Transforming solar and wind maintenance reports with Genie and AI agents
How Plenitude uses Databricks Genie and Agent Bricks to turn unstructured maintenance PDFs into a searchable data layer and natural language analytics across solar and wind plants.
- Plenitude built an agent-based system on Databricks Genie that converts unstructured PDFs for solar and wind maintenance into a unified, queryable data model.
- The solution uses Genie, coupled with Unity Catalog semantic metadata and AI Functions, to let users ask natural-language questions and create visualizations across plants and time.
- Early outcomes include faster multi-plant analysis, governed self-service access with row-level security and a foundation for predictive maintenance on critical assets like inverters.
From maintenance PDFs to actionable insights with AI agents
Operations and maintenance suppliers for solar and wind plants typically deliver reports as PDFs, with key information spread across free text, tables and images. This format is accessible but not scalable: teams must manually read each document to understand faults, trends or recurring issues, making cross‑plant comparisons slow and inconsistent as the number of assets grows.
Plenitude and Databricks built an agent‑based system that converts these PDF maintenance reports into structured data. The core idea is simple: transform documents into data, then use an AI agent to derive actionable insights from that data. Users can now ask questions in natural language, analyze trends over time, compare plants and export structured outputs, instead of navigating reports one by one.
Agent‑based architecture for PDF to data analytics
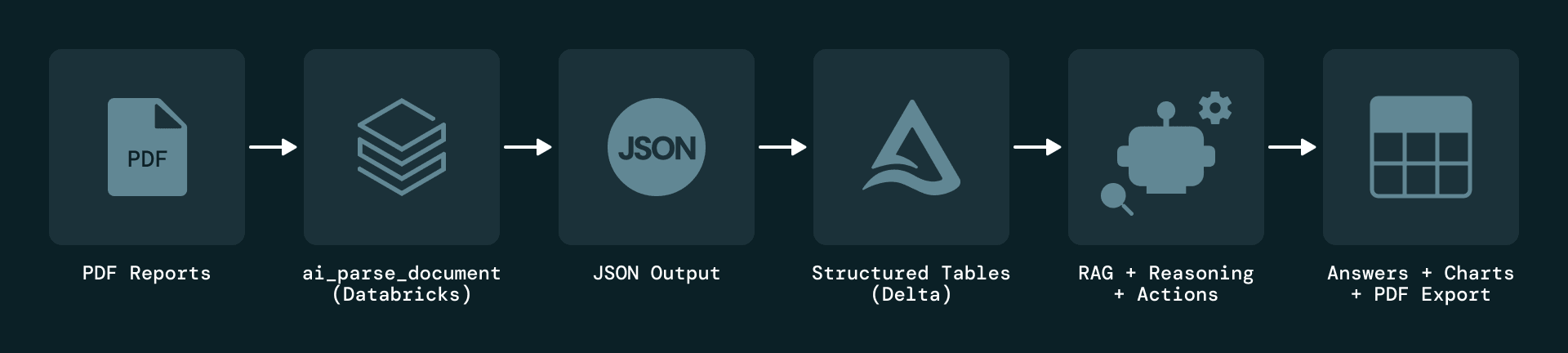
The solution starts with event-driven ingestion of plant-level PDF reports. Each new report triggers a Databricks Job that parses the document and applies LLM‑based extraction. Extracted elements are serialized as JSON and stored in Delta Lake, which maintains full version history for audit and replay.
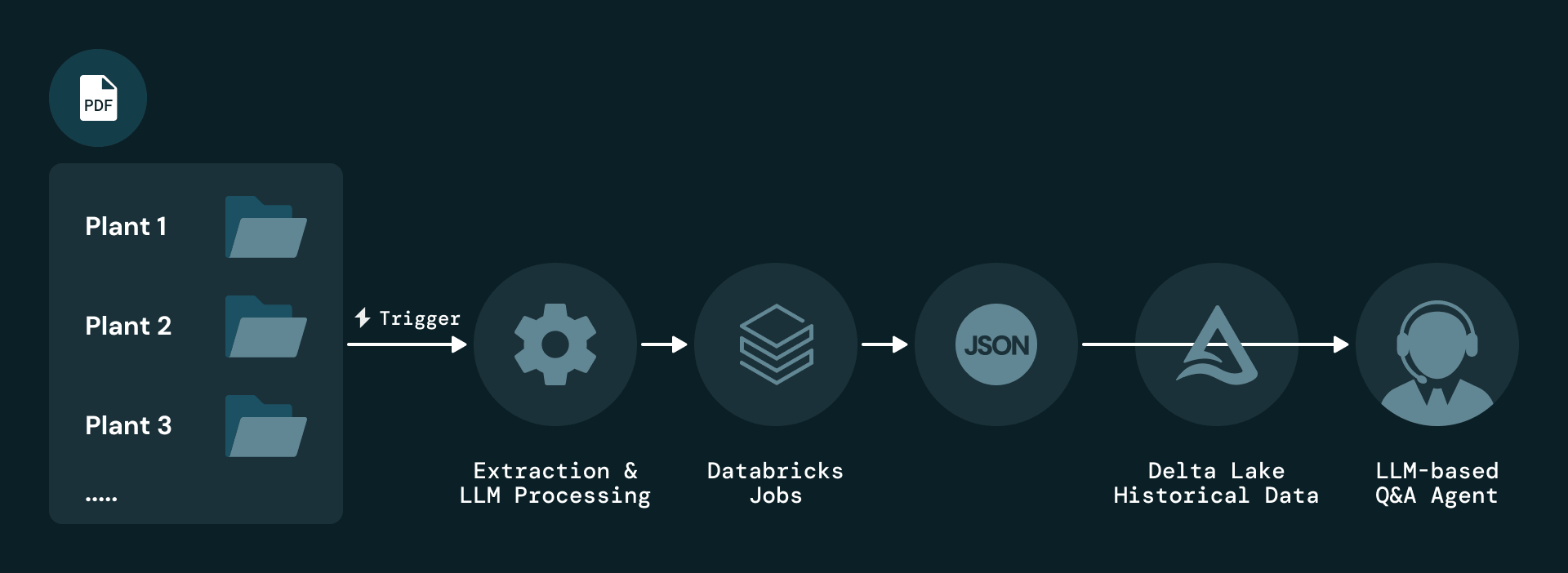
To address the fundamental problem that maintenance information lives almost entirely in unstructured PDFs, Plenitude uses Databricks Document Intelligence AI Functions — specifically ai_parse_document, to extract multiple types of elements from each page, including text blocks, tables, figures and metadata. Each element is enriched with attributes such as plant, reporting period, page number and content type, and every record maintains a direct link back to the original report for traceability.
This structure unlocks powerful capabilities:
- Filtering by time, category and geography.
- Identifying content types and using spatial coordinates.
- Tracing every insight back to the original PDF.
- Integrating with BI tools and digital agents without changing the underlying documents.
Instead of static files, maintenance reports become a persistent data layer ready for advanced analytics and agent reasoning.
Data processing on Databricks: from PDF to Delta Lake
The architecture is organized into three main layers: ingestion and parsing, data structuring and agent-based interaction.
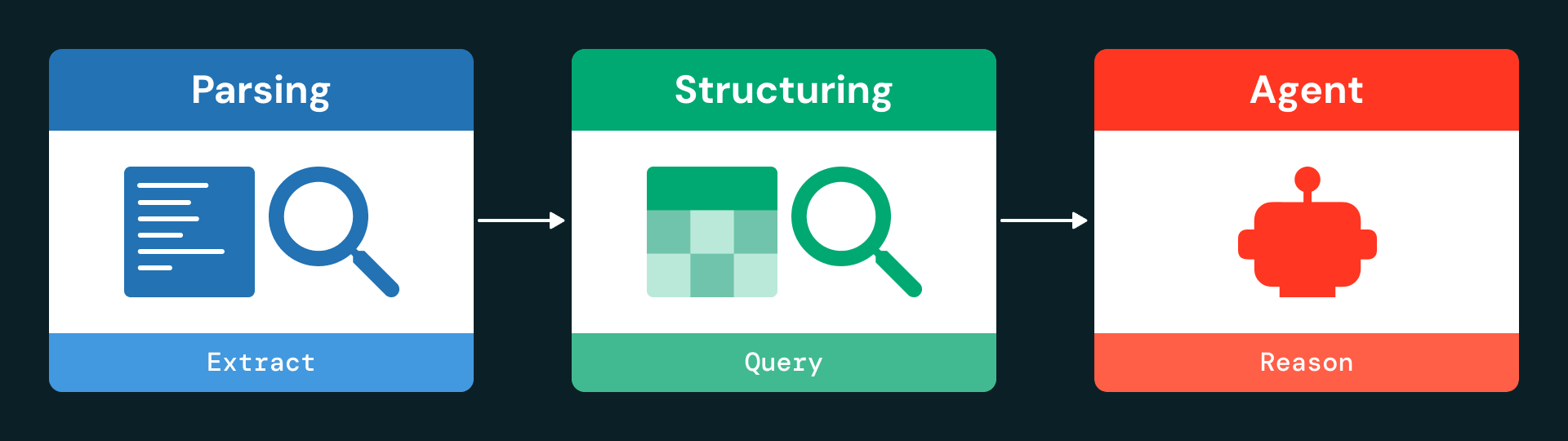
Step 1: parsing
Using ai_parse_document, the pipeline extracts text, tables and metadata from each page and serializes them as structured JSON objects. Even complex tables are captured with full context, including their location on the page and HTML representation.
Step 2: normalization and storage
For every page (page_id) and object (id), the system creates one row in a Delta Lake table. Each row contains:
- The extracted JSON content.
- Page and object identifiers.
- Coordinates (coords) representing the bounding box on the page.
- Content type (for example, text or table).
- High-value metadata such as month, year, file name, category and country.
This normalized model turns PDFs into a unified, queryable dataset that is transparent and easy to join with other sources, while preserving full traceability back to the original documents.
Step 3: Genie space and Agent mode
On top of this curated data layer, Plenitude builds a dedicated Genie space and then leverages Genie’s Agent mode to perform Deep Research on the data. Genie uses the structured Delta Lake tables as its primary context and lets users interact with maintenance data using natural language.
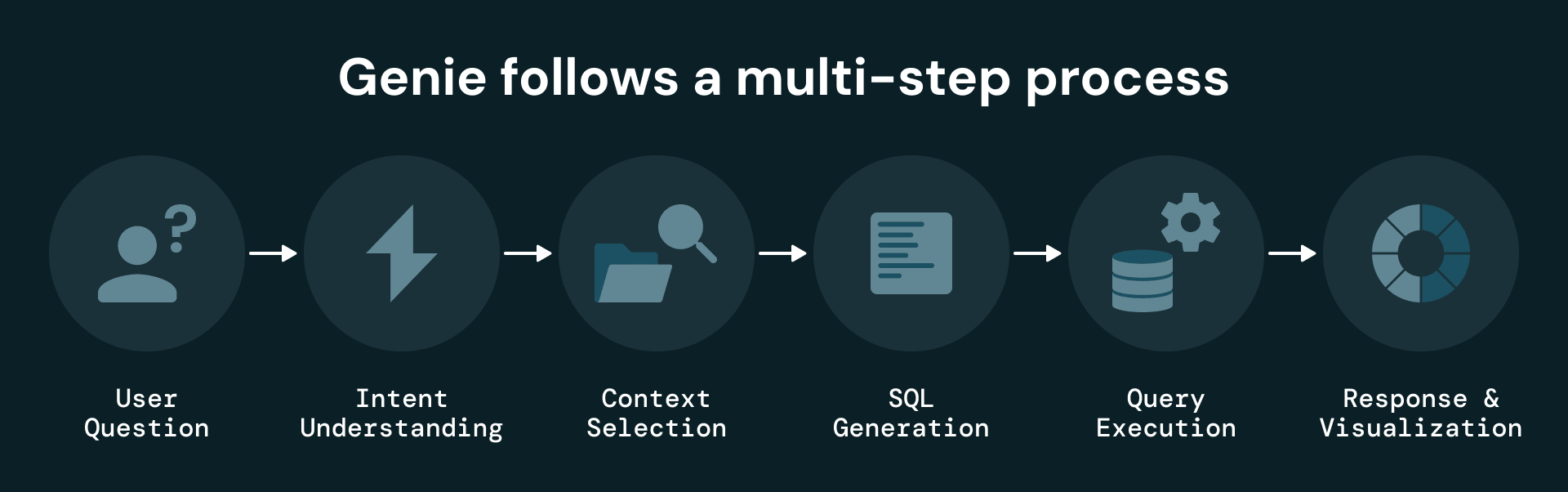
When a user asks a question, Genie:
- Uses semantic metadata in Unity Catalog to identify available tables and columns.
- Leverages detailed column descriptions, a curated knowledge store and SQL samples to guide query generation.
- Generates and executes SQL against the structured layer.
- Returns answers, visualizations and optionally exportable results.
This design enables Genie to understand both the business semantics of maintenance data and its underlying structure, resulting in accurate, context-aware answers.
Why metadata and instructions matter for Genie
To obtain reliable results from complex PDF-derived datasets, context alone is not sufficient. Plenitude found that two design patterns are critical: rich metadata and explicit instructions for the Genie space.
Metadata as a contract with the agent
Well-defined table and column descriptions tell Genie what each field means and how it should be used. For example, page_id identifies the source page in the original report, type indicates whether the element is text or a table, coords encodes the spatial location, and content contains the extracted text or table representation. This metadata turns raw JSON into understandable knowledge that Genie can reason over.
General instructions as operational grounding
When data is fragmented or spans multiple pages, domain-specific instructions added to the Genie space’s local knowledge store become essential. Plenitude encodes rules for handling multipage tables, ignoring HTML artifacts, excluding header rows and applying plant-specific filters.
A practical example: even with full metadata, Genie might compute an incorrect quarterly total if it sums YTD columns or ignores missing months. By adding clear instructions such as “only use month-level columns, never YTD fields” and “validate that all required months are present before summing,” the team provides Genie with operational guardrails that ensure consistent results.
These Genie space-specific instructions, combined with metadata from Unity Catalog, help Genie apply the right logic to interpret data correctly.
Using Genie and Agent Bricks for scalable agent workflows
While Genie provides a powerful research agent experience on top of the structured maintenance layer, Plenitude also needs repeatable workflows and orchestration to support a growing set of use cases. Agent Bricks is the next step in that evolution.
With Agent Bricks, Plenitude can move from “LLM plus prompt” patterns to agentic workflows that execute sequences of actions on behalf of maintenance analysts and engineers. The same curated Delta Lake tables, metadata and instructions that power Genie can be reused by Supervisor-style agents built with Agent Bricks to:
- Decompose complex questions into smaller analytical tasks.
- Call the Genie tool flows to generate and execute SQL.
- Trigger downstream actions, such as report generation or alert creation.
What used to require manual wiring of prompts, tools and validation logic can now be centralized in Agent Bricks, on the same Databricks Platform that manages the data.
Optimizing performance with automatic liquid clustering
Because agent-driven queries are exploratory and dynamic, traditional Z-ORDER-based tuning is not always ideal. Plenitude observed that access patterns evolve as new reports, users and questions appear, which makes manual clustering hard to maintain.
Automatic liquid clustering, by contrast, learns how tables are actually used and adapts the layout accordingly. This reduces the need for upfront index design and ongoing tuning, which is especially important during the proof-of-concept and early go-live phases. In this context, auto clustering is the preferred choice for agent and LLM-driven workloads on Delta tables.
Securing data access for Genie Rooms
Maintenance data often has country or region-specific access requirements. To enforce these rules consistently, Plenitude uses row-level security in combination with Unity Catalog and tables.
A Unity Catalog function determines which countries the current user can access and returns a list or the keyword ALL if they have full visibility. A table then filters rows based on that function, so each user only sees data for their authorized countries.
When users interact through the Genie Room, all queries run on the filtered table, so row-level security is applied automatically. This means users can ask questions in natural language, but only receive results from the data they are allowed to see. The same dataset powers Genie, agents and BI tools, while visibility adjusts per user.
Future improvements: toward predictive maintenance
Because maintenance reports contain open incidents and fault details, the structured data model is a strong foundation for predictive maintenance. Inverters are a good example: failures can lead to the loss of several megawatts-hours per unit, and recurring issues often appear first in maintenance notes.
By analyzing fault patterns over time, Plenitude can:
- Identify potential recording issues.
- Detect early warning signals.
- Prioritize plants that need deeper investigation.
- Feed predictive models with higher-quality incident histories.
The agent-based system turns those signals into accessible analytics, trends and visualizations so teams can anticipate issues rather than simply react to them.
Key benefits and capabilities
In the previous approach, analysis was limited to reading reports individually, which made it hard to build historical trends, compare plants or generate structured outputs. Creating charts, exporting results or combining insights from multiple reports was manual at best and often not feasible.
With the Genie Agent Mode on Databricks and an agent-friendly data model, Plenitude can:
- Explore maintenance data across time and across plants.
- Generate visualizations and export results, including PDF outputs.
- Detect early signals and recurring patterns.
- Scale analysis without scaling manual effort.
By combining structured data, business metadata and AI reasoning, the system generates analytics, trends and visualizations that support early detection and anticipation of problems, not just retrospective reporting.
Learn more about Databricks Genie and Agent Bricks.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.