Como as Tabelas de Sistema do Databricks ajudam os engenheiros de dados a alcançar uma observabilidade avançada
As System Tables fornecem a amplitude e a profundidade de que os engenheiros de dados precisam para simplesmente monitorar a integridade de seus pipelines de dados em escala, para workloads mais econômicos e confiáveis.
por Theresa Hammer
- Aprenda como as Tabelas de Sistema expõem a telemetria da plataforma como tabelas consultáveis, incluindo metadados e percepções de execução para os Lakeflow jobs e pipelines.
- Use consultas de exemplo para transformar essa telemetria em percepções sobre oportunidades de confiabilidade, custo e eficiência em escala para jobs do Lakeflow.
- Centralize essas percepções em uma visão operacional compartilhada e diária para equipes de engenharia de dados com o modelo de painel do Lakeflow.
O problema das 3 da manhã
São 3 da manhã e algo deu errado. O painel está desatualizado, um SLA não foi cumprido e todos estão tentando adivinhar qual parte da plataforma apresentou desvio. Talvez um job tenha ficado horas em execução sem um timeout. Talvez um pipeline tenha atualizado uma tabela que ninguém lê há meses. Talvez um cluster ainda esteja em um runtime antigo. Talvez a única pessoa que conhece o proprietário do job esteja de férias.
Estes são os padrões que sobrecarregam as equipes de dados: computação desperdiçada de pipelines não utilizados, lacunas de confiabilidade por falta de regras de integridade, problemas de higiene de runtimes desatualizados e atrasos causados por propriedade pouco clara. Eles aparecem silenciosamente, crescem lentamente e, de repente, tornam-se o que tira o sono do engenheiro de plantão.
Tabelas de Sistema do Databricks fornecem uma camada consistente para identificar esses problemas antecipadamente, expondo metadados de jobs, cronogramas de tarefas, comportamento de execução, histórico de configuração, linhagem, sinais de custo e propriedade em um só lugar.
Com as recém-lançadas Tabelas do sistema para Lakeflow Jobs, agora você tem acesso a esquemas expandidos que fornecem detalhes de execução e sinais de metadados mais ricos e permitem uma observabilidade mais avançada.
Visibilidade mais profunda e centralizada de todos os seus dados, facilitada com as System Tables
O que são as Tabelas do Sistema?
As System Tables do Databricks são um conjunto de tabelas somente leitura e gerenciadas pelo Databricks no catálogo system que fornecem dados operacionais e de observabilidade para sua conta. Elas vêm prontas para uso e cobrem uma ampla variedade de dados, incluindo Jobs, pipelines, clusters, faturamento, linhagem e muito mais.
Categoria | O que ele rastreia |
Jobs do Lakeflow | Configurações de jobs, definições de tarefas, cronogramas de execução |
Lakeflow Spark Declarative Pipelines | Metadados do pipeline, histórico de atualizações |
Cobrança | Uso, atribuição de custos por carga de trabalho |
Linhagem | Dependências de leitura/gravação no nível da tabela |
Clusters | Configurações e utilização da compute |
Por que as Tabelas do sistema são importantes para a observabilidade
As Tabelas de Sistema suportam análises entre workspaces dentro de uma região, permitindo que as equipes de engenharia de dados analisem facilmente qualquer comportamento de carga de trabalho e padrões operacionais em escala a partir de uma única interface consultável. Usando essas tabelas, os profissionais de dados podem monitorar centralmente a integridade de todos os seus pipelines, identificar oportunidades de economia de custos e identificar rapidamente as falhas para uma maior confiabilidade.
Algumas Tabelas de Sistema usam a semântica SCD Tipo 2, preservando o histórico completo de alterações ao inserir uma nova linha para cada atualização. Isso permite a auditoria de configuração e a análise histórica do estado da plataforma ao longo do tempo.
Tabelas do Sistema Lakeflow
Tabelas do Sistema Lakeflow armazenam dados dos últimos 365 dias e consistem nas seguintes tabelas.
Para obter uma lista completa das Tabelas do Sistema e seus relacionamentos, consulte a documentação.
Tabelas de observabilidade de jobs (Disponibilidade geral)
system.Lakeflow Jobs– Metadados SCD2 para jobs, incluindo configuração e tags. Útil para inventário, governança e análise de desvio de configuração.system.lakeflow.job_tasks– tabela SCD2 que descreve todas as tarefas de job, suas definições e dependências. Útil para entender as estruturas de tarefas em grande escala.system.lakeflow.job_run_timeline– Linha do tempo imutável de execuções de jobs com status, compute e tempo. Ideal para análise de SLA e de tendências de desempenho.system.lakeflow.job_task_run_timeline– Linha do tempo de execuções de tarefas individuais em cada job. Ajuda a identificar gargalos e problemas no nível da tarefa.
Tabelas de observabilidade de pipeline (Pré-visualização pública)
system.lakeflow.pipelines– Tabela de metadados SCD2 para pipelines SDP, permitindo visibilidade de pipeline entre workspaces e acompanhamento de alterações.system.lakeflow.pipeline_update_timeline– Logs de execução imutáveis para atualizações de pipeline, compatíveis com depuração e otimização históricas.
As Tabelas de Sistema do Lakeflow tiveram um rápido crescimento em popularidade, com dezenas de milhões de queries sendo executadas todos os dias, marcando um aumento de 17 vezes em relação ao ano anterior. Esse aumento destaca o valor que os engenheiros de dados obtêm das Tabelas de Sistema do Lakeflow, que se tornaram um componente crucial da observabilidade diária para muitos clientes do Databricks Lakeflow.
Vamos analisar os casos de uso agora possíveis com as Tabelas do Sistema de Jobs, recentemente expandidas e agora em disponibilidade geral.
System Tables na vida real: integridade operacional para jobs do Lakeflow
Como engenheiro de dados em uma equipe de plataforma central, você é responsável por gerenciar centenas de jobs em várias equipes. Seu objetivo é manter a plataforma de dados eficiente em custos, confiável e de alto desempenho, garantindo que as equipes sigam as melhores práticas operacionais e de governança.
Para isso, você começa a auditar seus Lakeflow jobs e pipelines com base em quatro objetivos principais:
- Otimize os custos: Identifique jobs agendados que atualizam datasets que nunca são usados downstream.
- Garanta a confiabilidade: Aplique timeouts e limites de Runtime para evitar Jobs descontrolados e violações de SLA.
- Mantenha a organização: verifique a consistência das versões de runtime e dos padrões de configuração.
- Atribua responsabilidade: Identifique os proprietários dos jobs para agilizar o acompanhamento e a correção.
Padrão 1: Encontrar jobs que produzem dados não utilizados
O problema: Jobs agendados são executados fielmente, atualizando tabelas que nenhum consumidor subsequente jamais lê. Essa costuma ser a maneira mais fácil de economizar custos, se você conseguir encontrá-los.
A abordagem: Una as tabelas do Lakeflow Jobs com as de linhagem e faturamento para identificar produtores sem consumidores, classificados por custo.
O que fazer a seguir: Analise os principais ofensores com seus proprietários. Alguns podem ser pausados com segurança imediatamente. Outros podem precisar de um plano de descontinuação se sistemas externos dependerem deles fora do Databricks.
Padrão 2: encontrar jobs sem timeouts ou limites de duração
O problema: Jobs sem timeouts podem ser executados indefinidamente. Uma tarefa travada consome compute por horas, ou até dias, antes que alguém perceba. Além de aumentar os custos, isso também pode causar violações de SLA. Portanto, você precisa identificar excedentes com antecedência e tomar medidas antes que os prazos ou processos downstream sejam afetados.
A abordagem: query as configurações de job atuais para encontrar configurações ausentes de tempo limite e limite de duração.
Próximos passos: Faça uma referência cruzada com os Runtimes de execução históricos de job_run_timeline para definir limites realistas. Um job que normalmente é executado em 20 minutos pode justificar um timeout de 1 hora e um limite de duração de 30 minutos. Um job que varia muito pode precisar primeiro de uma investigação.
Padrão 3: Detectar versões de runtime legadas
O problema: Runtimes obsoletos não recebem patches de segurança e melhorias de desempenho e estão sujeitos aos próximos prazos de EOL. Mas com centenas de Jobs, o acompanhamento de quem ainda está usando versões antigas é entediante.
A abordagem: query as configurações de tarefa do job para encontrar versões de runtime e sinalize tudo que estiver abaixo do seu limite.
Próximos passos: Priorize as atualizações com base nos cronogramas de EOL. Compartilhe esta lista com os proprietários dos jobs e acompanhe o progresso em follow-up queries.
Padrão 4: Identificar proprietários de jobs para remediação
O problema: Quando um job falha ou não está configurado corretamente, você precisa saber quem contatar para corrigir o problema.
A abordagem: Consulte (query) as tabelas do sistema para identificar facilmente os proprietários do job para cada ação que precisa ser realizada.
O que fazer a seguir: Entre em contato com os proprietários do job para atribuir a responsabilidade por problemas que exigem uma ação.
Juntos, esses padrões ajudam a otimizar custos, manter os dados atualizados, impor barreiras de proteção de confiabilidade e atribuir propriedade clara para remediação. Eles formam a base para a observabilidade operacional.
Juntando tudo: Operacionalizando percepções com dashboards
Executar essas consultas de forma ad-hoc é útil. Mas, para as operações do dia a dia, você vai querer uma shared view que toda a sua equipe possa consultar.
O painel do Lakeflow me dá uma visão de view dos Jobs em todos os meus Workspaces, não apenas no nível de custo, mas também para a higiene e as operações do pipeline: acompanhando gastos, identificando pipelines inativos, monitorando falhas e detectando oportunidades de otimização. - Zoe Van Noppen, Arquiteta de Soluções de Dados, Cubigo
Para começar, importe o dashboard para seu workspace. Para obter instruções passo a passo, consulte a documentação oficial.
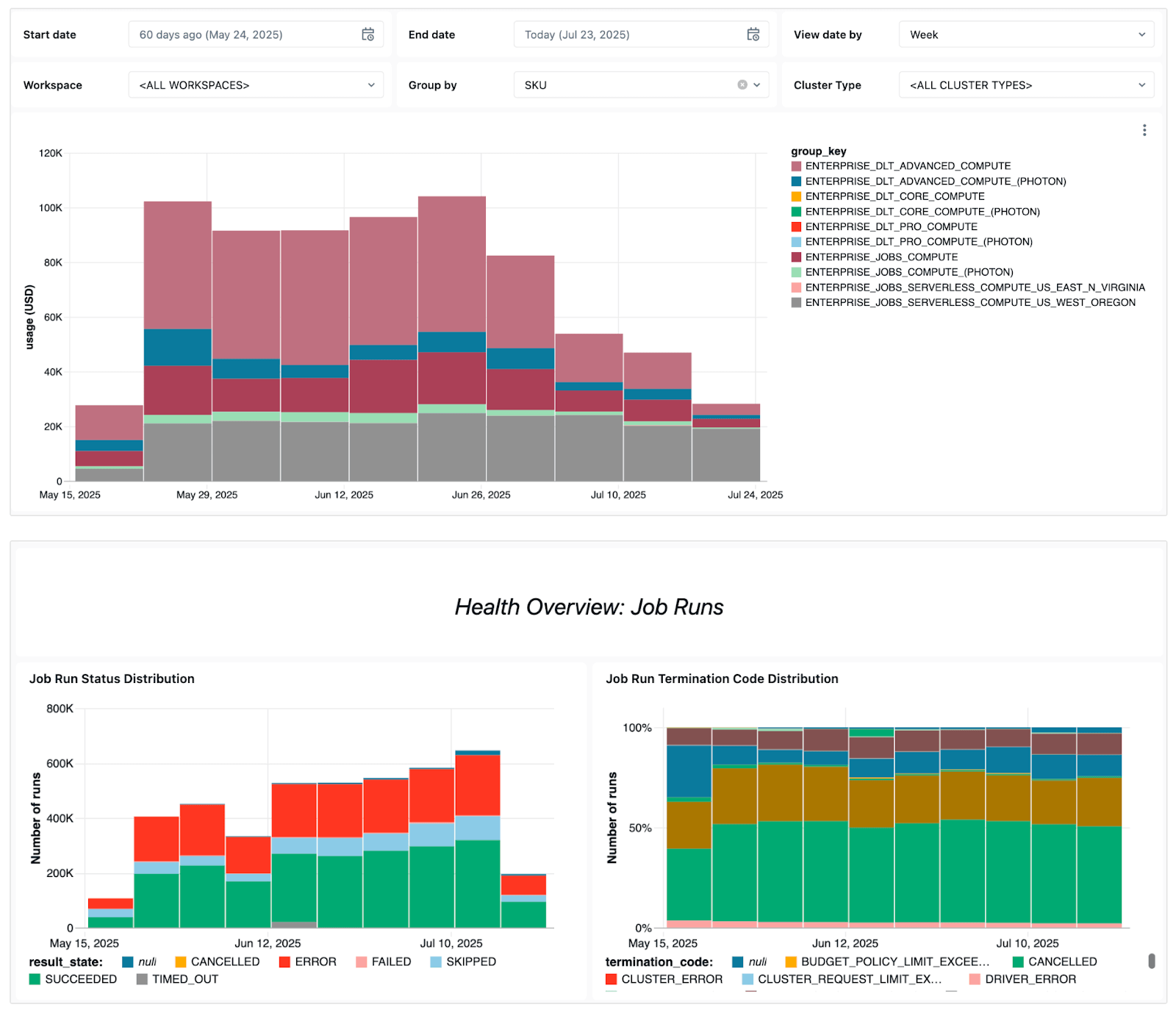
O painel apresenta vários sinais operacionais importantes, incluindo:
- Tendências de falhas - para que você veja quais jobs falham com mais frequência, as tendências gerais de erros e as mensagens de erro comuns.
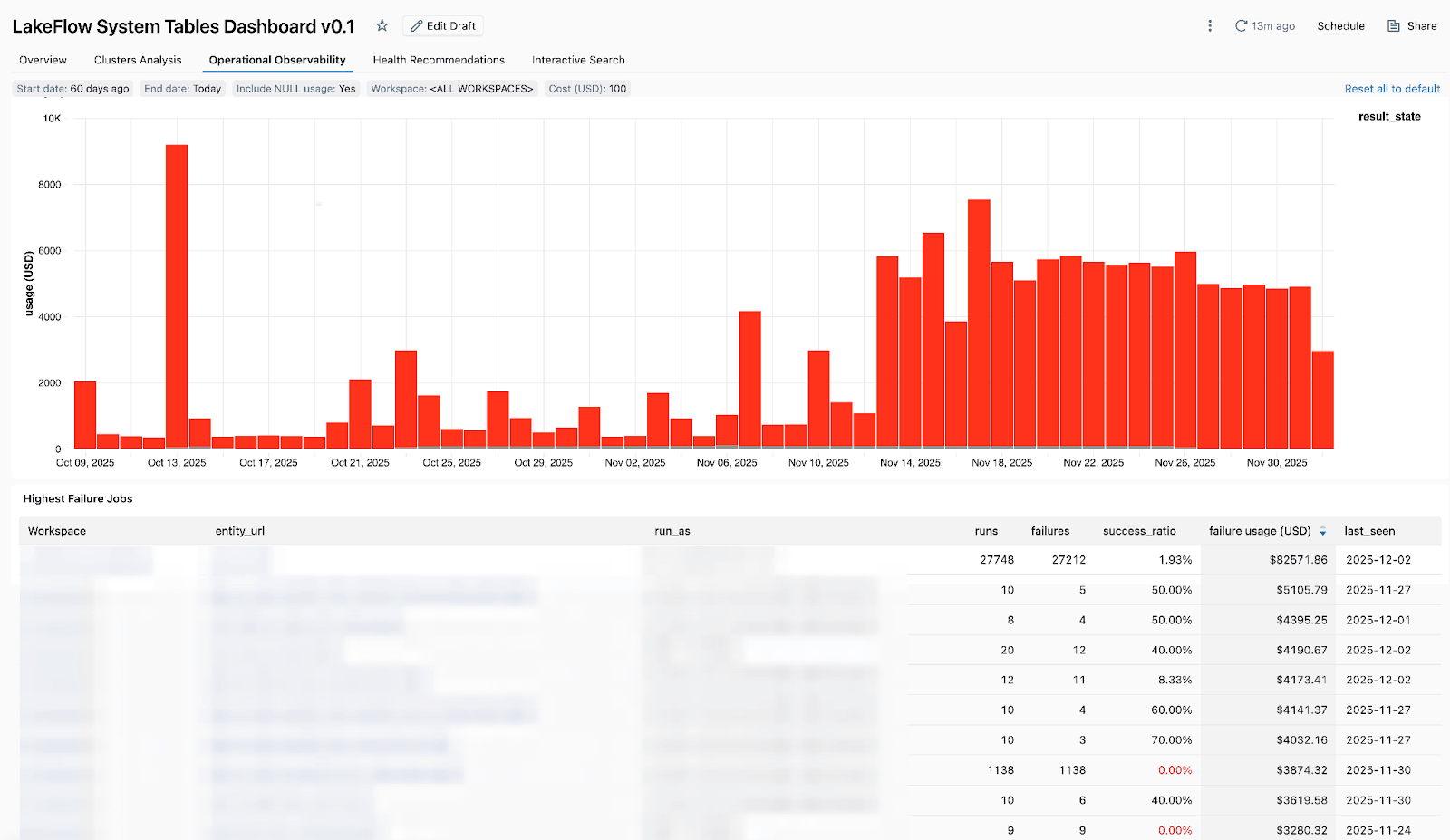
- Jobs de alto custo - para que você possa identificar os jobs mais caros e as execuções de jobs individuais nos últimos 30 dias ou ao longo do tempo. A tabela abaixo é classificada pelos jobs de maior custo durante o período selecionado e mostra suas tendências de custo ao longo do tempo.
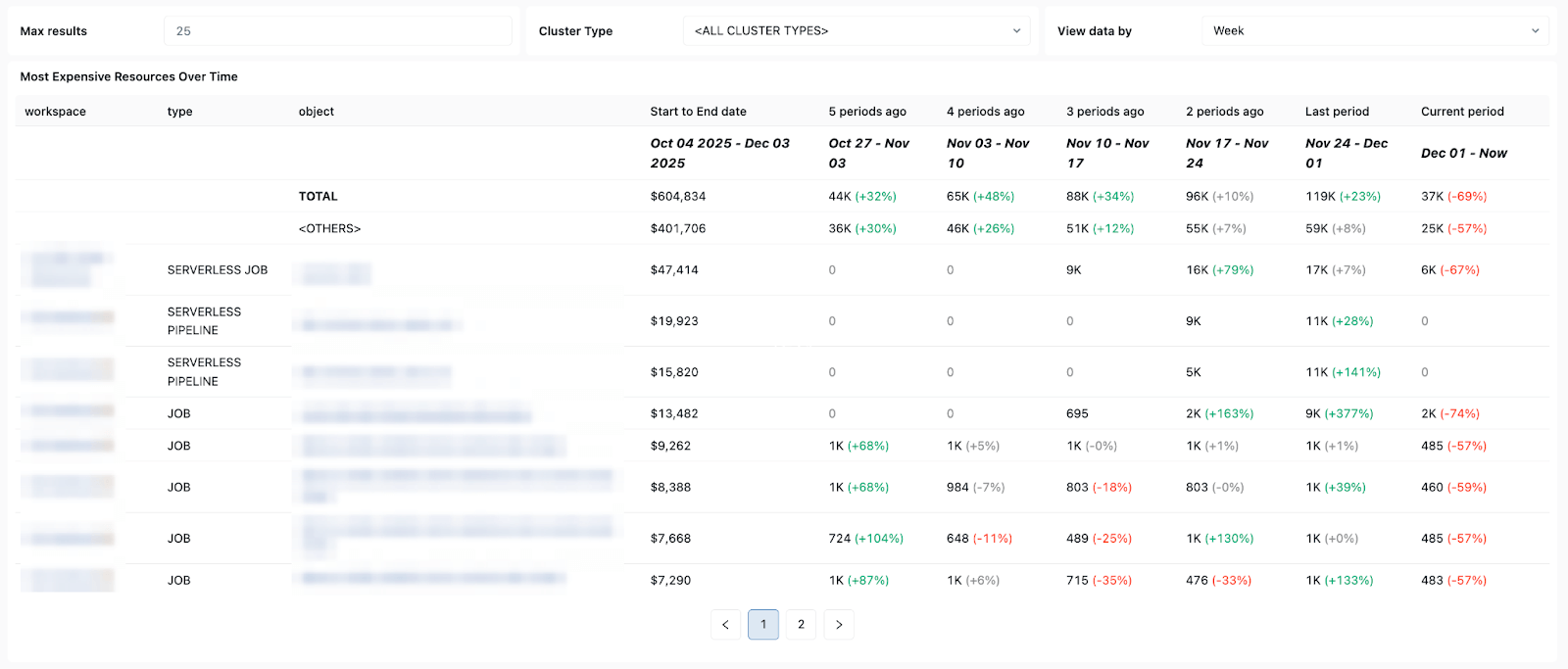
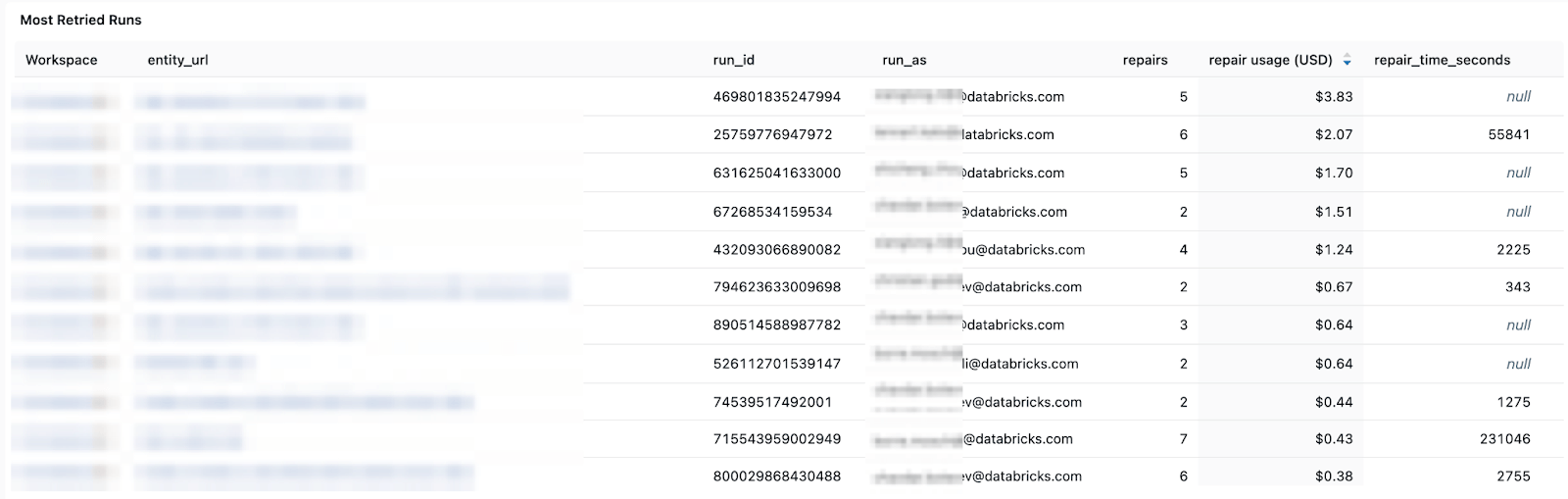
Padrões de custo e de novas tentativas - ajudando você a acompanhar as tendências de custo e o impacto de novas tentativas ou execuções de reparo no gasto total.
- Percepções de configuração - permitindo que você verifique a eficiência dos clusters, regras de integridade, timeouts e versões de Runtime para higiene operacional.
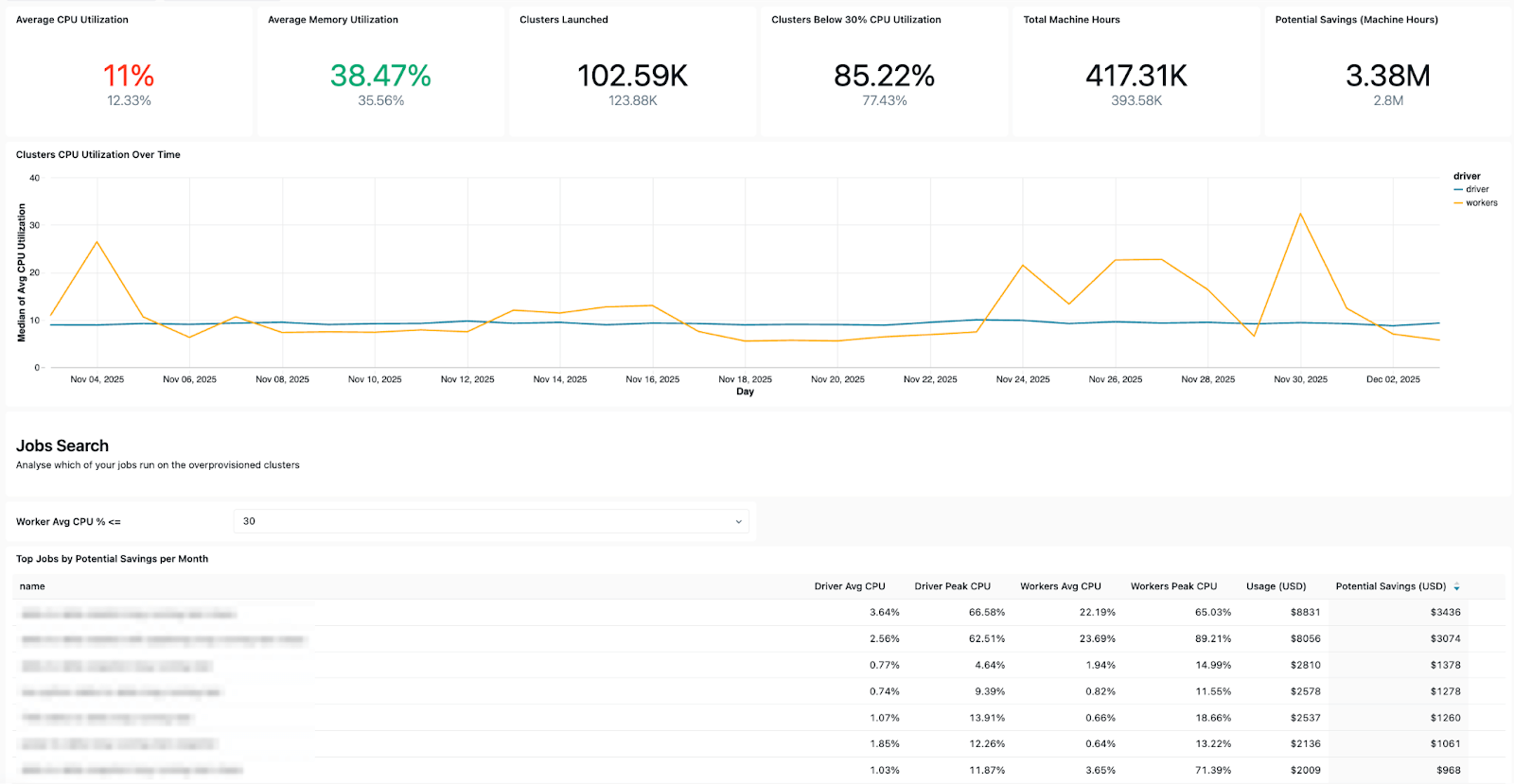
- Detalhes de propriedade - para que você possa encontrar facilmente os usuários “execução-as” e os criadores do job para saber com quem entrar em contato.
Em resumo, as System Tables do Databricks facilitam o monitoramento, a auditoria e a solução de problemas de LakeFlow Jobs de forma eficiente, em escala e entre Workspaces. Com visuais claros, simples e acessíveis de seus Jobs e pipelines disponíveis no modelo de dashboard, todo engenheiro de dados que usa o Lakeflow pode alcançar observabilidade avançada e garantir consistentemente pipelines prontos para produção, econômicos e confiáveis.
As System Tables transformam a telemetria da sua plataforma em um ativo consultável. Em vez de juntar sinais de cinco ferramentas diferentes, você escreve SQL em um esquema unificado e obtém respostas em segundos.
O seu eu das 3 da manhã vai agradecer.
Para saber mais sobre as Tabelas do Sistema, confira os seguintes recursos:
Novo no Databricks? Experimente o Databricks gratuitamente hoje mesmo!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.