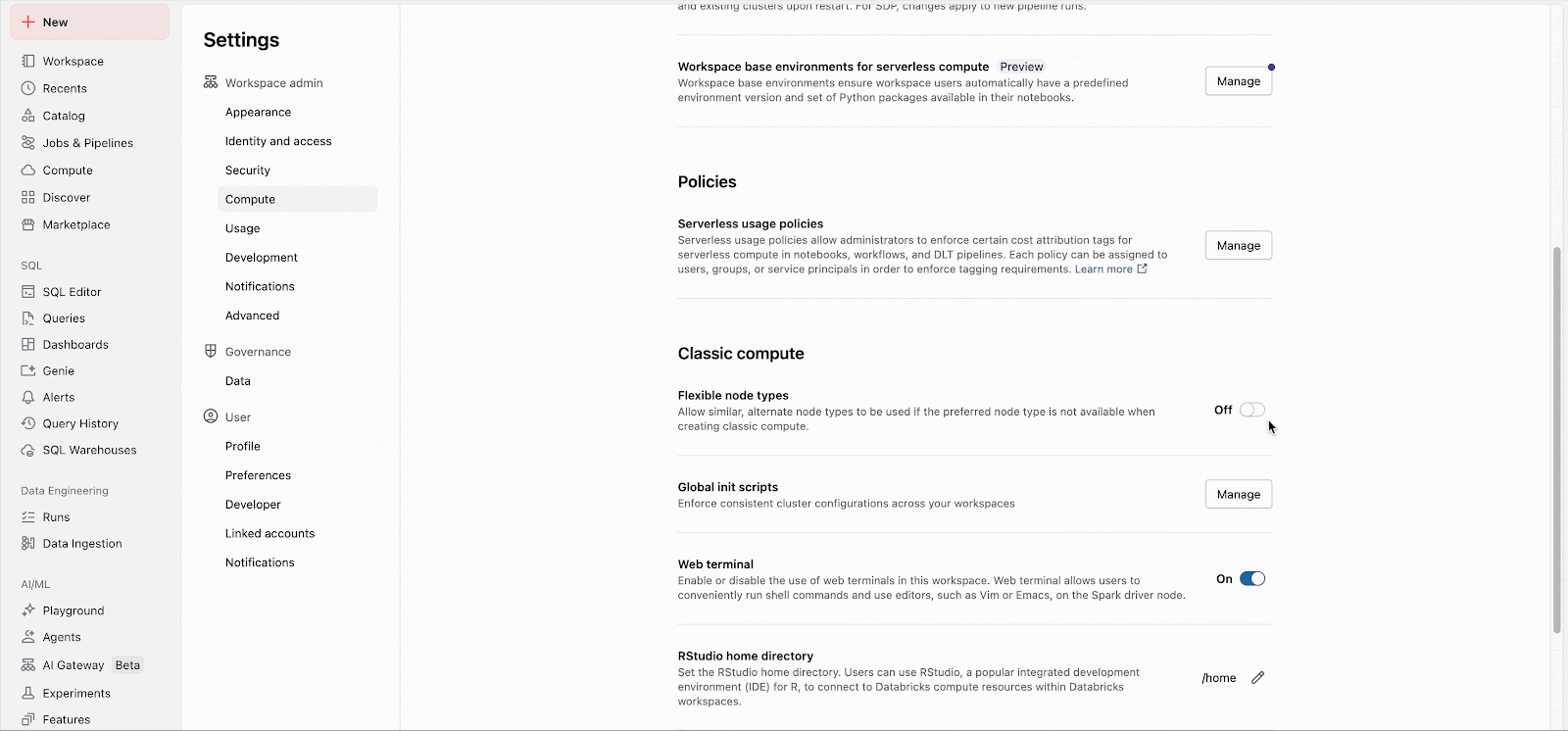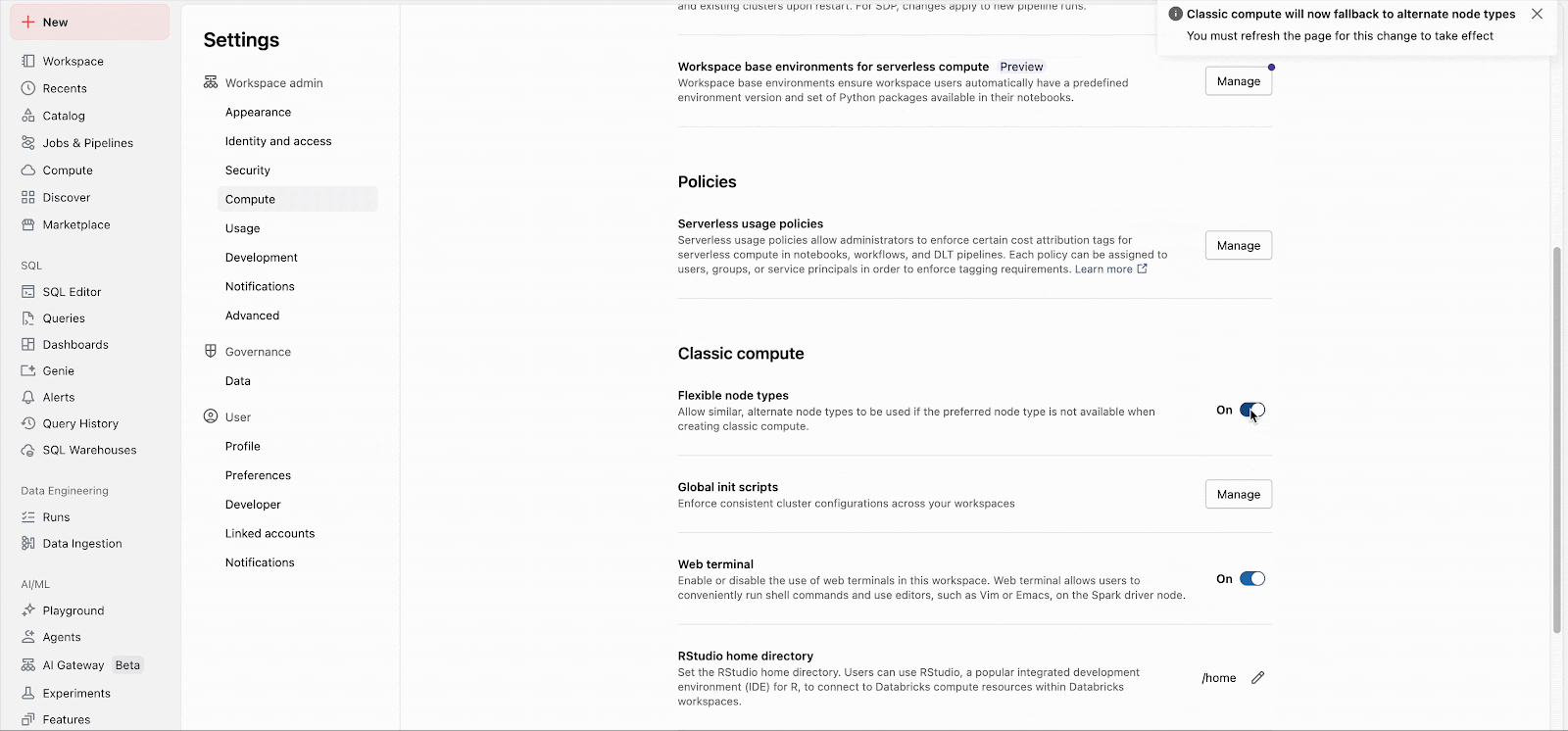
Listas de fallback personalizadas podem ser configuradas pela API, independentemente da configuração do workspace.
Detalhes adicionais
Consulte a documentação para obter mais detalhes sobre como configurar tipos de nós flexíveis com pools de instâncias, faturamento, cotas de tipo de nó e habilitação/desabilitação seletiva (Documentos: AWS, Azure, GCP).
Os Tipos de Nós Flexíveis são projetados para tornar sua plataforma de dados mais resiliente e econômica. Os administradores podem habilitar este recurso hoje com 1 clique nas configurações de administrador do workspace, seguindo as instruções na documentação.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.