A pedra de Roseta da CPS: a biblioteca com IA da Claroty
Como um sistema de IA multiagente na Databricks resolve a crise de identidade CPS
por Ben Hazan, Anton Berlinsky, Ohad Avni, Itay Wagner, Guy Zalcman , Dor Bdolach, Ravid Ariely e Gal Sberro
- A Biblioteca de CPS com IA da Claroty resolve a crise de identidade de ativos - onde 88% dos dispositivos CPS não possuem um código de produto exato - automatizando a resolução de entidades em mais de 17 milhões de ativos industriais e de saúde.
- Um sistema de IA multiagente construído sobre os Agentes Personalizados da Databricks combina agentes de raciocínio e NLP com feedback humano no loop, potencializado por uma Arquitetura Medallion no Delta Lake, para transformar sinais fragmentados de dispositivos em uma fonte única e determinística de verdade.
- O resultado: Apenas no MVP, vimos mais de 25% de melhoria na precisão da atribuição de vulnerabilidades e mais de 56% dos dispositivos analisados recebendo novas recomendações de segurança para firmware desatualizado anteriormente invisível.
A Pedra de Roseta de CPS: Por Dentro da Biblioteca Revolucionária com IA da Claroty
Por décadas, o mundo dos Sistemas Ciberfísicos (CPS) - as máquinas que impulsionam nossas fábricas, hospitais e infraestruturas críticas - sofreu de uma "crise de identidade" silenciosa. Enquanto um administrador de TI pode facilmente identificar cada laptop em sua rede, uma equipe de segurança de OT (Tecnologia Operacional) muitas vezes luta para saber exatamente o que está rodando em sua planta.
Um relatório recente da equipe de pesquisa Team82 da Claroty revelou uma realidade chocante: 88% dos ativos de CPS não transmitem um código de produto exato, e 76% usam códigos de produto que diferem dos registros oficiais do fornecedor. Essa falta de um "certificado de nascimento digital" torna o gerenciamento de vulnerabilidades quase impossível, pois as equipes de segurança são forçadas a juntar manualmente informações de fontes inconsistentes.
Para resolver isso, a Claroty recentemente apresentou sua Biblioteca de CPS com IA, um motor de mapeamento autoritativo, o primeiro de seu tipo, projetado para ser o "tradutor universal" para hardware industrial e de saúde.
Em sua essência, este é um desafio de Resolução de Entidades (ER) e o propósito do sistema é resolver a crise de identidade, combinando e consolidando dados ruidosos do mundo real em uma única fonte de verdade. Para alcançar rastreabilidade determinística de alta fidelidade, fomos além dos algoritmos de correspondência padrão, projetando uma arquitetura híbrida que combina métodos clássicos de ER testados em batalha com o poder cognitivo da IA Generativa.
Em resposta a um ponto crítico da indústria, fizemos uma parceria com a Databricks através do programa GenAI MVP. Essa colaboração alavanca nossa oferta especializada e as capacidades de Dados e IA da Databricks para entregar uma solução definitiva para o problema.
Como isso se parece na realidade
Imagine uma situação típica em uma fábrica: a xDome da Claroty encontra um dispositivo com um número de modelo como 1769-L36ERMS/B usando o protocolo CIP. Para uma pessoa ou uma ferramenta de segurança simples, este é apenas um código interno da Rockwell Automation - não está em nenhum banco de dados de vulnerabilidade e não sugere imediatamente nenhum risco.
Para proteger este dispositivo, a equipe geralmente teria que descobrir manualmente o que é, o que envolve:
- Pesquisar na Web: Procurar nos catálogos da Rockwell para descobrir que este código se refere a um controlador Compact GuardLogix 5370.
- Verificar Vulnerabilidades: Pesquisar avisos da CISA por esse nome, o que pode apontar para CVE-2020-6998 como um risco para "versões 33 e anteriores".
- Confirmar Detalhes: Verificar o NVD (National Vulnerability Database) para ver se o CPE (Common Platform Enumeration) específico corresponde, apenas para encontrar uma entrada geral para "CompactLogix 5370 L3" que pode ou não incluir o subtipo "GuardLogix".
Este "trabalho de detetive" manual é frequentemente onde a segurança falha. A Biblioteca de CPS com IA automatiza todo esse processo. Ela reconhece instantaneamente o código interno, o vincula ao nome comercial, identifica as peças e versões de firmware específicas e anexa os CVEs corretos com precisão definitiva - transformando uma string de caracteres confusa em uma configuração clara e segura em milissegundos.
Resolvendo a Crise de Identidade com Visibilidade Determinística
A Biblioteca de CPS não é apenas um banco de dados; é um sistema de IA multiagente que permite a remediação "de última milha". Ao fazer parceria com gigantes da indústria, a Claroty construiu um grafo de evidências que reconcilia dados de rede confusos em uma única fonte de verdade.
Principais Avanços Incluem:
- Rastreabilidade Determinística: Mesmo quando um dispositivo relata dados mínimos, a biblioteca usa inferência estatística e lógica guiada por domínio para triangular sua identidade exata.
- Atribuição de Vulnerabilidade: Ao identificar subcomponentes específicos e árvores de firmware, a biblioteca melhorou a precisão na identificação de vulnerabilidades em 25%.
- Insights Acionáveis: Em testes iniciais, 56% dos dispositivos analisados receberam recomendações de segurança novas ou atualizadas para firmware desatualizado que antes eram invisíveis para as equipes de segurança.
Por Dentro: O Motor de Inteligência de Dados da Databricks
Para gerenciar um catálogo global de mais de 17 milhões de ativos e suas intrincadas dependências, a Claroty utiliza a Plataforma de Inteligência de Dados da Databricks como sua espinha dorsal unificada. Ao adotar uma arquitetura Lakehouse, a Claroty elimina silos de dados tradicionais, permitindo a ingestão de diversos conjuntos de dados - de protocolos proprietários de OT e chamadas de API a manuais PDF de fornecedores não estruturados - em um único ambiente escalável. Essa base fornece a computação de alto desempenho necessária para executar modelos complexos de inferência estatística em milhões de pontos de dados, garantindo que cada CPS-ID (o novo padrão da indústria para identidade de sistemas ciberfísicos pela Claroty) seja apoiado por integridade de dados rigorosa e inteligência entre silos.
Engenharia de Dados em Escala: O Pipeline Medallion
Alimentando este ecossistema está uma robusta Arquitetura Medallion construída sobre Delta Lake e governada no Unity Catalog. A jornada começa na camada Bronze, onde cargas JSON brutas e heterogêneas são capturadas em tabelas Delta somente de adição. A partir daí, para um pipeline de promoção - lendo do Delta Change Data Feed (CDF) - aplica dinamicamente um registro de mapeamento para transformar evidências brutas em um esquema canônico governado. Ao utilizar a evolução de esquema e viagem no tempo do Delta Lake, a Claroty mantém uma cadeia de custódia inquebrável; cada registro de ativo é rastreável até seu artefato bruto original e a versão específica de mapeamento que o classificou, garantindo auditabilidade completa mesmo nos ambientes industriais mais sensíveis.
Inteligência Multiagente via Agentes Personalizados da Databricks
A parte mais sofisticada deste motor híbrido é o uso dos Agentes Personalizados da Databricks. Em vez de depender de um único modelo monolítico, a Claroty projetou um Sistema Multiagente Orquestrado, uma rede sincronizada onde agentes de IA especializados colaboram para interpretar sinais complexos.
Para alimentar esses agentes com contexto confiável, combinamos análise estatística clássica de dados estruturados coletados de fontes proprietárias com técnicas avançadas de NLP que extraem sinais do ruído inerente à documentação do fornecedor, folhas de dados técnicas e fontes abertas da web. O Unity Catalog da Databricks fornece a base de dados governada necessária para unificar esses diversos conjuntos de dados, enquanto os pipelines impulsionados pelo Spark processam e normalizam informações em escala. Juntas, essas capacidades sintetizam informações fragmentadas e inconsistentes nas respostas precisas e contextualizadas que os agentes precisam para fornecer correspondências de resolução de entidades precisas.
O sistema é construído em torno de três componentes principais:
- Agentes de NLP: Analisam dados complexos de formato misto - incluindo strings de nomenclatura derivadas de protocolos e marcadores de software obscuros que modelos padrão frequentemente perdem.
- Agentes de Raciocínio: Aplicam pontuação de confiança e testes estatísticos para ponderar evidências, discriminando sinais de alta fidelidade do ruído para garantir a integridade dos dados.
- Human-in-the-loop (HITL): Um mecanismo de feedback crítico que sinaliza mapeamentos de baixa confiança para revisão por um especialista. A saída dessas sessões é realimentada no sistema, retreinando os modelos para ganhos contínuos de precisão.
Inovação através das Capacidades da Databricks
O sucesso desta arquitetura reside não apenas nos próprios agentes, mas no ecossistema de ponta a ponta construído na Databricks que os impulsiona. Alavancamos toda a amplitude da plataforma para passar do MVP para a produção com velocidade e confiabilidade:
1. Inteligência Específica de Domínio via Model Serving Para lidar com as nuances de saúde e OT, embeddings genéricos eram insuficientes para o nível de precisão que exigimos. Identificamos que, para o "Tradutor Universal" ter sucesso de verdade, arquiteturas RAG genéricas devem evoluir para frameworks específicos de domínio. Atualmente, preenchemos essa lacuna implantando modelos de embedding médicos de ponta como endpoints personalizados usando Databricks Model Serving. No entanto, ao olharmos para o futuro, vemos o fine-tuning desses modelos como o próximo passo lógico para garantir que nossos agentes entendam os dialetos industriais mais obscuros com precisão determinística.
2. RAG Avançado e Extração de Informações Aproveitamos o Knowledge Assistant para construir sistemas RAG (Retrieval-Augmented Generation) robustos capazes de ingerir grandes quantidades de documentação proprietária. Ao utilizar um agente de Extração de Informações, podemos analisar estruturalmente documentos proprietários não estruturados, transformando texto bruto em inteligência acionável para a Biblioteca de CPS.
3. Gerenciamento Completo do Ciclo de Vida com MLflow que serve como a espinha dorsal do nosso ciclo de vida de desenvolvimento de ML, fornecendo uma plataforma unificada desde a fase inicial do MVP até a avaliação rigorosa e a implantação final.
- Avaliação Contínua: Implementamos uma estratégia abrangente de avaliação usando "LLM como Juiz" juntamente com sessões de rotulagem manual. As capacidades do MLflow nos permitiram avaliar constantemente o desempenho do modelo para prevenir o desvio de conceito.
- Observabilidade e Monitoramento: Em produção, utilizamos os recursos de observabilidade do MLflow para monitorar a integridade do agente em tempo real. Isso inclui o rastreamento do uso de tokens e custos de infraestrutura, a identificação de gargalos de latência e a detecção de possíveis bugs antes que eles afetem os usuários. Uma área de foco estratégico é a relação custo-benefício dos nossos índices de AI Search. Embora o desempenho seja de ponta, a falta atual de um modelo "scale-to-zero" para endpoints vetoriais — uma nuance particularmente relevante para a natureza intermitente e orientada a eventos dos dados de segurança industrial — exige que projetemos padrões arquitetônicos específicos para manter um ROI alto durante períodos ociosos.
Ao fundir métodos clássicos de Entity Resolution com uma estratégia sofisticada e orquestrada de múltiplos agentes — suportada pela infraestrutura robusta da Databricks — criamos uma camada de inteligência autoaperfeiçoável, econômica e altamente precisa. Este sistema finalmente preenche a lacuna entre dados de rede desorganizados e a fonte única de verdade, resolvendo a crise de identidade para a segurança de CPS.
Automação usando Jobs, Pipelines e LLM
Para lidar com a vasta quantidade de informações de várias fontes, a Claroty usa Lakeflow Jobs para orquestrar todo o processo - de dados brutos a uma tabela bem estruturada.
Um dos nossos pipelines orquestra um processo ETL que analisa CSAF, um advisory de segurança formatado em JSON, em uma estrutura tabular. Neste processo, cada etapa lê e escreve entradas em uma delta table dedicada.
Neste ETL, e em muitos outros casos de uso, usamos LLMs para enriquecer os dados - de tarefas de classificação e AI Functions como ai_query, usando vários Serving endpoints e MLflow para avaliar as respostas que recebemos do LLM, usando métricas estatísticas e LLM-as-a-judge, e monitorar o custo.
Para manter este pipeline confiável em escala, usamos a abordagem LLM as a Judge para pontuar continuamente a qualidade das nossas próprias saídas de LLM. Em vez de depender apenas de ground truth totalmente rotulados — que muitas vezes estão ausentes ou são ambíguos em dados de CPS do mundo real — permitimos que um modelo juiz dedicado revise a resposta de outro modelo e decida se ela parece aceitável. O trabalho do juiz é simples e conservador: marcar cada resultado como aprovado, parece correto, falha, parece errado ou desconhecido, sem informações suficientes. Todos esses Juízes são armazenados em Delta table. Usando este método, nossas equipes podem carregar amostras de avaliação, iniciar custom MLflow GenAI judges e executar avaliações estruturadas. As capacidades nativas de monitoramento MLflow GenAI nos dão uma maneira consistente de monitorar a qualidade, comparar versões e capturar regressões em muitos casos de uso de LLM — sem construir uma stack de avaliação personalizada para cada novo fluxo de trabalho.
Integridade Transacional com Lakebase
Para que a "Biblioteca" funcione, os dados devem ser consistentes e altamente disponíveis. A Claroty integra Lakebase, uma camada de dados transacional totalmente gerenciada na Databricks. O Lakebase é construído sobre Postgres e fornece o desempenho de baixa latência necessário para consultas em tempo real, mantendo um link contínuo com o Lakehouse mais amplo para processamento analítico, permitindo restrições rigorosas para garantir que nossos dados mantenham sua alta qualidade e garantindo que os mapeamentos de ativos permaneçam precisos mesmo quando as configurações mudam.
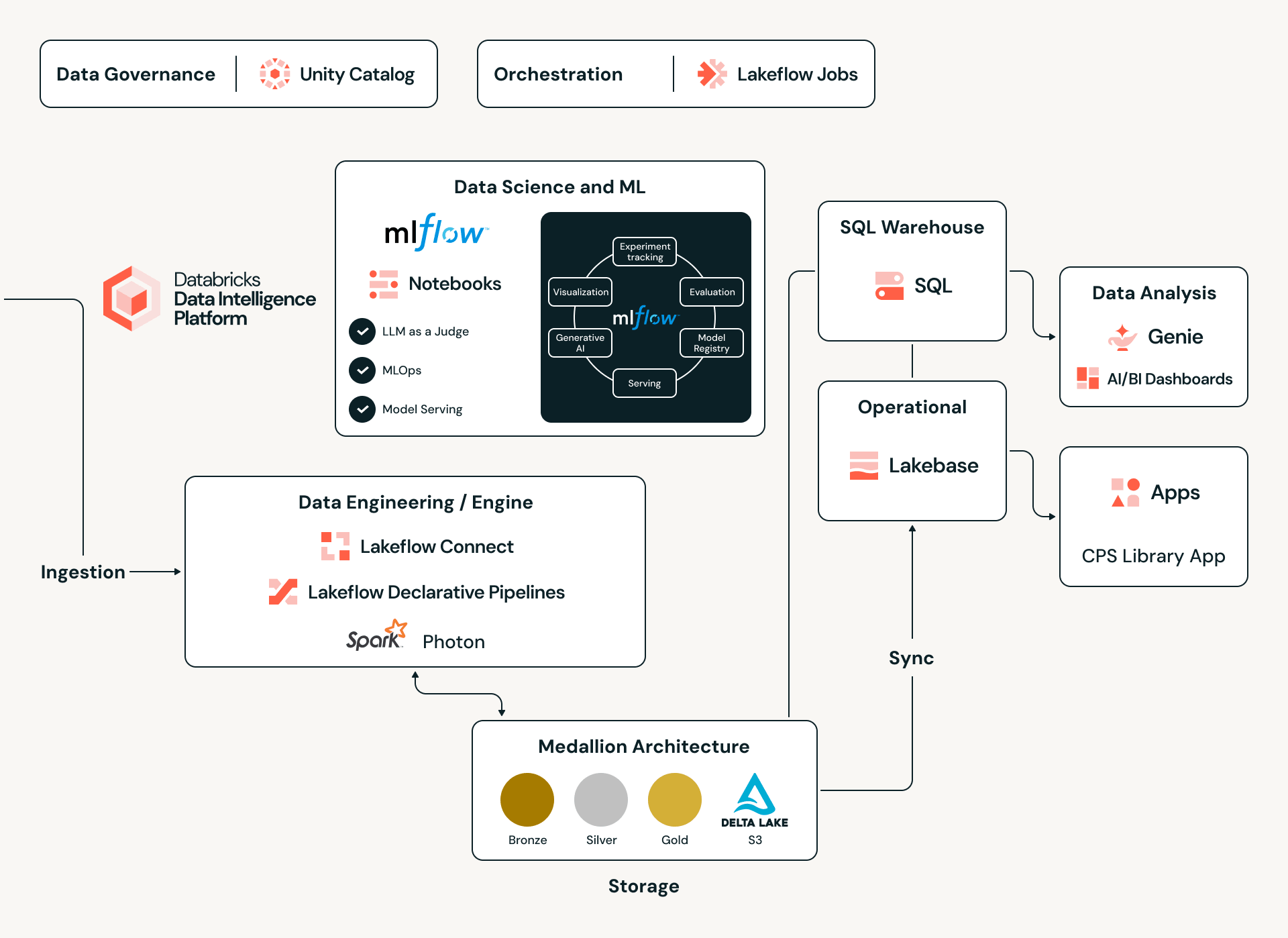
Inovação Rápida com Databricks Apps
Para reunir todas essas percepções, utilizamos Databricks Apps, um recurso que permite à Claroty construir e implantar aplicativos full-stack e intensivos em dados diretamente no ambiente Databricks. Usando frameworks de UI modernos (como React ou Streamlit) para o frontend, e Lakebase, o banco de dados OLTP Postgres totalmente gerenciado da Databricks, para cargas de trabalho transacionais, podemos hospedar tanto a lógica do aplicativo quanto os dados operacionais na mesma plataforma que nosso lakehouse. Isso significa que o aplicativo herda a segurança, governança e autenticação integradas da plataforma (via Unity Catalog e OAuth), ao mesmo tempo que elimina a necessidade de servidores de aplicativos, bancos de dados e pipelines de implantação separados. O que tradicionalmente exigiria a junção de várias pilhas de tecnologia e serviços é consolidado em uma única solução robusta e econômica.
Human-in-the-Loop via Databricks Apps
Embora nossos pipelines de IA automatizem o trabalho pesado, a principal necessidade no campo para criar confiança é o feedback de SMEs (Subject Matter Experts) com intervenção humana. Com o Databricks App e o Lakebase, permitimos uma visão transparente e um ciclo de feedback "human-in-the-loop" contínuo. Esta interface intuitiva permite que especialistas do domínio revisem classificações, corrijam e enriqueçam entidades, e alimentem dados de alta fidelidade e validados de volta em nossos pipelines MLflow e migração de P&D, garantindo que o sistema se torne mais inteligente e preciso ao longo do tempo.
O Futuro da Resiliência
Ao combinar a profunda expertise de domínio da Claroty em protocolos de OT com o poder da plataforma Databricks, a Biblioteca CPS está estabelecendo um novo padrão. Não se trata mais apenas de ver que um dispositivo existe, mas de saber exatamente o que ele é, quais riscos ele carrega e como corrigi-lo com total confiança.
A liderança da Claroty neste espaço foi recentemente validada ao ser nomeada Líder no Gartner® Magic Quadrant™ 2025 para Plataformas de Proteção de CPS, posicionada mais alta em "Capacidade de Execução". À medida que a indústria avança, essa abordagem "identity-first" será a base para avançar a resiliência em todos os ambientes conectados.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.