Como migrar do Apache Airflow® para o Databricks Lakeflow Jobs
Um guia prático mapeando práticas comuns do Airflow para o Databricks Lakeflow Jobs com exemplos de código lado a lado.
- Aprenda como padrões comuns de orquestração do Apache Airflow se mapeiam diretamente para os recursos do Lakeflow Jobs, o orquestrador integrado do Databricks.
- Entenda como o fluxo de controle, gatilhos, parâmetros e execução dinâmica funcionam quando a orquestração é integrada ao lakehouse.
- Use exemplos de código "copiar e colar" para migrar DAGs reais do Airflow para o Lakeflow Jobs incrementalmente.
No post anterior, De Apache Airflow® a Lakeflow: Orquestração Orientada a Dados, a orquestração foi redefinida em torno de dados e do lakehouse, em vez de agendadores externos. Este post se baseia nessa fundação e foca nos detalhes de execução para equipes que já executam o Airflow em produção e desejam migrar para o orquestrador nativo da Databricks, Lakeflow Jobs.
Este guia foi escrito tanto para profissionais que migram do Airflow quanto para agentes de programação que geram fluxos de trabalho do Lakeflow Jobs. O objetivo é mostrar como esses mesmos fluxos de trabalho podem ser expressos naturalmente quando a orquestração faz parte do próprio lakehouse dentro do Databricks.
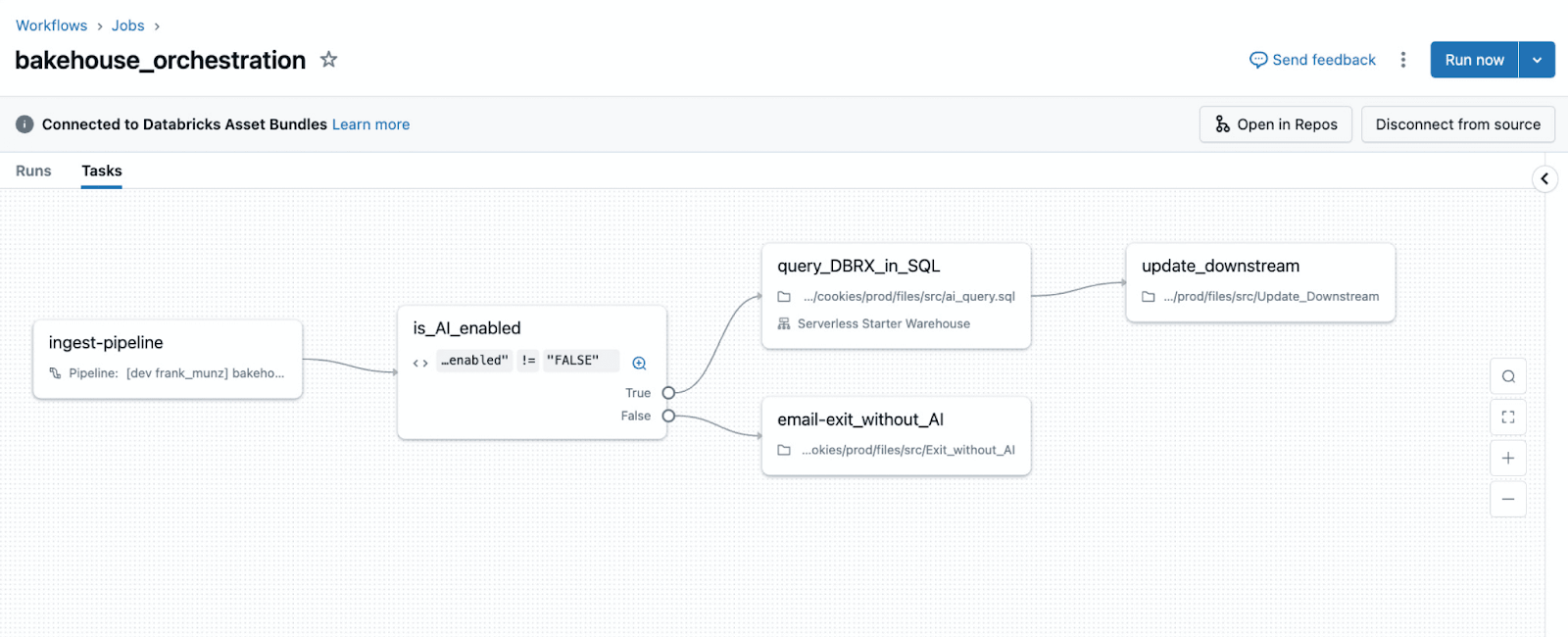
Mapa de migração do Airflow para Lakeflow Jobs
A tabela abaixo resume como os padrões comuns de orquestração do Airflow se traduzem para o Lakeflow Jobs e se a migração é uma tradução direta ou um refator conceitual.
Padrão do Airflow | Uso principal | Equivalente no Lakeflow Jobs | Orientação de migração |
XComs | Passar metadados de controle pequenos entre tarefas | Use valores de tarefa para metadados pequenos; mova quaisquer dados reais para tabelas do Unity Catalog | |
Sensores | Aguardar arquivos ou condições | Gatilhos de chegada de arquivo / gatilhos de atualização de tabela | Substitua sensores de polling por gatilhos integrados |
Backfills | Reexecutar para datas históricas | Job backfills + parâmetros | Trate o tempo como dado, use backfills parametrizados |
Ramificação | Execução condicional de tarefas | Tarefas de condição (if/else) | Substitua task.branch por tarefas If-Else |
Mapeamento dinâmico de tarefas | Fan-out em tempo de execução | Tarefas For-each | Use for-each quando o número de tarefas depender de dados em tempo de execução |
Estratégia de migração: incremental, não tudo de uma vez
A maioria das equipes migra incrementalmente em vez de substituir o Airflow por completo. Abordagens comuns incluem:
- Começar com fluxos de trabalho autônomos ou orientados a eventos
- Migrar gatilhos de chegada de arquivo e orientados a dados precocemente
- Manter pipelines Airflow estáveis inalterados inicialmente
- Evitar reescritas de jobs maduros e de baixo risco
O Lakeflow Jobs foi projetado para coexistir durante a migração e assumir responsabilidades de orquestração onde agrega mais valor.
Checklist
XComs com metadados pequenos → valores de tarefa; XComs com dados → tabelas ou volumes do Unity Catalog.
- Sensores/ativos de arquivo → gatilhos de chegada de arquivo ou atualização de tabela onde os dados estão no UC.
Macros de data de execução (
ds, etc.) → parâmetros explícitos + execuções de backfill.Ramificação (
@task.branch) → tarefas de condição.Mapeamento dinâmico de tarefas → tarefas for-each onde o fan-out é orientado por dados.
(Opcional) Jobs e esquemas gerenciados via Python Asset Bundles para ambientes consistentes.
Visão geral do Lakeflow Jobs
Ao migrar do Airflow, é útil internalizar algumas suposições centrais que moldam como o Lakeflow Jobs funciona:
Plano de controle vs. plano de dados
Operações no plano de dados (consultas, leituras, gravações e transformações) impulsionam o uso de computação. Operações do plano de controle, como gatilhos, valores de tarefa e parâmetros, não.
Jobs são a unidade de orquestração
- Jobs encapsulam tarefas e dependências; a coordenação entre jobs geralmente usa dados (tabelas, arquivos), não sinais entre DAGs
- Isso muda o design de “DAG falando com DAG” para “produtor escreve uma tabela, job consumidor dispara quando essa tabela muda”.
- Uma tarefa Run Job existe para casos em que a invocação de job para job é intencional, mas complementa em vez de substituir o modelo de coordenação orientado por dados.
Gatilhos são de primeira classe
- Gatilhos de chegada de arquivo e atualização de tabela são recursos integrados, não implementados por meio de sensores de longa duração.
- Isso muda a orquestração de polling para orientada a eventos por padrão.
Essas suposições explicam por que alguns padrões do Airflow se traduzem diretamente, enquanto outros são intencionalmente simplificados ou substituídos.
Etapas de migração
1. XComs para valores de tarefa para controle, tabelas para dados
Airflow: XComs para metadados de controle pequenos
No Apache Airflow, os XComs são usados para passar pequenos pedaços de metadados entre tarefas dentro de uma execução de DAG. Um exemplo mínimo do Airflow que passa um valor pequeno entre tarefas:
Isso funciona bem para pequenos IDs, valores, flags e contagens, mas se torna difícil de raciocinar quando muitas tarefas dependem de XComs ou quando grandes cargas úteis são enviadas.
Lakeflow: valores de tarefa para controle, tabelas para dados
No Lakeflow Jobs, os valores de tarefa desempenham o papel de XCom para metadados de controle. Jobs e tarefas são tipicamente definidos por meio de pacotes de ativos, e suas implementações residem em notebooks ou arquivos Python. Snippet do pacote (Python) definindo duas tarefas e uma dependência:
Notebook do produtor:
Notebook do consumidor:
Os valores das tarefas ficam visíveis na interface do Lakeflow Jobs por execução e são limitados a cargas úteis pequenas, tornando-os ideais para flags, contadores e IDs. Para objetos maiores ou saídas reutilizáveis, as tarefas devem gravar em tabelas ou visualizações do Unity Catalog:
💡 Regra geral: Use valores de tarefas apenas para metadados de controle; coloque qualquer coisa que pareça dados em tabelas, visualizações ou volumes.
Dicas de migração
- XComs simples → valores de tarefas.
- XComs que transportam dataframes ou JSON grandes → leituras/gravações no Unity Catalog em vez disso.
- Evite reproduzir DAGs com muitos XComs; confie no lakehouse como estado compartilhado.
2. Sensores e ativos para gatilhos de arquivos e tabelas
Airflow: sensores de arquivo e ativos
Padrão típico do Airflow para um pipeline orientado por arquivos:
Isso mantém um slot de worker ocupado sondando e muitas vezes se combina com o rastreamento de ativos personalizado quando vários consumidores dependem dos mesmos dados.
Lakeflow: gatilhos de chegada de arquivo
Trecho mostrando um gatilho de chegada de arquivo
Implementação do notebook
A plataforma gerencia o estado do gatilho, debounce e cooldown, e você não precisa mais de sensores de longa duração ou agendadores externos para monitorar arquivos.
Lakeflow: gatilhos de atualização de tabela (agendamento no estilo de ativo)
Quando os produtores gravam em tabelas do Unity Catalog, os consumidores podem acionar atualizações de tabela em vez de agendamentos baseados em tempo.
💡Regra geral: Acione trabalhos em chegadas de arquivos ou atualizações de tabelas sempre que possível; use agendamentos apenas quando realmente precisar deles.
Dicas de migração
- Sensores de arquivo → gatilhos de chegada de arquivo em locais ou volumes do UC.
- Registros de ativos → tabelas do Unity Catalog com gatilhos de atualização de tabela.
- Eventos não de dados → gatilhos externos explícitos ou parâmetros.
3. Datas de execução para parâmetros e execuções de backfill
Airflow: data de execução e ds
O Airflow incentiva a lógica de modelagem com datas de execução:
Backfills são impulsionados pelo agendador do Airflow e datas de execução; a lógica depende implicitamente do conceito de tempo do agendador.
Lakeflow: parâmetros explícitos e backfill
No Lakeflow Jobs, a “data de execução lógica” deve ser modelada como um parâmetro. Definição do trabalho (bundles) com um parâmetro:
Nota: você também pode usar {{ job.trigger.time.iso_date }} se quiser usar o estilo Airflow {{ds}} ou {{ execution_date }} em vez de dados codificados no exemplo acima.
SQL usa o parâmetro:
Para fazer backfill, você define um conjunto de valores de parâmetros e executa backfills sobre eles na interface do usuário ou via API, em vez de depender do catchup implícito do agendador. Os parâmetros são definidos uma vez e substituídos no momento da execução ao acionar uma execução de backfill
💡Regra geral: Trate o tempo como dados; modele-o como um parâmetro, passe-o explicitamente para as tarefas e impulsione backfills por meio de intervalos de parâmetros.
Dicas de migração
- Substitua
{{ ds }}e macros relacionadas por parâmetros (por exemplo, :run_date). - Torne as tarefas idempotentes para um determinado conjunto de parâmetros para que os backfills permaneçam seguros.
- Use execuções de backfill do Lakeflow em vez de recriar a lógica de catchup orientada pelo agendador.
4. Ramificação e mapeamento dinâmico para tarefas de condição e for-each
Airflow: ramificação e mapeamento dinâmico de tarefas
Ramificação com @task.branch:
Mapeamento dinâmico de tarefas para fan-out em tempo de execução usando expand():
Lakeflow: tarefas condicionais
Jobs do Lakeflow usam tarefas condicionais para ramificação orientada por dados
check_quality notebook emite um valor de tarefa:
O gráfico mostra o branch explicitamente, e a lógica de decisão é expressa por meio de dados (valores de tarefa) em vez de fluxo de controle Python incorporado.
💡Regra geral: Use tarefas condicionais quando uma expressão booleana sobre parâmetros ou valores de tarefa determinar o caminho.
Lakeflow: tarefas for-each para fan-out em tempo de execução
Tarefas For-each implementam fan-out quando a contagem de tarefas depende de dados em tempo de execução.
generate_items notebook:
process_item notebook vê o item atual como {{input}} (ou variável de tempo de execução equivalente, dependendo do wrapper de linguagem).
💡Regra geral: Use for-each quando o fan-out é impulsionado por dados em tempo de execução; mantenha as tarefas estáticas quando o fan-out for fixo no momento do design.
Dicas de migração
@task.branch→ tarefas condicionais usando valores de tarefa ou parâmetros.- Mapeamento dinâmico de tarefas → tarefas for-each impulsionadas por valores de tarefa ou tabelas.
- Metadados de iteração grandes → tabelas/volumes; IDs/índices pequenos → valores de tarefa.
5. (Opcional) Geração programática com Python Asset Bundles
Muitas implantações do Airflow geram DAGs dinamicamente (um DAG por tabela ou arquivo SQL) e gerenciam diferenças de ambiente por meio de convenções e scripts. Python Asset Bundles oferecem uma maneira estruturada de gerar jobs e recursos relacionados programaticamente.
Exemplo: um job por arquivo SQL:
Você pode combinar isso com mutadores para ajustar notificações, identidades de execução ou retentativas por ambiente, centralizando padrões enquanto mantém as definições de job em Python.
💡 Regra geral: Use a geração programática para codificar convenções de plataforma, não para ocultar hacks pontuais.
Próximos passos
Se você está executando o Airflow hoje, escolha um DAG que dependa de sensores, XComs ou mapeamento dinâmico de tarefas e o reimplemente usando um gatilho, uma tarefa for-each e parâmetros explícitos. Isso geralmente é suficiente para internalizar o modelo mental do Lakeflow Jobs.
Clone e execute os exemplos de trabalho completos usados neste guia
Saiba mais sobre orquestração data-first
Explore a documentação do Lakeflow Jobs
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.