Modernize sua plataforma de engenharia de dados com o Lakeflow no Azure Databricks
O Databricks Lakeflow no Azure oferece uma solução de engenharia de dados moderna, de nível empresarial e confiável
- O Lakeflow oferece uma solução unificada de ponta a ponta para engenheiros de dados que trabalham no Azure Databricks, incluindo ingestão, transformação e orquestração de dados
- De segurança e governança unificadas a observabilidade integrada, computação sem servidor, processamento de streaming e uma UI code-first, os profissionais que usam o Azure Databricks podem se beneficiar de uma ampla gama de recursos do Lakeflow, em combinação com sua plataforma de dados do Azure.
- Engenheiros de dados que usam o Lakeflow no Azure Databricks podem criar e implantar pipelines de dados prontos para produção até 25 vezes mais rápido, obter um desempenho superior e uma redução nos custos de ETL de até 83%.
Os engenheiros de dados estão cada vez mais frustrados com o número de ferramentas e soluções desconexas de que precisam para criar pipelines prontos para produção. Sem uma plataforma centralizada de data intelligence platform ou governança unificada, as equipes lidam com muitos problemas, incluindo:
- Desempenho ineficiente e inicializações demoradas
- Interface desarticulada e alternância constante de contexto
- Falta de segurança e controle granular
- CI/CD complexo
- Visibilidade limitada da linhagem de dados
- etc.
O resultado? Equipes mais lentas e menos confiança em seus dados.
Com o Lakeflow no Azure Databricks, você pode resolver esses problemas centralizando todos os seus esforços de engenharia de dados em uma única plataforma nativa do Azure.

Uma solução unificada de engenharia de dados para o Azure Databricks
O Lakeflow é uma solução moderna e completa de engenharia de dados desenvolvida na Plataforma de Inteligência de Dados da Databricks no Azure que integra todas as funções essenciais de engenharia de dados. Com o Lakeflow, você obtém:
- Ingestão, transformação e orquestração de dados integradas em um só lugar
- Conectores de ingestão gerenciados
- ETL declarativo para um desenvolvimento mais rápido e simples
- Processamento incremental e de transmissão para SLAs mais rápidos e percepções mais recentes
- Governança e linhagem nativas via Unity Catalog, a solução de governança integrada da Databricks
- Observabilidade integrada para qualidade de dados e confiabilidade de pipeline
E muito mais! Tudo em uma interface flexível e modular que pode se adaptar a todas as necessidades dos usuários, seja para codificar ou para usar uma interface de apontar e clicar.
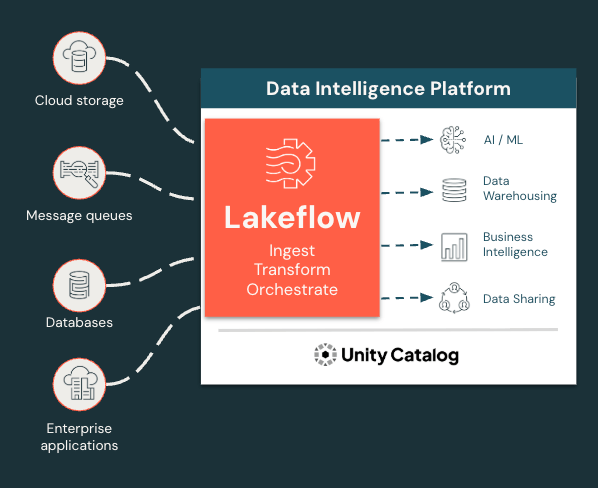
Ingira, transforme e orquestre todas as cargas de trabalho em um só lugar
O Lakeflow unifica a experiência de engenharia de dados para que você possa avançar com mais rapidez e confiabilidade.
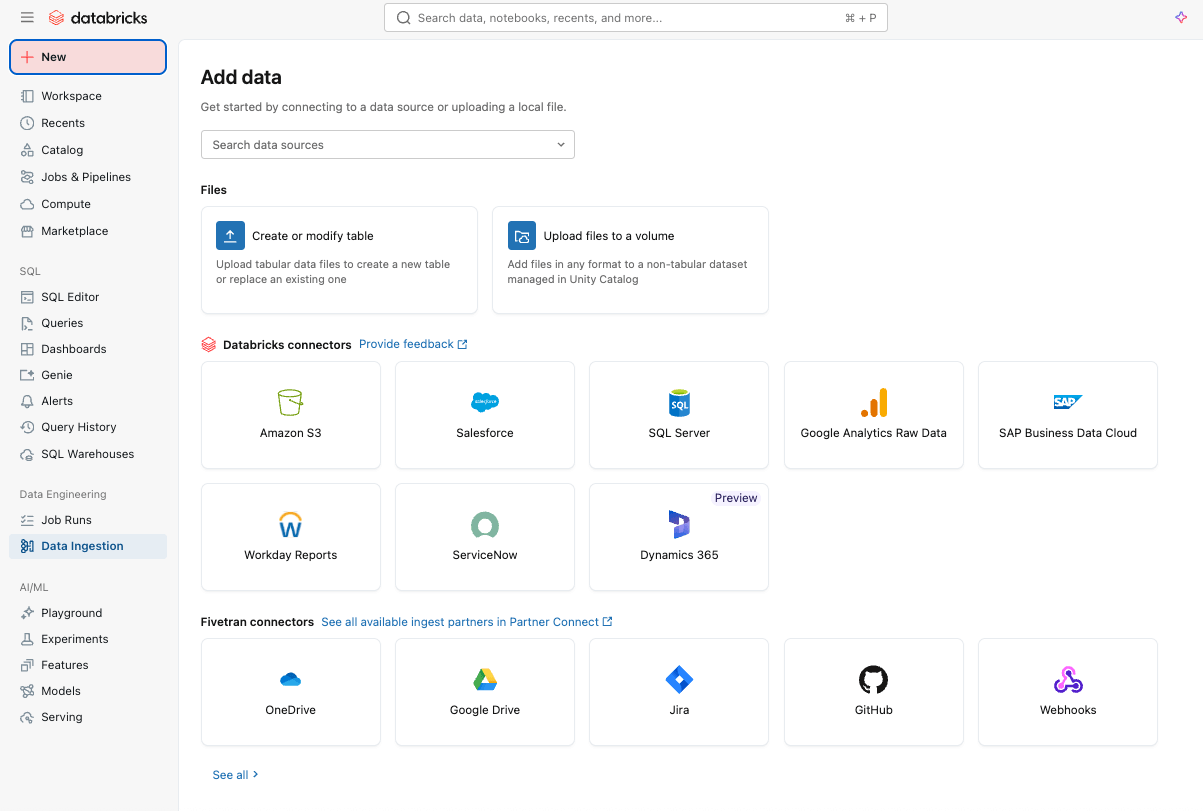
Ingestão de dados simples e eficiente com o Lakeflow Connect
Você pode começar ingerindo dados facilmente em sua plataforma com o Lakeflow Connect usando uma interface point-and-click ou uma API simples.
Você pode ingerir dados estruturados e não estruturados de uma ampla variedade de fontes compatíveis no Azure Databricks, incluindo aplicativos SaaS populares (por exemplo, Salesforce, Workday, ServiceNow), bancos de dados (por exemplo, SQL Server), armazenamento em nuvem, barramentos de mensagens e muito mais. O Lakeflow Connect também oferece suporte a padrões de rede do Azure, como o Private Link e a implantação de gateways de ingestão em uma VNet para bancos de dados.
Para ingestão em tempo real, confira o Zerobus Ingest, uma API serverless de gravação direta no Lakeflow no Azure Databricks. Ela envia dados de eventos diretamente para a plataforma de dados, eliminando a necessidade de um barramento de mensagens para uma ingestão mais simples e com menor latência.
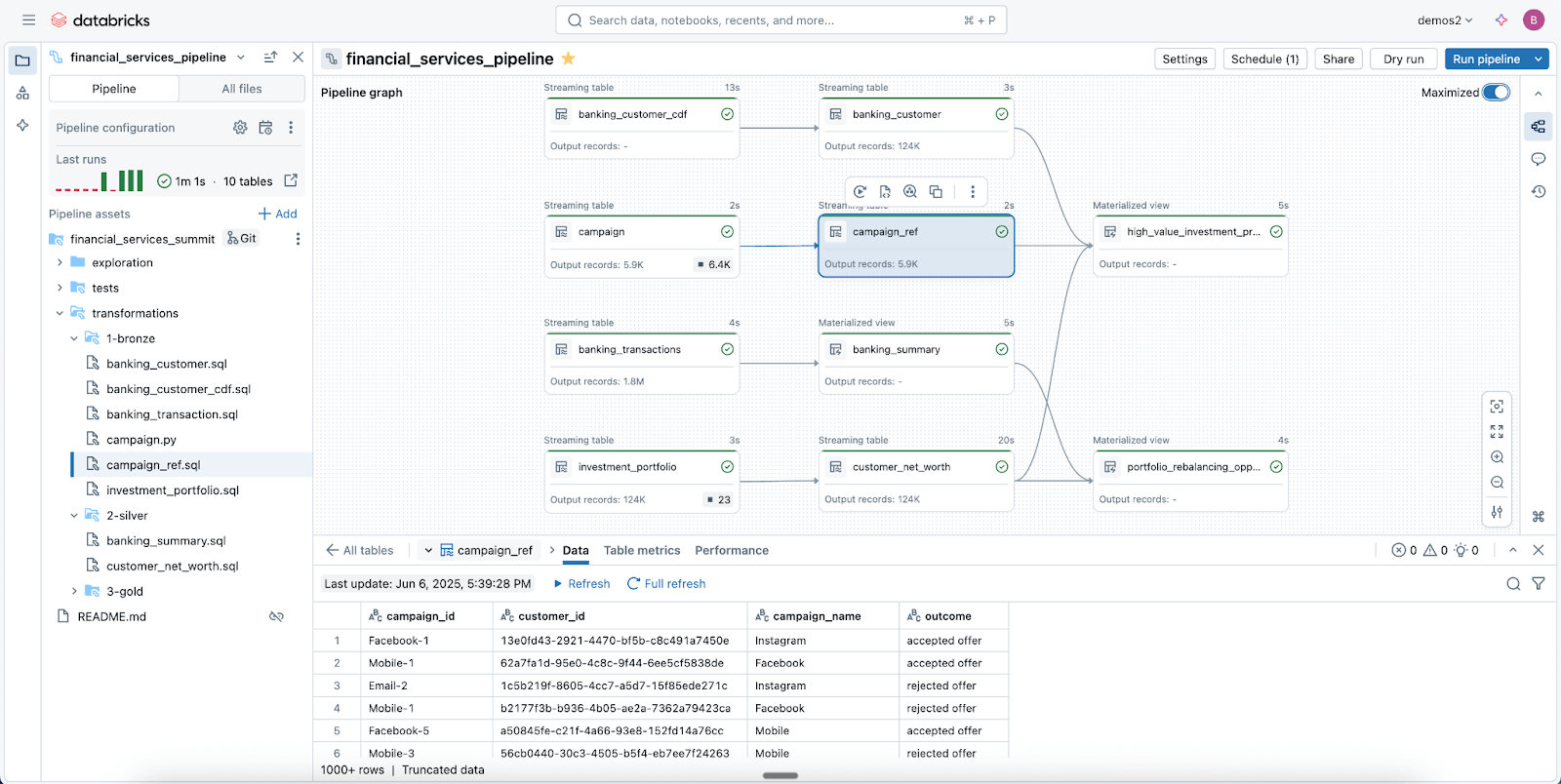
Pipelines de dados confiáveis facilitados com o Spark Declarative Pipelines
Aproveite o Lakeflow Spark Declarative Pipelines (SDP) para limpar, modelar e transformar seus dados facilmente da maneira que sua empresa precisa.
SDP permite que você crie ETLs de lotes e transmissão confiáveis com apenas algumas linhas de Python (ou SQL). Basta declarar as transformações de que você precisa, e o SDP cuida do resto, incluindo mapeamento de dependências, infraestrutura de implantação e qualidade dos dados.
O SDP minimiza o tempo de desenvolvimento e a sobrecarga operacional, ao mesmo tempo em que codifica as melhores práticas de engenharia de dados prontas para uso, facilitando a implementação da incrementalização ou de padrões complexos como SCD Tipo 1 e 2 com apenas algumas linhas de código. É todo o poder do Spark Structured Streaming, de forma incrivelmente simples.
E como o Lakeflow está integrado ao Azure Databricks, você pode usar as ferramentas do Azure Databricks, incluindo Databricks Asset Bundles (DABs), Lakehouse Monitoring e muito mais, para implantar pipelines prontos para produção e governados em minutos.
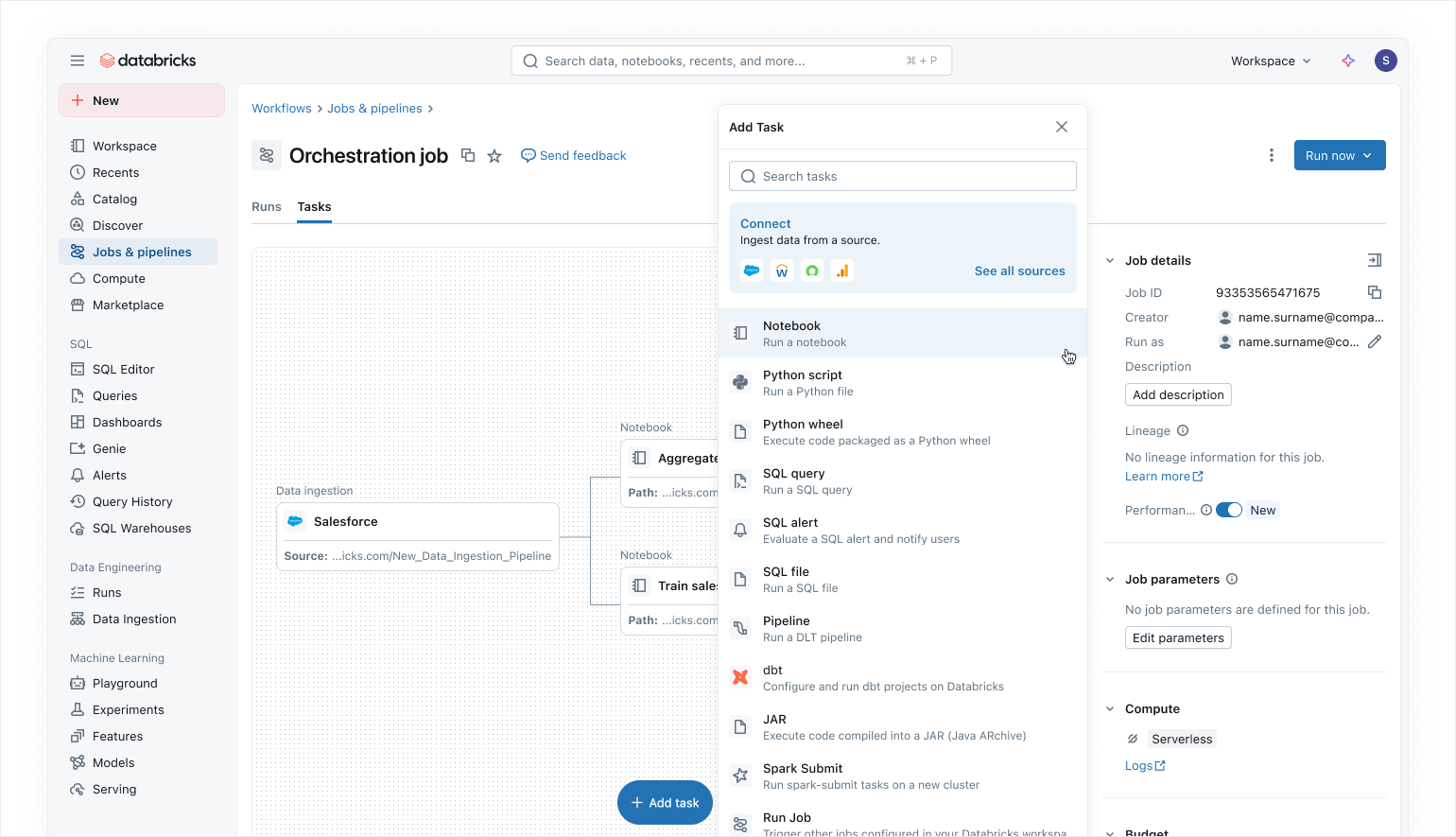
Orquestração moderna que prioriza os dados com o Lakeflow Jobs
Use o Lakeflow Jobs para orquestrar suas cargas de trabalho de dados e AI no Azure Databricks. Com uma abordagem moderna, simplificada e que prioriza os dados, o Lakeflow Jobs é o orquestrador mais confiável para o Databricks, oferecendo suporte ao processamento de dados e AI em grande escala e à analítica em tempo real com 99,9% de confiabilidade.
No Lakeflow Jobs, você pode visualizar todas as suas dependências coordenando cargas de trabalho SQL, código Python, dashboards, pipelines e sistemas externos em um único DAG unificado. A execução do fluxo de trabalho é simples e flexível com gatilhos com reconhecimento de dados, como atualizações de tabelas ou chegada de arquivos, e tarefas de controle de fluxo.Graças a execuções de backfill sem código e observabilidade integrada, o Lakeflow Jobs facilita a manutenção de seus dados downstream atualizados, acessíveis e precisos.
Como usuários do Azure Databricks, vocês também podem atualizar e refresh automaticamente os modelos semânticos do Power BI usando a tarefa do Power BI no Lakeflow Jobs (leia mais aqui), tornando o Lakeflow Jobs um orquestrador perfeito para as cargas de trabalho do Azure.
Segurança integrada e governança unificada
Com o Unity Catalog, o Lakeflow herda controles centralizados de identidade, segurança e governança em toda a ingestão, transformação e orquestração. As conexões armazenam credenciais com segurança, as políticas de acesso são aplicadas de forma consistente em todas as cargas de trabalho e as permissões refinadas garantem que apenas os usuários e sistemas certos possam ler ou gravar dados.
O Unity Catalog também fornece linhagem de ponta a ponta desde a ingestão por meio dos Lakeflow Jobs até a analítica downstream e o Power BI, facilitando o rastreamento de dependências e a garantia da conformidade. As System Tables oferecem visibilidade operacional e de segurança em jobs, usuários e uso de dados para ajudar as equipes a monitorar a qualidade e aplicar as melhores práticas sem precisar juntar logs externos.
Juntos, o Lakeflow e o Unity Catalog fornecem aos usuários do Azure Databricks pipelines governados por padrão, resultando em uma entrega de dados segura, auditável e pronta para produção na qual as equipes podem confiar.
Leia nosso blog sobre como o Unity Catalog oferece suporte ao OneLake.
Experiência de usuário flexível e criação para todos
Além de todos esses recursos, o Lakeflow é incrivelmente flexível e fácil de usar, o que o torna uma ótima opção para qualquer pessoa em sua organização, especialmente para desenvolvedores.
Usuários que priorizam o código adoram o Lakeflow graças ao seu poderoso motor de execução e ferramentas avançadas focadas em desenvolvedores. Com o Lakeflow Pipeline Editor, os desenvolvedores podem aproveitar um IDE e usar ferramentas de desenvolvimento robustas para criar seus pipelines. O Lakeflow Jobs também oferece criação que prioriza o código e ferramentas de desenvolvimento com o SDK DB Python e DABs para padrões de CI/CD repetíveis.
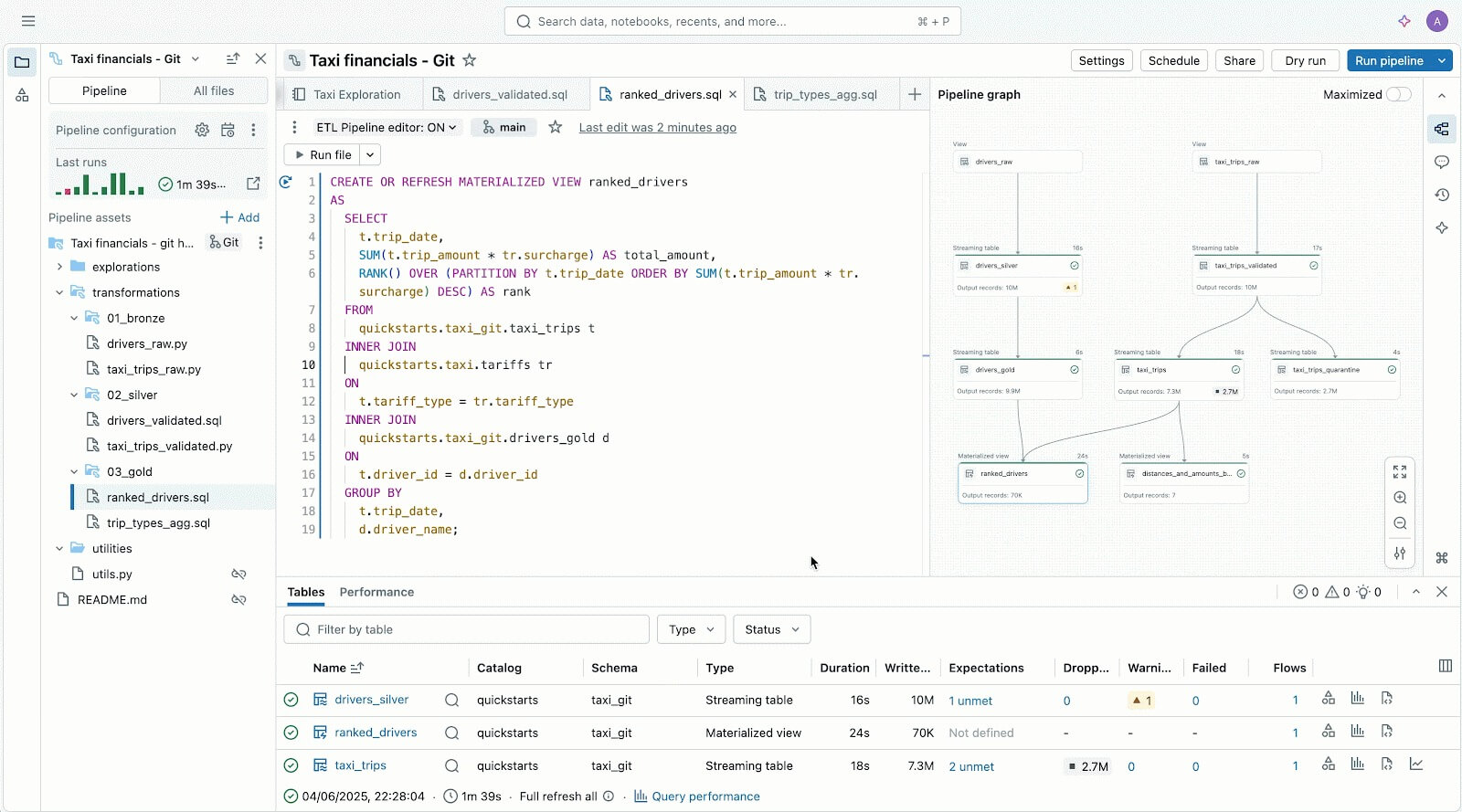
Editor de Pipelines do Lakeflow para ajudar você a criar e testar pipelines de dados — tudo em um só lugar.
Para iniciantes e usuários de negócios, o Lakeflow é muito intuitivo e fácil de usar, com uma interface simples de apontar e clicar e uma API para ingestão de dados via Lakeflow Connect.
Menos suposições, solução de problemas mais precisa com observabilidade nativa
As soluções de monitoramento geralmente são isoladas da sua plataforma de dados, o que torna a observabilidade mais difícil de operacionalizar e seus pipelines mais propensos a falhas
O Lakeflow Jobs no Azure Databricks oferece aos engenheiros de dados a visibilidade profunda e de ponta a ponta de que precisam para entender e resolver problemas em seus pipelines rapidamente. Com os recursos de observabilidade do Lakeflow, você pode identificar imediatamente problemas de desempenho, gargalos de dependência e tarefas com falha em uma única UI com nossa lista de execuções unificada.
As Tabelas do Sistema do Lakeflow e a linhagem de dados integrada com o Unity Catalog também fornecem contexto completo entre datasets, workspaces, queries e impactos downstream, agilizando a análise de causa raiz. Com as Tabelas do Sistema em Jobs, recém-lançadas em disponibilidade geral (GA), você pode criar dashboards personalizados para todos os seus Jobs e monitorar centralmente a integridade deles.
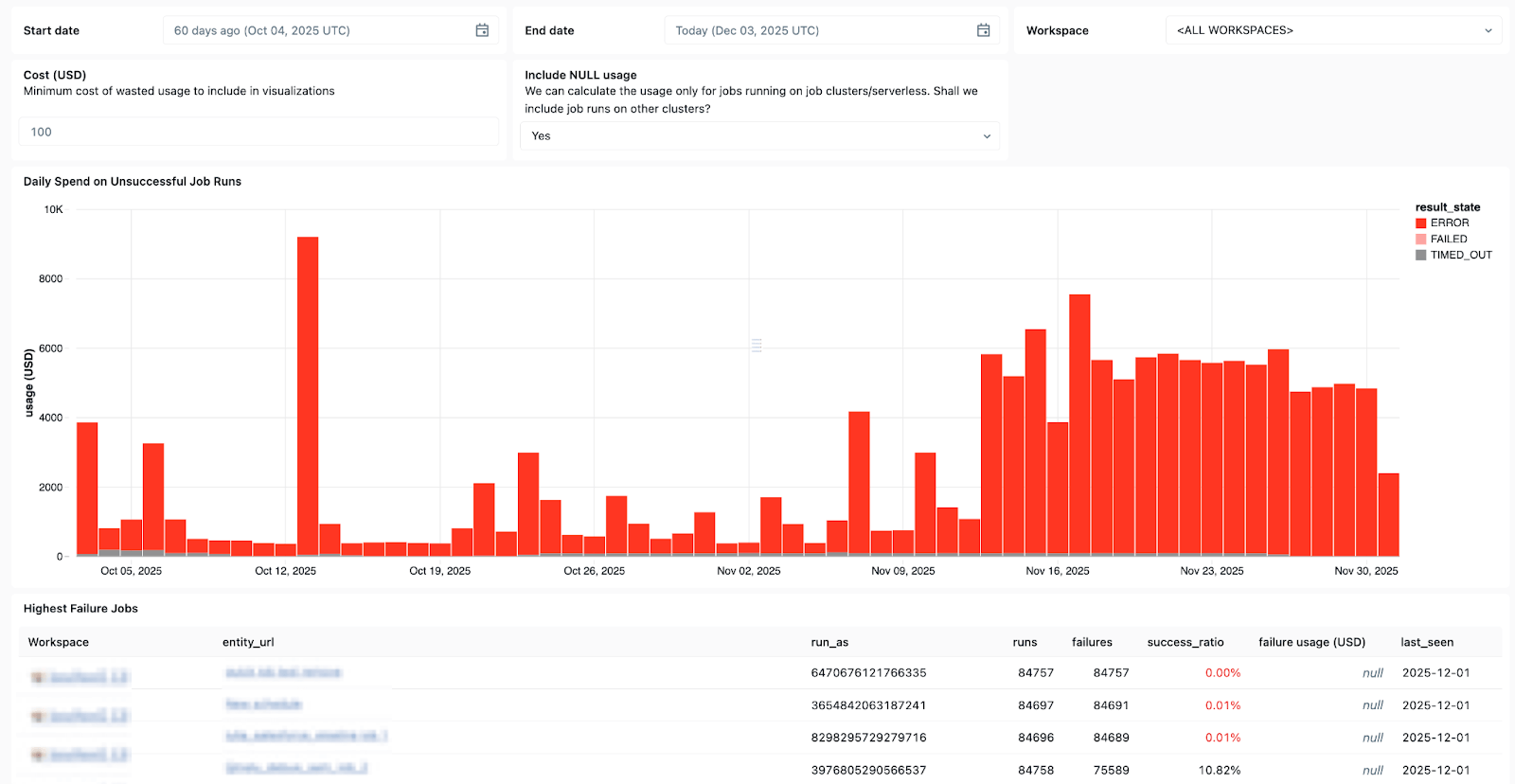
Use as Tabelas do Sistema no Lakeflow para ver quais jobs falham com mais frequência, as tendências gerais de erros e as mensagens de erro comuns.
E quando surgem problemas, o Databricks Assistant está aqui para ajudar.
O Databricks Assistant é um copiloto de AI ciente do contexto incorporado ao Azure Databricks que ajuda você a se recuperar mais rápido de falhas, permitindo criar e solucionar problemas de Notebooks, queries SQL, Jobs e dashboards rapidamente usando linguagem natural.
Mas o Assistente faz mais do que depuração. Ele também pode gerar código PySpark/SQL e explicá-lo com recursos todos baseados no Unity Catalog, para que ele entenda seu contexto. Ele também pode ser usado para executar sugestões, revelar padrões e realizar o descobrimento de dados e EDA, tornando-o um ótimo companheiro para todas as suas necessidades de engenharia de dados.
Seu custo e consumo sob controle
Quanto maiores seus pipelines, mais difícil é dimensionar corretamente o uso de recursos e manter os custos sob controle.
Com o processamento de dados sem servidor do Lakeflow, a compute é otimizada de forma automática e contínua pelo Databricks para minimizar o desperdício ocioso e o uso de recursos. Os engenheiros de dados podem decidir se devem executar o modo sem servidor no modo desempenho para cargas de trabalho de missão crítica ou no modo Standard, onde o custo é mais importante, para maior flexibilidade.
O Lakeflow Jobs também permite a reutilização de clusters, para que várias tarefas em um fluxo de trabalho possam ser executadas no mesmo cluster de Job, eliminando atrasos de inicialização a frio, e oferece suporte a controle detalhado, para que cada tarefa possa ser direcionada ao cluster de Job reutilizável ou a seu próprio cluster dedicado. Juntamente com a computação sem servidor, a reutilização de clusters minimiza as inicializações para que os engenheiros de dados possam reduzir a sobrecarga operacional e ter mais controle sobre seus custos de dados.
Microsoft Azure + Databricks Lakeflow - Uma combinação comprovadamente vencedora
O Databricks Lakeflow permite que as equipes de dados avancem de forma mais rápida e confiável, sem comprometer a governança, a escalabilidade ou o desempenho. Com a engenharia de dados perfeitamente integrada ao Azure Databricks, as equipes podem se beneficiar de uma única plataforma de ponta a ponta que atende a todas as necessidades de dados e IA em escala.
Os clientes no Azure já viram resultados positivos ao integrar o Lakeflow em seu stack, incluindo:
- desenvolvimento mais rápido de pipelines: As equipes podem criar e implantar pipelines de dados prontos para produção até 25 vezes mais rápido e reduzir o tempo de criação em 70%.
- maior desempenho e confiabilidade: Alguns clientes estão observando uma melhoria de 90 vezes no desempenho e reduzindo os tempos de processamento de horas para minutos.
- mais eficiência e economia de custos: A automação e o processamento otimizado reduzem drasticamente a sobrecarga operacional. Clientes relataram economias de até dezenas de milhões de dólares anualmente e reduções nos custos de ETL de até 83%.
Leia as histórias de sucesso de clientes do Azure e do Lakeflow em nosso blog do Databricks.
Ficou curioso sobre o Lakeflow? Experimente o Databricks gratuitamente para conhecer a plataforma de engenharia de dados.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.