Como a arquitetura lakehouse permanece resiliente a falhas na nuvem
por Jasraj Dange e Hans Norheim
- As cargas de trabalho de agentes estão remodelando os requisitos de confiabilidade da nuvem. Agentes criam bancos de dados 4x mais rápido que humanos, exigem infraestrutura serverless e de autoescalonamento, e tratam operações do plano de controle (como iniciar um banco de dados) como trabalho crítico do plano de dados. No Lakebase, agora iniciamos dezenas de milhões de bancos de dados por dia.
- A arquitetura do lakebase é construída para resiliência, não adaptada para ela. Computação Postgres sem estado em armazenamento com redundância de zona significa que instâncias podem ser substituídas instantaneamente sem hot standbys ou recuperação de falhas. Estamos separando operações do plano de controle de caminho quente em um serviço dedicado, minimizando dependências do provedor de nuvem e compartimentando cada região em células autônomas.
- Provamos a confiabilidade por meio de testes e medições, não de promessas. Cada lançamento passa por testes de caos com injeção de falhas nos níveis de processo, nó e zona de disponibilidade, validado contra ferramentas de código aberto como SqlLancer. Monitoramos a disponibilidade por banco de dados (não médias de frota) em relação a uma meta mensal de 99,99%, com atingimento publicado de forma transparente.
No último ano, os agentes esticaram os limites da infraestrutura de nuvem com novos padrões de uso:
- Maior taxa de transferência de operações do plano de controle: Agentes criam e gerenciam programaticamente bancos de dados, armazenamento, computação e outros componentes de infraestrutura em taxas muito mais altas do que humanos. No Databricks Lakebase, os agentes criam 4x mais bancos de dados do que os humanos.
- Mais demanda sob demanda: Infraestrutura serverless, de escalonamento automático (autoscaling) e de suspensão automática é a nova norma. Se o agente entra em modo de espera, por que pagar por infraestrutura provisionada?
- Gargalo de capacidade: A demanda por computação, GPUs e infraestrutura de nuvem está aumentando. A noção de que a nuvem tem capacidade “infinita” está mostrando rachaduras.
Isso é um desafio tanto para construtores de plataforma quanto para provedores de nuvem. Os planos de controle estão vendo aumentos significativos no volume de requisições para criar, gerenciar e escalar infraestrutura, estressando a confiabilidade. Alocar nova capacidade de nuvem nem sempre será bem-sucedido. Ao mesmo tempo, cargas de trabalho agentivas exigem confiabilidade em nível de plano de dados para operações centrais do plano de controle como parte de seus fluxos operacionais. Nos últimos meses, vimos agentes impulsionarem um aumento exponencial no início de bancos de dados e agora estamos iniciando dezenas de milhões de bancos de dados todos os dias.
A consequente onda de falhas e incidentes entre serviços de nuvem nos ensinou lições que informam nosso roteiro de confiabilidade, e queremos compartilhar como estamos tornando a arquitetura e o design do lakebase mais resilientes a falhas na nuvem. Alguns itens já estão em produção, outros estão em andamento.
Arquitetura de alta disponibilidade
Na base está nossa arquitetura de computação e armazenamento separados, onde a Alta Disponibilidade (HA) é um princípio de design central do sistema e não um complemento.
Computação Postgres sem estado (Stateless)
Ao contrário de muitas configurações de serviço de banco de dados Postgres na nuvem que são monolíticas e têm computação com estado, o Postgres na arquitetura lakebase é sem estado (stateless). Todos os dados duráveis residem em um serviço de armazenamento remoto, então o processo de computação não retém estado durável no disco local. Se o Postgres ou o hardware em que ele roda falhar, ele pode ser substituído instantaneamente sem replicar dados para um standby quente ou executar a recuperação de falhas usual do Postgres. Um standby quente em uma configuração monolítica requer uma cópia completa dos dados (não é gratuito), enquanto a recuperação de falhas deve reproduzir o log de gravação antecipada (write-ahead log) desde o último ponto de verificação, o que escala com a taxa de gravação no momento da falha e pode levar dezenas de minutos, dependendo da configuração. Como o conteúdo do banco de dados é armazenado em nosso serviço de armazenamento resiliente a zonas, uma instância Postgres de computação única no Lakebase tem disponibilidade significativamente melhorada em comparação com uma instância Postgres única com estado, sem o custo de uma instância de computação adicional de standby quente.
Para bancos de dados que exigem os mais altos níveis de disponibilidade, você pode configurar alta disponibilidade. Isso provisiona computações dedicadas em múltiplas zonas de disponibilidade para o seu banco de dados, garantindo que seu banco de dados permaneça disponível mesmo que o provedor de nuvem fique sem capacidade durante (ou como resultado de) o evento de falha. Essas computações podem ser adicionalmente utilizadas para escalar leituras.
Armazenamento redundante de zona para todos
Configurações monolíticas de Postgres são geralmente suportadas por dispositivos de bloco locais que raramente são redundantes de zona. Isso exige replicação física e réplicas de standby quente caras em múltiplas zonas de disponibilidade. No Lakebase e Neon, todos os bancos de dados, independentemente do nível e configuração, são suportados por armazenamento distribuído, redundante de zona e altamente disponível. Os dados são armazenados em armazenamento de objetos altamente durável e redundante de zona, e o desempenho é acelerado por caches NVMe SSD em múltiplas zonas de disponibilidade sem custo adicional para você.
O plano de controle é o novo plano de dados
Na arquitetura de serviço de banco de dados monolítico na nuvem, o plano de dados é a parte crítica do serviço. Ele é projetado para mais de 99,99% de disponibilidade e estabilidade estática. O plano de controle importa “apenas” para operações de gerenciamento. Com cargas de trabalho agentivas e sob demanda, a parte do plano de controle que inicia bancos de dados é efetivamente o plano de dados. Isso mudou a forma como pensamos sobre nossa arquitetura. Atualmente, nosso plano de controle lida com tudo, desde o início de bancos de dados até o faturamento. O primeiro é claramente mais crítico. Tivemos interrupções onde operações de manutenção em segundo plano consumiram recursos de inícios de bancos de dados sob demanda - isso claramente não está certo.
Atualmente, estamos trabalhando arduamente para separar as partes críticas do plano de controle em um serviço de controlador de plano de dados que lida apenas com operações de caminho quente (iniciar/suspender). Este serviço tem menos lógica de negócios, um conjunto estrito e mínimo de dependências externas (veja a próxima seção) e é projetado desde o início com resiliência, degradação graciosa e defesa em profundidade como prioridade máxima.
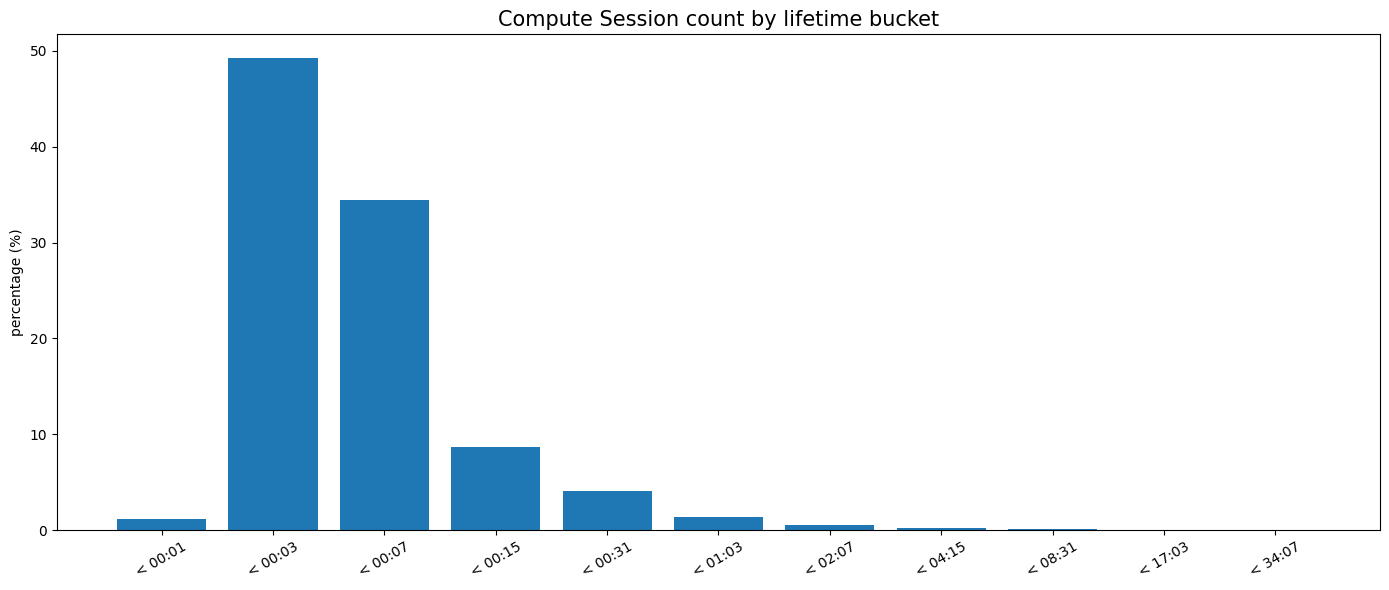
Para ilustrar o quão central o plano de controle é para o tráfego de banco de dados, podemos analisar os tempos de vida das sessões de computação (o tempo desde a retomada automática devido a uma conexão de entrada até o desligamento por inatividade). No Neon, 90% das sessões de computação para bancos de dados com suspensão automática são inferiores a 10 minutos.
Considere cuidadosamente as dependências do caminho crítico, incluindo os planos de controle do provedor de nuvem
Servir cargas de trabalho agentivas significa que a criação e retomada de bancos de dados devem ser altamente confiáveis. A confiabilidade está fortemente correlacionada com a cadeia de dependências e a quantidade de mecanismos envolvidos no fluxo. Em uma configuração tradicional com Postgres em VMs de provedores de nuvem, isso vai muito além do plano de dados:
- Plano de controle de computação do provedor de nuvem para provisionar VMs
- Capacidade de VM disponível (onde o provedor de nuvem controla a política de quem a obtém)
- Plano de controle de armazenamento de blocos do provedor de nuvem para provisionar armazenamento local
- Plano de controle de rede do provedor de nuvem para alocar IPs, configurar firewalls e rotas de rede para a nova VM
- Se usar Kubernetes (K8s) - uma dependência adicional nos serviços do sistema K8s.
No Lakebase, adotamos uma abordagem diferente que reduz drasticamente a quantidade de mecanismos do plano de controle envolvidos em fluxos críticos de banco de dados:
- Alocamos um pool de instâncias grandes (geralmente bare metal) do provedor de nuvem. Mantemos buffers para sustentar interrupções de provisionamento do provedor de nuvem.
- Construímos nossa própria camada de virtualização com escalonamento vertical (vertically autoscaling) que agenda múltiplas instâncias Postgres nessas instâncias de nuvem.
- Não dependemos de dispositivos de armazenamento de blocos da nuvem, mas sim armazenamos dados em nosso próprio armazenamento resiliente a zonas que é, em última análise, suportado em armazenamentos de objetos como S3 ou Azure Blob storage.
Muitos outros serviços no Databricks enfrentam os mesmos desafios de confiabilidade. É aqui que o Lakebase se beneficia de fazer parte do Databricks: O Databricks tem os meios e está investindo pesadamente na construção de uma plataforma comum para aumentar a confiabilidade de todos os produtos nas três principais nuvens.
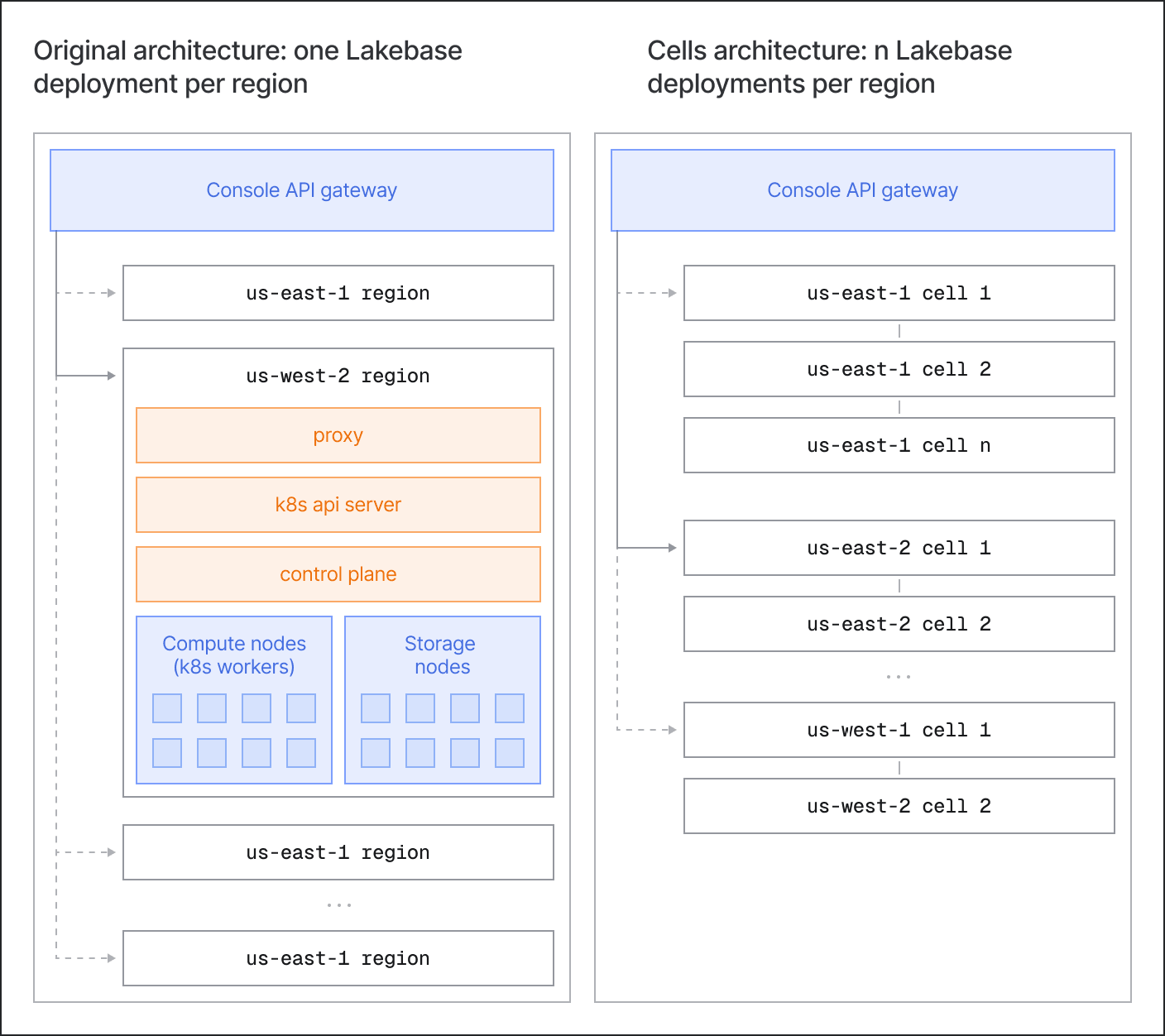
Compartimentalizar e conter o raio de explosão
Em vez de executar uma única implantação regional monolítica, o Lakebase compõe uma região a partir de uma ou mais células com formato idêntico. Uma célula é uma fatia completa e autônoma da pilha Neon e Lakebase: Kubernetes, plano de controle, computação e armazenamento.
Isso ajuda de duas maneiras:
- Escalabilidade: Para expandir uma região, adicionamos outra célula. Quando uma célula existente se aproxima dos limites de escalabilidade do Kubernetes e do plano de controle, a criação de novos projetos é roteada para uma célula recém-provisionada. As células são iniciadas rapidamente conforme a demanda aumenta.
- Contenção do raio de explosão: Mesmo com testes completos e proteções integradas, as coisas ainda dão errado em produção - problemas no plano de controle/serviços do sistema Kubernetes, regressões de código ou configuração, situações de DoS, etc. O limite da célula isola falhas e impede que a situação se espalhe, deixando as outras células na região atendendo ao tráfego normalmente.
Juntos, isso permite que nossa plataforma escale uma região elasticamente, limitando o raio de explosão de qualquer falha única. Durante um incidente em 8 de maio de 2026, quando a AWS teve problemas com uma Zona de Disponibilidade em us-east-1, uma das células teve problemas para fazer failover para nós saudáveis. O impacto foi contido naquela célula. As outras sete células na região fizeram failover corretamente, então o incidente afetou apenas ~13% dos bancos de dados na região. Neste caso, a arquitetura baseada em células reduziu o impacto em aproximadamente uma ordem de magnitude.
Simulação e injeção de falhas
A arquitetura e os princípios de redundância não valem muito a menos que funcionem na prática. Pode-se pensar em todos os modos de falha possíveis, mas a Lei de Murphy está viva e bem, e sistemas complexos sempre encontram uma maneira de surpreendê-lo. Cada lançamento do Lakebase passa por injeção de falhas e testes de caos antes de ir para produção. Implantamos o lançamento em um cluster real, o executamos com uma mistura de cargas de trabalho OLTP e OLAP agentivas e não agentivas em concorrência de nível de estresse, e então começamos a quebrar as coisas por baixo. Matamos processos, derrubamos nós, injetamos falhas de rede, limpamos o conteúdo do disco e reiniciamos componentes em loops, tudo enquanto a carga de trabalho continua em execução. Usamos failpoints liberalmente em nosso código para injetar erros difíceis de reproduzir, como uma falha no pior momento possível. Isso é impulsionado por um framework interno de injeção de falhas que pode ter como alvo um único processo ou coordenar falhas em todo o cluster em uma célula inteira.
Nossa barra de aprovação é mais rigorosa do que "o teste não deu erro". Utilizamos ferramentas de código aberto como SqlLancer e SqlSmith, juntamente com ferramentas internas semelhantes, para verificar o comportamento correto do Postgres. Enquanto a injeção de falhas está em execução, validamos a consistência interna dos dados, que nenhuma transação confirmada foi perdida e que cada componente se recupera para um estado consistente por conta própria.
Agora estamos levando isso um nível acima, de caos em nível de componente para simulações de queda de AZ inteira. Em um cluster real com cargas de trabalho em execução, desconectamos programaticamente a rede de uma zona de disponibilidade do restante do cluster e observamos como o sistema reage: com que rapidez o armazenamento muda para réplicas sobreviventes, com que rapidez as computações são transferidas para AZs saudáveis, como a camada de proxy redireciona conexões e quanto tempo qualquer banco de dados individual vê uma interrupção. Nosso objetivo é que nenhuma carga de trabalho fique inativa por mais de 30 segundos.
Medir, medir, medir
Lord Kelvin disse, “Se você não consegue medir, não é ciência”. Incorporamos o mesmo, e fazemos uma ciência de medir disponibilidade e confiabilidade. O status visível para o usuário que você vê em https://neonstatus.com/ é uma visão de alto nível. Internamente, medimos Indicadores de Nível de Serviço (SLIs) e definimos metas (SLOs) para todos os componentes do sistema e operações importantes, especialmente as voltadas para o usuário. Por exemplo, medimos:
- Disponibilidade do Banco de Dados: Quantos por cento do tempo cada banco de dados individual está disponível. Não medimos apenas a disponibilidade agregada da frota, porque um cliente individual não se importa se a frota teve ótima disponibilidade se o banco de dados dele estava inativo.
- Tempo de Inicialização do Banco de Dados: Quão rápido um banco de dados suspenso fica disponível quando você se conecta, ou quão rápido um banco de dados totalmente novo é iniciado.
- Troca/Failover de Banco de Dados: Frequência e latência. Tão infrequente quanto possível, e o mais rápido possível quando acontece.
- Armazenamento: Disponibilidade e latência de leituras de página e gravações duráveis do Postgres para o armazenamento. Isso nos diz se sua carga de trabalho está recebendo o que precisa.
- APIs do Plano de Controle: Taxas de sucesso e latência de operações importantes, como branching.
Nosso objetivo é que cada banco de dados exceda 99,99% de disponibilidade todos os meses. Medimos o quão perto estamos desse objetivo com atingimento: Quantos % dos bancos de dados da frota atingiram a meta. Abaixo está o atingimento de disponibilidade do Neon até agora em 2026 para bancos de dados ativos mensais.
Mês | Bancos de dados atingiram 99,95% | Bancos de dados atingiram 99,99% |
2026-01 | 99,96% | 99,85% |
2026-02 | 99,95% | 99,84% |
2026-03 | 99,96% | 99,81% |
2026-04 | 99,93% | 99,75% |
Confiabilidade e disponibilidade de ponta são de suma importância em sistemas operacionais. Estamos trabalhando duro para construir sua confiança em nosso serviço de banco de dados.
A Equipe
O trabalho de confiabilidade acima está sendo impulsionado por pessoas que passaram carreiras construindo e operando bancos de dados relacionais. Alguns deles:
- Jasraj Dange - Líder de engenharia no Lakebase, anteriormente liderou o trabalho em Desempenho, Escalabilidade do Azure SQL Database e tornou o Azure SQL Database uma plataforma robusta para Aplicações.
- Hans Norheim - Focado na disponibilidade e confiabilidade do Lakebase, passou 13 anos na Microsoft trabalhando no SQL Server e Azure SQL Database, incluindo a tecnologia de hot patching que permite atualizar o SQL Server sem tempo de inatividade, e a orquestração de atualização que mantém o Azure SQL Database em seu SLA de 99,995% de uptime.
- Stas Kelvich - Agora trabalhando no Lakebase após co-fundar a Neon. Antes da Neon, ele trabalhou em internos do Postgres na Postgres Professional por cinco anos, incluindo replicação multi-master tolerante a falhas com commit de quórum, isolamento de snapshot entre nós usando relógios levemente sincronizados, e melhorias no two-phase commit e replicação lógica.
- John Spray - Liderando o Armazenamento do Lakebase. Anteriormente liderou armazenamento e computação, impulsionando melhorias chave para escala, como sharding. Antes disso, trabalhou com armazenamento e sistemas distribuídos na Redpanda, Red Hat (Ceph) e Intel.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.