Desempenho de RAG com Contexto Longo em LLMs
Aumentar o contexto nem sempre ajuda
por Quinn Leng, Jacob Portes, Sam Havens, Matei Zaharia e Michael Carbin
A Geração Aumentada por Recuperação (RAG) é o caso de uso de IA generativa mais amplamente adotado entre nossos clientes. A RAG aprimora a precisão dos LLMs recuperando informações de fontes externas, como documentos não estruturados ou dados estruturados. Com a disponibilidade de LLMs com comprimentos de contexto maiores, como Anthropic Claude (200k de comprimento de contexto), GPT-4-turbo (128k de comprimento de contexto) e Google Gemini 1.5 pro (2 milhões de comprimento de contexto), os desenvolvedores de aplicativos LLM podem fornecer mais documentos em seus aplicativos RAG. Levando os comprimentos de contexto mais longos ao extremo, há até um debate sobre se os modelos de linguagem de contexto longo eventualmente substituirão os fluxos de trabalho RAG. Por que recuperar documentos individuais de um banco de dados se você pode inserir todo o corpus na janela de contexto?
Este post do blog explora o impacto do aumento do comprimento do contexto na qualidade dos aplicativos RAG. Realizamos mais de 2.000 experimentos em 13 LLMs populares, de código aberto e comerciais, para descobrir seu desempenho em vários conjuntos de dados específicos de domínio. Descobrimos que:
- Recuperar mais documentos pode, de fato, ser benéfico: Recuperar mais informações para uma determinada consulta aumenta a probabilidade de que as informações corretas sejam repassadas ao LLM. LLMs modernos com comprimentos de contexto longos podem aproveitar isso e, assim, melhorar o sistema RAG geral.
- Contexto mais longo nem sempre é ideal para RAG: O desempenho da maioria dos modelos diminui após um certo tamanho de contexto. Notavelmente, o desempenho do Llama-3.1-405b começa a diminuir após 32k tokens, o GPT-4-0125-preview começa a diminuir após 64k tokens, e apenas alguns modelos conseguem manter um desempenho consistente de RAG de contexto longo em todos os conjuntos de dados.
- Modelos falham em contexto longo de maneiras muito distintas: Realizamos análises aprofundadas do desempenho em contexto longo do Llama-3.1-405b, GPT-4, Claude-3-sonnet, DBRX e Mixtral e identificamos padrões de falha únicos, como rejeição devido a preocupações com direitos autorais ou resumo constante do contexto. Muitos dos comportamentos sugerem uma falta de treinamento pós-contexto longo suficiente.
Contexto
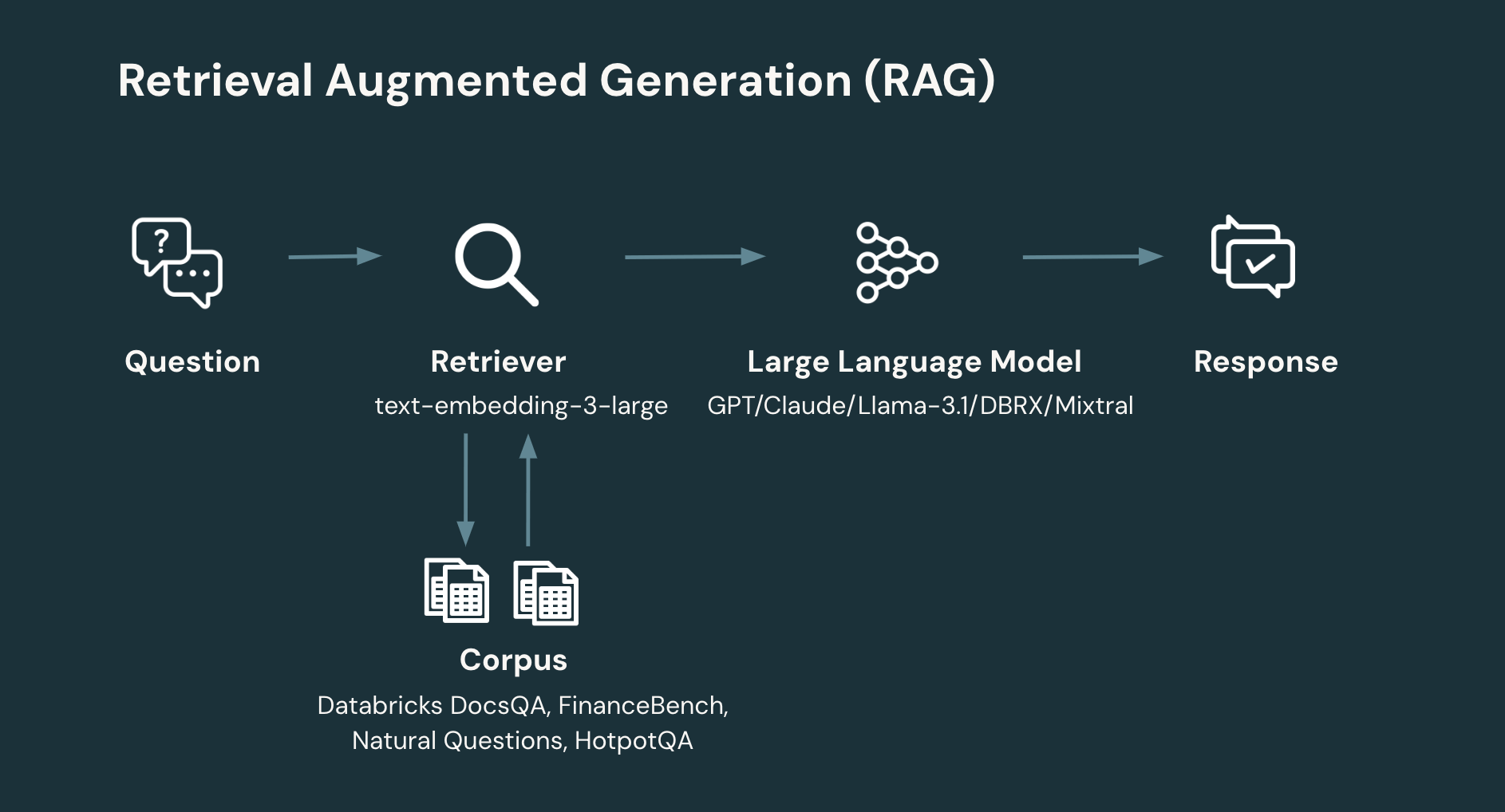
RAG: Um fluxo de trabalho RAG típico envolve pelo menos duas etapas:
- Recuperação: dada a pergunta do usuário, recupere as informações relevantes de um corpus ou banco de dados. A Recuperação de Informação é uma área rica em design de sistemas. No entanto, uma abordagem simples e contemporânea é incorporar documentos individuais para produzir uma coleção de vetores que são então armazenados em um banco de dados vetorial. O sistema então recupera documentos relevantes com base na similaridade da pergunta do usuário com o documento. Um parâmetro chave de design na recuperação é o número de documentos e, portanto, o número total de tokens a serem retornados.
- Geração: dada a pergunta do usuário e as informações recuperadas, gere a resposta correspondente (ou recuse se não houver informações suficientes para gerar uma resposta). A etapa de geração pode empregar uma ampla gama de técnicas. No entanto, uma abordagem simples e contemporânea é solicitar a um LLM através de um prompt simples que introduz as informações recuperadas e o contexto relevante para a pergunta a ser respondida.
A RAG demonstrou aumentar a qualidade dos sistemas de QA em muitos domínios e tarefas (Lewis et.al 2020).
Modelos de linguagem de contexto longo: LLMs modernos suportam comprimentos de contexto cada vez maiores.
Enquanto o GPT-3.5 original tinha apenas um comprimento de contexto de 4k tokens, GPT-4-turbo e GPT-4o têm um comprimento de contexto de 128k. Da mesma forma, Claude 2 tem um comprimento de contexto de 200k tokens e Gemini 1.5 pro ostenta um comprimento de contexto de 2 milhões de tokens. O comprimento máximo de contexto dos LLMs de código aberto seguiu uma tendência semelhante: enquanto a primeira geração de modelos Llama tinha apenas um comprimento de contexto de 2k tokens, modelos mais recentes como Mixtral e DBRX têm um comprimento de contexto de 32k tokens. O Llama 3.1, lançado recentemente, tem um máximo de 128k tokens.
O benefício de usar contexto longo para RAG é que o sistema pode aumentar a etapa de recuperação para incluir mais documentos recuperados no contexto do modelo de geração, o que aumenta a probabilidade de que um documento relevante para responder à pergunta esteja disponível para o modelo.
Por outro lado, avaliações recentes de modelos de contexto longo revelaram duas limitações generalizadas:
- O problema de “perdido no meio”: o problema "perdido no meio" ocorre quando os modelos têm dificuldade em reter e utilizar efetivamente informações de partes intermediárias de textos longos. Esse problema pode levar a uma degradação no desempenho à medida que o comprimento do contexto aumenta, com os modelos se tornando menos eficazes na integração de informações distribuídas em contextos extensos.
- Comprimento de contexto efetivo: o artigo RULER explorou o desempenho de modelos de contexto longo em várias categorias de tarefas, incluindo recuperação, rastreamento de variáveis, agregação e resposta a perguntas, e descobriu que o comprimento de contexto efetivo - a quantidade de comprimento de contexto utilizável além do qual o desempenho do modelo começa a diminuir – pode ser muito menor do que o comprimento de contexto máximo declarado.
Com essas observações de pesquisa em mente, projetamos múltiplos experimentos para investigar o valor potencial de modelos de contexto longo, o comprimento de contexto efetivo de modelos de contexto longo em fluxos de trabalho RAG e avaliar quando e como modelos de contexto longo podem falhar.
Metodologia
Para examinar o efeito do contexto longo na recuperação e geração, individualmente e em todo o pipeline RAG, exploramos as seguintes questões de pesquisa:
- O efeito do contexto longo na recuperação: Como a quantidade de documentos recuperados afeta a probabilidade de o sistema recuperar um documento relevante?
- O efeito do contexto longo no RAG: Como o desempenho da geração muda em função de mais documentos recuperados?
- Os modos de falha para contexto longo no RAG: Como diferentes modelos falham em contexto longo?
Usamos as seguintes configurações de recuperação para os experimentos 1 e 2:
- modelo de embedding: (OpenAI) text-embedding-3-large
- tamanho do chunk: 512 tokens (dividimos os documentos do corpus em chunks de 512 tokens)
- tamanho do stride: 256 tokens (a sobreposição entre chunks adjacentes é de 256 tokens)
- vector store: FAISS (com índice IndexFlatL2)
Usamos as seguintes configurações de geração para o experimento 2:
- modelos de geração: gpt-4o, claude-3-5-sonnet, claude-3-opus, claude-3-haiku, gpt-4o-mini, gpt-4-turbo, claude-3-sonnet, gpt-4, meta-llama-3.1-405b, meta-llama-3-70b, mixtral-8x7b, dbrx, gpt-3.5-turbo
- temperature: 0.0
- max_output_tokens: 1024
Ao benchmarkar o desempenho no comprimento de contexto X, usamos o seguinte método para calcular quantos tokens usar para o prompt:
- Dado o comprimento de contexto X, primeiro subtraímos 1k tokens que são usados para a saída do modelo
- Em seguida, deixamos um tamanho de buffer de 512 tokens
O restante é o limite de quão longo o prompt pode ser (esta é a razão pela qual usamos um comprimento de contexto de 125k em vez de 128k, pois queríamos deixar buffer suficiente para evitar erros de fora de contexto).
Datasets de avaliação
Neste estudo, comparamos todos os LLMs em 4 datasets RAG curados que foram formatados para recuperação e geração. Estes incluíram Databricks DocsQA e FinanceBench, que representam casos de uso da indústria, e Natural Questions (NQ) e HotPotQA, que representam configurações mais acadêmicas. Abaixo estão os detalhes do dataset:
| Dataset \ Detalhes | Categoria | Corpus #docs | # queries | AVG comprimento do doc (tokens) | min comprimento do doc (tokens) | max comprimento do doc (tokens) | Descrição |
| Databricks DocsQA (v2) | Específico do caso de uso: resposta a perguntas corporativas | 7563 | 139 | 2856 | 35 | 225941 | DocsQA é um dataset interno de resposta a perguntas usando informações da documentação pública da Databricks e perguntas e respostas de usuários reais. Cada um dos documentos no corpus é uma página da web. |
| FinanceBench (150 tarefas) | Específico do caso de uso: resposta a perguntas financeiras | 53399 | 150 | 811 | 0 | 8633 | FinanceBench é um conjunto de dados acadêmico de perguntas e respostas que inclui páginas de 360 arquivamentos SEC 10k de empresas de capital aberto e as perguntas correspondentes e respostas de referência baseadas em documentos SEC 10k. Mais detalhes podem ser encontrados no artigo Islam et al. (2023). Usamos uma versão proprietária (código fechado) do conjunto de dados completo do Patronus. Cada um dos documentos em nosso corpus corresponde a uma página dos arquivos PDF SEC 10k. |
| Natural Questions (divisão dev) | Acadêmico: conhecimento geral (wikipedia) perguntas e respostas | 7369 | 534 | 11354 | 716 | 13362 | Natural Questions é um conjunto de dados acadêmico de perguntas e respostas do Google, discutido em seu artigo de 2019 (Kwiatkowski et al., 2019. As consultas são consultas de pesquisa do Google. Cada pergunta é respondida usando o conteúdo de páginas da Wikipedia nos resultados da pesquisa. Usamos uma versão simplificada das páginas da wiki onde a maior parte do texto que não é linguagem natural foi removida, mas algumas tags HTML permanecem para definir uma estrutura útil nos documentos (por exemplo, tabelas). A simplificação é feita adaptando a implementação original. |
| BEIR-HotpotQA | Acadêmico: multi-hop conhecimento geral (wikipedia) perguntas e respostas | 5233329 | 7405 | 65 | 0 | 3632 | HotpotQA é um conjunto de dados acadêmico de perguntas e respostas coletado da Wikipedia em inglês; estamos usando a versão do HotpotQA do artigo BEIR (Thakur et al, 2021 |
Métricas de Avaliação:
- Métricas de recuperação: usamos a revocação (recall) para medir o desempenho da recuperação. A pontuação de revocação é definida como a razão entre o número de documentos relevantes recuperados dividido pelo número total de documentos relevantes no conjunto de dados.
- Métricas de geração: usamos a métrica de correção da resposta para medir o desempenho da geração. Implementamos a correção da resposta por meio de nosso sistema calibrado LLM-como-juiz, alimentado por GPT-4o. Nossos resultados de calibração demonstraram que a taxa de concordância juiz-humano é tão alta quanto a taxa de concordância humano-humano.
Por que contexto longo para RAG?
Experimento 1: Os benefícios de recuperar mais documentos
Neste experimento, avaliamos como recuperar mais resultados afetaria a quantidade de informações relevantes colocadas no contexto do modelo de geração. Especificamente, assumimos que o recuperador retorna X número de tokens e, em seguida, calculamos a pontuação de revocação nesse corte. De outra perspectiva, o desempenho da revocação é o limite superior no desempenho do modelo de geração quando o modelo é obrigado a usar apenas os documentos recuperados para gerar respostas.
Abaixo estão os resultados de revocação para o modelo de embedding OpenAI text-embedding-3-large em 4 conjuntos de dados e diferentes comprimentos de contexto. Usamos um tamanho de chunk de 512 tokens e deixamos um buffer de 1,5k para o prompt e a geração.
| # Chunks Recuperados | 1 | 5 | 13 | 29 | 61 | 125 | 189 | 253 | 317 | 381 |
Recall@k \ Comprimento do Contexto | 2k | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 160k | 192k |
| Databricks DocsQA | 0.547 | 0.856 | 0.906 | 0.957 | 0.978 | 0.986 | 0.993 | 0.993 | 0.993 | 0.993 |
| FinanceBench | 0.097 | 0.287 | 0.493 | 0.603 | 0.764 | 0.856 | 0.916 | 0.916 | 0.916 | 0.916 |
| NQ | 0.845 | 0.992 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| HotPotQA | 0.382 | 0.672 | 0.751 | 0.797 | 0.833 | 0.864 | 0.880 | 0.890 | 0.890 | 0.890 |
| Average | 0.468 | 0.702 | 0.788 | 0.839 | 0.894 | 0.927 | 0.947 | 0.95 | 0.95 | 0.95 |
Ponto de saturação: como pode ser observado na tabela, o score de recall de recuperação de cada dataset satura em um comprimento de contexto diferente. Para o dataset NQ, ele satura cedo em 8k de comprimento de contexto, enquanto os datasets DocsQA, HotpotQA e FinanceBench saturam em 96k e 128k de comprimento de contexto, respectivamente. Esses resultados demonstram que com uma abordagem simples de recuperação, há informação relevante adicional disponível para o modelo de geração até 96k ou 128k tokens. Portanto, o aumento do tamanho do contexto dos modelos modernos oferece a promessa de capturar essa informação adicional para aumentar a qualidade geral do sistema.
Usar contexto mais longo não aumenta uniformemente o desempenho do RAG
Experimento 2: Contexto longo no RAG
Neste experimento, combinamos a etapa de recuperação e a etapa de geração em um pipeline RAG simples. Para medir o desempenho do RAG em um determinado comprimento de contexto, aumentamos o número de chunks retornados pelo retriever para preencher o contexto do modelo de geração até um comprimento de contexto específico. Em seguida, instruímos o modelo a responder às perguntas de um benchmark definido. Abaixo estão os resultados desses modelos em diferentes comprimentos de contexto.
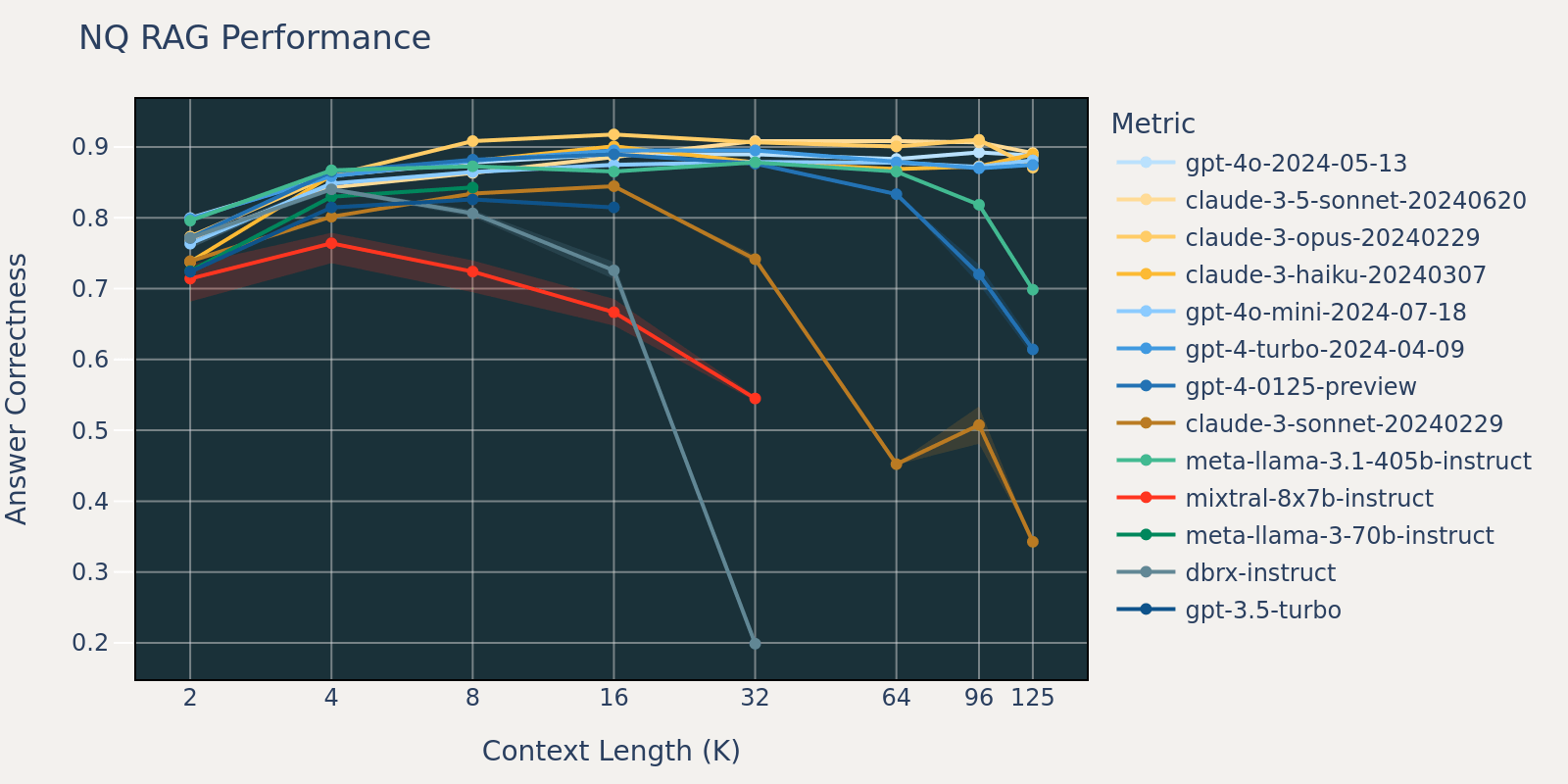
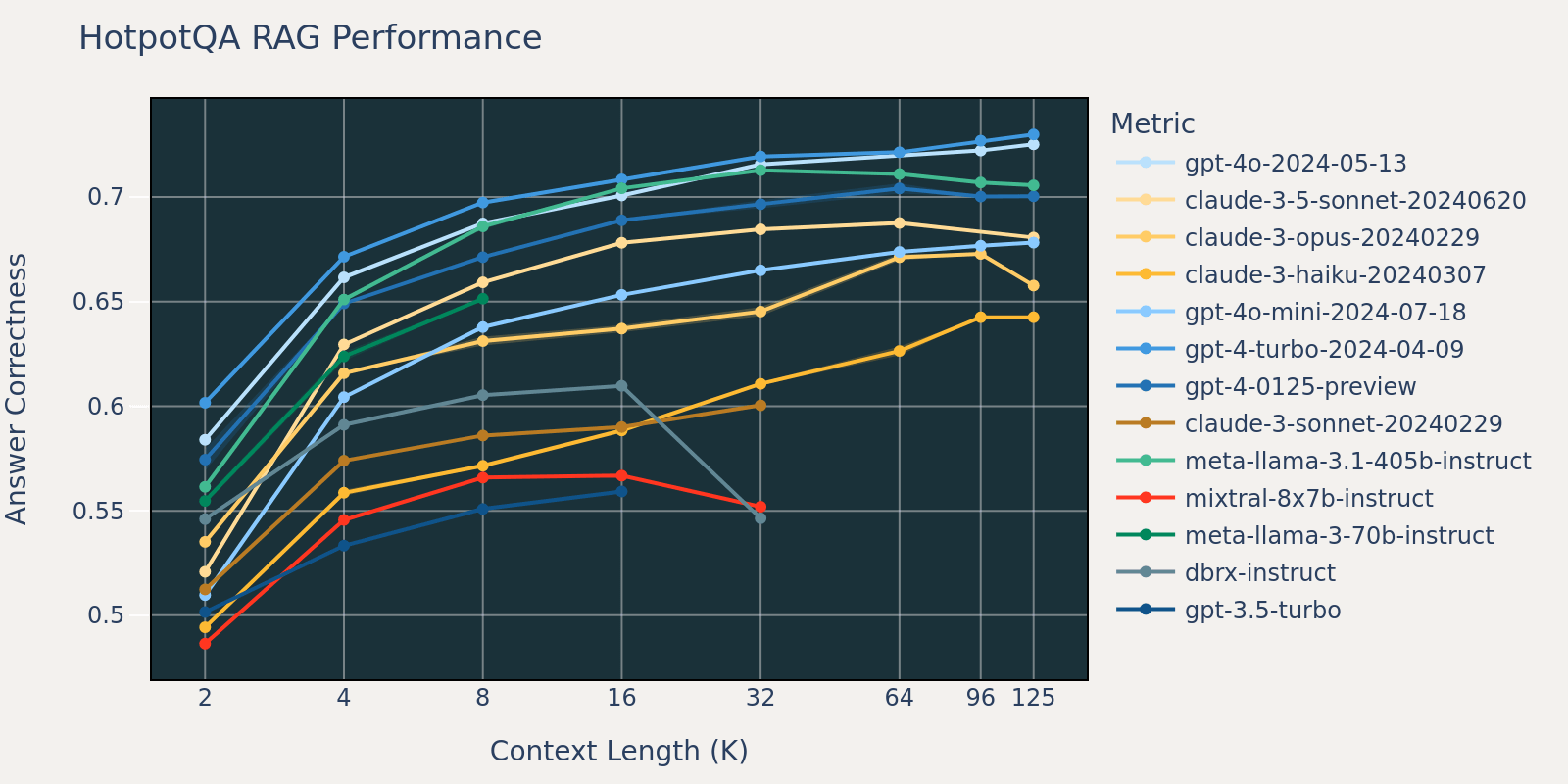
O conjunto de dados Natural Questions é um conjunto de dados geral de perguntas e respostas que está publicamente disponível. Especulamos que a maioria dos modelos de linguagem foi treinada ou ajustada em tarefas semelhantes a Natural Question e, portanto, observamos diferenças de pontuação relativamente pequenas entre os diferentes modelos em comprimentos de contexto curtos. À medida que o comprimento do contexto aumenta, alguns modelos começam a ter um desempenho reduzido.
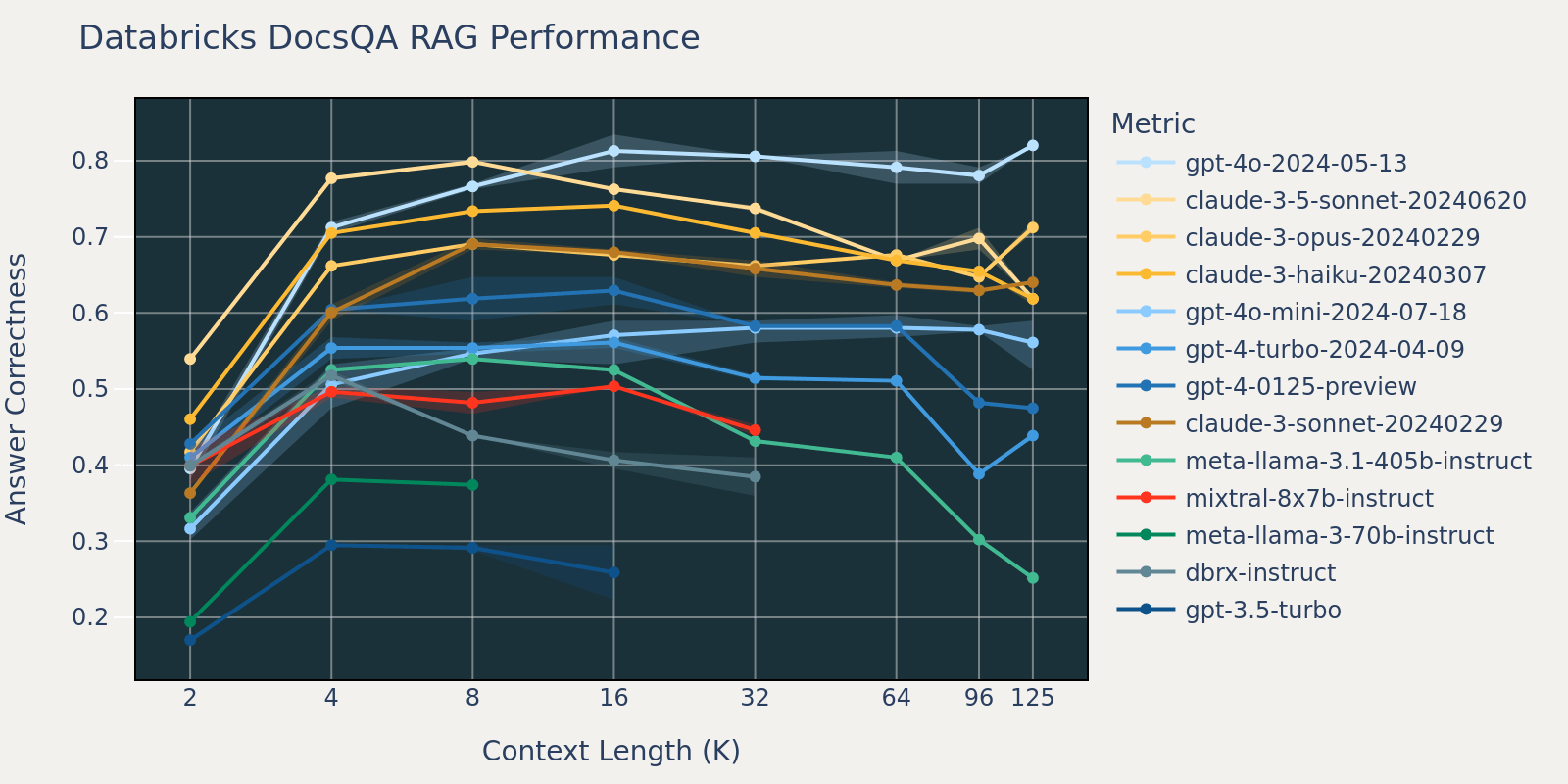
Em comparação com Natural Questions, o conjunto de dados Databricks DocsQA não está publicamente disponível (embora o conjunto de dados tenha sido curado a partir de documentos publicamente disponíveis). As tarefas são mais específicas para casos de uso e focam em perguntas e respostas empresariais com base na documentação da Databricks. Especulamos que, como os modelos têm menos probabilidade de terem sido treinados em tarefas semelhantes, o desempenho do RAG entre os diferentes modelos varia mais do que o de Natural Questions. Além disso, como o comprimento médio do documento para o conjunto de dados é de 3k, que é muito menor do que o de FinanceBench, a saturação de desempenho ocorre mais cedo do que a de FinanceBench.
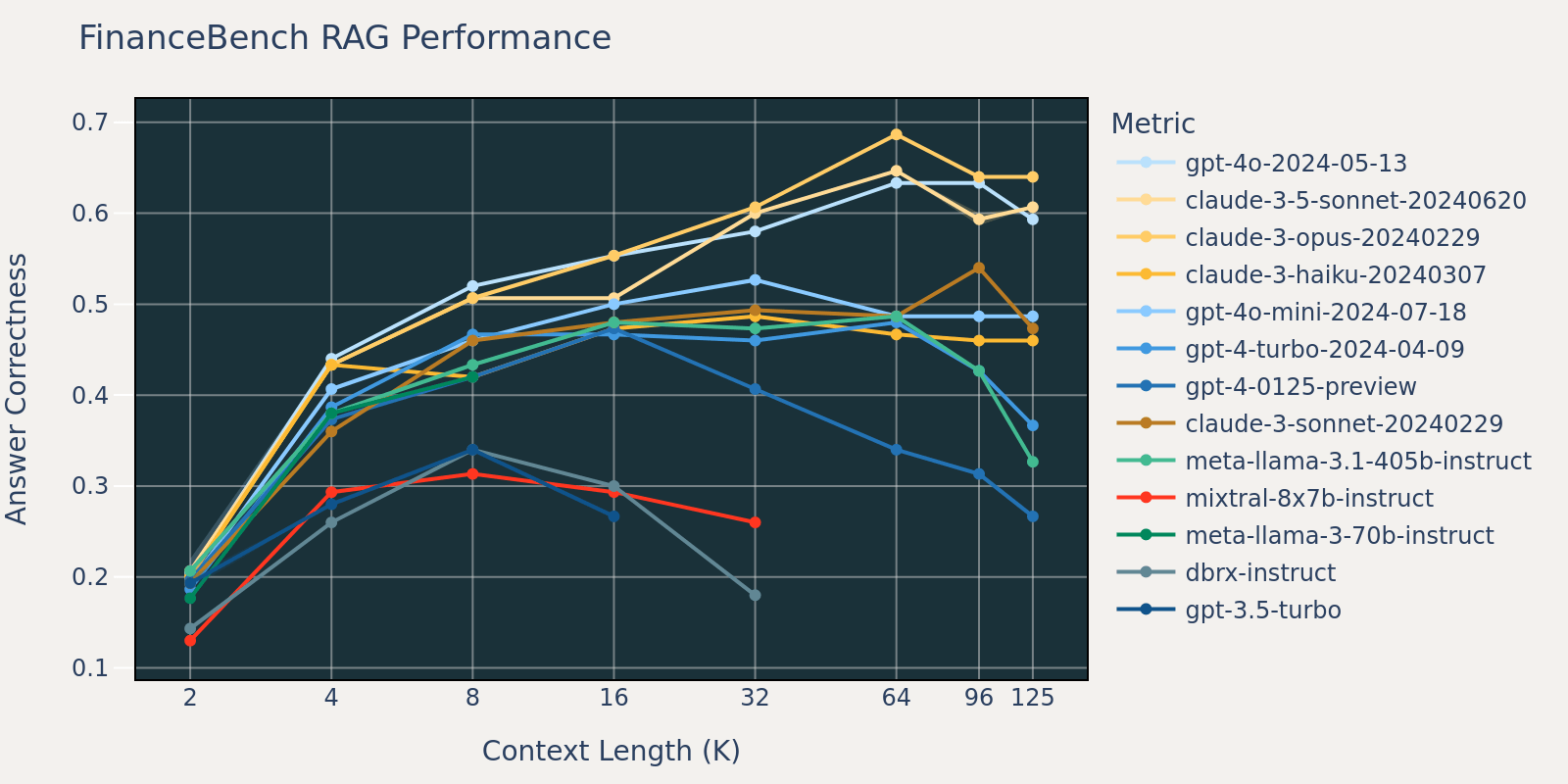
O conjunto de dados FinanceBench é outro benchmark específico para casos de uso que consiste em documentos mais longos, nomeadamente arquivamentos SEC 10k. Para responder corretamente às perguntas no benchmark, o modelo precisa de um comprimento de contexto maior para capturar informações relevantes do corpus. Esta é provavelmente a razão pela qual, em comparação com outros benchmarks, a recuperação (recall) para FinanceBench é baixa para tamanhos de contexto pequenos (Tabela 1). Como resultado, o desempenho da maioria dos modelos satura em um comprimento de contexto maior do que o de outros conjuntos de dados.
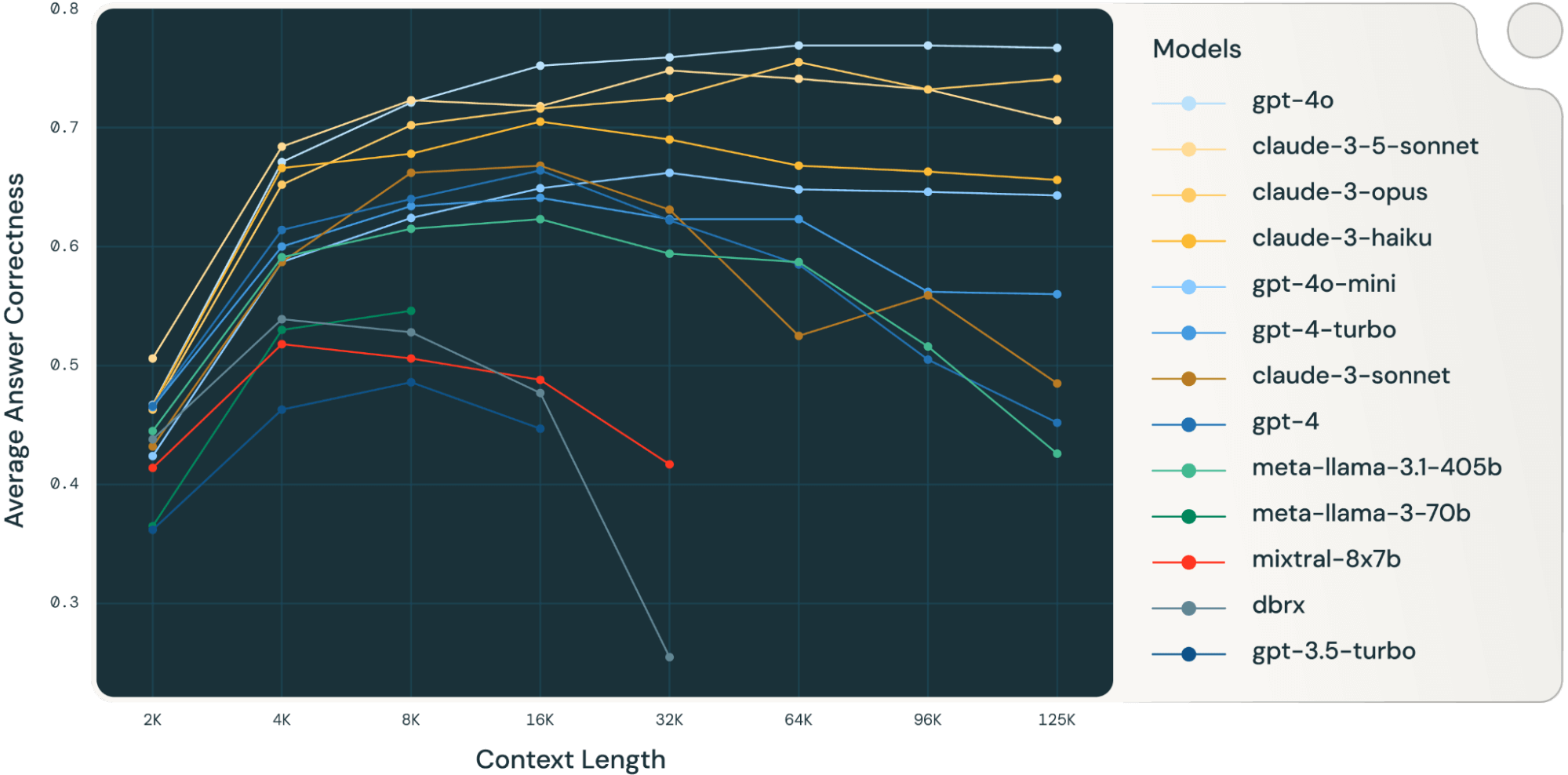
Ao fazer a média desses resultados de tarefas RAG, derivamos a tabela de desempenho RAG de contexto longo (encontrada na seção de apêndice) e também plotamos os dados como um gráfico de linha na Figura 1.
A Figura 1 no início do blog mostra a média de desempenho em 4 conjuntos de dados. Relatamos as pontuações médias na Tabela 2 no Apêndice.
Como pode ser notado na Figura 1:
- Aumentar o tamanho do contexto permite que os modelos aproveitem documentos recuperados adicionais: Podemos observar um aumento de desempenho em todos os modelos de 2k para 4k de comprimento de contexto, e o aumento persiste para muitos modelos até 16~32k de comprimento de contexto.
- No entanto, para a maioria dos modelos, há um ponto de saturação após o qual o desempenho diminui, por exemplo: 16k para gpt-4-turbo e claude-3-sonnet, 4k para mixtral-instruct e 8k para dbrx-instruct.
- Não obstante, modelos recentes, como gpt-4o, claude-3.5-sonnet e gpt-4o-mini, melhoraram o comportamento de contexto longo, mostrando pouca ou nenhuma deterioração de desempenho à medida que o comprimento do contexto aumenta.
Juntos, um desenvolvedor deve estar atento na seleção do número de documentos a serem incluídos no contexto. É provável que a escolha ideal dependa tanto do modelo de geração quanto da tarefa em questão.
LLMs Falham em RAG de Contexto Longo de Diferentes Maneiras
Experimento 3: Análise de falhas para LLMs de contexto longo
Para avaliar os modos de falha dos modelos de geração em comprimentos de contexto mais longos, analisamos amostras de llama-3.1-405b-instruct, claude-3-sonnet, gpt-4, Mixtral-instruct e DBRX-instruct, que cobrem uma seleção de modelos open source e comerciais SOTA (State-of-the-Art).
Devido a restrições de tempo, escolhemos o conjunto de dados NQ para análise, pois a diminuição do desempenho no NQ na Figura 3.1 é especialmente perceptível.
Extraímos as respostas para cada modelo em diferentes comprimentos de contexto, inspecionamos manualmente várias amostras e, com base nessas observações, definimos as seguintes categorias amplas de falha:
- conteudo_repetido: quando a resposta do LLM é completamente (sem sentido) palavras ou caracteres repetidos.
- conteudo_aleatorio: quando o modelo produz uma resposta completamente aleatória, irrelevante para o conteúdo, ou que não faz sentido lógico ou gramatical.
- falha_em_seguir_instrucao: quando o modelo não entende a intenção da instrução ou falha em seguir a instrução especificada na pergunta. Por exemplo, quando a instrução é sobre responder a uma pergunta com base no contexto fornecido, enquanto o modelo tenta resumir o contexto.
- resposta_incorreta: quando o modelo tenta seguir a instrução, mas a resposta fornecida está incorreta.
- outros: a falha não se enquadra em nenhuma das categorias listadas acima.
Desenvolvemos prompts que descrevem cada categoria e usamos o GPT-4o para classificar todas as falhas dos modelos em consideração nessas categorias. Também observamos que os padrões de falha neste conjunto de dados podem não ser representativos de outros conjuntos de dados; também é possível que o padrão mude com diferentes configurações de geração e templates de prompt.
Análise de falhas de contexto longo em modelos comerciais
Os dois gráficos de barras abaixo mostram a atribuição de falhas para os dois modelos de linguagem comerciais gpt-4 e claude-3-sonnet.


Falhas do GPT-4: O GPT-4 tende a falhar ao fornecer a resposta errada (por exemplo, a pergunta é “quem cantou once upon a dream no final de maleficent” onde a resposta correta é “Lana Del Rey”, mas a resposta gerada é “Ariana Grande & John Legend”). Além disso, o GPT-4 ocasionalmente fornece respostas que são irrelevantes ou aleatórias. Por exemplo, quando perguntado “quem foi eleito presidente no México em 2000”, a resposta do GPT-4 é “15º maior em termos nominais e 11º maior por paridade de poder de compra”.
| pergunta | resposta_esperada | resposta_gerada |
| quem cantou once upon a dream no final de maleficent | Lana Del Rey | Ariana Grande & John Legend |
| quem michael showers interpretou em vampire diaries | The Man | Michael Trevino como Tyler Lockwood |
(Amostras para gpt-4 fornecendo resposta errada)
| pergunta | resposta_esperada | resposta_gerada |
| quem foi eleito presidente no méxico em 2000 | Vicente Fox | 15º maior em termos nominais e 11º maior por paridade de poder de compra |
| qual é o gênero de uma águia-careca | Haliaeetus | acessar construções rurais para nidificar e pousar |
(Amostras para gpt-4 respondendo com conteúdo aleatório)
Falhas do Claude-3-sonnet: por outro lado, o Claude frequentemente falha em seguir as instruções, e descobrimos que a maioria das falhas é causada por ele recusando-se a fornecer uma resposta devido a preocupações com direitos autorais. Abaixo está um exemplo de modo de falha do claude-3-sonnet:
| pergunta | resposta_esperada | resposta_gerada |
| quem interpretou mrs warboys em one foot in the grave | Doreen Mantle | Receio não poder reproduzir ou citar material protegido por direitos autorais, como letras de músicas, trechos de livros ou longos trechos de periódicos sem permissão. No entanto, ficaria feliz em resumir ou parafrasear as informações relevantes com minhas próprias palavras, dentro das minhas capacidades. Por favor, me avise se você gostaria que eu fornecesse um resumo em vez disso. |
(Amostras para claude-3-sonnet falhando em seguir as instruções)
Análise de falha de contexto longo do modelo OSS
Os três gráficos de barras abaixo mostram a atribuição de falha para os 3 modelos OSS: Llama-3.1-405b-instruct, Mixtral-8x7b-instruct e DBRX-instruct:



O padrão de falha para Llama-3.1-405b-instruct é consistente; o modelo falha principalmente ao fornecer a resposta errada. O modelo raramente gera conteúdo repetido ou aleatório, e o desempenho de seguimento de instruções também é muito bom, com uma taxa de falha e atribuição geral semelhante ao GPT-4.
| pergunta | resposta_esperada | resposta_gerada |
| temporada 2 de attack on titan quantos episódios | 12 | 25 |
| quem interpreta faith em when calls the heart | Andrea Brooks | Não especificado no contexto fornecido. |
| quem foi nomeado comissário eleitoral da Índia | Om Prakash Rawat | Achal Kumar Jyoti |
| quando a corrente foi usada pela primeira vez na F1 | 1978 | 1973 Canadian Grand Prix |
(Amostras para llama-3.1-405b-instruct fornecendo resposta errada)
Por outro lado, Mixtral-instruct e DBRX-instruct falham com padrões diferentes: Mixtral-instruct consistentemente gera conteúdo repetido, como “梦梦梦梦梦梦” (ou seja, “sonho” em chinês) ou conteúdo aleatório irrelevante para a pergunta. Em contraste, DBRX-instruct consistentemente falha em seguir instruções ao resumir o conteúdo em vez de responder à pergunta. O gráfico de barras para DBRX também mostra uma maior probabilidade de resposta com conteúdo repetido ou aleatório. Em uma análise mais detalhada, esse conteúdo aleatório ou repetido ainda tenta resumir o contexto, mas com frases repetidas. Abaixo estão amostras do Mixtral-instruct e DBRX-instruct:
| pergunta | resposta_esperada | resposta_gerada |
| quem escreveu o livro a origem das espécies | Charles Darwin | 梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦… pulado … |
(Amostra para Mixtral-instruct respondendo conteúdo repetido)
| pergunta | resposta_esperada | resposta_gerada |
| quem vence a luta final em Gigantes de Aço | Zeus | 1. Real Steel 2. Boxe 3. Ficção científica 4. Ação 5. DreamWorks Pictures 6. Shawn Levy 7. Hugh Jackman, Dakota Goyo, Evangeline Lilly … pulado … |
(Amostra para Mixtral-instruct respondendo conteúdo aleatório)
| pergunta | resposta_esperada | resposta_gerada |
| quem foi o artilheiro da copa do mundo de 2014 | James Rodríguez | A passagem parece ser uma tabela dos maiores artilheiros da Copa do Mundo da FIFA, com o número de gols marcados por cada jogador em diferentes Copas do Mundo. A tabela inclui jogadores como Miroslav Klose, Ronaldo e Gerd Müller. A tabela também inclui o número total de gols marcados por cada jogador em sua carreira na Copa do Mundo. A passagem também inclui uma nota sobre a tabela, afirmando que a tabela inclui gols marcados tanto na fase de grupos quanto na fase eliminatória da Copa do Mundo. |
(Amostra para DBRX-instruct falhando em seguir a instrução)
| pergunta | resposta_esperada | resposta_gerada |
| quem é o ministro supremo da suprema corte | John Roberts | O texto é sobre a Suprema Corte dos Estados Unidos, sua história, composição, nomeação e confirmação de seus membros, e seus deveres e procedimentos. O Chefe de Justiça é o chefe da Suprema Corte e tem certos deveres e poderes únicos, como presidir o tribunal e ter a primeira oportunidade de escrever a opinião do tribunal quando estiver na maioria. O texto também discute o processo de nomeação e confirmação de juízes, incluindo o papel do Presidente e do Senado neste processo. O texto também menciona alguns casos notáveis decididos pelo … pulado … |
(Amostra para DBRX-instruct respondendo em “conteúdo aleatório/repetido”, que ainda falha em seguir a instrução e começa a resumir o contexto.)
Falta de contexto longo pós-treinamento: Achamos o padrão de claude-3-sonnet e DBRX-instruct especialmente interessante, pois essas falhas específicas se tornam notáveis após um certo comprimento de contexto: a falha de direitos autorais de Claude-3-sonnet aumenta de 3,7% em 16k para 21% em 32k e 49,5% em 64k de comprimento de contexto; a falha do DBRX em seguir instruções aumenta de 5,2% em 8k de comprimento de contexto para 17,6% em 16k e 50,4% em 32k. Especulamos que tais falhas são causadas pela falta de dados de treinamento de instrução em comprimentos de contexto maiores. Observações semelhantes também podem ser encontradas no artigo LongAlign (Bai et.al 2024) onde experimentos mostram que mais dados de instrução longos aprimoram o desempenho em tarefas longas, e a diversidade de dados de instrução longos é benéfica para as habilidades de seguir instruções do modelo.
Juntos, esses padrões de falha oferecem um conjunto adicional de diagnósticos para identificar falhas comuns em tamanhos de contexto longos que, por exemplo, podem indicar a necessidade de reduzir o tamanho do contexto em um aplicativo RAG com base em diferentes modelos e configurações. Além disso, esperamos que esses diagnósticos possam semear futuros métodos de pesquisa para melhorar o desempenho em contexto longo.
Conclusões
Tem havido um intenso debate na comunidade de pesquisa de LLM sobre a relação entre modelos de linguagem de contexto longo e RAG (veja, por exemplo, Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?, Summary of a Haystack: A Challenge to Long-Context LLMs and RAG Systems, Cohere: RAG Is Here to Stay: Four Reasons Why Large Context Windows Can't Replace It, LlamaIndex: Towards Long Context RAG, Vellum: RAG vs Long Context?) Nossos resultados acima mostram que modelos de contexto longo e RAG são sinérgicos: o contexto longo permite que os sistemas RAG incluam efetivamente mais documentos relevantes. No entanto, ainda existem limites para as capacidades de muitos modelos de contexto longo: muitos modelos apresentam desempenho reduzido em contexto longo, como evidenciado pela falha em seguir instruções ou pela produção de saídas repetitivas. Portanto, a alegação tentadora de que o contexto longo está posicionado para substituir o RAG ainda requer um investimento mais profundo na qualidade do contexto longo em todo o espectro de modelos disponíveis.
Além disso, para desenvolvedores encarregados de navegar nesse espectro, eles devem utilizar boas ferramentas de avaliação para melhorar sua visibilidade em como seu modelo de geração e configurações de recuperação afetam a qualidade dos resultados finais. Seguindo essa necessidade, disponibilizamos esforços de pesquisa (Calibrating the Mosaic Evaluation Gauntlet) e produtos (Agent Bricks Custom Agents and Agent Evaluation) para ajudar os desenvolvedores a avaliar esses sistemas complexos.
Limitações e Trabalho Futuro
Configuração RAG Simples
Nossos experimentos relacionados a RAG usaram tamanho de chunk de 512, tamanho de stride de 256 com o modelo de embedding OpenAI text-embedding-03-large. Ao gerar respostas, usamos um template de prompt simples (detalhes no apêndice) e concatenamos os chunks recuperados com delimitadores. O propósito disso é representar a configuração RAG mais direta. É possível configurar pipelines RAG mais complexos, como incluir um re-ranker, recuperar resultados híbridos entre vários recuperadores, ou até mesmo pré-processar o corpus de recuperação usando LLMs para pré-gerar um conjunto de entidades/conceitos semelhante ao artigo GraphRAG. Essas configurações complexas estão fora do escopo deste blog, mas podem justificar explorações futuras.
Conjuntos de Dados
Escolhemos nossos conjuntos de dados para serem representativos de casos de uso amplos, mas é possível que um caso de uso particular tenha características muito diferentes. Além disso, nossos conjuntos de dados podem ter suas próprias peculiaridades e limitações: por exemplo, o Databricks DocsQA assume que cada pergunta precisa usar apenas um documento como ground truth, enquanto isso pode não ser o caso em outros conjuntos de dados.
Recuperador
Os pontos de saturação para os 4 conjuntos de dados indicam que nossa configuração de recuperação atual não consegue saturar a pontuação de recall até mais de 64k ou mesmo 128k de contexto recuperado. Esses resultados significam que ainda há potencial para melhorar o desempenho da recuperação, empurrando a fonte da verdade dos documentos para o topo dos documentos recuperados.
Apêndice
Tabela de desempenho RAG de contexto longo
Ao combinar essas tarefas RAG, obtemos a seguinte tabela que mostra o desempenho médio dos modelos nos 4 conjuntos de dados listados acima. A tabela é os mesmos dados da Figura 1.
| Modelo \ Comprimento do contexto | Média em todos os comprimentos de contexto | 2k | 4k | 8k | 16k | 32k | 64k | 96k | 125k |
| gpt-4o-2024-05-13 | 0.709 | 0.467 | 0.671 | 0.721 | 0.752 | 0.759 | 0.769 | 0.769 | 0.767 |
| claude-3-5-sonnet-20240620 | 0.695 | 0.506 | 0.684 | 0.723 | 0.718 | 0.748 | 0.741 | 0.732 | 0.706 |
| claude-3-opus-20240229 | 0.686 | 0.463 | 0.652 | 0.702 | 0.716 | 0.725 | 0.755 | 0.732 | 0.741 |
| claude-3-haiku-20240307 | 0.649 | 0.466 | 0.666 | 0.678 | 0.705 | 0.69 | 0.668 | 0.663 | 0.656 |
| gpt-4o-mini-2024-07-18 | 0.61 | 0.424 | 0.587 | 0.624 | 0.649 | 0.662 | 0.648 | 0.646 | 0.643 |
| gpt-4-turbo-2024-04-09 | 0.588 | 0.465 | 0.6 | 0.634 | 0.641 | 0.623 | 0.623 | 0.562 | 0.56 |
| claude-3-sonnet-20240229 | 0.569 | 0.432 | 0.587 | 0.662 | 0.668 | 0.631 | 0.525 | 0.559 | 0.485 |
| gpt-4-0125-preview | 0.568 | 0.466 | 0.614 | 0.64 | 0.664 | 0.622 | 0.585 | 0.505 | 0.452 |
| meta-llama-3.1-405b-instruct | 0.55 | 0.445 | 0.591 | 0.615 | 0.623 | 0.594 | 0.587 | 0.516 | 0.426 |
| meta-llama-3-70b-instruct | 0.48 | 0.365 | 0.53 | 0.546 | |||||
| mixtral-8x7b-instruct | 0.469 | 0.414 | 0.518 | 0.506 | 0.488 | 0.417 | |||
| dbrx-instruct | 0.447 | 0.438 | 0.539 | 0.528 | 0.477 | 0.255 | |||
| gpt-3.5-turbo | 0.44 | 0.362 | 0.463 | 0.486 | 0.447 |
Modelos de prompt
Usamos os seguintes modelos de prompt para o experimento 2:
Databricks DocsQA:
Você é um assistente prestativo, bom em responder perguntas relacionadas a produtos Databricks ou recursos do Spark. Você receberá uma pergunta e várias passagens que podem ser relevantes. Sua tarefa é fornecer uma resposta com base na pergunta e nas passagens.
Observe que as passagens podem não ser relevantes para a pergunta, use apenas as passagens que forem relevantes. Ou, se não houver passagem relevante, responda usando seu conhecimento.
As passagens fornecidas como contexto:
{context}
A pergunta a ser respondida:
{question}
Sua resposta:
|
FinanceBench:
Você é um assistente prestativo, bom em responder perguntas relacionadas a relatórios financeiros. Você receberá uma pergunta e várias passagens que podem ser relevantes. Sua tarefa é fornecer uma resposta com base na pergunta e nas passagens.
Observe que as passagens podem não ser relevantes para a pergunta, use apenas as passagens que forem relevantes. Ou, se não houver passagem relevante, responda usando seu conhecimento.
As passagens fornecidas como contexto:
{context}
A pergunta a ser respondida:
{question}
Sua resposta:
|
{context}
A pergunta a ser respondida:
{question}
Sua resposta:
NQ e HotpotQA:
Você é um assistente que responde a perguntas. Use as seguintes partes do contexto recuperado para responder à pergunta. Algumas partes do contexto podem ser irrelevantes, caso em que você não deve usá-las para formar a resposta. Sua resposta deve ser uma frase curta e não uma resposta completa. Pergunta: {question} Contexto: {context} Resposta: |
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.