The Rosetta stone of CPS: Claroty’s AI-powered library
How a multi-agent AI system on Databricks solves the CPS identity crisis
by Ben Hazan, Anton Berlinsky, Ohad Avni, Itay Wagner, Guy Zalcman , Dor Bdolach, Ravid Ariely and Gal Sberro
- Claroty's AI-Powered CPS Library solves the asset identity crisis - where 88% of CPS devices lack an exact product code - by automating entity resolution across 17M+ industrial and healthcare assets.
- A multi-agent AI system built on Databricks' Custom Agents combines NLP and reasoning agents with human-in-the-loop feedback, powered by a Medallion Architecture on Delta Lake, to turn fragmented device signals into a deterministic single source of truth.
*The result: In MVP alone, we've seen over 25% improvement in vulnerability attribution accuracy and more than 56% of analyzed devices receiving new security recommendations for previously invisible outdated firmware.
The Rosetta Stone of CPS: Inside Claroty’s Revolutionary AI-Powered Library
For decades, the world of Cyber-Physical Systems (CPS) - the machinery that powers our factories, hospitals, and critical infrastructures has suffered from a silent "identity crisis". While an IT administrator can easily identify every laptop on their network, an OT (Operational Technology) security team often struggles to know exactly what’s running on their plant floor.
A recent report by Claroty’s Team82 research team revealed a staggering reality: 88% of CPS assets do not transmit an exact product code, and 76% use product codes that differ from the vendor's official records. This lack of a "digital birth certificate" makes vulnerability management nearly impossible, as security teams are forced to manually puzzle together information from inconsistent resources.
To solve this, Claroty recently unveiled its AI-Powered CPS Library, a first-of-its-kind authoritative mapping engine designed to be the "universal translator" for industrial and healthcare hardware.
At its core, this is an Entity Resolution (ER) challenge and the purpose of the system is to solve the identity crisis by matching and consolidating noisy real-world data into a single source of truth. To achieve high-fidelity deterministic traceability, we moved beyond standard matching algorithms, engineering a hybrid architecture that combines battle-tested, classic ER methods with the cognitive power of Generative AI.
In response to a critical industry pain point, we partnered with Databricks through their GenAI MVP program. This collaboration leverages our specialized offering and Databricks’ Data & AI capabilities to deliver a definitive solution to the problem.
What it looks like in reality
Imagine a typical situation in a factory: Claroty’s xDome finds a device with a model number like 1769-L36ERMS/B using the CIP protocol. For a person or a simple security tool, this is just an internal Rockwell Automation code—it’s not in any vulnerability databases and doesn't immediately suggest any risk.
To secure this device, staff would usually have to manually figure out what it is, which involves:
- Searching the Web: Looking through Rockwell’s catalogs to find out this code means it's a Compact GuardLogix 5370 controller.
- Checking for Vulnerabilities: Searching CISA warnings for that name, which might point to CVE-2020-6998 as a risk for "versions 33 and earlier."
- Confirming Details: Checking the NVD (National Vulnerability Database) to see if the specific CPE (Common Platform Enumeration) matches, only to find a general entry for "CompactLogix 5370 L3" that may or may not include the "GuardLogix" sub-type.
This manual "detective work" is often where security fails. The AI-Powered CPS Library automates this entire process. It instantly recognizes the internal code, links it to the commercial name, identifies the specific parts and firmware versions, and attaches the correct CVEs with definite accuracy—turning a confusing string of characters into a clear, secure setup in milliseconds.
Solving the Identity Crisis with Deterministic Visibility
The CPS Library isn't just a database; it’s a multi-agent AI system that enables "last-mile" remediation. By partnering with industry giants, Claroty has built an evidence graph that reconciles messy network data into a single source of truth.
Key Breakthroughs Include:
- Deterministic Traceability: Even when a device reports minimal data, the library uses statistical inference and domain-guided logic to triangulate its exact identity.
- Vulnerability Attribution: By identifying specific sub-components and firmware trees, the library has improved the accuracy of identifying vulnerabilities by 25%.
- Actionable Insights: In early tests, 56% of analyzed devices received new or updated security recommendations for outdated firmware that were previously invisible to security teams.
Under the Hood: The Databricks Data Intelligence Engine
To manage a global catalog of 17 million+ assets and their intricate dependencies, Claroty leverages the Databricks Data Intelligence Platform as its unified backbone. By adopting a Lakehouse architecture, Claroty eliminates traditional data silos, enabling the ingestion of diverse datasets—from proprietary OT protocols and API calls to unstructured vendor PDF manuals—into a single, scalable environment. This foundation provides the high-performance compute necessary to run complex statistical inference models across millions of data points, ensuring that every CPS-ID (the new industry standard for cyber-physical system identity by Claroty) is backed by rigorous data integrity and cross-silo intelligence.
Data Engineering at Scale: The Medallion Pipeline
Powering this ecosystem is a robust Medallion Architecture built on Delta Lake and governed in Unity Catalog. The journey begins in the Bronze layer, where raw, heterogeneous JSON payloads are captured in append-only Delta tables. From there, to a promotion pipeline— reading from Delta Change Data Feed (CDF)—dynamically applies a mapping registry to transform raw evidence into a governed, canonical schema. By utilizing Delta Lake’s schema evolution and time travel, Claroty maintains an unbreakable chain of custody; every asset record is traceable back to its original raw artifact and the specific mapping version that classified it, ensuring full auditability in even the most sensitive industrial environments.
Multi-Agent Intelligence via Databricks' Custom Agents
The most sophisticated part of this hybrid engine is its use of the Databricks' Custom Agents Rather than relying on a single monolithic model, Claroty engineered an Orchestrated Multi-Agent System, a synchronized network where specialized AI agents collaborate to interpret complex signals.
To fuel these agents with reliable context, we combine classic statistical analysis of structured data gathered from proprietary sources with advanced NLP techniques that extract signals from the noise inherent in vendor documentation, technical datasheets, and open web sources. Databricks' Unity Catalog provides the governed data foundation needed to unify these diverse datasets, while Spark-powered pipelines process and normalize information at scale. Together, these capabilities synthesize fragmented, inconsistent information into the precise, contextualized answers the agents need to deliver accurate entity resolution matchings.
The system is built around three core components:
- NLP Agents: Parse complex, mixed-format data — including protocol-derived naming strings and obscure software markers that standard models often miss.
- Reasoning Agents: Apply confidence scoring and statistical tests to weigh evidence, discriminating high-fidelity signals from noise to ensure data integrity.
- Human-in-the-loop (HITL): A critical feedback mechanism that flags low-confidence mappings for expert to review. The output from these sessions is fed back into the system, retraining the models for continuous accuracy gains.
Innovation through Databricks Capabilities
The success of this architecture lies not just in the agents themselves, but in the end-to-end ecosystem built on Databricks that powers them. We leveraged the full breadth of the platform to move from MVP to production with speed and reliability:
1. Domain-Specific Intelligence via Model Serving To tackle the nuances of healthcare and OT, generic embeddings were insufficient for the level of precision we require. We identified that for the 'Universal Translator' to truly succeed, generic RAG architectures must evolve into domain-specific frameworks. We currently bridge this gap by deploying best-in-class medical embedding models as custom endpoints using Databricks Model Serving. However, as we look to the future, we see fine-tuning these models as the next logical step to ensure our agents understand the most obscure industrial dialects with deterministic accuracy.
2. Advanced RAG & Information Extraction We harnessed the Knowledge Assistant to build robust RAG (Retrieval-Augmented Generation) systems capable of ingesting vast amounts of proprietary documentation. By utilizing an Information Extraction agent, we can structurally parse unstructured proprietary documents, turning raw text into actionable intelligence for the CPS Library.
3. Full Lifecycle Management with MLflow that serves as the backbone of our ML development lifecycle, providing a unified platform from the initial MVP phase through to rigorous evaluation and final deployment.
- Continuous Evaluation: We implemented a comprehensive evaluation strategy using "LLM as a Judge" alongside manual labeling sessions. MLflow capabilities allowed us to constantly evaluate model performance to prevent concept drift.
- Observability & Monitoring: In production, we utilize MLflow’s observability features to monitor agent health in real-time. This includes tracking token usage and infrastructure costs, identifying latency bottlenecks, and detecting potential bugs before they impact users. One area of strategic focus is the cost-efficiency of our AI Search indices. While the performance is world-class, the current lack of a "scale-to-zero" model for vector endpoints—a nuance particularly relevant for the bursty, event-driven nature of industrial security data—requires us to design specific architectural patterns to maintain high ROI during idle periods.
By fusing classic Entity Resolution methods with a sophisticated, orchestrated multi-agent strategy—supported by the robust infrastructure of Databricks—we have created a self-improving, cost-efficient, and highly accurate intelligence layer. This system finally bridges the gap between messy network data and the single source of truth, solving the identity crisis for CPS security.
Automation using Jobs, Pipelines and LLM
To handle the vast amount of information from various sources, Claroty uses Lakeflow Jobs to orchestrate the full process - from raw data to a well structured table.
One of our pipelines orchestrates an ETL process that parses CSAF, a JSON formatted security advisory, into a tabular structure. In this process, each step reads and writes entries into a dedicated delta table.
In this ETL, and in many more use cases, we use LLMs to enrich the data - from classification tasks and AI Functions like ai_query, using various Serving endpoints and MLflow to evaluate the answers we get from the LLM, using statistic metrics and LLM-as-a-judge, and monitor the cost.
To keep this pipeline reliable at scale, we use an LLM as a Judge approach to continuously score the quality of our own LLM outputs. Instead of relying only on fully labeled ground truth—which is often missing or ambiguous in real-world CPS data—we let a dedicated judge model review another model’s response and decide whether it looks acceptable. The judge’s job is simple and conservative: mark each result as pass, looks correct, fail, looks wrong, or unknown, not enough information. All of these Judges are stored in Delta table. Using this method, our teams can load evaluation samples, spin up custom MLflow GenAI judges, and run structured evaluations. MLflow GenAI monitoring native capabilities gives us a consistent way to monitor quality, compare versions, and catch regressions across many LLM use cases—without building a bespoke evaluation stack for every new workflow.
Transactional Integrity with Lakebase
For the "Library" to work, the data must be consistent and highly available. Claroty integrates Lakebase, a fully managed transactional data layer on Databricks. Lakebase is built on Postgres and provides the low-latency performance required for real-time queries while maintaining a seamless link to the broader Lakehouse for analytical processing, allowing strict constraints to make sure our data keeps its high quality and ensuring that asset mappings remain accurate even as configurations drift.
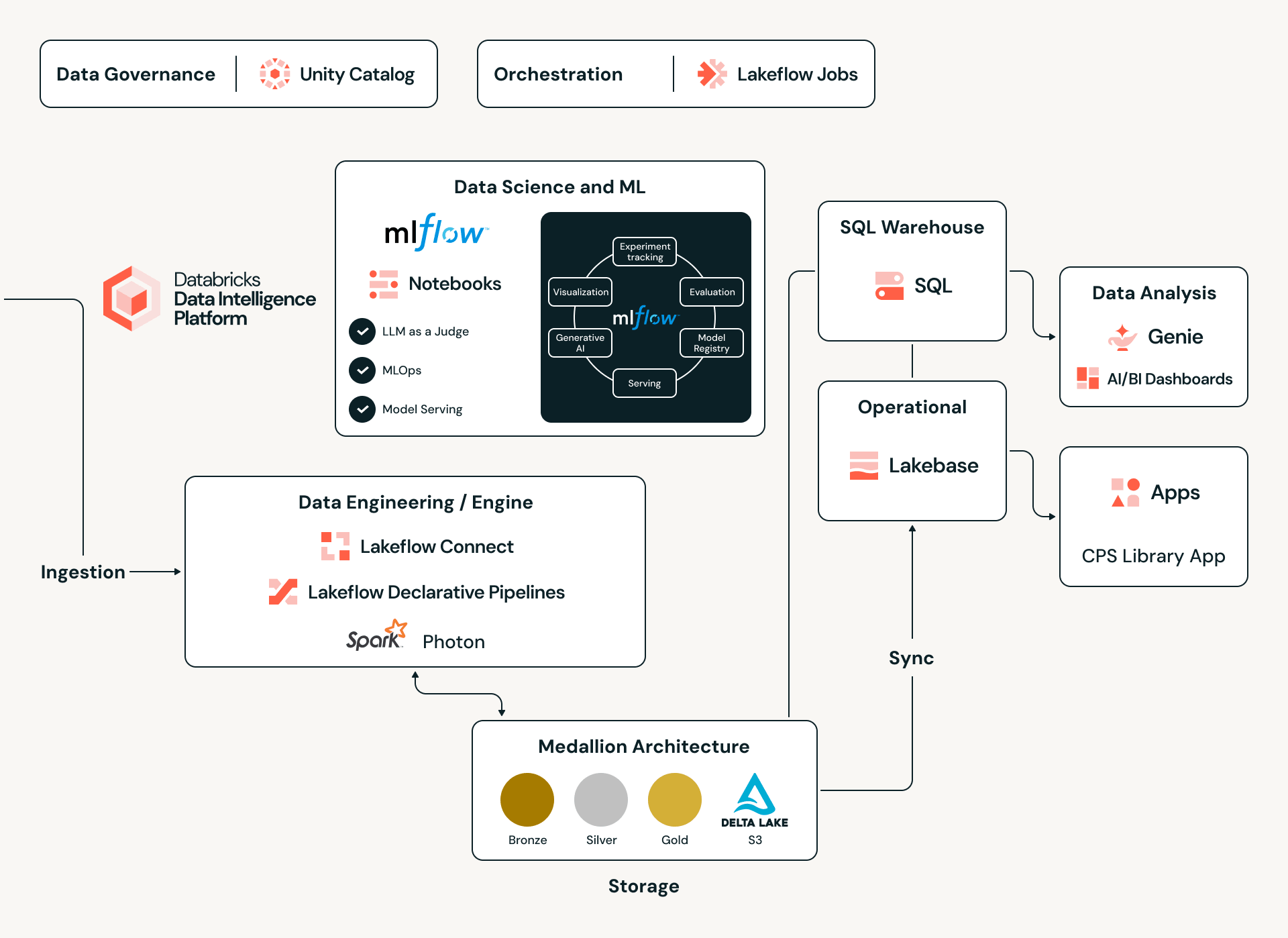
Rapid Innovation with Databricks Apps
To bring all these insights together, we utilize Databricks Apps, a capability that lets Claroty build and deploy full-stack, data-intensive applications directly within the Databricks environment. Using modern UI frameworks (such as React or Streamlit) for the frontend, and Lakebase, Databricks' fully managed Postgres OLTP database, for transactional workloads, we can host both application logic and operational data on the same platform as our lakehouse. This means the application inherits the platform's built-in security, governance, and authentication (via Unity Catalog and OAuth), while eliminating the need for separate app servers, databases, and deployment pipelines. What would traditionally require stitching together multiple technology stacks and services is consolidated into a single, cost-effective, and robust solution.
Human-in-the-Loop via Databricks Apps
While our AI pipelines automate the heavy lifting, the top need in the field to create trust is human-in-the-loop SME feedback. With the Databricks App and Lakebase, we enable a transparent view and a seamless "human-in-the-loop" feedback cycle. This intuitive interface allows domain experts to review classifications, correct and enrich entities, and feed high-fidelity, validated data back into our MLflow pipelines and R&D migration, ensuring the system grows smarter and more accurate over time.
The Future of Resilience
By combining Claroty’s deep domain expertise in OT protocols with the power of the Databricks platform, the CPS Library is setting a new standard. It is no longer just about seeing that a device exists, it is about knowing exactly what it is, what risks it carries, and how to fix it with total confidence.
Claroty’s leadership in this space was recently validated by being named a Leader in the 2025 Gartner® Magic Quadrant™ for CPS Protection Platforms, positioned highest for "Ability to Execute". As the industry moves forward, this "identity-first" approach will be the foundation for advancing resilience in every connected environment.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.