Real-Time Decisioning for AI Agents: Why you Need a Customer Context Layer First
A Snowplow perspective on Scott Brinker's "The New Martech Stack for the AI Age"
by Alex Dean
- Scott Brinker recently published a research report with Databricks, The New Martech “Stack” for the AI Age, which outlined a 3-5 year shift from rigid stacks to a fluid composable canvas for marketing architecture
- Alex Dean, Co-Founder and CEO at Snowplow, shares his perspective on how the customer context layer captures real-time behavioral data that AI agents use for in-the-moment decisions
- The agentic feedback loop turns marketing into a flywheel: collect and unify real-time human and AI behavior, activate it for decisioning, then close the loop so agents continuously learn and improve based on outcomes

Scott Brinker's new report with Databricks articulates something I've been watching take shape for years: the martech "stack", the familiar Tetris arrangement of boxes, is beginning to dissolve. What's emerging in its place is what Scott calls a composable canvas: a fluid, data-centric architecture where AI agents and custom software operate on shared data rather than fighting through integration pipelines.
Reading through it, I found myself nodding along more than once. Not because it's an easy thesis to make (it's actually a fairly radical reframing of how enterprises think about marketing technology), but because it describes an architectural direction we at Snowplow committed to a long time ago, often before there was shared vocabulary for it.
I wanted to share a few reactions: where the report resonates strongly, how we think Snowplow fits into the architecture it describes, and one dimension I'd add to the model that I think becomes more important as AI agents take on a larger role in customer interactions.
The data platform is now the center of gravity for real-time decisioning
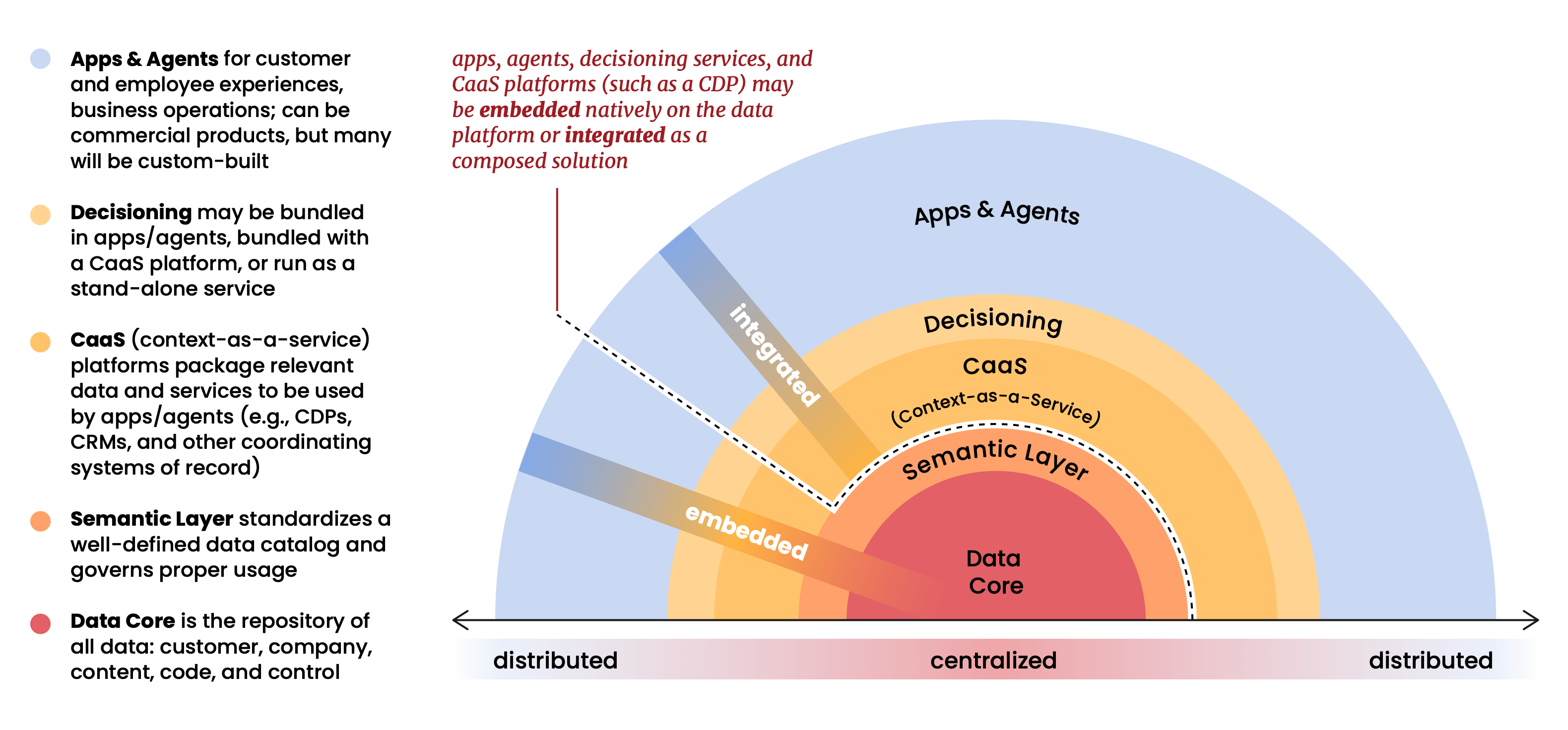
The report's core structural argument is that the data platform (Databricks, Snowflake, BigQuery, etc.) has become the gravitational center of the entire martech stack. Applications, agents, and analytics no longer sit on top of the data; they operate within it. The data platform isn't a repository at the bottom of the stack anymore. It is the stack.
This is a view we've held at Snowplow for a long time, and it's one that shaped a lot of early decisions about how we built our product. When we were first putting Snowplow together in 2012, the prevailing model was to accumulate customer data inside vendor systems and provide managed access to it. We took the opposite position: your data belongs in your infrastructure, governed by your rules, queryable by any tool you choose. At the time, that felt like a principled architectural stance, maybe even a slightly contrarian one. As this report makes clear, it's now the only architecture that makes sense at scale.
What is the Customer Context Layer? And why real-time decisioning depends on it
What is the customer context layer? The customer context layer is the real-time behavioral infrastructure that sits across your data foundation and your customer-facing systems. It’s wired directly into digital experiences so that AI agents can understand what a customer is doing right now, in addition to their entire historical journey.
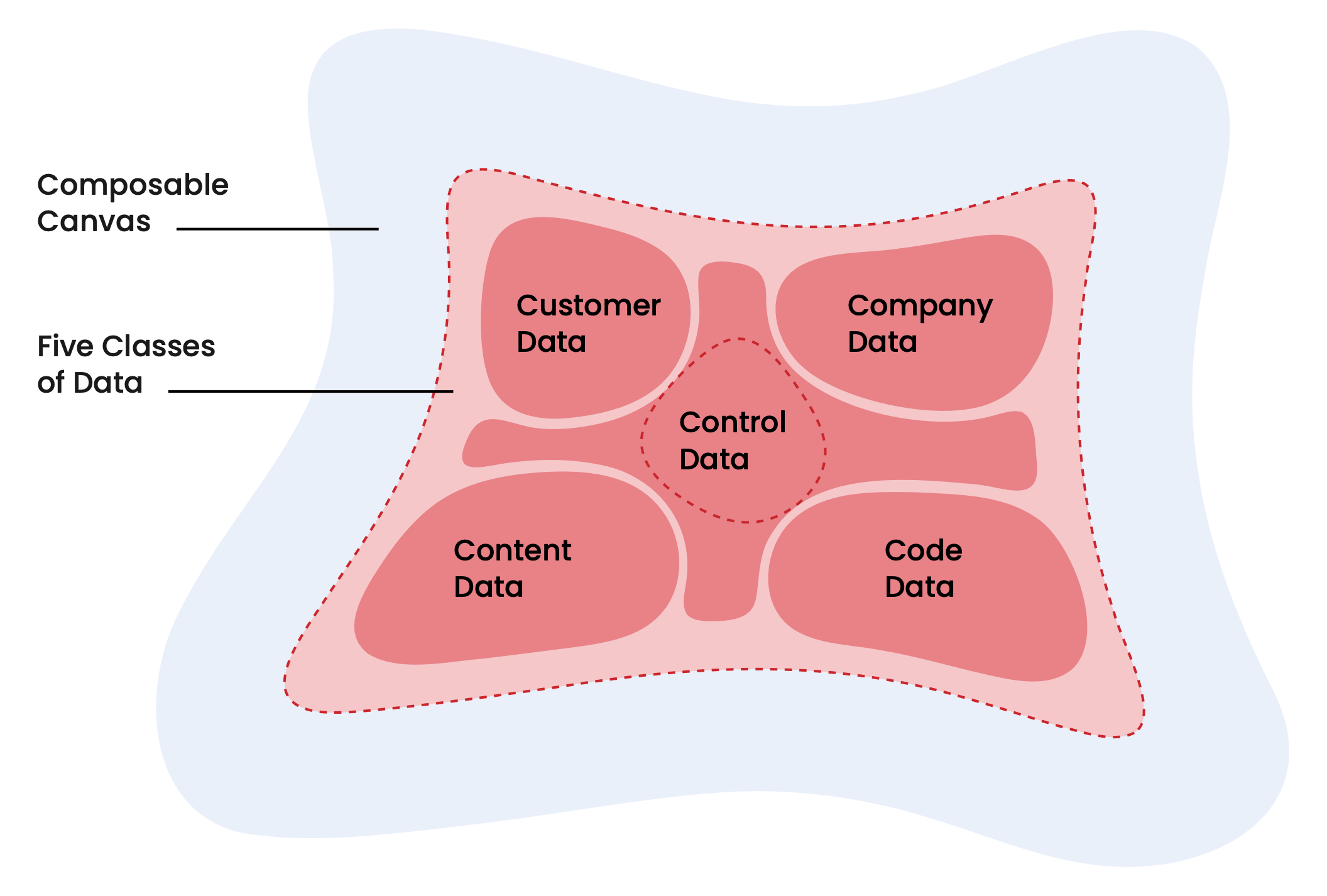
The report describes five classes of data converging on the unified foundation: customer data, company data, content data, code data, and control data. Customer data: "individual and account profiles, transaction histories, behavioral signals (web visits, product usage)" sits at the heart of it all.
This is where Snowplow operates. But I'd push the framing slightly further than the report does.
There's a meaningful difference between customer records and customer context. CRMs and CDPs have long managed the former well: who the customer is, what deals they have, what segments they belong to. What's been consistently harder to serve is the latter, ie: what are they doing, right now, and what does that behavior tell you about their intent?
Behavioral event streams, the continuous, granular record of how customers interact with your product, your website, your app, are the richest real-time signal available to any AI agent trying to make a decision. And they're notoriously hard to get right. Events need to be structured at the point of collection, validated against a schema, and enriched before they hit the data foundation. If the behavioral data going into your unified platform is noisy, inconsistent, or poorly modeled, the AI agents operating on it will compound those errors at scale.
Snowplow is the customer context layer. We sit between the moment a customer does something (a click, a product event, a search, a scroll) and the data platform that needs to act on it. Our job is to ensure that behavioral data is structured, well-governed, and semantically coherent from the moment it's created.
And context without identity is noise. A rich behavioral stream is only as useful as your ability to stitch it to a known, resolved individual across touchpoints, devices, and sessions, including the transitions between anonymous and authenticated states. Snowplow's Identities does this work at the collection layer, before data lands in the platform. The result isn't just a stream of events. It's a resolved, continuous picture of each customer's journey that your data platform, your analysts, and your AI agents can all operate on with confidence.
Composability was always the architecture, not the feature
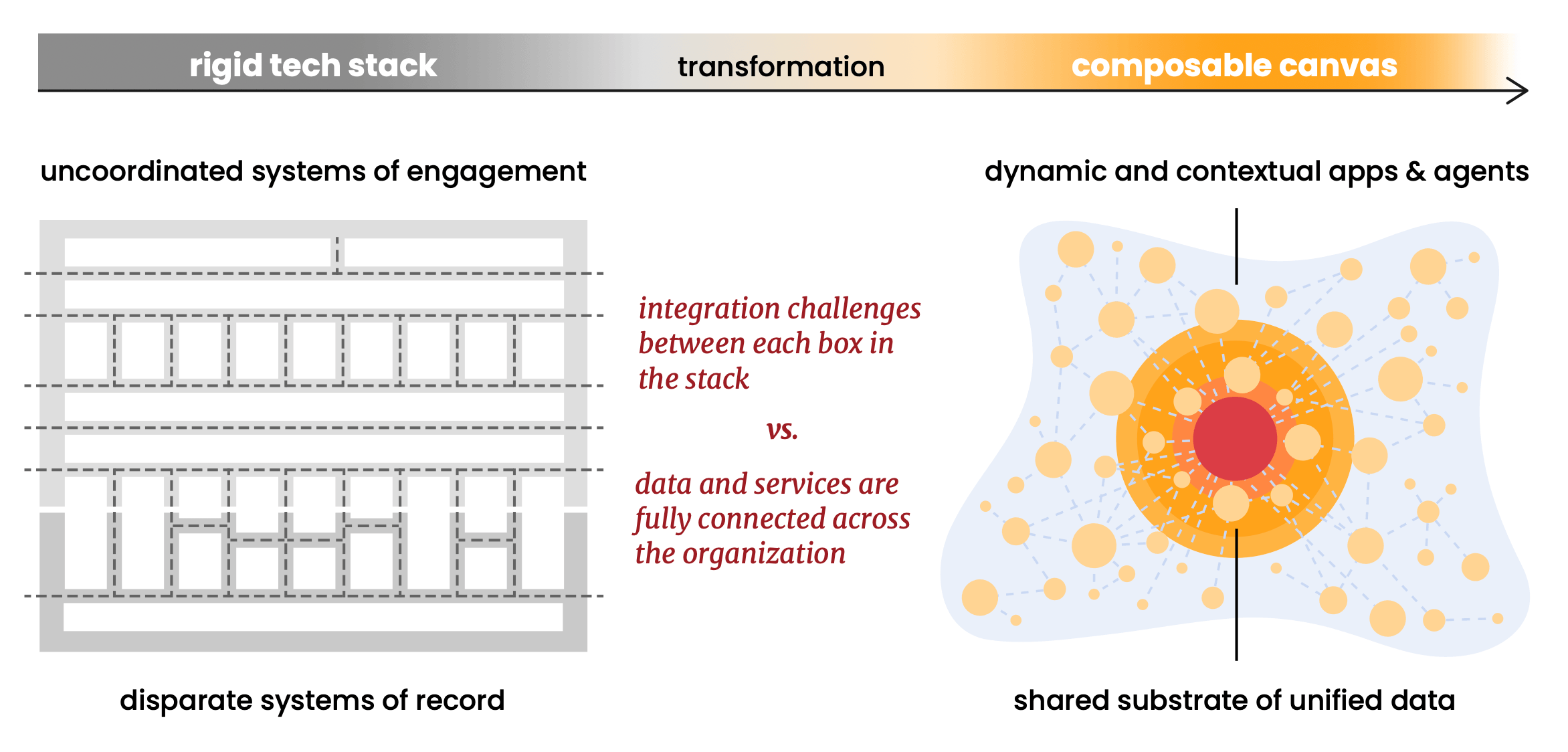
The report's composability argument is one of its strongest. It advocates for open data formats (Linux Foundation Delta Lake, Apache Iceberg), open protocols (MCP for agents), and open standards as the precondition for a genuinely composable canvas. The principle: standardize the foundation so you can diversify everything that runs on top.
We believe in this deeply, and we built Snowplow around it from the start. We believe in open core standards. Our data structures run on Apache Iceberg and Linux Foundation Delta Lake natively. We run inside your cloud account (referenced as hyperscalers in Scott’s piece: AWS, GCP, or Azure), which means your behavioral data never leaves your environment. There's no proprietary Snowplow data store that becomes a dependency or a migration risk. When you want to replace or extend any part of the stack, the behavioral data is already where it needs to be: in your platform, in open formats, ready to compose.
The report notes that "composable CDPs flip" the traditional model by bringing CDP capabilities to the data rather than pulling data into the CDP. Snowplow was doing this before the category had a name, because for us, composability was never a feature we added. It was the founding principle the product was built on.
The semantic layer begins before the platform
One of the most important ideas the report develops is the role of the semantic layer, specifically what it calls "the keeper of coherence." This is the shared vocabulary that makes data meaningful and consistent across every agent and application that touches it. What "customer" means across teams. How "conversion" is calculated. What constitutes a "qualified lead."
From our vantage point, I'd add one practical observation: most of these questions need to be answered before data enters the platform, not after. Behavioral data in particular is remarkably easy to collect badly. Events arrive with inconsistent naming, missing properties, undefined schemas. By the time the data reaches the platform, it's already incoherent. You can build a semantic layer on top of bad data, but you're papering over a structural problem rather than solving it.
Snowplow's schema registry and event validation via our Event Studio enforces semantic coherence at the point of collection. We reject or flag events that don't conform to defined structures before they land in the data platform. In the composable canvas the report describes — where dozens of agents and applications all draw from the same behavioral data — the quality of that data at the source is what determines whether you can trust anything built on top of it.
The Agentic Feedback Loop: How real-time decisioning actually closes
The report makes a point I think deserves even more emphasis: AI agents are "ravenous for context." They don't just need customer records; they need to understand what's happening in the moment, ie: the behavioral signals that indicate intent, urgency, and opportunity.
I'd add something to the model Scott has laid out here. The report frames data as flowing toward agents — a foundation that agents draw on to make decisions. What it doesn't fully develop is the loop that happens after the agent acts, and why closing that loop is increasingly the most strategically important data problem in martech. This is something we think about a great deal at Snowplow, and it's central to how the composable canvas actually operates in practice.
The loop has four stages:
- The Collect stage captures behavioral events from both human and AI-driven interactions as structured, schema-validated data flowing continuously into the data platform. But the definition of "behavioral data" needs to expand to include a second class of activity that most architectures aren't yet capturing well. This second class has two distinct faces. The first is AI Agent Analytics: when a customer interacts with a conversational agent, receives a personalized recommendation, or has a journey shaped by an automated decisioning system — those agent-driven interactions are themselves events that need to be collected with the same rigor as any human behavior. The second is Agentic Analytics: AI agents conducting research on behalf of a user. When an AI is browsing your product pages, reading your documentation, or comparing options as a customer's proxy, that traffic is intent, only expressed through a non-human actor. Treating it as bot noise to filter out means discarding a signal that tells you something real about what a customer is evaluating. Snowplow distinguishes and captures both as structured behavioral events, separate from direct human interaction but equally meaningful for understanding intent and informing decisioning.
- The Resolve and Enrich stage transforms raw event streams into a coherent customer picture through identity resolution, stitching sessions, devices, and touchpoints to a known individual. This is where the behavioral stream becomes a coherent picture: not "a user visited three pages" but "this account, currently in late-stage evaluation, has had three executives researching pricing in the last 48 hours."
- The Serve stage delivers enriched behavioral context in two simultaneous modes: real-time for in-session personalization, and combined real-time plus historical for AI agent decisioning. For in-session personalization, it's real-time: the data platform surfaces behavioral signals fast enough that the experience being rendered to this customer right now reflects what they've been doing in this session. For AI agent decisioning, it's both real-time and historical: an agent coordinating the next-best-action for an account draws on the live behavioral stream and the full customer historical record. The question isn't just "what is this customer doing?" but "what does this behavior mean, given everything we know about customers like them?"
- The Learn stage closes the feedback loop by routing the outcomes of every agent decision back into the data foundation as first-class behavioral events. The output of every agent decision, every personalized experience, every automated action is itself a behavioral event. Did the recommended product get added to cart? Did the personalized email get opened? Did the in-session intervention change the trajectory of the session? Did the AI research agent's browsing session ultimately convert? These outcomes need to flow back into the same data foundation that powered the original decision. Without this feedback, AI agents are operating on historical data that gets staler every day. With it, the system becomes genuinely self-improving.
This is where AI Agent Analytics and Agentic Analytics complete the loop. You've collected AI agent behavioral events as first-class data; now you can analyze them with the same rigor you'd apply to human behavior. Which agents are performing? Which decisioning models are degrading? Where is AI-generated research traffic converting, and where is it dropping off? These questions can only be answered if the collection was right from the start. AI Agent and Agentic analytics aren't a reporting layer you bolt on later. They’re a consequence of how you collected the data in the first place.
This is the feedback loop that's unique to getting behavioral data infrastructure right. It isn't a pipeline. It's a flywheel.
From analytics to decisioning: the right tooling for real-time decisioning
Something the report gestures at that I think deserves more space, particularly for marketing and data leaders thinking about what AI actually requires of their stack: the shift from using behavioral data for analytics to using it for decisioning is a meaningful architectural change, not simply a use-case expansion.
Analytics is backward-looking. You collect events, model them, and query the results. Latency of minutes or hours is acceptable. The data informs a human who makes a decision.
Decisioning is forward-looking and real-time. An AI agent needs behavioral context within milliseconds to determine what experience to serve this customer, in this session, right now. The infrastructure requirements are different. The data quality requirements are higher because errors don't surface as a dashboard anomaly that someone catches next week; they surface as a poor customer experience delivered instantly, at scale.
Unfortunately, most data pipelines force a trade-off. Some optimize for speed, but cause you to lose the historical depth. And others optimize for richness, but cause you to lose the latency headroom real-time decisioning needs.
The composable canvas demands both at the same time, on the same data. That's a harder infrastructure problem than it sounds, and one worth solving at the foundation rather than trying to patch later when an agent is making decisions at millisecond speed and you realise your historical context is sitting in a separate store.
On context graphs and behavioral data
The report introduces a concept I found genuinely interesting: the context graph — a living record of decision traces that captures not just what happened but why it was allowed to happen. Decision rationale, exception grants, approval chains. The kind of institutional memory that currently lives in Slack threads and people's heads.
I'd argue that behavioral event streams are the natural raw material for context graphs on the customer side. Every agent action that involves a customer (a recommendation made, a segment triggered, a message sent) should be traceable back to the behavioral signals that prompted it. Snowplow's event model is structured to capture precisely this causality: what signal fired, what data was observed, what threshold was crossed.
As context graphs mature as an architectural pattern, the behavioral data layer will be foundational to them. The "what happened" and the "why it happened" are both encoded in the event stream, if you collect it correctly from the start.
How to build a real-time decisioning foundation that scales
For any organization building toward the composable canvas the report describes, getting behavioral data infrastructure right is the first and highest-leverage investment: not because it's the most exciting, but because everything else runs on it.
That means getting four things right from the start:
- Structured collection with schema validation baked in from day one
- Identity resolution at the collection layer, not retrofitted later
- A pipeline built for real-time decisioning and historical analytics on the same data
- The discipline to collect AI agent interaction outputs as first-class behavioral events, so the feedback loop closes from the beginning
The composable architecture also means the vendor decisions you make today should be reversible. If your behavioral data pipeline writes to open formats in your own cloud infrastructure, you preserve optionality. If it writes to a proprietary store, you've created a dependency that will constrain every future decision about the stack.
The 3rd Age is already here for those who invested early
The report frames the 3rd Age of Martech as a 3-5 year horizon. For the Snowplow customers who've already made the architectural investments described here, ie: data platforms as the operational core, behavioral data feeding real-time agents, the full decisioning-to-analytics feedback loop running on a composable foundation, this isn't a future state. It's already how they operate today.
That's not a claim about Snowplow specifically. It's evidence that the architecture is achievable now, for organizations willing to prioritize it. The composable canvas isn't waiting on new technology. It's waiting on architectural decisions and the conviction to make them.
Scott's report is a clear and generous articulation of what those decisions should be. We're glad to see this conversation happening at this level of depth — and glad to be part of it!

Read Scott Brinker’s full research report here: The New Martech “Stack” for the AI Age
Live webinar with Scott Brinker, Samsara’s CMO, and HP’s VP of Marketing Data Science on how martech is evolving for AI: Register for the webinar
If you want to go deeper on what the data foundation for agentic analytics actually needs to look like, the team at Snowplow have covered it in detail here: What Is Agentic Analytics? A Guide for Data Leaders
FAQ:
How is real-time decisioning different from batch processing? Batch processing collects and analyzes data in scheduled intervals, often hours after an interaction occurs. Real-time decisioning processes behavioral signals the moment they are generated and triggers an action within the same session, often within milliseconds. The infrastructure requirements, data quality standards, and latency tolerances are fundamentally different between the two approaches.
Why do AI agents need a customer context layer? AI agents making in-session decisions require behavioral context that reflects what a customer is doing right now, not what they did yesterday. The customer context layer provides structured, identity-resolved behavioral event streams that AI agents can query in real time. Without it, agents are operating on stale data that degrades decision quality at scale.
What is the difference between customer records and customer context? Customer records describe who a customer is: their profile, purchase history, account status, and segment membership. Customer context describes what they are doing in the current moment: which pages they've visited, what they've searched for, how long they've engaged, and what that behavior signals about their intent. Real-time decisioning requires both, but most data stacks are better at the former than the latter.
What are the four stages of the agentic feedback loop? The agentic feedback loop runs through four stages: (1) Collect — capturing behavioral events from human and AI-driven interactions as structured data; (2) Resolve and enrich — stitching events to a known identity and building a coherent customer picture; (3) Serve — delivering enriched context to AI agents and personalization systems in real time; (4) Learn — feeding the outcomes of every agent decision back into the data foundation so the system continuously improves.
What data infrastructure is required for real-time decisioning? Real-time decisioning requires four foundational capabilities: structured event collection with schema validation at the point of capture; identity resolution at the collection layer rather than retrofitted later; a data pipeline capable of serving both real-time and historical context simultaneously; and the discipline to treat AI agent interaction outputs as first-class behavioral events that feed back into the system.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.