Conheça o KARL: um agente mais rápido para o conhecimento corporativo, impulsionado por RL personalizado
Aprendizagem por Reforço para Agentes Corporativos
Para ver o relatório técnico completo, clique aqui. Interessado em experimentar o RL personalizado da Databricks em seu agente corporativo? Clique aqui.
A capacidade de raciocínio aprimorada dos modelos atuais levou a uma explosão de agentes implantados para o trabalho de conhecimento, como escrever código, fazer perguntas sobre dados corporativos e automatizar fluxos de trabalho comuns. Embora os modelos usados em tarefas corporativas sejam muito poderosos, eles também são extremamente caros, e os custos de inferência começaram a crescer de forma insustentável para muitos casos de uso. Neste post e no relatório técnico correspondente, descrevemos nossa experiência usando a aprendizagem por reforço (RL) para criar modelos personalizados para potencializar casos de uso que são uma parte fundamental do nosso produto Agent Bricks. Este exemplo demonstra que, a custos relativamente baixos, é possível criar modelos personalizados que dominam estritamente os modelos de fronteira nas três dimensões críticas: custo de inferência, latência e qualidade. Nossas descobertas são consistentes com outras observações do setor, como o modelo Composer da Cursor, em que a personalização baseada em RL conseguiu melhorar drasticamente tanto a velocidade quanto a qualidade em comparação com as alternativas.
KARL: um agente de conhecimento mais rápido, mais forte e mais barato para usuários da Databricks
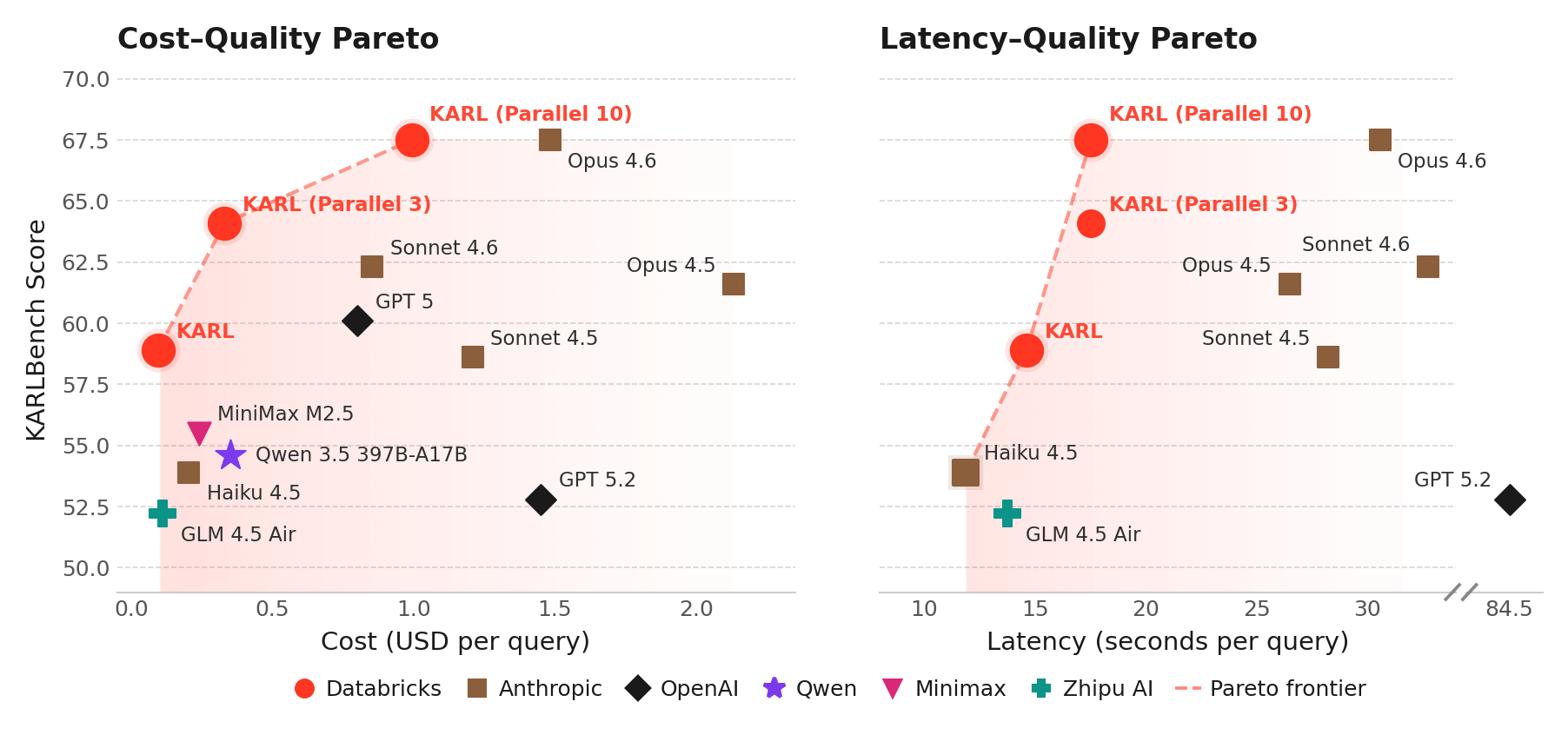
O modelo que treinamos, que chamamos de KARL, aborda uma capacidade corporativa crítica, o raciocínio fundamentado: responder a perguntas pesquisando documentos, apurando fatos, cruzando informação e raciocinando ao longo de dezenas ou centenas de os passos. O raciocínio fundamentado é necessário para vários produto Databricks, como o Agent Bricks Knowledge Assistant. Diferentemente de matemática e programação, a tarefa de raciocínio fundamentado é difícil de verificar – muitas vezes não há uma única resposta correta. Em situações como essa, orientar a aprendizagem por reforço para boas soluções é especialmente difícil.
Usando as técnicas de RL e a infraestrutura desenvolvidasna Databricks, o KARL iguala o desempenho dos modelos proprietários mais poderosos do mundo por uma fração do custo de serviço e da latência, inclusive em novas tarefas de raciocínio fundamentado que ele nunca tinha visto. ( Consulte o relatório técnico para obter todos os detalhes.) Fizemos isso com apenas alguns milhares de horas de GPU de treinamento e dados totalmente sintéticos.
Em testes internos com usuários humanos, o KARL forneceu respostas melhores e mais abrangentes do que nossos produtos existentes e os mais recentes modelos de fronteira. Esta pesquisa está sendo incorporada aos agentes Databricks que você usa hoje, como o Agent Bricks, fundamentando as respostas em seus dados não estruturados e estruturados no Databricks Lakehouse.
Um pipeline de RL reutilizável para clientes da Databricks
Temos o prazer de anunciar que os mesmos pipelines e infraestrutura de RL que usamos para criar o KARL (e outros agentes sobre os quais falaremos em breve) agora estão disponíveis para os clientes da Databricks que buscam melhorar o desempenho do modelo e reduzir os custos de suas cargas de trabalho de agentes de alto volume. Quase todas as tarefas corporativas do mundo real são difíceis de verificar, então o KARL abre caminho – não apenas para uma melhor experiência para os usuários da Databricks – mas para que nossos clientes criem seus próprios modelos de RL personalizados para seus agentes populares. Nosso private preview do RL Personalizado, apoiado pelo AI Runtime, permite que você use a infraestrutura do KARL para criar uma versão mais eficiente e específica do domínio para o seu agente. Se você tem um agente de IA que está escalando rapidamente e tem interesse em otimizá-lo com RL, inscreva-se aqui para manifestar seu interesse neste preview.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.