Apresentando SQL Espacial no Databricks: mais de 80 funções para análise geoespacial de alto desempenho
O melhor "armazém" de dados é um lakehouse
por Kent Marten e Michael Johns
- Acelere suas consultas geoespaciais em escala com mais de 80 funções Spatial SQL, agora disponíveis em preview público.
- Armazene dados planares e geodésicos de forma integrada usando os tipos de dados nativos GEOMETRY e GEOGRAPHY.
- Melhore sua análise espacial com joins espaciais de alta performance e esqueça a indexação manual.
Todos os dias, bilhões de pontos de dados estão ligados a locais no mapa. Rotas de entrega, visitas a lojas, redes de estradas, torres de celular e campos agrícolas, todos carregam um contexto importante para a tomada de decisões de negócios. O problema é que analisar esses dados em escala tem sido difícil. Sistemas espaciais legados são lentos, exigem indexação manual e frequentemente travam informações em formatos proprietários.
Hoje, apresentamos o Spatial SQL no Databricks. O Spatial SQL traz a análise geoespacial diretamente para a Plataforma Databricks. Agora você pode trabalhar com tipos de dados nativos GEOMETRY e GEOGRAPHY, usar mais de 80 funções SQL e executar junções espaciais com alta velocidade e desempenho, tudo isso mantendo seus dados abertos e prontos para escalar.
Os dados de localização desempenham um papel em quase todos os setores, e o Spatial SQL facilita o uso dessas informações.
Aqui estão alguns exemplos:
- Operações de varejo podem entender de onde vêm seus clientes analisando áreas e fluxo de pessoas
- Analistas de transporte podem melhorar a segurança e a experiência do cliente analisando incidentes de veículos e conectividade de rede celular
- Empresas de energia podem otimizar a implantação de equipes durante interrupções e encontrar locais ideais para fazendas de energia eólica e solar
- Operadores agrícolas podem aplicar técnicas de agricultura de precisão para reduzir custos e melhorar a eficiência da produção
- Analistas de seguros podem entender o risco analisando endereços de segurados em zonas de inundação, incêndio e furacão
- Organizações de saúde podem comparar e prever resultados de saúde analisando fatores ambientais em diferentes geografias
- E muito mais!
O Spatial SQL já está ajudando os clientes a acelerar o desempenho e reduzir custos:
“O Databricks Spatial SQL redefiniu como executamos junções espaciais em larga escala. Ao integrar funções do Spatial SQL em nossos pipelines de processamento, vimos um desempenho mais de 20 vezes mais rápido e custos mais de 50% menores nas mesmas cargas de trabalho. Essa inovação possibilita integrar e entregar dados ricos de rede rodoviária em uma escala e velocidade que simplesmente não eram viáveis antes.”
– Laxmi Duddu, Sr. Manager, Autonomy Data Platform & Analytics, Rivian Automotive
Anteriormente, os clientes lutavam para gerenciar e escalar cargas de trabalho espaciais com sistemas legados, bibliotecas de terceiros ou recorrendo a estratégias de indexação manual. Com o Spatial SQL, os clientes obtêm simplicidade e escalabilidade prontas para uso.
“O Spatial SQL nos permite escalar ETL geoespacial como nunca antes. Em vez de sobrecarregar servidores PostGIS com consultas pesadas, transferimos a carga para o Databricks e aproveitamos o processamento distribuído, junções espaciais rápidas e tratamento eficiente de dados vetoriais. É uma abordagem mais eficiente, resiliente e escalável para lidar com conjuntos de dados geoespaciais grandes e complexos.”
— Pierre Chenaux, Tech Leader do departamento Geoespacial, TotalEnergies
Um dos principais impulsionadores de desempenho é o suporte para tipos de dados geoespaciais de primeira classe. Em vez de armazenar dados geo em colunas de string, binário ou decimal, agora você pode usar os tipos de dados nativos GEOMETRY e GEOGRAPHY. Esses tipos incluem estatísticas de bounding box que o Databricks usa durante a execução da consulta para pular dados irrelevantes e acelerar junções. O Spatial SQL também fornece funções de importação para formatos padrão como Well Known Text, Well Known Binary, GeoJSON e valores simples de latitude ou longitude.
Esses tipos de dados são completamente abertos em Parquet, Iceberg e Delta. A equipe do Databricks contribuiu para a definição das especificações propostas, garantindo que não haja bloqueio em data warehouses proprietários. Com o SPIP do Apache Spark™ aprovado, GEOMETRY e GEOGRAPHY em breve serão tipos de dados de primeira classe no motor de código aberto também.
O que você pode fazer com o Spatial SQL?
O Spatial SQL é mais do que um conjunto de novas funções. Ele oferece os blocos de construção para gerenciar toda a jornada dos dados espaciais, desde o armazenamento e importação até a análise e transformação. Ao trabalhar com tipos de dados nativos e operações eficientes, você pode trazer a localização para consultas do dia a dia sem adicionar complexidade.
Aqui estão algumas das principais coisas que você pode fazer:
- Armazenar dados espaciais nativamente com GEOMETRY e GEOGRAPHY
- Importar e exportar em formatos como WKT, WKB, GeoJSON e GeoHash
- Construir novos objetos com construtores como ST_Point ou ST_MakeLine
- Calcular medições usando funções como ST_Distance e ST_AREA
- Realizar junções espaciais usando relacionamentos como ST_Contains e ST_Intersects
- Transformar entre sistemas de coordenadas com ST_Transform
- Editar, validar e combinar objetos espaciais usando ST_ISVALID ou ST_UNION_AGG
- E muito mais!
Esses recursos oferecem um kit de ferramentas completo para análise espacial diretamente em SQL, também disponível com APIs Python e Scala. Quando você os combina, eles desbloqueiam fluxos de trabalho reais que importam na prática, o que abordaremos na próxima seção.
Exemplos de Spatial SQL na prática
Dados geoespaciais estão em toda parte e crescendo. Traços de GPS com latitudes e longitudes são emitidos por um número crescente de dispositivos, sensores e veículos a cada segundo do dia. O mundo está sendo catalogado e atualizado constantemente, com locais, estradas, redes e limites modelados como pontos, linhas e polígonos. Em todos os setores – varejo, transporte e logística, energia, clima e ciências naturais, agricultura, setor público, serviços financeiros, imobiliário, seguros, telecomunicações – a localização é importante para todos os tomadores de decisão que precisam entender o “onde” em seus dados.
Criamos quatro exemplos curtos para começar a trabalhar com os novos tipos de dados e expressões espaciais com os seguintes objetivos.
- Preparar dados para processamento eficiente usando o novo tipo GEOMETRY
- Realizar enriquecimento de dados combinando dois conjuntos de dados espaciais usando uma junção espacial
- Transformar dados em um sistema de referência espacial apropriado para melhorar a precisão das medições de distância
- Medir a distância entre duas cidades
Nesses exemplos, usaremos conjuntos de dados de endereços, edifícios e divisões do OvertureMaps.org. Esses conjuntos de dados são oferecidos para download de várias maneiras, como GeoParquet.
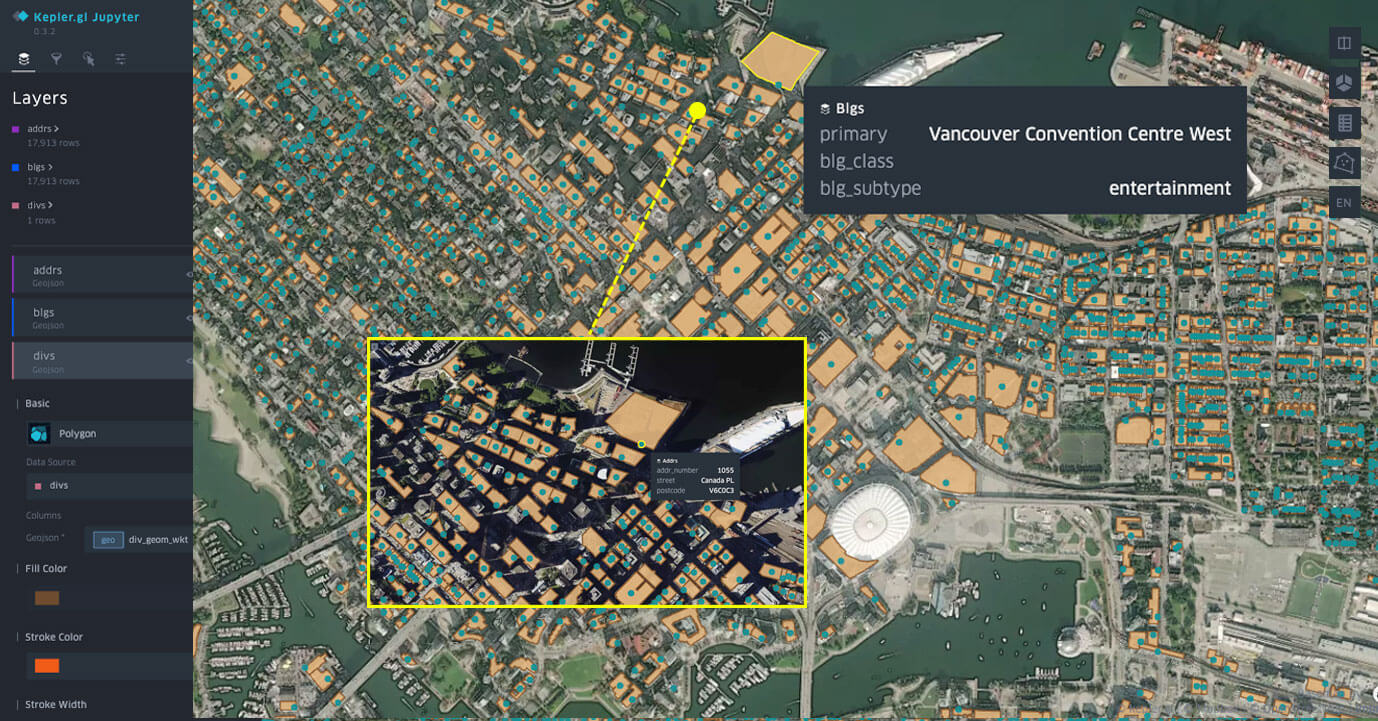
Conjuntos de dados do Overture Maps visualizados no Databricks Notebook com kepler.gl.
1. Criando uma coluna GEOMETRY
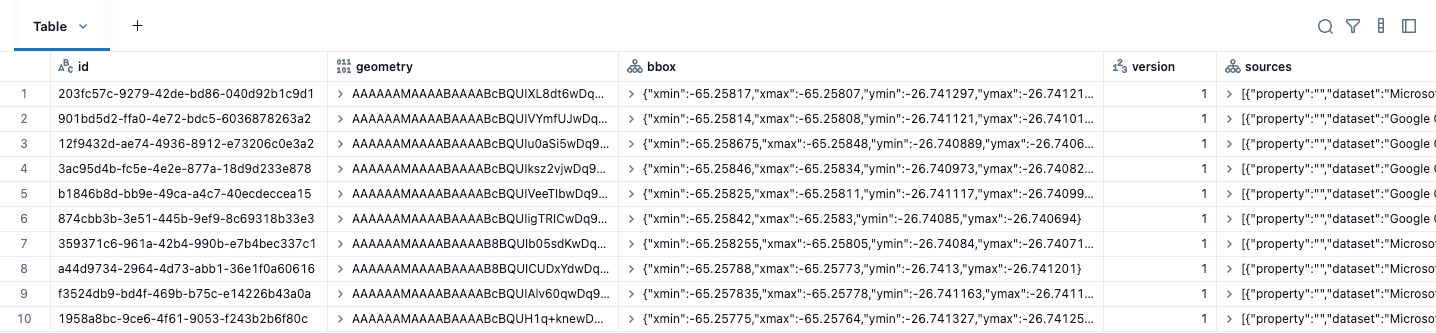
O primeiro passo antes de realizar qualquer análise espacial é converter seus dados para usar os tipos de dados GEOMETRY OU GEOGRAPHY. Após baixar os dados do Overture Maps, precisamos simplesmente criar uma coluna GEOMETRY nativa a partir da coluna de geometria WKB fornecida e remover outras colunas desnecessárias como bbox. Um bounding box é o menor retângulo que contém uma geometria. Em consultas espaciais, bounding boxes aceleram as consultas descartando rapidamente dados que não podem possivelmente se sobrepor. Se dois bounding boxes não se intersectam, as geometrias dentro deles definitivamente não se intersectam, então o banco de dados pode pular a verificação de interseção cara e reduzir a quantidade de dados sendo processados. Não precisamos do campo bbox porque essa informação agora é gerenciada nas estatísticas da coluna. Para esses conjuntos de dados, endereços são PONTOS, enquanto edifícios e divisões são POLÍGONOS / MULTI-POLÍGONOS. Aqui estão os dados de edifícios inicialmente baixados, mostrando as primeiras cinco colunas.
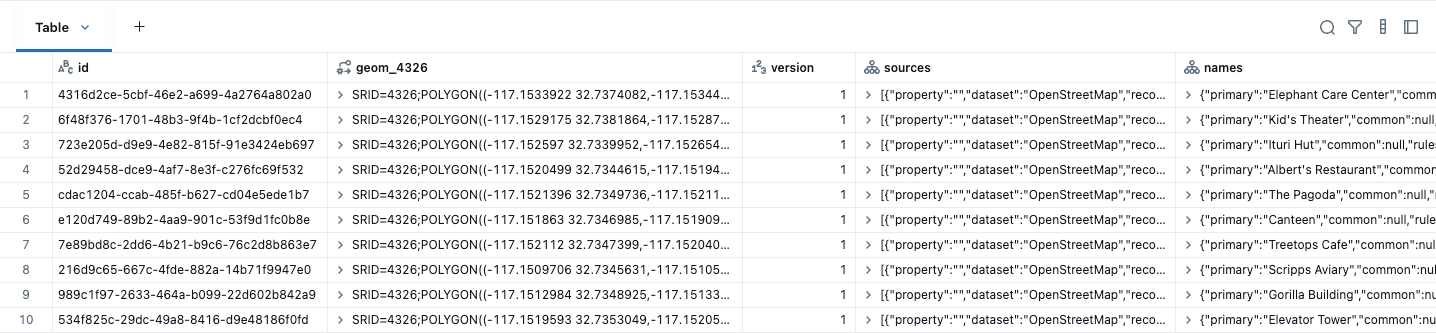
Esses dados podem ser facilmente convertidos em uma Tabela Lakehouse com GEOMETRY nativa usando ST_GeomFromWKB, como mostrado no exemplo abaixo para edifícios. Sabemos que nossos dados estão em WGS84 (EPSG:4326), então especificamos isso na criação do tipo espacial. Um SRID identifica o sistema de coordenadas dos seus dados espaciais, que define as unidades (como graus ou metros) usadas em cálculos como distância e área. Você deve definir um SRID válido ao criar uma coluna de geometria, caso contrário, a consulta retornará um erro. Além disso, observe que nossos tipos nativos são exibidos em um formato amigável (EWKT).
Além de WKB, dados espaciais também podem ser importados diretamente para nossos tipos nativos dos formatos de intercâmbio mais comuns:
- Coordenadas de latitude e longitude usando ST_POINT
- WKT usando ST_GeomFromWKT ou ST_GeomFromText
- WKB usando ST_GeomFromWKB ou ST_GeomFromBinary
- GeoJSON usando ST_GeomFromGeoJSON
- GeoHash usando ST_PointFromGeoHash
Da mesma forma, dados espaciais podem ser exportados como vários formatos:
- WKT usando ST_AsWKT ou ST_AsText
- WKB usando ST_AsWKB ou ST_AsBinary
- GeoJSON usando ST_AsGeoJSON
- WKT estendido usando ST_AsEWKT
- WKB estendido usando ST_AsEWKB
- GeoHash usando ST_GeoHash
Observação: Também temos expressões de importação e exportação para tipos GEOGRAPHY.
2. Juntando espacialmente vários conjuntos de dados
Junções espaciais estão entre as operações mais importantes e amplamente utilizadas no processamento de dados geoespaciais. Elas permitem combinar atributos de diferentes conjuntos de dados e realizar agregações ou enriquecimento de dados com base em seus relacionamentos espaciais, como contenção, interseção e proximidade. Isso torna as junções espaciais essenciais para responder a perguntas do mundo real, como identificar quais edifícios estão dentro de uma zona de inundação, atribuir dados demográficos de censo a endereços de clientes e analisar veículos conectados dentro de áreas de cobertura de celular. Como grande parte da análise geoespacial depende da integração de vários conjuntos de dados, as junções espaciais são frequentemente um primeiro passo na análise espacial exploratória, modelagem espacial e tomada de decisão baseada em localização.
Em seguida, juntaremos as tabelas de endereço e divisão usando uma junção espacial. Qualquer pessoa que tenha trabalhado com fontes de dados de endereço sabe que endereços podem ser dados confusos (uma causa comum é que diferentes países usam sistemas de endereçamento diferentes). Além disso, a tabela de endereços não inclui uma hierarquia administrativa completa (ou seja, nenhuma informação de condado para endereços dos EUA). Portanto, usaremos a tabela de divisão para validar as informações da cidade e enriquecê-la adicionando informações equivalentes de condado.
Esse processo de validação e enriquecimento de dados seria diferente de resolver sem uma junção espacial. Para fazer isso, precisamos encontrar o endereço dentro da divisão. Usaremos ST_Contains para realizar uma junção espacial ponto-em-polígono, deixando o Databricks lidar com os detalhes internos da operação, sem necessidade de indexação espacial manual.
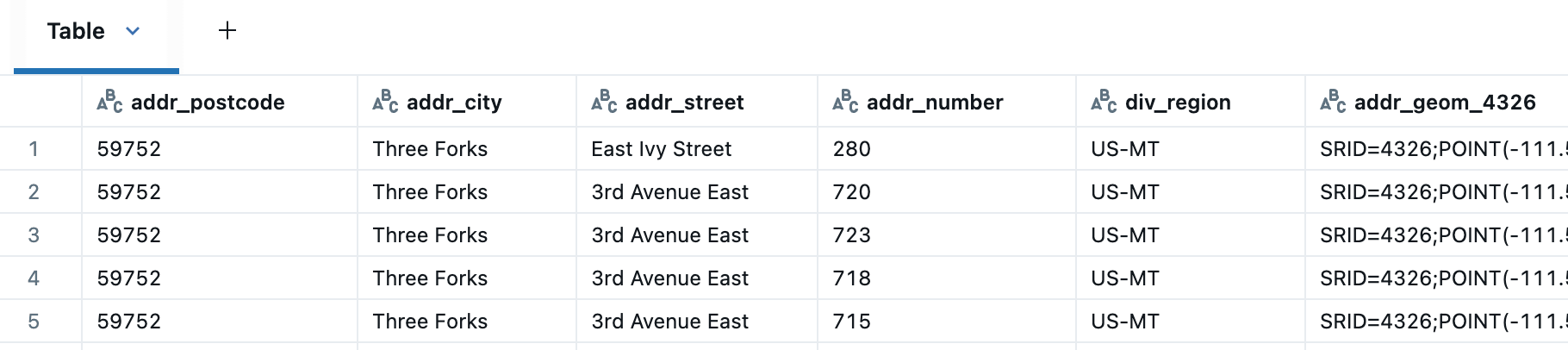
Agora podemos padronizar mais facilmente para a cidade, estado, condado e país corretos, por exemplo, substituir cidades ausentes em endereços pelas fornecidas na tabela de divisões.
Após validar os endereços, seguimos uma abordagem semelhante para juntar os endereços aos edifícios usando ST_Intersects para enriquecer a tabela Buildings com informações de endereço. Para os EUA, essa junção espacial casou 44 milhões de endereços com edifícios, com 55 milhões de edifícios permanecendo sem correspondência. No próximo exemplo, veremos como podemos usar a proximidade para identificar potencialmente edifícios que não corresponderam a um endereço.
3. Transformando dados para sistemas de referência espacial específicos
Conjuntos de dados geoespaciais são frequentemente criados em diferentes sistemas de referência de coordenadas (CRS), como latitude-longitude (WGS84) ou sistemas projetados como UTM, dependendo de sua origem e propósito. Enquanto cada CRS define como a superfície curva da Terra é representada em um mapa plano, usar conjuntos de dados com projeções incompatíveis pode fazer com que os recursos se desalinharem, distorçam distâncias ou produzam junções e medições espaciais incorretas. Uma loja localizada em uma zona de inundação não corresponderá em uma junção espacial se sistemas de coordenadas diferentes forem usados. Para análises precisas — seja calculando áreas, juntando camadas ou visualizando relacionamentos espaciais — é essencial garantir que todos os conjuntos de dados sejam transformados para a mesma projeção, para que compartilhem uma referência espacial consistente.
Para identificar endereços próximos aos 55 milhões de edifícios não correspondentes restantes nos EUA, vamos projetar nossos dados GEOMETRY WGS84 para Conus Albers (EPSG:5070) para a América do Norte, o que nos dá unidades em metros. Isso é realizado com a função ST_Transform.
Vamos aplicar ST_DWithin entre nossos edifícios e endereços não correspondentes dos EUA, usando um valor de distância dentro de apenas 2 metros.
O valor de distância dentro pode ser aumentado conforme necessário para reunir um conjunto de possíveis correspondências de endereço; além disso, uma CTE Recursiva pode ser útil para iterar sobre várias distâncias. Para este exemplo, um polígono de filtro nos permite isolar facilmente nossa pesquisa para a vizinhança de Saint Petersburg, Flórida. O polígono é inicialmente preparado a partir de WKT usando ST_GeomFromWKT, e então transformado para SRID 5070 para corresponder aos dados de endereço e edifício.
Para configurar conjuntos de dados para a CTE recursiva, aplicamos um filtro espacial em nossos dados, intersectando edifícios e endereços com o polígono de pesquisa, mostrando os edifícios abaixo (endereços são tratados de forma semelhante).
A CTE recursiva abaixo itera sobre os edifícios para identificar candidatos a endereço dentro de 5, 10 e 15 metros. A tabela de resultados remove endereços duplicados em distâncias sucessivas usando a seguinte expressão de janela: QUALIFY RANK() OVER (PARTITION BY blg_id,addr_id ORDER BY dwithin) = 1.
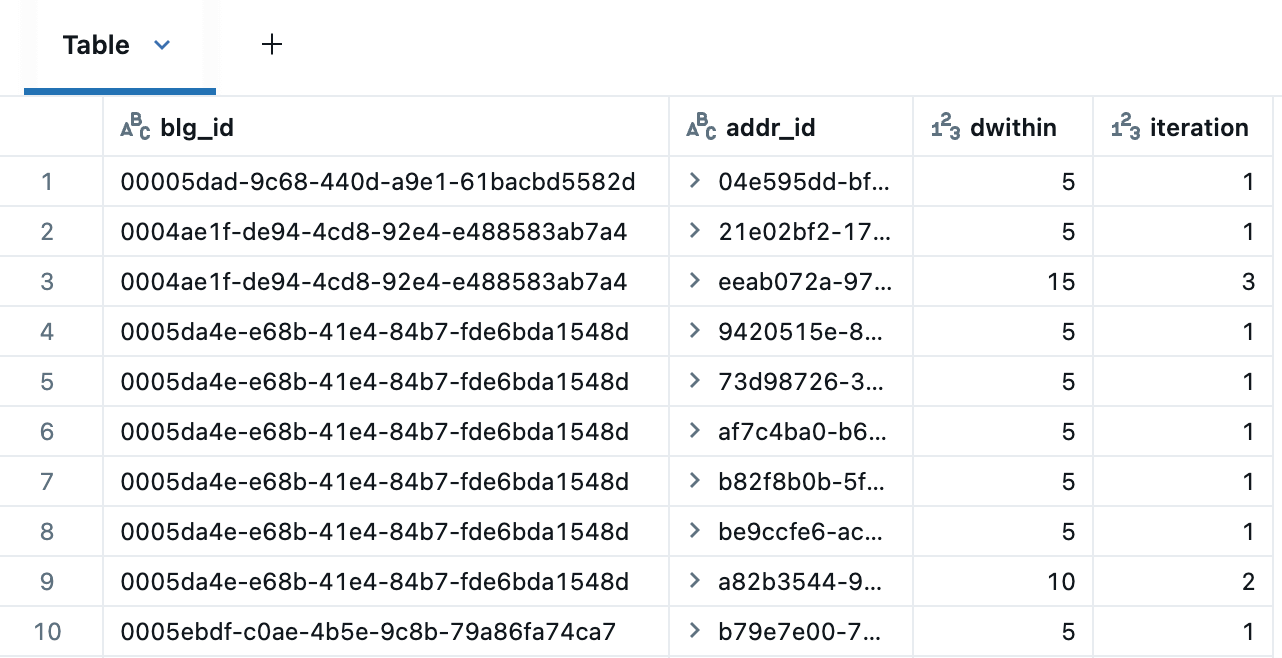
Aqui estão os candidatos de endereço ao redor de um dos prédios, mostrando correspondências a 5m (azul), 10m (laranja) e 15m (verde). Isso é renderizado usando os Marker Maps integrados do Databricks com o modo de cluster, que espalhará pontos próximos para facilitar a visualização. Ao criar um Dashboard, também poderíamos ter usado AI/BI Point Maps, que suportam filtros cruzados e drill-through.
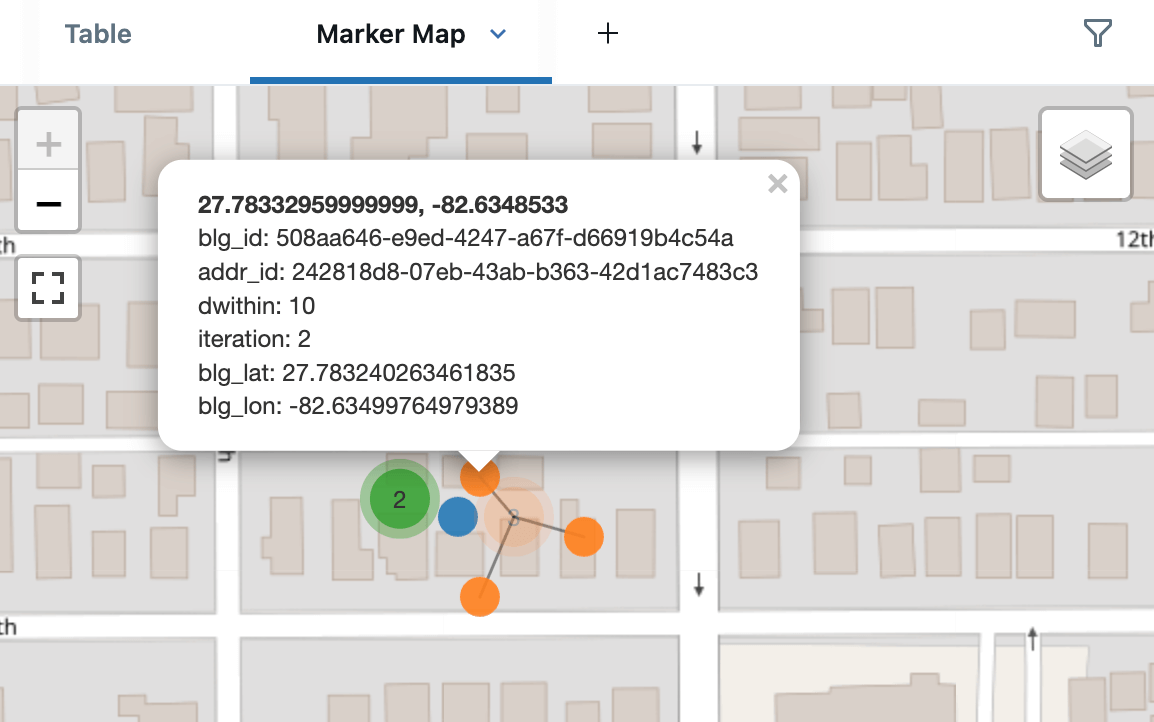
Existem inúmeros usos alternativos de CTEs Recursivas para processamento espacial, por exemplo, implementando o algoritmo de Prim para construir uma árvore geradora mínima de seus pontos de entrega.
4. Medindo distâncias entre locais
Proximidade é um conceito central na análise espacial porque a distância frequentemente determina a força ou relevância das relações entre locais. Seja identificando o hospital mais próximo, analisando a concorrência entre lojas ou mapeando padrões de deslocamento, entender a proximidade das feições umas das outras fornece um contexto crítico.
Continuando com nosso conjunto de dados de exemplo, realizamos a mesma operação de transformação Conus Albers em nossas cidades na Flórida para medir suas distâncias. Estamos medindo a partir do centro geométrico das cidades, gerado usando a função: ST_Centroid.
Ao calcular a distância entre duas GEOMETRIES, existem várias funções diferentes a serem consideradas:
- ST_Distance - Retorna a distância cartesiana nas unidades das GEOMETRIES fornecidas, calculando o caminho em linha reta com base em suas coordenadas x e y, como se a Terra fosse plana.
- ST_DistanceSphere - Retorna a distância esférica (sempre em metros) entre duas GEOMETRIES de ponto, medida no raio médio do elipsoide WGS84 da Terra, com pontos de coordenadas assumidos como tendo unidades de graus, por exemplo, SRID 4326 seria válido, mas não SRID 5070.
- ST_DistanceSpheroid - Retorna a distância geodésica (sempre em metros) entre duas GEOMETRIES de ponto no elipsoide WGS84 da Terra; também, com pontos de coordenadas assumidos como tendo unidades de graus. Novamente, SRID 4326, ou qualquer outro SRID com unidades em graus, seriam entradas válidas para este exemplo.
Os vários cálculos de distância são aplicados entre city1 e city2 com ST_Distance usada para as GEOMETRIES em 5070, então ST_DistanceSphere e ST_DistanceSpheroid para as GEOMETRIES em 4326.
Entre as funções de distância, anteciparíamos que ST_DistanceSpheriod (medições baseadas na forma elipsoidal da Terra) seria a mais precisa neste caso, seguida por ST_DistanceSphere (medições assumem que a Terra é uma esfera perfeita). Observe que ST_Distance é mais útil ao trabalhar em sistemas de referência de coordenadas projetados ou quando a curvatura da Terra pode ser ignorada. Mesmo que SRID 5070 esteja em metros, podemos ver os efeitos dos cálculos cartesianos em distâncias maiores. ST_Distance geralmente não seria uma escolha adequada para SRID 4326, dado que a distância coberta por um grau de longitude muda drasticamente à medida que você se move do equador para os polos, por exemplo, 1 grau de longitude difere em até 6KM apenas dentro do estado da Flórida.
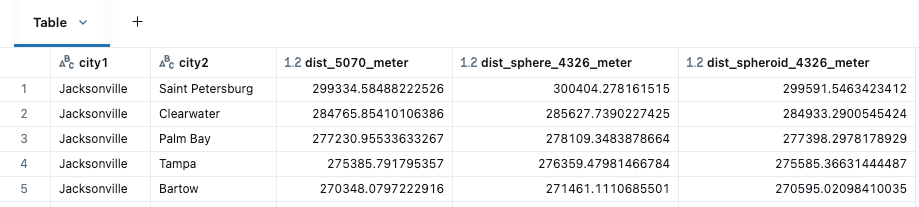
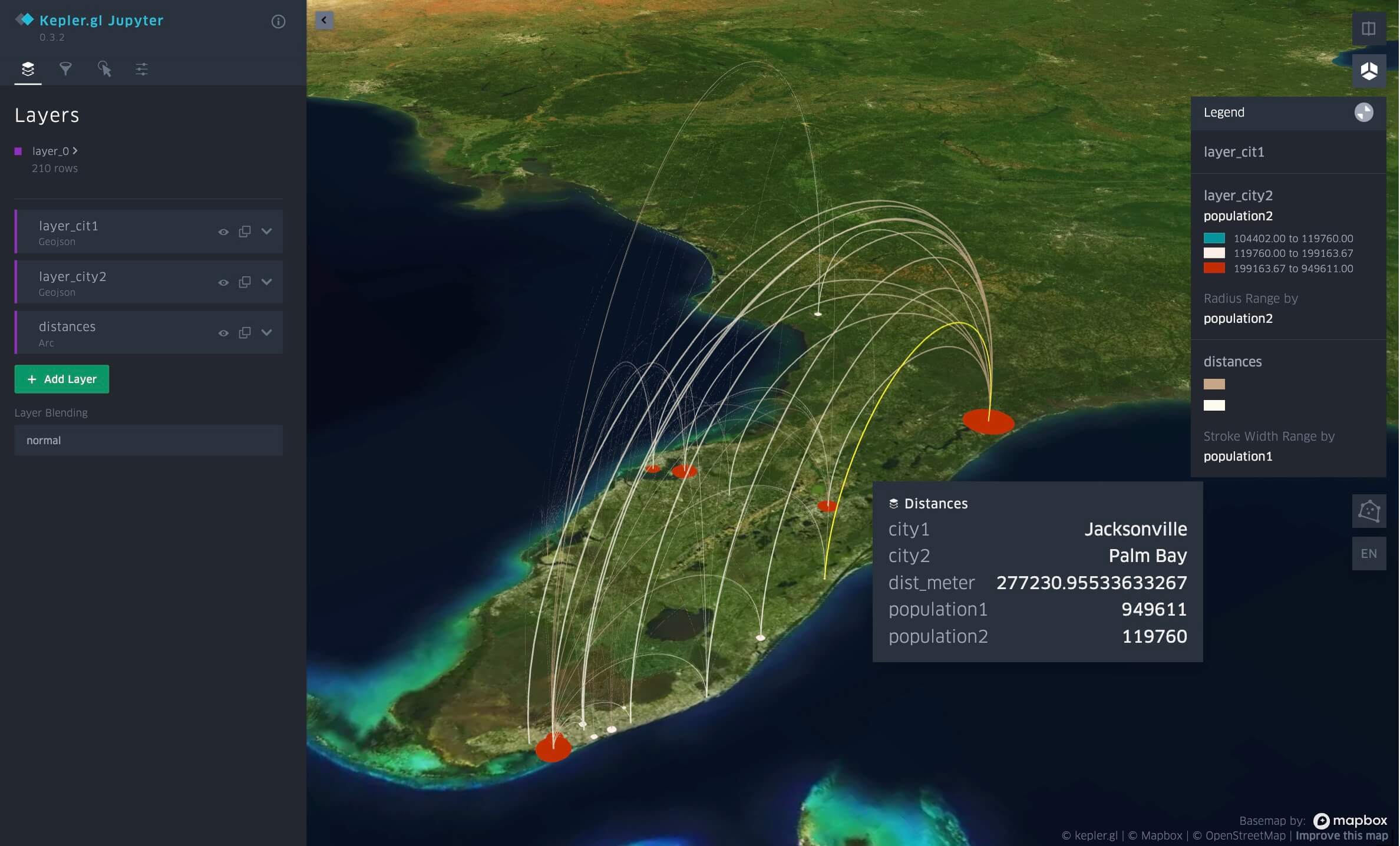
Proximidade por distância entre cidades da Flórida, visualizada no Databricks Notebook com kepler.gl.
O SQL Espacial inclui mais de 80 funções, permitindo que os clientes realizem operações comuns de dados espaciais com simplicidade e escala. Alimentado pelo SQL Espacial, os clientes agora estão começando a mudar sua abordagem para gerenciar e integrar com sistemas GIS:
“Dados espaciais estão no centro de tudo o que fazemos na OSPRI, seja Rastreabilidade de Gado, Erradicação de Doenças ou Gerenciamento de Pragas. O Databricks Spatial SQL nos permite integrar totalmente o Databricks com todo o nosso trabalho. Esses avanços nos permitem transferir grandes tarefas de modelagem espacial baseadas em desktop para uma plataforma onde elas estão mais próximas dos dados e podem ser executadas em paralelo, em alta velocidade. Semanas de iterações entre fronteiras operacionais podem ser confortavelmente executadas em um ou dois dias, reduzindo nosso tempo para a tomada de decisão. Essas novas funções também nos permitem fazer do Databricks a camada de integração entre nossos sistemas transacionais e nossa plataforma GIS, garantindo que ela possa ser informada por dados de toda a organização sem compromisso.” - Campbell Fleury, Gerente de Produtos de Dados e Informações, OSPRI Nova Zelândia
Próximos passos
Há muito que você pode fazer com o SQL Espacial no Databricks, com mais por vir, incluindo novas expressões e junções espaciais mais rápidas. Se você gostaria de compartilhar quais expressões ST adicionais você precisa, por favor, preencha esta curta pesquisa.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.