Tomada de Decisão em Tempo Real para Agentes de IA: Por que você Precisa Primeiro de uma Camada de Contexto do Cliente
Uma perspectiva da Snowplow sobre "The New Martech Stack for the AI Age" de Scott Brinker
por Alex Dean
- Scott Brinker publicou recentemente um relatório de pesquisa com a Databricks, "The New Martech “Stack” for the AI Age", que descreveu uma mudança de 3 a 5 anos de stacks rígidos para uma tela composível e fluida para arquitetura de marketing.
- Alex Dean, Co-fundador e CEO da Snowplow, compartilha sua perspectiva sobre como a camada de contexto do cliente captura dados comportamentais em tempo real que os agentes de IA usam para decisões no momento.
- O loop de feedback agentivo transforma o marketing em um volante: colete e unifique o comportamento humano e de IA em tempo real, ative-o para tomada de decisão e, em seguida, feche o loop para que os agentes aprendam e melhorem continuamente com base nos resultados.
O novo relatório de Scott Brinker com a Databricks articula algo que venho observando se formar por anos: a "pilha" de martech, a familiar disposição em Tetris de caixas, está começando a se dissolver. O que está surgindo em seu lugar é o que Scott chama de tela composable: uma arquitetura fluida e centrada em dados onde agentes de IA e software personalizado operam sobre dados compartilhados em vez de lutar através de pipelines de integração.
Lendo, me peguei concordando mais de uma vez. Não porque seja uma tese fácil de defender (na verdade, é uma reformulação bastante radical de como as empresas pensam sobre tecnologia de marketing), mas porque descreve uma direção arquitetônica à qual nós da Snowplow nos comprometemos há muito tempo, muitas vezes antes de haver um vocabulário compartilhado para isso.
Queria compartilhar algumas reações: onde o relatório ressoa fortemente, como achamos que a Snowplow se encaixa na arquitetura que descreve e uma dimensão que eu adicionaria ao modelo que acho que se torna mais importante à medida que os agentes de IA assumem um papel maior nas interações com os clientes.
A plataforma de dados é agora o centro de gravidade para tomada de decisão em tempo real
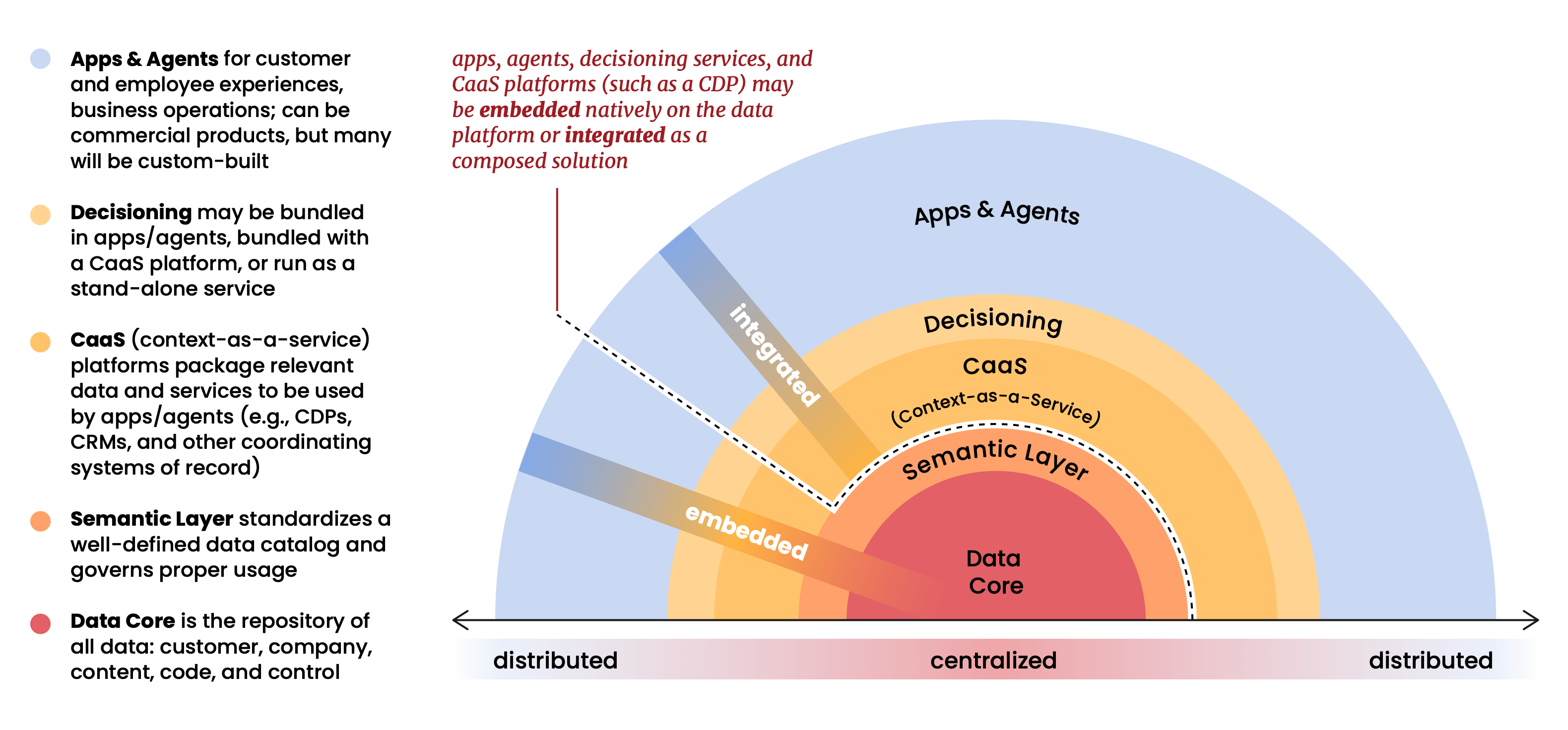
O argumento estrutural central do relatório é que a plataforma de dados (Databricks, Snowflake, BigQuery, etc.) se tornou o centro gravitacional de toda a pilha de martech. Aplicações, agentes e análises não ficam mais em cima dos dados; eles operam dentro deles. A plataforma de dados não é mais um repositório na parte inferior da pilha. Ela é a pilha.
Esta é uma visão que temos na Snowplow há muito tempo, e é uma que moldou muitas decisões iniciais sobre como construímos nosso produto. Quando estávamos montando a Snowplow em 2012, o modelo predominante era acumular dados de clientes dentro de sistemas de fornecedores e fornecer acesso gerenciado a eles. Adotamos a posição oposta: seus dados pertencem à sua infraestrutura, governados por suas regras, consultáveis por qualquer ferramenta que você escolher. Na época, parecia uma posição arquitetônica de princípios, talvez até um pouco contraintuitiva. Como este relatório deixa claro, agora é a única arquitetura que faz sentido em escala.
O que é a Camada de Contexto do Cliente? E por que a tomada de decisão em tempo real depende dela
O que é a camada de contexto do cliente? A camada de contexto do cliente é a infraestrutura comportamental em tempo real que fica entre sua base de dados e seus sistemas voltados para o cliente. Ela está conectada diretamente às experiências digitais para que os agentes de IA possam entender o que um cliente está fazendo agora, além de sua jornada histórica completa.
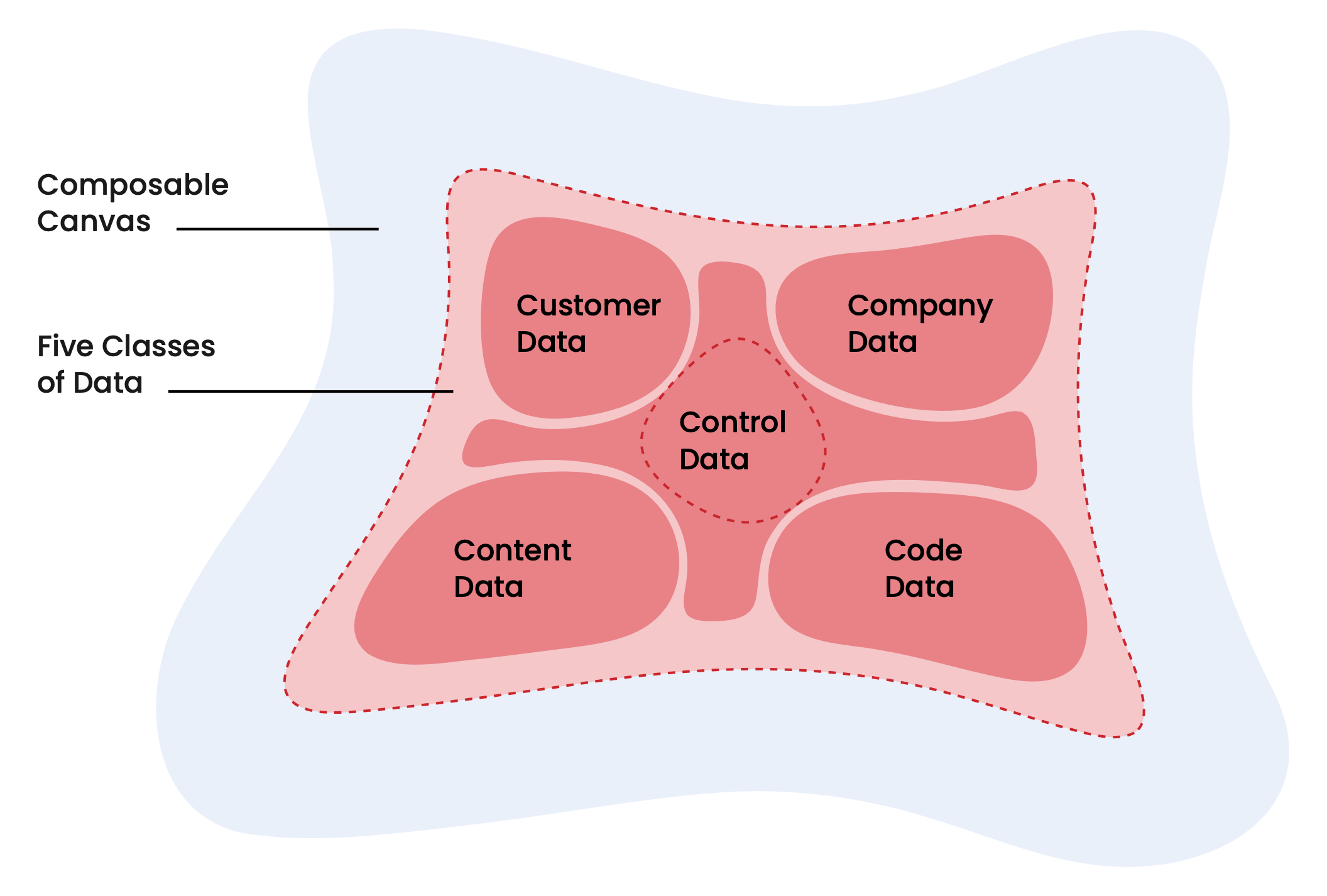
O relatório descreve cinco classes de dados convergindo para a base unificada: dados do cliente, dados da empresa, dados de conteúdo, dados de código e dados de controle. Dados do cliente: "perfis individuais e de contas, históricos de transações, sinais comportamentais (visitas ao site, uso do produto)" está no centro de tudo.
É aqui que a Snowplow opera. Mas eu ampliaria um pouco o enquadramento além do que o relatório faz.
Há uma diferença significativa entre registros de clientes e contexto do cliente. CRMs e CDPs gerenciam bem os primeiros há muito tempo: quem é o cliente, quais negócios ele tem, a quais segmentos pertence. O que tem sido consistentemente mais difícil de fornecer é o último, ou seja: o que ele está fazendo, agora, e o que esse comportamento diz sobre sua intenção?
Fluxos de eventos comportamentais, o registro contínuo e granular de como os clientes interagem com seu produto, seu site, seu aplicativo, são o sinal em tempo real mais rico disponível para qualquer agente de IA que tenta tomar uma decisão. E eles são notoriamente difíceis de acertar. Os eventos precisam ser estruturados no ponto de coleta, validados contra um esquema e enriquecidos antes de chegarem à base de dados. Se os dados comportamentais que entram em sua plataforma unificada são ruidosos, inconsistentes ou mal modelados, os agentes de IA que operam sobre eles irão agravar esses erros em escala.
Snowplow é a camada de contexto do cliente. Ficamos entre o momento em que um cliente faz algo (um clique, um evento de produto, uma pesquisa, um scroll) e a plataforma de dados que precisa agir sobre isso. Nosso trabalho é garantir que os dados comportamentais sejam estruturados, bem governados e semanticamente coerentes desde o momento em que são criados.
E contexto sem identidade é ruído. Um fluxo comportamental rico só é tão útil quanto sua capacidade de vinculá-lo a um indivíduo conhecido e resolvido em diferentes pontos de contato, dispositivos e sessões, incluindo as transições entre estados anônimos e autenticados. O Identities da Snowplow faz esse trabalho na camada de coleta, antes que os dados cheguem à plataforma. O resultado não é apenas um fluxo de eventos. É uma imagem resolvida e contínua da jornada de cada cliente sobre a qual sua plataforma de dados, seus analistas e seus agentes de IA podem operar com confiança.
Composabilidade sempre foi a arquitetura, não o recurso
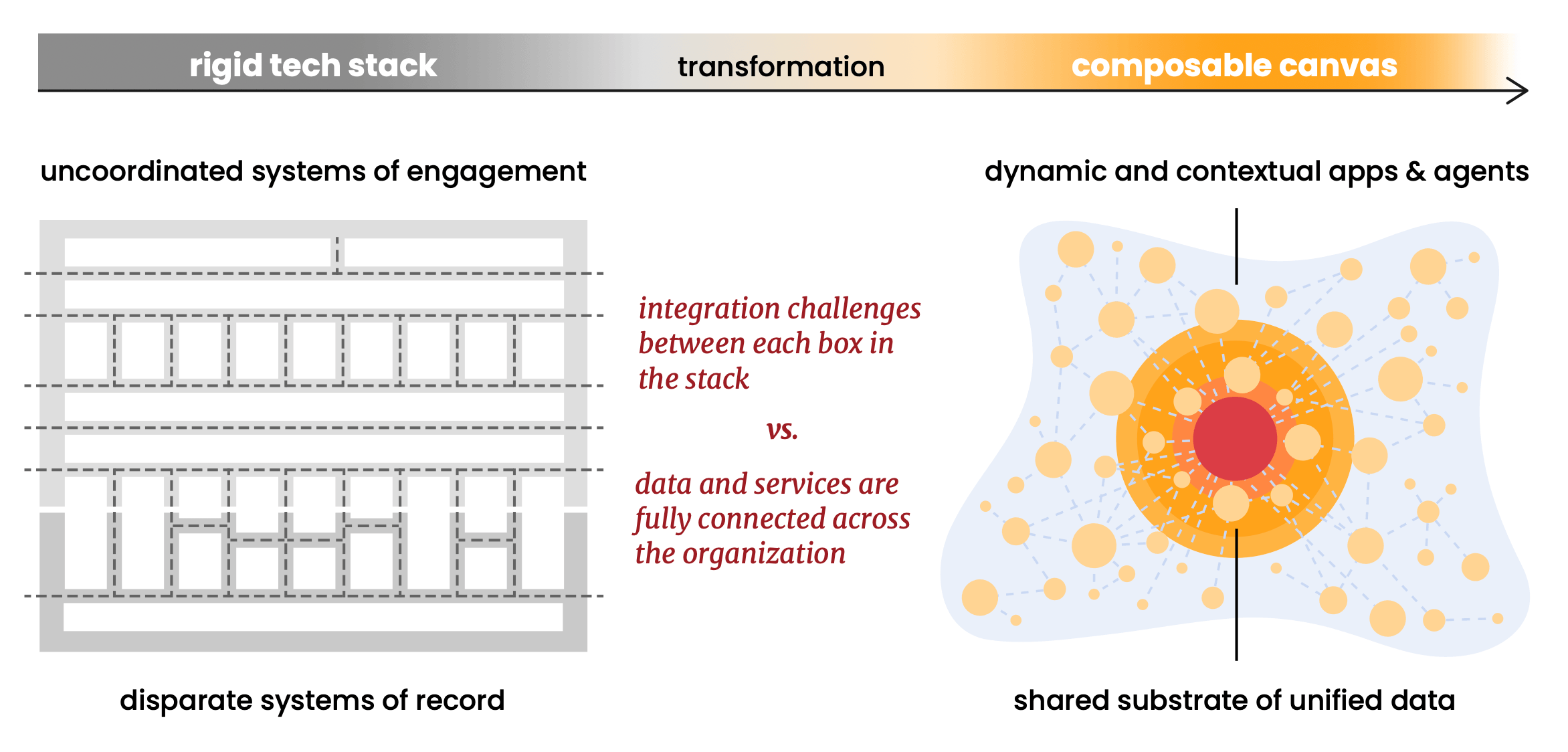
O argumento de composabilidade do relatório é um dos seus mais fortes. Ele defende formatos de dados abertos (Delta Lake da Linux Foundation, Apache Iceberg), protocolos abertos (MCP para agentes) e padrões abertos como pré-condição para uma tela genuinamente composable. O princípio: padronizar a base para poder diversificar tudo o que roda sobre ela.
Acreditamos profundamente nisso, e construímos a Snowplow em torno disso desde o início. Acreditamos em padrões abertos de núcleo. Nossas estruturas de dados rodam nativamente em Apache Iceberg e Delta Lake da Linux Foundation. Operamos dentro da sua conta de nuvem (referida como hiperscalers no artigo de Scott: AWS, GCP ou Azure), o que significa que seus dados comportamentais nunca saem do seu ambiente. Não há um data store proprietário da Snowplow que se torne uma dependência ou um risco de migração. Quando você quiser substituir ou estender qualquer parte da pilha, os dados comportamentais já estarão onde precisam estar: em sua plataforma, em formatos abertos, prontos para compor.
O relatório observa que os "CDPs composables invertem" o modelo tradicional ao trazer as capacidades do CDP para os dados, em vez de puxar os dados para o CDP. A Snowplow fazia isso antes mesmo da categoria ter um nome, porque para nós, composabilidade nunca foi um recurso que adicionamos. Foi o princípio fundador sobre o qual o produto foi construído.
A camada semântica começa antes da plataforma
Uma das ideias mais importantes que o relatório desenvolve é o papel da camada semântica, especificamente o que ele chama de "guardião da coerência". Este é o vocabulário compartilhado que torna os dados significativos e consistentes em todos os agentes e aplicações que os tocam. O que "cliente" significa entre as equipes. Como a "conversão" é calculada. O que constitui um "lead qualificado".
Do nosso ponto de vista, eu adicionaria uma observação prática: a maioria dessas perguntas precisa ser respondida antes que os dados entrem na plataforma, não depois. Dados comportamentais em particular são notavelmente fáceis de coletar mal. Eventos chegam com nomes inconsistentes, propriedades ausentes, esquemas indefinidos. Quando os dados chegam à plataforma, eles já estão incoerentes. Você pode construir uma camada semântica sobre dados ruins, mas está encobrindo um problema estrutural em vez de resolvê-lo.
O registro de esquemas da Snowplow e a validação de eventos através do nosso Event Studio impõem a coerência semântica no ponto de coleta. Rejeitamos ou sinalizamos eventos que não estão em conformidade com as estruturas definidas antes que eles cheguem à plataforma de dados. Na tela composable que o relatório descreve — onde dezenas de agentes e aplicações extraem os mesmos dados comportamentais — a qualidade desses dados na origem é o que determina se você pode confiar em qualquer coisa construída sobre eles.
O Loop de Feedback Agente: Como a tomada de decisão em tempo real se fecha
O relatório faz um ponto que acho que merece ainda mais ênfase: os agentes de IA são "famintos por contexto". Eles não precisam apenas de registros de clientes; eles precisam entender o que está acontecendo no momento, ou seja: os sinais comportamentais que indicam intenção, urgência e oportunidade.
Eu adicionaria algo ao modelo que Scott apresentou aqui. O relatório enquadra os dados fluindo em direção aos agentes — uma base da qual os agentes extraem para tomar decisões. O que ele não desenvolve totalmente é o loop que acontece depois que o agente age, e por que fechar esse loop é cada vez mais o problema de dados mais estrategicamente importante em martech. Isso é algo sobre o qual pensamos muito na Snowplow, e é central para como a tela composable realmente opera na prática.
O loop tem quatro estágios:
- O estágio de Coleta captura eventos comportamentais de interações humanas e de IA como dados estruturados e validados por esquema, fluindo continuamente para a plataforma de dados. Mas a definição de "dados comportamentais" precisa se expandir para incluir uma segunda classe de atividade que a maioria das arquiteturas ainda não captura bem. Essa segunda classe tem duas faces distintas. A primeira é a Análise de Agentes de IA: quando um cliente interage com um agente conversacional, recebe uma recomendação personalizada ou tem uma jornada moldada por um sistema de decisão automatizado — essas interações impulsionadas pelo agente são em si eventos que precisam ser coletados com o mesmo rigor de qualquer comportamento humano. A segunda é a Análise Agentic: agentes de IA realizando pesquisas em nome de um usuário. Quando uma IA está navegando em suas páginas de produtos, lendo sua documentação ou comparando opções como um proxy de cliente, esse tráfego é intenção, apenas expressa através de um ator não humano. Tratando-o como ruído de bot para filtrar significa descartar um sinal que lhe diz algo real sobre o que um cliente está avaliando. Snowplow distingue e captura ambos como eventos comportamentais estruturados, separados da interação humana direta, mas igualmente significativos para entender a intenção e informar a tomada de decisão.
- O estágio de Resolução e Enriquecimento transforma fluxos brutos de eventos em um quadro coerente do cliente através da resolução de identidade, unindo sessões, dispositivos e pontos de contato a um indivíduo conhecido. É aqui que o fluxo comportamental se torna um quadro coerente: não "um usuário visitou três páginas", mas "esta conta, atualmente em fase final de avaliação, teve três executivos pesquisando preços nas últimas 48 horas".
- O estágio de Servir entrega contexto comportamental enriquecido em dois modos simultâneos: em tempo real para personalização na sessão, e tempo real combinado mais histórico para tomada de decisão por agentes de IA. Para personalização na sessão, é em tempo real: a plataforma de dados expõe sinais comportamentais rápido o suficiente para que a experiência que está sendo renderizada para este cliente agora reflita o que ele esteve fazendo nesta sessão. Para tomada de decisão por agentes de IA, é tanto em tempo real quanto histórico: um agente coordenando a próxima melhor ação para uma conta utiliza o fluxo comportamental ao vivo e o registro histórico completo do cliente. A questão não é apenas "o que este cliente está fazendo?", mas "o que este comportamento significa, dado tudo o que sabemos sobre clientes como eles?"
- O estágio de Aprendizado fecha o ciclo de feedback roteando os resultados de cada decisão do agente de volta para a base de dados como eventos comportamentais de primeira classe. A saída de cada decisão do agente, cada experiência personalizada, cada ação automatizada é em si um evento comportamental. O produto recomendado foi adicionado ao carrinho? O e-mail personalizado foi aberto? A intervenção na sessão mudou a trajetória da sessão? A sessão de pesquisa do agente de IA resultou em conversão? Esses resultados precisam fluir de volta para a mesma base de dados que alimentou a decisão original. Sem esse feedback, os agentes de IA estão operando com dados históricos que ficam mais desatualizados a cada dia. Com ele, o sistema se torna genuinamente auto-aprimorável.
É aqui que a Análise de Agentes de IA e a Análise Agentic completam o ciclo. Você coletou eventos comportamentais de agentes de IA como dados de primeira classe; agora você pode analisá-los com o mesmo rigor que aplicaria ao comportamento humano. Quais agentes estão performando? Quais modelos de decisão estão degradando? Onde o tráfego de pesquisa gerado por IA está convertendo e onde está caindo? Essas perguntas só podem ser respondidas se a coleta foi correta desde o início. A análise de Agentes de IA e Agentic não é uma camada de relatórios que você adiciona depois. É uma consequência de como você coletou os dados em primeiro lugar.
Este é o ciclo de feedback que é único em acertar a infraestrutura de dados comportamentais. Não é um pipeline. É um volante.
Da análise à tomada de decisão: as ferramentas certas para tomada de decisão em tempo real
Algo que o relatório sugere e que acho que merece mais espaço, especialmente para líderes de marketing e dados que pensam sobre o que a IA realmente exige de seu stack: a mudança de usar dados comportamentais para análise para usá-los para tomada de decisão é uma mudança arquitetural significativa, não simplesmente uma expansão de caso de uso.
Análise é retrospectiva. Você coleta eventos, os modela e consulta os resultados. Latência de minutos ou horas é aceitável. Os dados informam um humano que toma uma decisão.
Tomada de decisão é prospectiva e em tempo real. Um agente de IA precisa de contexto comportamental em milissegundos para determinar qual experiência servir a este cliente, nesta sessão, agora. Os requisitos de infraestrutura são diferentes. Os requisitos de qualidade de dados são mais altos porque erros não aparecem como uma anomalia em um dashboard que alguém pega na semana seguinte; eles aparecem como uma experiência ruim do cliente entregue instantaneamente, em escala.
Infelizmente, a maioria dos pipelines de dados força um compromisso. Alguns otimizam para velocidade, mas fazem você perder a profundidade histórica. E outros otimizam para riqueza, mas fazem você perder a margem de latência que a tomada de decisão em tempo real necessita.
A tela composable exige ambos ao mesmo tempo, nos mesmos dados. Esse é um problema de infraestrutura mais difícil do que parece, e que vale a pena resolver na base, em vez de tentar corrigir depois, quando um agente estiver tomando decisões em velocidade de milissegundos e você perceber que seu contexto histórico está em um armazenamento separado.
Sobre grafos de contexto e dados comportamentais
O relatório introduz um conceito que achei genuinamente interessante: o grafo de contexto — um registro vivo de rastros de decisão que captura não apenas o que aconteceu, mas por que foi permitido acontecer. Racional de decisão, concessões de exceção, cadeias de aprovação. O tipo de memória institucional que atualmente vive em threads do Slack e na cabeça das pessoas.
Eu argumentaria que fluxos de eventos comportamentais são a matéria-prima natural para grafos de contexto no lado do cliente. Cada ação do agente que envolve um cliente (uma recomendação feita, um segmento acionado, uma mensagem enviada) deve ser rastreável até os sinais comportamentais que a motivaram. O modelo de eventos do Snowplow é estruturado para capturar precisamente essa causalidade: qual sinal disparou, quais dados foram observados, qual limite foi cruzado.
À medida que os grafos de contexto amadurecem como um padrão arquitetural, a camada de dados comportamentais será fundamental para eles. O "o que aconteceu" e o "por que aconteceu" estão ambos codificados no fluxo de eventos, se você o coletar corretamente desde o início.
Como construir uma base de tomada de decisão em tempo real que escala
Para qualquer organização construindo em direção à tela composable que o relatório descreve, acertar a infraestrutura de dados comportamentais é o primeiro e mais alavancado investimento: não porque é o mais empolgante, mas porque tudo o mais roda sobre ela.
Isso significa acertar quatro coisas desde o início:
- Coleta estruturada com validação de esquema incorporada desde o primeiro dia
- Resolução de identidade na camada de coleta, não retroativamente depois
- Um pipeline construído para tomada de decisão em tempo real e análise histórica nos mesmos dados
- A disciplina de coletar os resultados de interações de agentes de IA como eventos comportamentais de primeira classe, para que o ciclo de feedback se feche desde o início
A arquitetura composable também significa que as decisões de fornecedor que você toma hoje devem ser reversíveis. Se o seu pipeline de dados comportamentais escreve em formatos abertos em sua própria infraestrutura de nuvem, você preserva a opcionalidade. Se ele escreve em um armazenamento proprietário, você criou uma dependência que restringirá todas as decisões futuras sobre o stack.
A 3ª Era já chegou para aqueles que investiram cedo
O relatório enquadra a 3ª Era do Martech como um horizonte de 3-5 anos. Para os clientes Snowplow que já fizeram os investimentos arquiteturais descritos aqui, ou seja: plataformas de dados como o núcleo operacional, dados comportamentais alimentando agentes em tempo real, o ciclo completo de feedback de tomada de decisão para análise rodando em uma base composable, este não é um estado futuro. É como eles operam hoje.
Isso não é uma afirmação sobre o Snowplow especificamente. É evidência de que a arquitetura é alcançável agora, para organizações dispostas a priorizá-la. A tela composable não está esperando por novas tecnologias. Está esperando por decisões arquiteturais e a convicção para tomá-las.
O relatório de Scott é uma articulação clara e generosa de quais deveriam ser essas decisões. Ficamos felizes em ver essa conversa acontecendo nesse nível de profundidade — e felizes em fazer parte dela!

Leia o relatório de pesquisa completo de Scott Brinker aqui: O Novo "Stack" Martech para a Era da IA
Webinar ao vivo com Scott Brinker, CMO da Samsara e VP de Ciência de Dados de Marketing da HP sobre como o martech está evoluindo para a IA: Registre-se para o webinar
Se você quiser se aprofundar no que a base de dados para análise agentic realmente precisa parecer, a equipe da Snowplow cobriu em detalhes aqui: O Que é Análise Agentic? Um Guia para Líderes de Dados
FAQ:
Qual a diferença entre tomada de decisão em tempo real e processamento em lote? O processamento em lote coleta e analisa dados em intervalos programados, muitas vezes horas após uma interação ocorrer. A tomada de decisão em tempo real processa sinais comportamentais no momento em que são gerados e aciona uma ação dentro da mesma sessão, muitas vezes em milissegundos. Os requisitos de infraestrutura, os padrões de qualidade de dados e as tolerâncias de latência são fundamentalmente diferentes entre as duas abordagens.
Por que os agentes de IA precisam de uma camada de contexto do cliente? Agentes de IA que tomam decisões durante a sessão precisam de contexto comportamental que reflita o que um cliente está fazendo agora, não o que ele fez ontem. A camada de contexto do cliente fornece fluxos de eventos comportamentais estruturados e com identidade resolvida que os agentes de IA podem consultar em tempo real. Sem ela, os agentes operam com dados desatualizados que degradam a qualidade da decisão em escala.
Qual a diferença entre registros de cliente e contexto do cliente? Registros de cliente descrevem quem é um cliente: seu perfil, histórico de compras, status da conta e pertencimento a segmentos. Contexto do cliente descreve o que ele está fazendo no momento atual: quais páginas visitou, o que pesquisou, quanto tempo se engajou e o que esse comportamento sinaliza sobre sua intenção. A tomada de decisão em tempo real requer ambos, mas a maioria das pilhas de dados é melhor no primeiro do que no segundo.
Quais são as quatro fases do loop de feedback agentivo? O loop de feedback agentivo passa por quatro fases: (1) Coletar — capturar eventos comportamentais de interações humanas e impulsionadas por IA como dados estruturados; (2) Resolver e enriquecer — vincular eventos a uma identidade conhecida e construir um quadro coerente do cliente; (3) Servir — entregar contexto enriquecido a agentes de IA e sistemas de personalização em tempo real; (4) Aprender — alimentar os resultados de cada decisão do agente de volta à base de dados para que o sistema melhore continuamente.
Qual infraestrutura de dados é necessária para tomada de decisão em tempo real? A tomada de decisão em tempo real requer quatro capacidades fundamentais: coleta de eventos estruturados com validação de esquema no ponto de captura; resolução de identidade na camada de coleta em vez de ser adaptada posteriormente; um pipeline de dados capaz de servir contexto em tempo real e histórico simultaneamente; e a disciplina de tratar os resultados das interações do agente de IA como eventos comportamentais de primeira classe que alimentam o sistema de volta.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.