Plotagem Nativa PySpark
Crie visualizações diretamente de DataFrames PySpark com facilidade
por Xinrong Meng e Ruifeng Zheng
- Introdução à Plotagem Nativa PySpark: Este blog explica a necessidade de capacidades de visualização integradas no PySpark, alinhando-se com a funcionalidade que os usuários esperam da API Pandas no Spark e dos DataFrames pandas nativos.
- Principais Recursos e Capacidades: Explicamos vários tipos de gráficos suportados, como a plotagem PySpark aproveita estratégias eficientes de processamento de dados (por exemplo, amostragem, métricas globais) e integração com o Plotly para visualizações.
- Exemplo Prático: Demonstramos a plotagem PySpark com um exemplo prático, orientando os leitores na criação e personalização de visualizações e destacando insights acionáveis derivados dos gráficos.
Introdução
Estamos entusiasmados em apresentar a plotagem nativa no PySpark com o Databricks Runtime 17.0 (notas de lançamento), um avanço empolgante para a visualização de dados. Chega de alternar entre ferramentas apenas para visualizar seus dados; agora, você pode criar gráficos bonitos e intuitivos diretamente dos seus DataFrames PySpark. É rápido, perfeito e integrado. Este recurso tão esperado torna a exploração de seus dados mais fácil e poderosa do que nunca.
Trabalhar com big data no PySpark sempre foi poderoso, especialmente quando se trata de transformar e analisar conjuntos de dados em grande escala. Embora os DataFrames do PySpark sejam construídos para escala e desempenho, os usuários anteriormente precisavam convertê-los em DataFrames da Pandas API no Apache Spark™ para gerar gráficos. Mas este passo extra tornava os fluxos de trabalho de visualização mais complicados do que precisavam ser. A diferença na estrutura entre PySpark e DataFrames estilo pandas muitas vezes levava a atritos, retardando o processo de exploração de dados visualmente.
Exemplo
Aqui está um exemplo de uso do PySpark Plotting para analisar Vendas, Lucro e Margens de Lucro em várias categorias de produtos.
Começamos com um DataFrame contendo dados de vendas e lucro para diferentes categorias de produtos, conforme mostrado abaixo:
Nosso objetivo é visualizar a relação entre Vendas e Lucro, enquanto também incorporamos a Margem de Lucro como uma dimensão visual adicional para tornar a análise mais significativa. Aqui está o código para criar o gráfico:
Note que “fig” é do tipo “plotly.graph_objs._figure.Figure”. Podemos melhorar sua aparência atualizando o layout usando as funcionalidades existentes do Plotly. A figura ajustada se parece com isso:
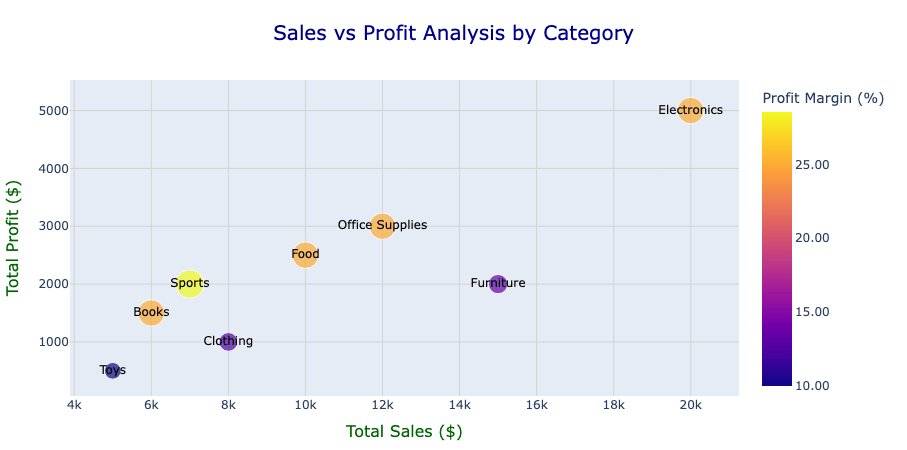
A partir da figura, podemos observar relações claras entre vendas e lucros em diferentes categorias. Por exemplo, Eletrônicos mostra altas vendas e lucros com uma margem de lucro relativamente moderada, indicando forte geração de receita, mas espaço para melhorar a eficiência.
Recursos do PySpark Plotting
Interface do Usuário
O usuário interage com o PySpark Plotting chamando a propriedade plot em um DataFrame do PySpark e especificando o tipo desejado de gráfico, seja como um submétodo ou definindo o parâmetro "kind". Por exemplo:
ou equivalentemente:
Este design está alinhado com as interfaces da API Pandas no Apache Spark e pandas nativo, proporcionando uma experiência consistente e intuitiva para os usuários já familiarizados com a plotagem do pandas.
Tipos de Gráficos Suportados
A plotagem PySpark suporta uma variedade de tipos de gráficos comuns, como linha, barra (incluindo horizontal), área, dispersão, pizza, caixa, histograma e gráficos de densidade/KDE. Isso permite aos usuários visualizar tendências, distribuições, comparações e relações diretamente dos DataFrames PySpark.
Interno
O recurso é alimentado por Plotly (versão 4.8 ou posterior) como o backend de visualização padrão, oferecendo capacidades de plotagem ricas e interativas, enquanto o pandas nativo é usado internamente para processar dados para a maioria dos gráficos.
Dependendo do tipo de gráfico, o processamento de dados no PySpark Plotting é gerenciado através de uma de três estratégias:
- Top N Linhas: O processo de plotagem usa um número limitado de linhas do DataFrame (padrão: 1000). Isso pode ser configurado usando o "spark.sql.pyspark.plotting.max_rows" opção, tornando-o eficiente para insights rápidos. Isso se aplica a gráficos de barras, gráficos de barras horizontais e gráficos de pizza.
- Amostragem: A amostragem aleatória representa efetivamente a distribuição geral sem processar todo o conjunto de dados. Isso garante escalabilidade mantendo a representatividade. Isso se aplica a gráficos de área, gráficos de linha e gráficos de dispersão.
- Métricas Globais: Para gráficos de caixa, histogramas e gráficos de densidade/KDE, os cálculos são realizados em todo o conjunto de dados. Isso permite uma representação precisa das distribuições de dados, garantindo a correção estatística.
Esta abordagem respeita as estratégias de plotagem da API Pandas no Apache Spark para cada tipo de gráfico, com melhorias adicionais de desempenho:
- Amostragem: Anteriormente, eram necessárias duas passagens por todo o conjunto de dados - uma para calcular a taxa de amostragem e outra para realizar a amostragem real. Implementamos um novo método baseado em amostragem de reservatório, reduzindo-o a uma única passagem.
- Subplots: Para casos em que cada coluna corresponde a um subplot, agora calculamos métricas para todas as colunas juntas, melhorando a eficiência.
- Gráficos baseados em ML: Introduzimos expressões SQL internas dedicadas para esses gráficos, permitindo otimizações do lado SQL, como a geração de código.
Conclusão
A Plotagem Nativa PySpark preenche a lacuna entre PySpark e a visualização intuitiva de dados. Este recurso capacita os usuários do PySpark a criar gráficos de alta qualidade diretamente de seus DataFrames do PySpark, tornando a análise de dados mais rápida e acessível do que nunca. Sinta-se à vontade para experimentar este recurso no Databricks Runtime 17.0 para aprimorar sua experiência de visualização de dados!
Pronto para explorar mais? Confira a documentação da API PySpark para guias detalhados e exemplos.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.