Revolucionando o armazenamento e a análise de dados de medição de carros: a solução em escala de petabytes da Mercedes-Benz na Databricks Intelligence Platform
por Dr. Thomas Bonfert, Jonathan Bräuer, Dr. Xuan Wang e Florian Doll
- A Mercedes-Benz fez uma parceria com a Databricks para construir um modelo de dados inovador na Databricks Intelligence Platform para representar e analisar petabytes de dados de séries temporais de veículos, otimizando o custo e a escalabilidade.
- Avaliamos e fizemos o benchmark de vários layouts de dados do modelo em dados reais da Mercedes-Benz, e identificamos que usar a Codificação por Comprimento de Execução com o Liquid Clustering é o layout de dados mais adequado.
- Nossa abordagem equilibra os requisitos de armazenamento e a velocidade de execução, permitindo uma análise de dados de séries temporais automotivas mais rápida e eficiente para impulsionar a inovação preparada para o futuro.
Resumo
Com o avanço dos veículos conectados, a indústria automotiva está vivenciando uma explosão de dados de séries temporais. Centenas de Unidades de Controle Eletrônico (ECUs) transmitem dados continuamente em redes veiculares em altas frequências (1Hz-100Hz). Esses dados oferecem um potencial imenso para análise preditiva e inovação, mas extrair conhecimento em escala de petabytes apresenta grandes desafios técnicos, financeiros e de sustentabilidade.
Neste post de blog, apresentamos um modelo de dados semântico hierárquico inovador, projetado para dados de séries temporais em grande escala. Aproveitando os recursos mais recentes (p. ex., liquid clustering) apresentado pela Databricks Intelligence Platform, permite análises escaláveis e econômicas, transformando dados brutos de medição automotiva em insights acionáveis que impulsionam o desenvolvimento de veículos, o ajuste de desempenho e a manutenção preditiva.
Além disso, compartilhamos benchmarks com base em dados do mundo real da Mercedes-Benz e comparamos estratégias de otimização de dados de ponta para avaliar o desempenho nos principais casos de uso do setor.
Introdução
A análise de séries temporais na indústria automotiva não é apenas processamento de números; é como ler o pulso de cada veículo na estrada. Cada ponto de dados conta uma história, desde as vibrações sutis de um motor até as decisões de frações de segundo dos sistemas de direção autônoma ou mesmo as interações entre motorista e veículo. À medida que esses pontos de dados se unem em tendências e padrões, eles revelam insights que podem revolucionar o desenvolvimento de veículos, aprimorar os recursos de segurança e até mesmo prever necessidades de manutenção antes que uma única luz de aviso pisque no painel.
No entanto, o grande volume desses dados representa um desafio formidável. Veículos modernos, equipados com centenas de ECUs, geram uma quantidade enorme de dados de séries temporais. Embora coletar e armazenar essa riqueza de informações seja crucial, o verdadeiro desafio — e a oportunidade — está em aproveitar seu poder para ir além de relatórios simples e avançar para análises preditivas prospectivas usando ML & AI.
No centro deste desafio, está a necessidade de um modelo universalmente aplicável, eficiente e escalável para representar dados de séries temporais — um que suporte tanto casos de uso bem definidos quanto emergentes. Para atender a essa necessidade, apresentamos um modelo de dados semântico hierárquico inovador que aborda a complexidade da análise de séries temporais automotivas, transformando dados brutos de medição em um ativo estratégico.
No desenvolvimento deste modelo de dados, focamos em três aspectos críticos:
- Acesso a dados econômico e escalável: um modelo de dados deve ser projetado para suportar padrões de consulta comuns na análise de dados de séries temporais, permitindo o processamento rápido e eficiente em termos de recursos de datasets massivos.
- Usabilidade: a facilidade de uso para profissionais de dados e especialistas de domínio é fundamental, garantindo que o trabalho com os dados seja direto e intuitivo, independentemente da escala, para obter insights rapidamente sem gastar horas escrevendo consultas.
- Descoberta e Governança de Dados: Minimizar o modelo de dados para séries temporais de até milhares ou milhões de sinais diferentes e metadados contextuais é crucial para a governança e a manutenibilidade. Dados de qualquer número de frotas de carros podem ser facilmente registrados em algumas tabelas do Unity Catalog, e os usuários podem descobrir, acessar e colaborar com segurança em dados confiáveis.
Em colaboração com a Mercedes-Benz AG, uma das maiores fabricantes de veículos premium com sede em Stuttgart, na Alemanha, aprimoramos o modelo de dados com base nos padrões ASAM para ajudar a Mercedes-Benz a desenvolver o carro mais desejado, aproveitando o poder do Mercedes-Benz Operating System (MB.OS). Assim como o carro-conceito Mercedes-Benz Vision EQXX, que estabelece novos padrões de autonomia e eficiência elétrica, estamos elevando o desempenho e a eficiência das análises a um nível totalmente novo, usando tecnologias de ponta.
Neste post de blog, apresentamos casos de uso produtivos de análise de dados e dados do mundo real para demonstrar as capacidades do nosso modelo de dados estendido em várias configurações. Além disso, realizamos pesquisas científicas sobre diferentes estratégias de otimização e executamos benchmarks sistemáticos nos layouts de dados Z-Ordering e Liquid Clustering.
Um modelo de dados semântico e hierárquico para abordar os três aspectos críticos
Este modelo de dados pode representar dados de séries temporais de dezenas de milhares de sinais em uma única tabela e inclui uma representação hierárquica de metadados contextuais. Nosso modelo, portanto, oferece as seguintes vantagens:
- Filtragem eficiente: a estrutura hierárquica permite a filtragem rápida em múltiplas dimensões, permitindo que os analistas restrinjam rapidamente seu espaço de busca.
- Relações Semânticas: Ao incorporar relações semânticas entre amostras e metadados contextuais, o modelo facilita recursos de consulta mais intuitivos e poderosos.
- Escalabilidade: a natureza hierárquica do modelo suporta a organização eficiente dos dados à medida que o volume cresce para a escala de petabytes.
- Integração Contextual: A camada semântica permite a integração perfeita de metadados contextuais, aprimorando a profundidade da análise possível.
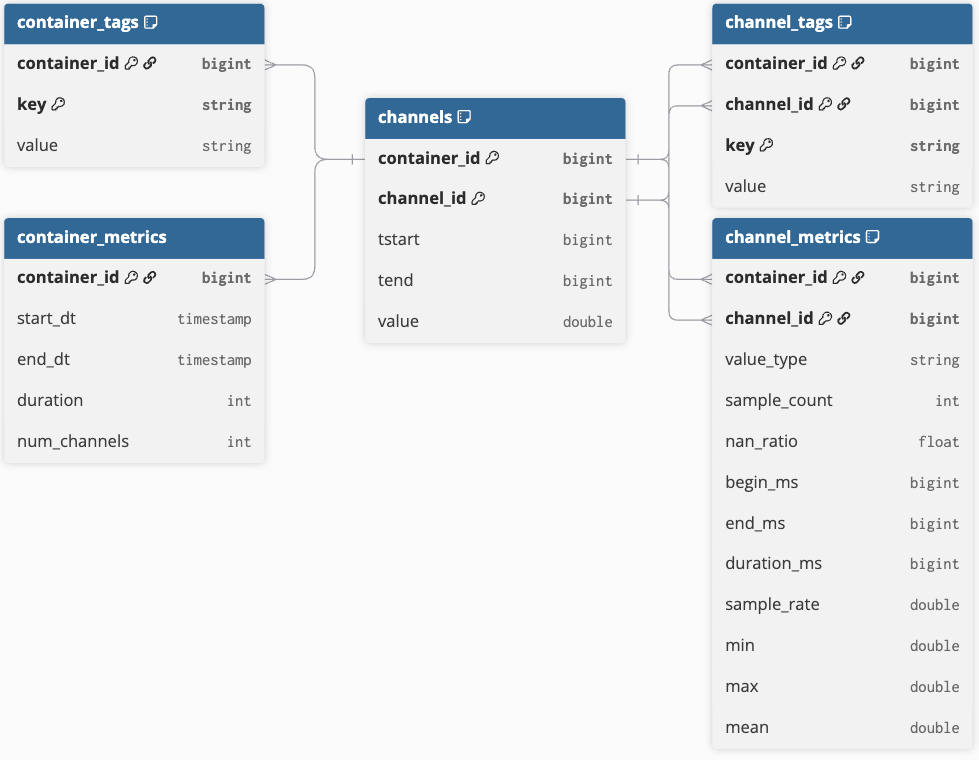
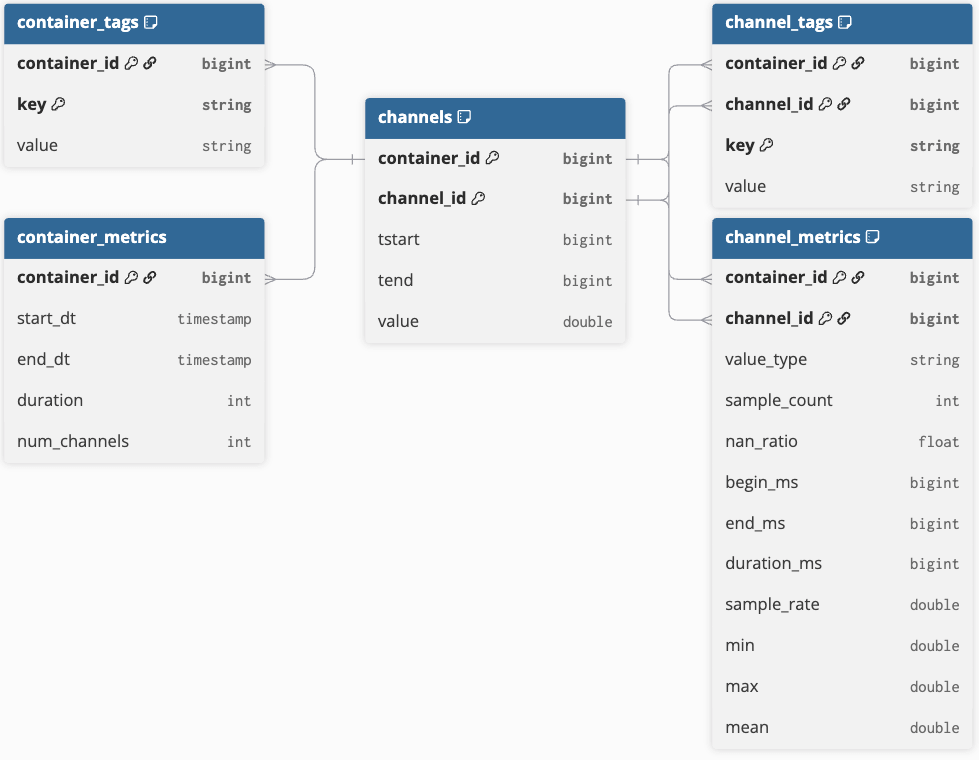
O modelo de dados principal
O modelo principal consiste em cinco tabelas que representam eficientemente dados de séries temporais e metadados contextuais (consulte a Figura 1 para ver o diagrama de relacionamento de entidades). O elemento central do modelo é a tabela de amostras, que contém dados de séries temporais em um formato estreito com duas colunas de identificador: container_id e channel_id. O container_id serve como um identificador exclusivo para um conjunto de objetos de séries temporais, enquanto o channel_id identifica exclusivamente cada série temporal (ou canal) dentro desse contêiner. Essa estrutura permite a análise distribuída dos dados de séries temporais subjacentes.
No contexto automotivo, um contêiner inclui canais predefinidos gravados por registradores de dados do carro durante um test drive e armazenados em um único arquivo. No entanto, vários arquivos de medição podem ser agrupados em um único contêiner se as medições de uma viagem forem divididas devido a restrições de tamanho. Este conceito também se aplica a fluxos contínuos de dados de séries temporais (por exemplo, de dispositivos IoT), onde os limites do contêiner podem ser definidos por tempo (por exemplo, por hora ou por dia) ou por conhecimento do processo, como a divisão de fluxos com base em etapas ou lotes de produção.
Todos os dados de amostra são armazenados usando a codificação run-length encoding (RLE), que mescla amostras consecutivas com o mesmo valor em uma única linha definida por um tempo de início (“tstart”), um tempo de fim (“tend”) e o valor registrado. O tempo final não é inclusivo, marcando a transição para o próximo valor. RLE é um método de compactação simples que facilita a análise eficiente, como o cálculo de histogramas pelo agrupamento de valores e pela soma da duração (tend - tstart). Cada linha é indexada por container_id, channel_id, e pelo período de tempo ativo. Esta tabela de amostras principal é mantida simples para minimizar o tamanho do armazenamento и melhorar o desempenho da consulta.
Além da tabela de amostras, temos 4 tabelas para representar os metadados contextuais:
- “container_metrics” e “container_tags” são indexadas por seu “container_id” fornecido.
- Os metadados de “channel_metrics” e “channel_tags” são adicionalmente identificáveis pelo “channel_id” correspondente.
- Ambas as tabelas de métricas têm um esquema estático que contém informações valiosas para otimizar consultas.
- Ambas as tabelas de tags são usadas como um repositório simples de pares chave-valor que pode conter qualquer tipo de metadado.
Alguns metadados podem ser extraídos diretamente dos arquivos de medição; as tags também podem ser enriquecidas de fontes de metadados externas para dar contexto aos contêineres e sinais vinculados.
{kind=link}
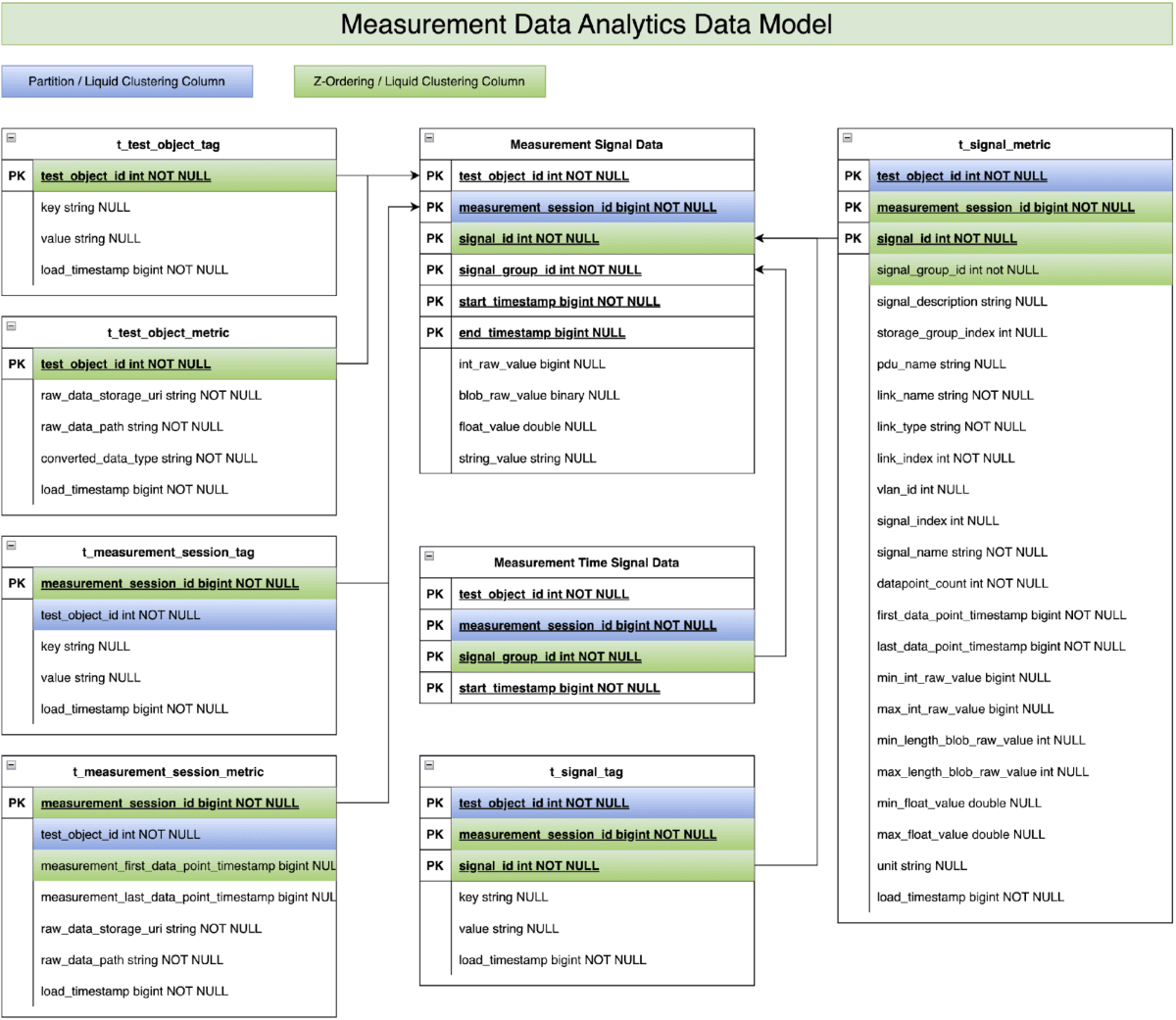
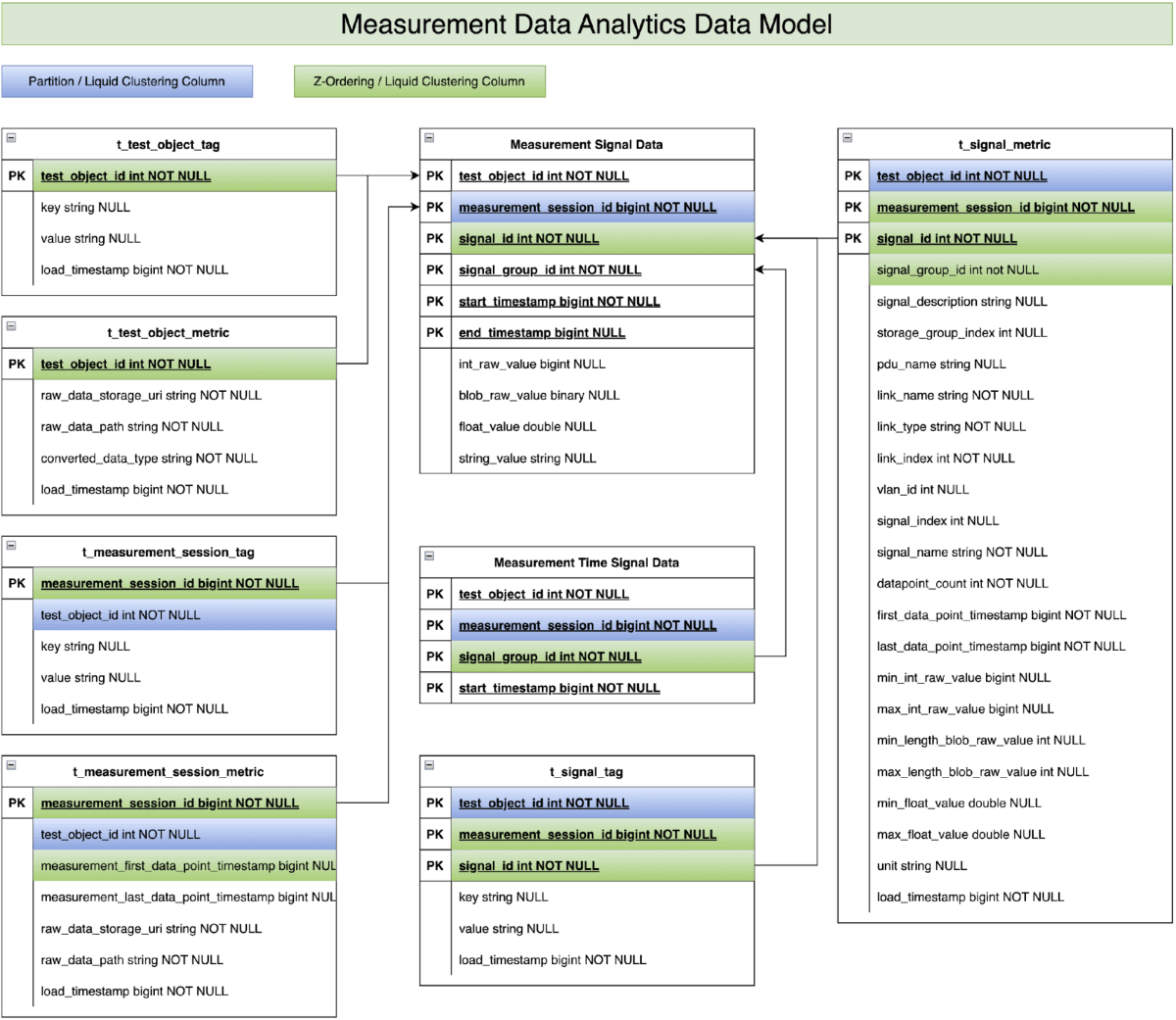
Implementação da Mercedes-Benz
Como membro da comunidade da Association for Standardization of Automation and Measuring Systems (ASAM) (status em agosto de 2025), a Mercedes-Benz há muito tempo utiliza várias tecnologias para analisar os dados de medição coletados. Através da nossa colaboração com a Databricks, reconhecemos o imenso potencial do modelo de dados de séries temporais mencionado anteriormente para apoiar o desenvolvimento de veículos da Mercedes-Benz. Consequentemente, aproveitamos nossa experiência em desenvolvimento de veículos para aprimorar o modelo de dados com base no padrão ASAM MDF (veja a Figura 2). Contribuímos com dados produtivos de medição de veículos de desenvolvimento e adaptamos casos de uso de análise de dados reais. Isso nos permitiu validar o conceito do modelo de dados e demonstrar sua viabilidade em aprimorar o processo de desenvolvimento e a qualidade do veículo.
Nosso foco agora será demonstrar o desempenho deste modelo de dados aprimorado com os dados de medição de veículos de desenvolvimento da Mercedes-Benz:
- Filtragem de nível 1 via “t_test_object_metric” & “t_test_object_tag”: estas duas tabelas armazenam informações de negócios e estatísticas no nível do objeto de teste (p. ex., veículo de teste). Exemplos incluem tipo de veículo, série do veículo, ano do modelo, configuração do veículo, etc. Essa informação permite que os casos de uso de análise de dados, na primeira etapa, se concentrem em objetos de teste específicos entre centenas de objetos de teste.
- Filtragem de nível 2 via “t_measurement_session_metric” e “t_measurement_session_tag”: Essas duas tabelas armazenam as informações de negócios e estatísticas no nível da sessão de medição. Exemplos incluem eventos de teste, informações de fuso horário e timestamps de início/fim da medição. Os carimbos de data/hora de início/fim da medição ajudam os scripts de análise de dados na segunda etapa a restringir as centenas de sessões de medição interessantes de milhões de sessões de medição.
- Filtragem de nível 3 via “t_signal_metric” e “t_signal_tag”: Essas duas tabelas armazenam as informações de negócios e estatísticas no nível da chave do sinal. Os exemplos incluem velocidade do veículo, tipo de estrada, condição climática, sinais do piloto automático etc. Os scripts de análise de dados aproveitam as informações na etapa final para identificar os sinais relevantes para a consulta subjacente entre milhares de sinais disponíveis.
- Scripts de análise em tabelas de dados de sinal de medição: a lógica de análise propriamente dita é executada nas tabelas de dados de sinal de medição, que armazenam os dados de séries temporais coletados dos veículos de teste. No entanto, após aplicar os três níveis de filtragem de dados mencionados acima, normalmente apenas uma pequena fração dos dados brutos originais de séries temporais precisa ser processada e analisada.
{kind=link}
Caso de uso de exemplo da Mercedes-Benz para trabalhar com as tabelas de metadados
Ao introduzir diferentes níveis de tabelas de métricas e tags como metadados principais, o desempenho da análise de dados melhorou significativamente em comparação com as soluções existentes na Mercedes-Benz. Para ilustrar como os metadados principais melhoram o desempenho da análise, gostaríamos de usar a detecção de prontidão do sistema de mudança automática de faixa (ALC) como exemplo.
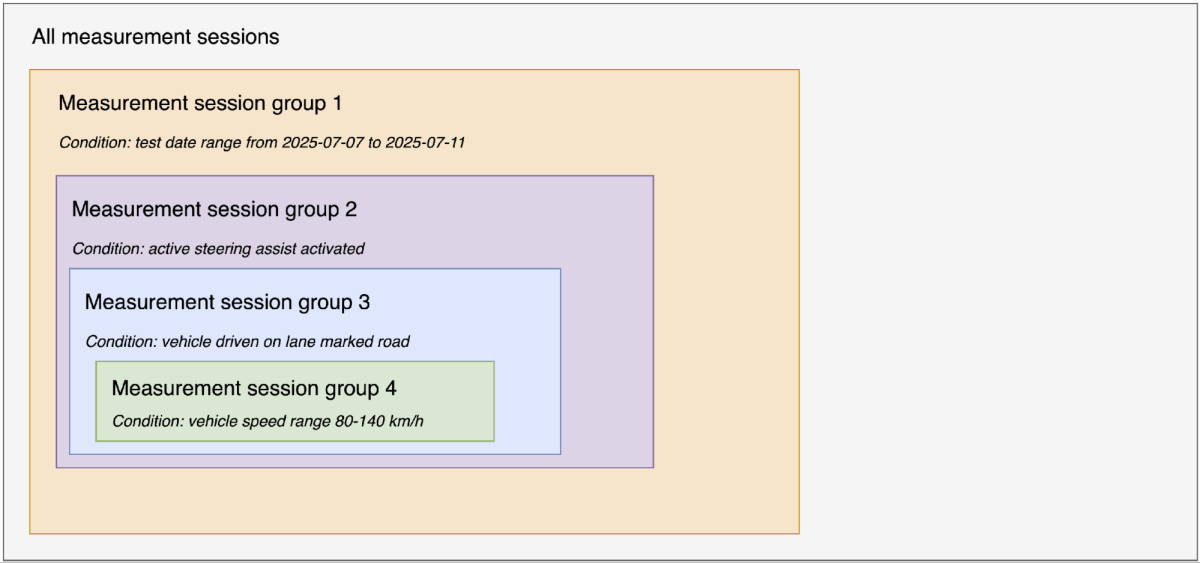
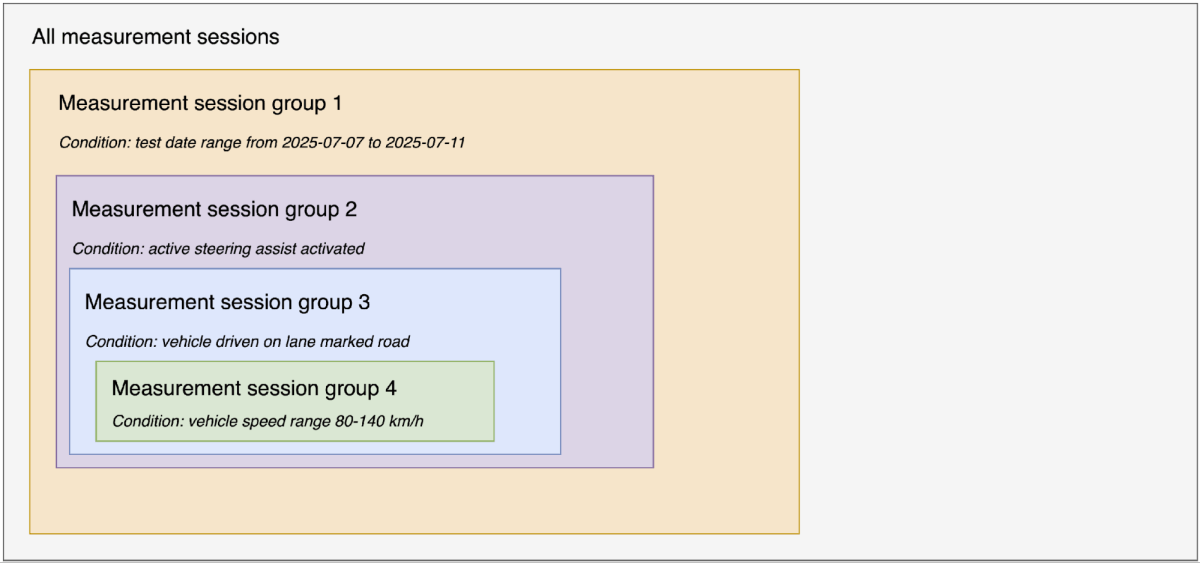
Conforme destacado em inovação da Mercedes-Benz, a função ALC é parte integrante do Active Distance Assist DISTRONIC com o Active Steering Assist. Se um veículo mais lento estiver à frente, o veículo pode iniciar uma mudança de faixa sozinho na faixa de velocidade de 80-140 km/h e ultrapassar de forma totalmente automática se as marcações de faixa forem detectadas e houver espaço livre suficiente. O pré-requisito é uma estrada com limite de velocidade e o veículo estar equipado com o MBUX Navigation. O sistema sofisticado não requer nenhum impulso adicional do motorista para executar a mudança automática de faixa. Essas três pré-condições ajudam o script de análise a filtrar as sessões relevantes entre milhares de sessões. Para maior clareza, apresentamos nossa metodologia de maneira lógica e sequencial (ver Figura 3); é importante observar que a implementação real pode ser realizada em paralelo.
- Filtre as sessões durante o intervalo de datas do test drive, entre 07/07/2025 e 11/07/2025, de todas as sessões de medição geradas para criar o grupo de sessões 1. Nesta etapa, usamos as colunas measurement_first_data_point_timestamp e measurement_end_data_point_timestamp na tabela “t_measurement_session_metric” para identificar as sessões relevantes de todas as sessões registradas do veículo.
- Filtre as sessões dentro do grupo de sessões 1 que contenham o Active Steering Assist ativado para criar o grupo de sessões 2. Nesta etapa, verificamos as sessões onde max_int_raw_value > 0 (assumindo que o valor bruto inteiro do sinal para o Active Steering Assist ativado é 1) na tabela “t_signal_metric” para identificar as sessões relevantes do grupo de sessões 1.
- Filtrar sessões no grupo de sessões 2 onde o veículo é conduzido em uma estrada com faixas marcadas para criar o grupo de sessões 3. Nesta etapa, verificamos as sessões em que max_int_raw_value > 2 (supondo que o valor bruto inteiro do sinal para o tipo de estrada com faixas marcadas seja 3) na tabela “t_signal_metric” para identificar as sessões relevantes do grupo de sessões 2.
- Filtrar sessões no grupo de sessões 3 que contêm velocidade do veículo no intervalo de 80-140 km/h para criar o grupo de sessões 4. Nesta etapa, verificamos as sessões em que max_float_value >= 80 OU min_float_value <= 140 na tabela “t_signal_metric” para identificar as sessões relevantes do grupo de sessões 3.
- Filtre os IDs de sinal necessários dentro do grupo de sessões 4. Nesta etapa, usamos a combinação de pdu_name, link_name, vlan_id, e signal_name para encontrar os IDs dos sinais relevantes.
- Use os IDs de sinal e os IDs de sessão de medição filtrados do grupo de sessões 4 para fazer o join com a tabela de pontos de dados de sinal de medição e identificar a prontidão do sistema ALC.
{kind=link}
Selecionando o layout de dados ideal por meio de benchmarks de dados do mundo real e casos de uso
Para demonstrar o desempenho e a escalabilidade do modelo de dados descrito, realizamos benchmarks sistemáticos com dados de medição e casos de uso do mundo real. Em nosso estudo de benchmark, avaliamos várias combinações de layouts de dados e técnicas de otimização. Os benchmarks foram projetados para otimizar:
- Layout de dados e estratégias de otimização: Testamos diferentes abordagens de layout de dados, como esquemas de particionamento, RLE, não RLE, Z-Ordering e Liquid Clustering, para otimizar o desempenho da consulta.
- Escalabilidade: focamos em soluções capazes de lidar com o volume cada vez maior de dados de medição, mantendo a eficiência.
- Custo-benefício: Consideramos os custos de armazenamento e o desempenho das consultas para identificar a abordagem com melhor custo-benefício para retenção e análise de dados a longo prazo.
Como os resultados do benchmark são cruciais para selecionar o esquema e o formato de dados de medição futuros na Mercedes-Benz, usamos dados produtivos e scripts de análise para avaliar as diferentes opções.
Na prática, mesmo otimizações pequenas podem gerar grandes economias em escala, permitindo que milhares de engenheiros extraiam insights com segurança e economia. O benchmarking é fundamental para validar a eficiência de uma solução sugerida e deve ser repetido continuamente com alterações maiores no sistema.
Configuração do Benchmark
O conjunto de dados de benchmark contém dados de medição de 21 veículos de teste distintos, cada um equipado com modernos registradores de dados veiculares para coletar os dados de medição. A coleção apresenta entre 30.000 e 60.000 sinais registrados por veículo, que oferecem uma ampla gama de pontos de dados para análise. No total, o conjunto de dados representa 40.000 horas de gravações, com 12.500 horas capturando dados especificamente enquanto os veículos estavam ativos (ignição ligada). Este conjunto de dados permite o estudo de vários aspectos do comportamento e desempenho automotivo em diferentes veículos e condições de operação.
As quatro categorias de consulta analítica a seguir foram executadas como parte do benchmark:
- Análise de distribuição de sinal - Geramos histogramas unidimensionais para sinais-chave (p. ex. Velocidade do veículo) para avaliar a distribuição de dados e os padrões de frequência.
- Operações Aritméticas de Sinais - Realizamos cálculos básicos (por ex., subtração, razões) em vários a milhares de sinais.
- Identificação de casos de teste – As consultas identificam e validam cenários operacionais predefinidos no conjunto de dados, definidos por uma sequência de eventos que ocorrem em uma determinada ordem.
- Detecção de Prontidão do Sistema Assistente de Mudança de Faixa Automatizada - Esta consulta utiliza extensivamente as tabelas de metadados antes que os dados de séries temporais subjacentes sejam consultados.
Observe que, nesta postagem do blog, apresentamos apenas os resultados para as categorias 1 e 4, pois os resultados das outras categorias produzem resultados de desempenho comparáveis e não fornecem insights adicionais.
Para avaliar a escalabilidade da solução, usamos quatro tamanhos de cluster diferentes. O tipo de nó Standard_E8d_v4 otimizado para memória foi selecionado por causa do seu recurso de delta cache e maior memória para armazenar os metadados principais. Quanto ao runtime do Databricks, o 15.4 LTS era o runtime de suporte de longo prazo mais recente disponível. Em nossa investigação anterior, o recurso Photon provou ser mais econômico, apesar de seu custo mais alto em DBU, então o Photon foi utilizado em todos os benchmarks. A Tabela 1 fornece detalhes do cluster Databricks selecionado.
| Tamanho da camiseta | Tipo de nó | DBR | #Nós (driver + worker) | Photon |
|---|---|---|---|---|
| XS | Standard_E8d_v4 | 15.4 LTS | 1 + 2 | sim |
| Pequeno | Standard_E8d_v4 | 15.4 LTS | 1 + 4 | sim |
| Médio | Standard_E8d_v4 | 15.4 LTS | 1 + 8 | sim |
| Grande | Standard_E8d_v4 | 15.4 LTS | 1 + 16 | sim |
Tabela 1: As configurações do cluster de benchmark
Resultados de benchmark
O benchmark foi executado em duas versões principais do modelo de dados. A primeira versão tem dados de amostras com codificação por comprimento de execução (RLE) (consulte a seção Modelo de Dados Principal), enquanto a segunda versão não usa RLE. Além disso, aplicamos duas otimizações de layout de dados diferentes a ambas as versões do modelo de dados. Na primeira otimização, usamos o particionamento no estilo Hive para particionar a tabela de dados de sinal de medição pela coluna measurement_session_id e aplicamos a técnica Z-Ordering na coluna signal_id. Na segunda otimização, usamos o Liquid Clustering para clusterizar a tabela de dados de sinal de medição por measurement_session_id e signal_id.
Desempenho de tempo de execução
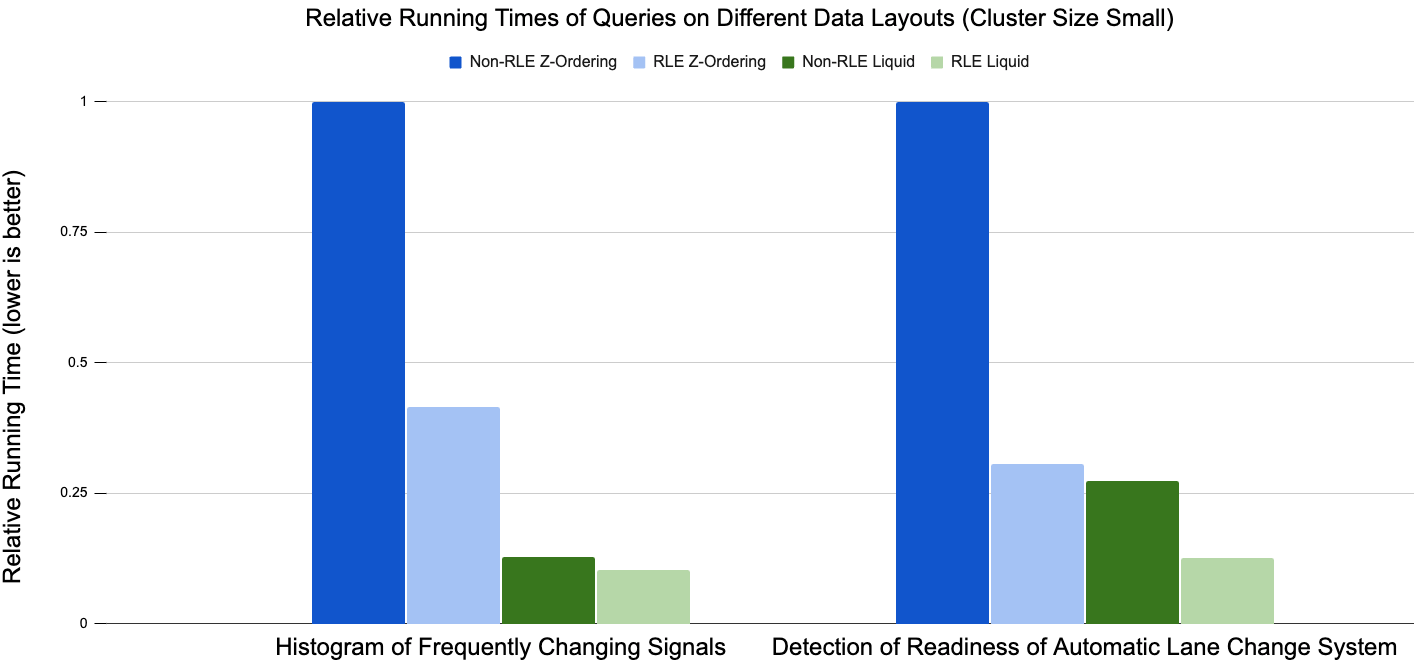
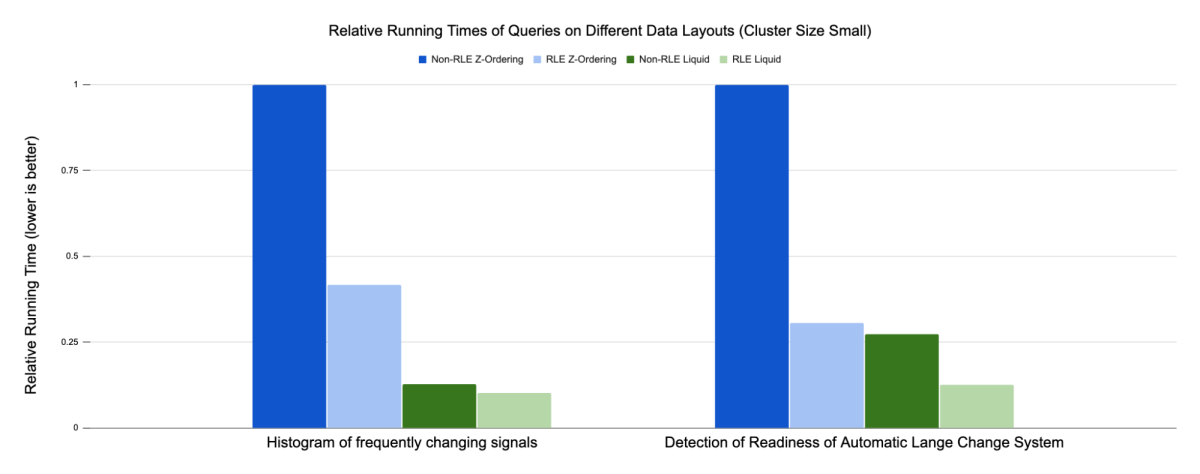
Devido às diferenças significativas nos tempos de execução absolutos entre as configurações de benchmark, decidimos usar o tempo de execução relativo com base nos resultados de Z-Ordering sem RLE para visualizar os resultados. Geralmente, em todos os testes que realizamos, o Liquid Clustering (barras verdes) supera o desempenho do particionamento no estilo Hive + Z-Ordering (barras azuis). Para o histograma de sinais que mudam com frequência, a otimização RLE reduz o tempo de execução em aproximadamente 60% para Z-Ordering, enquanto reduz o tempo de execução em menos de 10% para Liquid Clustering.
No segundo caso de uso, detecção de prontidão do sistema de mudança automática de faixa, o RLE reduziu o tempo de execução em quase 70% para Z-Ordering e em mais de 50% para Liquid Clustering. Os resultados gerais dos casos de uso demonstrados indicam que a combinação de RLE e Liquid Clustering tem o melhor desempenho no modelo de dados.
{kind=link}
Escalabilidade
Para avaliar a escalabilidade da solução, executamos todas as quatro consultas analíticas em um conjunto de dados estático usando diferentes tamanhos de cluster. Na verdade, em cada execução de benchmark, dobramos o tamanho do cluster em comparação com a execução anterior. Idealmente, para uma solução que escala perfeitamente, o tempo de execução de uma consulta deve diminuir por um fator de 2 a cada duplicação do tamanho do cluster. No entanto, as limitações técnicas muitas vezes impedem o escalonamento perfeito.
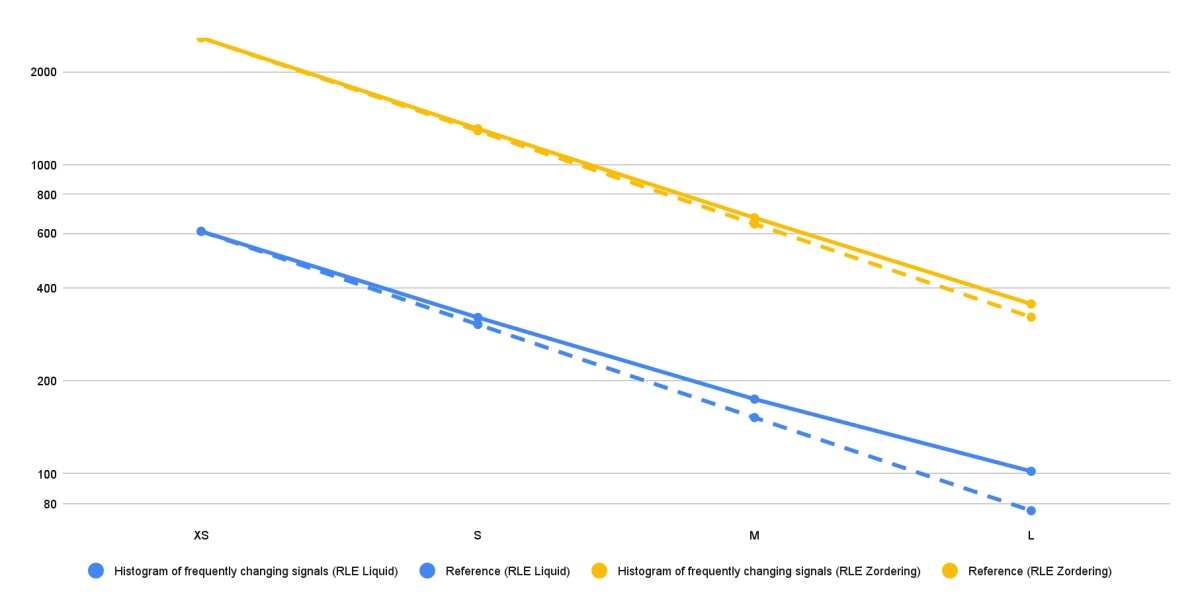
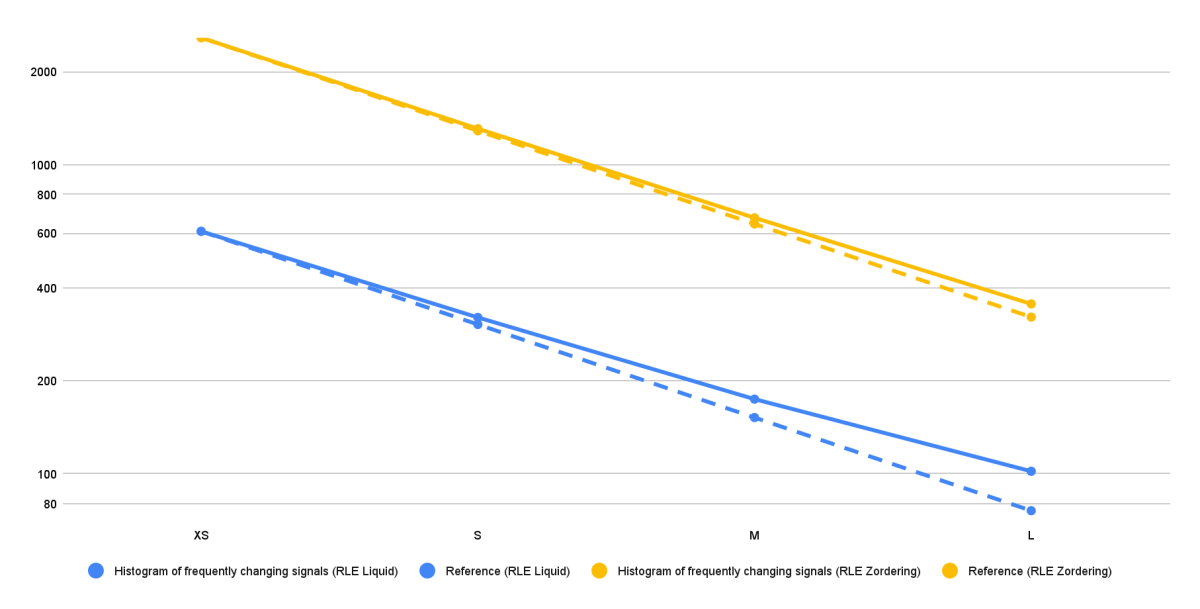
A Figura 5 mostra os resultados em tempos de execução absolutos (segundos) para várias configurações de benchmark para um caso de uso, embora tenhamos observado o mesmo padrão exato em todos os outros casos de uso. As linhas de referência (linhas tracejadas amarela e azul) representam o limite inferior dos tempos de execução (escalonamento perfeito) para as duas diferentes configurações de benchmark. Para o caso de uso mostrado, o tempo de execução geralmente diminui quase perfeitamente à medida que o tamanho do cluster aumenta de X-Small para Large. Isso indica que o modelo de dados e as estratégias de otimização são escaláveis, beneficiando-se de nós adicionais e poder de processamento.
No entanto, podemos ver que os tempos de execução da solução RLE Liquid Clustering (linha azul) começam a se afastar da linha de referência de escalonamento perfeito a partir do tamanho de cluster Médio. Essa diferença torna-se ainda mais pronunciada com o tamanho de cluster Large. Contudo, é importante notar que os tempos de execução absolutos para a solução RLE Liquid Clustering são significativamente mais baixos do que os da solução RLE Z-Ordering. Portanto, prevê-se que a solução RLE Liquid Clustering exibiria melhorias de escalabilidade diminuídas em tamanhos de cluster maiores, pois seu tempo de execução base já é excepcionalmente baixo nessa fase.
{kind=link}
Tamanho do armazenamento
Nossos dados de benchmark foram gerados a partir de 64,55 TB de arquivos MDF proprietários, coletados de 21 veículos de teste MB.OS da Mercedes-Benz durante um período de teste de cinco meses. Para maximizar o desempenho da consulta, mantendo um tamanho de armazenamento aceitável, usamos a compressão zstd para arquivos Parquet e definimos o tamanho do arquivo de destino DELTA como 32MB, com base nos resultados de investigações anteriores. Tamanhos de arquivo pequenos são desejáveis neste cenário para evitar o armazenamento de muitos sinais no mesmo arquivo físico, tornando a exclusão dinâmica de arquivos mais eficiente para consultas altamente seletivas.
Todos os layouts de dados resultaram em tabelas Delta com tamanho comparável aos dados proprietários MDF (consulte a Tabela 2). Em geral, a taxa de compressão do formato de arquivo bruto para as tabelas Delta depende muito de diferentes características dos arquivos MF4. O conjunto de dados subjacente contém até 60.000 sinais por veículo e muitos deles foram registrados apenas na mudança de valor. Para esses sinais, técnicas de compressão como RLE não têm efeito. Para outros conjuntos de dados com apenas milhares, mas com sinais gravados continuamente, descobrimos que o tamanho do armazenamento foi reduzido em >50% em comparação com os arquivos MDF brutos.
Nossos resultados mostraram que as tabelas Liquid Clustering eram significativamente maiores em tamanho quando comparadas às tabelas Z-Ordered (+14% para os layouts de dados RLE). No entanto, considerando os resultados do benchmark de desempenho do tempo de execução apresentados acima, o tamanho de armazenamento adicional exigido pelo layout RLE Liquid Clustering é justificado por seu desempenho superior.
| Formato | Arquivo MDF Proprietário | RLE Z-Ordering | RLE Liquid Clustering |
|---|---|---|---|
| Tamanho do armazenamento [TB] | 64.55 | 67.43 | 77,05 |
Tabela 2: Tamanhos de armazenamento de dados brutos e dos diferentes layouts de dados RLE
Conclusão
Desenvolvemos um modelo de dados semântico e hierárquico para armazenar e analisar eficientemente dados de séries temporais em escala de petabytes de veículos conectados na Databricks Intelligence Platform. Projetado para acesso econômico e escalável, usabilidade e governança robusta, o modelo permite transformar telemetria bruta em insights acionáveis.
Usando dados do mundo real da Mercedes-Benz, mostramos como as tabelas de metadados hierárquicas melhoram o desempenho da análise por meio da filtragem em vários níveis. No exemplo de Prontidão para Mudança Automática de Faixa, essa estrutura permitiu a identificação rápida de sessões e sinais relevantes, reduzindo drasticamente o tempo de processamento.
O benchmarking revelou que a combinação de Run-Length Encoding (RLE) com Liquid Clustering proporcionou o melhor desempenho em todos os tipos de consulta analítica, superando o RLE com Z-Ordering, especialmente no tempo de execução. Embora exigisse mais armazenamento, a compensação foi justificada por ganhos significativos na velocidade da consulta. Os testes de escalabilidade confirmaram um ótimo desempenho mesmo com o aumento dos volumes de dados.
No futuro, a equipe da Databricks publicará soluções sobre 1) como converter arquivos MDF para o modelo de dados recém-introduzido com o Databricks Jobs, 2) como governar conjuntos de dados complexos que contêm grandes frotas ou outros ativos e permitir a fácil descoberta, mantendo a privacidade, a segurança e as complexidades crescentes com o Unity Catalog, e 3) introduzir um framework para que engenheiros sem grande conhecimento em SQL ou Python obtenham insights dos dados de forma eficiente e por conta própria.
Em resumo, o modelo de dados semântico e hierárquico com RLE e Liquid Clustering oferece uma solução poderosa, governada e escalável para análise de séries temporais automotivas, acelerando o desenvolvimento na Mercedes-Benz e promovendo a colaboração orientada por dados em direção a um futuro mais sustentável e eficiente.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.