Primeiros passos com personalização por meio de pontuação de propensão
por Tian Tan, Sam Steiny e Bryan Smith

Os consumidores esperam cada vez mais ser abordados de forma personalizada. Seja um e-mail promovendo produtos para complementar uma compra recente, um banner online anunciando uma promoção de produtos em uma categoria navegada com frequência ou conteúdo alinhado aos interesses manifestados, os consumidores têm cada vez mais opções de onde gastar seu dinheiro e preferem fazê-lo em canais que reconheçam suas necessidades e preferências pessoais.
Uma pesquisa recente da McKinsey destaca que quase três quartos dos consumidores agora esperam interações personalizadas como parte de sua experiência de compra. O estudo incluído nesta pesquisa destaca que as empresas que acertam nessa estratégia tendem a gerar 40% mais receita por meio de engajamentos personalizados, tornando a personalização um diferencial fundamental para os principais players do varejo.
Mesmo assim, muitos varejistas enfrentam dificuldades com a personalização. Uma pesquisa recente da Forrester revela que apenas 30% dos consumidores dos US e 26% dos do UK acreditam que os varejistas fazem um bom trabalho na criação de experiências relevantes para eles. Em outra pesquisa da 3radical, apenas 18% dos entrevistados concordaram plenamente que recebem recomendações personalizadas, enquanto 52% expressaram frustração por receberem comunicações e ofertas irrelevantes. Com os consumidores cada vez mais empoderados para mudar de marca e de canal, acertar na personalização tornou-se uma prioridade para um número crescente de empresas.
A personalização é uma jornada
Para uma organização que está começando na personalização, a ideia de oferecer engajamentos um para um (one-to-one) parece assustadora. Como superar processos isolados, governança de dados ineficiente e preocupações com a privacidade dos dados para reunir as informações necessárias para essa abordagem? Como criar conteúdos e mensagens que pareçam realmente personalizados com recursos de marketing limitados? Como garantir que o conteúdo que criamos seja direcionado de forma eficaz a indivíduos com necessidades e preferências em constante evolução?
Embora grande parte da literatura sobre personalização destaque abordagens de ponta que se sobressaem pela novidade (mas nem sempre pela sua eficácia), a realidade é que a personalização é uma jornada. Nas fases iniciais, a ênfase é colocada no aproveitamento de dados primários (first-party data), onde a privacidade e a confiança do cliente são mantidas com mais facilidade. Técnicas preditivas bastante padronizadas são aplicadas para trazer recursos comprovados à tona. À medida que o valor é demonstrado e a organização desenvolve não apenas familiaridade com essas novas técnicas, mas também com as diversas maneiras de integrá-las às suas práticas, abordagens mais sofisticadas passam a ser empregadas.
A pontuação de propensão (propensity scoring) costuma ser o primeiro passo rumo à personalização
Um dos primeiros passos na jornada de personalização costuma ser a análise dos dados de vendas para obter insights sobre as preferências individuais dos clientes. Em um processo conhecido como pontuação de propensão (propensity scoring), as empresas podem estimar a receptividade potencial dos clientes a uma oferta ou a conteúdos relacionados a um subconjunto de produtos. Com base nessas pontuações, os profissionais de marketing podem determinar qual das muitas mensagens à sua disposição deve ser apresentada a um cliente específico. Da mesma forma, essas pontuações podem ser usadas para identificar segmentos de clientes que são mais ou menos receptivos a uma forma específica de engajamento.
O ponto de partida para a maioria dos exercícios de pontuação de propensão é o cálculo de atributos numéricos (features) a partir de interações passadas. Essas features podem incluir elementos como a frequência de compras do cliente, a porcentagem de gastos associada a uma categoria específica de produtos, os dias decorridos desde a última compra e muitas outras métricas derivadas dos dados históricos. O período histórico imediatamente posterior ao período a partir do qual essas features foram calculadas é então analisado em busca de comportamentos de interesse, como a compra de um produto de uma categoria específica ou o resgate de um cupom. Se o comportamento for observado, um rótulo (label) de 1 é associado às features. Caso contrário, atribui-se um rótulo de 0.
Usando as features como preditores dos rótulos, os cientistas de dados podem treinar um modelo para estimar a probabilidade de ocorrência do comportamento de interesse. Ao aplicar esse modelo treinado às features calculadas para o período mais recente, os profissionais de marketing podem estimar a probabilidade de um cliente apresentar esse comportamento no futuro próximo.
Com inúmeras ofertas, promoções, mensagens e outros conteúdos à nossa disposição, vários modelos — cada um prevendo um comportamento diferente — são treinados e aplicados a esse mesmo conjunto de features. Um perfil por cliente, composto por pontuações para cada um dos comportamentos de interesse, é compilado e publicado em sistemas downstream para uso do marketing na orquestração de várias campanhas.
O Databricks oferece recursos essenciais para a pontuação de propensão
Por mais simples que pareça a pontuação de propensão, ela não deixa de ter seus desafios. Em nossas conversas com varejistas que implementam a pontuação de propensão, frequentemente nos deparamos com as mesmas três perguntas:
- Como mantemos as centenas e, às vezes, milhares de features que usamos para treinar nossos modelos de propensão?
- Como treinar rapidamente modelos alinhados com as novas campanhas que a equipe de marketing deseja realizar?
- Como reimplantar rapidamente no pipeline de pontuação os modelos retreinados à medida que os padrões dos clientes sofrem desvios (drift)?
No Databricks, nosso foco é capacitar nossos clientes por meio de uma plataforma de análise desenvolvida pensando nas necessidades de ponta a ponta da empresa. Para isso, incorporamos à nossa plataforma recursos como o Feature Store, o AutoML e o MLflow, todos os quais podem ser utilizados para enfrentar esses desafios como parte de um processo robusto de pontuação de propensão.
Feature Store
O Databricks Feature Store é um repositório centralizado que permite a persistência, descoberta e compartilhamento de features em vários exercícios de treinamento de modelos. À medida que as features são capturadas, a linhagem (lineage) e outros metadados também são registrados, para que os cientistas de dados que desejam reutilizar features criadas por terceiros possam fazer isso com confiança e facilidade. Modelos de segurança padrão garantem que apenas usuários e processos autorizados possam utilizar essas features, de modo que os processos de ciência de dados sejam gerenciados de acordo com as políticas organizacionais de acesso a dados.
AutoML
O Databricks AutoML permite gerar modelos rapidamente aproveitando as melhores práticas do setor. Como uma solução de caixa de vidro (glass box), o AutoML gera primeiro uma coleção de notebooks que representam diferentes variações de modelos alinhadas ao seu cenário. Enquanto treina iterativamente os diferentes modelos para determinar qual funciona melhor com seu conjunto de dados, ele permite que você acesse os notebooks associados a cada um deles. Para muitas equipes de ciência de dados, esses notebooks tornam-se um ponto de partida editável para uma exploração mais aprofundada das variações de modelos, o que, em última análise, permite que cheguem a um modelo treinado que confiam que atenderá aos seus objetivos.
MLflow
O MLflow é um repositório de modelos de machine learning de código aberto, gerenciado dentro da plataforma Databricks. Esse repositório permite que a equipe de ciência de dados acompanhe e analise as várias iterações de modelos geradas tanto pelo AutoML quanto por ciclos de treinamento personalizados. Seus recursos de gerenciamento de fluxo de trabalho permitem que as organizações movam rapidamente modelos treinados do desenvolvimento para a produção, para que esses modelos possam causar um impacto mais imediato nas operações.
Quando usados em combinação com o Databricks Feature Store, os modelos persistidos com o MLflow retêm o conhecimento das features usadas durante o treinamento. À medida que os modelos são recuperados para inferência, essa mesma informação permite que o modelo recupere as features relevantes do Feature Store, simplificando bastante o fluxo de trabalho de pontuação e permitindo uma implantação rápida.
Construindo um fluxo de trabalho de pontuação de propensão
Usando esses recursos em combinação, vemos muitas organizações implementando a pontuação de propensão como parte de um fluxo de trabalho de três partes. Na primeira parte, os engenheiros de dados trabalham com os cientistas de dados para definir as features relevantes para o exercício de pontuação de propensão e persisti-las no Feature Store. Processos diários ou até mesmo em tempo real de engenharia de features (feature engineering) são então definidos para calcular valores de features atualizados à medida que novas entradas de dados chegam.
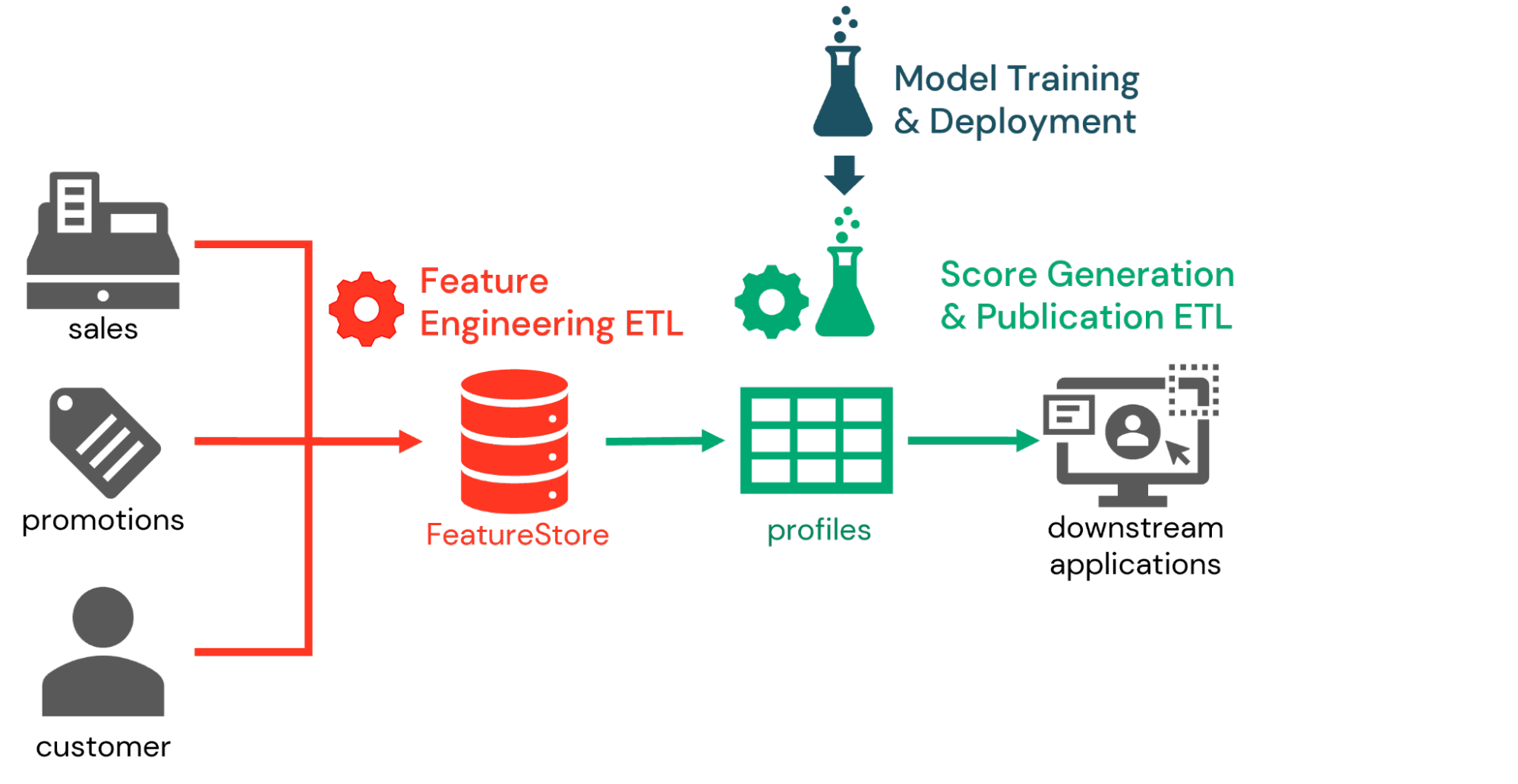
Em seguida, como parte do fluxo de trabalho de inferência, os identificadores de clientes são apresentados a modelos treinados anteriormente para gerar pontuações de propensão com base nas últimas features disponíveis. As informações da Feature Store capturadas com o modelo permitem que os engenheiros de dados recuperem essas features e gerem as pontuações desejadas com relativa facilidade. Essas pontuações podem ser persistidas para análise na plataforma Databricks, mas, mais comumente, são publicadas em sistemas de marketing downstream.
Por fim, no fluxo de trabalho de treinamento de modelo, os cientistas de dados retreinam periodicamente os modelos de pontuação de propensão para capturar mudanças nos comportamentos dos clientes. À medida que esses modelos são persistidos no MLflow, processos de gerenciamento de mudanças são empregados para avaliar os modelos e elevar aqueles que atendem aos critérios organizacionais para o status de produção. Na próxima iteração do fluxo de trabalho de inferência, a versão de produção mais recente de cada modelo é recuperada para gerar as pontuações dos clientes.
Para demonstrar como esses recursos funcionam juntos, criamos um fluxo de trabalho de pontuação de propensão de ponta a ponta baseado em um conjunto de dados disponível publicamente. Este fluxo de trabalho demonstra as três partes do fluxo de trabalho descrito acima e mostra como empregar os principais recursos do Databricks para criar um pipeline de pontuação de propensão eficaz.
Baixe os ativos aqui e use-os como ponto de partida para construir sua própria base de personalização usando a plataforma Databricks.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.