As restrições de chave primária e chave estrangeira estão em GA e agora permitem consultas mais rápidas
por Xinyi Yu, Justin Talbot e Serge Rielau
A Databricks tem o prazer de anunciar a Disponibilidade Geral (GA) das restrições de Chave Primária (PK) e Chave Estrangeira (FK), a partir do Databricks Runtime 15.2 e Databricks SQL 2024.30. Este lançamento segue uma prévia pública de grande sucesso, adotada por centenas de clientes ativos semanalmente, e representa um marco significativo no aprimoramento da integridade dos dados e do gerenciamento de dados relacionais dentro do Lakehouse.
Além disso, a Databricks agora pode usar essas restrições para otimizar consultas e eliminar operações desnecessárias do plano de consulta, proporcionando um desempenho muito mais rápido.
Restrições de Chave Primária e Chave Estrangeira
Chaves Primárias (PKs) e Chaves Estrangeiras (FKs) são elementos essenciais em bancos de dados relacionais, atuando como blocos de construção fundamentais para modelagem de dados. Elas fornecem informações sobre os relacionamentos dos dados no esquema para usuários, ferramentas e aplicativos; e permitem otimizações que utilizam restrições para acelerar consultas. Chaves primárias e estrangeiras estão agora geralmente disponíveis para suas tabelas Delta Lake hospedadas no Unity Catalog.
Linguagem SQL
Você pode definir restrições ao criar uma tabela:
No exemplo acima, definimos uma restrição de chave primária na coluna UserID. A Databricks também suporta restrições em grupos de colunas.
Você também pode modificar tabelas Delta existentes para adicionar ou remover restrições:
Aqui criamos a chave primária chamada products_pk na coluna não nula ProductID em uma tabela existente. Para executar esta operação com sucesso, você deve ser o proprietário da tabela. Observe que os nomes das restrições devem ser únicos dentro do esquema.
O comando subsequente remove a chave primária especificando o nome.
O mesmo processo se aplica às chaves estrangeiras. A tabela a seguir define duas chaves estrangeiras no momento da criação da tabela:
Consulte a documentação sobre as instruções CREATE TABLE e ALTER TABLE para mais detalhes sobre a sintaxe e operações relacionadas a restrições.
Restrições de chave primária e chave estrangeira não são aplicadas no motor Databricks, mas podem ser úteis para indicar um relacionamento de integridade de dados que se pretende que seja verdadeiro. A Databricks pode, em vez disso, aplicar restrições de chave primária a montante como parte do pipeline de ingestão. Veja Gerenciar qualidade de dados com Delta Live Tables para mais informações sobre restrições aplicadas. A Databricks também suporta restrições aplicadas NOT NULL e CHECK (veja a documentação de Restrições para mais informações).
Ecossistema de Parceiros
Ferramentas e aplicativos como as versões mais recentes do Tableau e PowerBI podem importar e utilizar automaticamente seus relacionamentos de chave primária e chave estrangeira da Databricks por meio de conectores JDBC e ODBC.
Visualizar as restrições
Existem várias maneiras de visualizar as restrições de chave primária e chave estrangeira definidas na tabela. Você também pode simplesmente usar comandos SQL para visualizar informações de restrição com o comando DESCRIBE TABLE EXTENDED:
Catalog Explorer e Diagrama de Entidade-Relacionamento
Você também pode visualizar as informações de restrições através do Catalog Explorer:
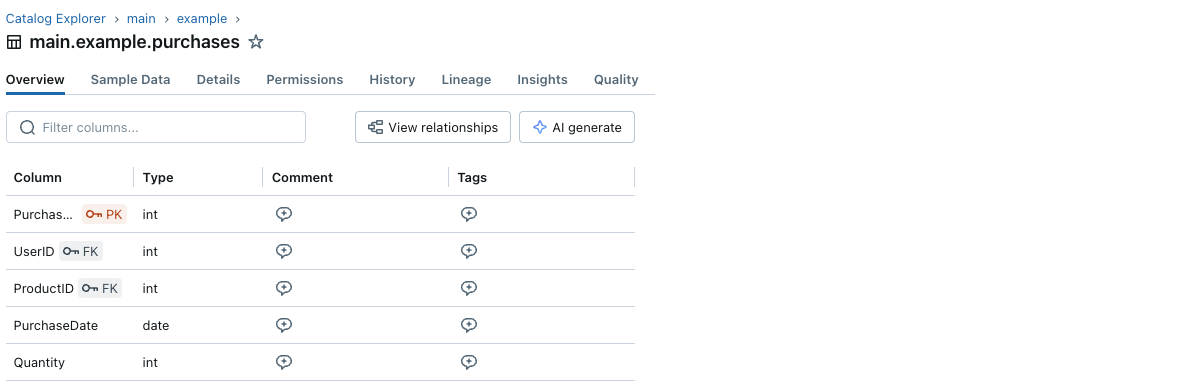
Cada coluna de chave primária e chave estrangeira tem um pequeno ícone de chave ao lado de seu nome.
E você pode visualizar as informações de chave primária e estrangeira e os relacionamentos entre tabelas com o Diagrama de Entidade-Relacionamento no Catalog Explorer. Abaixo está um exemplo de uma tabela purchases referenciando duas tabelas, users e products:

INFORMATION SCHEMA
As seguintes tabelas INFORMATION_SCHEMA também fornecem informações de restrição:
TABLE_CONSTRAINTS: Descreve metadados para todas as restrições de chave primária e estrangeira dentro do catálogo.KEY_COLUMN_USAGE: Lista as colunas das restrições de chave primária ou estrangeira dentro do catálogo.CONSTRAINT_TABLE_USAGE: Descreve as restrições que referenciam tabelas no catálogo.CONSTRAINT_COLUMN_USAGE: Descreve as restrições que referenciam colunas no catálogo.REFERENTIAL_CONSTRAINTS: Descreve restrições referenciais (chaves estrangeiras) definidas no catálogo.
Use a opção RELY para habilitar otimizações
Se você sabe que a restrição de chave primária é válida (por exemplo, porque seu pipeline de dados ou job ETL a aplica), então você pode habilitar otimizações baseadas na restrição especificando-a com a opção RELY, como:
Usar a opção RELY permite que a Databricks otimize consultas de maneiras que dependem da validade da restrição, pois você está garantindo que a integridade dos dados é mantida. Tenha cuidado aqui, pois se uma restrição for marcada como RELY, mas os dados violarem a restrição, suas consultas podem retornar resultados incorretos.
Quando você não especifica a opção RELY para uma restrição, o padrão é NORELY, caso em que as restrições ainda podem ser usadas para fins informativos ou estatísticos, mas as consultas não dependerão delas para serem executadas corretamente.
A opção RELY e as otimizações que a utilizam estão atualmente disponíveis para chaves primárias e também estarão disponíveis em breve para chaves estrangeiras.
Você pode modificar a chave primária de uma tabela para alterar se ela é RELY ou NORELY usando ALTER TABLE, por exemplo:
Acelere suas consultas eliminando agregações desnecessárias
Uma otimização simples que podemos fazer com restrições de chave primária RELY é eliminar agregações desnecessárias. Por exemplo, em uma consulta que aplica uma operação distinct sobre uma tabela com uma chave primária usando RELY:
Podemos remover a operação DISTINCT desnecessária:
Como você pode ver, esta consulta depende da validade da restrição de chave primária RELY - se houver IDs de cliente duplicados na tabela de clientes, a consulta transformada retornará resultados duplicados incorretos. Você é responsável por aplicar a validade da restrição se definir a opção RELY.
Se a chave primária for NORELY (o padrão), o otimizador não removerá a operação DISTINCT da consulta. Assim, ela pode rodar mais devagar, mas sempre retorna resultados corretos, mesmo com duplicatas. Se a chave primária for RELY, o Databricks pode remover a operação DISTINCT, o que pode acelerar muito a consulta - cerca de 2x para o exemplo acima.
Acelere suas consultas eliminando junções desnecessárias
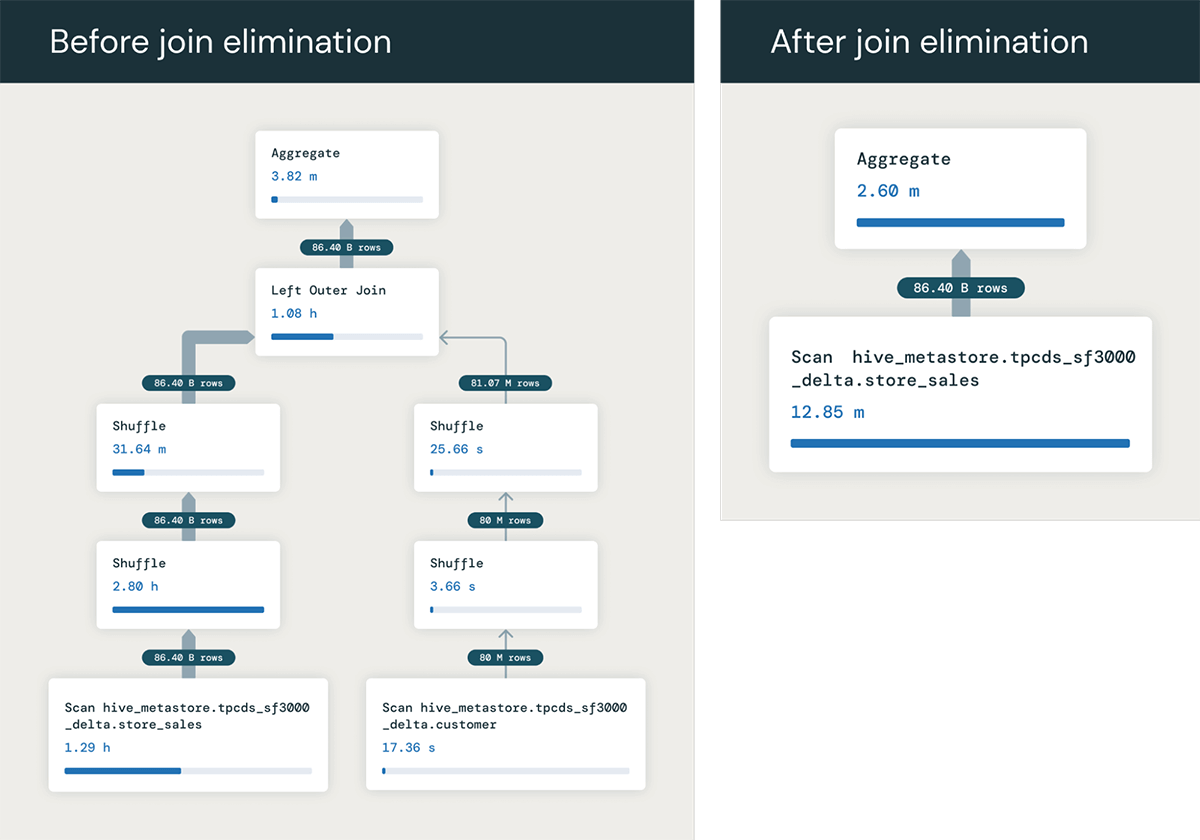
Outra otimização muito útil que podemos realizar com chaves primárias RELY é eliminar junções desnecessárias. Se uma consulta junta uma tabela que não é referenciada em nenhum lugar, exceto na condição de junção, o otimizador pode determinar que a junção é desnecessária e removê-la do plano de consulta.
Para dar um exemplo, digamos que temos uma consulta juntando duas tabelas, store_sales e customer, unidas pela chave primária da tabela de clientes PRIMARY KEY (c_customer_sk) RELY.
Se não tivéssemos a chave primária, cada linha de store_sales poderia corresponder a várias linhas em customer, e precisaríamos executar a junção para calcular o valor SUM correto. Mas como a tabela customer é unida por sua chave primária, sabemos que a junção retornará uma linha para cada linha de store_sales.
Portanto, a consulta na verdade só precisa da coluna ss_quantity da tabela de fatos store_sales. Assim, o otimizador de consulta pode eliminar completamente a junção da consulta, transformando-a em:
Isso roda muito mais rápido, evitando toda a junção - neste exemplo, observamos a otimização acelerar a consulta de 1,5 minuto para 6 segundos!. E os benefícios podem ser ainda maiores quando a junção envolve muitas tabelas que podem ser eliminadas!
Você pode perguntar: por que alguém executaria uma consulta como essa? Na verdade, é muito mais comum do que você imagina! Uma razão comum é que os usuários criam visualizações (views) que juntam várias tabelas, como unir muitas tabelas de fatos e dimensões. Eles escrevem consultas sobre essas visualizações que frequentemente usam colunas de apenas algumas das tabelas, não de todas - e assim o otimizador pode eliminar as junções com as tabelas que não são necessárias em cada consulta. Esse padrão também é comum em muitas ferramentas de Business Intelligence (BI), que frequentemente geram consultas juntando muitas tabelas em um esquema, mesmo quando uma consulta usa colunas de apenas algumas das tabelas.
Conclusão
Desde sua pré-visualização pública, mais de 2600 clientes Databricks usaram restrições de chave primária e chave estrangeira. Hoje, temos o prazer de anunciar a disponibilidade geral deste recurso, marcando uma nova etapa em nosso compromisso de aprimorar o gerenciamento e a integridade de dados no Databricks.
Além disso, o Databricks agora aproveita as restrições de chave com a opção RELY para otimizar consultas, como eliminando agregações e junções desnecessárias, resultando em um desempenho de consulta muito mais rápido.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.