Perfil Unificado UDF PySpark
Otimizando UDFs PySpark com Perfilamento Unificado: Melhor Desempenho e Insights de Memória
por Xinrong Meng e Takuya Ueshin
- Introduzindo o Perfilamento Unificado de UDF PySpark – Aprenda como o perfilamento de desempenho e memória para UDFs no Databricks Runtime 17.0 ajuda a otimizar a execução e o uso de recursos.
- Melhorando o Desempenho e a Depuração – Explore como rastrear chamadas de função, tempo de execução e consumo de memória para identificar gargalos e melhorar a eficiência.
- Substituindo o Perfilamento Legado por uma Abordagem Unificada – Entenda os benefícios do novo perfilamento baseado em SparkSession, sua compatibilidade com Spark Connect e como habilitar, visualizar e gerenciar resultados de perfilamento.
Estamos animados para lançar o Perfilamento Unificado para Funções Definidas pelo Usuário (UDFs) do PySpark como parte do Databricks Runtime 17.0 (notas de lançamento). O Perfilamento Unificado para UDFs do PySpark permite que os desenvolvedores perfilam o desempenho e o uso de memória de suas UDFs do PySpark, incluindo o rastreamento de chamadas de função, tempo de execução, uso de memória e outras métricas. Isso permite que os desenvolvedores PySpark identifiquem e resolvam gargalos facilmente, levando a UDFs mais rápidas e eficientes em termos de recursos.
Os perfis unificados podem ser ativados definindo a Configuração SQL em tempo de execução “spark.sql.pyspark.udf.profiler” para “perf” ou “memory” para habilitar o perfil de desempenho ou de memória, respectivamente, conforme mostrado abaixo.
Substituição para o Perfilamento Legado
O perfilamento legado [1, 2] foi implementado no nível do SparkContext e, portanto, não funcionava com o Spark Connect. O novo perfilamento é baseado em SparkSession, se aplica ao Spark Connect e pode ser habilitado ou desabilitado em tempo de execução. Ele maximiza a paridade da API com o perfilamento legado, fornecendo comandos de "show" e "dump" para visualizar os resultados do perfil e salvá-los em uma pasta de trabalho. Além disso, oferece APIs convenientes para ajudar a gerenciar e redefinir os resultados do perfilamento sob demanda. Por último, ele suporta UDFs registradas, que não eram suportadas pelo perfilamento legado.
Perfil de Desempenho PySpark
O profiler de desempenho do PySpark aproveita os profilers integrados do Python para estender as capacidades de perfilamento ao driver e UDFs executadas nos executores de maneira distribuída.
Vamos mergulhar em um exemplo para ver o perfilador de desempenho PySpark em ação. Executamos o seguinte código nos notebooks Databricks Runtime 17.0.
O comando added.show() exibe os resultados do perfilamento de desempenho, conforme mostrado abaixo.
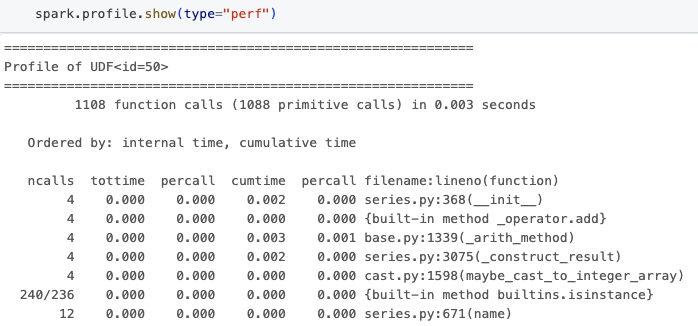
A saída inclui informações como o número de chamadas de função, tempo total gasto na função dada e o nome do arquivo, juntamente com o número da linha para auxiliar na navegação. Essa informação é essencial para identificar loops apertados em seus programas PySpark e permitir que você tome decisões para melhorar o desempenho.
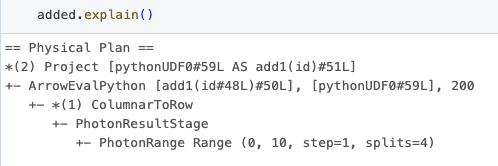
É importante notar que o id da UDF nestes resultados se correlaciona diretamente com o encontrado no plano Spark, observando o “ArrowEvalPython [add1(...)#50L]”, que é revelado ao chamar o método explain no dataframe.
Finalmente, podemos descarregar os resultados do perfilamento para uma pasta e limpar os perfis de resultado, conforme mostrado abaixo.
Perfilador de Memória PySpark
Ele é baseado no memory-profiler, que pode criar um perfil do driver, como visto aqui. PySpark expandiu seu uso para incluir o perfilamento de UDFs, que são executadas nos executores de maneira distribuída.
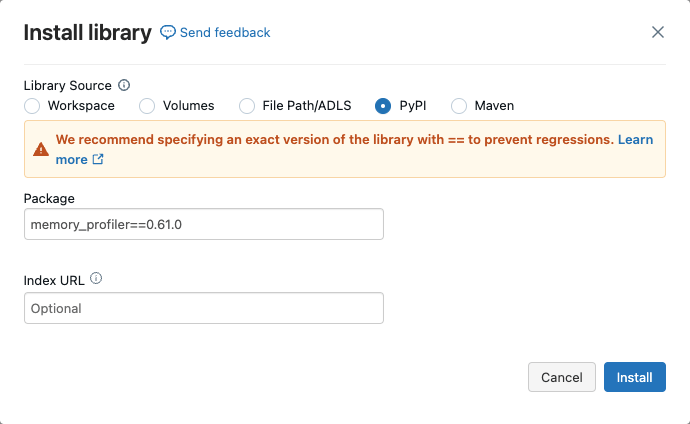
Para habilitar o perfilamento de memória em um cluster, devemos instalar o memory-profiler no cluster, conforme mostrado abaixo.
O exemplo acima modifica as duas últimas linhas por:
Em seguida, obtemos os resultados do perfilamento de memória, conforme mostrado abaixo.
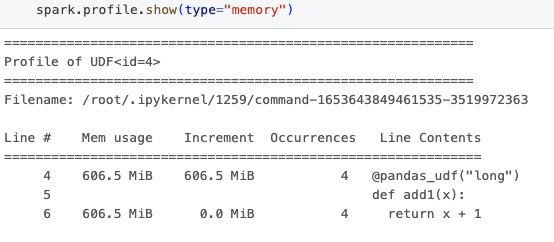
A saída inclui várias colunas que fornecem uma visão abrangente de como seu código se comporta em termos de uso de memória. "Uso de memória" revela o uso de memória após a execução dessa linha. "Incremento" detalha a mudança no uso de memória da linha anterior, ajudando você a identificar onde ocorrem picos de uso de memória. "Ocorrências" indica quantas vezes cada linha foi executada.
O id da UDF nestes resultados também se correlaciona diretamente com o encontrado no plano Spark, o mesmo que os resultados do perfil de desempenho, observando o “ArrowEvalPython [add1(...)#4L]”, que é revelado ao chamar o método explain no dataframe, conforme mostrado abaixo.
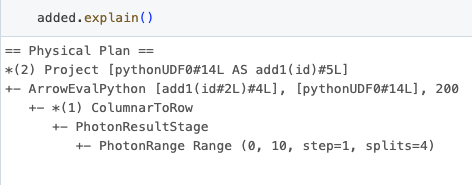
Por favor, note que para que essa funcionalidade funcione, o pacote memory-profiler deve estar instalado em seu cluster.
Conclusão
O Perfilamento Unificado PySpark, que inclui perfilamento de desempenho e memória para UDFs, está disponível no Databricks Runtime 17.0. O Perfilamento Unificado fornece um método simplificado para observar aspectos importantes como frequência de chamadas de função, durações de execução e consumo de memória. Ele simplifica o processo de identificar e resolver gargalos, abrindo caminho para o desenvolvimento de UDFs mais rápidas e eficientes em termos de recursos.
Pronto para explorar mais? Confira a documentação da API PySpark para guias detalhados e exemplos.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.