Como a UiPath construiu um pipeline ETL em tempo real escalável no Databricks
por Haowen Zhang, Beichen Xing e Chris Lawson
- Por que a UiPath reconstruiu sua arquitetura de streaming
- Como o Spark Structured Streaming no Databricks ajudou a simplificar e escalar
- Li�ções aprendidas em latência, confiabilidade e garantias de entrega
Cumprir a promessa de automação agente em tempo real requer uma base de dados rápida, confiável e escalável. Na UiPath, precisávamos de uma arquitetura de streaming moderna para sustentar produtos como Maestro e Insights, permitindo visibilidade quase em tempo real nas métricas de automação à medida que se desdobram. Essa jornada nos levou a unificar o processamento em lote e o streaming no Azure Databricks usando o Apache Spark™ Structured Streaming, possibilitando análises de baixa latência e custo-eficientes que suportam a tomada de decisões agente em toda a empresa.
Este blog detalha a abordagem técnica, as compensações e o impacto dessas melhorias.
Com o streaming baseado em Databricks, alcançamos latência de evento para armazém em menos de um minuto, ao mesmo tempo que oferecemos uma arquitetura simplificada e escalabilidade à prova de futuro, estabelecendo o novo padrão para o processamento de dados orientado a eventos em toda a UiPath.
Por que o Streaming é importante para o UiPath Maestro e UiPath Insights
Na UiPath, produtos como Maestro e Insights dependem fortemente de dados oportunos e confiáveis. Maestro atua como a camada de orquestração para nossa plataforma de automação agente; coordenando agentes de IA, robôs e humanos com base em eventos em tempo real. Seja reagindo a um gatilho do sistema, executando um fluxo de trabalho de longa duração, ou incluindo uma etapa humana no loop, Maestro depende de um processamento de sinal rápido e preciso para tomar as decisões corretas.
O UiPath Insights, que alimenta o monitoramento e análises em todas essas automações, adiciona outra camada de demanda: capturando métricas-chave e sinais comportamentais em tempo quase real para identificar tendências, calcular o ROI e apoiar a detecção de problemas.
Entregar esses tipos de resultados - orquestração reativa e observabilidade em tempo real - requer uma arquitetura de pipeline de dados que não seja apenas de baixa latência, mas também escalável, confiável e sustentável. Essa necessidade é o que nos levou a repensar nossa arquitetura de streaming no Azure Databricks.
Construindo a Fundação de Dados em Streaming
Cumprir a promessa de análises poderosas e monitoramento em tempo real requer uma base de pipelines de dados escaláveis e confiáveis. Ao longo dos últimos anos, desenvolvemos e expandimos várias pipelines para suportar novos recursos de produto e responder às crescentes exigências de negócios. Agora, temos a oportunidade de avaliar como podemos otimizar esses pipelines para não apenas economizar custos, mas também ter melhor escalabilidade e garantia de entrega pelo menos uma vez para suportar dados de novos serviços como o Maestro.
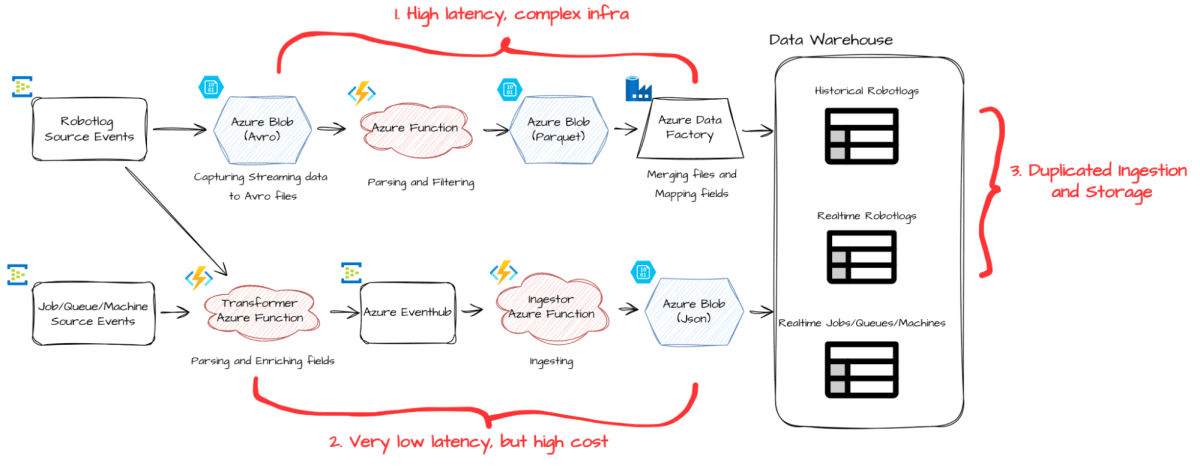
{kind=link}
Embora nossa configuração anterior (mostrada acima) tenha funcionado bem para nossos clientes, também revelou áreas para melhoria:
- O pipeline de processamento em lote introduziu até 30 minutos de latência e dependia de uma infraestrutura complexa
- O pipeline em tempo real entregou dados mais rapidamente, mas com um custo mais alto.
- Para Robotlogs, nosso maior conjunto de dados, mantivemos caminhos separados de ingestão e armazenamento para processamento histórico e em tempo real, resultando em duplicação e ineficiência.
- Para suportar o novo pipeline ETL para o UiPath Maestro, um novo produto UiPath, precisaríamos alcançar a garantia de entrega pelo menos uma vez.
Para enfrentar esses desafios, realizamos uma grande reformulação arquitetônica. Combinamos os processos de ingestão em lote e em tempo real para Robotlogs em uma única pipeline, e reestruturamos a pipeline de ingestão em tempo real para ser mais eficiente em termos de custo e escalável.
Por que Spark Structured Streaming no Databricks?
Quando começamos a simplificar e modernizar nossa arquitetura de pipeline, precisávamos de um framework que pudesse lidar tanto com cargas de trabalho em lote de alto rendimento quanto com dados em tempo real de baixa latência - sem introduzir sobrecarga operacional. O Spark Structured Streaming (SSS) no Azure Databricks foi uma escolha natural.
Construído em cima do Spark SQL e Spark Core, o Structured Streaming trata os dados em tempo real como uma tabela sem limites - permitindo-nos reutilizar construções de lotes do Spark familiar enquanto ganhamos os benefícios de um motor de streaming escalável e tolerante a falhas. Este modelo de programação unificado reduziu a complexidade e acelerou o desenvolvimento.
Já havíamos aproveitado o Spark Structured Streaming para desenvolver nosso recurso de Alerta em tempo real, que utiliza processamento de fluxo com estado no Databricks. Agora, estamos expandindo suas capacidades para construir nossa próxima geração de pipelines de ingestão em tempo real, permitindo-nos alcançar baixa latência, escalabilidade, eficiência de custo e garantias de entrega de pelo menos uma vez.
A Próxima Geração de Ingestão em Tempo Real
Nossa nova arquitetura, mostrada abaixo, simplifica dramaticamente o processo de ingestão de dados, consolidando componentes anteriormente separados em um pipeline unificado e escalável usando Spark Structured Streaming no Databricks:
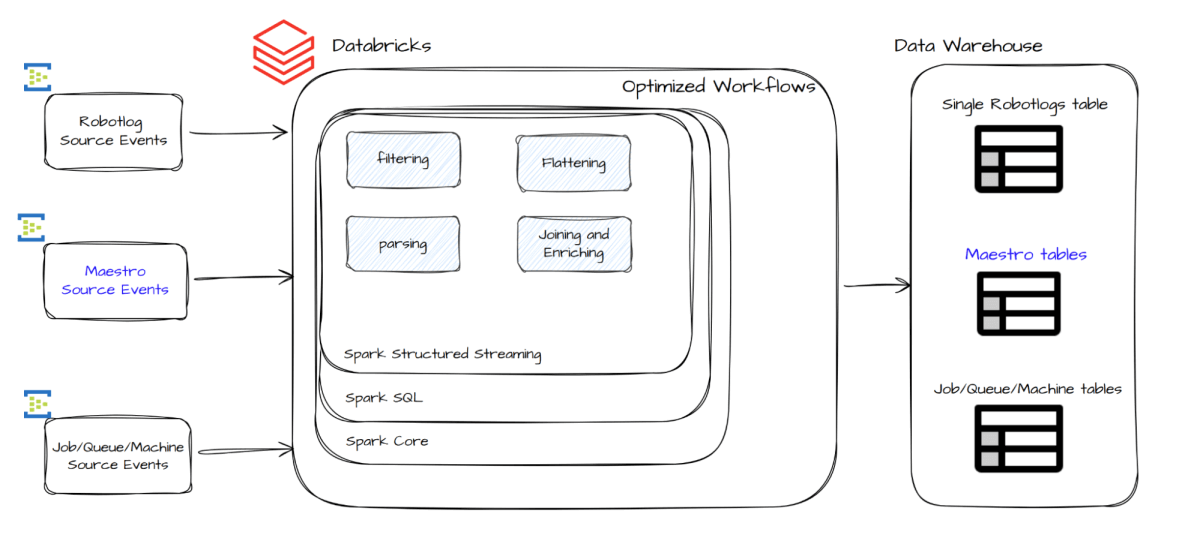
No cerne deste novo design está um conjunto de trabalhos de streaming que lêem diretamente das fontes de eventos. Esses trabalhos realizam análise, filtragem, achatamento e, mais criticamente, unem cada evento com dados de referência para enriquecê-lo antes de escrever em nosso armazém de dados.
Orquestramos esses trabalhos usando Databricks Lakeflow Jobs, que ajuda a gerenciar tentativas e recuperação de trabalhos em caso de falhas transitórias. Esta configuração simplificada melhora tanto a produtividade do desenvolvedor quanto a confiabilidade do sistema.
Os benefícios dessa nova arquitetura incluem:
- Eficiência de custo: Economiza COGS reduzindo a complexidade da infraestrutura e o uso de computação
- Baixa latência: A latência de ingestão tem uma média de cerca de um minuto, com a flexibilidade para reduzir ainda mais
- Escalabilidade à prova de futuro: A taxa de transferência é proporcional ao número de núcleos, e podemos escalar infinitamente
- Nenhum dado perdido: Spark faz o trabalho pesado de recuperação de falhas, suportando a entrega de pelo menos uma vez.
- Com a deduplicação do sink downstream no futuro desenvolvimento, será capaz de alcançar a entrega exatamente uma vez
- Desenvolvimento rápido graças à API DataFrame do Spark
- Arquitetura simples e unificada
Baixa latência
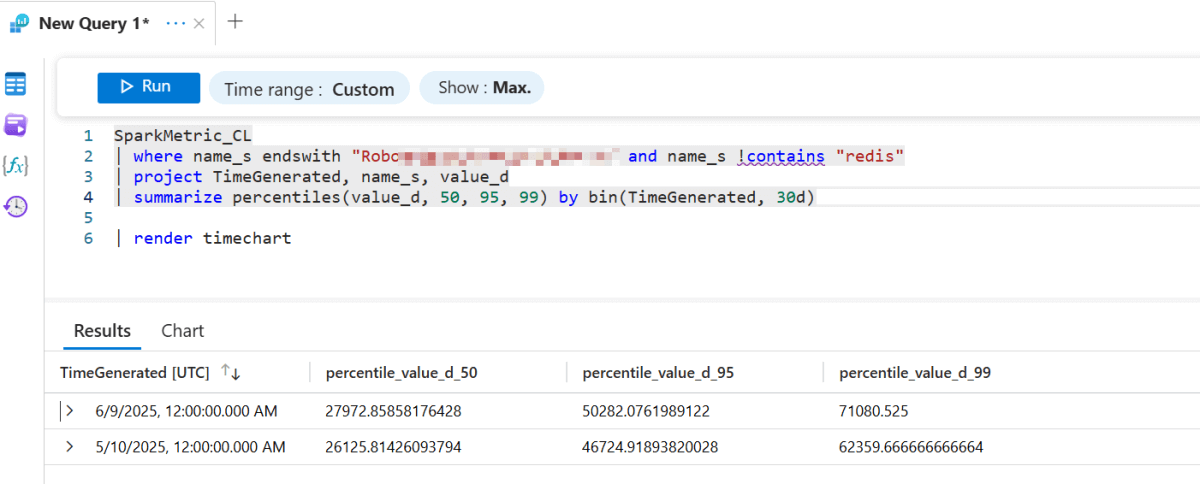
Nosso trabalho de streaming atualmente é executado em modo de micro-lote com um intervalo de gatilho de um minuto. Isso significa que, desde o momento em que um evento é publicado em nosso Event Bus, ele normalmente chega ao nosso armazém de dados em cerca de 27 segundos na mediana, com 95% dos registros chegando dentro de 51 segundos, e 99% dentro de 72 segundos.
Structured Streaming oferece configurações de gatilho configuráveis, que podem até reduzir a latência para alguns segundos. Por enquanto, escolhemos o gatilho de um minuto como o equilíbrio certo entre custo e desempenho, com a flexibilidade para reduzi-lo no futuro se as exigências mudarem.
Escalabilidade
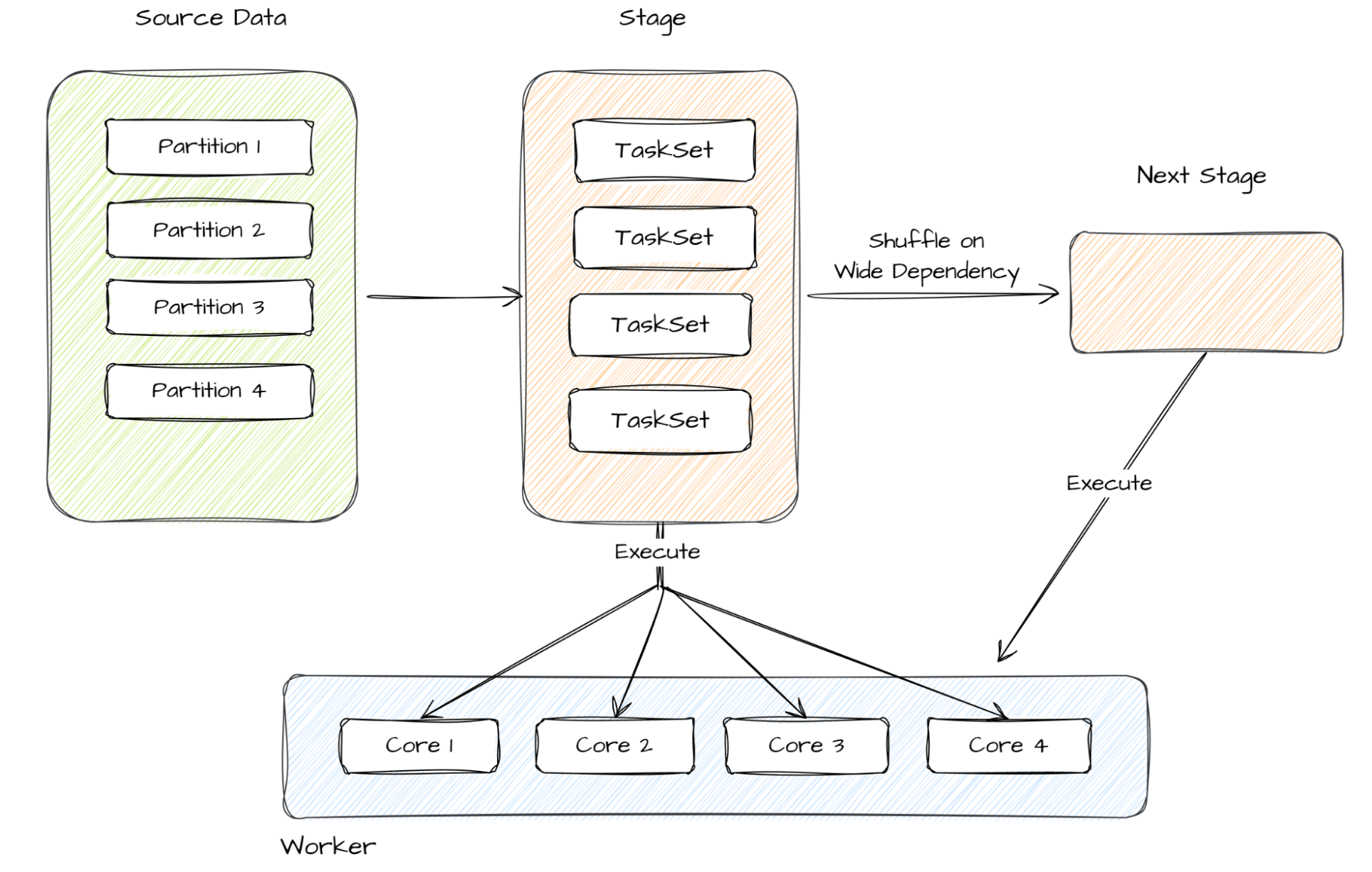
Spark divide o trabalho de big data por partições, que utilizam totalmente os núcleos de CPU do Worker/Executor. Cada trabalho de Structured Streaming é dividido em etapas, que são ainda mais divididas em tarefas, cada uma das quais é executada em um único núcleo. Esse nível de paralelização nos permite utilizar totalmente nosso cluster Spark e escalar eficientemente com o crescimento dos volumes de dados.
Graças a otimizações como processamento em memória, planejamento de consultas Catalyst, geração de código em estágio único e execução vetorizada, processamos cerca de 40.000 eventos por segundo na validação de escalabilidade. Se o tráfego aumentar, podemos escalar simplesmente aumentando a contagem de partições no Event Bus de origem e adicionando mais nós de trabalho - garantindo escalabilidade à prova de futuro com esforço de engenharia mínimo.
Garantia de Entrega
O Spark Structured Streaming fornece entrega exatamente uma vez por padrão, graças ao seu sistema de checkpoint. Após cada micro-lote, o Spark persiste o progresso (ou "época") de cada partição de origem como logs de gravação antecipada e o estado da aplicação do trabalho na loja de estado. No caso de uma falha, o trabalho retoma a partir do último checkpoint - garantindo que nenhum dado seja perdido ou ignorado.
Isso é mencionado no artigo original de pesquisa do Spark Structured Streaming, que afirma que para alcançar a entrega exatamente uma vez é necessário:
- A fonte de entrada deve ser reproduzível
- O sink de saída para suportar gravações idempotentes
Mas também há um terceiro requisito implícito que muitas vezes não é mencionado: o sistema deve ser capaz de detectar e lidar com falhas de maneira elegante.
É aqui que o Spark funciona bem - seus robustos mecanismos de recuperação de falhas podem detectar falhas de tarefas, falhas de executores e problemas de driver, e tomar automaticamente ações corretivas como tentativas ou reinícios.
Note que atualmente estamos operando com entrega pelo menos uma vez, pois nosso destino de saída ainda não é idempotente. Se tivermos mais requisitos de entrega exatamente uma vez no futuro, desde que coloquemos mais esforços de engenharia na idempotência, deveríamos ser capazes de alcançá-lo.
Dados Brutos são Melhores
Também fizemos algumas outras melhorias. Agora incluímos e persistimos um campo rawMessage comum em todas as tabelas. Esta coluna armazena a carga útil do evento original como uma string bruta. Para pegar emprestado o princípio do sushi (embora signifiquemos algo um pouco diferente aqui): dados brutos são melhores.
Dados brutos simplificam significativamente a solução de problemas. Quando algo dá errado - como um campo ausente ou um valor inesperado - podemos instantaneamente nos referir à mensagem original e rastrear o problema, sem ter que buscar logs ou sistemas upstream. Sem essa carga bruta, o diagnóstico de problemas de dados se torna muito mais difícil e lento.
A desvantagem é um pequeno aumento no armazenamento. Mas graças ao armazenamento em nuvem barato e ao formato colunar de nosso armazém, isso tem um custo mínimo e nenhum impacto no desempenho da consulta.
API Simples e Poderosa
A nova implementação está nos levando menos tempo de desenvolvimento. Isso se deve em grande parte à API DataFrame no Spark, que fornece uma abstração declarativa de alto nível sobre o processamento de dados distribuídos. No passado, usar RDDs significava raciocinar manualmente sobre planos de execução, entender DAGs e otimizar a ordem de operações como junções e filtros. DataFrames nos permitem focar na lógica do que queremos calcular, em vez de como calcular. Isso simplifica significativamente o processo de desenvolvimento.
Isso também melhorou as operações. Não precisamos mais reexecutar manualmente trabalhos falhados ou rastrear erros em vários componentes da pipeline. Com uma arquitetura simplificada e menos partes móveis, tanto o desenvolvimento quanto a depuração são significativamente mais fáceis.
Impulsionando Análises em Tempo Real em Todo o UiPath
O sucesso desta nova arquitetura não passou despercebido. Rapidamente se tornou o novo padrão para ingestão de eventos em tempo real em toda a UiPath. Além de sua implementação inicial para UiPath Maestro e Insights, o padrão tem sido amplamente adotado por várias novas equipes e projetos para suas necessidades de análise em tempo real, incluindo aqueles que trabalham em iniciativas de ponta. Essa adoção generalizada é um testemunho da escalabilidade, eficiência e extensibilidade da arquitetura, facilitando o embarque de novas equipes e possibilitando uma nova geração de produtos com poderosas capacidades de análise em tempo real.
Se você está procurando escalar suas cargas de trabalho de análise em tempo real sem o ônus operacional, a arquitetura descrita aqui oferece um caminho comprovado, alimentado por Databricks e Spark Structured Streaming e pronto para suportar a próxima geração de sistemas de IA e agentes.
Sobre a UiPath
UiPath (NYSE: PATH) é líder global em automação agente, capacitando empresas a aproveitar todo o potencial de agentes de IA para executar e otimizar autonomamente processos de negócios complexos. A Plataforma UiPath™ combina de forma única agência controlada, flexibilidade do desenvolvedor e integração perfeita para ajudar as organizações a escalar a automação agente de forma segura e confiante. Comprometida com a segurança, governança e interoperabilidade, a UiPath apoia as empresas à medida que transitam para um futuro onde a automação cumpre todo o potencial da IA para transformar indústrias.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.