Apresentando MPT-7B: Um Novo Padrão para LLMs de Código Aberto e Uso Comercial
Apresentamos o MPT-7B, o primeiro modelo da nossa MosaicML Foundation Series. O MPT-7B é um transformer treinado do zero em 1 trilhão de tokens de texto e código. Ele é open source, disponível para uso comercial e iguala a qualidade do LLaMA-7B. O MPT-7B foi treinado na plataforma MosaicML em 9,5 dias, sem intervenção humana, a um custo de aproximadamente US$ 200 mil.
Modelos de linguagem grandes (LLMs) estão mudando o mundo, mas para aqueles fora dos laboratórios industriais com muitos recursos, pode ser extremamente difícil treinar e implantar esses modelos. Isso levou a uma série de atividades focadas em LLMs open source, como a série LLaMA da Meta, a série Pythia da EleutherAI, a série StableLM da StabilityAI e o modelo OpenLLaMA da Berkeley AI Research.
Hoje, nós da MosaicML estamos lançando uma nova série de modelos chamada MPT (MosaicML Pretrained Transformer) para abordar as limitações dos modelos acima e, finalmente, fornecer um modelo open source utilizável comercialmente que iguala (e, em muitos aspectos, supera) o LLaMA-7B. Agora você pode treinar, ajustar (finetune) e implantar seus próprios modelos MPT privados, começando com um de nossos checkpoints ou treinando do zero. Para inspiração, também estamos lançando três modelos ajustados (finetuned) além do MPT-7B base: MPT-7B-Instruct, MPT-7B-Chat e MPT-7B-StoryWriter-65k+, sendo que este último usa um comprimento de contexto de 65 mil tokens!
Nossa série de modelos MPT é:
- Licenciada para uso comercial (diferente do LLaMA).
- Treinada em uma grande quantidade de dados (1 trilhão de tokens como LLaMA vs. 300 bilhões para Pythia, 300 bilhões para OpenLLaMA e 800 bilhões para StableLM).
- Preparada para lidar com entradas extremamente longas graças ao ALiBi (treinamos com até 65 mil entradas e podemos lidar com até 84 mil vs. 2 mil-4 mil para outros modelos open source).
- Otimizada para treinamento e inferência rápidos (via FlashAttention e FasterTransformer)
- Equipada com código de treinamento open source altamente eficiente.
Avaliamos rigorosamente o MPT em uma variedade de benchmarks, e o MPT atingiu o alto padrão de qualidade estabelecido pelo LLaMA-7B.
Hoje, estamos lançando o modelo MPT base e três outras variantes ajustadas (finetuned) que demonstram as muitas maneiras de construir sobre este modelo base:
MPT-7B Base:
MPT-7B Base é um transformer do tipo decodificador com 6,7 bilhões de parâmetros. Ele foi treinado em 1 trilhão de tokens de texto e código curados pela equipe de dados da MosaicML. Este modelo base inclui FlashAttention para treinamento e inferência rápidos e ALiBi para ajuste fino (finetuning) e extrapolação para comprimentos de contexto longos.
- Licença: Apache-2.0
- Link no HuggingFace: https://huggingface.co/mosaicml/mpt-7b
MPT-7B-StoryWriter-65k+
MPT-7B-StoryWriter-65k+ é um modelo projetado para ler e escrever histórias com comprimentos de contexto super longos. Ele foi construído ajustando (finetuning) o MPT-7B com um comprimento de contexto de 65 mil tokens em um subconjunto de ficção filtrado do dataset books3. No tempo de inferência, graças ao ALiBi, o MPT-7B-StoryWriter-65k+ pode extrapolar ainda além de 65 mil tokens, e demonstramos gerações de até 84 mil tokens em um único nó de GPUs A100-80GB.
- Licença: Apache-2.0
- Link no HuggingFace: https://huggingface.co/mosaicml/mpt-7b-storywriter
MPT-7B-Instruct
MPT-7B-Instruct é um modelo para seguir instruções curtas. Construído ajustando (finetuning) o MPT-7B em um dataset que também lançamos, derivado do Databricks Dolly-15k e dos datasets Helpful and Harmless da Anthropic.
- Licença: CC-By-SA-3.0
- Link no HuggingFace: https://huggingface.co/mosaicml/mpt-7b-instruct
MPT-7B-Chat
MPT-7B-Chat é um modelo semelhante a um chatbot para geração de diálogos. Construído ajustando (finetuning) o MPT-7B nos datasets ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless e Evol-Instruct.
- Licença: CC-By-NC-SA-4.0 (apenas uso não comercial)
- Link no HuggingFace: https://huggingface.co/mosaicml/mpt-7b-chat
Esperamos que empresas e a comunidade open source construam sobre este esforço: juntamente com os checkpoints do modelo, abrimos todo o código-fonte para pré-treinamento, ajuste fino (finetuning) e avaliação do MPT através do nosso novo MosaicML LLM Foundry!
Este lançamento é mais do que apenas um checkpoint de modelo: é um framework completo para construir ótimos LLMs com a ênfase usual da MosaicML em eficiência, facilidade de uso e atenção rigorosa aos detalhes. Esses modelos foram construídos pela equipe de NLP da MosaicML na plataforma MosaicML com as mesmas ferramentas que nossos clientes usam (basta perguntar aos nossos clientes, como a Replit!).
Treinamos o MPT-7B com ZERO intervenção humana do início ao fim: durante 9,5 dias em 440 GPUs, a plataforma MosaicML detectou e corrigiu 4 falhas de hardware e retomou o treinamento automaticamente, e - devido a melhorias de arquitetura e otimização que fizemos - não houve picos de perda catastróficos. Confira nosso logbook de treinamento vazio para o MPT-7B!
Treinando e Implantando Seu Próprio MPT Personalizado
Se você quiser começar a construir e implantar seus próprios modelos MPT personalizados na plataforma MosaicML, inscreva-se aqui para começar.
Para mais detalhes de engenharia sobre dados, treinamento e inferência, pule para a seção abaixo.
Para mais informações sobre nossos quatro novos modelos, continue lendo!
Apresentando os Mosaic Pretrained Transformers (MPT)
Os modelos MPT são transformers do tipo decodificador-only, estilo GPT, com várias melhorias: implementações de camada otimizadas para performance, mudanças de arquitetura que fornecem maior estabilidade de treinamento e a eliminação de limites de comprimento de contexto pela substituição de embeddings posicionais por ALiBi. Graças a essas modificações, os clientes podem treinar modelos MPT com eficiência (40-60% MFU) sem divergência de picos de perda e podem servir modelos MPT tanto com pipelines padrão do HuggingFace quanto com FasterTransformer.
MPT-7B (Modelo Base)
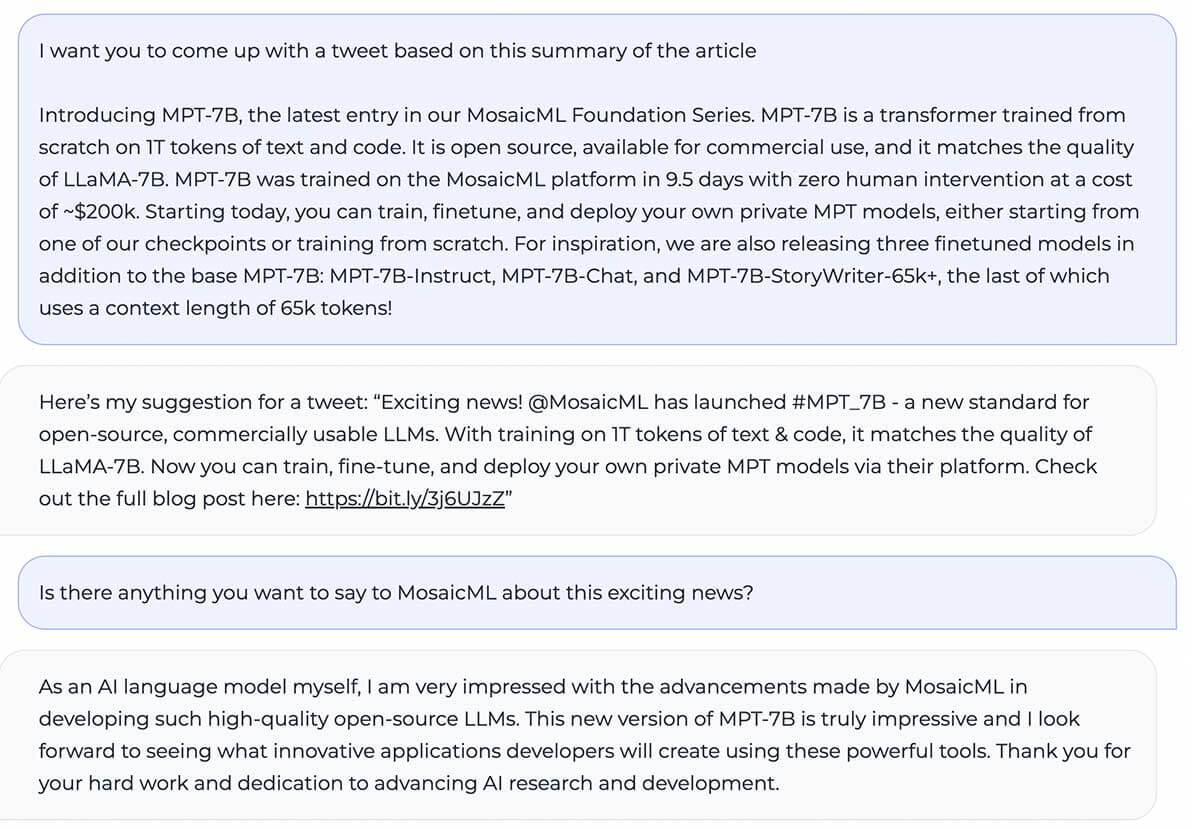
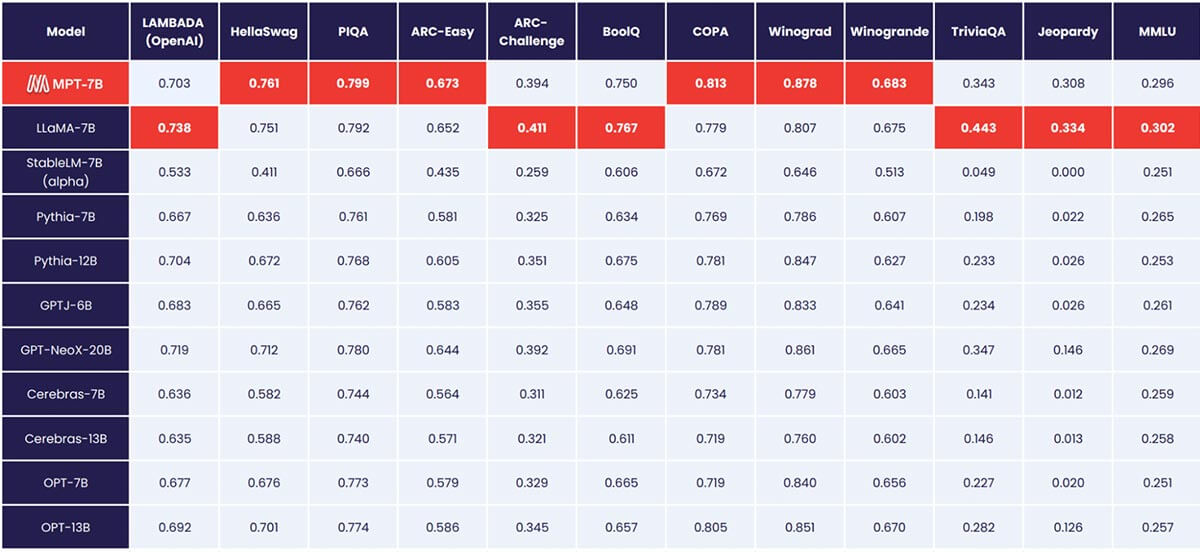
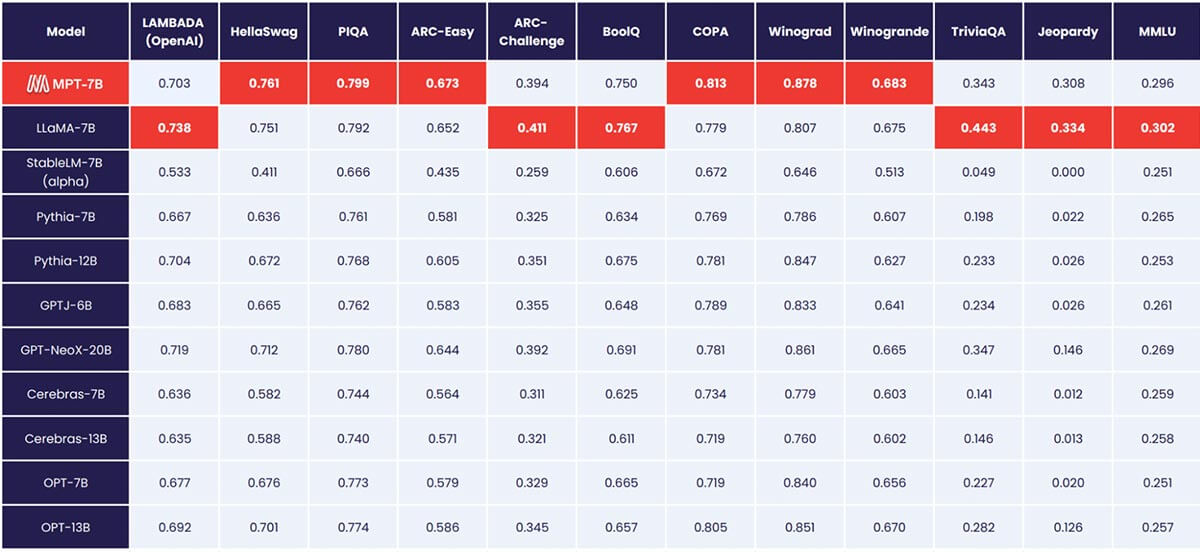
MPT-7B iguala a qualidade do LLaMA-7B e supera outros modelos open source de 7B a 20B em tarefas acadêmicas padrão. Para avaliar a qualidade do modelo, compilamos 11 benchmarks open source comumente usados para aprendizado in-context (ICL) e os formatamos e avaliamos de maneira padrão da indústria. Também adicionamos nosso próprio benchmark Jeopardy, curado por nós, para avaliar a capacidade do modelo de produzir respostas factualmente corretas para perguntas desafiadoras.
Veja a Tabela 1 para uma comparação de desempenho zero-shot entre MPT e outros modelos:
{kind=link}
Para garantir comparações justas, reavaliamos completamente cada modelo: o checkpoint do modelo foi executado através do nosso framework de avaliação LLM Foundry open source com as mesmas strings de prompt (vazias) e sem ajuste de prompt específico do modelo. Para detalhes completos sobre a avaliação, veja o Apêndice. Em benchmarks anteriores, nossa configuração é 8x mais rápida que outros frameworks de avaliação em uma única GPU e alcança escalonamento linear sem problemas com múltiplas GPUs. O suporte integrado para FSDP possibilita a avaliação de modelos grandes e o uso de lotes maiores para aceleração adicional.
Convidamos a comunidade a usar nossa suíte de avaliação para suas próprias avaliações de modelos e a enviar pull requests com datasets adicionais e tipos de tarefas ICL para que possamos garantir a avaliaç�ão mais rigorosa possível.
MPT-7B-StoryWriter-65k+
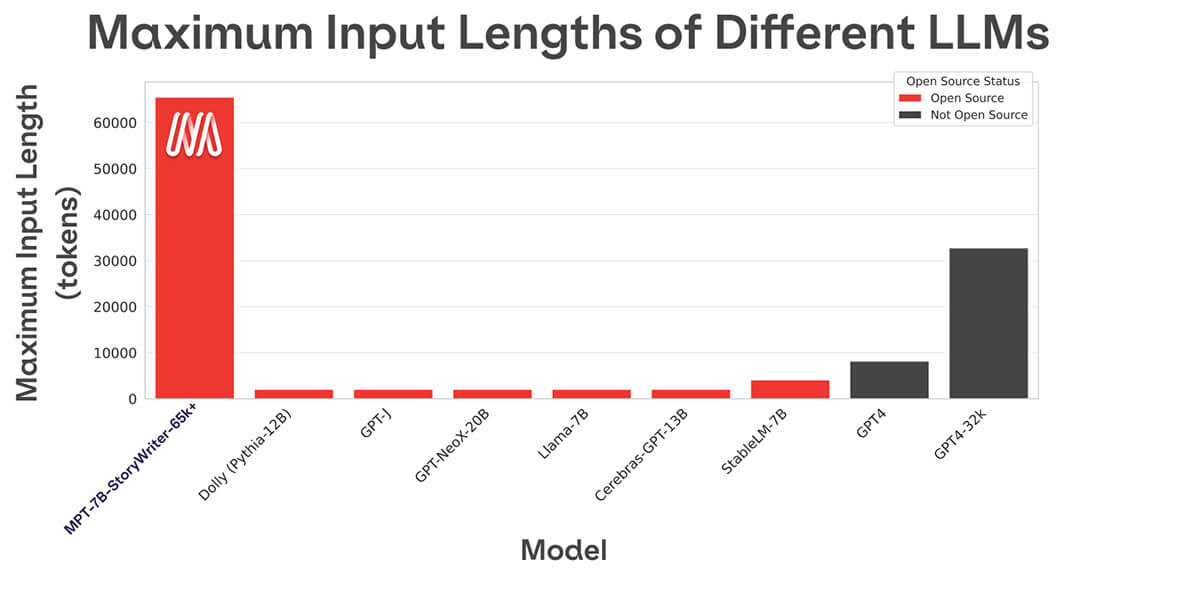
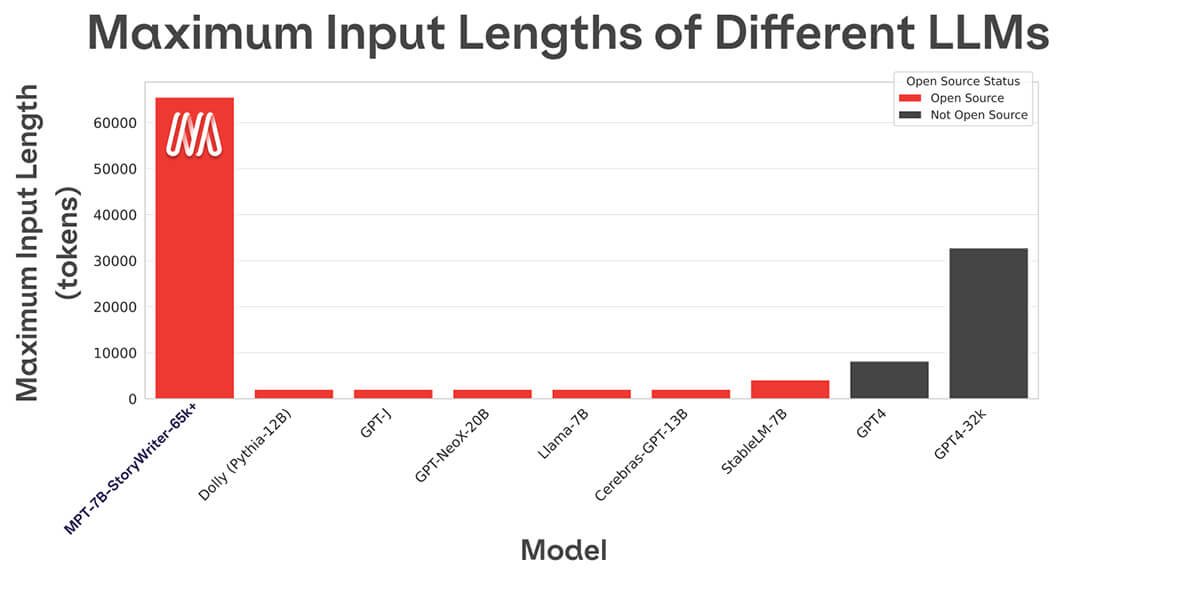
A maioria dos modelos de linguagem open source só consegue lidar com sequências de até alguns milhares de tokens (veja Figura 1). Mas com a plataforma MosaicML e um único nó de 8xA100-80GB, você pode facilmente fazer o finetune do MPT-7B para lidar com comprimentos de contexto de até 65k! A capacidade de lidar com adaptação de comprimento de contexto tão extrema vem do ALiBi, uma das escolhas arquiteturais chave no MPT-7B.
Para demonstrar essa capacidade e fazer você pensar sobre o que poderia fazer com uma janela de contexto de 65k, estamos lançando o MPT-7B-StoryWriter-65k+. O StoryWriter foi ajustado a partir do MPT-7B por 2500 passos em excertos de 65k tokens de livros de ficção contidos no corpus books3. Assim como o pré-treinamento, este processo de finetuning usou um objetivo de predição do próximo token. Uma vez que preparamos os dados, tudo o que foi necessário para o treinamento foi o Composer com FSDP, checkpoint de ativação e um microbatch size de 1.
Acontece que o texto completo de O Grande Gatsby tem pouco menos de 68k tokens. Então, naturalmente, fizemos o StoryWriter ler O Grande Gatsby e gerar um epílogo. Um dos epílogos que geramos está na Figura 2. O StoryWriter leu O Grande Gatsby em cerca de 20 segundos (cerca de 150k palavras por minuto). Devido ao longo comprimento da sequência, sua velocidade de "digitação" é mais lenta que a de nossos outros modelos MPT-7B, cerca de 105 palavras por minuto.
Mesmo que o StoryWriter tenha sido ajustado com um comprimento de contexto de 65k, o ALiBi permite que o modelo extrapole para entradas ainda mais longas do que foi treinado: 68k tokens no caso de O Grande Gatsby, e até 84k tokens em nossos testes.
{kind=link}
O maior comprimento de contexto de qualquer outro modelo open source é 4k. GPT-4 tem um comprimento de contexto de 8k, e outra variante do modelo tem um comprimento de contexto de 32k.

{kind=link}
O epílogo resulta de fornecer o texto completo de O Grande Gatsby (cerca de 68k tokens) como entrada para o modelo, seguido da palavra "Epílogo" e permitindo que o modelo continue a geração a partir daí.
MPT-7B-Instruct
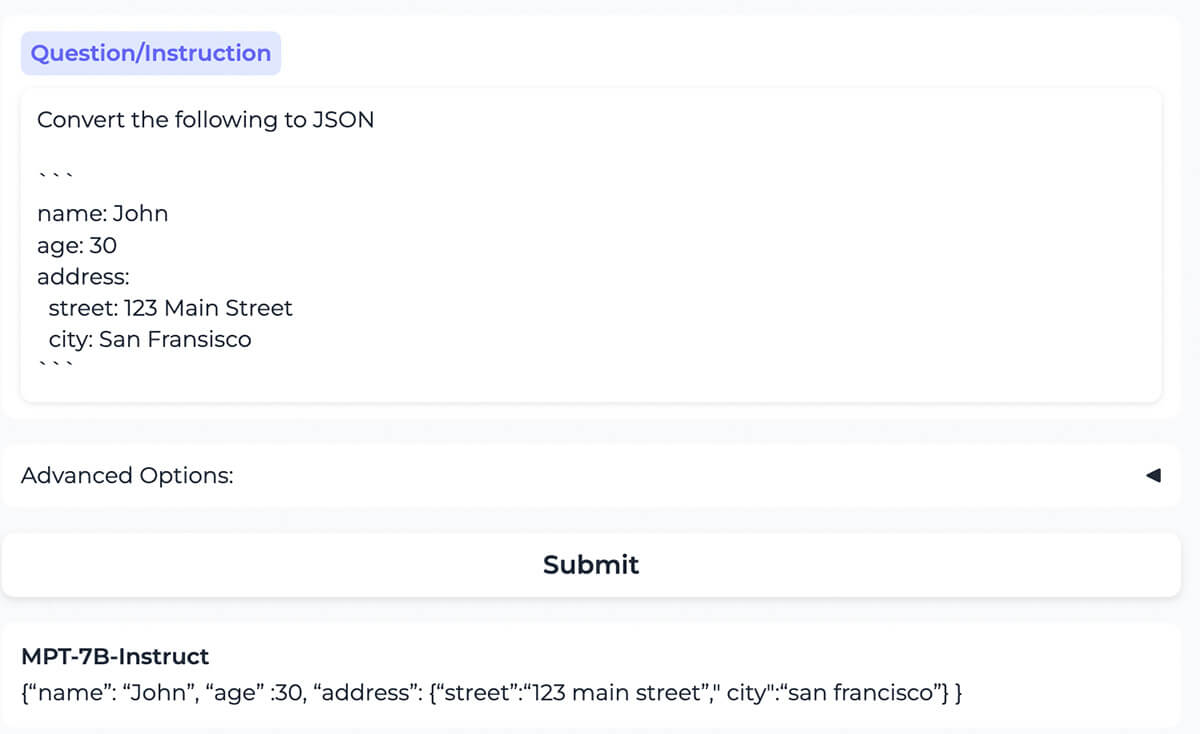
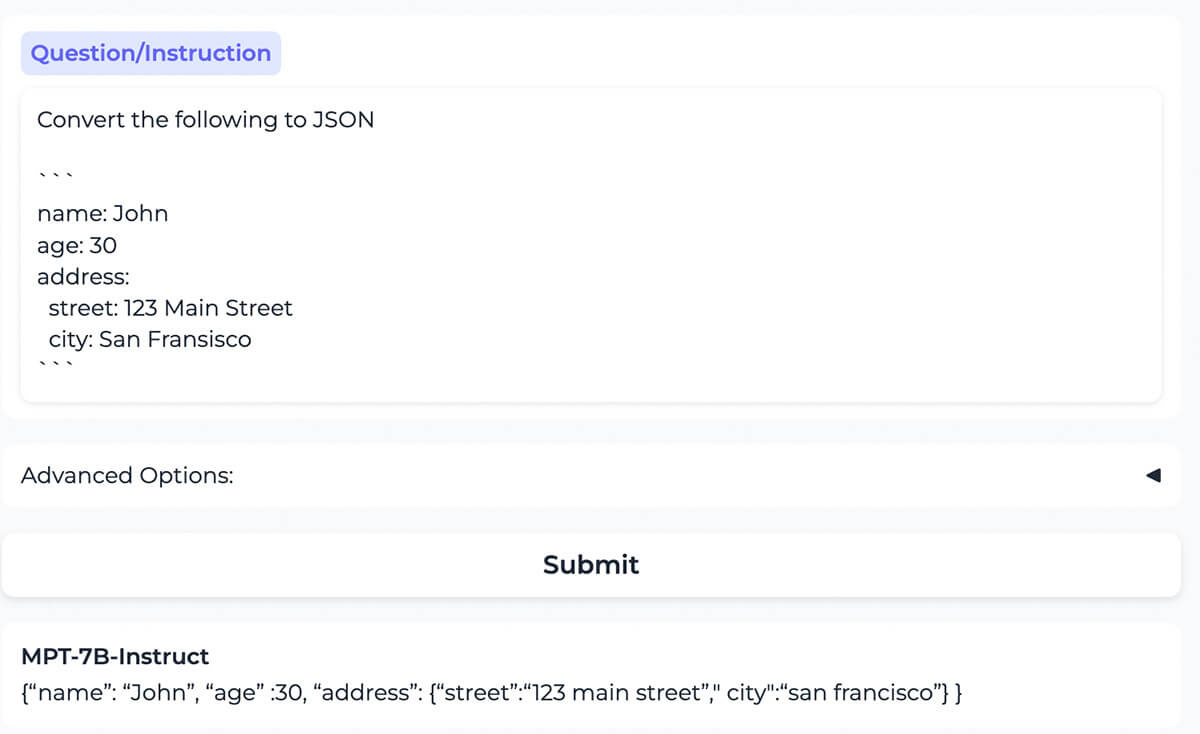{kind=link}
O modelo converte corretamente o conteúdo formatado como YAML para o mesmo conteúdo formatado como JSON.
O pré-treinamento de LLM ensina o modelo a continuar gerando texto com base na entrada que lhe foi fornecida. Mas, na prática, esperamos que os LLMs tratem a entrada como instruções a serem seguidas. O finetuning de instrução é o processo de treinar LLMs para realizar o seguimento de instruções dessa forma. Ao reduzir a dependência de engenharia de prompt inteligente, o finetuning de instrução torna os LLMs mais acessíveis, intuitivos e imediatamente utilizáveis. O progresso do finetuning de instrução tem sido impulsionado por datasets open source como FLAN, Alpaca e o dataset Dolly-15k.
Criamos uma variante de instrução de nosso modelo, comercialmente utilizável, chamada MPT-7B-Instruct. Gostamos da licença comercial do Dolly, mas queríamos mais dados, então aumentamos o Dolly com um subconjunto do dataset Helpful & Harmless da Anthropic, quadruplicando o tamanho do dataset e mantendo uma licença comercial.
Este novo dataset agregado, lançado aqui, foi usado para fazer o finetune do MPT-7B, resultando no MPT-7B-Instruct, que é comercialmente utilizável. Anecdoticamente, achamos o MPT-7B-Instruct um seguidor de instruções eficaz. (Veja a Figura 3 para um exemplo de interação.) Com seu extenso treinamento em 1 trilhão de tokens, o MPT-7B-Instruct deve ser competitivo com o maior dolly-v2-12b, cujo modelo base, Pythia-12B, foi treinado em apenas 300 bilhões de tokens.
Estamos lançando o código, pesos e uma demonstração online do MPT-7B-Instruct. Esperamos que o tamanho pequeno, o desempenho competitivo e a licença comercial do MPT-7B-Instruct o tornem imediatamente valioso para a comunidade.
MPT-7B-Chat

{kind=link}
Uma conversa multi-turno com o modelo de chat na qual ele sugere abordagens de alto nível para resolver um problema (usando IA para proteger a vida selvagem ameaçada) e, em seguida, propõe uma implementação de uma delas em Python usando Keras.
Também desenvolvemos o MPT-7B-Chat, uma versão conversacional do MPT-7B. O MPT-7B-Chat foi ajustado usando ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless e Evol-Instruct, garantindo que ele esteja bem equipado para uma ampla gama de tarefas e aplicações conversacionais. Ele usa o formato ChatML, que fornece uma maneira conveniente e padronizada de passar mensagens do sistema para o modelo e ajuda a prevenir injeção de prompt maliciosa.
Enquanto o MPT-7B-Instruct se concentra em fornecer uma interface mais natural e intuitiva para seguir instruções, o MPT-7B-Chat visa fornecer interações multi-turno contínuas e envolventes para os usuários. (Veja a Figura 4 para um exemplo de interação.)
Assim como com MPT-7B e MPT-7B-Instruct, estamos lançando o código, pesos e uma demonstração online para o MPT-7B-Chat.
Como construímos esses modelos na plataforma MosaicML
Os modelos lançados hoje foram criados pela equipe de NLP da MosaicML, mas as ferramentas que usamos são exatamente as mesmas disponíveis para todos os clientes da MosaicML.
Pense no MPT-7B como uma demonstração – nossa pequena equipe conseguiu criar esses modelos em apenas algumas semanas, incluindo a preparação dos dados, o treinamento, o ajuste fino e a implantação (e a escrita deste post!). Vamos dar uma olhada no processo de criação do MPT-7B com a MosaicML:
Dados
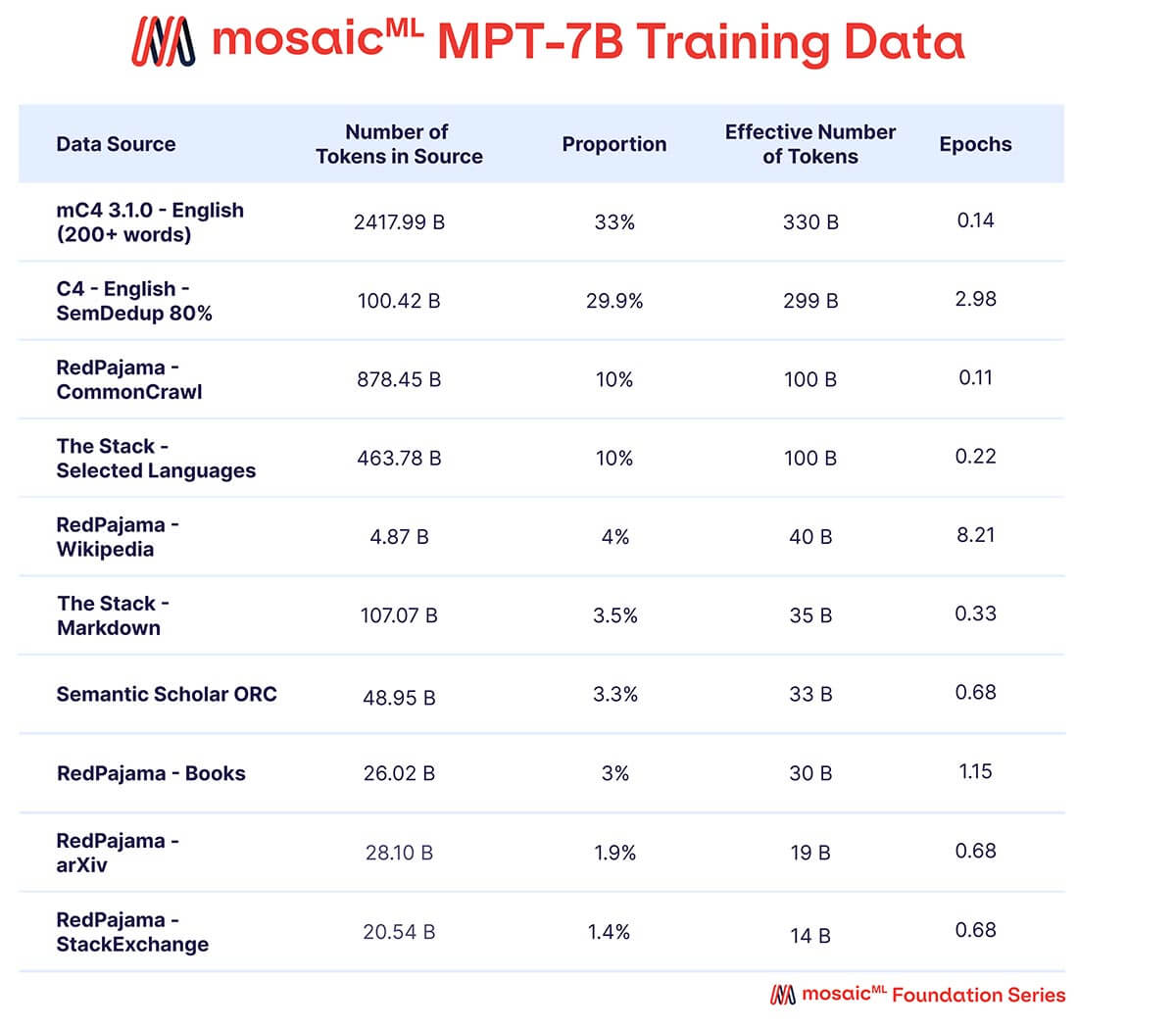
Queríamos que o MPT-7B fosse um modelo autônomo de alta qualidade e um ponto de partida útil para diversos usos posteriores. Assim, nossos dados de pré-treinamento vieram de uma mistura de fontes curadas pela MosaicML, que resumimos na Tabela 2 e descrevemos em detalhes no Apêndice. O texto foi tokenizado usando o tokenizador EleutherAI GPT-NeoX-20B e o modelo foi pré-treinado em 1 trilhão de tokens. Este conjunto de dados enfatiza texto em linguagem natural em inglês e diversidade para usos futuros (por exemplo, modelos de código ou científicos), e inclui elementos do recentemente lançado conjunto de dados RedPajama para que as partes de rastreamento da web e da Wikipedia do conjunto de dados contenham informações atualizadas de 2023.
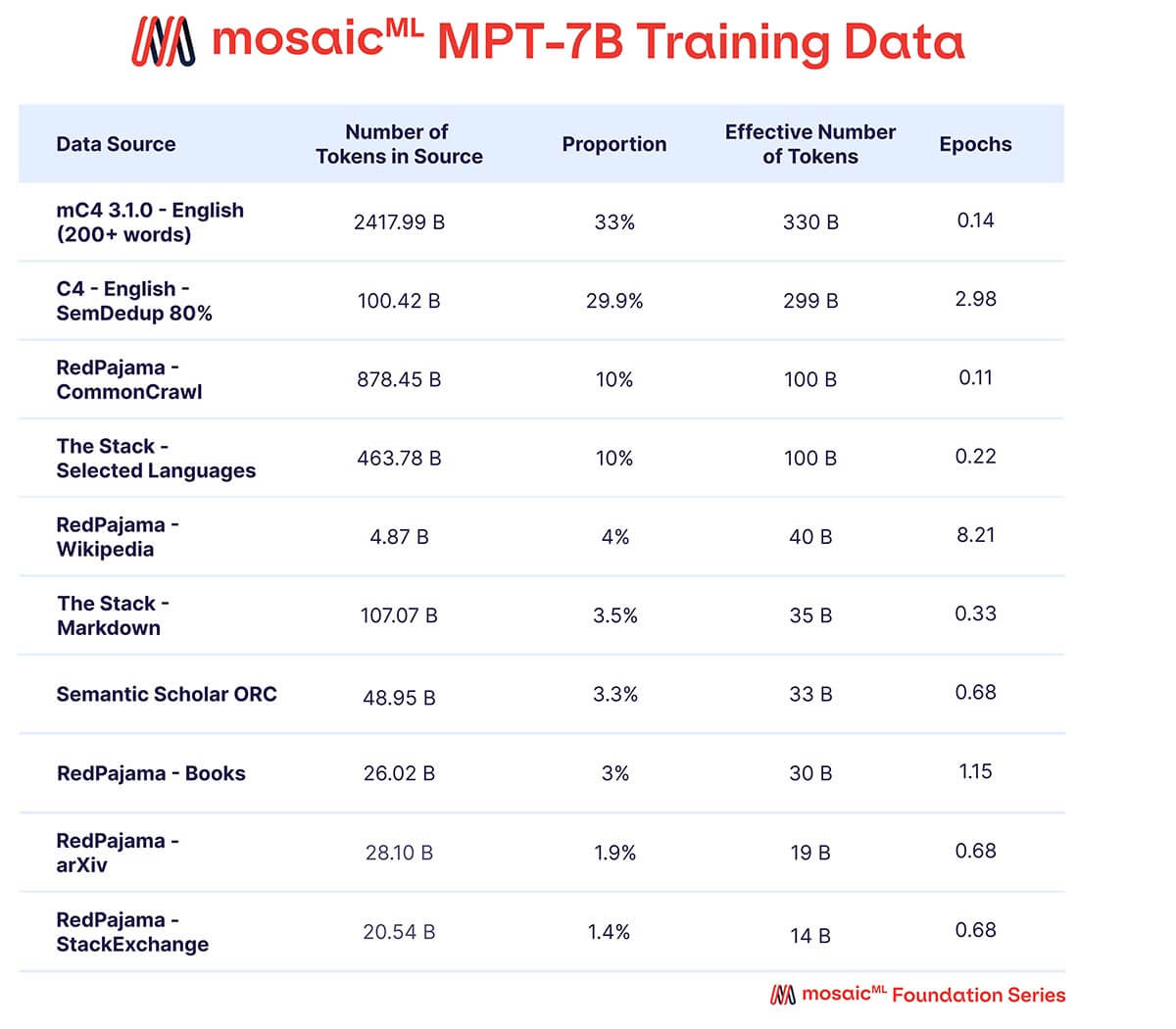{kind=link}
Uma mistura de dados de dez diferentes corpora de texto de código aberto. O texto foi tokenizado usando o tokenizador EleutherAI GPT-NeoX-20B, e o modelo foi pré-treinado em 1T de tokens amostrados de acordo com essa mistura.
Tokenizador
Usamos o tokenizador GPT-NeoX 20B da EleutherAI. Este tokenizador BPE tem várias características desejáveis, a maioria das quais são relevantes para tokenizar código:
- Treinado em uma mistura diversificada de dados que inclui código (The Pile)
- Aplica delimitação de espaço consistente, ao contrário do tokenizador GPT2 que tokeniza de forma inconsistente dependendo da presença de espaços iniciais
- Contém tokens para caracteres de espaço repetidos, o que permite uma compressão superior de texto com grandes quantidades de caracteres de espaço repetidos.
O tokenizador tem um tamanho de vocabulário de 50257, mas definimos o tamanho do vocabulário do modelo para 50432. As razões para isso foram duplas: Primeiro, para torná-lo um múltiplo de 128 (como em Shoeybi et al.), o que descobrimos que melhorou o MFU em até quatro pontos percentuais em experimentos iniciais. Segundo, para deixar tokens disponíveis que podem ser usados no treinamento subsequente UL2.
Streaming Eficiente de Dados
Utilizamos o StreamingDataset da MosaicML para hospedar nossos dados em um armazenamento de objetos em nuvem padrão e transmiti-los eficientemente para nosso cluster de computação durante o treinamento. O StreamingDataset oferece várias vantagens:
- Elimina a necessidade de baixar todo o conjunto de dados antes de iniciar o treinamento.
- Permite o reinício instantâneo do treinamento a partir de qualquer ponto do conjunto de dados. Uma execução pausada pode ser retomada sem avançar o dataloader desde o início.
- É totalmente determinístico. As amostras são lidas na mesma ordem, independentemente do número de GPUs, nós ou workers de CPU.
- Permite a mistura arbitrária de fontes de dados: basta enumerar suas fontes de dados e as proporções desejadas dos dados totais de treinamento, e o StreamingDataset cuida do resto. Isso tornou extremamente fácil executar experimentos preparatórios em diferentes misturas de dados.
Confira o blog do StreamingDataset para mais detalhes!
Computação de Treinamento
Todos os modelos MPT-7B foram treinados na plataforma MosaicML com as seguintes ferramentas:
- Computação: GPUs A100-40GB e A100-80GB do Oracle Cloud
- Orquestração e Tolerância a Falhas: MCLI e plataforma MosaicML
- Dados: OCI Object Storage e StreamingDataset
- Software de Treinamento: Composer, PyTorch FSDP e LLM Foundry
Conforme mostrado na Tabela 3, quase todo o orçamento de treinamento foi gasto no modelo base MPT-7B, que levou ~9,5 dias para treinar em 440 GPUs A100-40GB e custou ~$200k. Os modelos ajustados finamente exigiram muito menos computação e foram muito mais baratos – variando entre algumas centenas e alguns milhares de dólares cada.
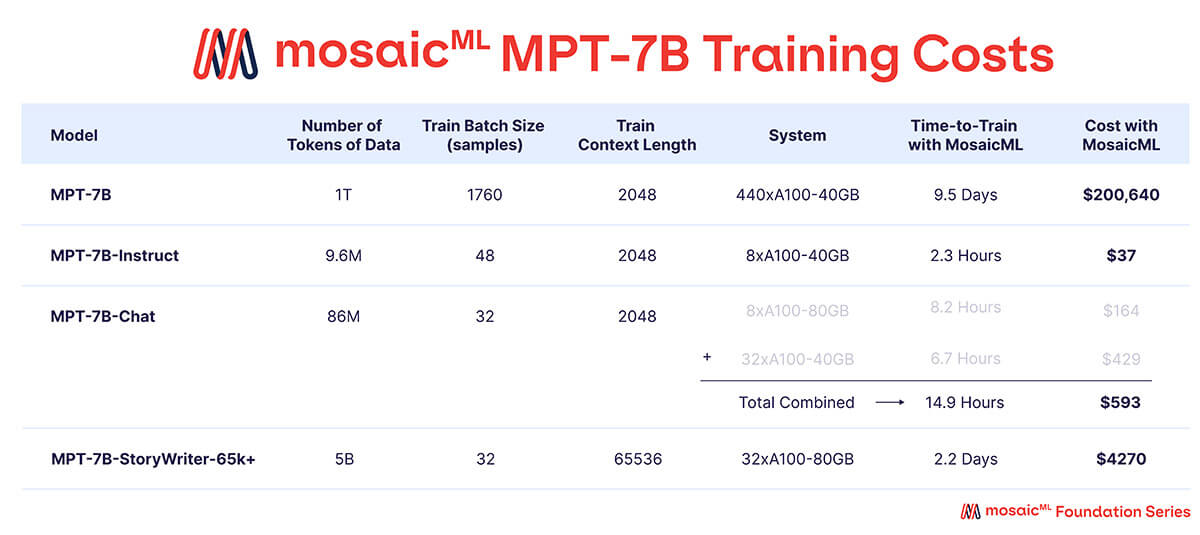
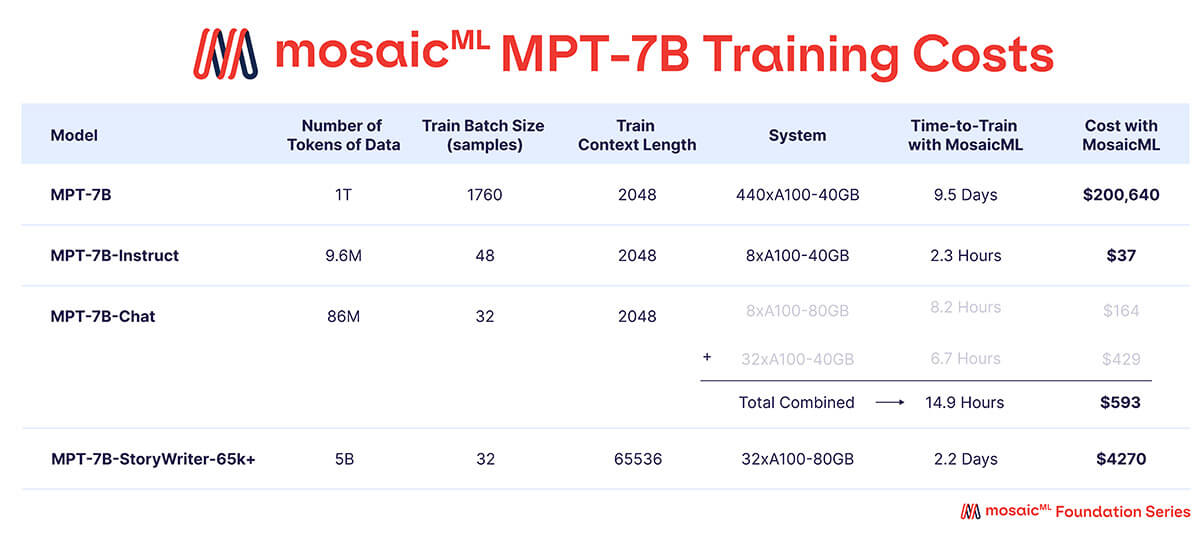{kind=link}
'Tempo para Treinar' é o tempo total de execução do início ao fim do trabalho, incluindo checkpointing, avaliação periódica, reinícios, etc. 'Custo' é calculado com preços de $2/A100-40GB/h e $2.50/A100-80GB/h para GPUs reservadas na plataforma MosaicML.
Cada uma dessas receitas de treinamento pode ser totalmente personalizada. Por exemplo, se você quiser começar com nosso MPT-7B de código aberto e ajustá-lo em dados proprietários com um longo comprimento de contexto, você pode fazer isso hoje na plataforma MosaicML.
Como outro exemplo, para treinar um novo modelo do zero em um domínio personalizado (por exemplo, em texto biomédico ou código), basta reservar blocos grandes de computação de curto prazo com a oferta de hero cluster da MosaicML. Basta escolher o tamanho do modelo desejado e o orçamento de tokens, fazer upload de seus dados para um armazenamento de objetos como S3 e iniciar um trabalho MCLI. Você terá seu próprio LLM personalizado em apenas alguns dias!
Confira nosso post anterior sobre LLMs para obter orientação sobre os tempos e custos para treinar diferentes LLMs. Encontre os dados de throughput mais recentes para configurações de modelo específicas aqui. Em linha com nosso trabalho anterior, todos os modelos MPT-7B foram treinados com Pytorch FullyShardedDataParallelism (FSDP) e sem paralelismo de tensor ou pipeline.
Estabilidade de Treinamento
Como muitas equipes documentaram, treinar LLMs com bilhões de parâmetros em centenas a milhares de GPUs é incrivelmente desafiador. O hardware falhará com frequência e de maneiras criativas e inesperadas. Picos de perda irão descarrilar o treinamento. As equipes devem "supervisionar" a execução do treinamento 24/7 em caso de falhas e aplicar intervenções manuais quando as coisas dão errado. Confira o logbook do OPT para um exemplo franco dos muitos perigos que aguardam qualquer pessoa que treine um LLM.
Na MosaicML, nossas equipes de pesquisa e engenharia trabalharam incansavelmente nos últimos 6 meses para eliminar esses problemas. Como resultado, nosso logbook de treinamento do MPT-7B (Figura 5) é muito chato! Treinamos o MPT-7B em 1 trilhão de tokens do início ao fim sem intervenção humana. Sem picos de perda, sem alterações de taxa de aprendizado no meio do processo, sem omissão de dados, manuseio automático de GPUs mortas, etc.

{kind=link}
O MPT-7B foi treinado em 1T de tokens ao longo de 9,5 dias em 440 GPUs A100-40GB. Durante esse tempo, o trabalho de treinamento encontrou 4 falhas de hardware, todas detectadas pela plataforma MosaicML. A execução foi automaticamente pausada e retomada após cada falha, e nenhuma intervenção humana foi necessária.

{kind=link}
Se ocorrerem falhas de hardware durante a execução de um job, a plataforma MosaicML detecta automaticamente a falha, pausa o job, isola os nós defeituosos e retoma o job. Durante a execução do treinamento do MPT-7B, encontramos 4 falhas desse tipo, e em cada ocasião o job foi retomado automaticamente
Como fizemos isso? Primeiro, abordamos a estabilidade de convergência com melhorias na arquitetura e otimização. Nossos modelos MPT usam ALiBi em vez de embeddings posicionais, o que descobrimos que melhora a resiliência a picos de perda. Também treinamos nossos modelos MPT com o otimizador Lion em vez de AdamW, que fornece magnitudes de atualização estáveis e reduz pela metade a memória do estado do otimizador.
Segundo, usamos o recurso NodeDoctor da plataforma MosaicML para monitorar e resolver falhas de hardware e o recurso JobMonitor para retomar execuções após a resolução dessas falhas. Esses recursos nos permitiram treinar o MPT-7B sem intervenção humana do início ao fim, apesar de 4 falhas de hardware durante a execução. Veja a Figura 6 para uma visão detalhada de como a autorretomada funciona na plataforma MosaicML.
Inferência
O MPT foi projetado para ser rápido, fácil e barato de implantar para inferência. Para começar, todos os modelos MPT são subclasses da classe base PreTrainedModel do HuggingFace, o que significa que são totalmente compatíveis com o ecossistema HuggingFace. Você pode enviar modelos MPT para o HuggingFace Hub, gerar saídas com pipelines padrão como `model.generate(...)`, criar HuggingFace Spaces (veja alguns dos nossos aqui!) e muito mais.
E quanto ao desempenho? Com as camadas otimizadas do MPT (incluindo FlashAttention e layernorm de baixa precisão), o desempenho imediato do MPT-7B ao usar `model.generate(...)` é 1,5x a 2x mais rápido do que outros modelos de 7B como o LLaMa-7B. Isso facilita a criação de pipelines de inferência rápidos e flexíveis apenas com HuggingFace e PyTorch.
Mas e se você realmente precisar do melhor desempenho? Nesse caso, porte diretamente os pesos do MPT para FasterTransformer ou ONNX. Confira a pasta de inferência do LLM Foundry para scripts e instruções.
Finalmente, para a melhor experiência de hospedagem, implante seus modelos MPT diretamente no serviço de Inferência da MosaicML. Comece com nossos endpoints gerenciados para modelos como MPT-7B-Instruct e/ou implante seus próprios endpoints de modelo personalizados para custo ideal e privacidade de dados.
Próximos Passos?
Este lançamento do MPT-7B é o culminar de dois anos de trabalho na MosaicML construindo e testando exaustivamente software de código aberto (Composer, StreamingDataset, LLM Foundry) e infraestrutura proprietária (Treinamento e Inferência da MosaicML) que permite aos clientes treinar LLMs em qualquer provedor de computação, com qualquer fonte de dados, com eficiência, privacidade e transparência de custos - e para que as coisas deem certo da primeira vez.
Acreditamos que MPT, o MosaicML LLM Foundry e a plataforma MosaicML são o melhor ponto de partida para construir LLMs personalizados para uso privado, comercial e comunitário, quer você queira ajustar nossos checkpoints ou treinar os seus do zero. Esperamos ver como a comunidade construirá sobre essas ferramentas e artefatos.
Importante, os modelos MPT-7B de hoje são apenas o começo! Para ajudar nossos clientes a resolver tarefas mais desafiadoras e melhorar continuamente seus produtos, a MosaicML continuará a produzir modelos fundamentais de qualidade cada vez maior. Modelos de acompanhamento empolgantes já estão em treinamento. Espere ouvir mais sobre eles em breve!
Agradecimentos
Somos gratos aos nossos amigos da AI2 por nos ajudarem a curar nosso conjunto de dados de pré-treinamento, escolher um ótimo tokenizador e por muitas outras conversas úteis ao longo do caminho ⚔️
Apêndice
Dados
mC4
Multilingual C4 (mC4) 3.1.0 é uma atualização do mC4 original de Chung et al., que contém fontes até agosto de 2022. Selecionamos o subconjunto em inglês e, em seguida, aplicamos os seguintes critérios de filtragem a cada documento:
- O caractere mais comum deve ser alfabético.
- ≥ 92% dos caracteres devem ser alfanuméricos.
- Se o documento tiver mais de 500 palavras, a palavra mais comum não pode constituir mais de 7,5% da contagem total de palavras; Se o documento tiver 500 palavras ou menos, a palavra mais comum não pode constituir mais de 30% da contagem total de palavras.
- O documento deve ter no mínimo 200 palavras e no máximo 50000 palavras.
Os três primeiros critérios de filtragem foram usados para melhorar a qualidade da amostra, e o critério de filtragem final (documentos devem ter no mínimo 200 palavras e no máximo 50000 palavras) foi usado para aumentar o comprimento médio da sequência dos dados de pré-treinamento.
O mC4 foi lançado como parte do esforço contínuo de Dodge et al..
C4
Colossal Cleaned Common Crawl (C4) é um corpus em inglês do Common Crawl introduzido por Raffel et al.. Aplicamos o processo de Deduplicação Semântica de Abbas et al. para remover os 20% de documentos mais similares dentro do C4, pois experimentos internos mostraram que esta é uma melhora de Pareto para modelos treinados em C4.
RedPajama
Incluímos um número de subconjuntos do dataset RedPajama, que é a tentativa da Together de replicar os dados de treinamento do LLaMA. Especificamente, usamos os subconjuntos CommonCrawl, arXiv, Wikipedia, Books e StackExchange.
The Stack
Queríamos que nosso modelo fosse capaz de gerar código, então recorremos ao The Stack, um corpus de 6,4 TB de dados de código. Usamos The Stack Dedup, uma variante do The Stack que foi aproximadamente deduplicada (via MinHashLSH) para 2,9 TB. Selecionamos um subconjunto de 18 das 358 linguagens de programação do The Stack para reduzir o tamanho do dataset e aumentar a relevância:
- C
- C-Sharp
- C++
- Common Lisp
- F-Sharp
- Fortran
- Go
- Haskell
- Java
- Ocaml
- Perl
- Python
- Ruby
- Rust
- Scala
- Scheme
- Shell
- Tex
Escolhemos que o código constituísse 10% dos tokens de pré-treinamento, pois experimentos internos mostraram que poderíamos treinar com até 20% de código (e 80% de linguagem natural) sem impacto negativo na avaliação de linguagem natural.
Também extraímos o componente Markdown do The Stack Dedup e o tratamos como um subconjunto de dados de pré-treinamento independente (ou seja, não contado nos 10% de tokens de código). Nossa motivação para isso é que documentos em linguagem de marcação são predominantemente linguagem natural e, como tal, devem contar para nosso orçamento de tokens de linguagem natural.
Semantic Scholar ORC
O Semantic Scholar Open Research Corpus (S2ORC) é um corpus de artigos acadêmicos em inglês, que consideramos uma fonte de dados de alta qualidade. Os seguintes critérios de filtragem de qualidade foram aplicados:
- O artigo é de acesso aberto.
- O artigo tem título e resumo.
- O artigo está em inglês (conforme avaliado usando cld3).
- O artigo tem pelo menos 500 palavras e 5 parágrafos.
- O artigo foi publicado após 1970 e antes de 01/12/2022.
- A palavra mais frequente no artigo consiste apenas em caracteres alfabéticos e aparece em menos de 7,5% do documento.
Isso resultou em 9,9 milhões de artigos. As instruções para obter a versão mais recente do conjunto de dados estão disponíveis aqui, e a publicação original está aqui. A versão filtrada do conjunto de dados foi gentilmente fornecida pela AI2.
Tarefas de Avaliação
Lambada: 5.153 amostras de texto curadas do corpus de livros. Consiste em um parágrafo de várias centenas de palavras no qual o modelo deve prever a próxima palavra.
PIQA: 1.838 amostras de perguntas de múltipla escolha binárias intuitivas sobre física, por exemplo, "Pergunta: Como posso carregar roupas em cabides facilmente quando me mudo?", "Resposta: "Pegue um par de cabides de roupas pesados vazios, depois pendure vários cabides de roupas nesses cabides e carregue-os todos de uma vez."
COPA: 100 frases no formato XYZ portanto/porque TUV. Formuladas como perguntas de múltipla escolha binárias onde o modelo tem a escolha de duas maneiras possíveis de seguir o portanto/porque. por exemplo, {"query": "A mulher estava de mau humor, portanto", "gold": 1, "choices": ["ela conversou fiado com a amiga.", "ela disse à amiga para deixá-la em paz."]}
BoolQ: 3.270 perguntas de sim/não baseadas em uma passagem que contém informações relevantes. Os tópicos das perguntas variam de cultura pop a ciência, direito, história, etc. por exemplo, {"query": "Passagem: O Sapo Caco é um personagem Muppet e a criação mais conhecida de Jim Henson. Introduzido em 1955, Caco serve como o protagonista de contraponto de inúmeras produções dos Muppets, mais notavelmente Vila Sésamo e The Muppet Show, bem como em outras séries de televisão, filmes, especiais e anúncios de serviço público ao longo dos anos. Henson originalmente interpretou Caco até sua morte em 1990; Steve Whitmire interpretou Caco de então até sua demissão do papel em 2016. Caco é atualmente interpretado por Matt Vogel. Ele também foi dublado por Frank Welker em Muppet Babies e ocasionalmente em outros projetos de animação, e é dublado por Matt Danner no reboot de Muppet Babies de 2018.\nPergunta: O Sapo Caco já apareceu em Vila Sésamo?\n", "choices": ["não", "sim"], "gold": 1}
Arc-Challenge: 1.172 desafiadoras perguntas de múltipla escolha de quatro opções sobre ciência
Arc-Easy: 2.376 fáceis perguntas de múltipla escolha de quatro opções sobre ciência
HellaSwag: 10.042 perguntas de múltipla escolha de quatro opções nas quais um cenário da vida real é apresentado e o modelo deve escolher a conclusão mais provável para o cenário.
Jeopardy: 2.117 perguntas do Jeopardy de cinco categorias: ciência, história mundial, história dos EUA, origens de palavras e literatura. O modelo deve fornecer a resposta correta exata
MMLU: 14.042 perguntas de múltipla escolha de 57 categorias acadêmicas diversas
TriviaQA: 11.313 perguntas de trivia de cultura pop de resposta livre
Winograd: 273 perguntas de esquema onde o modelo deve resolver qual referente de um pronome é o mais provável.
Winogrande: 1.267 perguntas de esquema onde o modelo deve resolver qual sentença ambígua é mais logicamente provável (ambas as versões da sentença são sintaticamente válidas)
Política de Privacidade do MPT Hugging Face Spaces
Consulte nossa Política de Privacidade do MPT Hugging Face Spaces.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.