Balanceamento de carga inteligente do Kubernetes no Databricks
Balanceamento de carga em tempo real do lado do cliente para tráfego interno e de entrada no Kubernetes
- Por que o balanceamento de carga padrão do Kubernetes é insuficiente para conexões persistentes e de alta taxa de transferência como o gRPC, especialmente na escala do Databricks.
- Como construímos um sistema de balanceamento de carga no lado do cliente, orientado por plano de controle, usando um cliente rpc personalizado e xDS.
- Vantagens e desvantagens de abordagens alternativas, como serviços headless e Istio, e por que escolhemos um modelo leve e orientado pelo cliente.
Introdução
Na Databricks, o Kubernetes está no centro dos nossos sistemas internos. Em um único cluster do Kubernetes, as primitivas de rede padrão, como serviços ClusterIP, CoreDNS e kube-proxy, geralmente são suficientes. Eles oferecem uma abstração simples para rotear o tráfego de serviço. Mas quando o desempenho e a confiabilidade são importantes, essas configurações padrão começam a mostrar suas limitações.
Neste post, compartilharemos como construímos um sistema inteligente de balanceamento de carga no lado do cliente para melhorar a distribuição do tráfego, reduzir as latências de cauda e tornar a comunicação de serviço a serviço mais resiliente.
Se você for um usuário do Databricks, não precisa entender este blog para poder usar a plataforma em todo o seu potencial. Mas, se você tiver interesse em dar uma espiada nos bastidores, continue lendo para saber sobre algumas das coisas legais em que estamos trabalhando!
Declaração do problema
A comunicação serviço a serviço de alto desempenho no Kubernetes apresenta vários desafios, especialmente ao usar conexões HTTP/2 persistentes, como fazemos na Databricks com o gRPC.
Como o Kubernetes roteia requisições por padrão
- O cliente resolve o nome do serviço (por exemplo, my-service.default.svc.cluster.local) pelo CoreDNS, que retorna o ClusterIP do serviço (um IP virtual).
- O cliente envia a solicitação para o ClusterIP, supondo que ele seja o destino.
- No nó, as regras do iptables, IPVS ou eBPF (configuradas pelo kube-proxy) interceptam o pacote. O kernel reescreve o IP de destino para um dos IPs do Pod de backend com base em um balanceamento de carga básico, como o round-robin, e encaminha o pacote.
- O pod selecionado processa a solicitação e a resposta é enviada de volta para o cliente.
Embora este modelo geralmente funcione, seu desempenho cai rapidamente em ambientes sensíveis ao desempenho, levando a limitações significativas.
Limitações
No Databricks, operamos centenas de serviços sem estado (stateless) que se comunicam por gRPC em cada cluster do Kubernetes. Esses serviços geralmente são de alta taxa de transferência, sensíveis à latência e executados em grande escala.
O modelo de balanceamento de carga padrão não é suficiente neste ambiente por vários motivos:
- Alta latência de cauda: o gRPC usa HTTP/2, que mantém conexões TCP de longa duração entre clientes e serviços. Como o balanceamento de carga do Kubernetes ocorre na Camada 4, o pod de backend é escolhido apenas uma vez por conexão. Isso leva à distorção do tráfego (traffic skew), em que alguns pods recebem uma carga significativamente maior do que outros. Como resultado, as latências de cauda aumentam e o desempenho se torna inconsistente sob carga.
- Uso ineficiente de recursos: quando o tráfego não é distribuído uniformemente, torna-se difícil prever os requisitos de capacidade. Alguns pods ficam sem CPU ou memória, enquanto outros ficam ociosos. Isso leva ao superprovisionamento e desperdício.
- Estratégias de balanceamento de carga limitadas: o kube-proxy oferece suporte apenas a algoritmos básicos, como round-robin ou seleção aleatória. Não há suporte para estratégias como:
- Round robin ponderado
- Roteamento ciente de erros
- Roteamento de tráfego com reconhecimento de zona
Essas limitações nos levaram a repensar como lidamos com a comunicação de serviço a serviço em um cluster do Kubernetes.
Nossa abordagem: balanceamento de carga do lado do cliente com descoberta de serviço em tempo real
Para lidar com as limitações do kube-proxy e do roteamento de serviço padrão no Kubernetes, construímos um sistema de balanceamento de carga sem proxy e totalmente orientado pelo cliente, suportado por um plano de controle de descoberta de serviço personalizado.
O requisito fundamental que tínhamos era dar suporte ao balanceamento de carga na camada de aplicação e remover a dependência do DNS em um caminho crítico. Um balanceador de carga da Camada 4, como o kube-proxy, não pode tomar decisões inteligentes por solicitação para protocolos da Camada 7 (como o gRPC) que utilizam conexões persistentes. Essa restrição de arquitetura cria gargalos, o que exige uma abordagem mais inteligente para o gerenciamento de tráfego.
A tabela a seguir resume as principais diferenças e as vantagens de uma abordagem no lado do cliente:
Tabela 1: LB padrão do Kubernetes vs. LB do lado do cliente da Databricks
| Recurso/Aspecto | Balanceamento de carga padrão do Kubernetes (kube-proxy) | Balanceamento de carga no lado do cliente do Databricks |
|---|---|---|
| Camada de balanceamento de carga | Camada 4 (TCP/IP) | Camada 7 (Aplicação/gRPC) |
| Frequência de decisão | Uma vez por conexão TCP | Por solicitação |
| Descoberta de serviço | CoreDNS + kube-proxy (IP virtual) | Plano de Controle baseado em xDS + Biblioteca de Cliente |
| Estratégias compatíveis | Básico (Round-robin, Aleatório) | Avançado (P2C, afinidade de zona, modular) |
| Impacto na latência de cauda | Alta (devido à distorção do tráfego em conexões persistentes) | Reduzida (distribuição uniforme, roteamento dinâmico) |
| Utilização de recursos | Ineficiente (provisionamento excessivo) | Eficiente (carga balanceada) |
| Dependência de DNS/Proxy | Alta | Mínimo/Mínimo, não está em um caminho crítico |
| Controle operacional | Limitada | Detalhado |
Este sistema permite um roteamento de solicitações inteligente e atualizado com dependência mínima de DNS ou de rede da Camada 4. Ele dá aos clientes a capacidade de tomar decisões informadas com base em dados de topologia e integridade em tempo real.
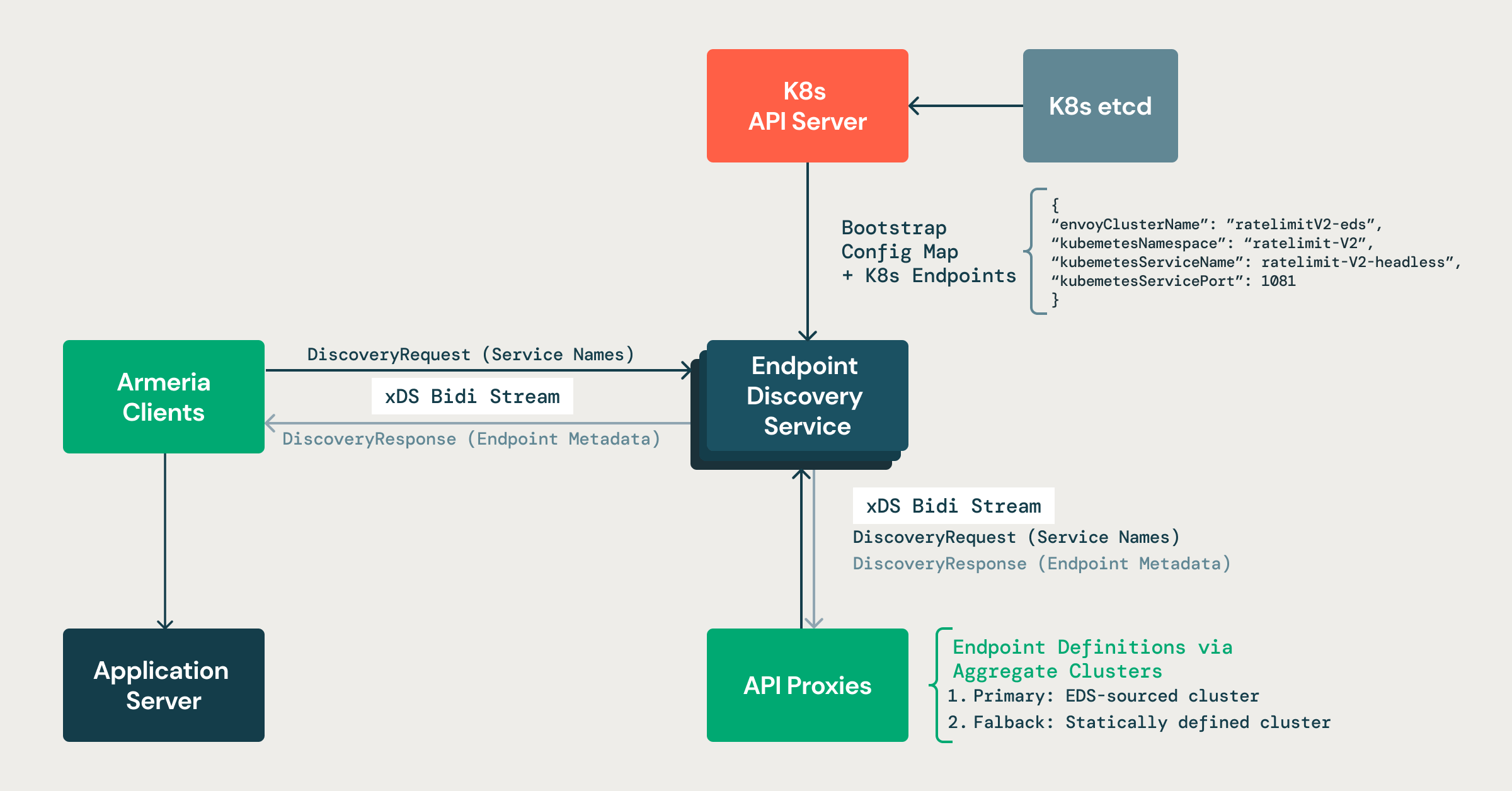
A figura mostra nosso Endpoint Discovery Service personalizado em ação. Ele lê dados de serviço e de endpoint da API do Kubernetes e os traduz em respostas xDS. Tanto os clientes Armeria quanto os proxies de API enviam solicitações via stream para ele e recebem metadados de endpoint em tempo real, que são usados pelos servidores de aplicação para roteamento inteligente com clusters de fallback como backup.”
Plano de controle personalizado (serviço de descoberta de endpoint)
Executamos um plano de controle leve que monitora continuamente a API do Kubernetes em busca de alterações nos Services e EndpointSlices. Ele mantém uma visualização atualizada de todos os pods de backend para cada serviço, incluindo metadados como zona, prontidão e rótulos de shard.
Integração do cliente RPC
Uma vantagem estratégica para a Databricks foi a adoção generalizada de um framework comum para comunicação entre serviços na maioria dos seus serviços internos, que são predominantemente escritos em Scala. Essa base compartilhada nos permitiu incorporar lógicas de descoberta de serviço e balanceamento de carga do lado do cliente diretamente no framework, facilitando a adoção entre as equipes sem exigir esforço de implementação personalizada.
Cada serviço se integra ao nosso cliente personalizado, que assina as atualizações do plano de controle para os serviços dos quais depende durante a configuração da conexão. O cliente mantém uma lista dinâmica de endpoints íntegros, incluindo metadados como zona ou shard, e é atualizada automaticamente à medida que o plano de controle envia as alterações.
Como o cliente ignora totalmente tanto a resolução de DNS quanto o kube-proxy, ele sempre tem uma visão precisa e em tempo real da topologia do serviço. Isso nos permite implementar estratégias de balanceamento de carga consistentes e eficientes em todos os serviços internos.
Balanceamento de carga avançado em clientes
O cliente rpc realiza o balanceamento de carga ciente da solicitação usando estratégias como:
- Poder de Duas Escolhas (P2C): para a maioria dos serviços, um simples algoritmo de Poder de Duas Escolhas (P2C) mostrou-se notavelmente eficaz. Essa estratégia envolve selecionar aleatoriamente dois servidores de backend e escolher aquele com menos conexões ativas ou menor carga. A experiência da Databricks indica que o P2C atinge um forte equilíbrio entre desempenho e simplicidade de implementação, levando consistentemente a uma distribuição de tráfego uniforme entre os endpoints.
- Baseado em afinidade de zona: o sistema também oferece suporte a estratégias mais avançadas, como o roteamento baseado em afinidade de zona. Essa capacidade é vital para minimizar os saltos de rede entre zonas, o que pode reduzir significativamente a latência da rede e os custos de transferência de dados associados, especialmente em clusters do Kubernetes geograficamente distribuídos.
O sistema também leva em consideração cenários em que uma zona não tem capacidade suficiente ou fica sobrecarregada. Nesses casos, o algoritmo de roteamento transfere de forma inteligente o tráfego para outras zonas íntegras, equilibrando a carga e, ao mesmo tempo, preferindo a afinidade local sempre que possível. Isso garante alta disponibilidade e desempenho consistente, mesmo sob uma distribuição de capacidade desigual entre as zonas. - Suporte conectável (pluggable): a flexibilidade da arquitetura permite o suporte conectável para estratégias adicionais de balanceamento de carga, conforme necessário.
Estratégias mais avançadas, como o roteamento ciente da zona, exigiam um ajuste cuidadoso e um contexto mais aprofundado sobre a topologia do serviço, os padrões de tráfego e os modos de falha; um tópico a ser explorado em uma postagem futura dedicada.
Para garantir a eficácia da nossa abordagem, executamos simulações extensivas, experimentos e análises de métricas do mundo real. Validamos que a carga permaneceu distribuída uniformemente e que as métricas principais, como latência de cauda, taxa de erro e custo de tráfego entre zonas, permaneceram dentro dos limites alvo. A flexibilidade para adaptar estratégias por serviço tem sido valiosa, mas, na prática, manter a simplicidade (e a consistência) tem funcionado melhor.
Integração do xDS com o Envoy
Nosso plano de controle estende sua utilidade para além da comunicação interna de serviço a serviço. Ele desempenha um papel crucial no gerenciamento do tráfego externo ao se comunicar com a API xDS para o Envoy, o protocolo de descoberta que permite que os clientes busquem dinamicamente configurações atualizadas (como clusters, endpoints e regras de roteamento). Especificamente, ele implementa o Endpoint Discovery Service (EDS) para fornecer ao Envoy metadados consistentes e atualizados sobre os endpoints de backend, programando os recursos ClusterLoadAssignment. Isso garante que o roteamento no nível do gateway (por exemplo, para tráfego de entrada ou público) esteja alinhado com a mesma fonte de verdade usada pelos clientes internos.
Resumo
Essa arquitetura nos dá controle detalhado sobre o comportamento de roteamento e, ao mesmo tempo, desvincula a descoberta de serviços das limitações do DNS e do kube-proxy. Os principais pontos são:
- os clientes sempre têm uma visão precisa e em tempo real dos endpoints e da integridade deles,
- as estratégias de balanceamento de carga podem ser personalizadas por serviço, melhorando a eficiência e a latência de cauda, e
- O tráfego interno e externo compartilham a mesma fonte de verdade, garantindo a consistência em toda a plataforma.
Impacto
Após a implantação do nosso sistema de balanceamento de carga no lado do cliente, observamos melhorias significativas tanto no desempenho quanto na eficiência:
- Distribuição uniforme de solicitações
O QPS do lado do servidor passou a ser distribuído uniformemente entre todos os pods de backend. Diferente da configuração anterior, onde alguns pods ficavam sobrecarregados enquanto outros permaneciam subutilizados, o tráfego agora se espalha de forma previsível. O gráfico superior mostra a distribuição antes do EDS, enquanto o gráfico inferior mostra a distribuição balanceada após o EDS.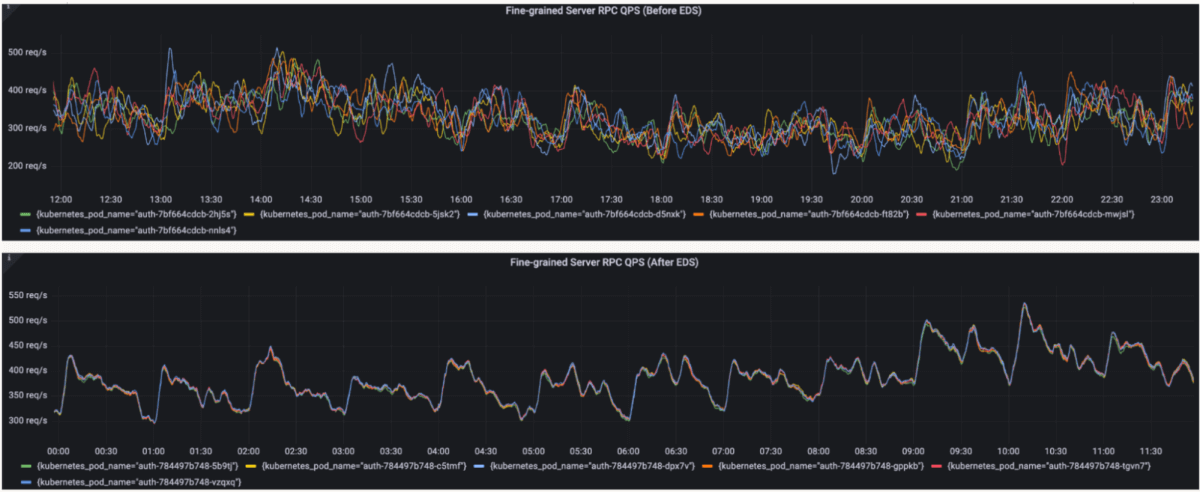
- Perfis de latência estáveis
A variação na latência entre os pods caiu visivelmente. As métricas de latência melhoraram e se estabilizaram entre os pods, reduzindo o comportamento de cauda longa nas cargas de trabalho gRPC. O diagrama abaixo mostra como a latência P90 se tornou mais estável após a ativação do balanceamento de carga do lado do cliente.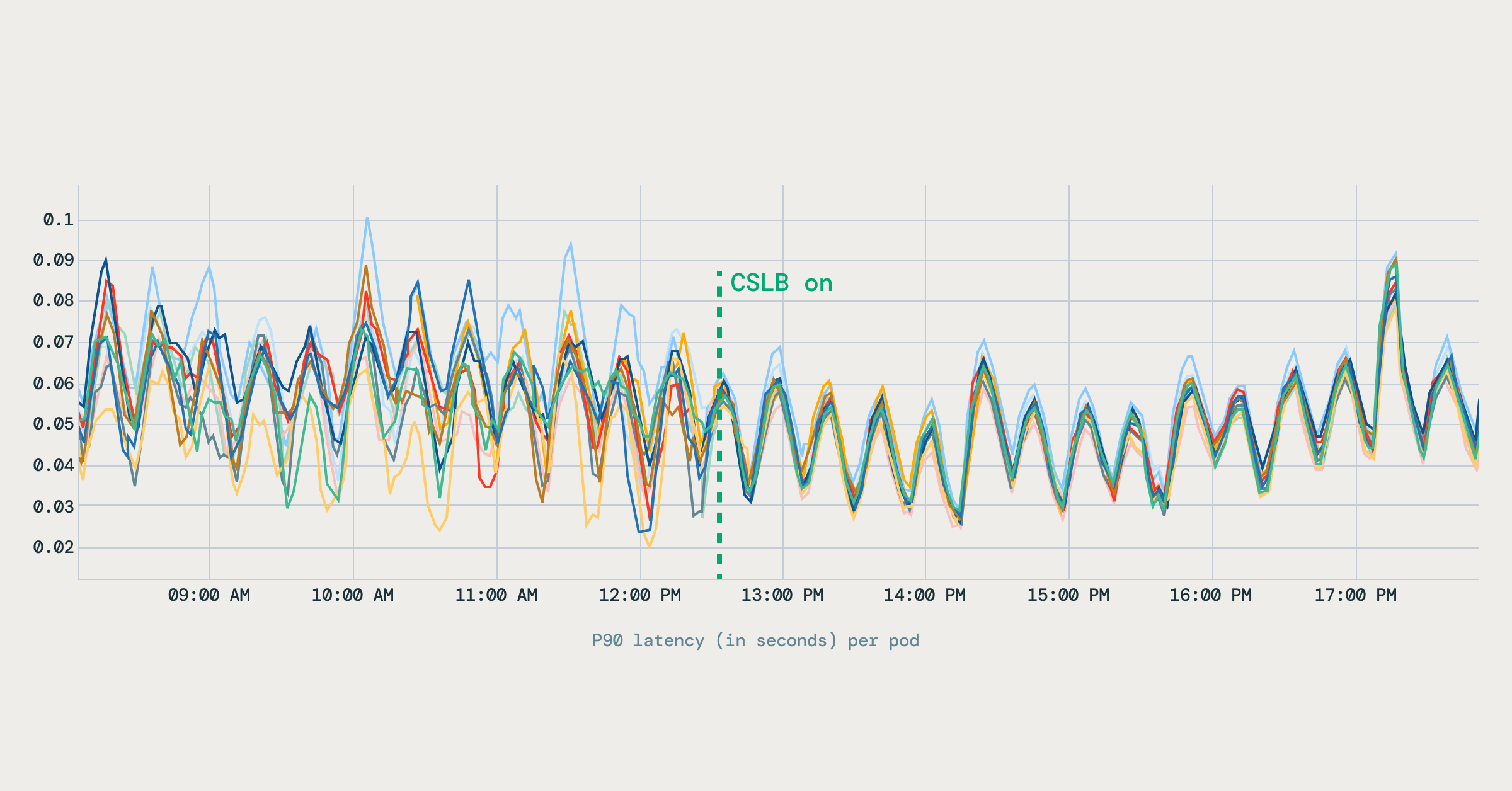
- Eficiência de recursos
Com latência mais previsível e carga balanceada, conseguimos reduzir a capacidade superprovisionada. Em vários serviços, isso resultou em uma redução de aproximadamente 20% na contagem de pods, liberando recursos de computação sem comprometer a confiabilidade.
Desafios e lições aprendidas
Embora a implementação tenha trazido benefícios claros, também descobrimos vários desafios e percepções ao longo do caminho:
- Cold starts do servidor: antes do balanceamento de carga do lado do cliente, a maioria das solicitações era enviada por conexões de longa duração, portanto, os novos pods raramente eram acionados até que as conexões existentes fossem recicladas. Após a mudança, novos pods começaram a receber tráfego imediatamente, o que trouxe à tona problemas de cold start, em que eles processavam solicitações antes de estarem totalmente aquecidos. Resolvemos isso introduzindo um ramp-up de início lento e desviando o tráfego de pods com taxas de erro observadas mais altas. Essas lições também reforçaram a necessidade de um framework de warmup dedicado.
- Roteamento baseado em métricas: Inicialmente, experimentamos desviar o tráfego com base em sinais de uso de recursos, como a CPU. Embora conceitualmente atraente, essa abordagem se mostrou pouco confiável: os sistemas de monitoramento tinham SLOs diferentes das cargas de trabalho de serviço, e métricas como a de CPU eram frequentemente indicadores tardios em vez de sinais de capacidade em tempo real. Acabamos abandonando esse modelo e optamos por confiar em sinais mais confiáveis, como a integridade do servidor.
- Integração da biblioteca do cliente: a criação do balanceamento de carga diretamente nas bibliotecas do cliente trouxe grandes benefícios de desempenho, mas também criou algumas lacunas inevitáveis. Linguagens sem a biblioteca, ou fluxos de tráfego que ainda dependem de balanceadores de carga de infraestrutura, permanecem fora do escopo do balanceamento do lado do cliente.
Alternativas consideradas
Ao desenvolver nossa abordagem de balanceamento de carga do lado do cliente, avaliamos outras soluções alternativas. Veja por que acabamos decidindo não usá-las:
Serviços headless
Os serviços headless do Kubernetes (clusterIP: None) fornecem IPs de pod diretos via DNS, permitindo que clientes e proxies (como o Envoy) realizem seu próprio balanceamento de carga. Essa abordagem contorna a limitação da distribuiç�ão baseada em conexão no kube-proxy e habilita estratégias avançadas de balanceamento de carga oferecidas pelo Envoy (como round robin, hashing consistente e round robin menos carregado).
Em teoria, a troca de serviços ClusterIP existentes por serviços headless (ou a criação de serviços headless adicionais usando o mesmo seletor) atenuaria os problemas de reutilização de conexão, fornecendo aos clientes visibilidade direta do endpoint. No entanto, essa abordagem tem limitações práticas:
- Falta de pesos de endpoint: os serviços headless por si sós não suportam a atribuição de pesos a endpoints, o que restringe nossa capacidade de implementar um controle detalhado da distribuição de carga.
- Cache e desatualização de DNS: os clientes frequentemente armazenam em cache as respostas do DNS, o que os leva a enviar solicitações para endpoints desatualizados ou não íntegros.
- Sem suporte para metadados: os registros DNS não carregam nenhum metadado adicional sobre os endpoints (por exemplo, zona, região, shard). Isso torna difícil ou impossível implementar estratégias como roteamento com reconhecimento de zona ou de topologia.
Embora os serviços headless possam oferecer uma melhoria temporária em relação aos serviços ClusterIP, os desafios práticos e as limitações os tornaram inadequados como uma solução de longo prazo na escala da Databricks.
Malhas de serviço (por exemplo, Istio)
O Istio fornece recursos poderosos de balanceamento de carga da Camada 7 usando sidecars do Envoy injetados em cada pod. Esses proxies lidam com roteamento, novas tentativas, interrupção de circuito e muito mais, tudo gerenciado centralmente por meio de um plano de controle.
Embora esse modelo ofereça muitos recursos, concluímos que ele não era adequado para nosso ambiente na Databricks por alguns motivos:
- Complexidade operacional: gerenciar milhares de sidecars e componentes do control plane adiciona uma sobrecarga significativa, especialmente durante atualizações e rollouts em grande escala.
- Sobrecarga de desempenho: os sidecars introduzem custos adicionais de CPU, memória e latência por pod, o que se torna substancial em nossa escala.
- Flexibilidade limitada do cliente: como toda a lógica de roteamento é tratada externamente, é difícil implementar estratégias que reconheçam a solicitação e que dependam do contexto da camada de aplicação.
Também avaliamos o Ambient Mesh do Istio. Como o Databricks já possuía sistemas proprietários para funções como distribuição de certificados e nossos padrões de roteamento eram relativamente estáticos, a complexidade adicional de adotar uma malha completa superou os benefícios. Isso foi especialmente verdadeiro para uma pequena equipe de infraestrutura que oferece suporte a uma base de código predominantemente em Scala.
Vale a pena notar que uma das maiores vantagens das malhas baseadas em sidecar é a independência de linguagem: as equipes podem padronizar a resiliência e o roteamento em serviços poliglotas sem precisar manter bibliotecas de cliente em todos os lugares. No Databricks, no entanto, nosso ambiente é fortemente baseado em Scala, e nossa cultura de monorepo e CI/CD rápido torna a abordagem sem proxy e com biblioteca de cliente muito mais prática. Em vez de introduzir a sobrecarga operacional dos sidecars, investimos na criação de um balanceamento de carga de primeira classe diretamente em nossas bibliotecas e componentes de infraestrutura.
Direções futuras e áreas de exploração
Nossa abordagem atual de balanceamento de carga no lado do cliente melhorou significativamente a comunicação interna de serviço a serviço. No entanto, à medida que o Databricks continua a crescer, estamos explorando várias áreas avançadas para aprimorar ainda mais nosso sistema:
Balanceamento de carga entre clusters e entre regiões: como gerenciamos milhares de clusters do Kubernetes em várias regiões, estender o balanceamento de carga inteligente para além dos clusters individuais é fundamental. Estamos explorando tecnologias como redes L3 planas e soluções de malha de serviço (service-mesh), integrando-se perfeitamente com clusters multirregionais do Endpoint Discovery Service (EDS). Isso permitirá um gerenciamento robusto do tráfego entre clusters, tolerância a falhas e utilização globalmente eficiente de recursos.
Estratégias avançadas de balanceamento de carga para casos de uso de IA: planejamos introduzir estratégias mais sofisticadas, como o balanceamento de carga ponderado, para dar melhor suporte a workloads de IA avançados. Essas estratégias permitirão uma alocação de recursos mais refinada e decisões de roteamento inteligentes com base nas características específicas da aplicação, otimizando, em última análise, o desempenho, o consumo de recursos e a eficiência de custos.
Se você tem interesse em trabalhar com desafios de infraestrutura distribuída em grande escala como este, estamos contratando. Venha construir conosco — explore as vagas abertas na Databricks!
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.