Otimizando Recálculos de Visualizações Materializadas
- Como detectar e monitorar o comportamento de atualização de visualizações materializadas (MV) em Pipelines Declarativos Lakeflow
- Causas comuns de recomputações completas desnecessárias em MVs
- Melhores práticas para otimizar atualizações incrementais e gerenciar recomputações completas para melhorar o desempenho e controlar os custos
Otimizar o Cálculo Incremental de Visualizações Materializadas
Embora as empresas nativas digitais reconheçam o papel crítico que a IA desempenha na promoção da inovação, muitas ainda enfrentam desafios para tornar suas pipelines ETL operacionalmente eficientes.
Visões Materializadas (MVs) existem para armazenar resultados de consultas pré-calculadas como tabelas gerenciadas, permitindo que os usuários acessem dados complexos ou frequentemente usados muito mais rápido, evitando a repetição do cálculo das mesmas consultas. As MVs melhoram o desempenho da consulta, reduzem os custos computacionais e simplificam os processos de transformação.
Lakeflow Declarative Pipelines (LDP) oferece uma abordagem declarativa e direta para a construção de pipelines de dados, suportando tanto atualizações completas quanto incrementais para MV. Os pipelines do Databricks são alimentados pelo motor Enzyme, que mantém as MVs atualizadas de forma eficiente, rastreando como os novos dados afetam os resultados da consulta e atualizando apenas o que é necessário. Ele utiliza um modelo de custo interno para selecionar entre várias técnicas, incluindo aquelas empregadas em visualizações materializadas e padrões ETL manuais comumente usados.
Este blog discutirá a detecção de recomputações completas inesperadas e a otimização de pipelines para atualizações incrementais adequadas de MV.
Considerações Arquitetônicas Chave
Cenários para Atualizações Incrementais & Completas
Um reprocessamento completo sobrescreve os resultados na MV ao reprocessar todos os dados disponíveis da fonte. Isso pode se tornar caro e demorado, pois requer o reprocessamento do conjunto de dados subjacente inteiro, mesmo que apenas uma pequena parte tenha mudado.
Embora a atualização incremental seja geralmente preferida por sua eficiência, existem situações em que uma atualização completa é mais apropriada. Nosso modelo de custo segue estas diretrizes de alto nível:
- Use uma atualização completa quando houver mudanças significativas nos dados subjacentes, especialmente se registros foram excluídos ou modificados de maneiras que o modelo de custo pode calcular e aplicar a mudança incremental de forma eficiente.
- Use uma atualização incremental quando as alterações são relativamente pequenas e as tabelas de origem são frequentemente atualizadas—essa abordagem ajuda a reduzir os custos de computação.
Enzyme Compute Engine
Em vez de reprocessar tabelas ou visualizações inteiras do zero toda vez que novos dados chegam ou ocorrem mudanças, o Enzyme determina e processa de maneira inteligente apenas os novos dados ou os dados alterados. Esta abordagem reduz drasticamente o consumo de recursos e a latência em comparação com os métodos tradicionais de ETL em lote.
O diagrama abaixo mostra como o motor Enzyme determina de maneira inteligente a maneira ideal de atualizar uma visualização materializada.
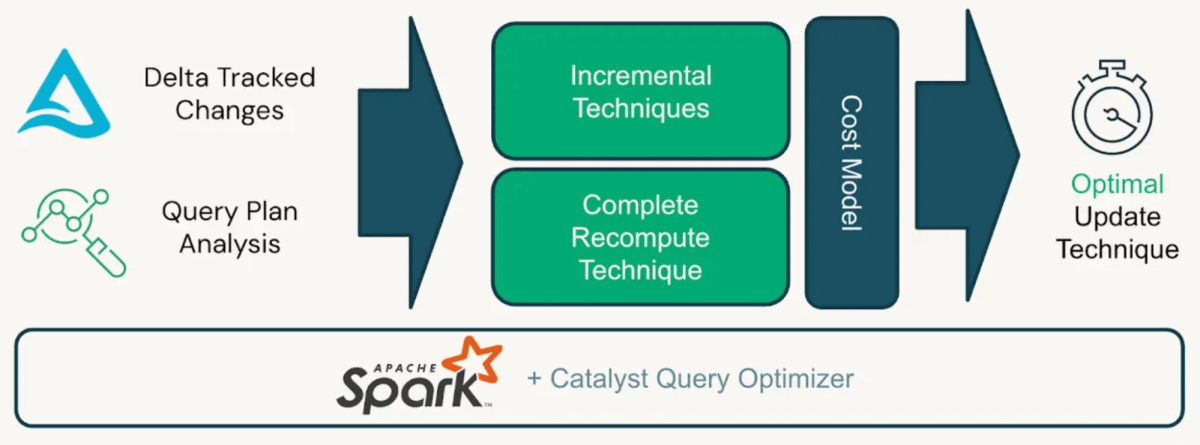
O motor Enzyme seleciona a estratégia de atualização e determina se deve realizar uma atualização incremental ou completa com base em seu modelo de custo interno, otimizando para desempenho e eficiência de computação.
Ativar Recursos da Tabela Delta
Habilitar rastreamento de linhas nas tabelas de origem é necessário para incrementar o re-cálculo da MV.
O rastreamento de linhas ajuda a detectar quais linhas foram alteradas desde a última atualização da MV. Isso permite que o Databricks rastreie a linhagem de nível de linha em uma tabela Delta e é necessário para atualizações incrementais específicas em visualizações materializadas.
Habilitar vetores de exclusão é um recurso opcional. Vetores de exclusão permitem que o Databricks rastreie quais linhas foram excluídas da tabela de origem. Isso evita a necessidade de reescrever arquivos completos e evita reescrever arquivos inteiros quando apenas algumas linhas são excluídas.
Para habilitar esses recursos de tabela na tabela de origem, aproveite o seguinte código SQL:
Descrição Técnica da Solução
A próxima seção explicará um exemplo de como detectar quando um pipeline aciona um reprocessamento completo versus uma atualização incremental em um MV e como incentivar uma atualização incremental.
Este tutorial técnico segue estas etapas de alto nível:
- Gere uma tabela Delta com dados gerados aleatoriamente
- Crie e use um LDP para criar uma visualização materializada
- Adicione uma função não determinística à visão materializada
- Execute novamente a pipeline e observe o impacto no comportamento de atualização
- Atualize o pipeline para restaurar a atualização incremental
- Consulte o log de eventos do pipeline para inspecionar a técnica de atualização
Para acompanhar este exemplo, clone este script: MV_Incremental_Technical_Breakdown.ipynb
Dentro da função run_mv_refresh_demo(), o primeiro passo gera uma tabela Delta com dados gerados aleatoriamente:
Em seguida, a seguinte função é executada para inserir dados gerados aleatoriamente. Isso é executado antes de cada nova execução de pipeline para garantir que novos registros estejam disponíveis para agregação.
Em seguida, o SDK Databricks é usado para criar e implantar o LDP.
As MVs podem ser criadas por meio de um LDP sem servidor ou Databricks SQL (DBSQL) e se comportam da mesma maneira. DBSQL MVs lançam um LDP gerenciado sem servidor que está acoplado à MV internamente. Este exemplo utiliza um LDP sem servidor para utilizar vários recursos, como a publicação do log de eventos, mas se comportaria da mesma maneira se uma MV DBSQL fosse usada.
Uma vez que o pipeline é criado com sucesso, a função executará uma atualização no pipeline:
Depois que o pipeline foi executado com sucesso e criou a visualização materializada inicial, o próximo passo é adicionar mais dados e atualizar a visualização. Após executar o pipeline, verifique o registro de eventos para revisar o comportamento da atualização.
Os resultados mostram que a visualização materializada foi atualizada incrementalmente, indicado pela mensagem GROUP_AGGREGATE:
| Executar # | Mensagem | Tipo de fluxo |
|---|---|---|
| 2 | O fluxo '<catalog_name>.demo.random_data_mv' foi planejado no DLT para ser executado como GROUP_AGGREGATE. | Nenhuma função não determinística. Atualizado incrementalmente. |
| 1 | Fluxo '<catalog_name>.demo.random_data_mv' foi planejado no DLT para ser executado como COMPLETE_RECOMPUTE. | Execução Inicial. Recompute completo |
A seguir, para demonstrar como a adição de uma função não determinística (RANDOM()) pode impedir que a visualização materializada seja atualizada incrementalmente, a MV é atualizada para o seguinte:
Para contabilizar as alterações na MV e demonstrar a função não determinística, o pipeline é executado duas vezes e os dados são adicionados. O log de eventos é consultado novamente e os resultados mostram um reprocessamento completo.
| Executar # | Mensagem | Explicação |
|---|---|---|
| 4 | Fluxo 'andrea_tardif.demo.random_data_mv' foi planejado no DLT para ser executado como RECALCULO_COMPLETO. | MV inclui não determinístico — recomputação completa acionada. |
| 3 | Fluxo '<catalog_name>.demo.random_data_mv' foi planejado no DLT para ser executado como COMPLETE_RECOMPUTE. | Definição de MV alterada — recomputação total acionada. |
| 2 | O fluxo '<catalog_name>.demo.random_data_mv' foi planejado no DLT para ser executado como GROUP_AGGREGATE. | Atualização incremental — sem funções não determinísticas presentes. |
| 1 | Fluxo '<catalog_name>.demo.random_data_mv' foi planejado no DLT para ser executado como COMPLETE_RECOMPUTE. | Execução inicial — reprocessamento completo necessário. |
Ao adicionar funções não determinísticas, como RANDOM() ou CURRENT_DATE(), a MV não pode ser atualizada incrementalmente porque a saída não pode ser prevista com base apenas nas mudanças nos dados de origem.
Dentro dos detalhes do log de eventos do pipeline, em planning_information, os detalhes do evento JSON fornecem o seguinte motivo para prevenir a incrementalização:
Se a presença de uma função não determinística for necessária para sua análise, uma abordagem melhor é inserir esse valor na própria tabela de origem, em vez de calculá-lo dinamicamente na visualização materializada. Faremos isso movendo a coluna random_number para puxar da tabela de origem em vez de adicioná-la no nível MV.
Abaixo está a consulta atualizada da visualização materializada para referenciar a coluna static random_number dentro da MV:
Uma vez que novos dados são adicionados e o pipeline é executado novamente, consulte o log de eventos. A saída mostra que a MV realizou um GROUP_AGGREGATE em vez de um COMPLETE_RECOMPUTE!
| Executar # | Mensagem | Explicação |
|---|---|---|
| 5 | O fluxo '<catalog_name>.demo.random_data_mv' foi planejado no DLT para ser executado como GROUP_AGGREGATE. | MV usa lógica determinística — atualização incremental. |
| 4 | Fluxo '<catalog_name>.demo.random_data_mv' foi planejado no DLT para ser executado como COMPLETE_RECOMPUTE. | MV inclui não determinístico — recomputação completa acionada. |
| 3 | Fluxo '<catalog_name>.demo.random_data_mv' foi planejado no DLT para ser executado como COMPLETE_RECOMPUTE. | Definição de MV alterada — recomputação total acionada. |
| 2 | O fluxo '<catalog_name>.demo.random_data_mv' foi planejado no DLT para ser executado como GROUP_AGGREGATE. | Atualização incremental — sem funções não determinísticas presentes. |
| 1 | Fluxo '<catalog_name>.demo.random_data_mv' foi planejado no DLT para ser executado como COMPLETE_RECOMPUTE. | Execução inicial — reprocessamento completo necessário. |
Uma atualização completa pode ser automaticamente acionada pela pipeline nas seguintes condições:
- Uso de funções não determinísticas como UUID() e RANDOM()
- Criando visualizações materializadas que envolvem junções complexas, como cruzadas, full outer, semi, anti e um grande número de junções.
- Enzyme determina que é menos dispendioso computacionalmente realizar um reprocessamento completo
Saiba mais sobre funções compatíveis com atualização incremental aqui.
Volume Real de Dados
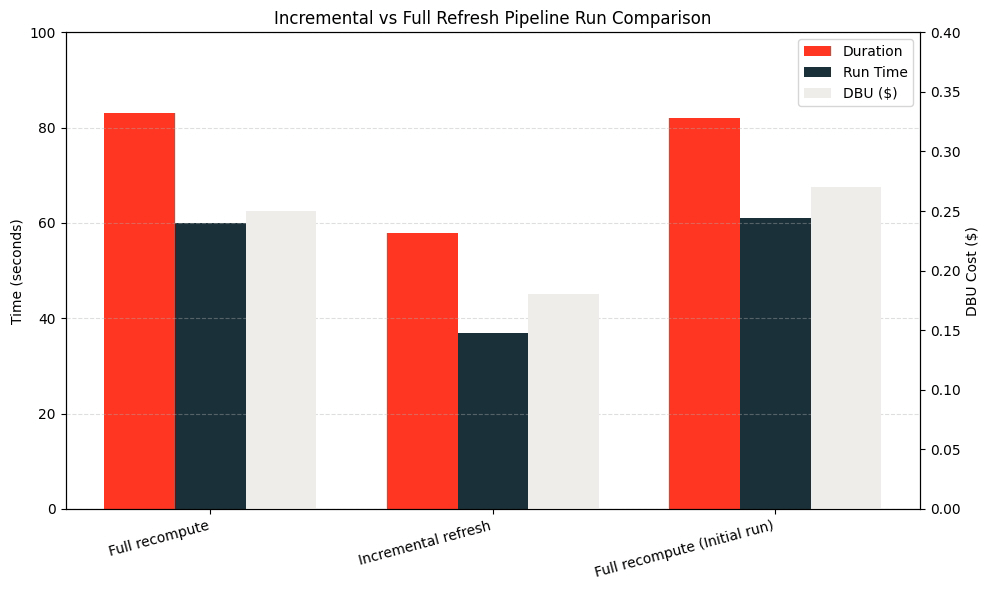
Na maioria dos casos, a ingestão de dados é muito maior do que inserir 5 linhas. Para ilustrar isso, vamos inserir 1 bilhão de linhas no carregamento inicial e depois 10 milhões em cada execução de pipeline.
Usando dbldatagen para gerar dados aleatoriamente e o SDK Databricks para criar e executar um LDP, 1 bilhão de linhas foram inseridas na tabela de origem, e o pipeline foi executado para gerar o MV. Em seguida, 10 milhões de linhas foram adicionadas aos dados de origem, e o MV foi atualizado incrementalmente. Depois disso, o pipeline foi forçado a atualizar para realizar uma recomputação completa.
Uma vez que o pipeline é concluído, use o list_pipeline_events e a tabela do sistema de faturamento, mesclados no dlt_update_id, para determinar o custo por atualização.
Como mostrado no gráfico abaixo, a atualização incremental foi duas vezes mais rápida e mais barata do que a atualização completa!
Considerações Operacionais
Práticas fortes de monitoramento, observabilidade e automação são cruciais para aproveitar totalmente os benefícios das atualizações incrementais em pipelines declarativos. A seção a seguir descreve como aproveitar as capacidades de monitoramento do Databricks para rastrear atualizações de pipeline e custos.
Monitorando Atualizações de Pipeline
Ferramentas como o registro de eventos e a interface do LDP UI fornecem visibilidade sobre os padrões de execução do pipeline, ajudando a detectar quando ocorrem várias atualizações.
Incluímos uma ferramenta aceleradora para ajudar as equipes a rastrear e analisar o comportamento de atualização da visão materializada. Esta solução aproveita os painéis de AI/BI para fornecer visibilidade sobre os padrões de atualização. Ele usa o SDK Databricks para recuperar todos os pipelines em seu espaço de trabalho configurado, coletar detalhes de eventos para os pipelines e, em seguida, produzir um painel semelhante ao abaixo.
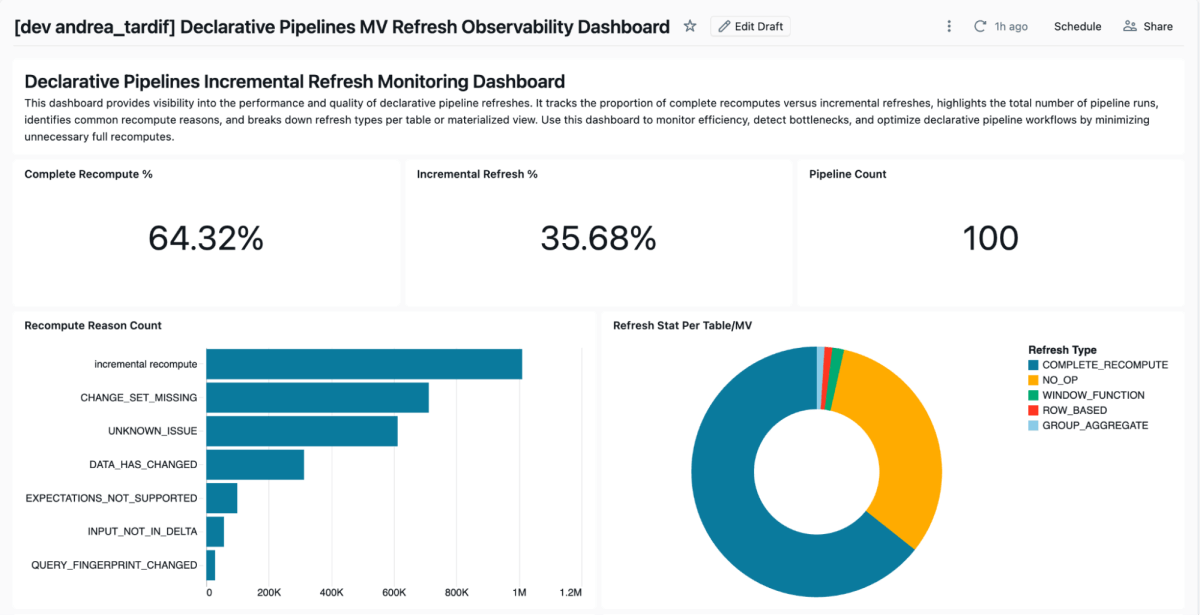
Link do Github: monitoring-declarative-pipeline-refresh-behavior
Principais Conclusões
Incrementalizar as atualizações da visualização materializada permite que o Databricks processe apenas dados novos ou alterados nas tabelas de origem, melhorando o desempenho e reduzindo os custos.
Com MVs, evite usar funções não determinísticas (ou seja, CURRENT_DATE() e RANDOM()) e limite a complexidade da consulta (ou seja, junções excessivas) para permitir atualizações incrementais eficientes. Ignorar recomputações completas inesperadas em MVs que poderiam ser refatoradas para serem recomputações incrementais pode levar a:
- Aumento dos custos de computação
- Menor atualização de dados para aplicações downstream
- Gargalos do pipeline à medida que o volume de dados aumenta
Com o cálculo sem servidor, os LDPs aproveitam o modelo de execução integrado, permitindo que o Enzyme realize um re-cálculo incremental ou completo com base no custo total de cálculo da pipeline.
Aproveite a ferramenta de aceleração para monitorar o comportamento de todos os seus pipelines em um painel de AI/BI para detectar reprocessamentos completos inesperados.
Em conclusão, para criar atualizações de visualização materializada eficientes, siga estas melhores práticas:
- Use lógica determinística quando aplicável.
- Refatore consultas para evitar funções não determinísticas
- Simplifique a lógica de junção
- Ative o rastreamento de linhas nas tabelas de origem
Próximos Passos & Recursos Adicionais
Reveja seus tipos de atualização de MV hoje!
Databricks Arquitetos de Soluções de Entrega (DSAs) aceleram iniciativas de Dados e IA em organizações. Eles fornecem liderança arquitetônica, otimizam plataformas para custo e desempenho, melhoram a experiência do desenvolvedor e conduzem a execução bem-sucedida do projeto. As DSAs preenchem a lacuna entre a implantação inicial e as soluções de produção, trabalhando de perto com várias equipes, incluindo engenharia de dados, líderes técnicos, executivos e outros stakeholders para garantir soluções personalizadas e um tempo de valor mais rápido. Para se beneficiar de um plano de execução personalizado, orientação estratégica e suporte ao longo de sua jornada de dados e IA de um DSA, entre em contato com sua Equipe de Conta Databricks.
Mais recursos
- Carregue e processe dados incrementalmente com fluxos de Pipelines Declarativas Lakeflow | Documentação Databricks
- Atualização incremental para visualizações materializadas | Documentação do Databricks
Crie um LDP e revise os tipos de atualização incremental de MV hoje!
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.