Alto Desempenho de Limitação de Taxa na Databricks
Reimaginando como o Controle de Taxa Distribuído poderia ser feito
por David Hoa, Jiaying Wang, Suyog Soti, Victoria Peng e Gaurav Nanda
- Por que o design de limitação de taxa Envoy + Redis criou gargalos de escalabilidade e alta latência sob cargas de trabalho crescentes
- Como reconstruímos o sistema com fragmentação em memória e relatórios em lote orientados pelo cliente para alcançar a aplicação de baixa latência e alta capacidade de processamento
- A adoção da limitação de taxa de token bucket para uma aplicação mais precisa, tolerância a rajadas e melhorias de 10x na latência final
Como Engenheiros da Databricks, temos o privilégio de trabalhar em problemas desafiadores com ótimos colegas. Neste post do blog de Engenharia, vamos mostrar como construímos um sistema de limitação de taxa de alto desempenho na Databricks. Se você é um usuário da Databricks, não precisa entender este blog para poder usar a plataforma ao máximo. Mas se você está interessado em dar uma olhada por baixo do capô, continue lendo para saber sobre algumas das coisas legais em que estamos trabalhando!
Plano de fundo
A limitação de taxa é sobre controlar o uso de recursos para fornecer isolamento e proteção contra sobrecarga entre inquilinos em um sistema multilocatário. No contexto do Databricks, isso poderia fornecer isolamento entre contas, espaços de trabalho, usuários, etc., e é mais frequentemente visto externamente como um limite por unidade de tempo, como o número de trabalhos iniciados por segundo, número de solicitações de API por segundo, etc. Mas também poderia haver usos internos de limites de taxa, como gerenciar a capacidade entre clientes de um serviço. A aplicação do limite de taxa desempenha um papel importante em tornar o Databricks confiável, mas é importante notar que essa aplicação incorre em sobrecarga que precisa ser minimizada.
O Problema
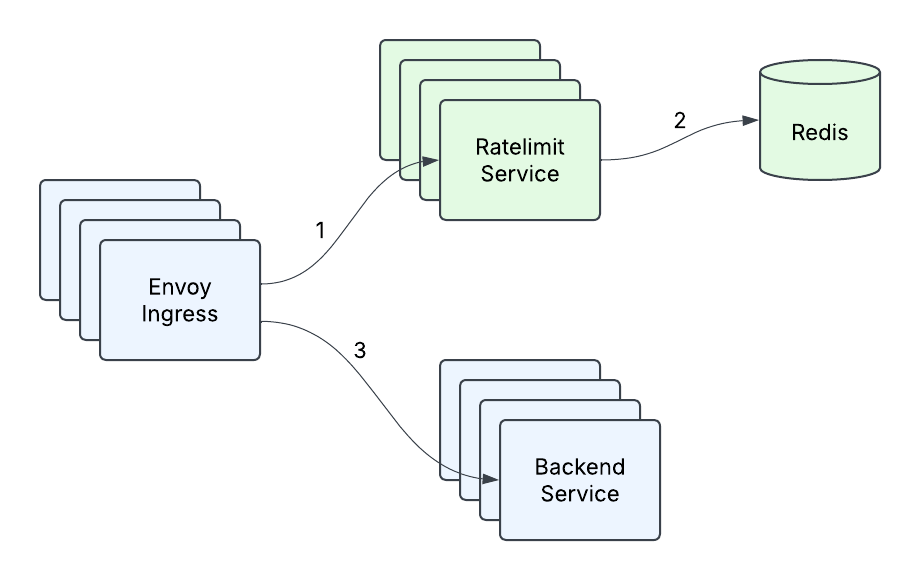
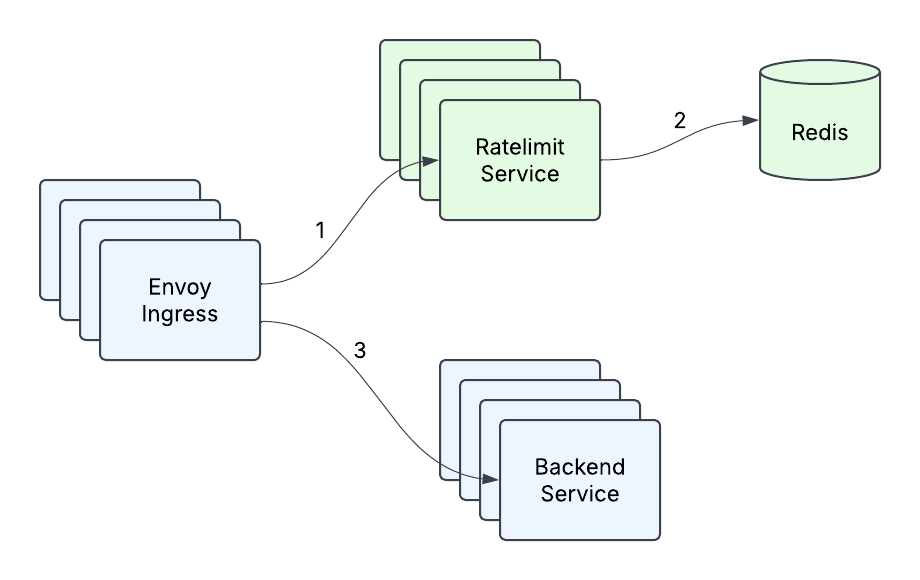
No início de 2023, a infraestrutura de Limitação de Taxa existente na Databricks consistia em um gateway de entrada Envoy fazendo chamadas para o Serviço de Limitação de Taxa, com uma única instância do Redis apoiando o serviço (Figura 1). Isso era perfeitamente adequado para as consultas por segundo (QPS) que qualquer cluster de máquinas dentro de uma região era esperado receber, bem como para a natureza transitória da contagem por segundo. Mas à medida que a empresa expandiu sua base de clientes e adicionou novos casos de uso, ficou claro que o que nos levou até aquele ponto não seria suficiente para atender nossas necessidades futuras. Com a introdução do serviço de modelo em tempo real e outros casos de uso de alta qps, onde um cliente poderia estar enviando ordens de magnitude mais tráfego do que o Serviço de Limitação de Taxa poderia atualmente lidar, surgiram alguns problemas:
- Latência alta na cauda - a latência na cauda do nosso serviço estava inaceitavelmente alta sob tráfego pesado, especialmente considerando que há dois saltos de rede envolvidos e que havia uma latência de rede P99 de 10ms-20ms em um dos provedores de nuvem.
- Vazão Limitada - em um certo ponto, adicionar mais máquinas e fazer otimizações pontuais (como cache) não nos permitiu mais lidar com mais tráfego.
- Redis como um único ponto de falha - Nossa única instância Redis era nosso único ponto de falha, e tivemos que fazer algo a respeito. Era hora de redesenhar nosso serviço.
{kind=link}
Terminologia
Na Databricks, temos um conceito de um Grupo de Limitação de Taxa (RLG), que é um identificador de string que representa um recurso ou conjunto de recursos que precisamos proteger, como um endpoint de API. Esses recursos seriam protegidos em certas Dimensões, como definir limites no nível de espaço de trabalho/usuário/conta. Por exemplo, uma dimensão transmitiria “Quero proteger a FooBarAPI no workspaceId e o workspaceId para esta solicitação é 12345.” Uma Dimensão seria representada assim:
Uma única solicitação shouldRateLimit poderia ter vários descritores, e um exemplo poderia ser definir limites, para uma API específica, no espaço de trabalho e no nível do usuário.
Onde o esquema do Descritor se parecerá com isto:
Solução
Respostas de Baixa Latência
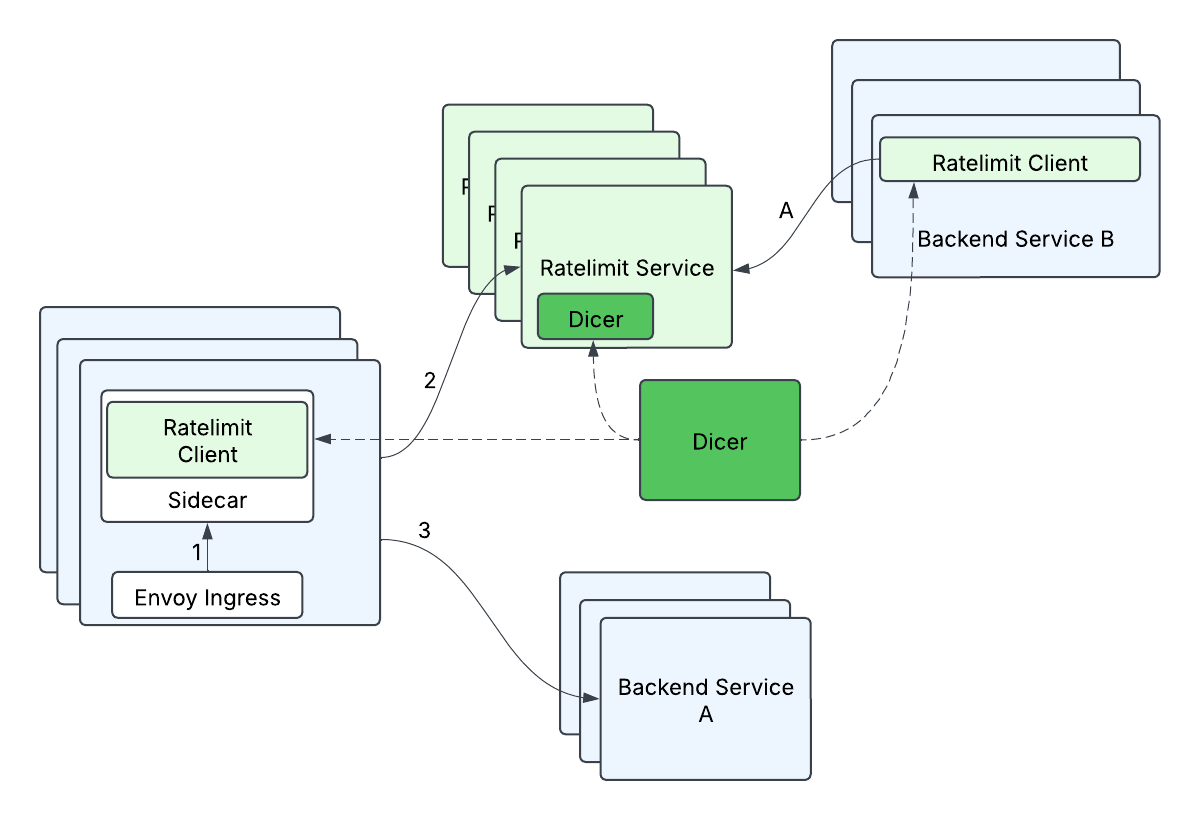
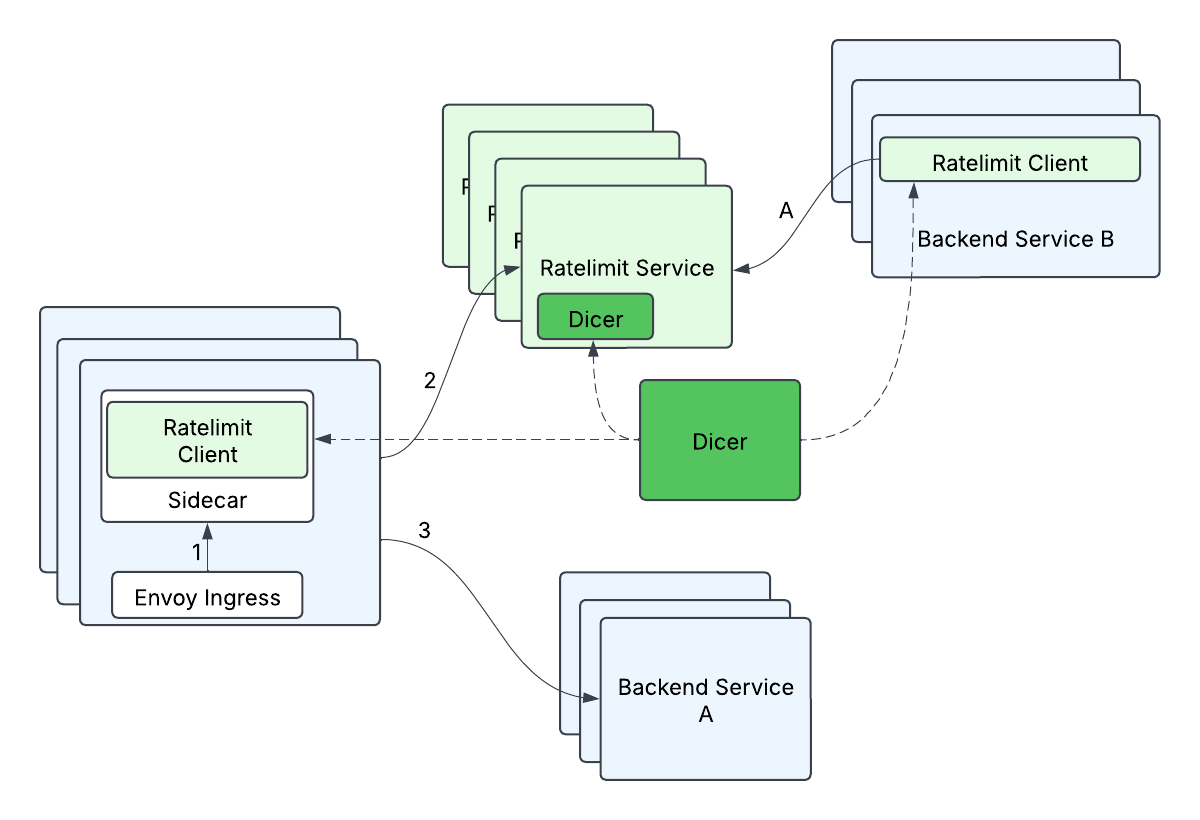
O primeiro problema que queríamos resolver era melhorar a latência do nosso Serviço de Limitação de Taxa. A limitação de taxa é, em última análise, apenas um problema de contagem, e sabíamos que idealmente queríamos mudar para um modelo onde sempre pudéssemos responder às solicitações de limite de taxa na memória, porque é ultra-rápido e a maioria dos nossos limites de taxa eram baseados em QPS, o que significava que essas contagens eram transitórias e não precisavam ser resilientes a reinicializações ou falhas de instâncias de serviço. Nossa configuração existente já fazia uma quantidade limitada de contagem em memória usando o hashing consistente do Envoy para aumentar as taxas de acerto do cache, enviando a mesma solicitação para a mesma máquina. No entanto, 1) isso não era possível compartilhar com serviços não-Envoy, 2) a rotatividade de atribuições durante redimensionamentos e reinicializações de serviço significava que ainda tínhamos que sincronizar regularmente com o Redis, e 3) o hash consistente é propenso a pontos quentes, e quando a carga não era distribuída uniformemente, muitas vezes só podíamos aumentar o número de instâncias para tentar distribuir melhor a carga, levando a uma utilização subótima do serviço.
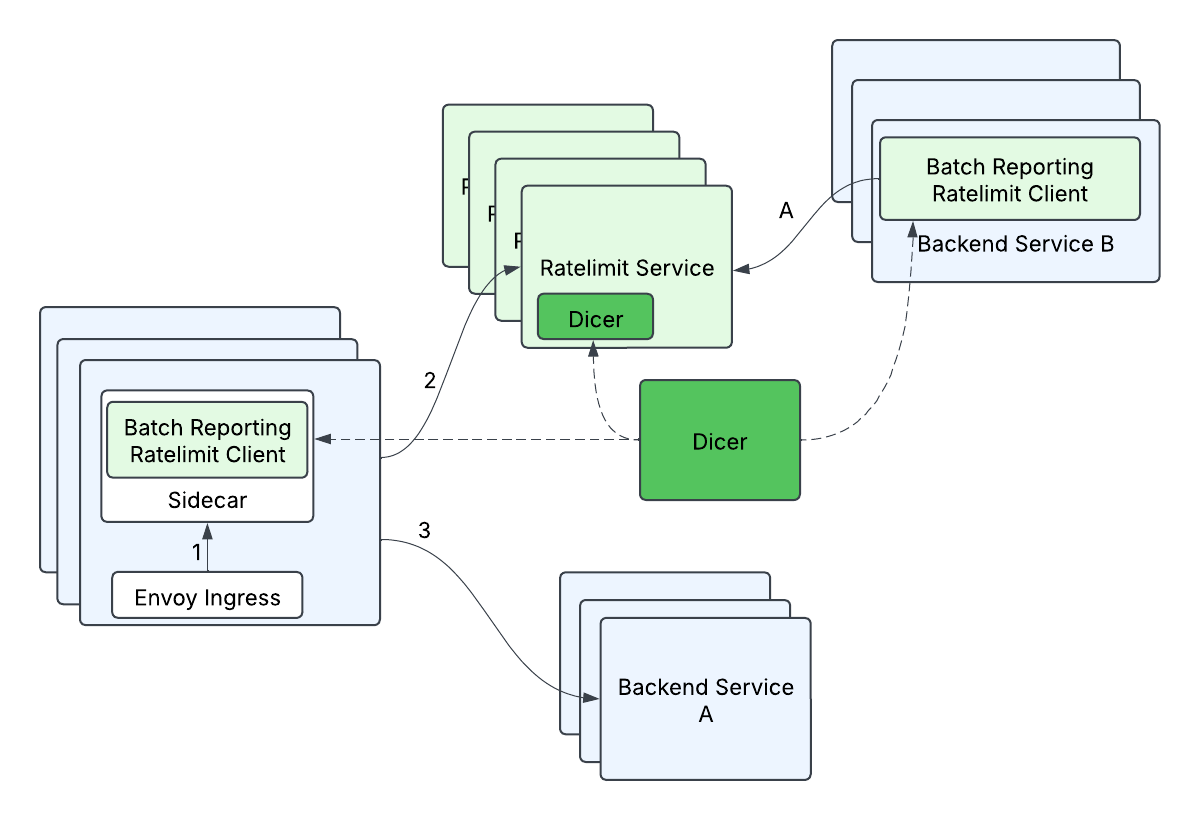
Por sorte, tivemos algumas pessoas incríveis se juntando ao Databricks, e elas estavam projetando o Dicer, uma tecnologia de autosharding que tornaria os serviços com estado mais fáceis de gerenciar, mantendo todos os benefícios de uma implantação de serviço sem estado. Isso nos permitiria controlar a latência do nosso servidor mantendo toda a contagem de limite de taxa na memória, porque os clientes poderiam pedir ao Dicer para mapear uma solicitação para um servidor de destino, e o servidor poderia validar com o Dicer que era o proprietário adequado de uma solicitação. Contar na memória é obviamente muito mais simples e rápido do que buscar essas informações de outra fonte, e o Dicer nos permitiu melhorar nossa latência de cauda do lado do servidor e escalar horizontalmente sem se preocupar com uma solução de armazenamento. ou seja, isso removeu nosso único ponto de falha (Redis) e nos deu solicitações mais rápidas ao mesmo tempo!
{kind=link}
Escalando Eficientemente
Embora entendêssemos como poderíamos resolver parte de nossos problemas, ainda não tínhamos uma maneira realmente boa de lidar com a quantidade massiva de solicitações previstas. Tivemos que ser mais eficientes e inteligentes sobre isso, em vez de jogar um grande número de servidores para o problema. No final das contas, não queríamos que uma solicitação do cliente se traduzisse em uma solicitação ao Serviço de Limitação de Taxa, porque em escala, milhões de solicitações ao Serviço de Limitação de Taxa seriam caras.
Quais eram nossas opções? Pensamos em muitas delas, mas algumas das opções que consideramos foram
- Pré-busca de tokens no cliente e tentativa de responder solicitações localmente.
- Agrupando um conjunto de solicitações, enviando e depois esperando por uma resposta para deixar o tráfego passar.
- Enviando apenas uma fração das solicitações (ou seja, Amostragem).
Nenhuma dessas opções era particularmente atraente; A pré-busca (a) tem muitos casos de borda durante a inicialização e quando os tokens se esgotam no cliente ou expiram. O agrupamento (b) adiciona atraso desnecessário e pressão na memória. E a Amostragem (c) só seria adequada para casos de alta qps, mas não em geral, onde poderíamos ter limites de taxa baixos.
O que acabamos projetando é um mecanismo que chamamos de relat�ório em lote, que combina dois princípios: 1) Nossos clientes não fariam chamadas remotas no caminho crítico do limite de taxa, e 2) nossos clientes realizariam limitação de taxa otimista, onde por padrão as solicitações seriam liberadas a menos que já soubéssemos que queríamos rejeitar essas solicitações específicas. Estávamos bem com a não garantia estrita dos limites de taxa como uma troca pela escalabilidade, porque os serviços de backend poderiam tolerar uma certa porcentagem de excesso de limite. Em um nível alto, o relatório em lote faz a contagem local no lado do cliente e periodicamente (por exemplo, 100ms) relata de volta as contagens para o servidor. O servidor informaria ao cliente se alguma das entradas precisasse ser limitada.
O fluxo de relatório em lote se parecia com isto:
- O cliente registra quantas solicitações permitiu (outstandingHits) e quantas solicitações rejeitou (rejectedHits)
- Periodicamente, um processo no cliente reportará as contagens coletadas para o servidor.
- Por exemplo.
KeyABC_SubKeyXYZ: outstandingHits=624, rejectedHits=857;KeyQWD_SubKeyJHP: outstandingHits=876, rejectedHits=0
- Por exemplo.
- O servidor retorna um array de respostas
- KeyABC_SubKeyXYZ: rejectTilTimestamp=..., rejectionRate=...
KeyQWD_SubKeyJHP: rejectTilTimestamp=..., rejectionRate=...
- KeyABC_SubKeyXYZ: rejectTilTimestamp=..., rejectionRate=...
Os benefícios desta abordagem foram enormes; poderíamos ter chamadas de limite de taxa praticamente sem latência, uma melhoria de 10x em comparação com algumas chamadas de latência de cauda, e transformar o tráfego de limite de taxa irregular em tráfego de qps (relativamente) constante! Combinado com a solução Dicer para limitação de taxa em memória, está tudo tranquilo a partir daqui, certo?
O Diabo está nos Detalhes
Embora tivéssemos uma boa ideia do objetivo final, houve muito trabalho de engenharia difícil para realmente torná-lo realidade. Aqui estão alguns dos desafios que encontramos ao longo do caminho, e como os resolvemos.
Alta Fanout
Porque precisávamos fragmentar com base no RateLimitGroup e dimensão, isso significava que uma única RateLimitRequest com N dimensões poderia se transformar em N solicitações, ou seja, uma solicitação típica de fanout. Isso poderia ser especialmente problemático quando combinado com relatórios em lote, já que uma única solicitação em lote poderia se espalhar para muitas (500+) chamadas remotas diferentes. Se não for tratado, a latência final do lado do cliente aumentaria drasticamente (de esperar apenas 1 chamada remota para esperar mais de 500 chamadas remotas), e a carga do lado do servidor aumentaria (de 1 solicitação remota no total para mais de 500 solicitações remotas no total). Otimizamos isso agrupando descritores por suas atribuições Dicer - descritores atribuídos à mesma réplica foram agrupados em uma única solicitação de lote de limite de taxa e enviados para o servidor de destino correspondente. Isso ajudou a minimizar o aumento nas latências finais do lado do cliente (algum aumento na latência final é aceitável, pois as solicitações em lote não estão no caminho crítico, mas sim processadas em uma thread de fundo), e minimiza a carga aumentada para o servidor (cada réplica do servidor lidará com no máximo 1 solicitação remota de uma réplica do cliente por ciclo de lote).
Precisão na Aplicação
Como o algoritmo de relatório em lote é tanto assíncrono quanto usa um intervalo baseado em tempo para relatar as contagens atualizadas para o Serviço de Limitação de Taxa, era muito possível que pudéssemos permitir muitas solicitações antes de podermos impor o limite de taxa. Mesmo que pudéssemos definir esses limites como imprecisos, ainda queríamos garantir que iríamos X% (por exemplo, 5%) acima do limite. Exceder excessivamente o limite poderia acontecer por dois motivos principais:
- O tráfego durante uma janela de loteamento (por exemplo. 100ms) poderia exceder a política de limite de taxa.
- Muitos de nossos casos de uso usaram o algoritmo de janela fixa e limites de taxa por segundo. Uma propriedade do algoritmo de janela fixa é que cada "janela" começa do zero (ou seja. reinicia e começa do zero), então poderíamos potencialmente exceder o limite de taxa a cada segundo, mesmo durante tráfego constante (mas alto)!
A maneira como resolvemos isso foi em três partes:
- Adicionamos uma taxa de rejeição na resposta do Serviço de Limitação de Taxa, para que pudéssemos usar o histórico passado para prever quando e quanto tráfego rejeitar no cliente.
rejectionRate=(estimatedQps-rateLimitPolicy)/estimatedQpsIsso usa a suposição de que o tráfego do próximo segundo será semelhante ao tráfego do segundo passado. - Adicionamos defesa em profundidade adicionando um limitador de taxa local do lado do cliente para cortar casos óbvios de tráfego excessivo imediatamente.
- Uma vez que tínhamos o autosharding implementado, implementamos um algoritmo de limitação de taxa token-bucket em memória, que trouxe alguns grandes benefícios:
- Agora poderíamos permitir rajadas controladas de tráfego
- Mais importante, o token-bucket "lembra" informações ao longo dos intervalos de tempo porque, em vez de reiniciar a cada intervalo de tempo como o algoritmo de janela fixa, ele pode contar continuamente, e até mesmo ficar negativo. Assim, se um cliente envia muitas solicitações, nós “lembramos” o quanto ele ultrapassou o limite e podemos rejeitar solicitações até que o balde seja reabastecido para pelo menos zero. Não conseguimos suportar este token bucket no Redis anteriormente porque o token-bucket precisava de operações bastante complexas no Redis, o que aumentaria nossas latências no Redis. Agora, porque o token-bucket não sofria de amnésia a cada intervalo de tempo, poderíamos nos livrar do mecanismo de taxa de rejeição.
- Token-bucket sem habilitar a funcionalidade extra de burst pode aproximar um algoritmo de janela deslizante, que é uma versão melhor da janela fixa que não sofre do problema de "reset".
Os benefícios da abordagem de token-bucket foram tão grandes que acabamos convertendo todos os nossos limites de taxa para token bucket.
Reconstruindo um Avião em Voo
Sabíamos o estado final que queríamos alcançar, mas isso exigia fazer duas mudanças independentes em um serviço crítico, nenhuma das quais garantia funcionar bem por si só. E lançar essas duas mudanças juntas não era uma opção, por razões técnicas e de gerenciamento de risco. Algumas das coisas interessantes que tivemos que fazer ao longo do caminho:
- Construímos um sidecar localhost para nosso ingresso envoy para que pudéssemos aplicar tanto o relatório em lote quanto o auto-sharding, porque o envoy é um código de terceiros que não podemos alterar.
- Antes de termos a limitação de taxa na memória, tínhamos que agrupar as gravações no Redis através de um script Lua para reduzir a latência de cauda das solicitações de relatório em lote, porque enviar descritores um a um para o Redis era muito lento com todas as viagens de ida e volta na rede, mesmo que tivéssemos mudado para execução em lote.
- Construímos um framework de simulação de tráfego com muitos padrões de tráfego diferentes e políticas de limite de taxa, para que pudéssemos avaliar nossa precisão, desempenho e escalabilidade ao longo desta transição.
{kind=link}
Estado Atual e Trabalho Futuro
Com a implementação bem-sucedida do relatório em lote e da limitação de taxa de token bucket em memória, vimos melhorias drásticas na latência de cauda (até 10x em alguns casos!) com crescimento sublinear no tráfego do lado do servidor. Nossos clientes de serviço interno estão particularmente felizes por não haver chamada remota quando eles fazem chamadas de limite de taxa, e que eles têm a liberdade de escalar independentemente do Serviço de Limitação de Taxa.
A equipe também tem trabalhado em outras áreas excitantes, como roteamento de malha de serviço e proteção contra sobrecarga de configuração zero, então fique ligado para mais postagens de blog! E a Databricks está sempre procurando por mais ótimos engenheiros que possam fazer a diferença, adoraríamos que você se juntasse a nós!
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.