Apresentando o AI Runtime: GPUs NVIDIA escaláveis e sem servidor no Databricks para treinamento e ajuste fino
Treine os LLMs mais recentes com GPUs NVIDIA H100 instantaneamente disponíveis conectadas ao seu Lakehouse
por Tejas Sundaresan, Jianwei Xie, Bandish Shah e Hanlin Tang
- Com o AI Runtime, o Databricks agora oferece suporte a GPUs NVIDIA no Serverless Compute, permitindo acesso sob demanda a GPUs NVIDIA A10 e H100 escaláveis sem sobrecarga de infraestrutura.
- Treine modelos de visão computacional, LLMs, sistemas de recomendação baseados em deep learning e outros modelos com nosso runtime dedicado para treinamento distribuído – tudo pronto para usar.
- O AI Runtime é integrado com carregamento de dados de alta velocidade do Lakehouse, orquestração de fluxo de trabalho com Lakeflow e governança com Unity Catalog.
As GPUs impulsionam as cargas de trabalho de IA mais avançadas da atualidade — desde previsões e recomendações até modelos de fundação multimodais. No entanto, as equipes enfrentam dificuldades na aquisição e no gerenciamento de infraestrutura de GPU, na configuração de ambientes de treinamento distribuído e na depuração de gargalos no carregamento de dados. Pesquisadores de deep learning preferem focar na modelagem, não na solução de problemas de infraestrutura.
Temos o prazer de anunciar a Prévia Pública do AI Runtime (AIR), uma nova pilha de treinamento que permite o treinamento distribuído de GPU sob demanda em A10 e H100. O AI Runtime contém toda a tecnologia usada para treinamento em larga escala de LLMs como MPT e DBRX. Mesmo em Beta, centenas de clientes, incluindo Rivian, Factset e YipitData, usaram o AIR para treinar e lançar modelos de deep learning em produção. Os casos de uso abrangem desde modelos de visão computacional até sistemas de recomendação e LLMs ajustados para tarefas de agente. Nossa própria equipe de Pesquisa de IA da Databricks usou o AIR para aprendizado por reforço de modelos, como em nosso recente artigo sobre KARL.
Com o AI Runtime, os usuários do Databricks agora têm:
- GPUs NVIDIA sob demanda e sem servidor: Basta configurar seu notebook em 2-3 cliques e obter conexão rápida às GPUs A10 e H100 sem servidor para iniciar o treinamento – sem necessidade de cluster. Pague apenas pelas GPUs que você usa, sem se preocupar com o tempo ocioso.
- Ferramentas robustas de orquestração: Use todo o poder da suíte de orquestração do Databricks com Jobs do Lakeflow e suporte a DABs para cargas de trabalho de GPU de longa execução.
- Treinamento distribuído otimizado: O AIR inclui aprimoramentos de desempenho para treinamento distribuído de GPU, como RDMA e carregamento de dados de alto desempenho.
- Governança e observabilidade centralizadas: execute, observe e governe cargas de trabalho de GPU exatamente onde seus dados residem, com gerenciamento de experimentos integrado via MLflow, gerenciamento de acesso com Unity Catalog e depuração assistida por agente.
GPUs NVIDIA H100 e A10 sob demanda em notebooks
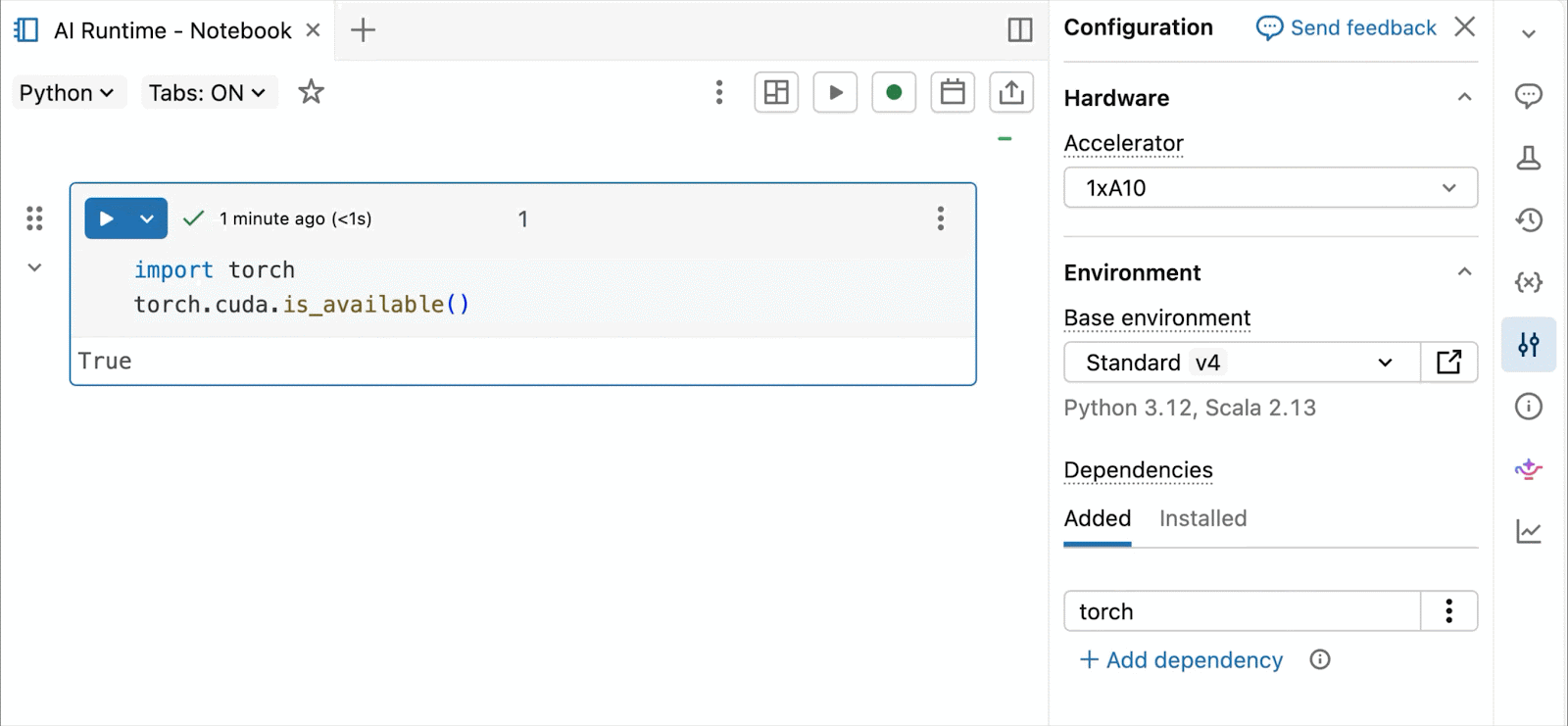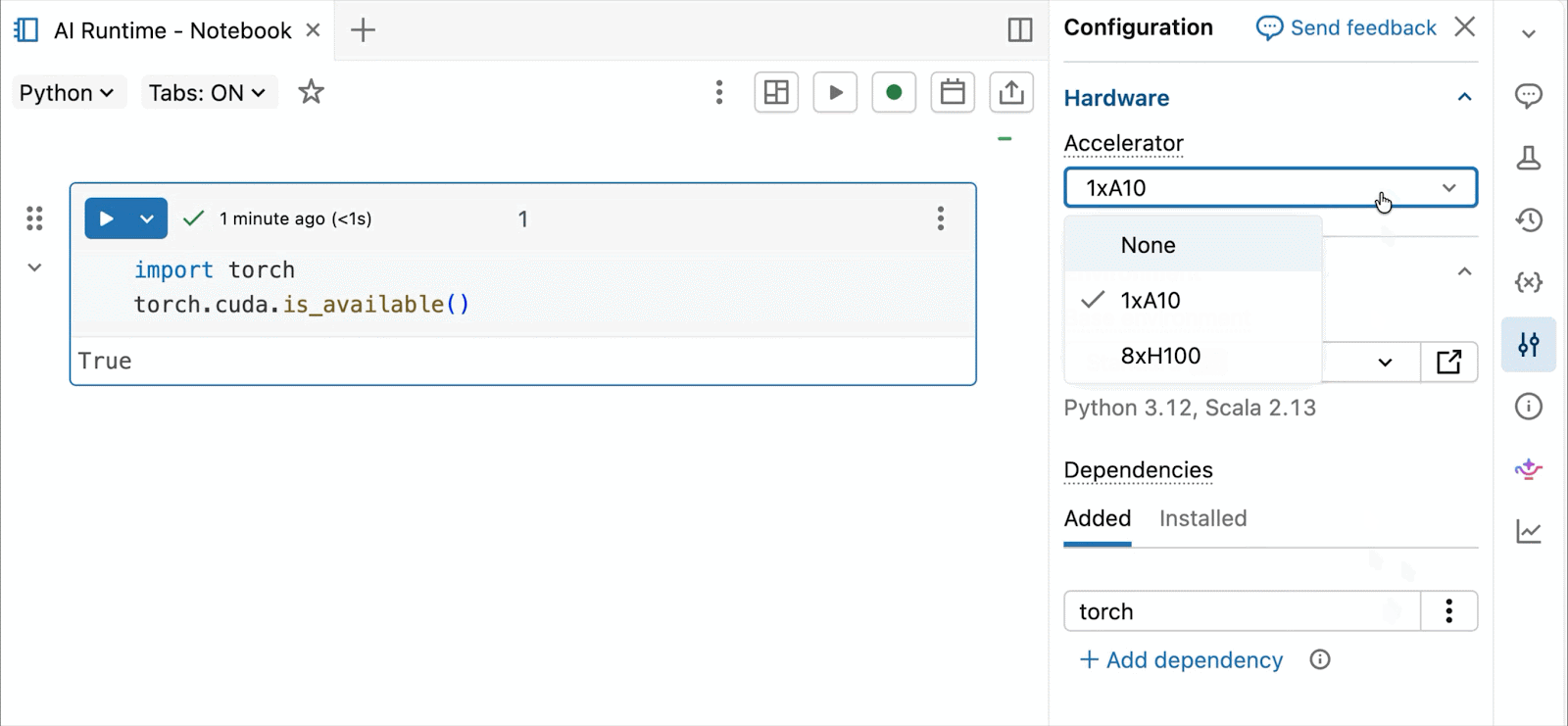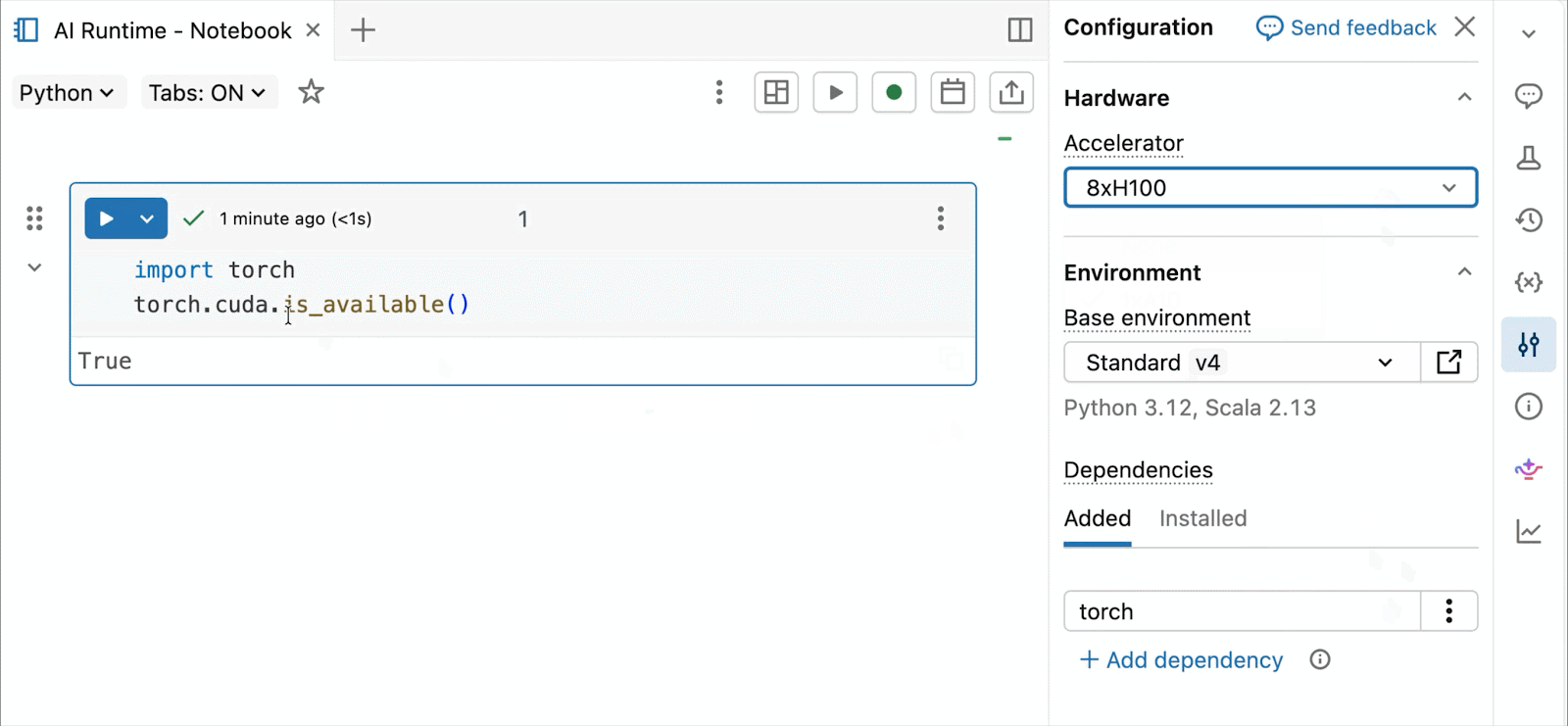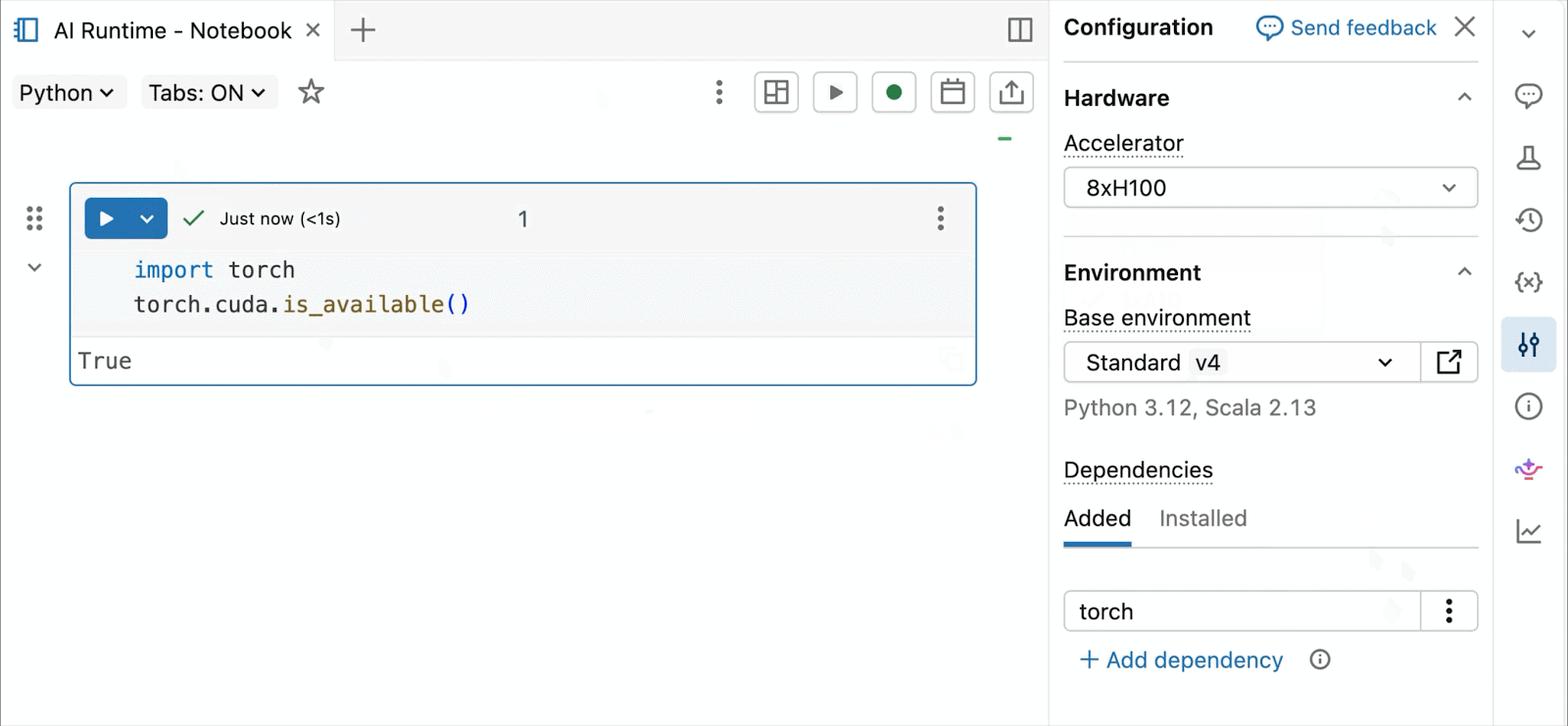
Para desenvolvimento interativo e depuração, conecte-se às GPUs A10 e H100 sob demanda nos Databricks Notebooks com apenas alguns cliques. A partir daí, aproveite toda a ergonomia do desenvolvedor pela qual o Databricks é conhecido, desde o gerenciamento de ambiente para pacotes Python comuns até a autoria e depuração com assistência de agente com Genie Code. Monte facilmente dados do Lakehouse para treinar modelos de deep learning, ou até mesmo invoque uma frota de CPUs remotas para cargas de trabalho de processamento de dados Spark a partir do seu notebook com GPU para preparar seus dados.
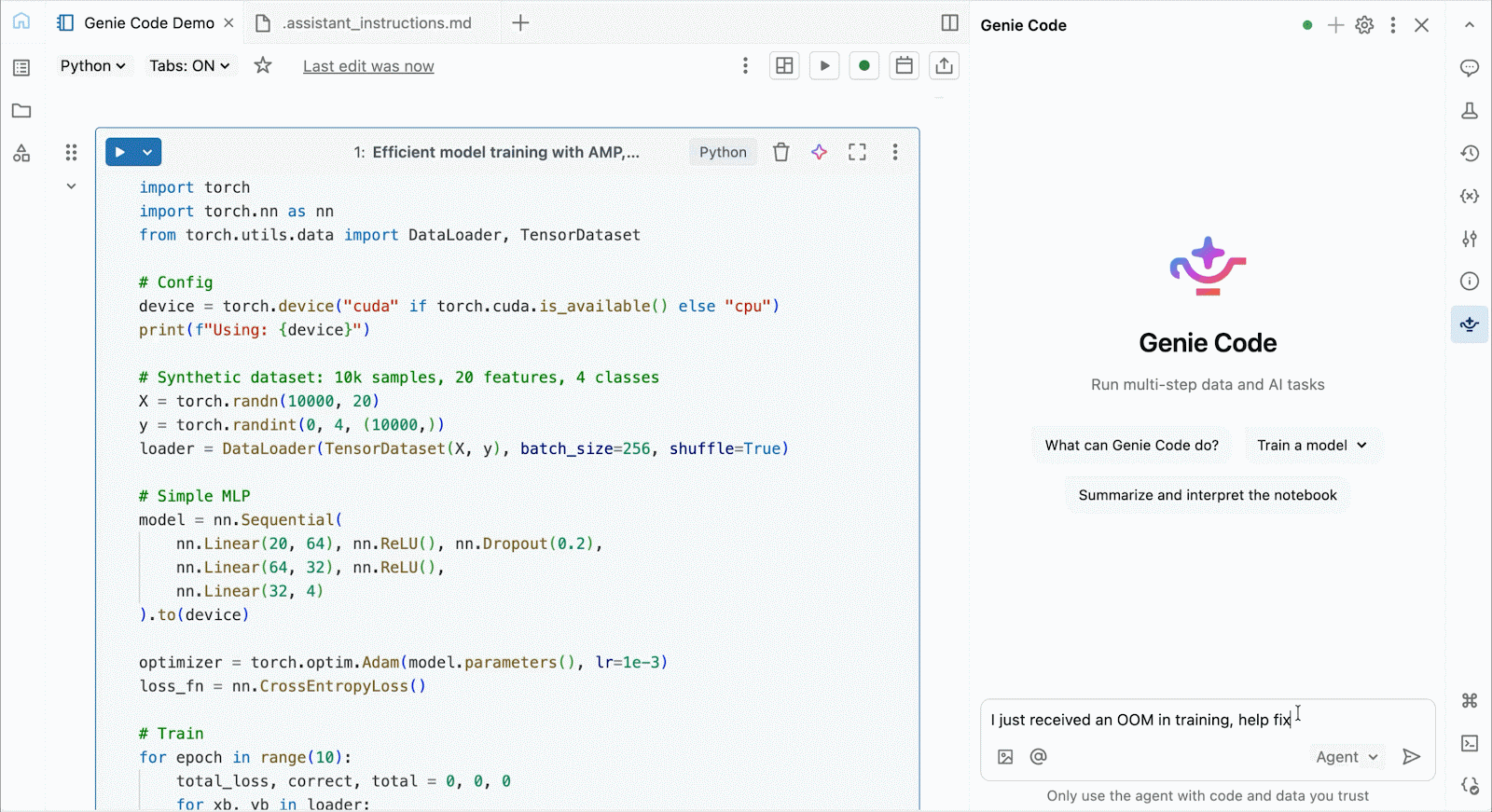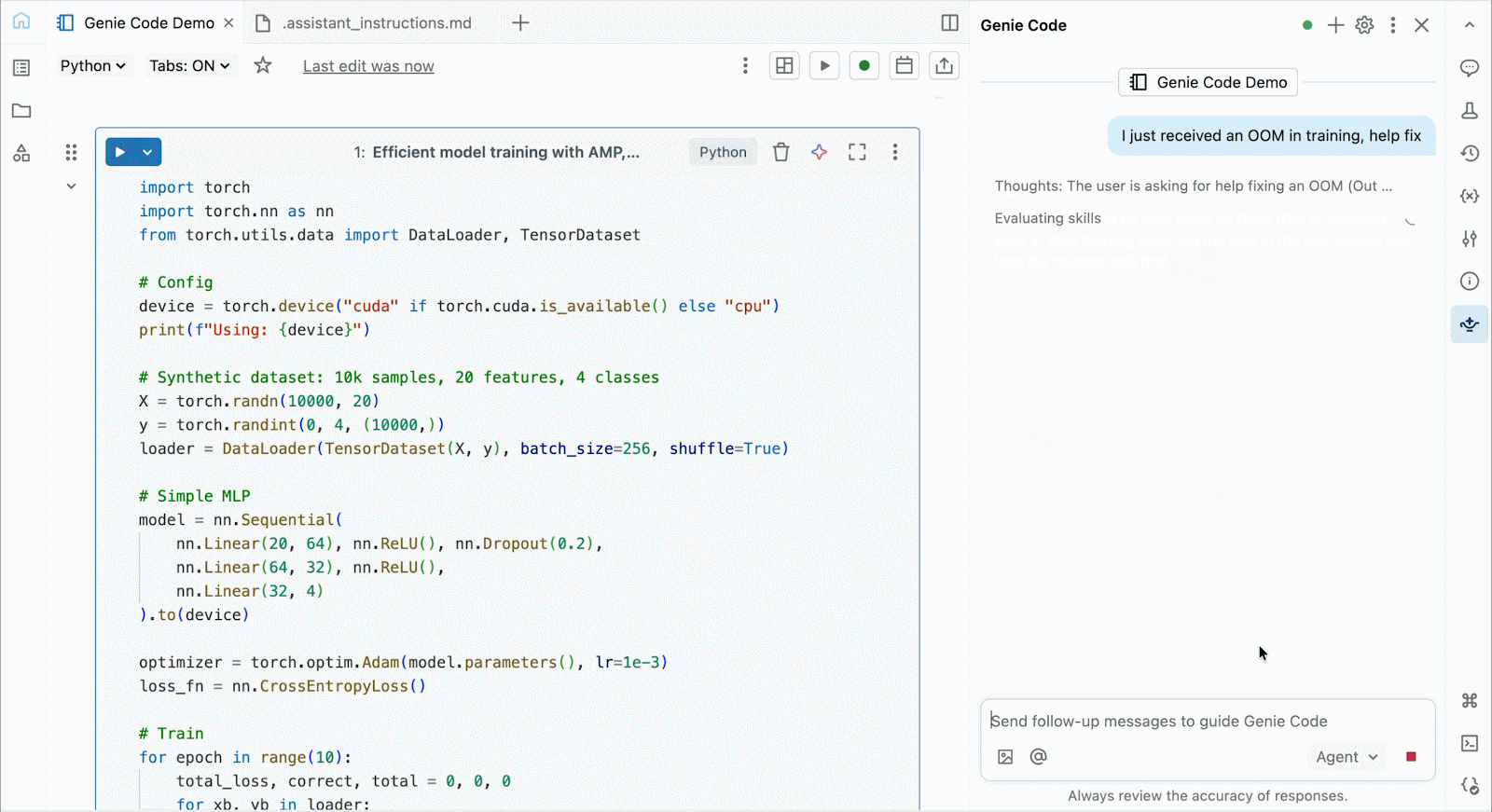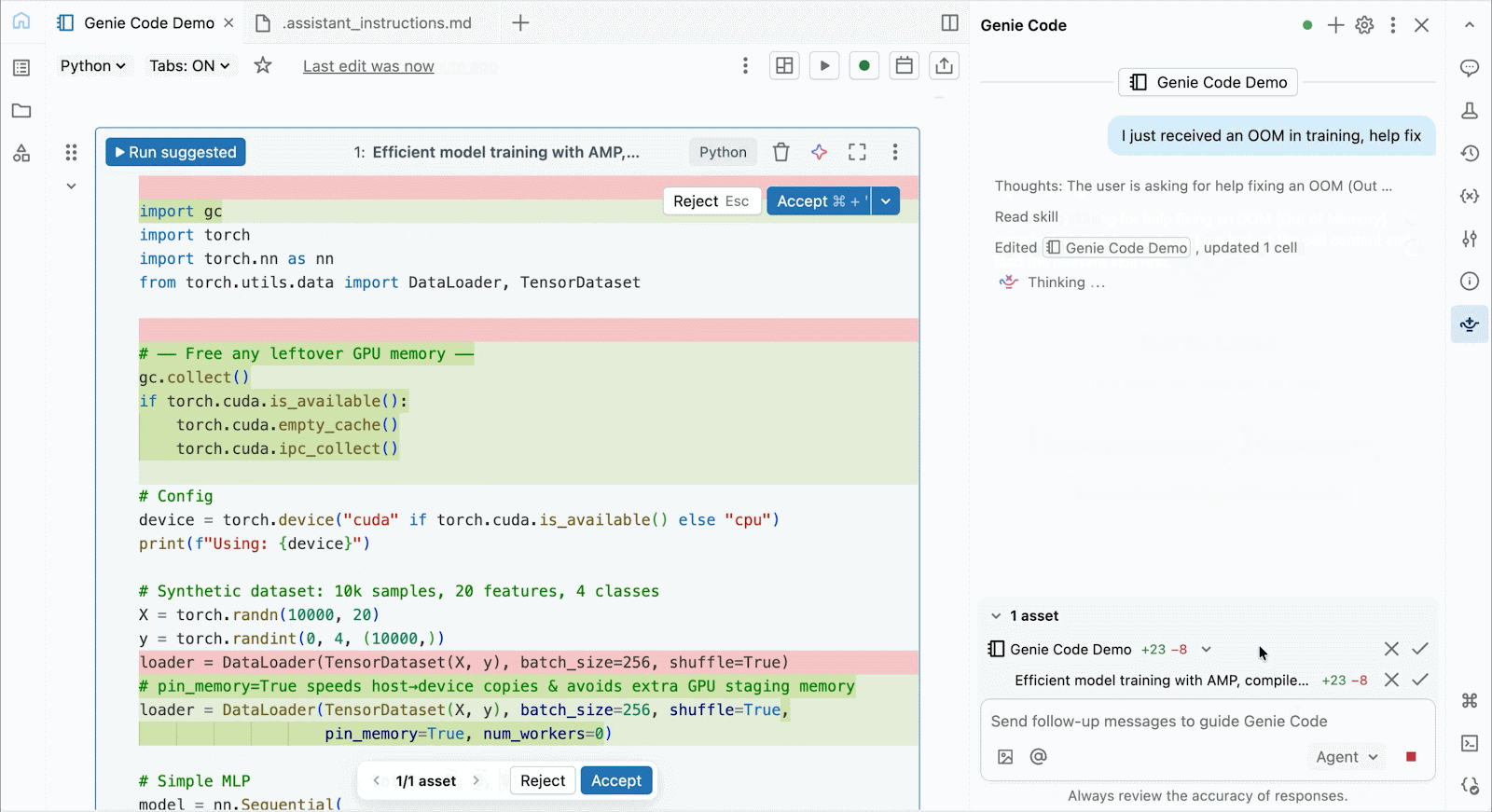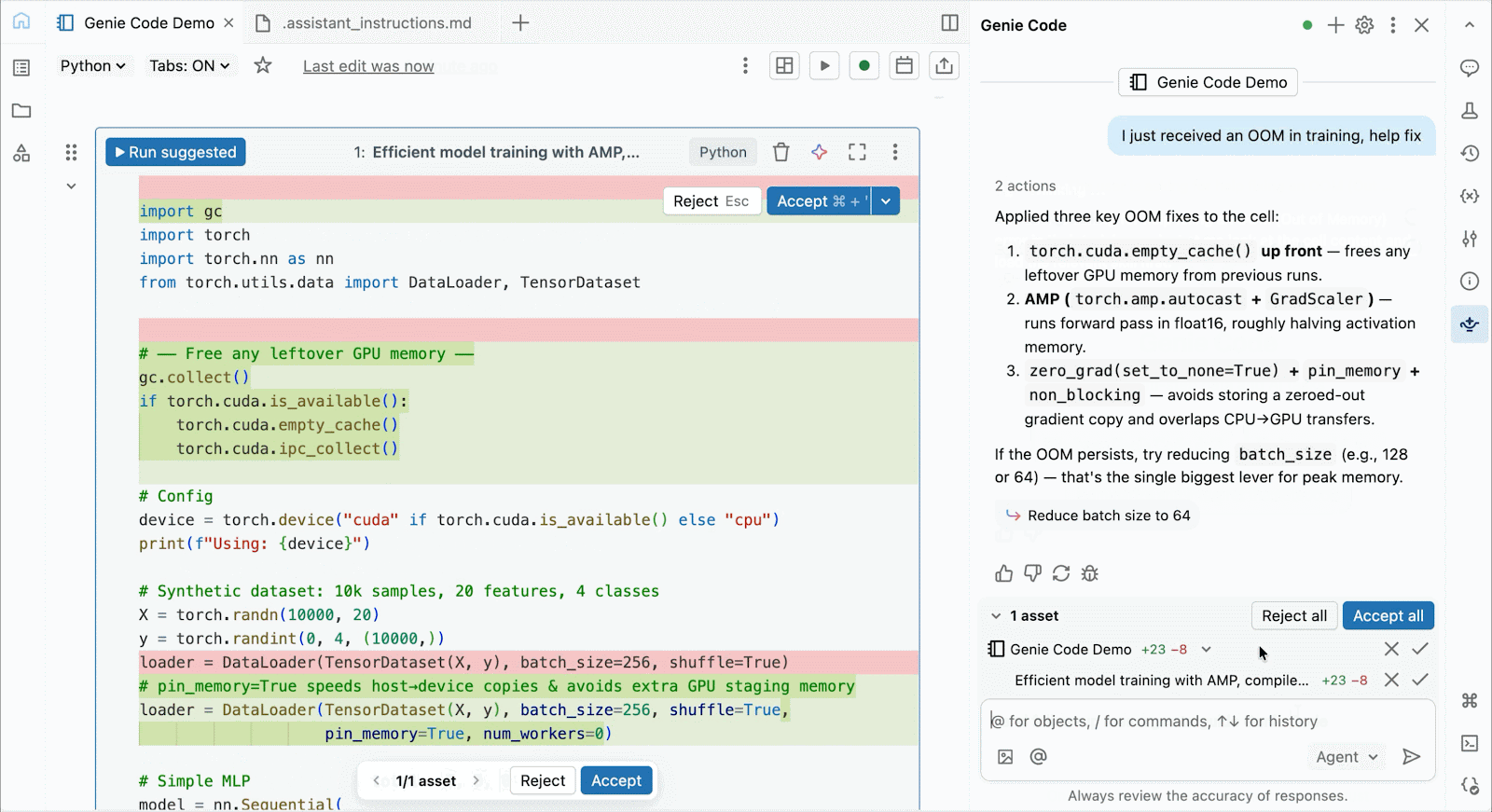
Use o Genie Code para ajudar a resolver gargalos de desempenho, experimentar novas arquiteturas ou depurar bugs complicados relacionados à convergência do modelo ou erros crípticos do framework.
Lakeflow para cargas de trabalho prontas para produção
O AI Runtime é uma plataforma de nível de produção para computação acelerada. Desenvolva seu código de deep learning em notebooks interativos e, em seguida, use todo o poder do Lakeflow para enviar e orquestrar jobs em computação de GPU. Tanto notebooks quanto repositórios de código personalizados podem ser executados pelo Lakeflow para jobs agendados ou de longa duração. Para necessidades de produção, como CI/CD (integração contínua e implantação contínua), o AI Runtime é totalmente compatível com nossos Declarative Automation Bundles (DABs).
Com nossa integração com o Lakeflow, os clientes podem manter o treinamento e o ajuste fino de modelos estritamente sincronizados com pipelines de dados upstream e sistemas de produção downstream.
“O AI Runtime da Databricks simplificou enormemente o processo de treinamento de um modelo personalizado de Texto para Fórmula (TTF). Sem configuração de infraestrutura ou atrasos, foi fácil escolher a computação certa com base no tamanho do prompt e na geração de tokens de saída. Isso nos permitiu avançar rapidamente, manter nossos fluxos de trabalho do Lakehouse e entregar um modelo de alta qualidade com governança completa, reduzindo o tempo de configuração, treinamento e implantação do nosso modelo de dias para horas.”—Nikhil Sunderraj, Principal Machine Learning Engineer, FactSet Research Systems, Inc.
Runtime otimizado para deep learning distribuído
Cargas de trabalho de treinamento distribuído podem ser difíceis de preparar, depurar e observar. Desde a solução de problemas de configurações RDMA até o rastreamento de telemetria de várias GPUs e a configuração correta de software, os usuários podem facilmente perder detalhes críticos que retardam dramaticamente o treinamento do modelo.
Em vez disso, o AI Runtime é otimizado para todo o ciclo de vida do deep learning — e foi projetado para economizar seu tempo. Dependências importantes como PyTorch e CUDA vêm pré-instaladas, juntamente com suporte otimizado para frameworks de treinamento distribuído como Ray, Hugging Face Transformers, Composer e outras bibliotecas, para que você possa começar a treinar imediatamente sem gerenciar ambientes. Os clientes também são bem-vindos para trazer suas próprias bibliotecas, de Unsloth a TorchRec a loops de treinamento personalizados.

SDKs integrados e ferramentas de observabilidade simplificam o gerenciamento de cargas de trabalho de treinamento distribuído. O MLFlow permite observabilidade profunda de cargas de trabalho de GPU, com rastreamento automático de utilização de GPU e experimentos de treinamento. Se você está ajustando modelos de fundação ou treinando modelos de previsão e personalização, o runtime é otimizado para acelerar fluxos de trabalho de treinamento com configuração mínima.
A Prévia Pública atual do AI Runtime suporta treinamento distribuído em 8x H100s em um único nó, com suporte multi-nó atualmente em Prévia Privada.
"O AI Runtime da Databricks nos permite executar cargas de trabalho de LLM (ajuste fino e inferência) de forma eficiente, sem sobrecarga de infraestrutura, diretamente em nosso lakehouse. Essa integração perfeita simplifica nossos pipelines e proporciona o uso eficiente de GPUs, permitindo-nos entregar insights de IA de alta qualidade aos nossos clientes e focar em inovação, não em infraestrutura.”—Lucas Froguel, Senior AI Platform Engineer, YipitData
Governança e observabilidade de dados centralizadas
O AI Runtime se integra nativamente ao Databricks Lakehouse, permitindo que você execute e governe cargas de trabalho de GPU onde seus dados residem. Isso elimina fluxos de trabalho fragmentados e simplifica o caminho da experimentação à produção.
- Governança centralizada com Unity Catalog: Aplique controles de acesso consistentes, linhagem e políticas de governança em cargas de trabalho de dados e IA, permitindo o uso seguro e em conformidade de recursos de GPU.
- Observabilidade unificada: Rastreie e monitore todas as cargas de trabalho — CPU e GPU — em um só lugar usando tabelas de sistema nativas para auditoria unificada, rastreamento de uso e insights operacionais.
Suas cargas de trabalho de IA são executadas totalmente dentro do perímetro de dados da sua empresa, oferecendo forte governança e segurança sem sacrificar a flexibilidade para experimentação e escala.
“Aproveitar o suporte de GPU sem servidor do Databricks dentro do nosso Lakehouse nos permite treinar eficientemente modelos avançados de áudio e multimodais sem sobrecarga de infraestrutura. Essa integração perfeita simplifica os fluxos de trabalho e proporciona o uso eficiente de recursos de GPU, garantindo que entreguemos sistemas de alto desempenho e foquemos na inovação.”—Arjuna Siva, VP de Infotainment & Connectivity, Rivian e Volkswagen Group Technologies
Integrando Inovação de GPU de Próxima Geração da NVIDIA
A demanda por computação acelerada continua crescendo em cargas de trabalho de IA e sistemas de agentes. O AI Runtime permite que mais clientes Databricks aproveitem o hardware NVIDIA para acelerar suas cargas de trabalho de IA e impulsionar seus negócios. Estamos animados para continuar a parceria com a NVIDIA para trazer a tecnologia NVIDIA mais recente, como o RTX PRO 4500 Blackwell Server Edition, anunciado na GTC 2026 para nossos clientes.
"À medida que a adoção de IA acelera em todos os setores, as organizações precisam de infraestrutura escalável e de alto desempenho para potencializar suas cargas de trabalho de dados e IA. As tecnologias NVIDIA trazem desempenho acelerado para a oferta de AI Runtime na Databricks Lakehouse Platform."—Pat Lee, Vice-Presidente de Parcerias Estratégicas na NVIDIA.
Comece hoje mesmo com o AI Runtime
Para ajudar você a começar, preparamos vários notebooks de modelo e guias de início rápido:
- Consulte nossa documentação para instruções detalhadas sobre configuração e uso diário.
- Modelos de início rápido para treinar sistemas de recomendação, modelos de ML clássicos, ajuste fino de LLMs e muito mais!
- Guia de migração de cargas de trabalho de GPU do Classic Compute para Serverless.
Entre em contato com sua equipe de conta para saber mais ou se tiver alguma dúvida!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.