O Poder do RLVR: Treinando um Modelo de Raciocínio SQL Líder no Databricks
Uma receita simples para raciocínio empresarial
Na Databricks, usamos aprendizado por reforço (RL) para desenvolver modelos de raciocínio para problemas que nossos clientes enfrentam, bem como para nossos produtos, como o Assistente Databricks e AI/BI Genie. Essas tarefas incluem a geração de código, análise de dados, integração de conhecimento organizacional, avaliação específica do domínio e extração de informações (IE) de documentos. Tarefas como codificação ou extração de informações geralmente têm recompensas verificáveis -- a correção pode ser verificada diretamente (por exemplo, passar em testes, combinar rótulos). Isso permite o aprendizado por reforço sem um modelo de recompensa aprendido, conhecido como RLVR (aprendizado por reforço com recompensas verificáveis). Em outros domínios, um modelo de recompensa personalizado pode ser necessário -- que o Databricks também suporta. Nesta postagem, nos concentramos no cenário RLVR.
Como exemplo do poder do RLVR, aplicamos nossa pilha de treinamento a um benchmark acadêmico popular em ciência de dados chamado BIRD. Este benchmark estuda a tarefa de transformar uma consulta em linguagem natural em um código SQL que é executado em um banco de dados. Este é um problema importante para os usuários do Databricks, permitindo que não especialistas em SQL conversem com seus dados. Também é uma tarefa desafiadora onde até mesmo os melhores LLMs proprietários não funcionam bem de imediato. Embora o BIRD não capture totalmente a complexidade do mundo real desta tarefa nem a amplitude total de produtos reais como o Databricks AI/BI Genie (Figura 1), sua popularidade nos permite medir a eficácia do RLVR para ciência de dados em um benchmark bem compreendido.
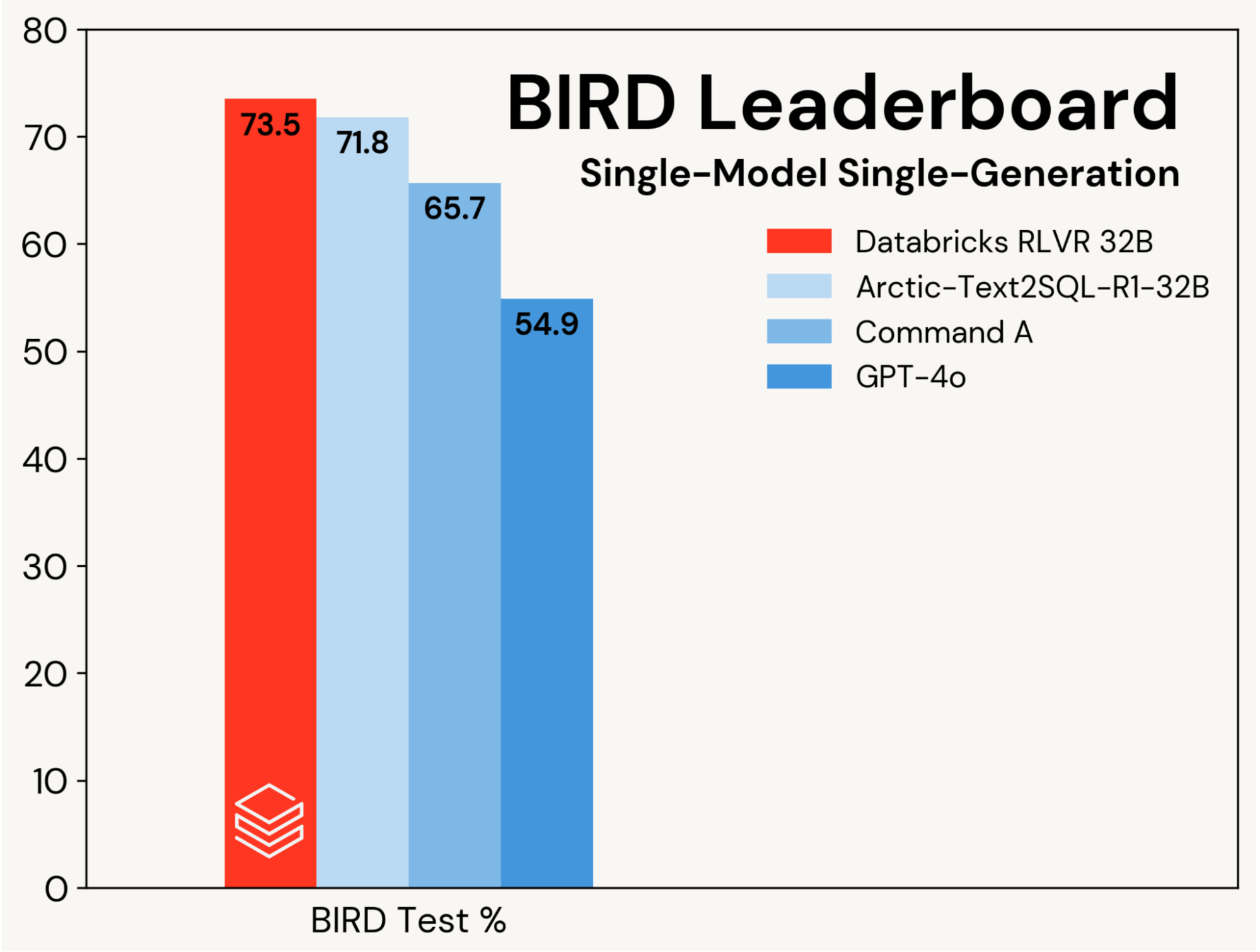
Nos concentramos em melhorar um modelo de codificação SQL base usando RLVR, isolando esses ganhos de melhorias impulsionadas por designs agentivos. O progresso é medido na pista de modelo único, geração única do ranking BIRD (ou seja, sem autoconsistência), que avalia em um conjunto de testes privado.
Estabelecemos uma nova precisão de teste de ponta de 73,5% neste benchmark. Fizemos isso usando nossa pilha RLVR padrão e treinando apenas no conjunto de treinamento BIRD. A melhor pontuação anterior nesta trilha foi de 71,8%[1], alcançada ao aumentar o conjunto de treinamento BIRD com dados adicionais e usando um LLM proprietário (GPT-4o). Nossa pontuação também é 8,7 pontos percentuais melhor do que o modelo base original, e é uma melhoria substancial sobre os LLMs proprietários (veja a Figura 2). Este resultado destaca a simplicidade e generalidade do RLVR: alcançamos essa pontuação com dados prontos para uso e os componentes RL padrão que estamos implementando no Agent Bricks, e fizemos isso em nossa primeira submissão ao BIRD. RLVR é uma linha de base poderosa que os desenvolvedores de IA devem considerar sempre que houver dados de treinamento suficientes disponíveis.
Construímos nossa submissão com base no conjunto de desenvolvimento do BIRD. Descobrimos que Qwen 2.5 32B Coder Instruct foi o melhor ponto de partida. Ajustamos este modelo usando tanto o Databricks TAO – um método RL offline, quanto nossa pilha RLVR. Esta abordagem, juntamente com uma cuidadosa seleção de prompts e modelos, foi suficiente para nos levar ao topo do Benchmark BIRD. Este resultado é uma demonstração pública das mesmas técnicas que estamos usando para melhorar produtos populares da Databricks, como AI/BI Genie e Assistant, e para ajudar nossos clientes a construir agentes usando Agent Bricks.
Nossos resultados destacam o poder do RLVR e a eficácia de nossa pilha de treinamento. Os clientes da Databricks também relataram ótimos resultados usando nossa pilha em seus domínios de raciocínio. Acreditamos que esta receita é poderosa, composta e amplamente aplicável a uma variedade de tarefas. Se você gostaria de visualizar o RLVR na Databricks, entre em contato conosco aqui.
1Veja a Tabela 1 em https://arxiv.org/pdf/2505.20315
Autores: Alnur Ali, Ashutosh Baheti, Jonathan Chang, Ta-Chung Chi, Brandon Cui, Andrew Drozdov, Jonathan Frankle, Abhay Gupta, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Kumar Misra, Jose Javier Gonzalez Ortiz, Krista Opsahl-Ong
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.