tutorial: como implantar alterações de dashboards de AI/BI com segurança e em escala com os Databricks Asset Bundles
Implante a analítica com confiança: um guia completo para criar dashboards de AI/BI confiáveis e escaláveis sem processos manuais
por Eason Gao, Noah Sommerfeld e Jen Lim
- Implante dashboards impactantes e para toda a organização com confiança e estabilidade.
- Mantenha a confiança com alterações e a história visíveis, revisáveis e reversíveis.
- Atualize as métricas e a lógica do dashboard à medida que as definições de negócios mudam, sem interromper os relatórios de produção.
A ideia de uma reunião do conselho começar com um painel cheio de erros deveria tirar o sono das equipes de analítica. Assim como descobrir, depois do ocorrido, que um plano de contratação, lançamento de produto ou previsão de receita foi baseado em uma métrica incorreta. Ou que uma equipe de suporte emitiu reembolsos demais porque um painel representou incorretamente a história de compras de um cliente.
Essas falhas raramente são causadas por uma análise ruim. Como em qualquer sistema de produção, eles geralmente surgem de dashboards que são atualizados manualmente à medida que os modelos de dados e os requisitos evoluem, sem versionamento, sem um processo de revisão confiável ou sem uma maneira repetível de promover alterações entre ambientes.
Esta postagem no blog defende um ponto simples: dashboards de nível de produção que impulsionam os negócios devem ser gerenciados com a mesma disciplina que o código de produção. Como o Databricks AI/BI é executado na mesma Plataforma de Inteligência de Dados que seus pipelines de dados e camada de governança, as equipes também podem aplicar aos dashboards essas mesmas práticas de produção: controle de versão, configuração específica do ambiente e implantação controlada.
Para exemplificar, apresentaremos como os analistas podem usar as funcionalidades do Databricks de nível de produção sem alterar a forma como criam dashboards no dia a dia.
Especificamente, mostraremos como esse fluxo permite que você:
- Revise e aprove cada alteração em um dashboard
- Rastrear a história de um dashboard e vincular alterações de código aos requisitos de negócios
- Reverta um dashboard para uma versão anterior
Pré-requisitos:
Este fluxo de trabalho requer uma configuração de infraestrutura única que a maioria das organizações já possui. Se você ainda não os tiver, peça ao seu grupo interno de DevOps ou TI para ajudar na configuração:
- Pelo menos dois workspaces do Databricks (por exemplo, um workspace de desenvolvimento e um de produção) para criar, testar e implantar dashboards
- Pastas com suporte do Git no Databricks (AWS | Azure | GCP), usadas para versionar as definições de dashboard
- Databricks Asset Bundles (DABs) (AWS | Azure | GCP) configurados para o projeto
Introdução: um fluxo de trabalho estruturado para entregar alterações de painel com segurança
Vamos apresentar um cenário realista: você possui um painel de desempenho de vendas usado semanalmente pela liderança de Finanças e Vendas. Começou como um projeto de estágio criado diretamente em um workspace, mas evoluiu com o tempo e agora é usado em várias revisões executivas.
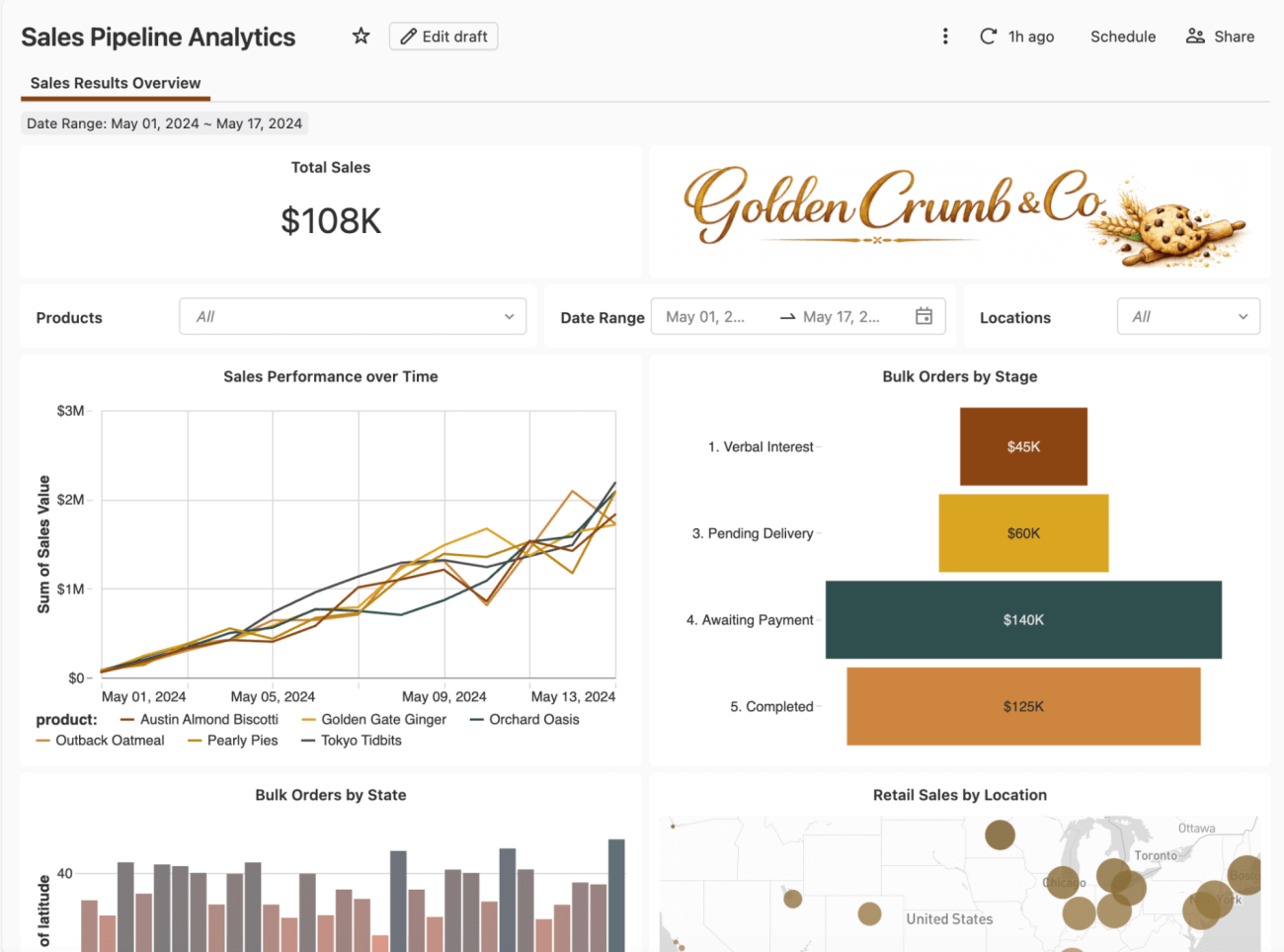
Uma mudança de prioridades em uma reunião do conselho traz um novo requisito: o departamento financeiro agora precisa rastrear valores de vendas comprometidos e não comprometidos, substituindo uma única métrica de vendas agregada, e o dashboard precisa refletir a nova definição antes da próxima revisão de previsão.
Esses valores alimentam diretamente decisões de negócios reais, incluindo cálculos de remuneração e bônus, então vamos pegar este dashboard e colocá-lo em um caminho de implantação disciplinado pela primeira vez.
Etapa 1: Adicionar o dashboard a um Databricks Asset Bundle
Antes de iniciar o processo, trabalhe com sua equipe de TI para configurar algumas ferramentas de código básicas: um repositório Git com um ‘Databricks Asset Bundle’ vazio e alguns scripts de CI/CD para implantar o pacote automaticamente.
Um repositório Git é uma ferramenta para rastrear alterações de arquivos. Para começar, precisamos conectá-lo ao Databricks para que possamos rastrear as alterações na configuração do dashboard. No workspace do Databricks, crie uma pasta Git e cole a URL do repositório na caixa de diálogo de configuração. Isso faz com que o Databricks reconheça o repositório e nos permite adicionar o dashboard a ele no próximo passo.

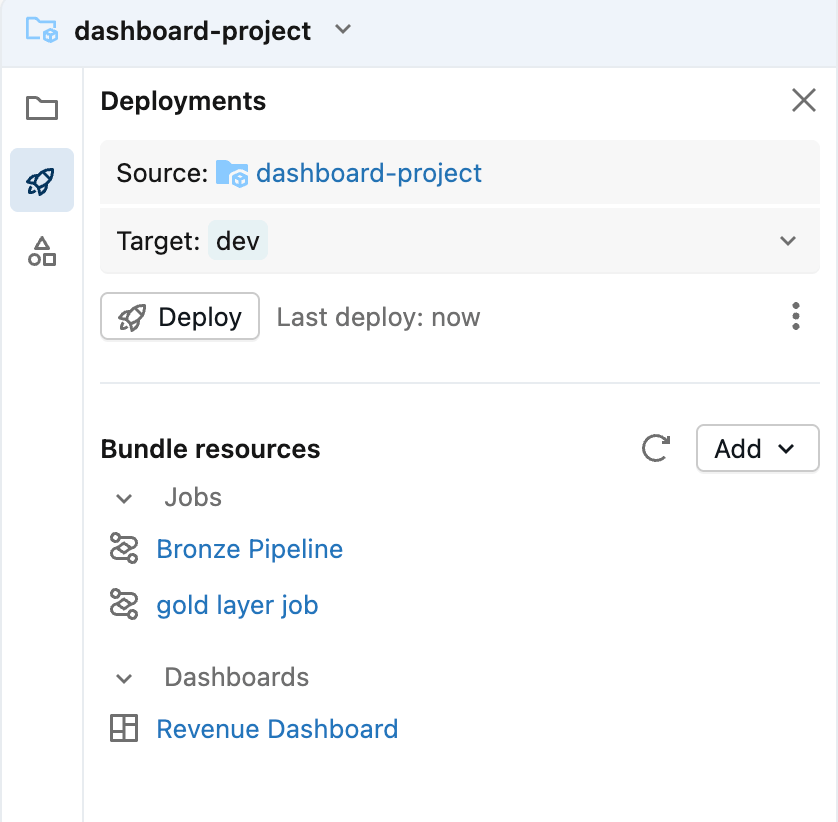
Um Pacote de Ativos Databricks é uma forma de agrupar arquivos de código (neste caso, um painel). Se o repositório já contiver um pacote, ele será detectado automaticamente e poderá ser aberto usando o ícone de seta. Caso contrário, um novo pacote pode ser criado no menu Criar na pasta Git.
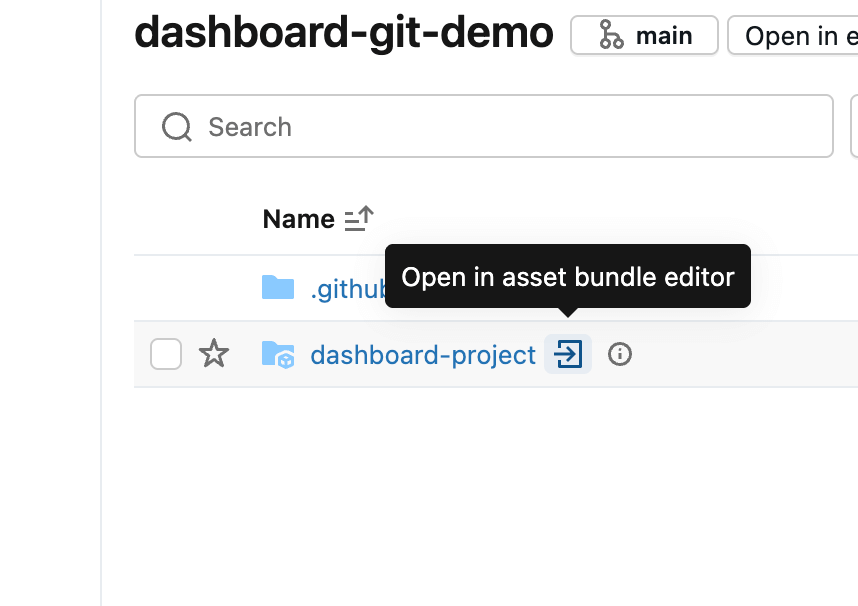
Dentro do editor do Pacote de Ativos, você pode adicionar componentes novos e existentes ao pacote que está atualmente vazio. Para incluir o dashboard, abra o menu Adicionar e selecione Adicionar dashboard existente. Depois de adicioná-lo, você verá o dashboard aparecer dentro da pasta src como parte do bundle.
A partir deste ponto, o dashboard é gerenciado como um ativo implementável, facilitando a promoção do mesmo dashboard entre workspaces de desenvolvimento, teste e produção.
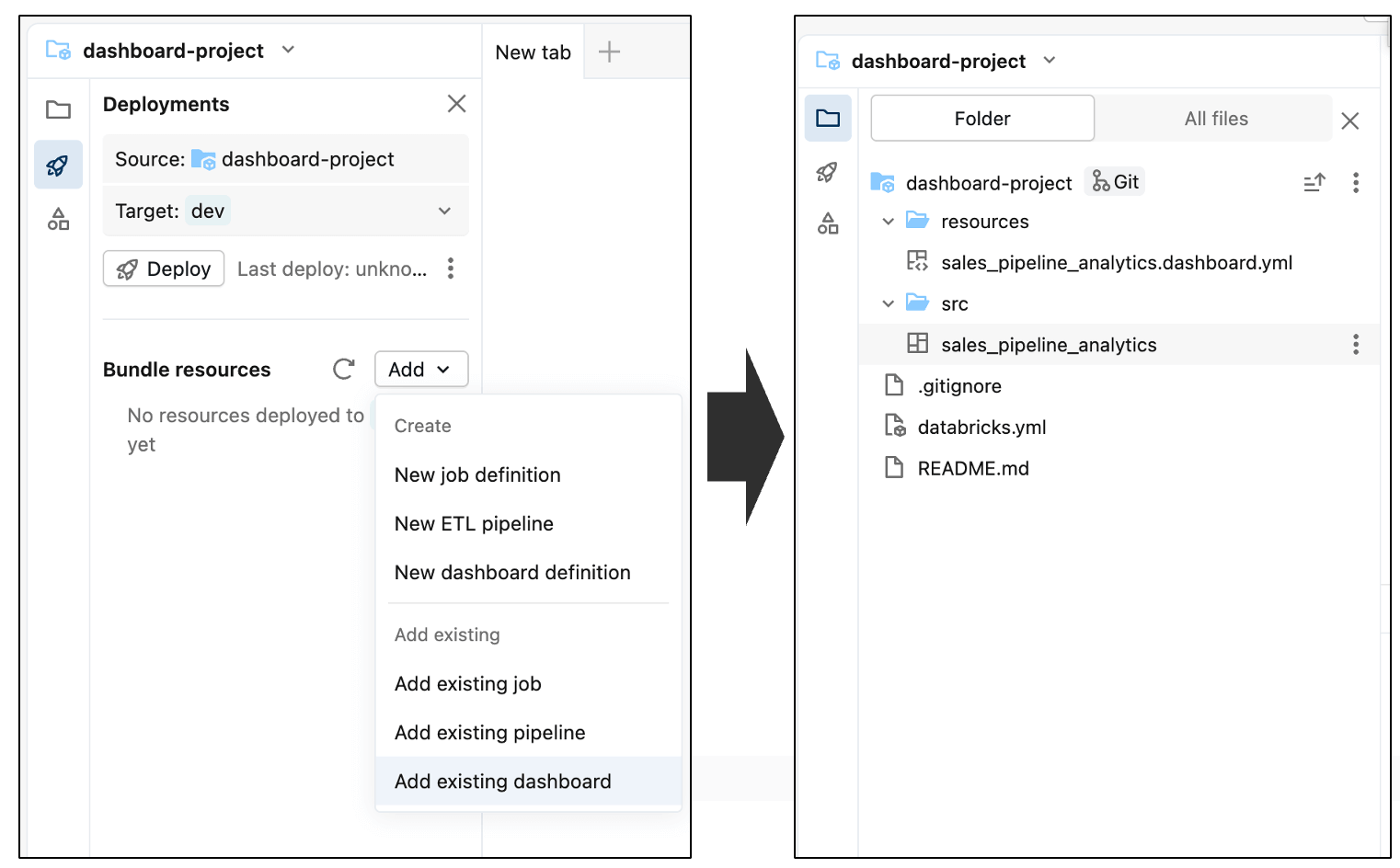
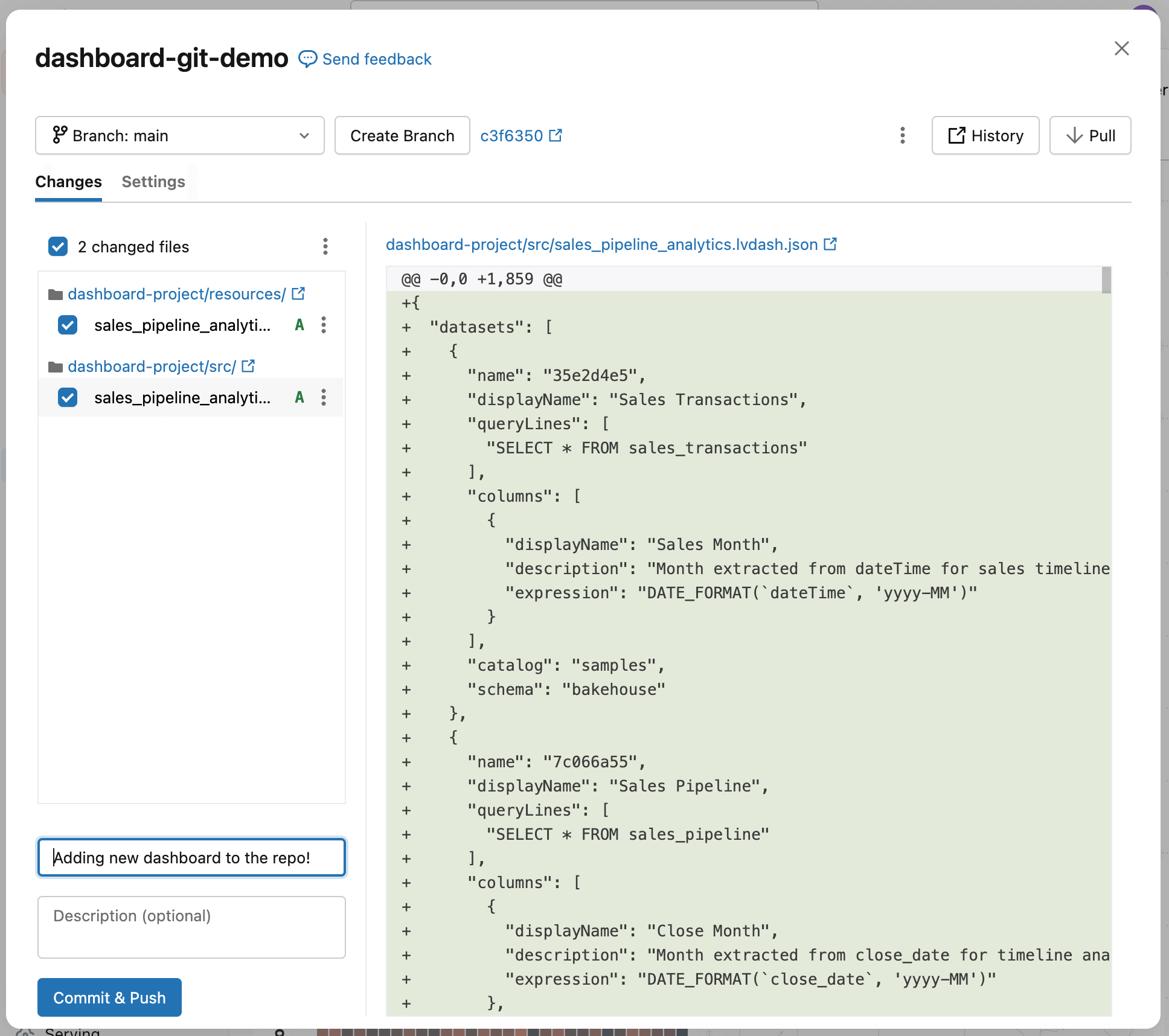
Finalmente, faça o commit do painel no repositório. Isso captura o estado atual do dashboard como uma linha de base e estabelece um ponto de partida claro para acompanhamento e revisão de alterações futuras.
Você verá que o dashboard foi adicionado ao repositório, juntamente com alguns arquivos de configuração gerados automaticamente (terminando com .yml). Estes arquivos descrevem como o painel deve ser implantado em diferentes ambientes — você não precisa editá-los.
Adicione uma nota curta descrevendo o que você fez no campo mensagem de commit e, em seguida, selecione Commit & Push. Isso cria um checkpoint para o dashboard (um estado funcional conhecido ao qual você pode retornar mais tarde) para que as alterações futuras possam ser comparadas, revisadas e implantadas com segurança.
Etapa 2: Atualize o dashboard
Agora que o dashboard existente foi comitado, você pode começar a fazer alterações nele sem afetar o que já está em produção, e o git rastreará as alterações específicas que você fez.
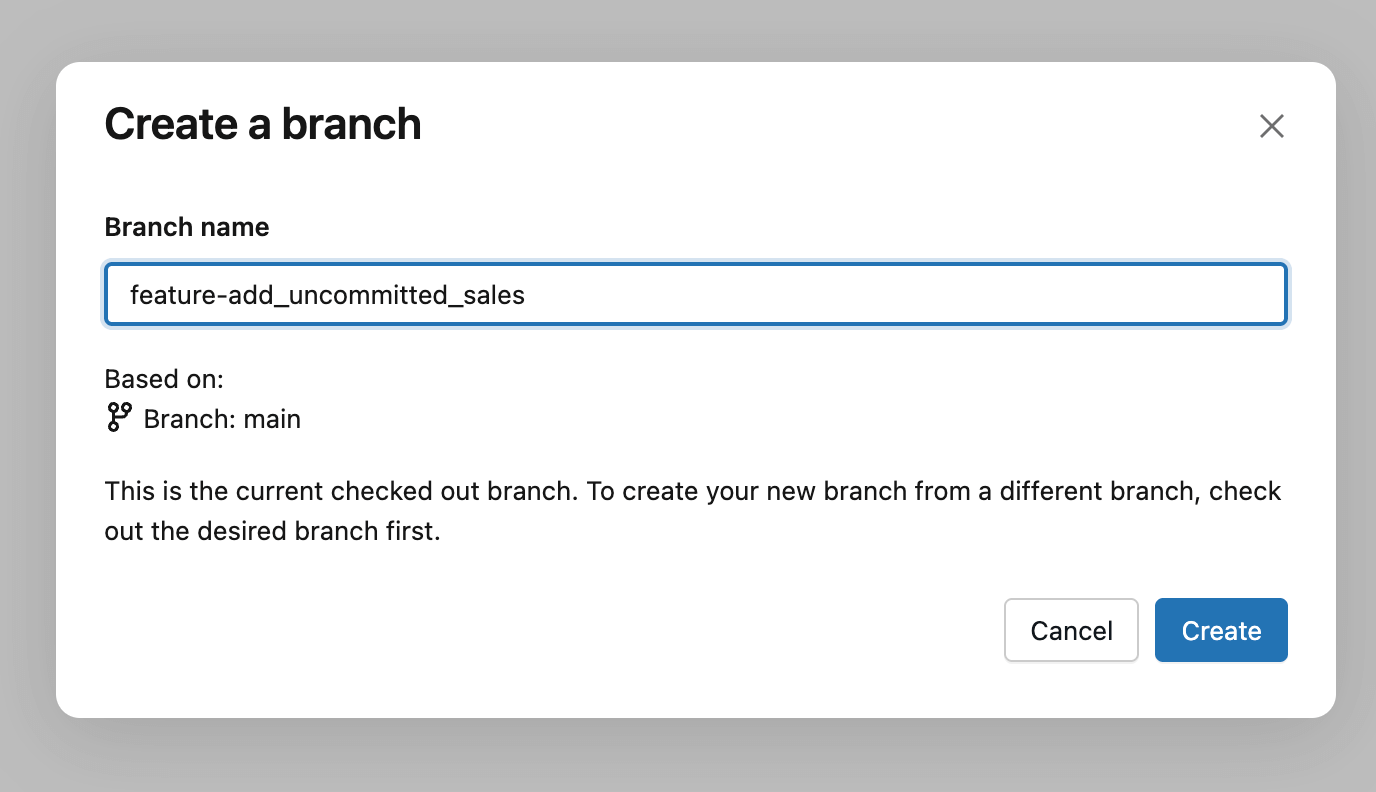
A prática geral é criar um branch do Git, uma versão do dashboard na qual se pode trabalhar sem afetar os outros. Você pode fazer isso por meio do botão Criar Branch e, em seguida, dar a ele um nome descritivo, como seu nome, um recurso ou o número de um ticket associado à alteração. Pense nisso como uma versão privada para sua atualização: você pode editar, testar e refinar o dashboard livremente e, em seguida, decidir separadamente quando suas alterações estarão prontas para serem revisadas e implantadas.
Agora você pode fazer as alterações no dashboard! Neste caso, você modificará o número de ventas no canto superior esquerdo para adicionar contadores de ventas não comprometidas e comprometidas (azul e vermelho em negrito escolhidos para visibilidade).
Você notará que nada na experiência de criação muda. Faça essas alterações como faria normalmente usando o editor de UI do dashboard.
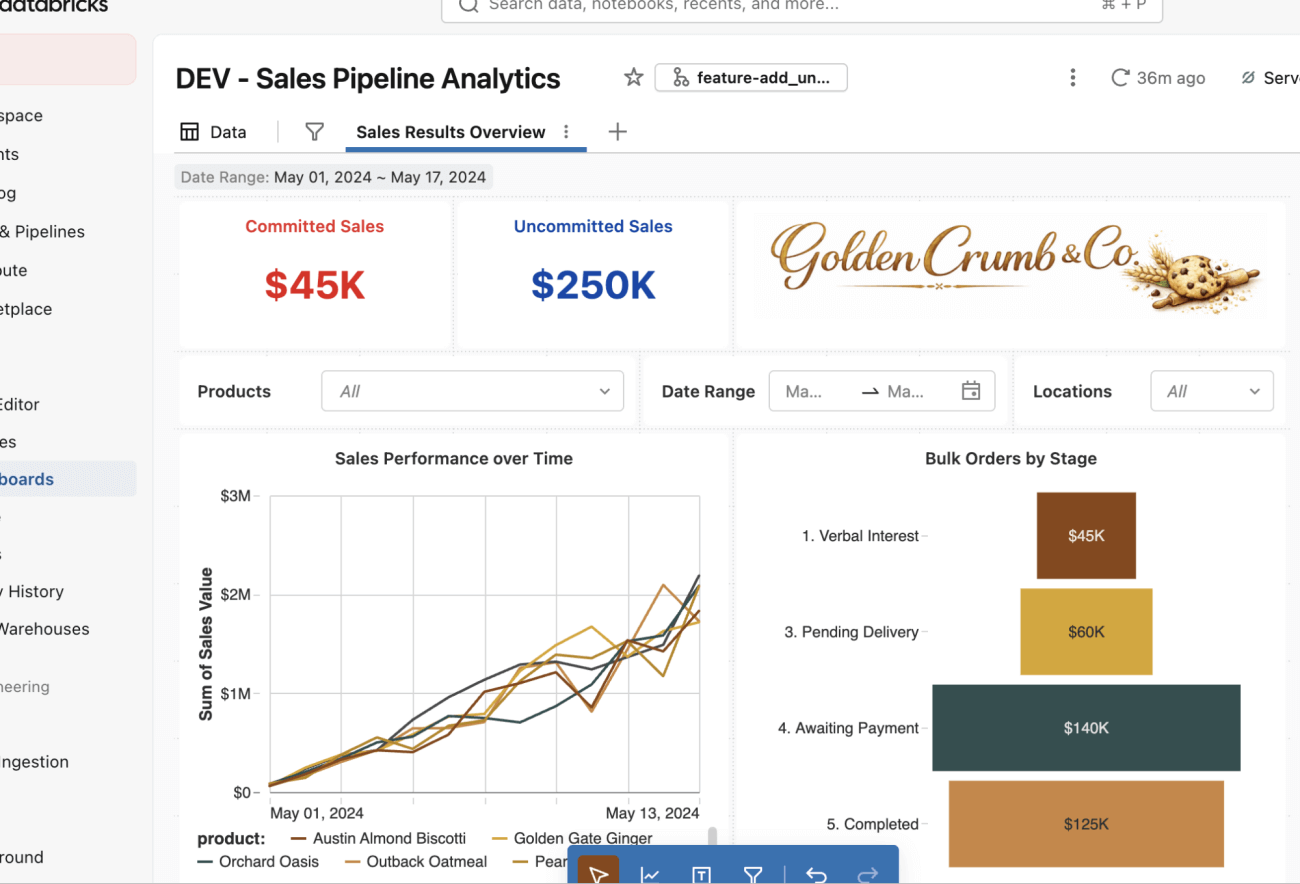
Quando o dashboard parecer correto em desenvolvimento, você estará pronto para levar as alterações para a produção. Use o mesmo botão Git na parte superior, como antes, para fazer o check-in dessas alterações com uma mensagem de commit curta.
o passo 3: Revisar a alteração
Em seguida, você desbloqueia outro benefício principal deste fluxo de trabalho: um local para que outras pessoas revisem as alterações e ofereçam feedback antes que a alteração chegue à produção. Exigir a revisão de uma segunda pessoa é uma prática recomendada geral, mas, o que é igualmente importante, cria um espaço de baixo risco para discutir ideias, validar suposições e refinar a alteração antes que ela afete os relatórios.
Para iniciar a revisão, crie um Pull Request (PR) em seu provedor Git, que é basicamente uma página de revisão para a atualização do dashboard. O revisor pode ver exatamente o que mudou, deixar comentários para você resolver e aprovar a atualização quando tudo estiver correto.
Durante a revisão, o dashboard de produção permanece inalterado. Somente após o feedback ser tratado e a alteração ser aprovada é que ela avança.
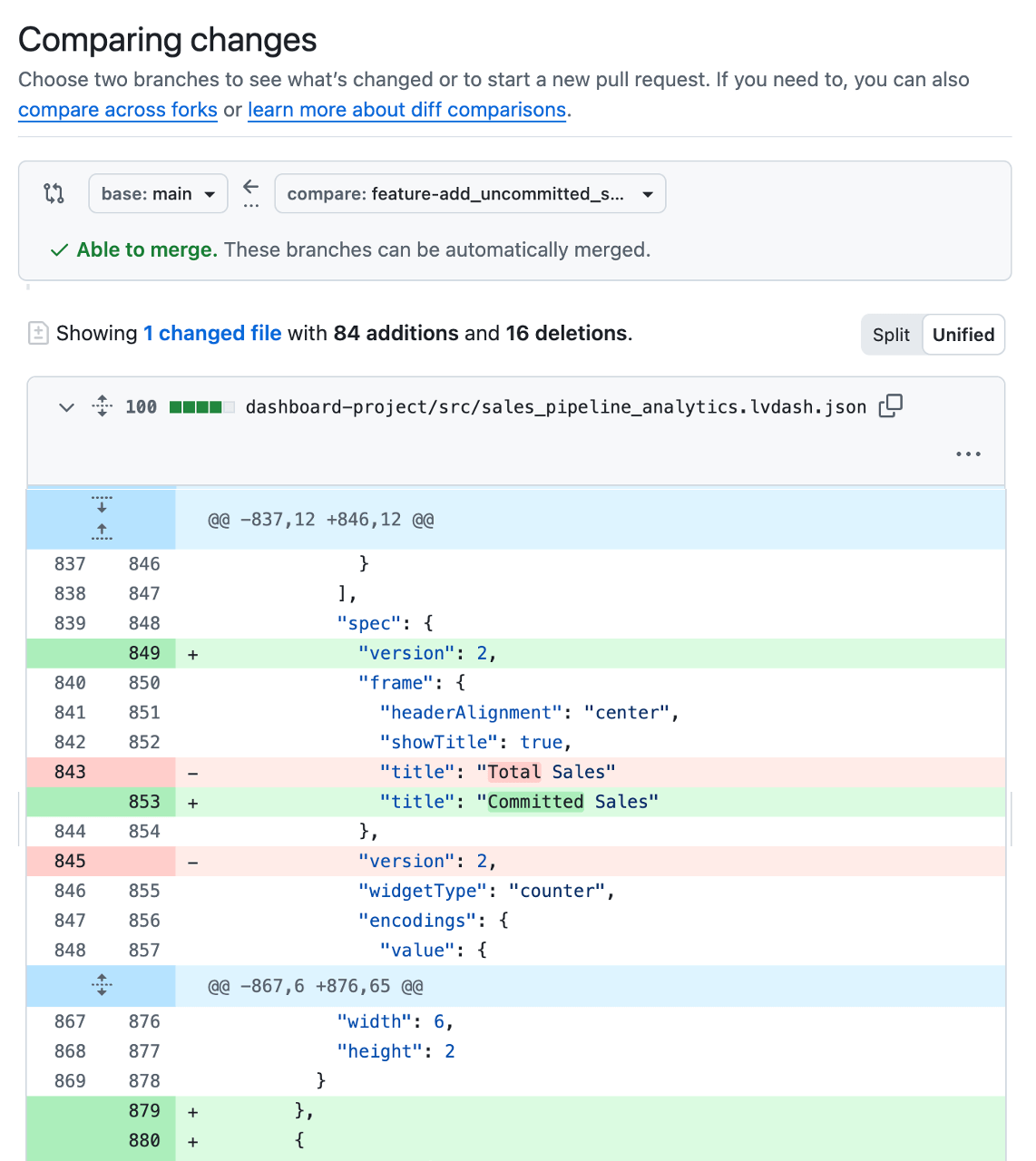
Embora as alterações no dashboard sejam armazenadas e rastreadas como arquivos de configuração nos bastidores, geralmente é difícil entender o que realmente mudou. Por isso, a maioria das equipes usa uma pequena automação para implantar automaticamente uma versão de teste temporária do dashboard para revisão sempre que um PR é aberto. Dessa forma, os revisores podem ver as métricas, os cálculos e as disposições propostas em contexto antes que qualquer coisa chegue à produção e detectar problemas de lógica de dados ou de IU. O fato de o desenvolvedor ou revisor incluir capturas de tela ou links para o painel de teste diretamente no PR também torna o feedback mais rápido e confiante.
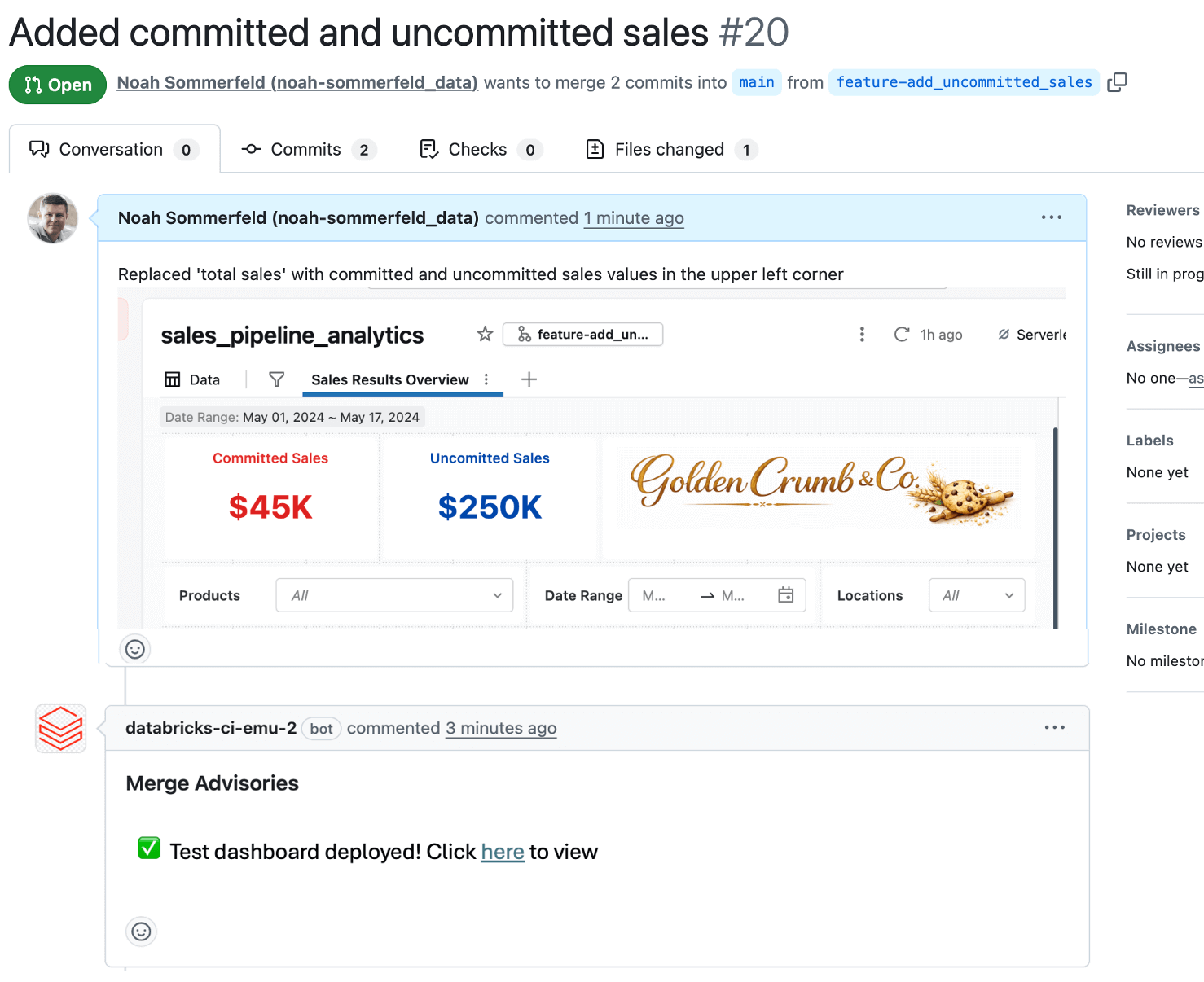
Os revisores podem adicionar comentários e aprovar, que são registrados para que a alteração seja mais fácil de entender posteriormente.
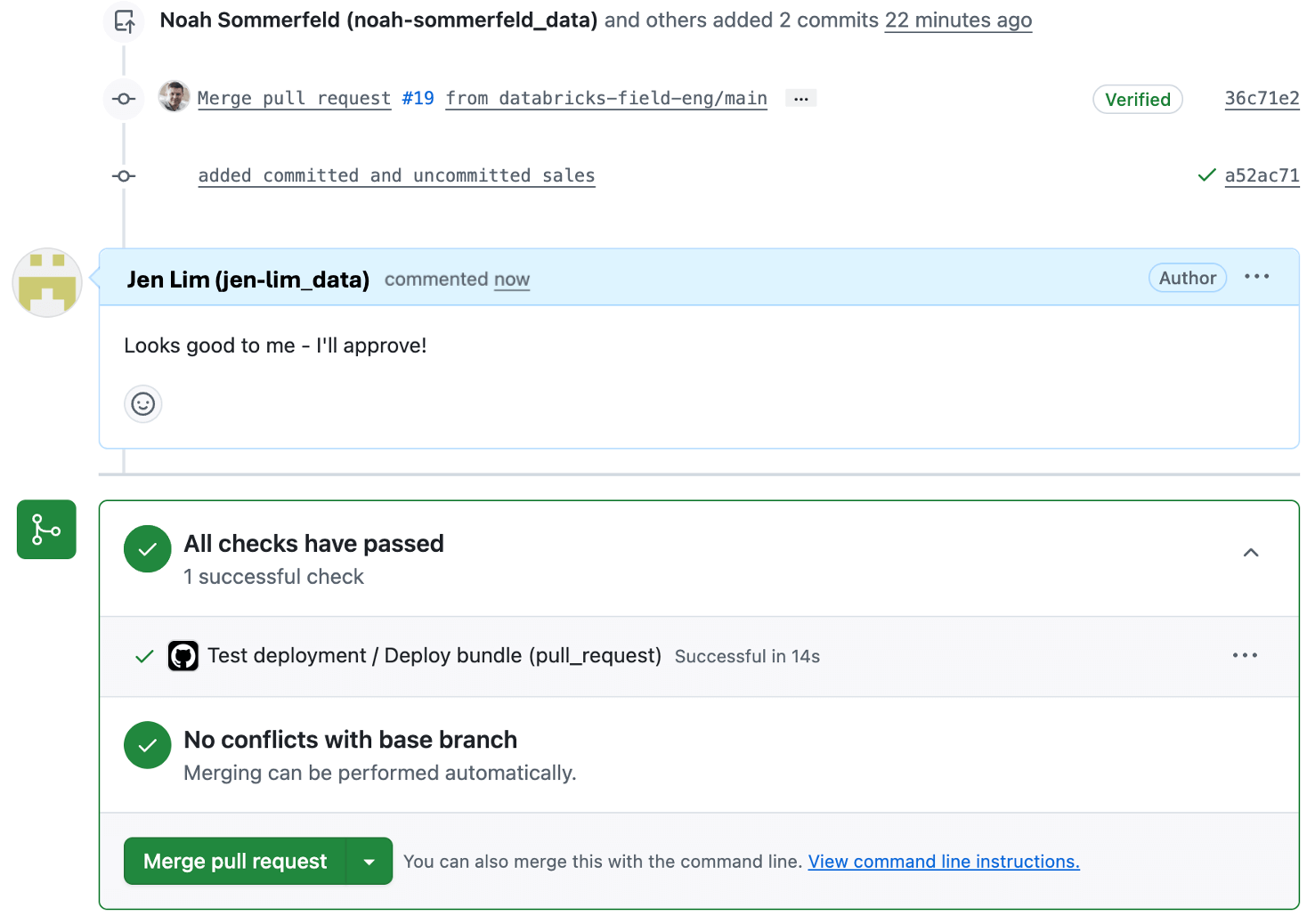
Etapa 4: implantar o dashboard em produção usando o bundle
Com a alteração aprovada, você está pronto para implantar o dashboard em produção.
Dashboards geralmente precisam de configurações diferentes em produção do que em desenvolvimento. Por exemplo, apontar para um catálogo ou esquema de produção em vez de um dataset de desenvolvimento, ou usar um SQL warehouse diferente.
A boa notícia é que essas diferenças são esperadas e tratadas como parte do processo de implantação.
Quando você adicionou o dashboard ao Pacote de Ativos, o Databricks gerou um pequeno arquivo .yml arquivo de configuração que captura essas configurações específicas do ambiente. Este arquivo permite substituir valores por ambiente sem alterar a lógica do próprio dashboard. No nosso caso, especificamos que o catálogo que o dashboard usa em produção deve ser diferente do de teste, usando um valor ${variable} para o nome do catálogo.
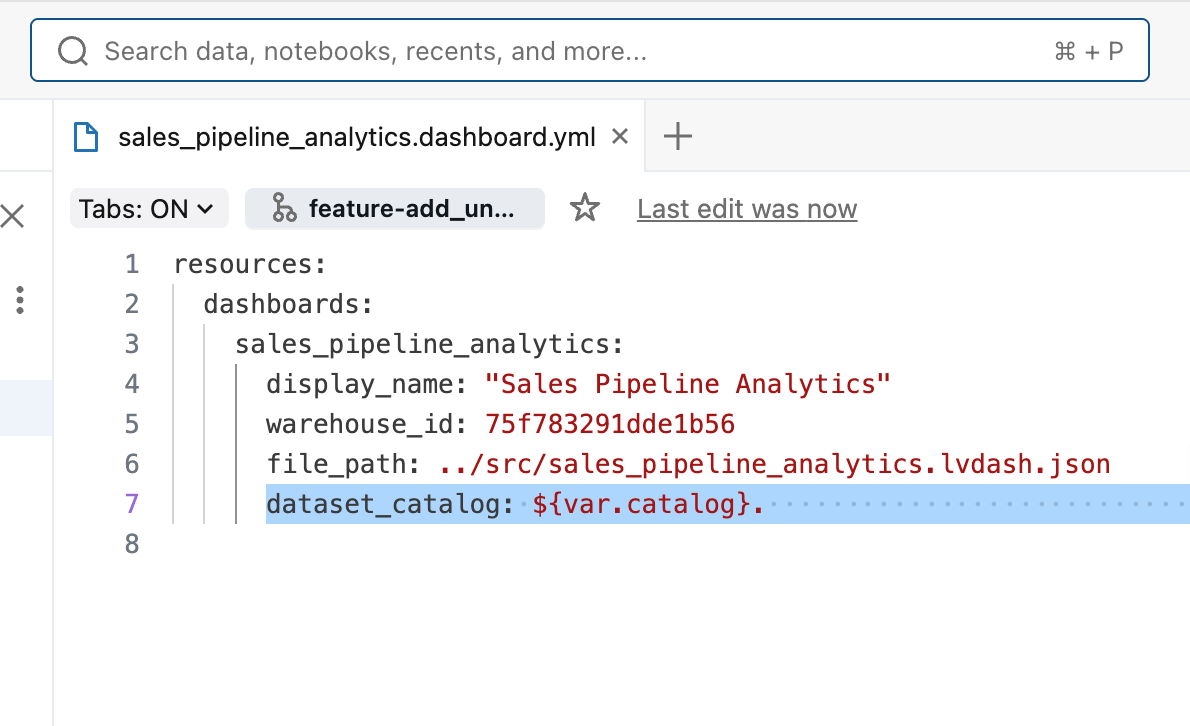
Finalmente, o arquivo databricks.yml conecta todos os recursos do bundle e define qual catálogo é usado em cada ambiente, facilitando o gerenciar de implantações consistentes entre Workspaces de desenvolvimento, teste e produção.
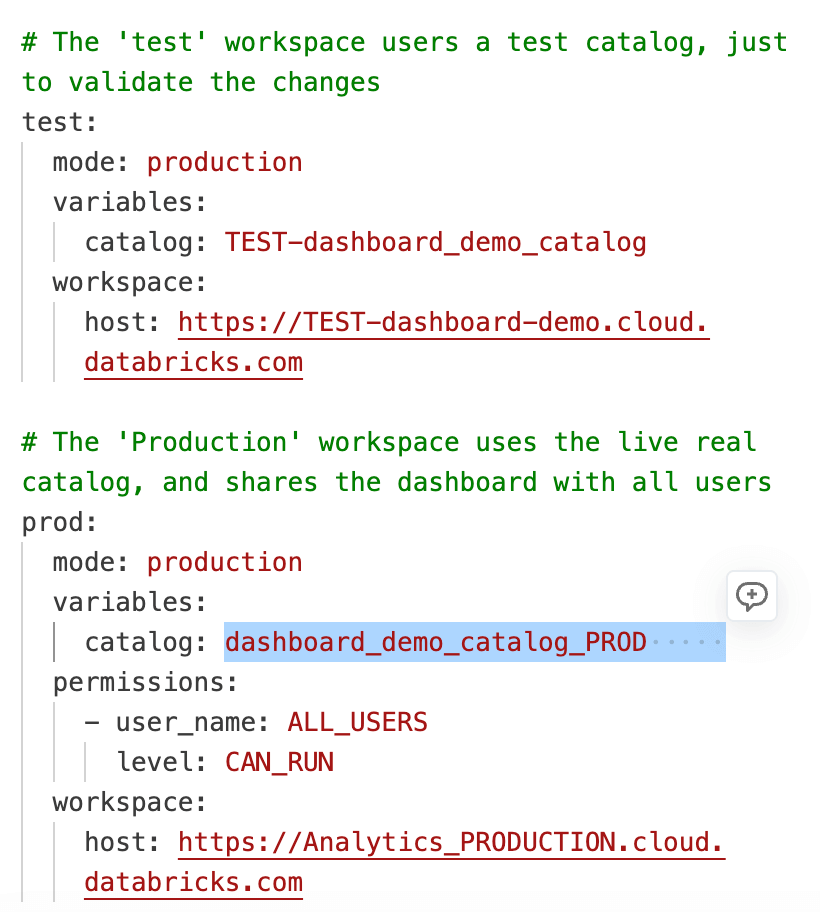
Depois que o Pull Request for aprovado e mesclado na branch principal, sua automação de implantação é executada e usa os valores específicos do ambiente definidos em databricks.yml. O mesmo código de dashboard é reutilizado em vários workspaces, enquanto configurações como catálogo, esquema e warehouse são aplicadas com base no ambiente de destino. Isso elimina a necessidade de manter cópias separadas do dashboard para cada workspace e garante que as alterações se comportem de forma previsível em todos os lugares.
Para a maioria dos provedores Git, você poderá ver a automação da implantação no pull request para poder monitorar a implantação e confirmar quando ela for concluída (ou se encontrar um problema). Se ocorrer um problema, a implantação para sem afetar o dashboard de produção existente, para permitir que você solucione o problema. Assim que a implantação for concluída com sucesso, o dashboard atualizado estará no ar em produção e pronto para as partes interessadas!
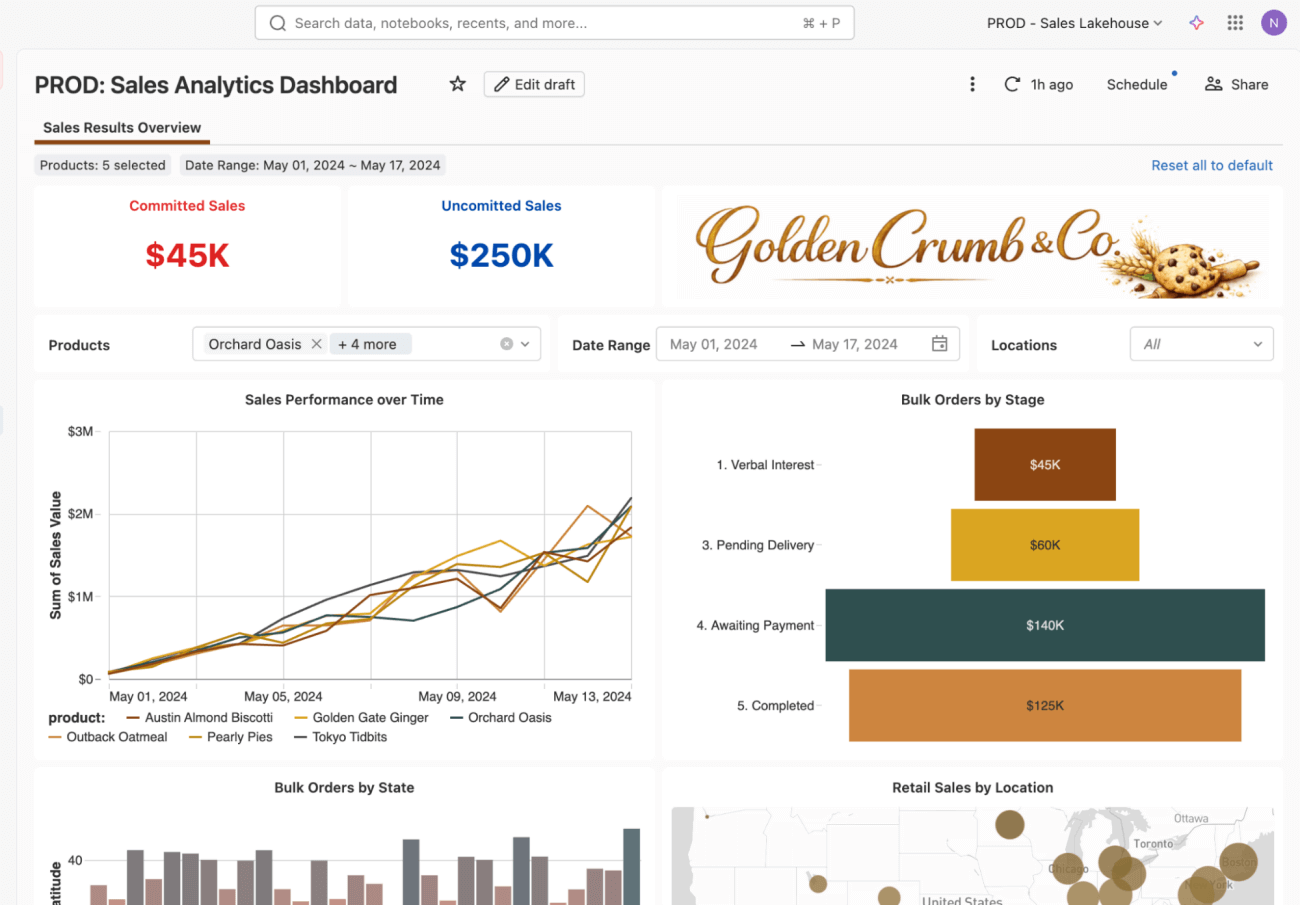
Bônus 1: E se você quiser inspecionar a história?
Depois que a atualização do dashboard estiver no ar, você pode precisar entender o histórico do que, quando e por que mudou. Uma vantagem desse fluxo é que a alteração agora é rastreável. Em vez de uma edição única feita diretamente em um workspace, ela aparece como uma sequência de versões salvas.
Cada entrada representa uma atualização do dashboard, junto com o autor e o timestamp. Você pode abrir qualquer entrada para revisar as alterações e revertê-las, se necessário.
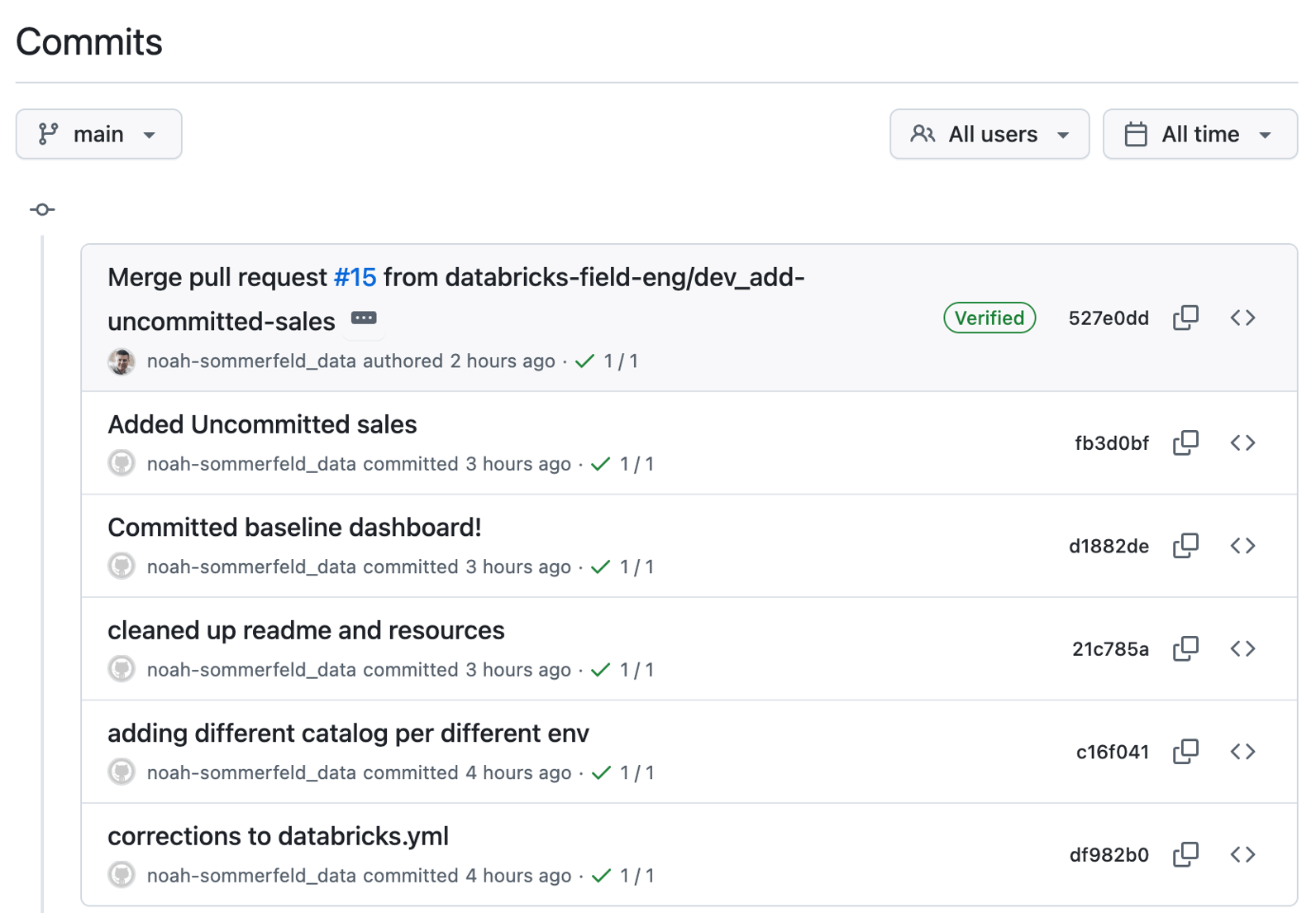
Bônus 2: E se você precisar reverter uma alteração?
Mesmo com revisão e testes cuidadosos, problemas ainda podem surgir, como um dashboard que não carrega ou uma definição de métrica que se revela incorreta.
Como o dashboard é gerenciado por meio desse fluxo de trabalho, você pode reverter para uma versão estável conhecida usando o mesmo processo controlado usado para implantar a atualização.
Comece abrindo o histórico de alterações do painel no repositório e localizando a atualização que você deseja desfazer. A partir daí, você pode revisar o que foi modificado para confirmar que está revertendo a alteração correta antes de prosseguir.
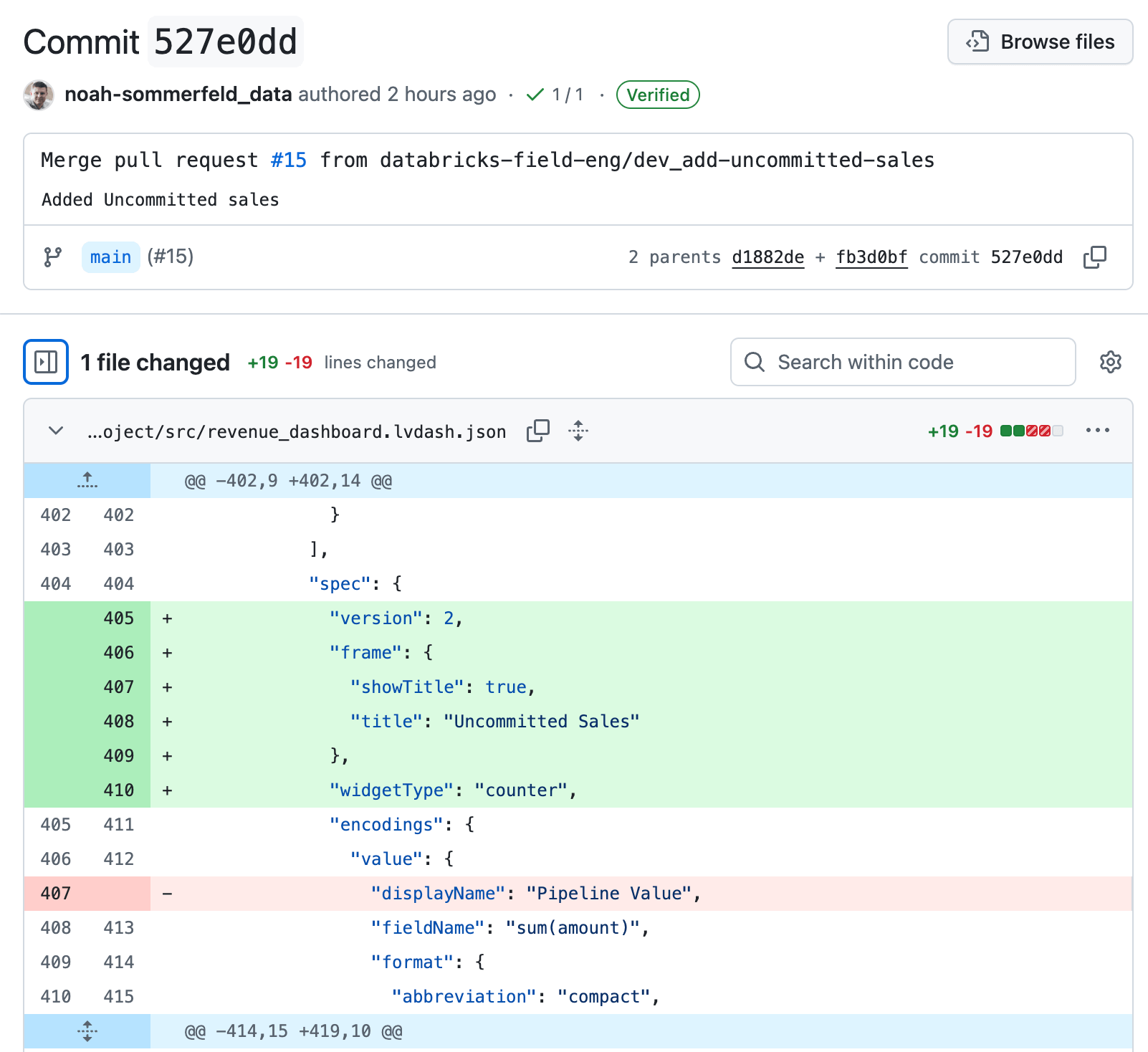
Nos detalhes da alteração, siga o link de volta para a página de revisão. Para reverter a atualização, selecione Reverter. Isso cria uma nova alteração de “desfazer” que reverte apenas aquela atualização específica, restaurando o dashboard à sua lógica anterior e mantendo o restante da história do dashboard intacta.
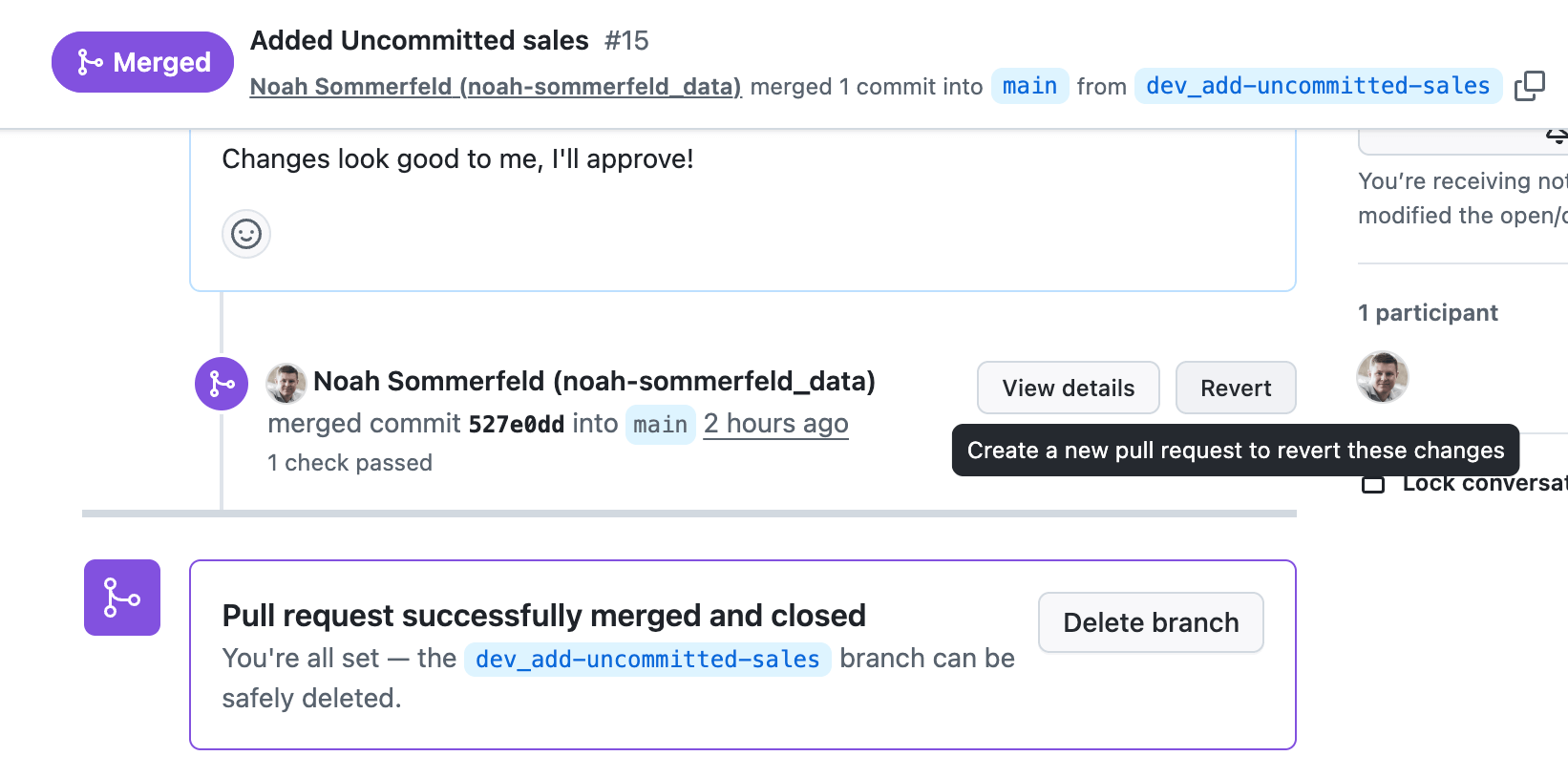
Depois que a alteração for mesclada na branch principal, a mesma automação que implantou o dashboard em produção a reverterá. Isso significa que você pode responder a uma interrupção ou a um problema de cálculo de alto impacto em minutos, sem contornar os controles que você já implementou.
Bônus 3: E se suas fontes de dados tiverem uma atualização?
A maioria dos painéis está intimamente ligada às suas fontes de dados, o que significa que as atualizações em um painel estão frequentemente ligadas a atualizações nos pipelines. A boa notícia é que os Pacotes de Ativos são projetados para agrupar componentes relacionados em um único pacote.
Isso garante que uma alteração no modelo de dados upstream nunca o pegue de surpresa e, quando as alterações na visualização exigirem atualizações do modelo de dados, você poderá implementar ambas as alterações em uma única implantação.
Conclusão
Tratar dashboards de IA/BI como produtos de dados de nível de produção é essencial para decisões de negócios confiáveis e mitigação de riscos. Neste fluxo de trabalho, um pequeno conjunto de passos adicionais torna as alterações no dashboard visíveis, revisáveis e reversíveis, sem alterar a forma como você cria dashboards no dia a dia.
Ao gerenciar dashboards com o Git e os Pacotes de Ativos Databricks, as equipes estabelecem um fluxo de trabalho rotineiro e previsível para atualizações: fazer a alteração, revisá-la, testá-la e implantá-la. O mesmo processo se aplica se a atualização for um pequeno ajuste visual ou uma alteração significativa na lógica de negócios.
Com a disciplina de implantação correta em vigor, as alterações no dashboard deixam de ser uma fonte de risco e passam a ser uma fonte confiável de percepções que evolui com o negócio, mesmo em situações de alto risco, como uma reunião de diretoria.
Saiba mais + Próximos os passos
Se você se sentiu inspirado e quer se aprofundar nas peças usadas neste fluxo de trabalho, aqui estão alguns recursos que são um bom lugar para continuar:
- 'Estratégia de ramificação' (AWS | Azure | GCP)
Aprenda como as alterações são mescladas e implantadas usando um modelo de ramificação que segue as melhores práticas. - Databricks Asset Bundles (AWS | Azure | GCP)
Aprenda como os Asset Bundles são usados para empacotar e implantar recursos do Databricks de forma consistente entre ambientes. - CI/CD para implantação automatizada no Databricks (AWS | Azure | GCP)
Aprenda a implementar CI/CD com scripts de início do Github Actions (AWS | Azure | GCP) - Usando Bundles de Ativos do Databricks Workspace UI (AWS | Azure | GCP)
Aprenda a criar, editar e implantar bundles diretamente do workspace. - Pastas com suporte do Git no Databricks (AWS | Azure | GCP)
Saiba como a integração com o Git funciona no Databricks e como o controle de versão se encaixa nos fluxos de trabalho de analítica do dia a dia.
Se você estiver pronto para dar o próximo passo com o Databricks AI/BI, pode escolher qualquer uma das seguintes opções:
- Edição Gratuita e Avaliação: obtenha experiência prática inscrevendo-se em nossa edição gratuita ou avaliação.
- Documentação: aprofunde-se nos detalhes com nossa documentação.
- Página da web: visite nossa página da web para saber mais.
- Demonstrações: assista aos nossos vídeos de demonstração, faça tours pelo produto e obtenha tutoriais práticos para ver essa AI/BI em ação.
- Treinamento: comece com o treinamento de produto gratuito da Databricks Academy.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.