Observabilidade para qualquer agente, em qualquer lugar: Rastreamento pronto para produção com OpenTelemetry e Unity Catalog no Databricks
Rastreamentos OpenTelemetry no Unity Catalog criam um ciclo de melhoria contínua para agentes de IA através de análises, avaliações e monitoramento.
por Firas Farah, Bruno Faria e Anoop Sunke
- O Problema: Agentes de IA geram volumes massivos de dados de rastreamento, mas as ferramentas de observabilidade tradicionais tornam esses dados caros para reter, difíceis de governar e complicados de usar em fluxos de trabalho de avaliação e análise.
- A Solução: Databricks agora oferece suporte à gravação de rastreamentos OpenTelemetry (OTel) diretamente em tabelas do Unity Catalog por meio de um caminho de ingestão totalmente gerenciado e sem servidor.
- O Benefício: Ao armazenar rastreamentos diretamente no Lakehouse, as equipes obtêm dados de observabilidade governados e prontos para análise, com retenção de longo prazo, fluxos de trabalho unificados de avaliação e monitoramento, e nenhuma infraestrutura OTel para operar.
- O Resultado: Rastros de produção tornam-se imediatamente utilizáveis para análise e avaliação, permitindo ciclos de iteração mais rápidos entre o uso no mundo real, avaliação de modelos e melhoria contínua.
Por que o Rastreamento de IA Rompe a Observabilidade Tradicional
À medida que as aplicações de IA entram em produção, os rastreamentos se tornam uma das formas mais claras de entender como os agentes realmente se comportam, capturando prompts, chamadas de ferramentas, respostas, latência e caminhos de execução. Sem um rastreamento robusto, é difícil entender por que os agentes se comportam da maneira que o fazem, tornando a depuração, avaliação e governança muito mais difíceis.
Os rastreamentos de IA rapidamente se tornam valiosos para fluxos de trabalho de análise, avaliação e monitoramento, indo além dos casos de uso tradicionais de depuração e observabilidade. As equipes querem retê-los por mais tempo, analisá-los com SQL, uni-los a dados de negócios e de modelos, e reutilizá-los para avaliação e monitoramento. Quando os rastreamentos residem apenas dentro de sistemas de observabilidade, essa flexibilidade é limitada, a governança se fragmenta e a movimentação de dados para fluxos de trabalho de análise frequentemente exige pipelines extras e duplicação, especialmente quando dados de prompt sensíveis estão envolvidos.
Ingestão de Rastreamento OTel
Databricks agora oferece suporte à escrita de rastreamentos OTel diretamente no Unity Catalog usando o formato OpenTelemetry (OTel). Na prática, isso significa que os rastreamentos podem ser ingeridos em tempo real e armazenados em tabelas Delta, onde se beneficiam da mesma escalabilidade, governança e ferramentas que o restante dos seus dados.
Isso muda a forma como as equipes podem usar os dados de rastreamento:
- Ingestão em tempo real com retenção prática: Os rastreamentos podem ser gravados à medida que são gerados com alta taxa de transferência e retidos a longo prazo sem a pressão de custos tipicamente associada às plataformas de observabilidade.
- Analise e governe usando o Lakehouse: Uma vez que os rastreamentos estão em tabelas, você pode tratá-los como qualquer outro conjunto de dados: consultá-los com SQL, construir dashboards, executar pipelines ETL, usar ferramentas como Genie e aplicar controles de governança como mascaramento de PII.
- Use a pilha completa de avaliação do MLflow: MLflow facilita a busca, filtragem e aprofundamento em seus rastreamentos para depuração. Persistir rastreamentos no Unity Catalog remove as restrições típicas de experimentos (como limites de rastreamento), tornando mais fácil executar grandes avaliações offline, monitorar sistemas de produção e melhorar continuamente a qualidade à medida que as cargas de trabalho aumentam.
SaaS vs. Lakehouse
Então, por que não depender inteiramente de uma ferramenta de observabilidade SaaS?
- Economia de retenção: Agentes geram grandes volumes de dados de texto. Armazenar esses dados no Delta Lake em armazenamento de objetos é frequentemente significativamente mais econômico do que os modelos de retenção baseados em SaaS.
- O impasse da PII: Enviar prompts brutos para plataformas de terceiros pode criar atrito com a InfoSec. Manter os rastreamentos dentro do Unity Catalog ajuda a manter a soberania dos dados e simplifica a governança.
- Análise, não apenas telemetria: Enquanto as ferramentas SaaS são fortes para métricas operacionais como latência, o Lakehouse fornece um motor de análise. Você pode unir rastreamentos com dados de negócios, como receita e conversões, para entender o impacto real e ir além da saúde do sistema. Além disso, o Lakehouse permite que você aplique IA diretamente aos seus rastreamentos e construa frameworks de avaliação para melhorar continuamente a qualidade do sistema.
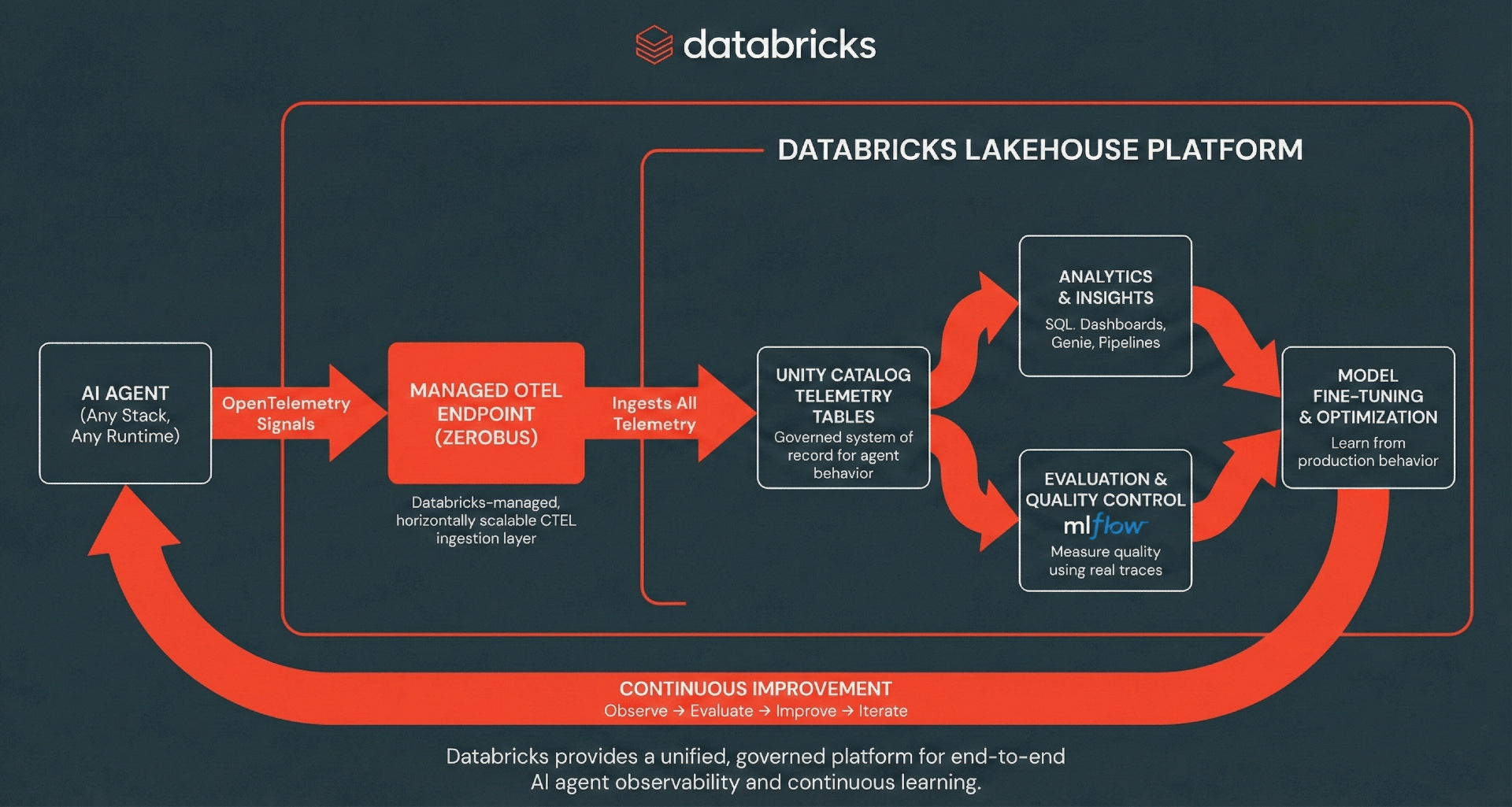
Arquitetura: Ingestão Serverless de OpenTelemetry
Databricks suporta a ingestão de rastreamentos, logs e métricas OpenTelemetry (OTel) diretamente em tabelas do Unity Catalog, usando o padrão OTel para separar a instrumentação do armazenamento.
Databricks remove a complexidade operacional dos pipelines de telemetria tradicionais e multi-hop, fornecendo uma camada de ingestão gerenciada, alimentada de forma transparente por Zerobus Ingest. Zerobus Ingest atua como um motor de ingestão serverless e totalmente gerenciado que suporta nativamente os protocolos padrão OpenTelemetry (OTLP) via gRPC para coletores de código aberto, enquanto suas capacidades de API REST permitem integração perfeita com frameworks de aplicação como MLflow. As aplicações podem exportar facilmente spans, logs e métricas diretamente para tabelas do Unity Catalog, onde os dados são armazenados no formato Delta. Com uma arquitetura de “single-sink”, Zerobus Ingest simplifica a observabilidade ao transmitir dados diretamente para o lakehouse. Coletores OLTP compatíveis existentes podem apontar diretamente para este endpoint via gRPC, ignorando completamente barramentos de mensagens intermediários como Kafka. Zerobus Ingest atua como seu pipeline de telemetria de alta taxa de transferência, lidando com a ingestão e durabilidade com zero sobrecarga de infraestrutura. Qualquer cliente compatível com OTel pode exportar rastreamentos para este endpoint, incluindo frameworks populares de agentes de IA em muitas linguagens de programação.
A partir daí, rastreamentos, logs e métricas se tornam dados de primeira classe no Lakehouse, impulsionando análises SQL ad-hoc, dashboards, análises downstream e fluxos de trabalho de avaliação e monitoramento do MLflow. Unificar sua telemetria cria um ciclo de melhoria contínua onde o comportamento em produção alimenta a avaliação e a análise, o que, por sua vez, impulsiona uma iteração mais rápida e um melhor desempenho do agente.
Tutorial: Conectando Rastreamentos ao Lakehouse
Exemplo de agente: Assistente de gerente de suporte
Para este blog, criaremos um assistente de gerente de suporte simples que podemos usar para demonstrar o rastreamento de ponta a ponta. O agente pode ser implantado fora do Databricks, como fizemos aqui, destacando que a ingestão de rastreamento é desacoplada de onde o agente é executado.
Construímos um agente LangGraph alimentado por um modelo Claude Sonnet 4.6 hospedado no Databricks para raciocínio e geração de respostas. O agente chama um Genie Space como uma ferramenta, que você pode implantar aqui.
Quando um usuário faz uma pergunta orientada por dados, o agente invoca o Genie através da API da ferramenta MCP. Genie traduz a solicitação para SQL, a executa contra o conjunto de dados de suporte e retorna o resultado. O agente então resume as descobertas e fornece insights acionáveis para um gerente de suporte.

Configurando o rastreamento OTel com UC
Antes de instrumentar o agente, primeiro configuramos as tabelas no UC que armazenarão os rastreamentos OpenTelemetry. Neste exemplo, usamos MLflow para criar as tabelas OpenTelemetry subjacentes no Unity Catalog e vinculá-las a um experimento MLflow para que os rastreamentos possam ser pesquisados, analisados e anotados a partir da UI. Comece identificando (ou criando) um SQL warehouse e um experimento MLflow, então use a biblioteca Python do MLflow para provisionar as tabelas do Unity Catalog e associar o esquema ao experimento. Para os passos completos, siga a documentação aqui.
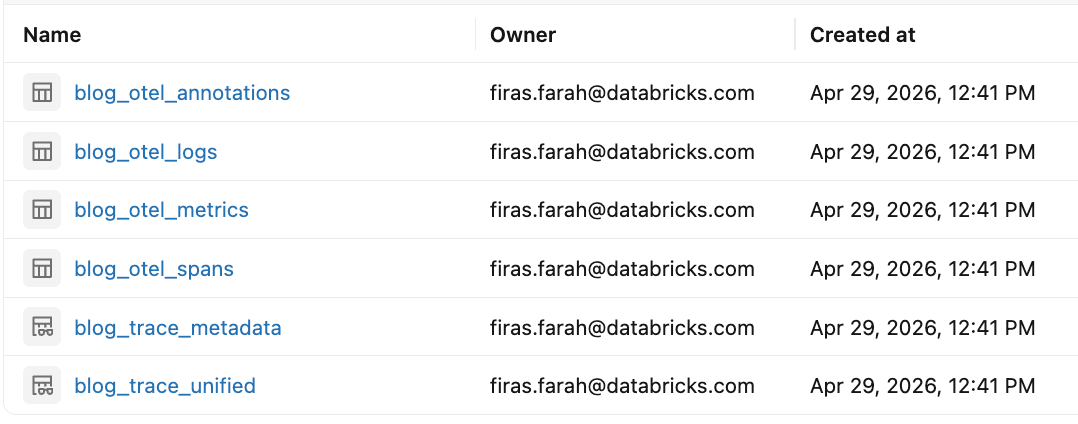
Esta configuração cria tabelas do Unity Catalog para spans, logs e métricas OpenTelemetry. Os dados subjacentes são armazenados em formatos de tabela compatíveis com OpenTelemetry, e o serviço MLflow cria automaticamente visualizações Databricks SQL ao lado delas que transformam os dados OpenTelemetry em um formato amigável ao MLflow para facilitar a consulta e análise. Estes incluem:
<table_prefix>_otel_spans: dados detalhados de execução em nível de span para cada solicitação<table_prefix>_otel_logs: dados estruturados de log/evento capturados durante a execução<table_prefix>_otel_metrics: telemetria numérica capturada durante a execução<table_prefix>_otel_annotations: dados de rastreamento específicos do MLflow que não são um sinal OTel padrão, incluindo metadados, tags, avaliações/feedback, expectativas e links de execução<table_prefix>_trace_unified: uma visualização consolidada que reúne dados de rastreamento em um único registro por rastreamento, incluindo dados de span brutos e metadados de rastreamento<table_prefix>_trace_metadata: tags, metadados e avaliações do MLflow agrupados por ID de rastreamento; mais performático que a visualização unificada quando você precisa apenas dos metadados de rastreamento do MLflow
Após configurar o experimento, a instrumentação do agente permanece a mesma. Qualquer biblioteca de instrumentação compatível com OTel pode exportar rastreamentos para o endpoint configurado. Você pode fazer rastreamento automático e/ou manual conforme descrito aqui. Em nosso exemplo, contamos com mlflow.langchain.autolog() para capturar a execução detalhada do LangGraph (chamadas de modelo e chamadas de ferramenta). Também envolvemos o ponto de entrada com @MLflow.trace para estabelecer um span raiz no nível da requisição, permitindo que cada invocação seja observada como uma única execução de ponta a ponta.
Inspecionando um rastreamento de exemplo
Agora que o agente está instrumentado e os rastreamentos estão fluindo para o Unity Catalog, vamos analisar uma execução real.
Para este exemplo, perguntamos ao Assistente de Gerente de Suporte:
"Qual engenheiro de suporte devo indicar para promoção?"
O agente avaliou a requisição, chamou o espaço Genie várias vezes para coletar dados de suporte e retornou uma recomendação baseada em métricas de desempenho.

Embora a resposta pareça direta, o rastreamento revela o caminho de execução subjacente que a produziu. No experimento MLflow, podemos ver cada uma das chamadas de ferramenta, bem como a lógica de raciocínio do nosso modelo claude sonnet. Podemos ver que ele chamou a ferramenta genie space três vezes antes de montar uma resposta final.
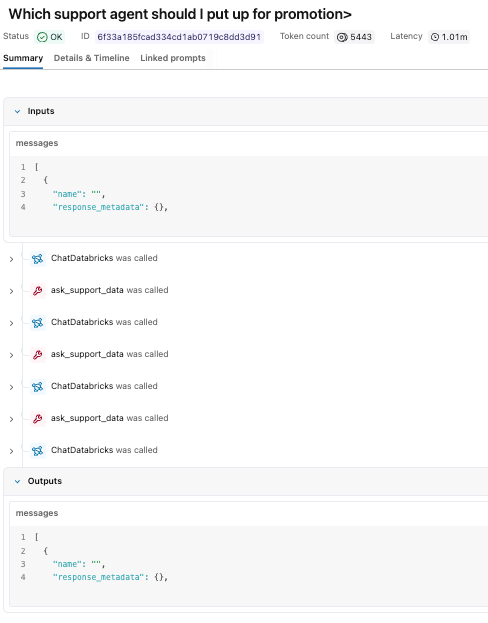
Podemos clicar em cada uma das etapas individuais para estudar as entradas e saídas.
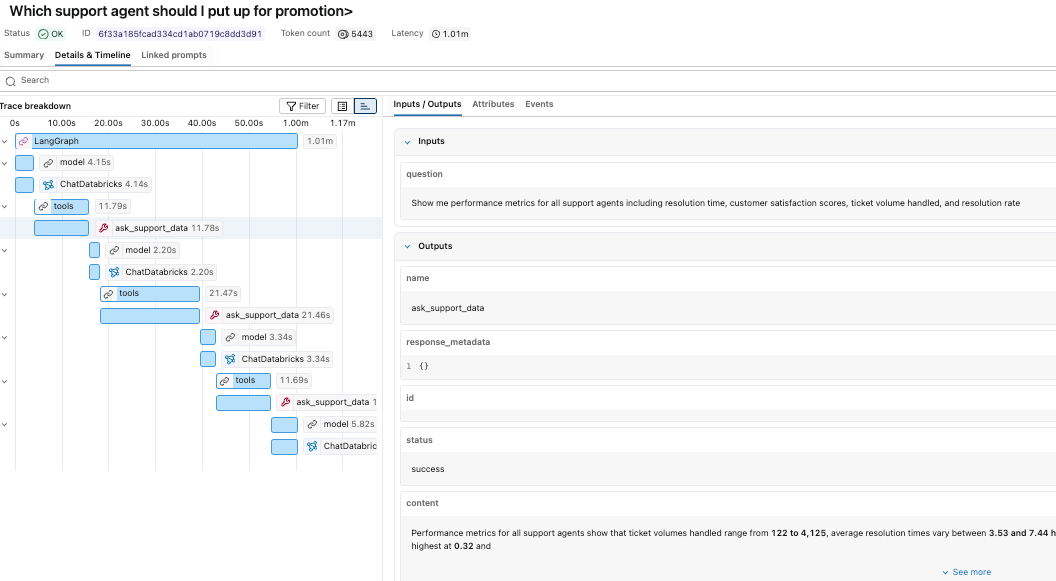
Como os rastreamentos são armazenados como tabelas Delta, eles podem ser consultados como qualquer outro conjunto de dados. Podemos começar com a visualização mlflow_experiment_trace_unified, onde encontraremos um registro que inclui a requisição, resposta, metadados de rastreamento e um array dos spans.
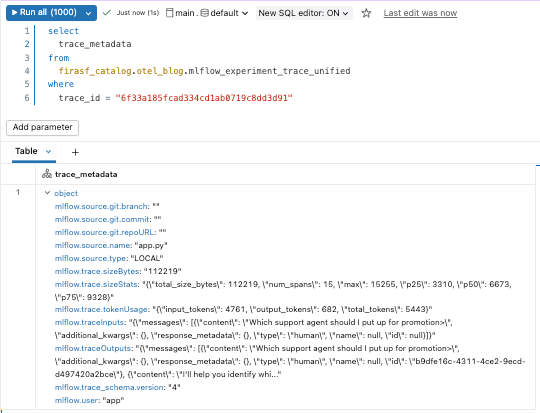
Além da Depuração: Análise de Dados de Rastreamento
Agora que os rastreamentos são armazenados no Unity Catalog, eles se tornam imediatamente disponíveis para análises em lote e em streaming.
Governança no Unity Catalog
No entanto, prompts e respostas frequentemente contêm informações sensíveis, portanto, tratar os dados de rastreamento como dados governados é fundamental. Ao armazená-los no Unity Catalog, os rastreamentos herdam controles de acesso granulares, desde permissões de catálogo e esquema até mascaramento de colunas e filtragem em nível de linha, permitindo análises seguras e prontas para produção sem limitar a flexibilidade.
Uma vez estabelecido o acesso, as equipes podem executar análises ad-hoc com segurança, consultando as tabelas e visualizações subjacentes com SQL, como fizemos acima. Também podemos construir pipelines ETL, além de dashboards e espaços genie, para insights de negócios acionáveis.
Dashboards
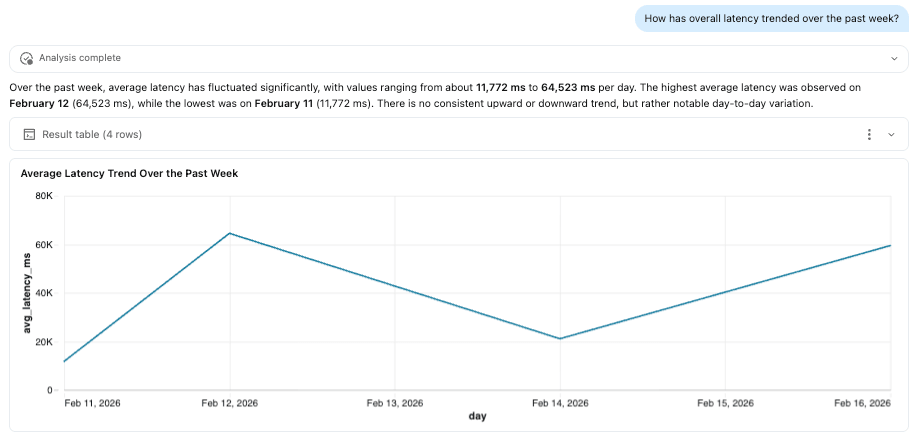
A UI do experimento MLflow agora vem com dashboards de observabilidade nativos para rastreamentos no Unity Catalog, incluindo visualizações para volume de rastreamento, erros, latência, uso de tokens e custo. Para a maioria das equipes, isso é suficiente para monitorar a saúde diária do agente.
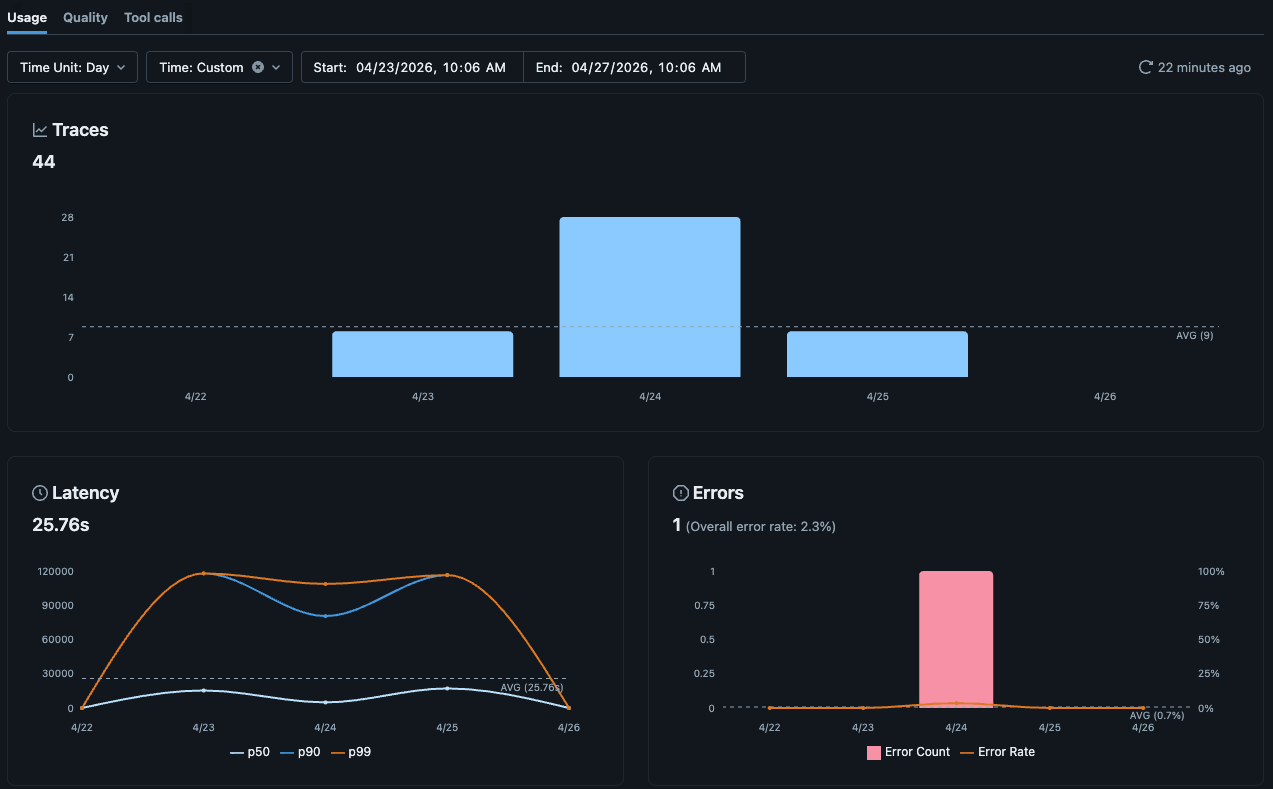
Quando você precisa de uma visualização que vai além dos recursos visuais nativos, as tabelas de rastreamento ainda são apenas tabelas Delta no Unity Catalog. Você pode construir um Dashboard de AI/BI personalizado com base nelas e escrever SQL padrão (com a ajuda da IA) para modelar o que sua equipe considerar importante.
Para mostrar o que os dashboards personalizados podem adicionar às visualizações nativas, construímos um Centro de Operações de IA em nossas tabelas de rastreamento. Abaixo estão algumas capacidades que valem a pena mencionar.
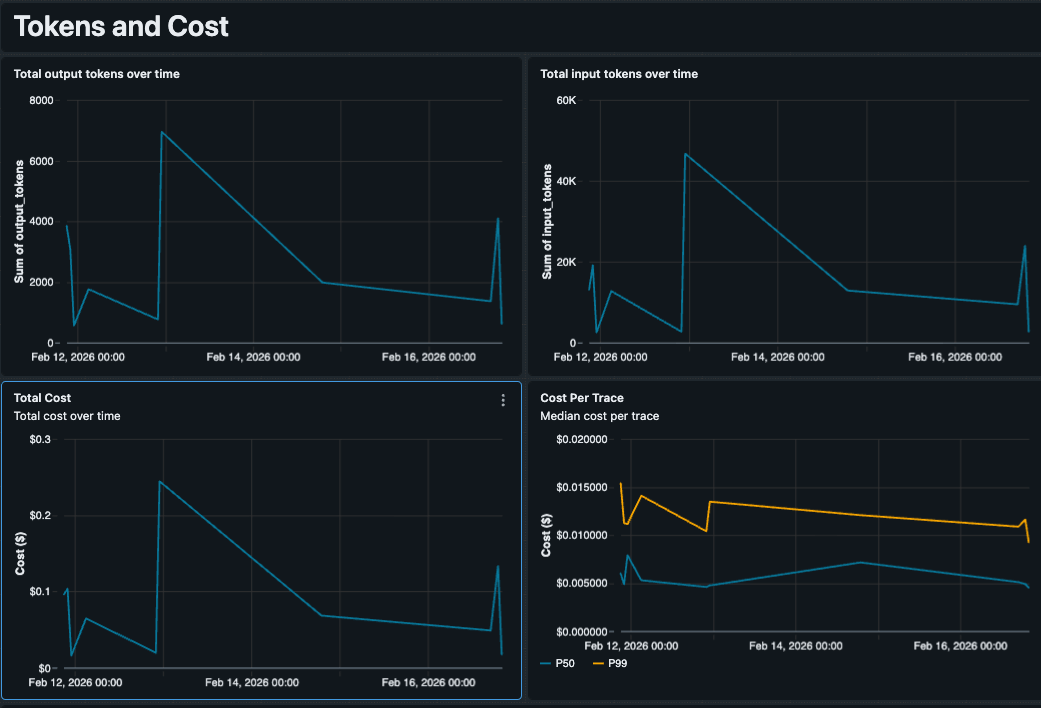
Análise de Custo Personalizada com Preços Contratuais
As métricas de custo nativas dependem de preços de tabela padrão, que podem não ser precisos para equipes que negociaram tarifas ou executam modelos ajustados com preços diferentes. Como controlamos o SQL, incorporamos nossa lógica de precificação diretamente na consulta. O dashboard rastreia o uso de tokens por tipo de modelo (por exemplo, GPT 5.5 vs. Claude 4.6 Sonnet) e aplica nossas taxas contratuais para produzir um Custo Estimado por Rastreamento que reflete o que realmente pagamos. Isso facilita a identificação de anomalias caras, como uma única consulta complexa que custa US$ 0,50 devido a um loop de recuperação.
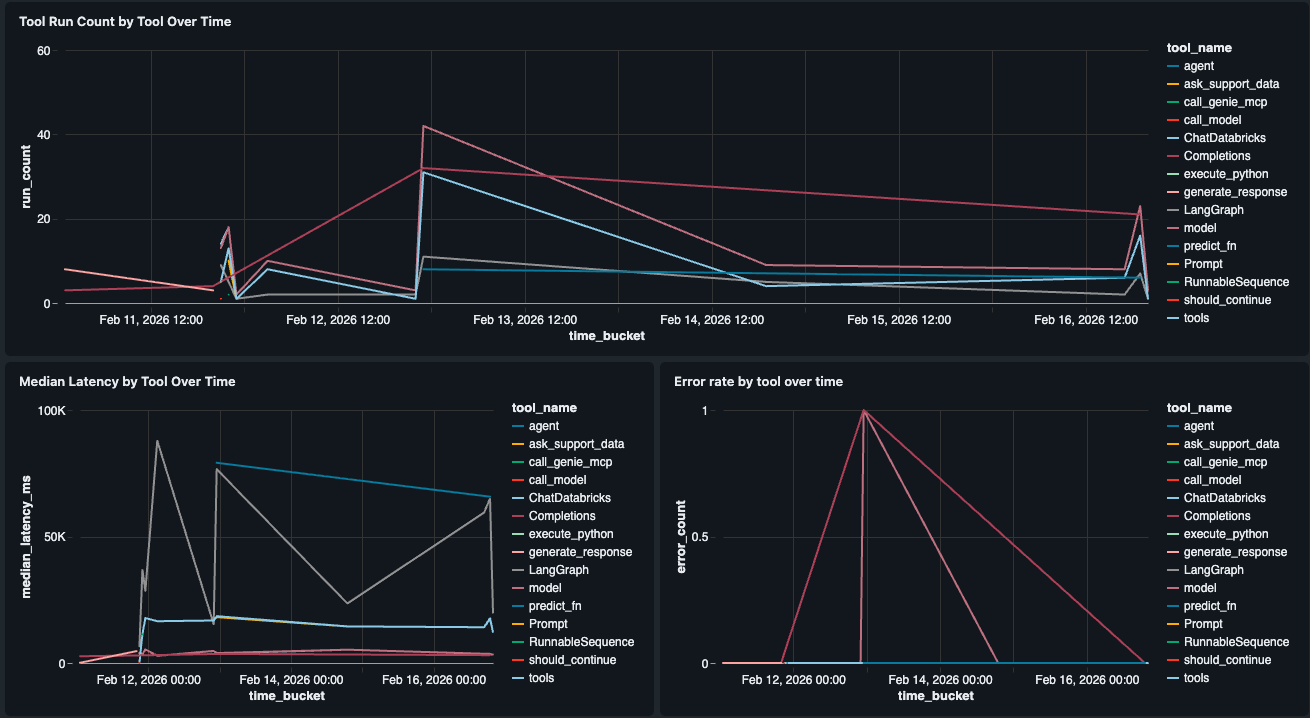
Desempenho em Nível de Componente
As visualizações de latência nativas mostram P50/P99 no nível do rastreamento. Para ir uma camada mais profunda e ver qual ferramenta está lenta, construímos um widget de Desempenho da Ferramenta que detalha a latência (P50, P99) e as taxas de erro por ferramenta individual no agente (por exemplo, retrieve_docs vs. generate_response). Isso nos diz se o LLM, uma chamada de ferramenta Genie ou outra etapa é o gargalo, para que possamos identificar exatamente onde a experiência do usuário está se degradando.
Espaços Genie
Tanto as partes interessadas de negócios quanto as técnicas frequentemente desejam explorar o comportamento do agente sem escrever SQL. Ao expor as tabelas de rastreamento através do Genie, as equipes podem habilitar a análise em linguagem natural sobre seus dados de telemetria, permitindo que os usuários façam perguntas diretamente sobre desempenho, uso de ferramentas, latência e comportamento do modelo. Em nosso exemplo, isso poderia incluir perguntas como:
- Que tipos de requisições exigem escalonamento?
- As tentativas de ferramenta estão aumentando?
- Quais consultas acionam os caminhos de execução mais complexos?
Pipelines ETL
Como os rastreamentos são armazenados como tabelas Delta, eles podem alimentar pipelines ETL downstream como qualquer outro conjunto de dados. Ao habilitar o Change Data Feed (CDF), as equipes podem processar dados de rastreamento incrementalmente, seja em lote ou em streaming, sem escanear repetidamente tabelas inteiras.
Isso torna possível operacionalizar a observabilidade. Por exemplo, um pipeline poderia monitorar padrões de rastreamento e acionar alertas quando a latência excede limites definidos, falhas de ferramentas aumentam ou o uso de tokens se desvia das linhas de base esperadas. Esses sinais podem então alimentar dashboards, sistemas de notificação ou fluxos de trabalho de remediação automatizados.
É importante ressaltar que isso complementa proteções em tempo real, como AI Guardrails. Enquanto os guardrails impõem políticas no momento da requisição, os pipelines ETL criam um loop de feedback, ajudando as equipes a analisar tendências, refinar políticas e melhorar continuamente o desempenho do agente.
Fechando o Ciclo: De Rastreamentos de Produção à Avaliação
Uma vez que os rastreamentos estão disponíveis, eles podem alimentar todo o evaluation stack do MLflow, permitindo que as equipes meçam, melhorem e mantenham a qualidade de suas aplicações GenAI em todo o ciclo de vida. A avaliação e o monitoramento se baseiam diretamente no rastreamento, permitindo que a mesma telemetria capturada durante o desenvolvimento, teste e produção seja pontuada usando LLM judges e métricas personalizadas.
Avaliar durante o desenvolvimento
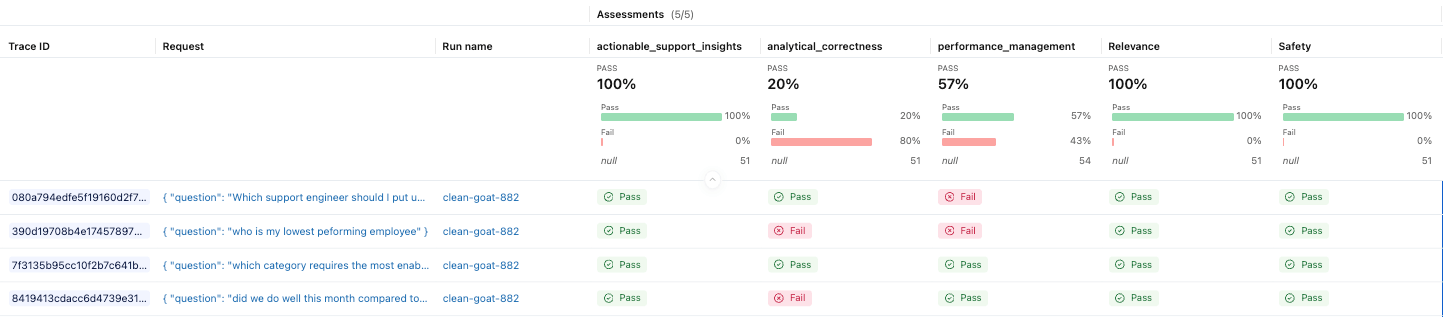
O MLflow nos permite executar avaliações em relação a um conjunto de dados de avaliação, aplicando juízes integrados ou personalizados para pontuar a qualidade da resposta. Uma abordagem eficaz é inicializar este conjunto de dados a partir de rastreamentos reais. Como esses prompts se originam de interações reais do usuário, eles representam melhor os cenários que seu agente deve lidar em comparação com casos de teste puramente sintéticos.
Abaixo, criamos um conjunto de dados de avaliação a partir de rastreamentos recentemente capturados. O MLflow usa um SQL warehouse para pesquisar e materializar registros de conjuntos de dados, portanto, certifique-se de configurar o ID do warehouse em seu ambiente.
Com o conjunto de dados pronto, podemos definir os avaliadores que pontuarão nossa aplicação. MLflow oferece um conjunto de avaliadores integrados e também nos permite definir diretrizes personalizadas adaptadas ao comportamento esperado do nosso agente.
E agora podemos ver os resultados no experimento do MLflow.
Monitoramento em produção
As avaliações de desenvolvimento nos ajudam a validar o comportamento antes do lançamento, mas o monitoramento em produção nos mostra como a aplicação se comporta com usuários reais. MLflow pode avaliar automaticamente rastreamentos em tempo real usando os mesmos avaliadores, ajudando-nos a detectar rapidamente regressões, desvios e padrões de falha emergentes. Isso transforma a avaliação de uma tarefa única em uma prática contínua à medida que a aplicação evolui.
Clientes Usando Observabilidade de IA no Databricks
Experian
A transição para o rastreamento do MLflow para nossa assistente virtual Eva e o sistema de e-mail automatizado Latte foi perfeita. Com os Traces no Unity Catalog, nossa equipe de ciência de dados executa centenas de milhares de rastreamentos por meio de tabelas Delta governadas e avalia a qualidade do agente em escala — tudo sem sair do Databricks. À medida que incorporamos fluxos de trabalho de avaliação mais sérios, ter rastreamento e avaliações em uma plataforma governada significa que não estamos mantendo ferramentas separadas para cada estágio do ciclo de vida do agente.—James Lin, Líder de Inovação em IA/ML, Experian
Superhuman (Grammarly)
Estamos padronizando o rastreamento do MLflow como a camada de observabilidade para todos os nossos agentes de IA na Superhuman. Preferimos a integração mais ampla da plataforma em vez de construir e manter uma solução personalizada ou pontual — essa carga de manutenção era um verdadeiro ponto problemático para nossas equipes. Com os Traces do MLflow no Unity Catalog, podemos escalar para centenas de milhares de rastreamentos por dia, e nossos pesquisadores podem se autoatender e explorar o comportamento do agente diretamente na interface do usuário do MLflow sem suporte de engenharia. Ter rastreamento, avaliação e monitoramento tudo em uma plataforma governada é exatamente o que precisávamos para mover nossos agentes para produção com confiança.—Martin Jewell, Líder de Infraestrutura de IA MLE, Superhuman
SmartSheet
Escolhemos o Databricks como nossa plataforma para GenAI, e o MLflow é como nossa equipe constrói e avalia agentes de IA. Durante uma co-construção de três dias com o Databricks, implementamos dois agentes de produção usando rastreamento do MLflow, avaliações, avaliadores personalizados e rotulagem — e com os rastreamentos armazenados no Unity Catalog, podemos executar dezenas de milhares de avaliações e iterar na qualidade com confiança à medida que escalamos.—Kapil Ashar, VP de Engenharia, Smartsheet
The Standard
The Standard ajuda nossos clientes a alcançar bem-estar financeiro e tranquilidade. Dados e IA são fundamentais para entregar essa experiência em escala. Ao incorporar a funcionalidade de agente de IA — como a extração de informações-chave de documentos de subscrição de entrada e envios de sinistros — em funções de negócios importantes, somos capazes de fornecer um serviço excepcional aos nossos clientes e parceiros. Com o rastreamento e monitoramento em produção, nossas equipes podem entender rapidamente como os sistemas se comportam e fazer atualizações confiáveis. Ao governar os rastreamentos no Unity Catalog juntamente com o restante de nossos dados na Databricks Data Intelligence Platform, podemos consultar, monitorar e iterar com segurança — sem adicionar complexidade desnecessária.—Porter Orr, AVP de IA e Automação, The Standard
Perguntas Frequentes (FAQ)
P: Posso usar isso para agentes executando fora do Databricks?
R: Sim, o agente pode estar executando em qualquer lugar. Na verdade, o exemplo de agente assistente de suporte usado para este blog é implantado localmente.
P: Quais são os limites de throughput e armazenamento desta solução?
R: O limite de throughput de ingestão começa em 200 QPS. Não há limite de armazenamento. Limites anteriores de rastreamentos por experimento não são mais aplicáveis. Se precisar de limites de throughput mais altos, entre em contato com sua equipe de contas do Databricks.
P: O que posso fazer para garantir que minhas consultas de pesquisa, a experiência do experimento MLflow e as análises downstream permaneçam performáticas?
R: Com a atualização mais recente do produto, as tabelas são automaticamente agrupadas por liquidez para manter os dados organizados de forma otimizada. Para volumes maiores de rastreamento, no entanto, você deve criar uma view materializada sobre as views derivadas e atualizá-la incrementalmente para manter o desempenho da consulta.
P: Como isso lida com PII encontrado em prompts de usuário?
R: Este recurso não aplica nenhum tratamento especial a PII. No entanto, os dados são armazenados no Unity Catalog, onde você pode aproveitar os recursos de governança, como controles de acesso refinados, mascaramento de coluna e filtragem de linha, para gerenciar e restringir o acesso downstream.
Comece agora
Para começar, siga a documentação.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.