Transformando relatórios de manutenção solar e eólica com Genie e agentes de IA
Como a Plenitude usa o Databricks Genie e o Agent Bricks para transformar PDFs de manutenção não estruturados em uma camada de dados pesquisável e análises em linguagem natural em usinas solares e eólicas.
por Maria Vallarelli
- A Plenitude desenvolveu um sistema baseado em agentes no Databricks Genie que converte PDFs não estruturados de manutenção solar e eólica em um modelo de dados unificado e consultável.
- A solução usa o Genie, combinado com metadados semânticos do Unity Catalog e AI Functions, para permitir que os usuários façam perguntas em linguagem natural e criem visualizações em diferentes usinas e ao longo do tempo.
- Os primeiros resultados incluem análises multiusinas mais rápidas, acesso por autoatendimento governado com segurança em nível de linha e uma base para manutenção preditiva em ativos críticos, como inversores.
De PDFs de manutenção a insights acionáveis com agentes de AI
Os fornecedores de operação e manutenção de usinas solares e eólicas normalmente entregam relatórios em formato PDF, com informações essenciais distribuídas em textos livres, tabelas e imagens. Esse formato é acessível, mas não escalável: as equipes precisam ler manualmente cada documento para entender falhas, tendências ou problemas recorrentes, tornando as comparações entre usinas lentas e inconsistentes à medida que o número de ativos cresce.
A Plenitude e a Databricks criaram um sistema baseado em agentes que converte esses relatórios de manutenção em PDF em dados estruturados. A ideia central é simples: transformar documentos em dados e, em seguida, usar um agente de AI para extrair insights acionáveis desses dados. Agora, os usuários podem fazer perguntas em linguagem natural, analisar tendências ao longo do tempo, comparar usinas e exportar resultados estruturados, em vez de navegar pelos relatórios um por um.
Arquitetura baseada em agentes para análise de dados de PDFs
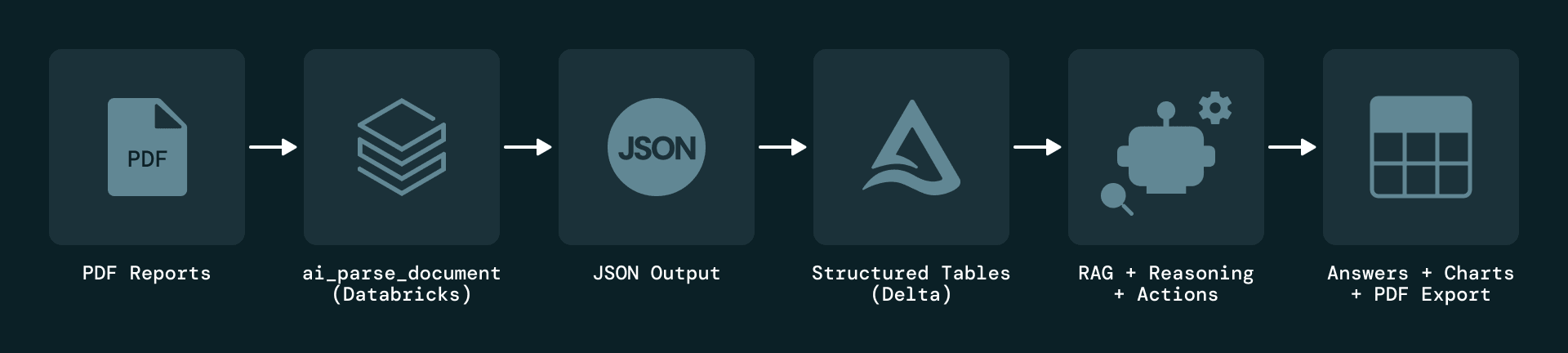
A solução começa com a ingestão orientada a eventos de relatórios em PDF no nível da usina. Cada novo relatório aciona um Databricks Job que analisa o documento e aplica a extração baseada em LLM. Os elementos extraídos são serializados como JSON e armazenados no Delta Lake, que mantém o histórico completo de versões para auditoria e reprodução.
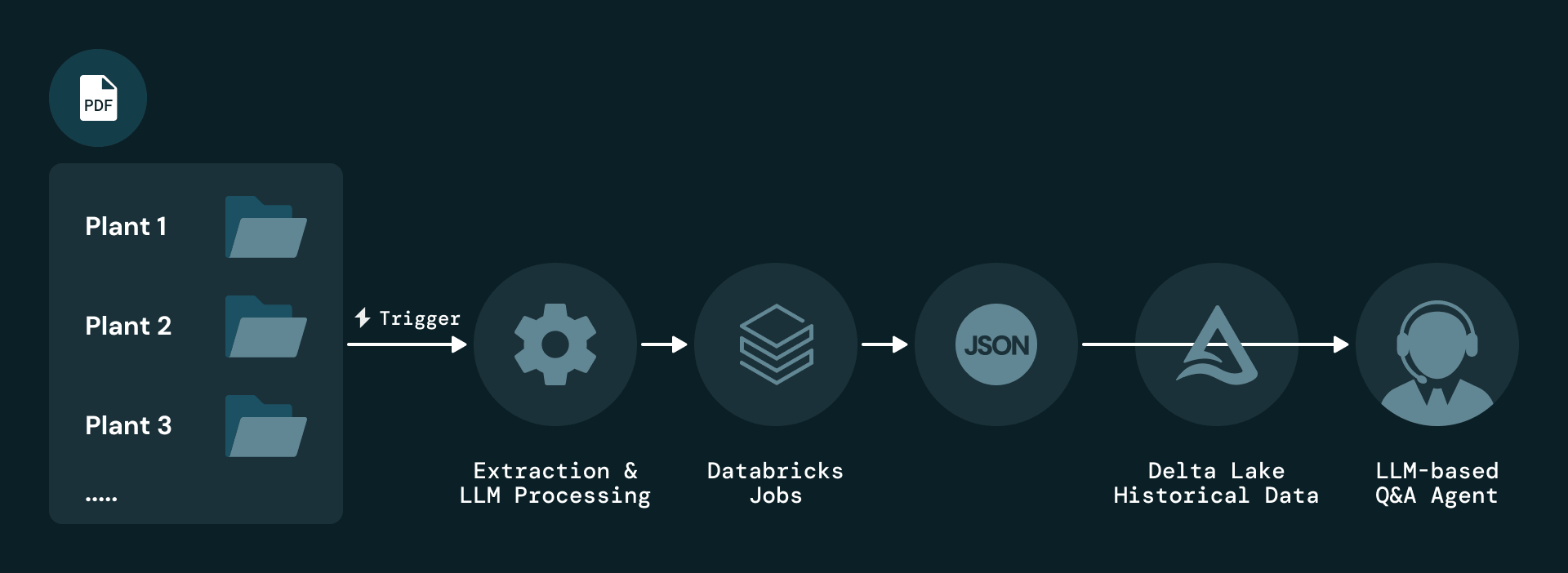
Para resolver o problema fundamental de que as informações de manutenção residem quase inteiramente em PDFs não estruturados, a Plenitude usa as AI Functions de Document Intelligence do Databricks — especificamente ai_parse_document, para extrair vários tipos de elementos de cada página, incluindo blocos de texto, tabelas, figuras e metadados. Cada elemento é enriquecido com atributos como usina, período do relatório, número da página e tipo de conteúdo, e cada registro mantém um link direto de volta ao relatório original para rastreabilidade.
Essa estrutura desbloqueia recursos avançados:
- Filtragem por tempo, categoria e geografia.
- Identificação de tipos de conteúdo e uso de coordenadas espaciais.
- Rastreamento de cada insight de volta ao PDF original.
- Integração com ferramentas de BI e agentes digitais sem alterar os documentos subjacentes.
Em vez de arquivos estáticos, os relatórios de manutenção tornam-se uma camada de dados persistente pronta para análises avançadas e raciocínio de agentes.
Processamento de dados no Databricks: do PDF ao Delta Lake
A arquitetura é organizada em três camadas principais: ingestão e parsing, estruturação de dados e interação baseada em agentes.
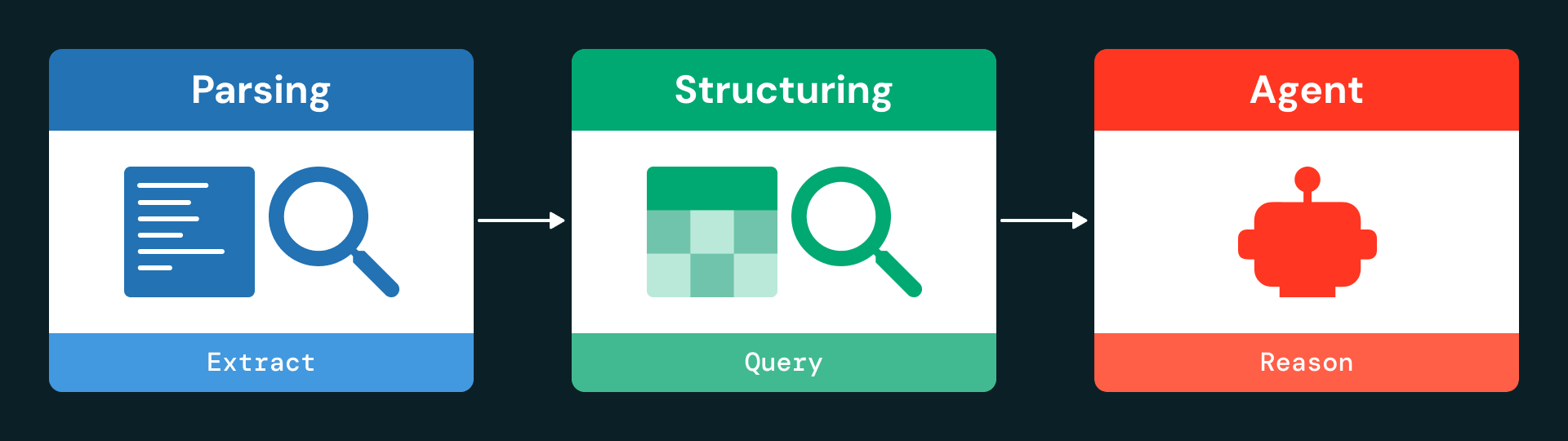
Etapa 1: parsing
Usando ai_parse_document, o pipeline extrai texto, tabelas e metadados de cada página e os serializa como objetos JSON estruturados. Mesmo tabelas complexas são capturadas com contexto completo, incluindo sua localização na página e representação em HTML.
Etapa 2: normalização e armazenamento
Para cada página (page_id) e objeto (id), o sistema cria uma linha em uma tabela do Delta Lake. Cada linha contém:
- O conteúdo JSON extraído.
- Identificadores de página e de objeto.
- Coordenadas (coords) que representam a caixa delimitadora na página.
- Tipo de conteúdo (por exemplo, texto ou tabela).
- Metadados de alto valor, como mês, ano, nome do arquivo, categoria e país.
Esse modelo normalizado transforma PDFs em um conjunto de dados unificado e consultável que é transparente e fácil de integrar com outras fontes, preservando a rastreabilidade total de volta aos documentos originais.
Etapa 3: espaço Genie e modo Agente
Sobre essa camada de dados refinada, a Plenitude cria um espaço Genie dedicado e, em seguida, aproveita o modo Agente do Genie para realizar pesquisas profundas (Deep Research) nos dados. O Genie usa as tabelas estruturadas do Delta Lake como seu contexto principal e permite que os usuários interajam com os dados de manutenção usando linguagem natural.
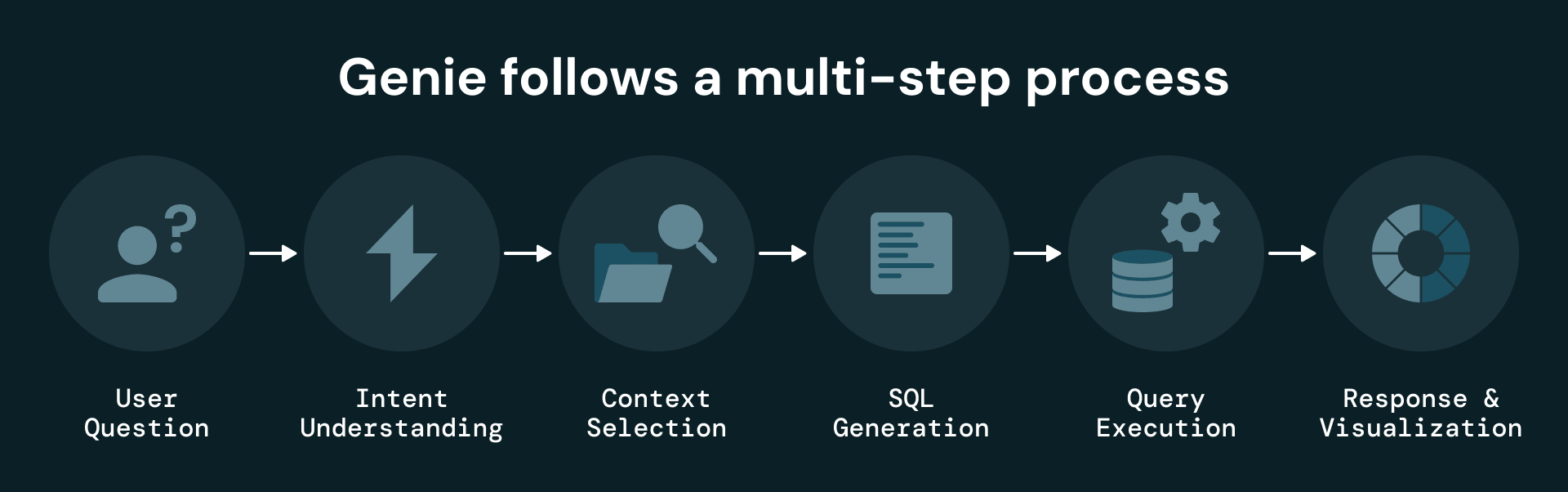
Quando um usuário faz uma pergunta, o Genie:
- Usa metadados semânticos no Unity Catalog para identificar tabelas e colunas disponíveis.
- Aproveita descrições detalhadas de colunas, um repositório de conhecimento (knowledge store) selecionado e amostras de SQL para guiar a geração de consultas.
- Gera e executa SQL na camada estruturada.
- Retorna respostas, visualizações e, opcionalmente, resultados exportáveis.
Esse design permite que o Genie entenda tanto a semântica de negócios dos dados de manutenção quanto sua estrutura subjacente, resultando em respostas precisas e sensíveis ao contexto.
Por que metadados e instruções são importantes para o Genie
Para obter resultados confiáveis de conjuntos de dados complexos derivados de PDFs, apenas o contexto não é suficiente. A Plenitude descobriu que dois padrões de design são essenciais: metadados ricos e instruções explícitas para o espaço Genie.
Metadados como um contrato com o agente
Descrições bem definidas de tabelas e colunas dizem ao Genie o que cada campo significa e como deve ser usado. For exemplo, page_id identifica a página de origem no relatório original, type indica se o elemento é texto ou uma tabela, coords codifica a localização espacial e content contém o texto extraído ou a representação da tabela. Esses metadados transformam o JSON bruto em conhecimento compreensível sobre o qual o Genie pode raciocinar.
Instruções gerais como fundamentação operacional
Quando os dados estão fragmentados ou abrangem várias páginas, as instruções específicas do domínio adicionadas ao knowledge store local do espaço Genie tornam-se essenciais. A Plenitude codifica regras para lidar com tabelas de várias páginas, ignorar artefatos HTML, excluir linhas de cabeçalho e aplicar filtros específicos da usina.
Um exemplo prático: mesmo com metadados completos, o Genie pode calcular um total trimestral incorreto se somar colunas YTD ou ignorar meses ausentes. Ao adicionar instruções claras como “use apenas colunas no nível do mês, nunca campos YTD” e “valide se todos os meses necessários estão presentes antes de somar”, a equipe fornece ao Genie proteções operacionais que garantem resultados consistentes.
Essas instruções específicas do espaço Genie, combinadas com os metadados do Unity Catalog, ajudam o Genie a aplicar a lógica correta para interpretar os dados adequadamente.
Usando o Genie e o Agent Bricks para fluxos de trabalho de agentes escaláveis
Embora o Genie forneça uma experiência poderosa de agente de pesquisa sobre a camada de manutenção estruturada, a Plenitude também precisa de fluxos de trabalho repetíveis e orquestração para dar suporte a um conjunto crescente de casos de uso. O Agent Bricks é o próximo passo nessa evolução.
Com o Agent Bricks, a Plenitude pode passar de padrões de “LLM mais prompt” para fluxos de trabalho de agentes que executam sequências de ações em nome de analistas e engenheiros de manutenção. As mesmas tabelas selecionadas do Delta Lake, metadados e instruções que alimentam o Genie podem ser reutilizados por agentes do tipo Supervisor criados com o Agent Bricks para:
- Decompor perguntas complexas em tarefas analíticas menores.
- Chamar os fluxos de ferramentas do Genie para gerar e executar SQL.
- Acionar ações downstream, como geração de relatórios ou criação de alertas.
O que antes exigia a conexão manual de prompts, ferramentas e lógica de validação agora pode ser centralizado no Agent Bricks, na mesma plataforma Databricks que gerencia os dados.
Otimizando o desempenho com o clustering líquido automático
Como as consultas orientadas por agentes são exploratórias e dinâmicas, o ajuste tradicional baseado em Z-ORDER nem sempre é o ideal. A Plenitude observou que os padrões de acesso evoluem à medida que novos relatórios, usuários e perguntas surgem, o que torna o clustering manual difícil de manter.
O clustering líquido automático, por outro lado, aprende como as tabelas são realmente usadas e adapta o layout de acordo. Isso reduz a necessidade de design de índice inicial e ajuste contínuo, o que é especialmente importante durante as fases de prova de conceito e go-live inicial. Nesse contexto, o clustering automático é a escolha preferida para cargas de trabalho orientadas por agentes e LLM em tabelas Delta.
Protegendo o acesso a dados para as Genie Rooms
Os dados de manutenção geralmente têm requisitos de acesso específicos por país ou região. Para aplicar essas regras de forma consistente, a Plenitude usa segurança em nível de linha em combinação com o Unity Catalog e tabelas.
Uma função do Unity Catalog determina quais países o usuário atual pode acessar e retorna uma lista ou a palavra-chave ALL se ele tiver visibilidade total. Uma tabela então filtra as linhas com base nessa função, para que cada usuário veja apenas os dados dos países autorizados.
Quando os usuários interagem por meio da Genie Room, todas as consultas são executadas na tabela filtrada, de modo que a segurança em nível de linha é aplicada automaticamente. Isso significa que os usuários podem fazer perguntas em linguagem natural, mas só recebem resultados dos dados que têm permissão para ver. O mesmo conjunto de dados alimenta o Genie, agentes e ferramentas de BI, enquanto a visibilidade é ajustada por usuário.
Melhorias futuras: rumo à manutenção preditiva
Como os relatórios de manutenção contêm incidentes em aberto e detalhes de falhas, o modelo de dados estruturado é uma base sólida para a manutenção preditiva. Os inversores são um bom exemplo: as falhas podem levar à perda de vários megawatts-hora por unidade, e os problemas recorrentes costumam aparecer primeiro nas notas de manutenção.
Ao analisar os padrões de falhas ao longo do tempo, a Plenitude pode:
- Identificar possíveis problemas de registro.
- Detectar sinais de alerta precoce.
- Priorizar usinas que precisam de uma investigação mais profunda.
- Alimentar modelos preditivos com históricos de incidentes de maior qualidade.
O sistema baseado em agentes transforma esses sinais em análises, tendências e visualizações acessíveis para que as equipes possam antecipar os problemas em vez de apenas reagir a eles.
Principais benefícios e recursos
Na abordagem anterior, a análise se limitava à leitura individual de relatórios, o que dificultava a criação de tendências históricas, a comparação de usinas ou a geração de resultados estruturados. Criar gráficos, exportar resultados ou combinar insights de vários relatórios era, na melhor das hipóteses, manual e, muitas vezes, inviável.
Com o Modo Agente do Genie no Databricks e um modelo de dados amigável para agentes, a Plenitude pode:
- Explorar dados de manutenção ao longo do tempo e entre usinas.
- Gerar visualizações e exportar resultados, incluindo saídas em PDF.
- Detectar sinais precoces e padrões recorrentes.
- Escalar a análise sem aumentar o esforço manual.
Ao combinar dados estruturados, metadados de negócios e raciocínio de AI, o sistema gera análises, tendências e visualizações que apoiam a detecção precoce e a antecipação de problemas, e não apenas relatórios retrospectivos.
Saiba mais sobre o Databricks Genie e o Agent Bricks.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.