Apresentando o Apache Spark 4.0
Agora disponível no Databricks Runtime 17.0
por Wenchen Fan, Serge Rielau, Herman van Hövell, Hyukjin Kwon, Allison Wang, Anish Shrigondekar, Daniel Tenedorio, Martin Grund, DB Tsai, Xiao Li e Reynold Xin
A Edição Gratuita substituiu a Edição Comunitária, oferecendo recursos aprimorados sem custo. Comece a usar a Edição Gratuita hoje mesmo.
Apache Spark 4.0 marca um marco importante na evolução do motor de análise Spark. Esta versão traz avanços significativos em todas as áreas – desde aprimoramentos na linguagem SQL e conectividade expandida, até novas capacidades em Python, melhorias em streaming e usabilidade. O Spark 4.0 foi projetado para ser mais poderoso, compatível com ANSI e fácil de usar do que nunca, mantendo a compatibilidade com cargas de trabalho Spark existentes. Neste post, explicamos os principais recursos e melhorias introduzidos no Spark 4.0 e como eles elevam sua experiência de processamento de big data.
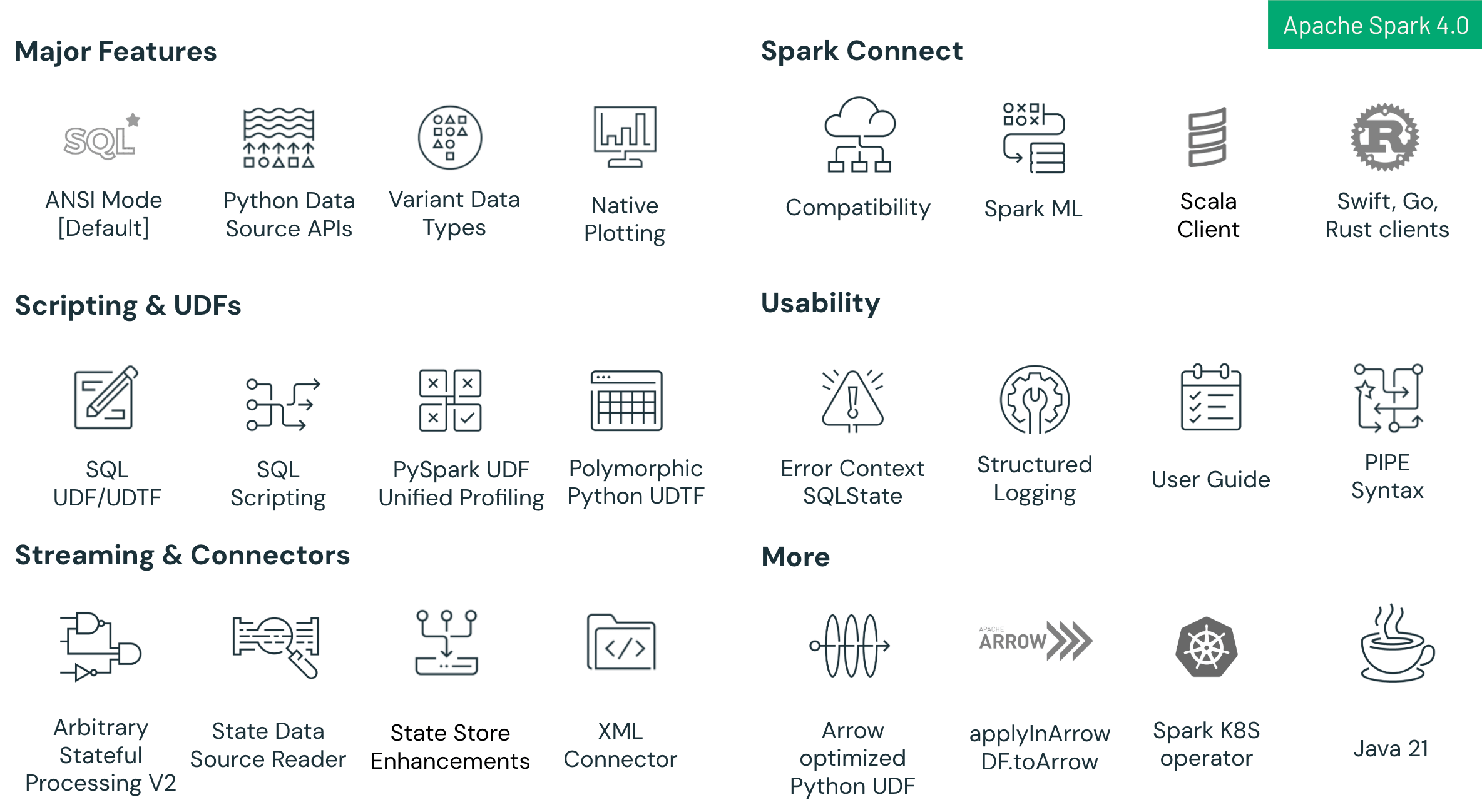
Principais Destaques no Spark 4.0 incluem:
- Aprimoramentos na Linguagem SQL: Novas funcionalidades, incluindo scripting SQL com variáveis de sessão e fluxo de controle, Funções Definidas pelo Usuário (UDFs) SQL reutilizáveis e a sintaxe intuitiva PIPE para otimizar e simplificar fluxos de trabalho analíticos complexos.
- Aprimoramentos no Spark Connect: O Spark Connect – a nova arquitetura cliente-servidor do Spark – agora atinge alta paridade de recursos com o Spark Clássico no Spark 4.0. Esta versão adiciona compatibilidade aprimorada entre Python e Scala, suporte a múltiplos idiomas (com novos clientes para Go, Swift e Rust) e um caminho de migração mais simples através da nova configuração spark.api.mode. Desenvolvedores podem alternar facilmente do Spark Clássico para o Spark Connect para se beneficiar de uma arquitetura mais modular, escalável e flexível.
- Aprimoramentos de Confiabilidade e Produtividade: O modo SQL ANSI ativado por padrão garante maior integridade de dados e melhor interoperabilidade, complementado pelo tipo de dados VARIANT para manipulação eficiente de dados JSON semiestruturados e logging JSON estruturado para melhor observabilidade e solução de problemas mais fácil.
- Avanços na API Python: Plotagem nativa baseada em Plotly diretamente em DataFrames PySpark, uma API Python Data Source que permite conectores batch e streaming personalizados em Python, e UDTFs Python polimórficas para suporte a esquemas dinâmicos e maior flexibilidade.
- Avanços em Structured Streaming: Nova API de Processamento de Estado Arbitrário chamada transformWithState em Scala, Java e Python para lógica de estado personalizada robusta e tolerante a falhas, melhorias na usabilidade do state store e um novo State Store Data Source para melhor depuração e observabilidade.
Nas seções abaixo, compartilhamos mais detalhes sobre esses recursos empolgantes e, ao final, fornecemos links para os esforços JIRA relevantes e posts de blog detalhados para aqueles que desejam saber mais. O Spark 4.0 representa uma plataforma robusta e preparada para o futuro para processamento de dados em larga escala, combinando a familiaridade do Spark com novas capacidades que atendem às necessidades modernas de engenharia de dados.
Principais Melhorias no Spark Connect
Uma das atualizações mais empolgantes no Spark 4.0 são as melhorias gerais no Spark Connect, em particular no cliente Scala. Com o Spark 4, todos os recursos do Spark SQL oferecem compatibilidade quase completa entre o Spark Connect e o modo de execução Clássico, com apenas pequenas diferenças restantes. O Spark Connect é a nova arquitetura cliente-servidor para Spark que desacopla a aplicação do usuário do cluster Spark e, no 4.0, está mais capaz do que nunca:
- Compatibilidade Aprimorada: Uma grande conquista para o Spark Connect no Spark 4 é a compatibilidade aprimorada das APIs Python e Scala, que torna a alternância entre o uso do Spark Clássico e do Spark Connect transparente. Isso significa que, para a maioria dos casos de uso, tudo o que você precisa fazer é habilitar o Spark Connect para suas aplicações definindo
spark.api.modecomoconnect. Recomendamos começar a desenvolver novos jobs e aplicações com o Spark Connect habilitado para que você possa se beneficiar ao máximo do poderoso motor de otimização e execução de consultas do Spark. - Suporte a Múltiplos Idiomas: O Spark Connect no 4.0 suporta uma ampla gama de idiomas e ambientes. Clientes Python e Scala são totalmente suportados, e novos clientes de conexão suportados pela comunidade para Go, Swift e Rust estão disponíveis. Este suporte poliglota significa que os desenvolvedores podem usar o Spark no idioma de sua escolha, mesmo fora do ecossistema JVM, através da API Connect. Por exemplo, uma aplicação de engenharia de dados em Rust ou um serviço Go agora pode se conectar diretamente a um cluster Spark e executar consultas DataFrame, expandindo o alcance do Spark além de sua base de usuários tradicional.
Recursos de Linguagem SQL
O Spark 4.0 adiciona novas capacidades para simplificar a análise de dados:
- Funções Definidas pelo Usuário (UDFs) SQL – O Spark 4.0 introduz UDFs SQL, permitindo que os usuários definam funções personalizadas reutilizáveis diretamente em SQL. Essas funções simplificam a lógica complexa, melhoram a manutenibilidade e se integram perfeitamente ao otimizador de consultas do Spark, aprimorando o desempenho das consultas em comparação com UDFs baseadas em código tradicionais. As UDFs SQL suportam definições temporárias e permanentes, facilitando o compartilhamento de lógica comum entre várias consultas e aplicações pelas equipes. [Leia o post do blog]
- Sintaxe PIPE SQL – O Spark 4.0 introduz uma nova sintaxe PIPE, permitindo que os usuários encadeiem operações SQL usando o operador |>. Essa abordagem de estilo funcional melhora a legibilidade e a manutenibilidade das consultas, permitindo um fluxo linear de transformações. A sintaxe PIPE é totalmente compatível com SQL existente, permitindo adoção gradual e integração em fluxos de trabalho atuais. [Leia o post do blog]
- Collações que diferenciam idioma, acento e maiúsculas/minúsculas - O Spark 4.0 introduz uma nova propriedade COLLATE para tipos STRING. Você pode escolher entre várias collações que diferenciam idioma e região para controlar como o Spark determina a ordem e as comparações. Você também pode decidir se as collações devem ser insensíveis a maiúsculas/minúsculas, acentos e espaços em branco no final. [Leia o post do blog]
- Variáveis de sessão - O Spark 4.0 introduz variáveis locais de sessão, que podem ser usadas para manter e gerenciar estado dentro de uma sessão sem usar variáveis de linguagem host. [Leia o post do blog]
- Marcadores de parâmetro - O Spark 4.0 introduz marcadores de parâmetro nomeados (":var") e não nomeados ("?"). Este recurso permite parametrizar consultas e passar valores com segurança através da API spark.sql(). Isso mitiga o risco de injeção de SQL. [Veja a documentação]
- Scripting SQL: Escrever fluxos de trabalho SQL de várias etapas é mais fácil no Spark 4.0 graças às novas capacidades de scripting SQL. Agora você pode executar scripts SQL com várias instruções com recursos como variáveis locais e fluxo de controle. Este aprimoramento permite que engenheiros de dados movam partes da lógica ETL para SQL puro, com o Spark 4.0 suportando construções que antes só eram possíveis através de linguagens externas ou stored procedures. Este recurso será ainda mais aprimorado em breve com o tratamento de condições de erro. [Leia o post do blog]
Integridade de Dados e Produtividade do Desenvolvedor
O Spark 4.0 introduz várias atualizações que tornam a plataforma mais confiável, compatível com padrões e fácil de usar. Esses aprimoramentos otimizam os fluxos de trabalho de desenvolvimento e produção, garantindo maior qualidade de dados e solução de problemas mais rápida.
- Modo SQL ANSI: Uma das mudanças mais significativas no Spark 4.0 é a ativação do modo SQL ANSI por padrão, alinhando o Spark mais de perto com a semântica SQL padrão. Essa mudança garante um tratamento de dados mais rigoroso, fornecendo mensagens de erro explícitas para operações que anteriormente resultavam em truncamentos silenciosos ou nulos, como overflows numéricos ou divisão por zero. Além disso, a adesão aos padrões SQL ANSI melhora muito a interoperabilidade, simplificando a migração de cargas de trabalho SQL de outros sistemas e reduzindo a necessidade de reescritas extensas de consultas e retreinamento de equipes. No geral, esse avanço promove fluxos de trabalho de dados mais claros, confiáveis e portáteis. [Veja a documentação]
- Novo Tipo de Dados VARIANT: O Apache Spark 4.0 introduz o novo tipo de dados VARIANT, projetado especificamente para dados semiestruturados. Ele permite o armazenamento de estruturas complexas de JSON ou semelhantes a mapas em uma única coluna, mantendo a capacidade de consultar eficientemente campos aninhados. Essa poderosa funcionalidade oferece flexibilidade significativa de esquema, facilitando a ingestão e o gerenciamento de dados que não se conformam a esquemas predefinidos. Além disso, a indexação e a análise de campos JSON integradas do Spark aprimoram o desempenho das consultas, facilitando buscas e transformações rápidas. Ao minimizar a necessidade de etapas repetidas de evolução de esquema, VARIANT simplifica os pipelines de ETL, resultando em fluxos de trabalho de processamento de dados mais otimizados. [Leia o post do blog]
- Logging Estruturado: O Spark 4.0 introduz um novo framework de logging estruturado que simplifica a depuração e o monitoramento. Ao habilitar
spark.log.structuredLogging.enabled=true,o Spark grava logs como linhas JSON — cada entrada incluindo campos estruturados como timestamp, nível de log, mensagem e o contexto completo do Mapped Diagnostic Context (MDC). Este formato moderno simplifica a integração com ferramentas de observabilidade como Spark SQL, ELK e Splunk, tornando os logs muito mais fáceis de analisar, pesquisar e interpretar. [Saiba mais]
Avanços na API Python
Os usuários Python têm muito o que comemorar no Spark 4.0. Esta versão torna o Spark mais "Pythonic" e melhora o desempenho das cargas de trabalho PySpark:
- Suporte Nativo a Plotagem: A exploração de dados no PySpark ficou mais fácil – o Spark 4.0 adiciona recursos nativos de plotagem aos DataFrames PySpark. Agora você pode chamar um método .plot() ou usar uma API associada em um DataFrame para gerar gráficos diretamente dos dados do Spark, sem coletar dados manualmente para o pandas. Nos bastidores, o Spark usa o Plotly como o backend de visualização padrão para renderizar gráficos. Isso significa que tipos de gráficos comuns como histogramas e gráficos de dispersão podem ser criados com uma linha de código em um DataFrame PySpark, e o Spark cuidará de buscar uma amostra ou agregação dos dados para plotar em um notebook ou GUI. Ao suportar plotagem nativa, o Spark 4.0 otimiza a análise exploratória de dados – você pode visualizar distribuições e tendências do seu conjunto de dados sem sair do contexto do Spark ou escrever código separado em matplotlib/plotly. Este recurso é um grande impulso de produtividade para cientistas de dados que usam PySpark para EDA.
- API Python de Fonte de Dados: O Spark 4.0 introduz uma nova API Python de Fonte de Dados que permite aos desenvolvedores implementar fontes de dados personalizadas para batch e streaming inteiramente em Python. Anteriormente, escrever um conector para um novo formato de arquivo, banco de dados ou fluxo de dados geralmente exigia conhecimento de Java/Scala. Agora, você pode criar leitores e gravadores em Python, o que abre o Spark para uma comunidade mais ampla de desenvolvedores. Por exemplo, se você tem um formato de dados personalizado ou uma API que possui apenas um cliente Python, você pode encapsulá-lo como uma fonte/destino de DataFrame do Spark usando esta API. Este recurso melhora muito a extensibilidade para PySpark em contextos de batch e streaming. Veja o post de aprofundamento em PySpark para um exemplo de implementação de uma fonte de dados personalizada simples em Python ou confira uma amostra de exemplos aqui. [Leia o post do blog]
- UDTFs Python Polimórficas: Baseado na capacidade UDTF do SQL, o PySpark agora suporta Funções de Tabela Definidas pelo Usuário em Python, incluindo UDTFs polimórficas que podem retornar diferentes formatos de esquema dependendo da entrada. Você pode criar uma classe Python como UDTF usando um decorador que gera um iterador de linhas de saída e registrá-la para que possa ser chamada do Spark SQL ou da API DataFrame. Um aspecto poderoso são as UDTFs de esquema dinâmico – sua UDTF pode definir um método analyze() para produzir um esquema dinamicamente com base em parâmetros, como ler um arquivo de configuração para determinar as colunas de saída. Esse comportamento polimórfico torna as UDTFs extremamente flexíveis, permitindo cenários como o processamento de um esquema JSON variável ou a divisão de uma entrada em um conjunto variável de saídas. UDTFs PySpark efetivamente permitem que a lógica Python produza um resultado de tabela completo por invocação, tudo dentro do motor de execução do Spark. [Veja a documentação]
Melhorias em Streaming
O Apache Spark 4.0 continua a refinar o Structured Streaming para melhorar desempenho, usabilidade e observabilidade:
- Processamento de Estado Arbitrário v2: O Spark 4.0 introduz um novo operador de Processamento de Estado Arbitrário chamado transformWithState. TransformWithState permite a construção de pipelines operacionais complexos com suporte para definição de lógica orientada a objetos, tipos compostos, suporte para timers e TTL, suporte para manipulação de estado inicial, evolução de esquema de estado e uma série de outros recursos. Esta nova API está disponível em Scala, Java e Python e fornece integrações nativas com outros recursos importantes, como o leitor de fonte de dados de estado, manipulação de metadados do operador, etc. [Leia o post do blog]
- Fonte de Dados de Estado - Leitor: O Spark 4.0 adiciona a capacidade de consultar o estado de streaming como uma tabela. Esta nova fonte de dados de armazenamento de estado expõe o estado interno usado em agregações de streaming com estado (como contadores, janelas de sessão, etc.), junções, etc., como um DataFrame legível. Com opções adicionais, este recurso também permite que os usuários rastreiem alterações de estado por atualização para visibilidade detalhada. Este recurso também ajuda a entender qual estado seu job de streaming está processando e pode auxiliar ainda mais na solução de problemas e monitoramento da lógica com estado de seus streams, bem como na detecção de quaisquer corrupções subjacentes ou violações de invariantes. [Leia o post do blog]
- Melhorias no State Store: O Spark 4.0 também adiciona inúmeras melhorias no state store, como gerenciamento aprimorado de reutilização de arquivos Static Sorted Table (SST), melhorias no gerenciamento de snapshots e manutenção, formato de checkpoint de estado reformulado, bem como melhorias adicionais de desempenho. Juntamente com isso, inúmeras alterações foram adicionadas em torno de logging e classificação de erros aprimorados para facilitar o monitoramento e a depuração.
Agradecimentos
O Spark 4.0 é um grande passo à frente para o projeto Apache Spark, com otimizações e novos recursos tocando todas as camadas — desde melhorias centrais até APIs mais ricas. Nesta versão, a comunidade fechou mais de 5000 JIRA issues e cerca de 400 contribuidores individuais — de desenvolvedores independentes a organizações como Databricks, Apple, Linkedin, Intel, OpenAI, eBay, Netease, Baidu — impulsionaram essas melhorias.
Estendemos nossos sinceros agradecimentos a cada contribuidor, seja você abriu um ticket, revisou código, melhorou a documentação ou compartilhou feedback em listas de e-mail. Além das principais melhorias em SQL, Python e streaming, o Spark 4.0 também oferece suporte a Java 21, operador Spark K8S, conectores XML, suporte Spark ML no Connect e Perfil Unificado de UDF PySpark. Para a lista completa de alterações e todos os outros refinamentos no nível do motor, consulte as notas de lançamento oficiais do Spark 4.0.
Obtendo o Spark 4.0: É totalmente open source — baixe-o de spark.apache.org. Muitos de seus recursos já estavam disponíveis no Databricks Runtime 15.x e 16.x, e agora eles vêm prontos de fábrica com o Runtime 17.0. Para explorar o Spark 4.0 em um ambiente gerenciado, inscreva-se na Edição Comunitária ou inicie um teste gratuito, escolha "17.0" ao iniciar seu cluster, e você estará executando o Spark 4.0 em minutos.
Se você perdeu nosso meetup do Spark 4.0 onde discutimos esses recursos, você pode ver as gravações aqui. Além disso, fique atento aos futuros meetups de aprofundamento sobre esses recursos do Spark 4.0.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.