De Lag para Agilidade: Reinventando a Arquitetura de Ingestão de Dados da Freshworks
Processamento de Dados em Escala SaaS com Databricks
por Anand Chiddarwar, Kiran Kumar, Tamajit Hati, Pavan Parasa e Vasan Vembusrini
- Alta Capacidade de Transformação de Dados
Aprenda como a Freshworks usa o Spark Structured Streaming para processar conjuntos de dados diversos e de grande escala em quase tempo real. - Ingestão de Dados Otimizada no Delta Lake
Explore como recursos como Deletion Vectors e Disk Caching gerenciam até 35% de atualizações nos dados e impulsionam 4X fusões mais rápidas para ingestão eficiente e desempenho de consulta em tempo real. - Processamento de Dados Escalável e Custo-Eficiente
Veja como a escalabilidade automática, a multitarefa e as otimizações do Delta Lake nos ajudam a manter os SLAs e a reduzir o TCO enquanto lidamos com cargas massivas de dados.
Como uma empresa global de software como serviço (SaaS) especializada em fornecer soluções de negócios intuitivas e impulsionadas por IA, projetadas para melhorar a experiência de clientes e funcionários. Freshworks depende de dados em tempo real para tomar decisões e fornecer melhores experiências para seus mais de 75.000 clientes. Com milhões de eventos diários entre os produtos, o processamento de dados em tempo hábil é crucial. Para atender a essa necessidade, Freshworks construiu uma pipeline de ingestão quase em tempo real na Databricks, capaz de gerenciar esquemas diversos entre produtos e lidar com milhões de eventos por minuto com um SLA de 30 minutos, garantindo a isolação de dados a nível de inquilino em um ambiente multi-inquilino.
Alcançar isso requer um pipeline de dados potente, flexível e otimizado - é exatamente isso que nos propusemos a construir.
Arquitetura Legada e o Caso para a Mudança
O pipeline legado da Freshworks foi construído com consumidores Python; onde cada ação do usuário disparava eventos enviados em tempo real dos produtos para o Kafka e os consumidores Python transformavam e direcionavam esses eventos para novos tópicos do Kafka. Um sistema de loteamento Rails então converteu os dados transformados em arquivos CSV armazenados no AWS S3, e os trabalhos do Apache Airflow carregaram esses lotes no armazém de dados. Após a ingestão, os arquivos intermediários foram excluídos para gerenciar o armazenamento. Esta arquitetura foi bem adequada para o crescimento inicial, mas logo atingiu limites conforme o volume de eventos aumentou.
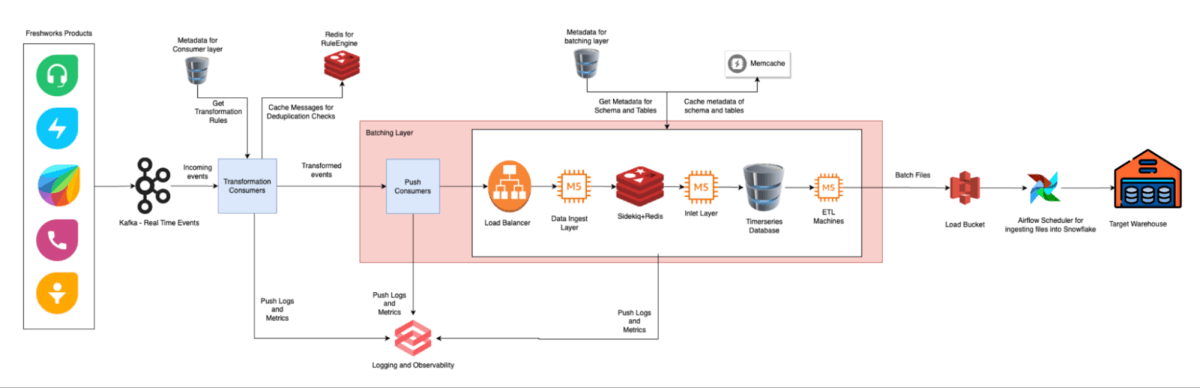
Crescimento rápido expôs desafios centrais:
- Escalabilidade: O pipeline teve dificuldades para lidar com milhões de mensagens por minuto, especialmente durante picos, e demandou escalonamento manual frequente.
- Complexidade Operacional: O fluxo em várias etapas tornou as alterações e a manutenção do esquema arriscadas e demoradas, resultando frequentemente em incompatibilidades e falhas.
- Ineficiência de Custo: As despesas de armazenamento e computação cresceram rapidamente, impulsionadas por processamento redundante e falta de otimização.
- Responsividade: A configuração legada não conseguia atender às demandas de ingestão em tempo real ou análises rápidas e confiáveis à medida que a Freshworks aumentava. Atrasos prolongados na ingestão prejudicaram a atualização dos dados e impactaram as percepções do cliente.
À medida que a escala e a complexidade aumentavam, a fragilidade e a sobrecarga do antigo sistema tornaram clara a necessidade de uma arquitetura de dados unificada, escalável e autônoma para apoiar o crescimento dos negócios e as necessidades de análise.
Nova Arquitetura: Processamento de Dados em Tempo Real com Apache Spark e Delta Lake
A solução - Um redesenho fundamental centrado em Spark Structured Streaming e Delta Lake, construído especificamente para processamento quase em tempo real, transformações escaláveis e simplicidade operacional.
Nós projetamos uma arquitetura única e simplificada onde o Spark Structured Streaming consome diretamente do Kafka, transforma dados e os escreve no Delta Lake - tudo em um único trabalho, funcionando inteiramente dentro do Databricks.
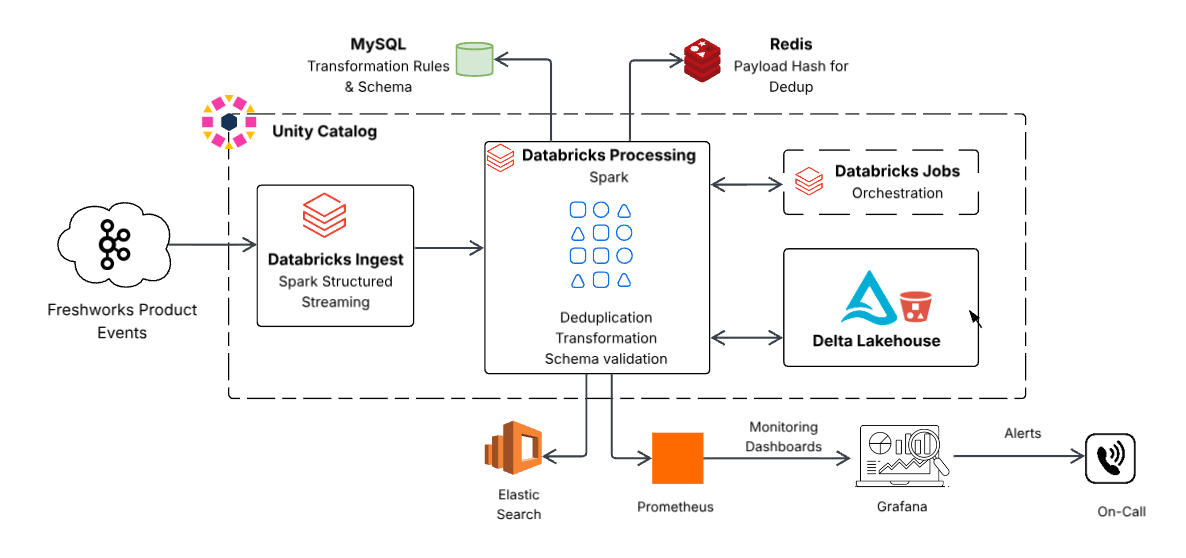
Esta mudança reduziu o movimento de dados, simplificou a manutenção e a resolução de problemas, e acelerou o tempo para obter informações.
Os principais componentes da nova arquitetura:
O Componente de Streaming: Spark Structured Streaming
Cada evento recebido do Kafka passa por uma série cuidadosamente orquestrada de etapas de transformação no Spark streaming; otimizado para precisão, escala e eficiência de custos:
- Desduplicação eficiente:
Eventos, identificados por UUIDs, são conferidos contra uma tabela Delta de UUIDs processados anteriormente para filtrar duplicatas entre lotes de transmissão. - Validação de Dados:
O esquema e as regras de negócios filtram registros com formato incorreto, garantem campos obrigatórios, e lidam com valores nulos. - Transformações Personalizadas com JSON-e:
O motor JSON-e permite uma lógica avançada e reutilizável - como condicionais, loops e UDFs Python - possibilitando que as equipes de produto definam uma lógica dinâmica e reutilizável adaptada a cada produto. - Transformação para Formulário Tabular:
Eventos JSON transformados são achatados em milhares de tabelas estruturadas. Uma ferramenta interna de gerenciamento de esquema separada (gerenciando mais de 20.000 tabelas e mais de 5 milhões de colunas) permite que as equipes de produto gerenciem alterações de esquema e as promovam automaticamente para produção, que é registrada no Delta Lake e captada pelo Spark streaming sem problemas. - Deduplicação de Dados Achatados:
Um hash das colunas armazenadas é comparado com as últimas 4 horas de dados processados no Redis, prevenindo a ingestão de duplicatas e reduzindo os custos computacionais.
O Componente de Armazenamento: Lakehouse
Uma vez transformados, os dados são escritos diretamente nas tabelas Delta Lake usando várias otimizações poderosas:
- Escritas em Paralelo com Multitarefa:
Um único trabalho do Spark geralmente escreve em ~250 tabelas Delta, aplicando lógica de transformação variável. Isso é executado usando a multitarefa do Python, que realiza fusões Delta em paralelo, maximizando a utilização do cluster e reduzindo a latência. - Atualizações eficientes com vetores de exclusão:
Até 35% dos registros por lote são atualizações ou exclusões. Em vez de reescrever grandes arquivos, aproveitamos os vetores de exclusão para permitir exclusões suaves. Isso melhora o desempenho da atualização em 3x, tornando as atualizações em tempo real práticas, mesmo em uma escala de terabyte. - Fusões aceleradas com Cache de Disco:
O Cache de Disco garante que os dados frequentemente acessados (hot) permaneçam em memória. Ao armazenar apenas as colunas necessárias para as fusões, conseguimos operações de fusão até 4x mais rápidas, reduzindo os custos de E/S e computação. Hoje, 95% das leituras de mesclagem são atendidas diretamente do cache.
Dimensionamento Automático e Adaptação em Tempo Real
O auto dimensionamento (Autoscaling) está incorporado no pipeline para garantir que o sistema se dimensiona para cima ou para baixo dinamicamente para lidar com o volume e custo de forma mais eficiente sem impactar o desempenho.
O autoescalonamento é guiado pelo atraso do lote e pelo tempo de execução, monitorados em tempo real. O redimensionamento é acionado através de APIs de trabalho no QueryListener do Spark (método OnProgress depois de cada lote), garantindo que o processamento em andamento não seja interrompido. Desta forma, o sistema é responsivo, resiliente e eficiente sem intervenção manual.
Resiliência Integrada: Lidando com Falhas de Forma Elegante
Para manter a integridade e disponibilidade dos dados, a arquitetura inclui uma forte tolerância a falhas:
- Eventos que falham na transformação são tentados novamente pelo Kafka com lógica de retrocesso.
- Registros permanentemente falhados são armazenados em uma tabela Delta para revisão offline e reprocessamento, garantindo que nenhum dado seja perdido.
- Este design garante a integridade dos dados sem intervenção humana, mesmo durante picos de carga ou mudanças de esquema e a capacidade de republicar os dados falhados posteriormente.
Observabilidade e Monitoramento em Cada Etapa
Uma poderosa pilha de monitoramento—construída com Prometheus, Grafana e Elasticsearch—integrada com Databricks nos proporciona visibilidade de ponta a ponta:
- Coleta de métricas:
Cada lote em Databricks registra métricas-chave - como contagem de registros de entrada, registros transformados e taxas de erro, que são integradas ao Prometheus, com alertas em tempo real para a equipe de suporte. - Rastreamento de Eventos:
Os status dos eventos são registrados no Elasticsearch, permitindo um depuração detalhada que permite que as equipes de produto (produtores) e análise (consumidores) rastreiem problemas.
Métricas de Execução e Transformação em Lotes:
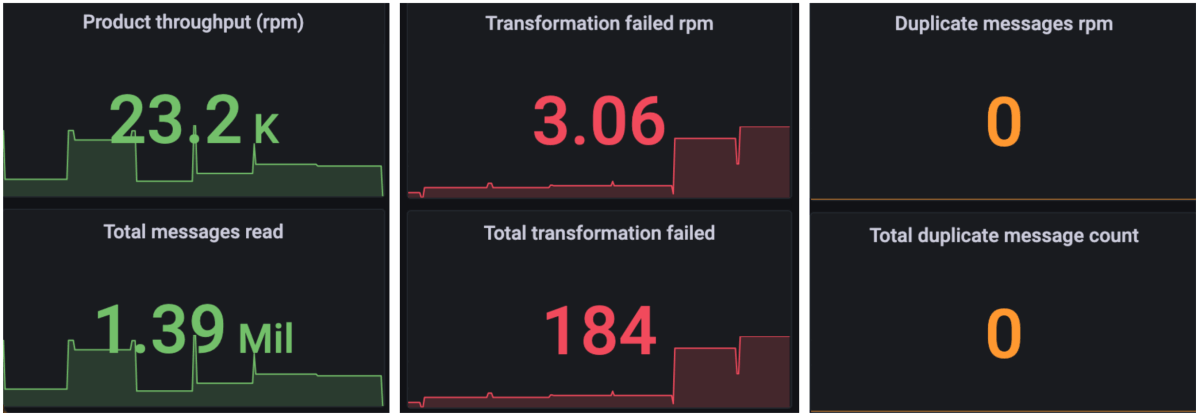


Acompanhe a saúde da transformação usando as métricas acima para identificar problemas e acionar alertas para investigações rápidas
Da Complexidade à Confiança
Talvez a mudança mais transformadora tenha sido na simplicidade.
O que antes envolvia cinco sistemas e inúmeros pontos de integração agora é uma única pipeline escalável e observável rodando inteiramente dentro do Databricks. Eliminamos dependências frágeis, simplificamos operações e permitimos que as equipes trabalhassem mais rápido e com maior autonomia. Efetivamente, menos peças móveis significaram menos surpresas e mais confiança.
Ao reinventar a pilha de dados em torno do streaming e do Deltalake, construímos um sistema que não apenas atende à escala atual, mas está pronto para o crescimento de amanhã.
Por que escolher Databricks?
À medida que reimaginei a arquitetura de dados, avaliamos várias tecnologias, incluindo Amazon EMR com Spark, Apache Flink e Databricks. Após rigorosos testes comparativos, Databricks se destacou como a escolha clara, oferecendo uma combinação única de performance, simplicidade e alinhamento com o ecossistema que atendeu às necessidades em evolução da Freshworks.
Um Ecossistema Unificado para Processamento de Dados
Em vez de juntar várias ferramentas, Databricks oferece uma plataforma de ponta a ponta que abrange orquestração de tarefas, governança de dados, e integração CI/CD, reduzindo a complexidade e acelerando o desenvolvimento.
- Catálogo Unity atua como a única fonte de verdade para a governança de dados. Com controle de acesso granular, rastreamento de linhagem e gerenciamento centralizado de esquema, garante
- nossa equipe é capaz de garantir que todos os ativos de dados estejam bem organizados, fornecendo acesso aos dados para cada inquilino, preservando limites estritos de acesso,
- Esteja em conformidade com as necessidades regulatórias, com todos os eventos e ações sendo auditados nas tabelas de auditoria, junto com informações sobre quem tem acesso a quais ativos, e
- Trabalhos Databricks tem orquestração inerente e substituíram a dependência de orquestradores externos, como Airflow. O agendamento nativo e a execução da pipeline reduziram o atrito operacional e melhoraram a confiabilidade.
- CI/CD e REST APIs ajudaram as equipes da Freshworks a automatizar tudo - da criação de trabalhos, dimensionamento de cluster a atualizações de esquema. Esta automação acelerou os lançamentos, melhorou a consistência e minimizou os erros manuais, permitindo-nos experimentar rápido e aprender rápido.
Plataforma Spark Otimizada
- Recursos chave como alocação automatizada de recursos, arquitetura unificada de batch e streaming, recuperação de falhas do executor e escalonamento dinâmico para processar milhões de registros nos permitiu manter um fluxo consistente, mesmo durante picos de tráfego ou problemas de infraestrutura.
Cache de Alto Desempenho
- O Cache de disco Databricks provou ser o fator chave para atender à latência de dados necessária, uma vez que a maioria das mesclagens eram atendidas pelos dados quentes armazenados no cache do disco.
- Sua capacidade de detectar automaticamente alterações nos arquivos de dados subjacentes e manter o cache atualizado garantiu que os intervalos de processamento em lote atendessem consistentemente ao SLA exigido.
Delta Lake: Base para Ingestão em Tempo Real e Confiável
A Delta Lake desempenha um papel crítico na pipeline, habilitando processamento de dados de baixa latência, compatível com ACID, e de alta integridade em grande escala.
| Recurso Delta Lake | Vantagem da Pipeline SaaS |
|---|---|
| Transações ACID | A Freshworks escreve streaming de alta frequência a partir de múltiplas fontes e gravações simultâneas nos dados. A conformidade ACID do Delta Lake garante a consistência dos dados em todas as leituras e escrituras. |
| Evolução do Esquema | Devido ao crescimento rápido e natureza inerente dos produtos, o esquema de vários produtos continua evoluindo e a evolução do esquema do Delta Lake se adapta às mudanças de requisitos, onde são aplicadas de maneira transparente às tabelas delta & são automaticamente capturadas por aplicações de streaming do spark. |
| Viagem no Tempo | Com milhões de transações e necessidades de auditoria, a capacidade de voltar a um snapshot de dados no Delta Lake suporta necessidades de auditoria e retorno ao ponto no tempo. |
| Manuseio de Mudanças Escaláveis & Vetores de Deleção | O Delta Lake suporta & permite operações eficientes de inserção/atualização/exclusão através de logs de transação sem a necessidade de reescrever grandes arquivos de dados. Isso se provou crucial para reduzir as latências de ingestão de várias horas para poucos minutos em nossos pipelines. |
| Formato aberto | Como a Freshworks é um sistema SAAS multilocatário, o formato Delta aberto oferece ampla compatibilidade com ferramentas analíticas em cima do Lakehouse; apoiando operações de leitura multilocatárias. |
Então, combinando velocidade do Databricks Spark, confiabilidade do Delta Lake, e plataforma integrada do Databricks, nós construímos uma base escalável, robusta, e de custo efetivo pronta para os análises de dados em tempo real do Freshworks.
O que aprendemos: Principais insights
Nenhuma transformação está livre de seus desafios. No caminho, encontramos algumas surpresas que nos ensinaram lições valiosas:
1. Sobrecarga do Armazenamento do Estado: Alto Uso de Memória e Problemas de Estabilidade.
O uso do dropDuplicatesWithinWatermark do Spark causou alto uso de memória e instabilidade, especialmente durante a expansão automática, e levou ao aumento dos custos de listagem do S3 devido a muitos arquivos pequenos.
Solução: Mudar para cache baseado em Delta para desduplicação melhorou drasticamente a eficiência e a estabilidade da memória. O custo total da lista S3 e a pegada de memória foram drasticamente reduzidos, ajudando a diminuir o tempo e o custo da desduplicação de dados.
2. Agrupamento Líquido: Desafios Comuns
O agrupamento em várias colunas resultou em distribuição esparsa de dados e aumentou as varreduras de dados, reduzindo o desempenho da consulta.
As consultas tinham um predicado primário com vários predicados secundários; o agrupamento em várias colunas levou a uma distribuição esparsa de dados na coluna do predicado primário.
Correção: Agrupar em uma única coluna primária levou a uma melhor organização de arquivos e consultas significativamente mais rápidas ao otimizar as leituras de dados.
3. Problemas de Limpeza Automática de Memória (GC): Reinícios de Jobs Necessários
Trabalhos de longa duração (7+ dias) começaram a apresentar lentidão no desempenho e ciclos de coleta de lixo mais frequentes.
Solução: Tivemos que introduzir reinícios de trabalho semanais para mitigar longos ciclos de GC e a degradação do desempenho.
4. Desequilíbrio de Dados: Lidar com o desequilíbrio dos tópicos Kafka
Observou-se skew de dados, pois diferentes tópicos Kafka tinham volumes de dados proporcionalmente variados. Isso levou à distribuição irregular de dados entre os nós de processamento, causando cargas de trabalho de tarefas distorcidas e utilização de recursos não uniforme.
Correção: A repartição antes das transformações garantiu uma distribuição de dados uniforme e equilibrada, equilibrando a carga de processamento de dados e melhorando a taxa de transferência.
5. Mesclagem condicional: Otimizando o desempenho da mesclagem
Mesmo se apenas algumas colunas fossem necessárias, as operações de mesclagem estavam carregando todas as colunas da tabela de destino, o que levava a tempos de mesclagem elevados e custos de I/O.
Solução: Implementamos uma anti-junção antes da fusão e descartado precocemente de registros que chegam tarde ou irrelevantes, acelerando significativamente as fusões por prevenir que dados desnecessários sejam carregados.
Conclusão
Ao usar Databricks e Delta Lake, a Freshworks redefine sua arquitetura de dados - passando de fluxos de trabalho fragmentados e manuais para uma plataforma unificada, moderna e em tempo real.
O impacto?
- Melhoria de 4x no tempo de sincronização de dados durante picos de tráfego
- Economia de custos de ~25% devido a operações escaláveis e eficientes em termos de custos com zero inatividade.
- Redução de 50% no esforço de manutenção
- Alta disponibilidade e desempenho compatível com SLA - mesmo durante picos de carga
- Melhoria da experiência do cliente por meio de insights em tempo real
Esta transformação permite que cada cliente da Freshworks - de TI ao Suporte - tome decisões mais rápidas, baseadas em dados, sem se preocupar com o volume de dados que suportam suas necessidades de negócios sendo servidos e processados.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.