Ingestão da Via Láctea: escala de petabytes com Zerobus Ingest
Uma análise detalhada da arquitetura que viabiliza 12 GB/s por tabela — e traz possibilidades ilimitadas
por Aleksandar Tomić, Victoria Bukta, Nikola Obradović, Danilo Najkov, Branko Grbić e Milos Milovanovic
- O Databricks Zerobus Ingest é uma API de streaming serverless que permite às equipes implantar instantaneamente pipelines de dados em escala de petabytes sem gerenciamento manual de infraestrutura.
- A arquitetura do Zerobus conta com particionamento dinâmico para escalar automaticamente os recursos de computação, lidando de forma eficiente com volumes de dados imprevisíveis sem a necessidade de ajustes complexos.
- Esse framework de configuração zero processa facilmente cargas de trabalho massivas, demonstrando a capacidade de sustentar um throughput de mais de 12 GB/s em uma única tabela durante benchmarks de 24 horas.
Os dados de telemetria estão em toda parte. Sensores de IoT em chãos de fábrica. Matrizes de satélites escaneando a atmosfera. Veículos autônomos estão registrando milhares de eventos por segundo. Cada um desses sistemas tem o mesmo problema subjacente: um fluxo contínuo e de alto volume de observações de séries temporais que precisa ir para algum lugar consultável. Ele precisa ser rápido, confiável e sem que uma equipe de engenharia passe semanas ajustando e mantendo a infraestrutura típica de cargas de trabalho baseadas em Kafka.
Esse é o problema que o Zerobus Ingest foi criado para resolver. O Zerobus é o serviço de ingestão de streaming serverless e totalmente gerenciado da Databricks. É uma API baseada em push que aceita dados de qualquer produtor e os grava diretamente em tabelas Delta, sob a governança do Unity Catalog.
- Sem infraestrutura para provisionar.
- Sem pipeline de conectores para manter.
- Sem partições ou tomada de decisão de brokers.
Em vez disso, você cria uma tabela e envia os dados. Eles chegam ao seu lakehouse, prontos para consulta em segundos. Você não precisa mais executar o Kafka como um pipe quando seu destino é o lakehouse.
Usamos o conjunto de dados NEOWISE da NASA, que representa 200 bilhões de pontos de dados ao longo de 11 anos, para fazer o benchmark do Zerobus Ingest, ingerindo 1 petabyte em menos de 24 horas, com configuração prévia zero e latência estável.
Ao ingerir 1 PB em 24 horas, demonstramos a capacidade do Zerobus de manter uma taxa de transferência contínua de 12 GB/s para uma única tabela! 🚀
Agora entregando escala de petabytes: streaming da Via Láctea (12 GB/s/tabela)
Para saber mais sobre como executar o benchmark você mesmo, leia este blog complementar na Databricks Community.
Este post aborda três das nossas decisões de design que tornaram isso possível.
- Projetar um sistema que faz escalonamento automático por meio de particionamento dinâmico.
- Construir nosso próprio decodificador protobuf de cópia zero (zero-copy).
- Implementar um log de gravação antecipada (write-ahead log) otimizado para latência antes que os dados sejam publicados no lakehouse.
Nossas principais decisões de design
Nossa aspiração era construir um sistema de streaming que pudesse suportar a escala de petabytes e fazer escalonamento automático para lidar com padrões de ingestão flutuantes.
As arquiteturas de streaming tradicionais exigem que você decida quantos brokers e partições uma determinada carga de trabalho precisa. Isso exige conhecimento da carga de pico e das restrições de ingestão do consumidor, bem como previsões e uma compreensão do pipeline de ponta a ponta.
Voltando aos princípios fundamentais, projetamos e construímos um sistema que se dimensiona para lidar com cargas de trabalho do tamanho de petabytes para produtores de dados de forma "mágica".
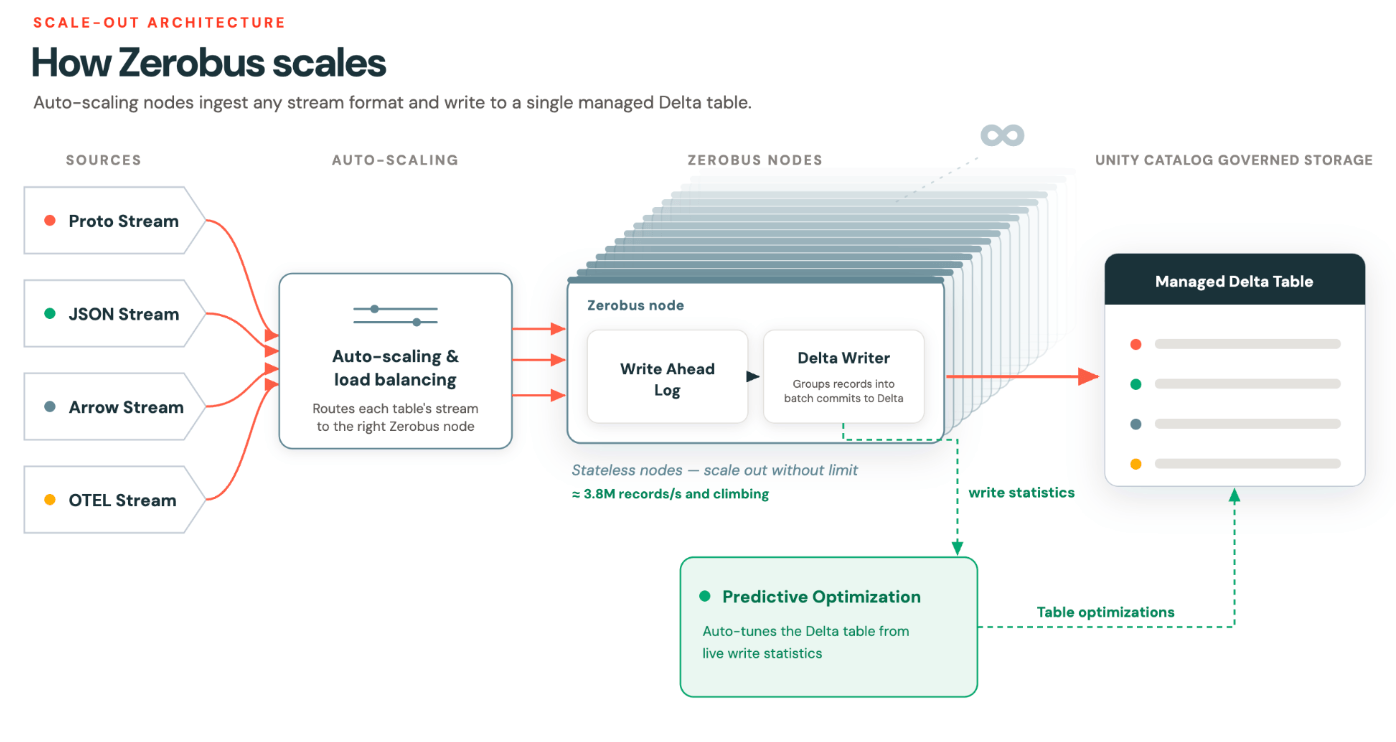
Escalonamento automático alcançado por meio de particionamento dinâmico
O problema que estávamos tentando resolver era como ter um escalonamento automático eficiente para alcançar um dimensionamento elástico "sem limites".
Nossa tese era de que, ao nos afastarmos do particionamento estático e nos movermos em direção à unidade lógica de um fluxo/conexão, poderíamos desbloquear o verdadeiro escalonamento automático e o rebalanceamento, mantendo as garantias de ordenação, que são importantes para as cargas de trabalho de consumo.
O problema da partição estática
Em arquiteturas de barramento de mensagens, as partições são a unidade tanto de paralelismo quanto de ordenação. Esse acoplamento cria uma restrição que pode ser dolorosa quando você tem consumidores que dependem dela.
A ordenação normalmente é uma garantia por partição, não por produtor. O número de partições e a distribuição de dados entre elas afetam a capacidade do consumidor de acompanhar a ingestão. Isso significa:
- Se a contagem de partições mudar, a função de roteamento que mapeia as mensagens de um produtor para uma partição poderá agora enviá-las para uma partição diferente. O consumidor agora precisa reconciliar isso.
- Na prática, a maioria das equipes trata a topologia de partição como imutável. Você faz o provisionamento para a carga de pico e carrega essa infraestrutura para sempre. Você pode adicionar partições, mas normalmente não pode diminuí-las com segurança.
- A solução alternativa padrão é uma chave de roteamento de partição derivada de um campo na mensagem. Isso ajuda na consistência da ordenação, mas ainda não resolve o problema de redução de escala (scale-down).
Movemos a garantia de ordenação para a conexão do fluxo (stream)
Em sistemas tradicionais, a ordenação é uma garantia no nível da partição. No Zerobus Ingest, a ordenação é uma garantia no nível da conexão do fluxo (stream).
Quando um produtor abre um fluxo (stream) com o Zerobus (uma conexão com o nosso servidor), ele está registrando uma identidade lógica com o serviço. Durante o tempo de vida dessa conexão, seus dados chegam em ordem, independentemente de qual pod de "partição" os processe.
"Seu fluxo está ordenado", não "sua partição está ordenada." Esse é o contrato.
Roteamento dinâmico (hot routing) e verdadeiro escalonamento automático (autoscaling)
Internamente, o Zerobus Ingest distribui fluxos por um pool de pods. O roteamento é baseado em heurística: se um pod estiver sobrecarregado (running hot), os novos fluxos de entrada serão roteados para um pod diferente. O produtor não percebe isso. Sua garantia de ordenação não é afetada.
A ordenação reside no nível do fluxo, o que significa que pods podem ser adicionados quando a demanda aumenta e removidos quando a demanda cai. Os fluxos existentes são então esvaziados gradualmente (drain gracefully), e novos fluxos deixam de ser roteados para lá. O pool então encolhe, mantendo a utilização de computação eficiente.
Isso é o verdadeiro escalonamento automático (autoscaling). A unidade de granularidade é a conexão do fluxo, não a atribuição de partição.
Nosso design de particionamento dinâmico permite que o Zerobus faça o escalonamento automático para uma taxa de transferência de mais de 12 GB por segundo para uma tabela, mantendo-se econômico.
Manipulação de dados de alto desempenho com cópia zero (zero-copy)
O principal objetivo do Zerobus é permitir uma transferência eficiente, linha por linha, de fluxos de dados de qualquer volume. Para conseguir isso, precisávamos evitar completamente qualquer cópia desnecessária e alocações de memória — desde os formatos de entrada que os clientes enviam para o Zerobus até os formatos internos que garantem durabilidade e formatos Delta abertos.
Atualmente, o Zerobus suporta os seguintes formatos de mensagem.
Entre as muitas otimizações que fizemos, vamos ilustrar a abordagem zero-copy por meio do ZeroParser - nosso decodificador protobuf personalizado.
Os decodificadores protobuf padrão forçam você a escolher entre velocidade e flexibilidade. Os decodificadores protobuf geralmente dependem de geração de código em tempo de compilação (codegen) ou reflexão em tempo de execução (runtime reflection).
- A geração de código é rápida, mas exige descritores em tempo de compilação. O Zerobus recebe descritores dinamicamente em tempo de execução, a partir de esquemas de usuário arbitrários. Codegen não é uma opção.
- A reflexão em tempo de execução resolve o problema de flexibilidade, mas cria um problema de desempenho. Os decodificadores protobuf dinâmicos são lentos e exigem a construção de um gráfico de objetos na memória em tempo de execução, levando a muitas pequenas alocações de memória.
Nenhuma das abordagens era aceitável. Precisávamos de suporte a descritores dinâmicos com o perfil de desempenho de codegen.
O resultado foi a criação do zeroparser: preenchendo essa lacuna ao usar parsing em uma única passagem com zero alocações de memória, permitindo sustentar taxas de transferência de ~1 GB/s de parsing de protobuf por núcleo de CPU, mesmo com descritores dinâmicos e esquemas complexos.
O Zeroparser permite o parsing direto no formato de transmissão (wire format) sem a desconstrução dos objetos de entrada, o que geraria cópia e alocações de memória. Com essa abordagem, o Zerobus consegue obter um desempenho melhor do que as soluções existentes de parsing de protobuf baseadas em geração de código, mantendo a total flexibilidade de fornecer descritores de protobuf dinamicamente.
O sistema de tempo de vida (lifetime) do Rust foi fundamental para o design do Zeroparser: ele garante a segurança em tempo de compilação durante o parsing do protocolo, mantendo os bytes brutos de transmissão sob propriedade exclusiva da rede, eliminando cópias desnecessárias de dados.
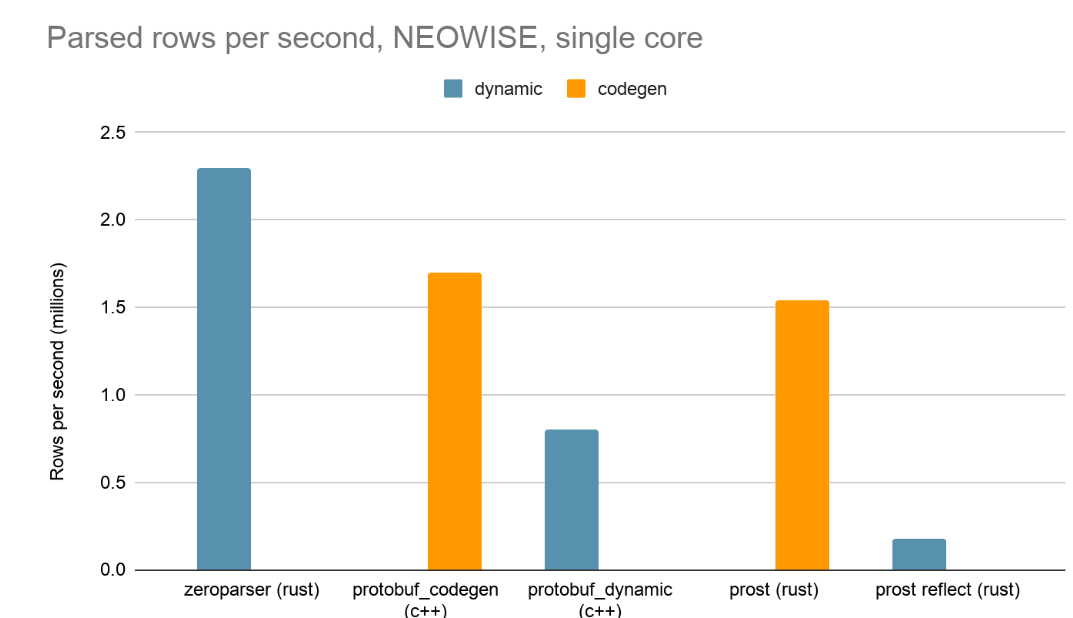
Os resultados mostram que o Zeroparser, embora esteja no grupo dinâmico, superou duas implementações baseadas em codegen que são padrão do setor.
O Zeroparser tem código aberto como parte do Zerobus SDK disponível aqui.
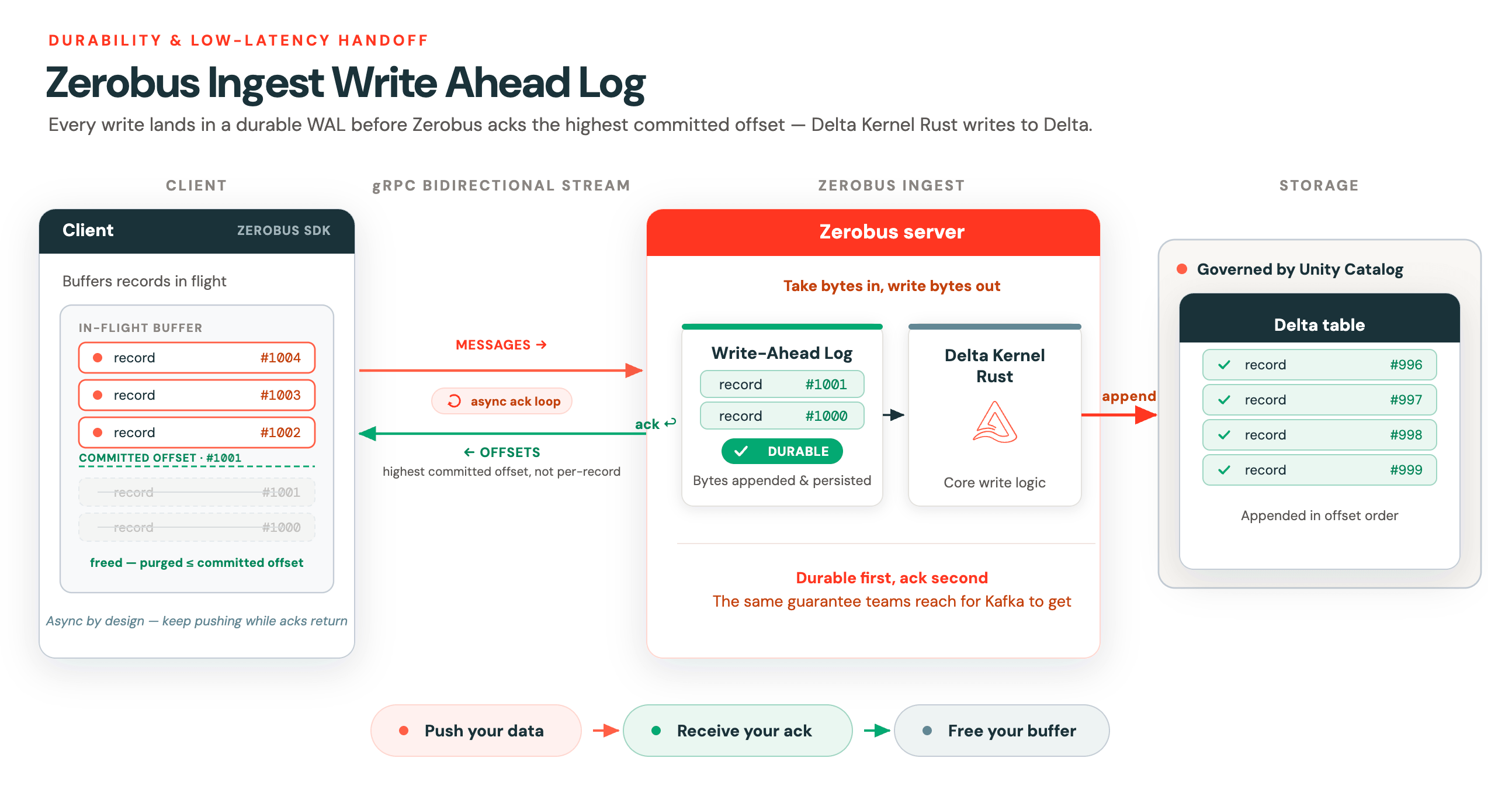
Write Ahead Log
Streaming não se trata apenas de ser capaz de lidar com cargas de trabalho de alta taxa de transferência (throughput). Para ser um serviço de streaming de verdade, você também precisa oferecer suporte à transferência de mensagens (handoff) o mais rápido possível. Essa baixa latência na transferência de dados é o que realmente diferencia as cargas de trabalho de streaming das de lote (batch).
Para dar suporte a essa transferência de baixa latência com garantia de durabilidade, o Zerobus implementa um write-ahead log (WAL) otimizado para latência. Assim que as mensagens se tornam duráveis, o Zerobus envia uma confirmação (acknowledgement) de volta ao cliente. Em vez de confirmar cada registro individualmente, o servidor retorna o maior deslocamento (offset) confirmado no stream. O resultado é este loop de ack assíncrono. O Delta Kernel Rust é usado para a lógica principal de gravação no Delta.
Esse design assíncrono é fundamental para clientes que armazenam dados em trânsito (data in flight) em buffer. O Zerobus usa streaming bidirecional gRPC, onde cada stream do Zerobus tem duas linhas de comunicação:
- Uma para o envio de mensagens
- A outra para receber confirmações de offsets.
Assim que o cliente recebe esse offset, ele pode expurgar com segurança tudo até esse ponto de seu buffer local em trânsito. Tudo isso é gerenciado para você pelos SDKs do Zerobus.
O WAL é o que mantém os clientes leves. Envie seus dados, receba seu ack, libere seu buffer. Essa transferência de baixa latência e alta durabilidade sempre foi o motivo pelo qual as equipes recorrem ao Kafka. O Zerobus oferece a mesma garantia.
Prova: Ingerindo a Via Láctea
A chave para realizar o benchmark de um sistema é entender como ele seria usado em um ambiente de produção e, em seguida, emular esse comportamento e uso. É por isso que, para testar o limite do Zerobus Ingest, decidimos escolher o conjunto de dados NEOWISE da NASA e usamos o Locust para emular padrões reais de fan-in.
Por que o Locust? O problema do Fan-In
O Zerobus Ingest foi desenvolvido para agregar streams de muitos produtores independentes em uma única tabela de destino. Sua taxa de transferência (throughput) escala com o número de streams abertos simultaneamente. Isso significa que você não pode testar seu limite de forma justa a partir de uma única máquina ou de um pequeno cluster. Um único host potente saturaria sua própria largura de banda ou CPU antes de exercer uma pressão significativa em nosso serviço, testando, portanto, o produtor, e não o Zerobus.
Para simular um padrão real de fan-in, usamos o Locust para coordenar a abertura de streams separados por pods para testar a ingestão em escala sob pressão.
O escalonamento automático (autoscaling) do Zerobus responde então à contagem de streams e à taxa de transferência para lidar com a taxa de ingestão.
Configuração do teste
Nosso benchmark foi implantado no Kubernetes com um master do Locust e uma frota de workers do Locust, cada um executando como um pod separado. Parâmetros principais:
Cada worker recebe uma lista exclusiva de arquivos Parquet para ingestão. Um worker faz o streaming de sua parte e não repete linhas.
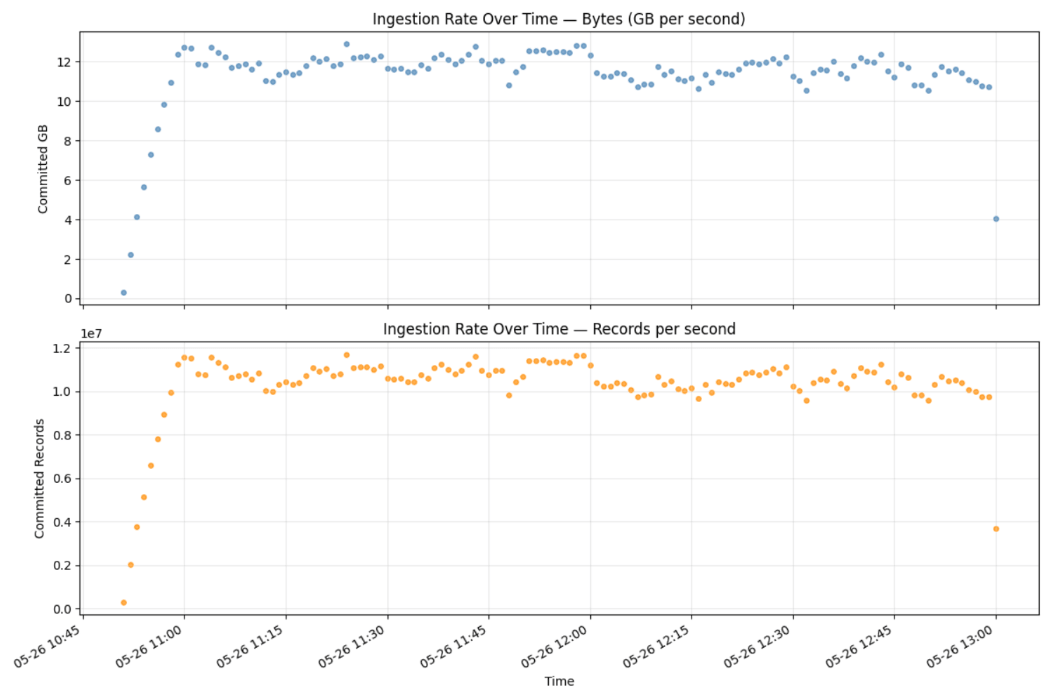
Os resultados
Nossos resultados de teste mostraram a capacidade do Zerobus Ingest de sustentar 12 GB/s em uma única tabela por um período de 24 horas, a partir de 2.048 workers simultâneos para uma única tabela. Nesse período, o Zerobus ingeriu mais de um trilhão de registros.
A agregação em intervalos de 5 segundos na coluna client_ts_ms fornece uma visão precisa e confirmada pelo servidor das linhas gravadas e dos bytes recebidos:
Essa consulta é executada na tabela ativa do Unity Catalog. Os números refletem as linhas que foram totalmente gravadas no armazenamento Delta.
Quer testar você mesmo?
A suíte de benchmark completa com preparação de dataset, código do produtor e instruções para execução em seu próprio endpoint Zerobus. Confira aqui.
O que vem a seguir
Zerobus Ingest já está em Disponibilidade Geral (GA) no Databricks e pronto para todas as suas cargas de trabalho de produção.
Nossas métricas de desempenho de 12 GB/s para uma tabela são o que você obtém de forma nativa com o Zerobus Ingest. As cotas podem ser aumentadas entrando em contato com a equipe da sua conta.
No roadmap:
- Suporte à API Kafka Producer
- Suporte à API MQTT
- Coluna de resgate
- Coluna de metadados do sistema
- Suporte ao Avro
Diga-nos para onde você quer que levemos o Zerobus a seguir! Qual você acha que é a próxima fronteira do streaming? Envie seus comentários em nosso blog complementar da Databricks Community.
Se você está pronto para começar a usar o Zerobus Ingest, consulte nossa documentação técnica, o Zerobus Ingest SDK ou confira o repositório do GitHub com o benchmark Neowise.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.