Integração de Dados Multimodais: Arquiteturas de Produção para IA em Saúde
A maioria dos esforços de IA multimodal em saúde para antes da produção. Aqui está um blueprint prático para unificar genômica, imagens, notas clínicas e wearables com governança, pipelines e estratégias de fusão que lidam com dados ausentes.
por Maks Khomutskyi
- Construa uma base multimodal governada: Incorpore genômica, recursos de imagem, entidades de notas clínicas e fluxos de wearables no Delta com controles de acesso do Unity Catalog, auditoria, linhagem e tags governadas.
- Escolha a fusão que sobrevive à realidade da produção: Use fusão baseada em início/intermediária/final/atenção com base na disponibilidade da modalidade, dimensionalidade e tempo — projetada para modalidades ausentes, não coortes perfeitas.
- Operacionalize ponta a ponta: Use o Lakeflow SDP para streaming + janelas de recursos, pesquisa vetorial para similaridade/coorte e pipelines reproduzíveis (versionamento/viagem no tempo + CI/CD + MLflow) para ir do POC à produção.
Os casos de uso de IA mais valiosos na área da saúde raramente residem em um único conjunto de dados. A integração de dados multimodais — combinando genômica, imagens, notas clínicas e wearables — é essencial para a oncologia de precisão e a detecção precoce, mas muitas iniciativas param antes da produção.
A oncologia de precisão requer a compreensão tanto dos impulsionadores moleculares do perfil genômico quanto do contexto anatômico das imagens. A detecção precoce melhora quando os sinais de risco herdados se encontram com wearables longitudinais. E muitos dos detalhes do “porquê” — sintomas, resposta, justificativa — ainda residem em notas clínicas.
Apesar do progresso real em pesquisa, muitas iniciativas multimodais param antes da produção — não porque a modelagem seja impossível, mas porque os dados e o modelo operacional não estão prontos para a realidade clínica. A restrição não é a sofisticação do modelo, mas a arquitetura: pilhas separadas por modalidade criam pipelines frágeis, governança duplicada e movimentação de dados custosa que falha sob as necessidades de implantação clínica.
Este post descreve um padrão de lakehouse voltado para a produção para medicina de precisão multimodal: como carregar cada modalidade em tabelas Delta governadas, criar recursos intermodais e escolher estratégias de fusão que sobrevivem a dados ausentes no mundo real.
Arquitetura de referência
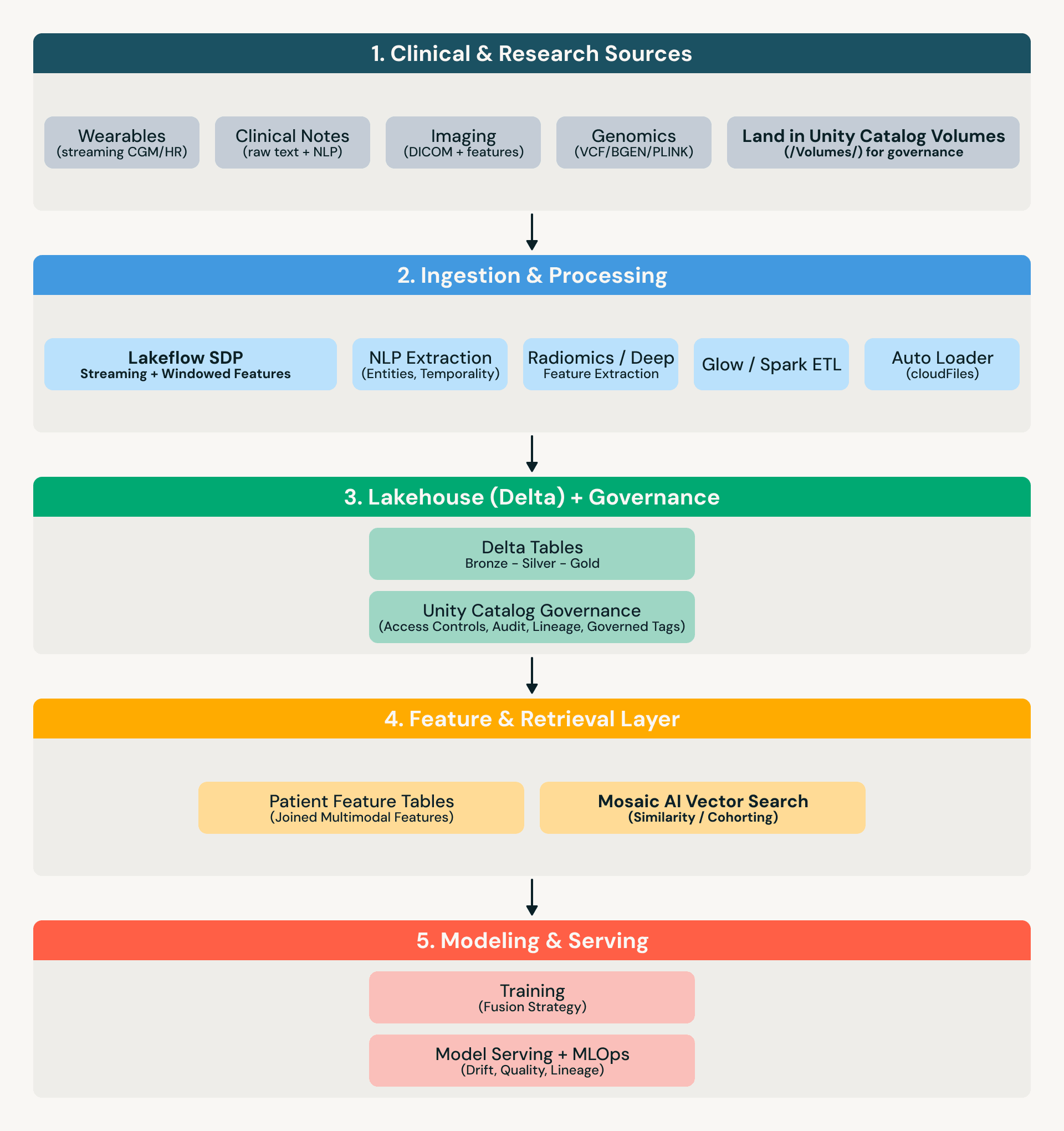
O que “governado” significa na prática
Ao longo deste post, “tabelas governadas” significa que os dados são protegidos e operacionalizados usando o Unity Catalog (ou controles equivalentes), incluindo:
Classificação de dados com tags governadas: PHI/PII/28 CFR Part 202/StudyID/…
- Controles de acesso granular: permissões de catálogo/esquema/tabela/volume, mais controles em nível de linha/coluna onde necessário para PHI.
- Auditabilidade: quem acessou o quê, quando (crítico para ambientes regulamentados).
- Linha do tempo: rastreie recursos e entradas de modelo de volta aos conjuntos de dados de origem.
- Compartilhamento controlado: limites de política consistentes entre equipes e ferramentas.
Reprodutibilidade: versionamento e viagem no tempo para conjuntos de dados, CI/CD para pipelines/jobs e MLflow para rastreamento de experimentos e versões de modelos.
Isso conecta a arquitetura técnica aos resultados de negócios: menos cópias de dados sensíveis, análises reproduzíveis e aprovações mais rápidas para produção.
Por que multimodal está se tornando o padrão
Modelos de modalidade única atingem limites reais em ambientes clínicos complexos. Imagens podem ser poderosas, mas muitas previsões complexas se beneficiam do contexto molecular + longitudinal. A genômica captura os impulsionadores, mas não o fenótipo, o ambiente ou a fisiologia do dia a dia. Notas e wearables adicionam os sinais “entre as linhas” que os dados estruturados muitas vezes perdem.
A realidade do volume importa: o Databricks observa que aproximadamente 80% dos dados médicos são não estruturados (por exemplo, texto e imagens). É por isso que a integração de dados multimodais precisa lidar com notas não estruturadas e imagens em escala — não apenas campos estruturados de EHR.
A conclusão prática: cada modalidade é incompleta por si só. Sistemas multimodais funcionam quando são projetados para:
- Preservar o sinal específico da modalidade.
- Permanecer robusto quando algumas entradas estão ausentes.
Quatro estratégias de fusão (e quando cada uma sobrevive à produção)
A escolha da fusão raramente é o único motivo pelo qual as equipes falham — mas muitas vezes explica por que os pilotos não se traduzem: os dados são esparsos, as modalidades chegam em cronogramas diferentes e os requisitos de governança diferem por tipo de dado.
1) Fusão antecipada (Concatene as entradas brutas antes do treinamento.)
- Use quando: coortes pequenas e estritamente controladas com disponibilidade consistente de modalidade.
- Compromisso: escala mal com genômica de alta dimensionalidade e grandes conjuntos de recursos.
2) Fusão intermediária (Codifique cada modalidade separadamente, depois mescle as representações ocultas.)
- Use quando: combinando ômica de alta dimensionalidade com recursos de EHR/clínicos de menor dimensionalidade.
- Compromisso: requer aprendizado de representação cuidadoso por modalidade e avaliação disciplinada.
3) Fusão tardia (Treine modelos por modalidade, depois combine as previsões.)
- Use quando: implantações em produção onde modalidades ausentes são comuns.
- Benefício: degrada graciosamente quando uma ou mais modalidades estão ausentes.
4) Fusão baseada em atenção (Aprenda ponderação dinâmica entre modalidades e tempo.)
- Use quando: o tempo é importante (wearables + notas longitudinais, imagens repetidas) e as interações são complexas.
- Compromisso: mais difícil de validar; requer controles cuidadosos para evitar correlações espúrias.
Framework de decisão: combine a fusão com sua realidade de implantação: padrões de disponibilidade de modalidade, equilíbrio de dimensionalidade e dinâmica temporal.
O lakehouse como um substrato multimodal
Uma abordagem de lakehouse reduz a movimentação de dados entre modalidades: genômica, metadados/recursos de imagem, entidades derivadas de texto e wearables de streaming podem ser governados e consultados em um só lugar — sem reconstruir pipelines para cada equipe.
Processamento de genômica (Glow + Delta)
O Glow permite o processamento distribuído de genômica no Spark sobre formatos comuns (por exemplo, VCF/BGEN/PLINK), com saídas derivadas armazenadas como tabelas Delta que podem ser unidas a recursos clínicos.
Similaridade de imagem (recursos derivados + Pesquisa Vetorial)
Para imagens, o padrão é: (1) derivar recursos/embeddings upstream (radiômica ou saídas de modelo profundo), (2) armazenar recursos como tabelas Delta governadas (protegidas via Unity Catalog) e (3) usar pesquisa vetorial para consultas de similaridade (por exemplo, “encontrar fenótipos semelhantes dentro do glioblastoma”).
Isso permite a descoberta de coortes e comparações retrospectivas sem exportar dados para sistemas separados.
Notas clínicas (NLP para recursos governados)
Notas frequentemente contêm contexto ausente — cronogramas, sintomas, resposta, justificativa. Uma abordagem prática é extrair entidades + temporalidade em tabelas (mudanças de medicação, sintomas, procedimentos, histórico familiar, cronogramas), manter o texto bruto sob governança rigorosa (Unity Catalog + controles de acesso) e unir recursos derivados de notas a imagens e ômica para modelagem e formação de coortes.
Dados de wearables (Lakeflow SDP para streaming + janelas de recursos)
Streams de wearables introduzem requisitos operacionais: evolução de esquema, eventos que chegam tarde e agregação contínua. O Lakeflow Spark Declarative Pipelines (SDP) fornece um padrão robusto de ingestão para recursos para tabelas de streaming e visualizações materializadas. Para legibilidade, nos referimos a ele como Lakeflow SDP abaixo.
Nota de sintaxe: O módulo pyspark.pipelines (importado como dp) com decoradores @dp.table e @dp.materialized_view segue a semântica Python atual do Databricks Lakeflow SDP.
Por que o modelo unificado de armazenamento + governança importa
A vitória operacional é a coerência:
Uma falha comum em implantações na nuvem é uma abordagem de “loja especializada por modalidade” (por exemplo: uma loja FHIR, uma loja ômica separada, uma loja de imagens separada e uma loja de recursos ou vetorial separada). Na prática, isso geralmente significa governança duplicada e pipelines inter-lojas frágeis — tornando a linha do tempo, a reprodutibilidade e as junções multimodais muito mais difíceis de operacionalizar.
- Reprodutibilidade: ACID + viagem no tempo para conjuntos de treinamento consistentes e reanálise.
- Auditabilidade: logs de acesso + linhagem (quais dados produziram qual feature/modelo).
- Segurança: limites de política consistentes entre modalidades (PHI seguro por design).
- Velocidade: menos transferências e menos cópias de dados entre equipes.
É isso que transforma um protótipo multimodal em algo que você pode executar, monitorar e defender em produção.
Resolvendo o problema da modalidade ausente
Implantações reais lidam com dados incompletos. Nem todos os pacientes recebem perfilamento genômico abrangente. Estudos de imagem podem não estar disponíveis. Wearables existem apenas para populações inscritas. A ausência de dados não é um caso extremo — é o padrão.
Projetos de produção devem assumir a esparsidade e planejar para ela:
- Mascaramento de modalidade durante o treinamento: remova entradas durante o desenvolvimento para simular a realidade da implantação.
- Atenção esparsa / modelos cientes de modalidade: aprenda a usar o que está disponível sem depender excessivamente de uma única modalidade.
- Estratégias de aprendizado por transferência: treine em coortes mais ricas e adapte-se a populações clínicas esparsas com validação cuidadosa.
Insight chave: arquiteturas que assumem dados completos tendem a falhar em produção. Arquiteturas projetadas para esparsidade generalizam.
Padrão de oncologia de precisão: da arquitetura ao fluxo de trabalho clínico
Um padrão prático de oncologia de precisão se parece com isto:
- Perfilamento genômico -> tabelas moleculares governadas (Unity Catalog). Armazene variantes, biomarcadores e anotações como tabelas consultáveis com linhagem e acesso controlado.
- Features derivadas de imagem -> similaridade + coorte. Indexe vetores de features de imagem para “encontrar casos similares” e correlações fenotipótipo-genótipo.
- Linhas do tempo derivadas de notas -> elegibilidade + contexto. Extraia entidades cientes do tempo para apoiar a triagem de ensaios e a compreensão longitudinal consistente.
- Camada de suporte a tumor board (humano no controle). Combine evidências multimodais em uma visualização de revisão consistente com proveniência. O objetivo não é automatizar decisões — é reduzir o tempo de ciclo e melhorar a consistência na coleta de evidências.
Impacto nos negócios: o que muda quando o multimodal se torna operacional
O crescimento do mercado é um motivo pelo qual isso importa — mas o impulsionador imediato é operacional:
- Montagem e reanálise mais rápidas de coortes quando novas modalidades chegam.
- Menos cópias de dados e menos pipelines pontuais.
- Ciclos de iteração mais curtos (semanas vs. meses) para fluxos de trabalho translacionais.
A análise de similaridade de pacientes também pode permitir o raciocínio prático “N-de-1” identificando correspondências históricas com perfis multimodais semelhantes — especialmente valioso em doenças raras e populações heterogêneas de oncologia.
Comece: um pragmático primeiro mês (30 dias)
- Escolha uma decisão clínica (por exemplo, correspondência de ensaio, estratificação de risco) e defina métricas de sucesso.
- Inventarie modalidades + ausência de dados (quem tem genômica? imagem? wearables longitudinais?).
- Configure tabelas bronze/prata/ouro governadas e protegidas via Unity Catalog.
- Escolha uma linha de base de fusão que tolere a ausência de dados (fusão tardia é frequentemente um começo seguro).
- Operacionalize: linhagem, verificações de qualidade de dados, monitoramento de drift, conjuntos de treinamento reproduzíveis.
- Planeje a validação: coortes de avaliação, verificações de viés, pontos de verificação do fluxo de trabalho clínico.
Palavras-chave: IA multimodal, medicina de precisão, processamento genômico, IA de imagem médica, integração de dados de saúde, estratégias de fusão, arquitetura lakehouse
Alta prioridade
Unity Catalog: https://www.databricks.com/product/unity-catalog
Saúde e Ciências da Vida: https://www.databricks.com/solutions/industries/healthcare-and-life-sciences
Plataforma de Inteligência de Dados para Saúde e Ciências da Vida: https://www.databricks.com/resources/guide/data-intelligence-platform-for-healthcare-and-life-sciences
Média prioridade
Documentação do Databricks AI Search: https://docs.databricks.com/en/generative-ai/vector-search.html
Delta Lake no Databricks: https://www.databricks.com/product/delta-lake-on-databricks
Data Lakehouse (glossário): https://www.databricks.com/glossary/data-lakehouse
Blogs relacionados adicionais
Una seus dados do paciente com RAG Multimodal: https://www.databricks.com/blog/unite-your-patients-data-multi-modal-rag
Transformando o gerenciamento de dados ômicos na Plataforma de Inteligência de Dados Databricks: https://www.databricks.com/blog/transforming-omics-data-management-databricks-data-intelligence-platform
Apresentando o Glow (Genômica): https://www.databricks.com/blog/2019/10/18/introducing-glow-an-open-source-toolkit-for-large-scale-genomic-analysis.html
Processando imagens DICOM em escala com databricks.pixels: https://www.databricks.com/blog/2023/03/16/building-lakehouse-healthcare-and-life-sciences-processing-dicom-images.html
Aceleradores de Soluções para Saúde e Ciências da Vida: https://www.databricks.com/solutions/accelerators
Pronto para mover a IA multimodal em saúde de pilotos para produção? Explore os recursos da Databricks para arquiteturas HLS, governança com Unity Catalog e padrões de implementação de ponta a ponta.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.