AI Generativa em publicidade: imagens de anúncios personalizadas a partir da segmentação
- Personalize o criativo de anúncio: Saiba como o Databricks combina imagens de semente, RAG multimodal e GenAI para gerar imagens de anúncio personalizadas.
- Basear em ativos da marca: use imagens de semente com embedding personalizado e busca vetorial para manter os criativos gerados consistentes, realistas e alinhados com exemplos reais.
- Uma demonstração prática: veja a solução de ponta a ponta em um aplicativo Databricks com tecnologia de servindo modelo e um agente de AI.
A publicidade de hoje exige mais do que apenas imagens atraentes. É preciso um criativo que realmente se adapte aos gostos, segmentos e expectativas de um público-alvo. Este é o natural próximo passo depois de entender seu público; usar o que você sabe sobre as preferências de um segmento para criar imagens que realmente repercutam (personalizadas para seu público).
A Geração Aumentada por Recuperação (RAG) Multimodal oferece uma maneira prática de fazer isso em escala. Ela funciona combinando uma compreensão baseada em texto de um segmento-alvo (por exemplo, “dono de cachorro que adora atividades ao ar livre”) com busca e recuperação rápidas de imagens reais semanticamente relevantes. Essas imagens recuperadas servem como contexto para gerar um novo criativo. Isso preenche a lacuna entre os dados do cliente e o conteúdo de alta qualidade, garantindo que o resultado se conecte com o público-alvo.
Esta postagem no blog demonstrará como a AI moderna, por meio da recuperação de imagens e do RAG multimodal, pode tornar os criativos de anúncios mais fundamentados e relevantes, tudo com tecnologia Databricks de ponta a ponta. Mostraremos como isso funciona na prática para uma marca hipotética de ração para animais de estimação chamada “Bricks”, que veicula campanhas com o tema de pets, mas a mesma técnica pode ser aplicada a quaisquer indústrias em que a personalização e a qualidade visual sejam importantes.
Visão geral da solução
Esta solução transforma o entendimento do público em visuais relevantes e alinhados à marca, aproveitando o Unity Catalog, Agent Framework, Model Serving, inferência em lotes, AI Search e Apps. O diagrama abaixo fornece uma visão geral de alto nível da arquitetura.
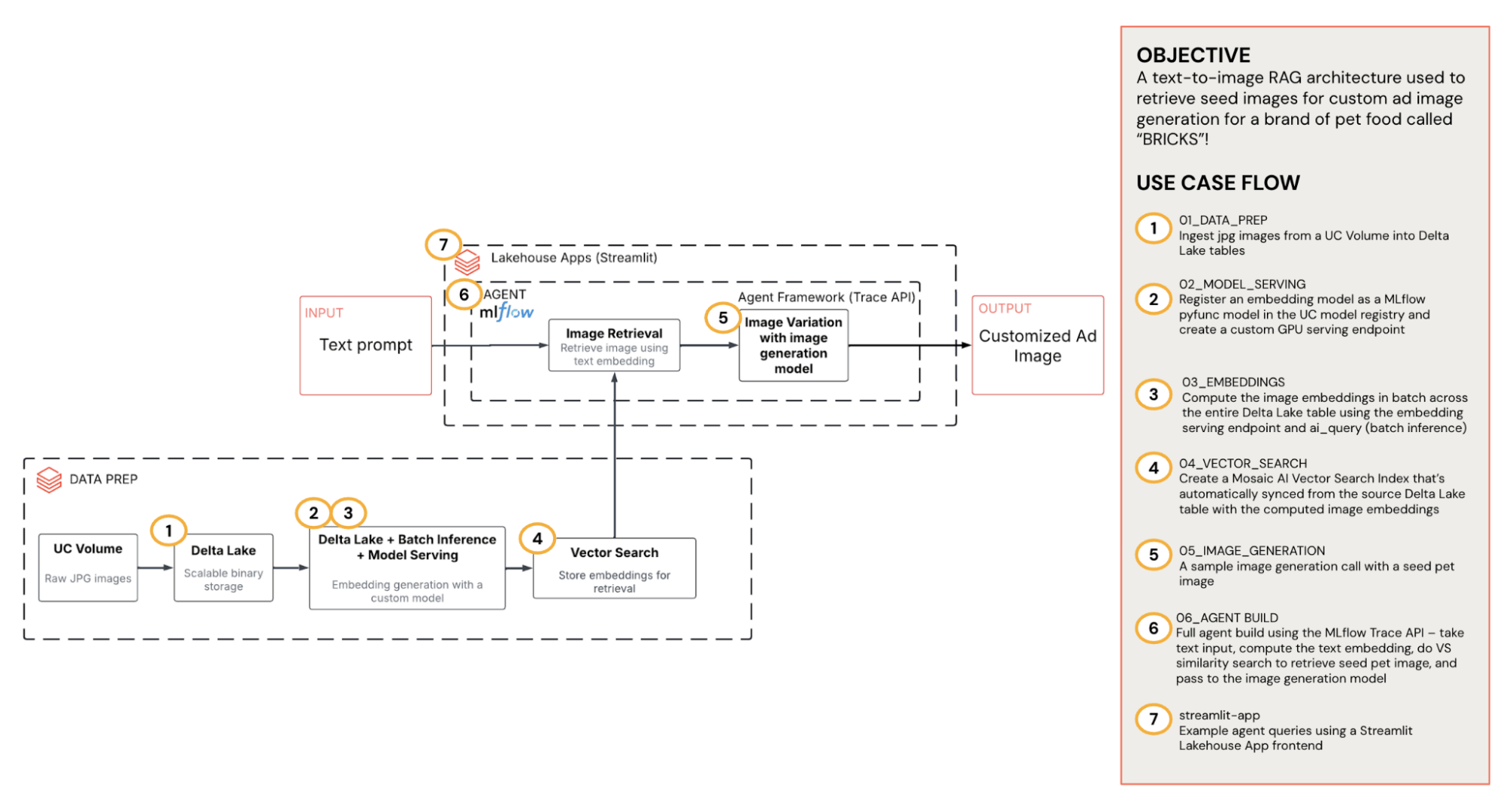
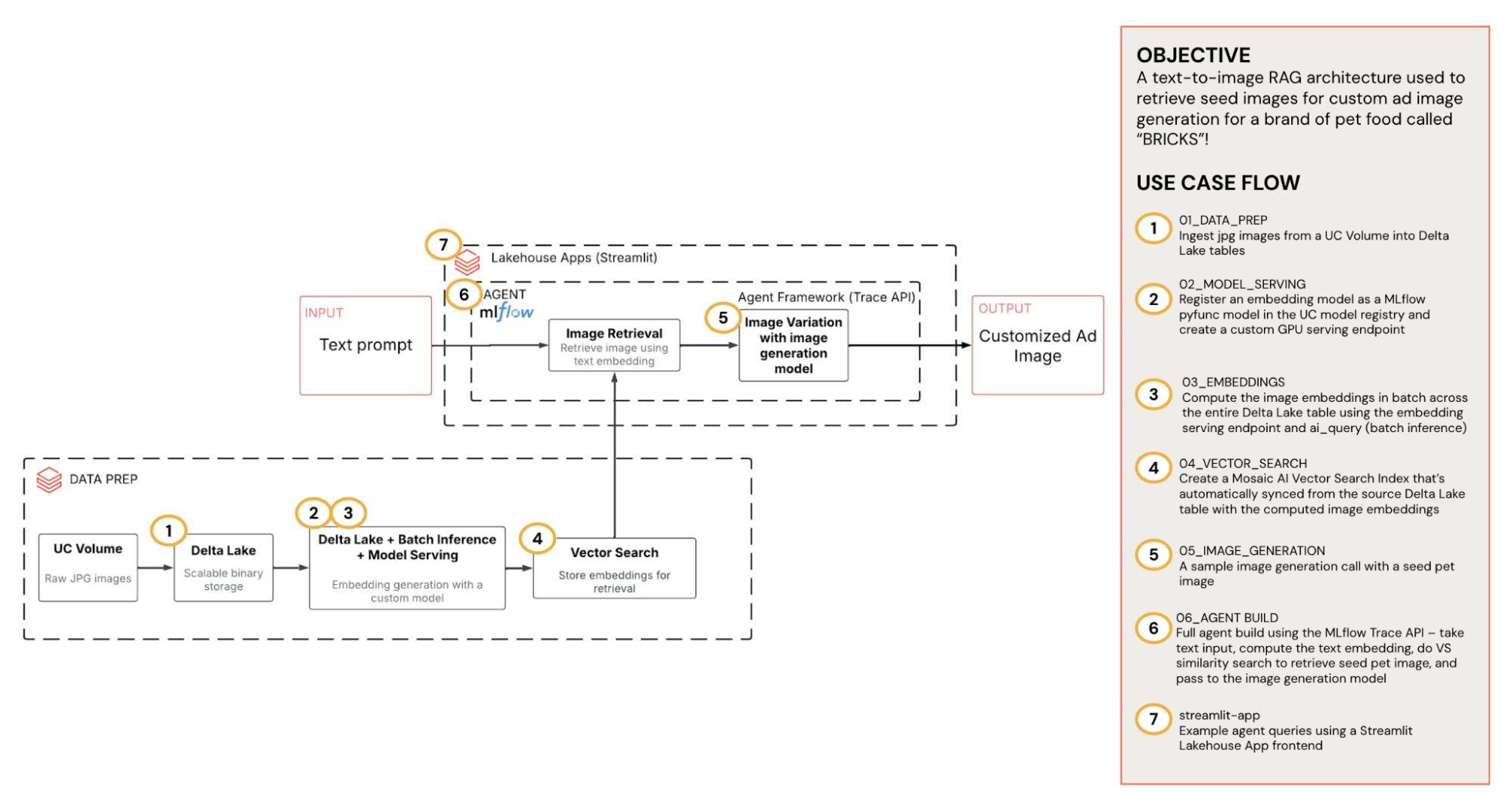{kind=link}
- Armazenamento e governança (Unity Catalog): todas as imagens de origem e anúncios gerados ficam em um Volume do Unity Catalog (UC). Também ingerimos as imagens de origem em uma tabela Delta para processamento em lote.
- Traga seus próprios embeddings:um endpoint de serviço de codificador de imagem leve CLIP converte imagens em vetores. Fazemos a inferência em lotes na tabela Delta para produzir embeddings em escala e, em seguida, os armazenamos novamente junto com os caminhos do Volume do UC.
- Recuperação da AI Search: os embeddings são indexados no Databricks AI Search, que é sincronizado automaticamente a partir da tabela Delta de origem para pesquisa semântica de baixa latência. Dado um prompt de texto curto, o índice retorna os K principais caminhos do UC.
- Agente RAG: um agente de chat que usa ferramentas coordena o fluxo de trabalho: recebe a entrada de texto → propõe uma descrição do pet → computa o embedding de texto → chama a pesquisa vetorial para recuperar a imagem semente → e, em seguida, passa a semente para o modelo de geração de imagem.
- App Databricks: um app amigável que expõe o agente aos usuários e os guia na geração de uma imagem de anúncio personalizada para seu segmento.
Como tudo flui pelo UC, o sistema é seguro por default, observável (rastreamento do MLflow na recuperação e geração) e fácil de evoluir (swap modelos, ajustar prompts). Vamos nos aprofundar.
Armazenamento e governança (Unity Catalog)
Todos os ativos de imagem de pets (imagens semente de pets, imagem da marca e anúncios finais) ficam em um Volume UC, por exemplo:
Os Volumes do UC fornecem uma solução de armazenamento eficiente para nossos dados de imagem com um ponto de montagem FUSE e são úteis, pois permitem um único plano de governança. As mesmas ACLs se aplicam independentemente de você acessar os arquivos a partir de Notebooks, Endpoints de serviço ou do aplicativo Databricks. Isso também significa que não há keys de blob em nosso código. Passamos caminhos (não bytes) entre os serviços.
Para uma indexação e governança rápidas, espelhamos o Volume em uma tabela Delta que carrega os bytes brutos das imagens (como uma coluna BINARY) juntamente com os metadados. Em seguida, convertemos isso em uma string codificada em base64 (necessária para o endpoint de servindo modelo). Isso torna os trabalhos em lote downstream (como a incorporação) simples e eficientes.
Agora há uma tabela consultável e também preservamos os caminhos de Volume originais para facilitar a leitura humana e o uso em aplicativos.
Use seus próprios Embeddings
CLIP é um codificador de imagem leve com um modelo codificador de texto transformer que é treinado por meio de aprendizado contrastivo para produzir embeddings de imagem e texto alinhados para classificação e recuperação zero-shot. Para manter a recuperação rápida e reproduzível, expomos os codificadores CLIP por trás de um endpoint de Model Serving do Databricks, que podemos usar tanto para consultas online quanto para inferência em lote offline. Nós simplesmente pacote o codificador como uma função pyfunc do MLflow, o registro como um modelo do UC e o servimos com um servindo modelo personalizado e, em seguida, o chamamos do SQL com ai_query para preencher a coluna de embeddings na tabela Delta.
O passo 1: pacote CLIP como um pyfunc do MLflow
Envolvemos o CLIP ViT-L/14 como um pequeno pyfunc que aceita uma strings de imagem base64 e retorna um vetor normalizado. Após o log, fazemos o registro do modelo para ser servido.
O passo 2: registro o modelo e fazer o log no UC
Fazemos o log do modelo usando o MLflow e o registro em um registro de modelo do UC.
O passo 3: servir o codificador
Criamos um endpoint de serviço de GPU para o modelo registrado. Isso nos dá uma API versionada e de baixa latência que podemos chamar.
O passo 4: Inferência em lotes com ai_query
Com as imagens inseridas em uma tabela Delta, compute os embeddings no local usando SQL. O resultado é uma nova tabela com uma coluna image_embeddings, pronta para a AI Search.
Recuperação com AI Search
Depois de materializarmos os embeddings de imagem no Delta, nós os tornamos pesquisáveis com o Databricks AI Search. O padrão é criar um índice do Delta Sync com embeddings autogerenciados, depois, em Runtime, incorporar o prompt de texto usando o CLIP e executar uma pesquisa de similaridade top-K. O serviço retorna resultados pequenos e estruturados (caminhos + metadados opcionais), e passamos os caminhos do Volume do UC adiante (não bytes brutos) para que o resto do pipeline permaneça leve e governado.
O passo 1: indexação da tabela de incorporações
Crie um índice de vetor uma única vez. Ele sincroniza continuamente a partir da nossa tabela de incorporações e atende a queries de baixa latência.
Como o índice é sincronizado com o Delta, quaisquer novas linhas da tabela de embeddings (ou linhas de embeddings atualizadas) serão indexadas automaticamente. O acesso à tabela e ao índice herda as ACLs do Unity Catalog, portanto, você não precisa de permissões separadas.
O passo 2: consultar os K principais candidatos em Runtime
Na inferência, incorporamos o prompt de texto e consultamos os três principais resultados com a pesquisa de similaridade.
Quando passarmos os resultados para o agente mais tarde, manteremos a resposta mínima e acionável. Retornamos apenas os caminhos UC classificados que o agente irá percorrer (se um usuário rejeitar a imagem semente inicial) sem consultar novamente o índice.
Agente RAG
O passo 1: endpoint de serviço de geração de imagem (recuperação + geração)
Aqui, criamos um endpoint que aceita um prompt de texto curto e orquestra dois os passos:
- Recuperação: incorpore o texto, query o índice do AI Search e retorne os 3 principais caminhos de Volume UC para as imagens de semente (classificados por ordem)
- Geração: carrega a semente escolhida, chama a API de geração de imagem, faz o upload da imagem final para o volume UC e retorna seu caminho.
Esta segunda parte é opcional e controlada por um seletor, dependendo se queremos a execução da geração da imagem ou apenas a recuperação.
Para o passo de geração, estamos chamando o Replicate usando o modelo Kontext multi-image max. Essa escolha é pragmática:
- Condicionamento multi-imagem: o Kontext pode usar uma foto semente de um animal de estimação e uma imagem da marca para compor um anúncio realista
- Fotorrealismo + retenção do plano de fundo: o Kontext tende a manter a pose/o ambiente original do pet enquanto posiciona o produto de forma natural
- Qualidade vs. latência: o Kontext oferece um bom equilíbrio entre qualidade e latência. Ele produz uma imagem de qualidade relativamente alta em cerca de 7 a 10 segundos. Outros modelos de geração de imagem de alta qualidade que testamos, como o gpt-4o, por meio da API gpt-image-1, geram imagens de qualidade superior em cerca de 50 segundos a um minuto.
Chamada de geração:
Gravação de volta no Volume UC: decodifique o base64 do gerador e grave por meio da API de Arquivos:
Se desejado, é fácil substituir Kontext/Replicate por qualquer API de imagem externa (p. ex., OpenAI) ou um modelo interno servido no Databricks sem alterar o resto do pipeline. Basta substituir os componentes internos do método _replicate_image_generation e manter idênticos o contrato de entrada (bytes da semente do pet + bytes da marca) e a saída (bytes PNG → upload no UC). O agente de chat, a recuperação e o aplicativo permanecem os mesmos porque operam em caminhos UC, e não em payloads de imagem.
O passo 2: Agente de chat
O agente de chat é um endpoint de serviço final que contém a política de conversação e chama o endpoint de geração de imagem como uma ferramenta. Ele propõe um tipo de pet, recupera as imagens semente candidatas e só gera a imagem final do anúncio com a confirmação do usuário.
O esquema da ferramenta é mantido de forma minimalista:
Em seguida, criamos a função de execução da ferramenta, onde o agente pode chamar o endpoint image-gen, que retorna uma resposta JSON estruturada.
O parâmetro replicate_toogle controla a geração de imagem.
Por que dividir os Endpoints?
Separamos os Endpoints do agente de chat e de geração de imagem por alguns motivos:
- Separação de responsabilidades: O endpoint de geração de imagens é um serviço determinístico (retrieve top-K → optionally generate one → return UC paths). O endpoint do agente de chat é responsável pela política e pela experiência do usuário. Ambos permanecem pequenos, testáveis e substituíveis
- Extensibilidade modular: o agente pode crescer adicionando ferramentas posteriormente por trás da mesma interface, por exemplo, sugestões de texto ou CTA, recuperação de dados estruturados, sem alterar o serviço de geração de imagem
O acima é tudo construído no Databricks Agent Framework, que nos fornece as ferramentas para transformar recuperação + geração em um agente confiável e governado. Primeiro, a estrutura nos permite registro o serviço de geração de imagem (incluindo o AI Search) como ferramentas e invocá-las deterministicamente a partir da política/prompt. Ele também nos fornece um scaffolding de produção pronto para uso. Usamos a interface ResponsesAgent para o loop de chat, com MLflow tracing em cada o passo. Isso oferece observabilidade total para depuração e operação de um fluxo de trabalho de várias etapas em produção. A MLflow tracing UI nos permite explorar isso visualmente.
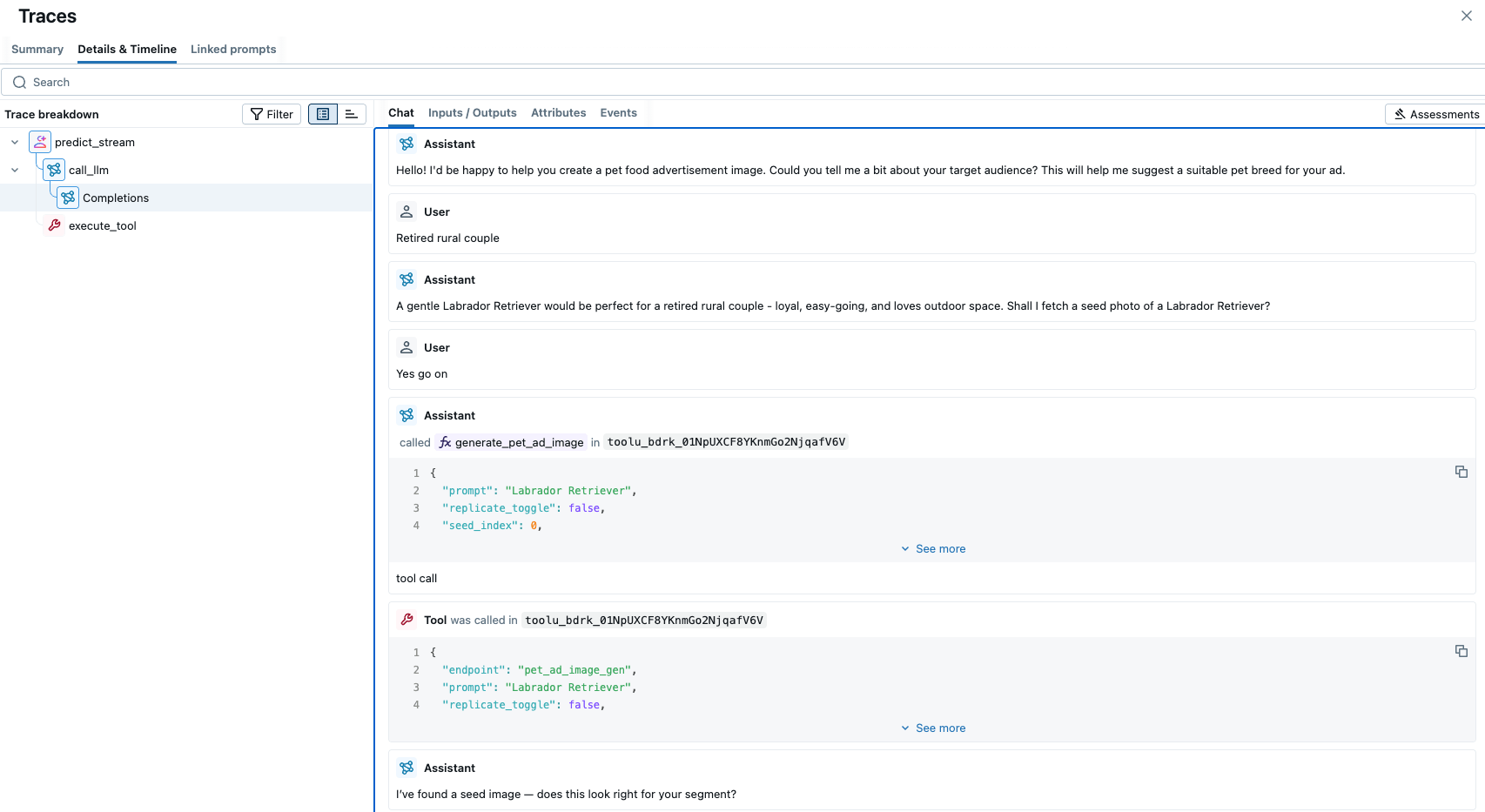
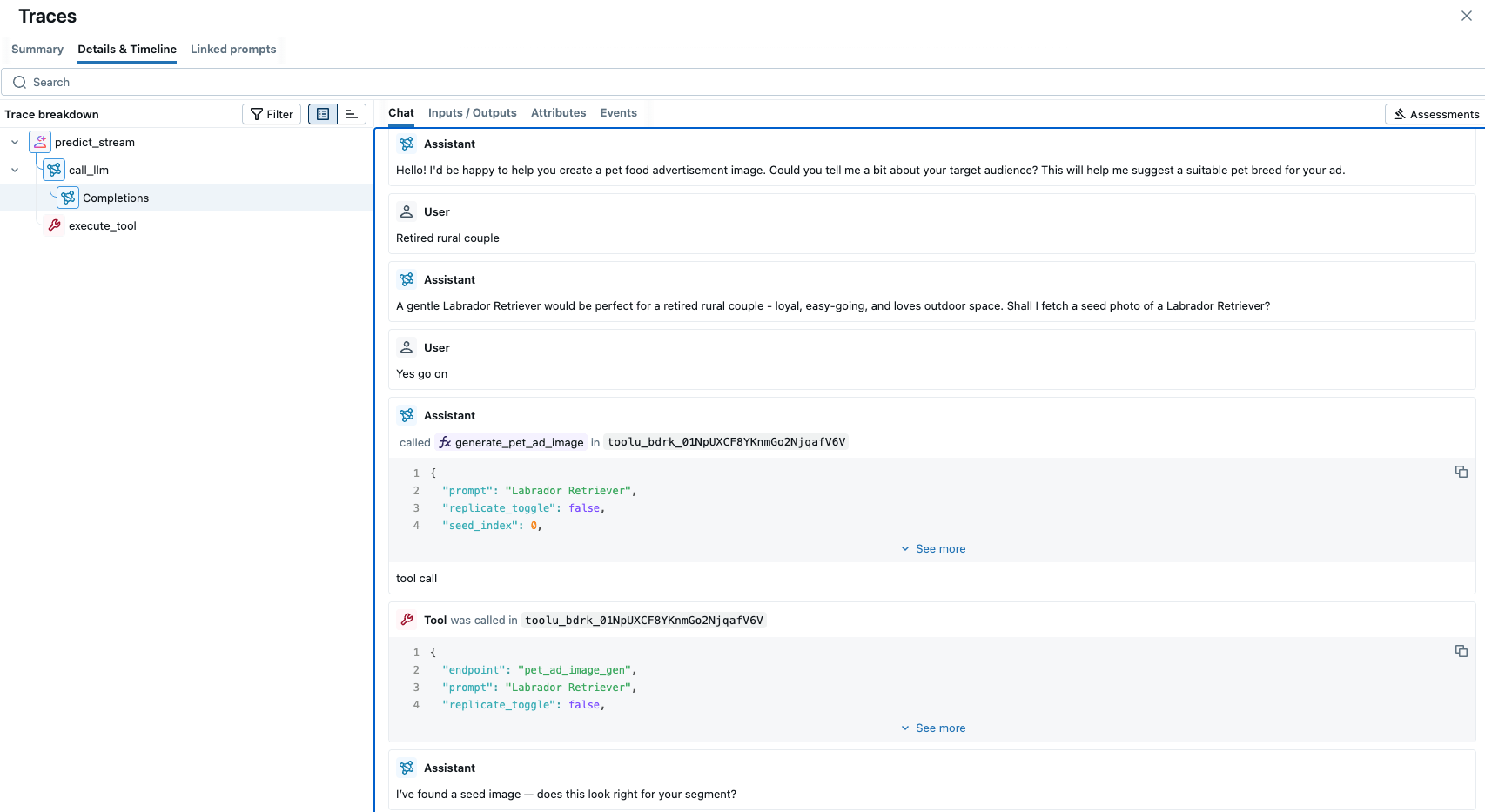{kind=link}
Databricks Apps
O aplicativo Streamlit apresenta uma experiência de conversação única que permite que o usuário converse com o agente de chat e renderiza as imagens. Ele combina todas as peças que construímos em uma experiência de produto única e governada.
Como tudo se encaixa:
- Governança e permissões: o aplicativo é executado no workspace do Databricks e se comunica diretamente com nosso endpoint de agente de chat. Com credenciais on-behalf-of, o aplicativo pode fazer o download das imagens semente/finais pelo caminho do UC, por meio da API Files, de acordo com as permissões do visualizador. Isso fornece controle de acesso por usuário e uma trilha de auditoria clara
- Configuração como código: as configurações do aplicativo (por exemplo, AGENT_ENDPOINT) são passadas por meio de variáveis de ambiente/segredos
- Interfaces claras: a interface do chat envia um payload de respostas compacto para o agente e recebe de volta um pequeno ponteiro JSON com um caminho do Volume do UC. A UI então faz o download da imagem e a renderiza para o usuário.
Abaixo são mostrados os dois key pontos de contato no código do aplicativo. Primeiro, chame o endpoint do agent:
E renderizar pelo caminho do UC Volume:
Exemplo de ponta a ponta
Vamos conhecer um fluxo único que conecta todo o sistema. Imagine que um comerciante queira gerar uma imagem de anúncio de pet personalizada para “jovens profissionais urbanos”.
1. Propor
O agente de chat interpreta o segmento e propõe um tipo de pet, por exemplo, um buldogue francês.
{kind=link}
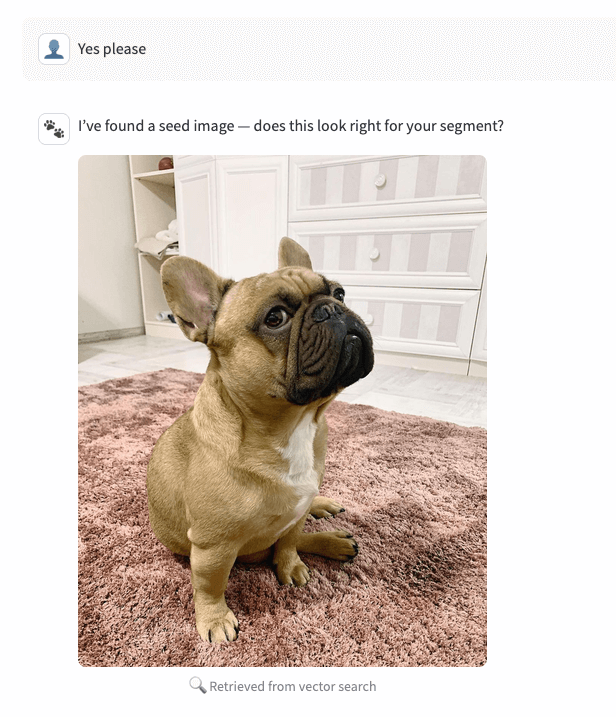
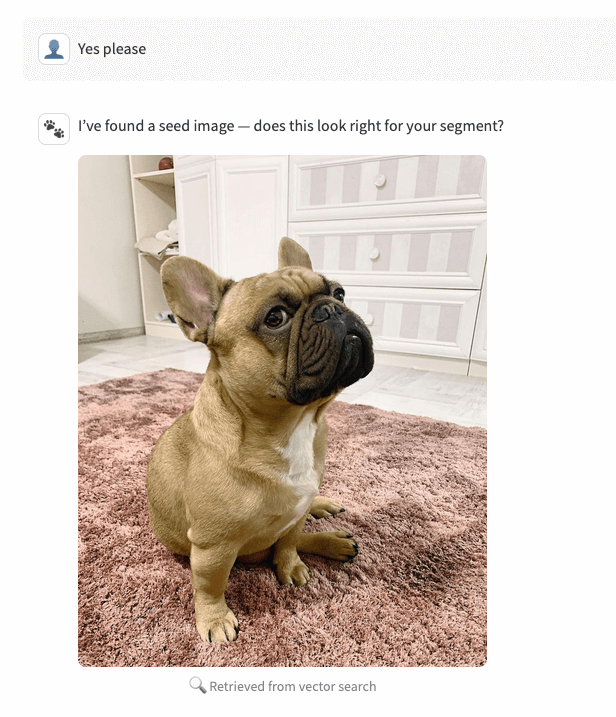
2. Recuperar (chamada de ferramenta, sem geração)
Com a resposta “sim”, o agent chama o endpoint image-gen em modo de recuperação e retorna as três principais imagens (caminhos de volume) do AI Search, classificadas por similaridade. O aplicativo exibe o candidato nº 0 como a imagem semente.
{kind=link}
3. Confirmar (ou iterar)
Se o usuário disser algo como “parece bom”, nós prosseguimos. Se disserem “não é bem isso”, o agente incrementa seed_index para 1 (depois 2) e reutiliza o mesmo conjunto top 3 (sem query vetoriais extras) para mostrar a próxima opção. Se, após três imagens, o usuário ainda não estiver satisfeito, o agente sugerirá uma nova descrição de pet e triggerá outra chamada da AI Search. Isso mantém a UX ágil e determinística.
4. Gerar e renderizar
Após a confirmação, o agente chama o endpoint novamente com replicate_toggle=true e o mesmo seed_index. O endpoint lê a imagem semente escolhida do UC, combina-a com a imagem da marca, executa o gerador Kontext multi-image-max no Replicate e, em seguida, faz o upload do PNG final de volta para um Volume UC. Apenas o caminho do UC é retornado. O app então faz o download da imagem e a renderiza de volta para o usuário.
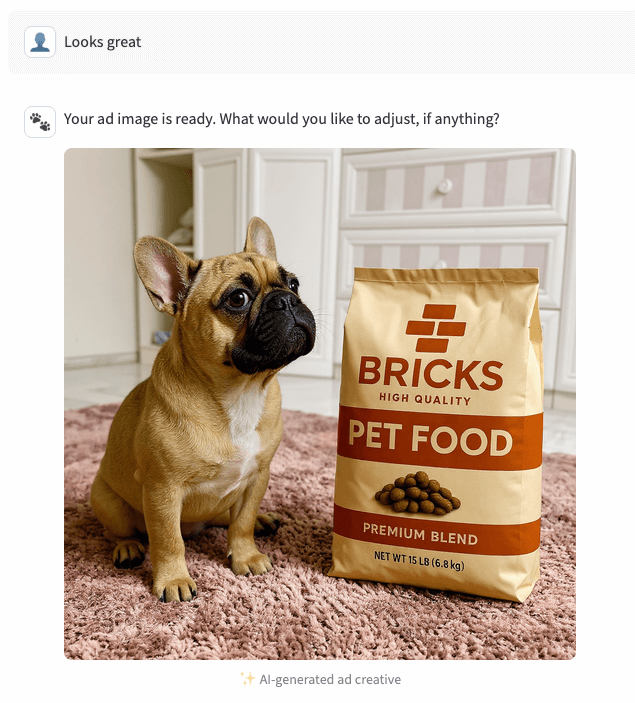
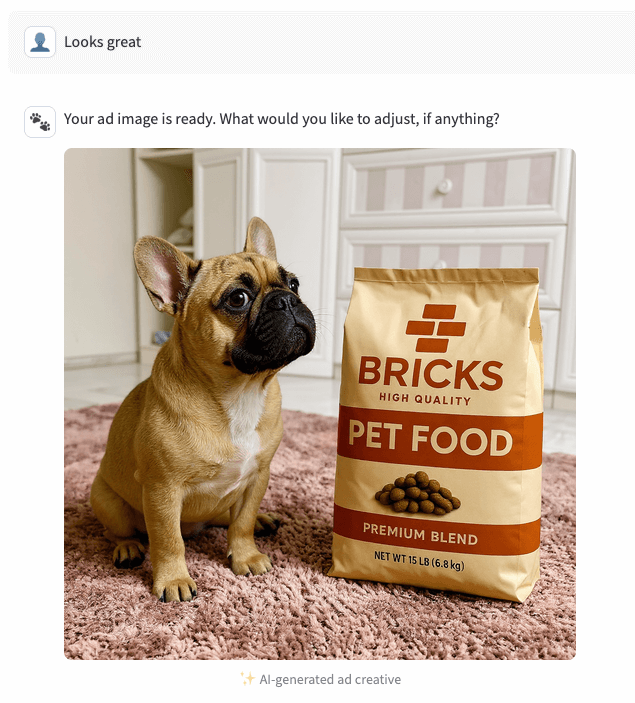{kind=link}
Conclusão
Neste blog, demonstramos como o RAG multimodal possibilita a personalização avançada de anúncios. Ancorar a geração na recuperação de imagens reais é a diferença entre visuais genéricos e um criativo que repercute em um público específico. Isso permite:
- Maior qualidade visual: as sementes fotográficas preservam detalhes mais finos que os prompts somente de texto têm dificuldade em reproduzir.
- Alinhamento contextual: a recuperação ancora cenas e pets ao contexto do público, melhorando a coerência entre mensagem e imagem.
- Geração mais previsível: o condicionamento de múltiplas imagens (imagem de semente + imagem da marca) restringe o modelo, reduzindo alucinações e melhorando a segurança da marca.
- Iteração rápida: retornar as 3 melhores sementes permite que a agência alterne entre elas sem precisar fazer uma nova consulta. O comerciante acompanha o processo e orienta a imagem final do anúncio.
O Databricks garante aplicações escaláveis, governadas e de alto desempenho. Esta arquitetura permanece pronta para produção, com cada o passo executado de ponta a ponta dentro da plataforma:
- O Unity Catalog governa tudo: imagens de origem e geradas, tabelas e agente. Acesso, auditoria e linhagem são consistentes.
- Tabelas Delta + AI Search mantêm os embeddings transacionais e as querys com baixa latência. Você pode refazer o embedding, reindexar ou filtrar por metadados sem alterar nada nas etapas seguintes.
- O Model Serving + o Agent Bricks Custom Agents separam as responsabilidades: o endpoint de geração de imagem é um serviço determinístico, e o agente de chat orquestra a política e as ferramentas. Cada um pode ser escala, versionado e revertido de forma independente.
- O Databricks Apps coloca a UI ao lado dos dados e serviços, e o rastreamento do MLflow fornece observabilidade passo a passo.
O resultado é um agente RAG modular e governado que transforma as percepções do público em criativos de alta qualidade e alinhados à marca em escala.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.