Avançando o Apache Iceberg no Databricks: Iceberg v3 GA, Compartilhamento Aberto e Governança Unificada
O catálogo mais abrangente e aberto para Apache Iceberg
por Jason Reid, Ryan Blue, Daniel Weeks e Michelle Leon
*O Unity Catalog é agora o catálogo Apache Iceberg mais abrangente, interoperável e pronto para produção, com Managed Iceberg, Iceberg v3 e Foreign Iceberg entrando em GA.
*Cinco recursos o diferenciam: APIs abertas, federação de catálogo, controle de acesso entre mecanismos, compartilhamento seguro sem cópia e otimização orientada por IA.
*Olhando para o futuro, Iceberg v4 e Delta 5.0 convergirão para uma estrutura de metadados unificada, acabando com o compromisso entre interoperabilidade e desempenho pronto para produção.
A próxima fase do open lakehouse será definida pelo catálogo. Formatos de tabela abertos possibilitaram que muitos motores trabalhassem nos mesmos dados, mas o catálogo determina se esses dados podem ser governados, otimizados e compartilhados de forma consistente entre sistemas. À medida que mais cargas de trabalho, incluindo IA e aplicações agentivas, dependem de acesso governado a dados em muitos sistemas, as empresas precisam de um catálogo Iceberg que possa fornecer interoperabilidade, ótimo desempenho e governança pronta para empresas.
É por isso que hoje, estamos anunciando o conjunto mais abrangente de capacidades Iceberg disponíveis em qualquer catálogo de lakehouse. Neste blog, discutiremos novas melhorias para o suporte Iceberg no Unity Catalog e detalharemos 5 coisas que tornam o Unity Catalog o catálogo Iceberg mais interoperável do mercado hoje.
O que há de novo: Capacidades Iceberg em resumo
Lançamos um amplo conjunto de capacidades Iceberg em todo o Databricks e Unity Catalog para Disponibilidade Geral e Preview para garantir que cada motor, cada catálogo e cada equipe possam trabalhar perfeitamente juntos.
- Iceberg Gerenciado (GA): Crie, leia, escreva, otimize, governe e compartilhe tabelas Iceberg diretamente no Unity Catalog, com Otimização Preditiva e Agrupamento Líquido eliminando o trabalho manual necessário para manter as tabelas com bom desempenho.
- Iceberg v3 (GA): Suporte nativo para vetores de exclusão, rastreamento de linhas e o novo tipo VARIANT em tabelas gerenciadas, externas e habilitadas para UniForm.
- Iceberg Externo (GA) & Venda de Credenciais para Iceberg Externo (GA): Registre, governe e consulte com segurança tabelas Iceberg gerenciadas em catálogos externos.
- Compartilhamento Externo para clientes Iceberg (GA): Compartilhe dados ao vivo com quaisquer clientes compatíveis com REST Iceberg usando o protocolo aberto DeltaSharing.
- Compartilhamento Externo de tabelas Iceberg Externas (Preview Público): Compartilhe tabelas Iceberg gerenciadas fora do Databricks nativamente no Databricks & em todo o ecossistema Delta Sharing.
- Visualizações Materializadas compatíveis com Iceberg (Preview Público Restrito): Crie visualizações materializadas de alto desempenho no Databricks e exponha-as downstream como tabelas Iceberg nativas.
- Controle de Acesso Baseado em Atributos entre motores (Beta): Aplique políticas de governança de granularidade fina para motores Iceberg externos através das APIs de Scan do Catálogo REST Iceberg.
- Novos conectores de federação de catálogo (Preview): Expandindo o suporte de federação de catálogo do Unity Catalog além do AWS Glue, Snowflake Horizon, Hive Metastore, e Salesforce Data Cloud para incluir Google Cloud Lakehouse e Palantir, tornando o Unity Catalog seu único ponto de visualização.
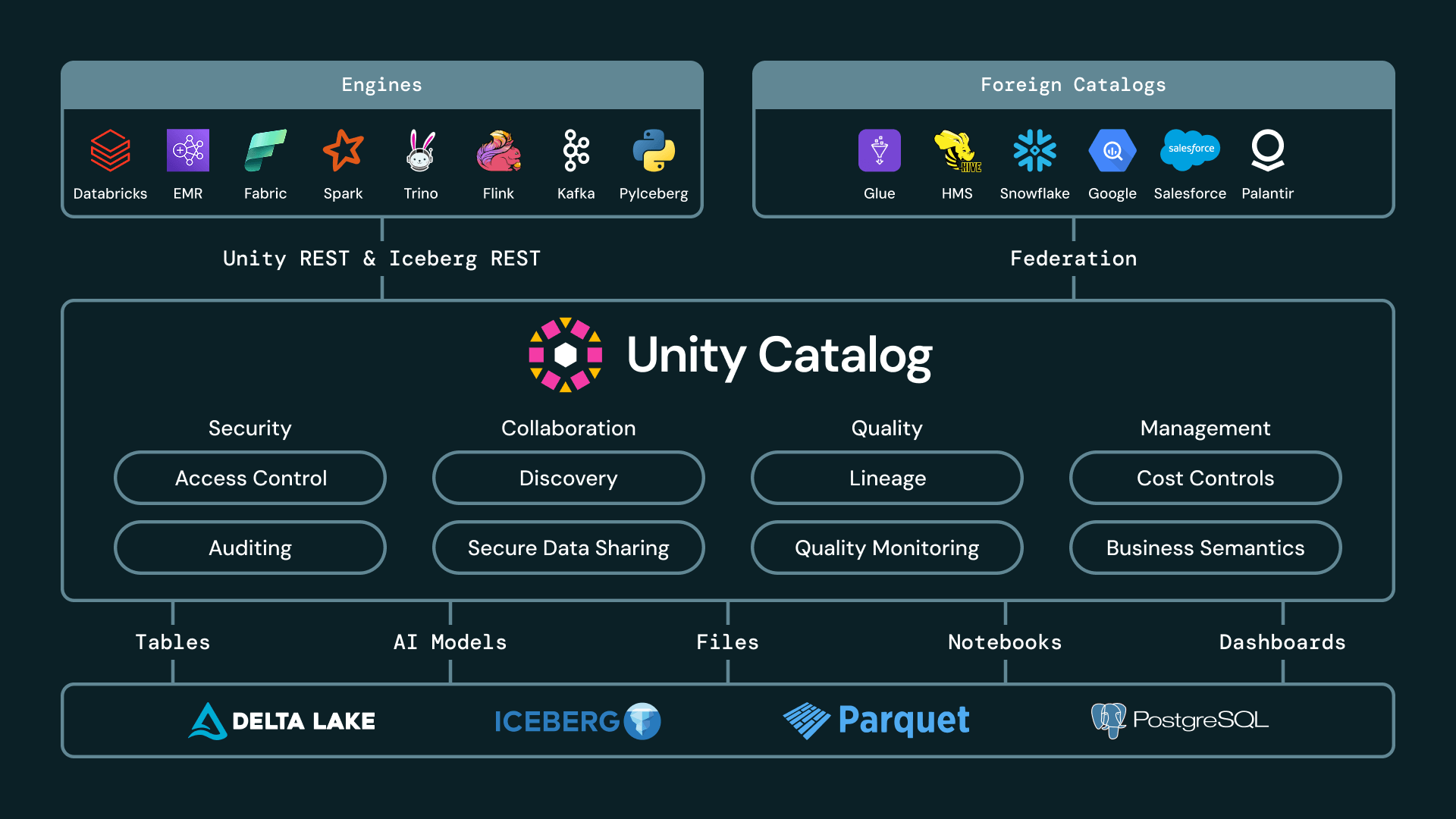
Cinco coisas que tornam o Unity Catalog o catálogo Iceberg mais interoperável
Para entregar um lakehouse totalmente aberto, um catálogo Iceberg deve ir além do rastreamento básico de metadados. Ele precisa lhe dar flexibilidade absoluta em diversos motores, fornecedores e modelos de governança. Acreditamos que a avaliação de um catálogo Iceberg aberto se resume a quão bem ele atende a cinco requisitos operacionais fundamentais: fornecer APIs abertas, federar entre ambientes externos, aplicar governança entre motores, habilitar compartilhamento seguro e aberto, e inovação contínua de desempenho e formato.
O Unity Catalog é o único catálogo que atende a todos os cinco requisitos.

1. APIs abertas e venda de credenciais
Os clientes devem ser capazes de usar o motor que melhor se adapta à carga de trabalho, seja Spark, Trino, Flink, Snowflake, DuckDB, pandas, ou outro cliente compatível com Iceberg, sem copiar dados ou dar a cada motor permissões amplas de armazenamento.
Com o Iceberg Gerenciado agora em disponibilidade geral no Databricks, os clientes podem criar, ler e escrever em tabelas Iceberg no Unity Catalog a partir de qualquer motor usando as APIs de Catálogo REST Iceberg do UC.
As APIs de Catálogo REST Iceberg do UC agora também se estendem além das tabelas Iceberg gerenciadas. O UC também vende credenciais para tabelas Iceberg federadas, fornecendo acesso seguro via APIs abertas mesmo para tabelas gerenciadas em catálogos externos. E, atualmente em Preview Público Restrito, os clientes podem criar visualizações materializadas no Databricks e expô-las como tabelas Iceberg para consumidores downstream. Com disponibilidade mais ampla nas próximas semanas, os clientes poderão criar visualizações materializadas compatíveis com Iceberg diretamente com CREATE MATERIALIZED VIEW my_mv USING ICEBERG.
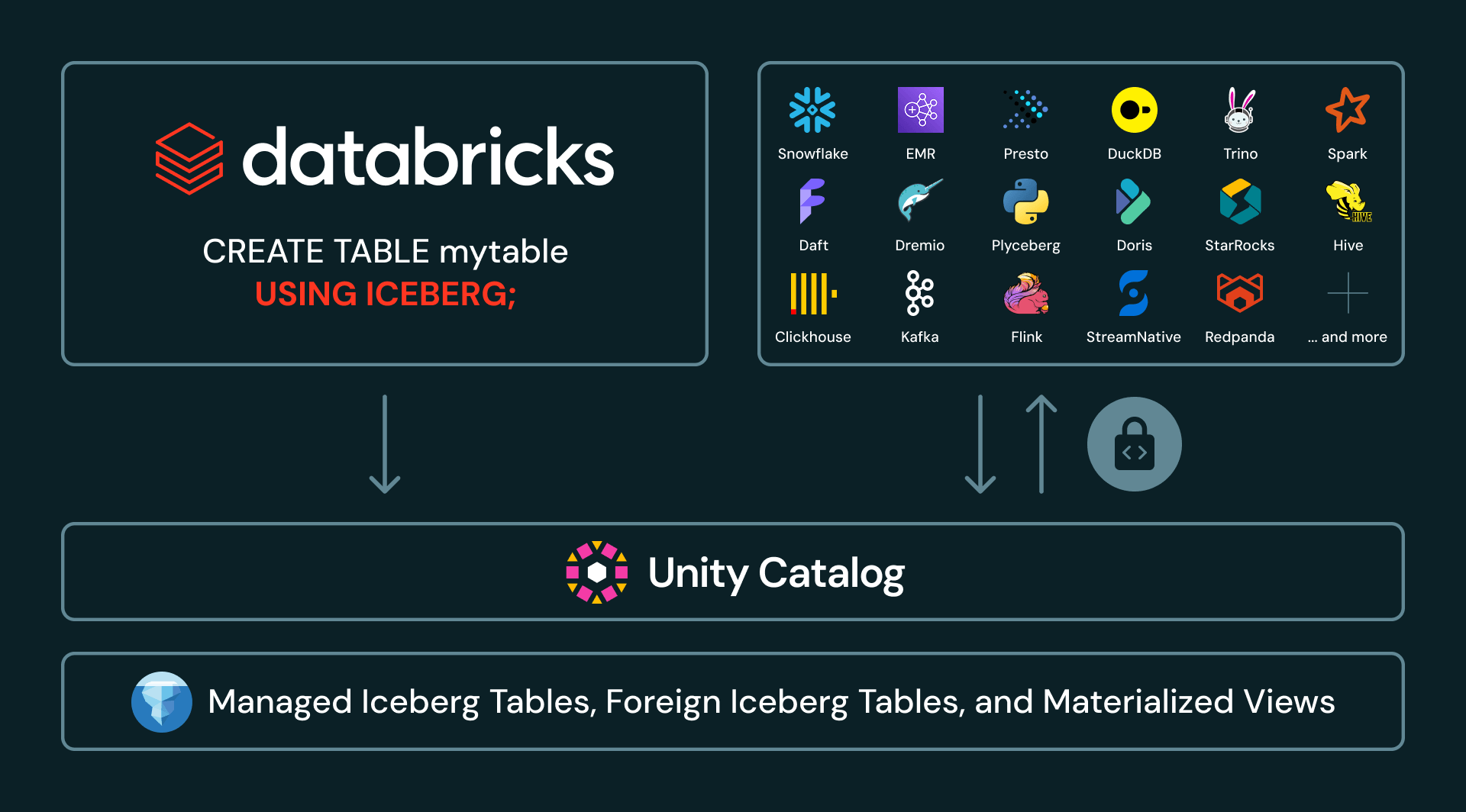
2. Federação de catálogo: todo o seu patrimônio Iceberg em uma única visualização
Muitas grandes empresas têm vários catálogos em seu lakehouse. Por exemplo, elas podem ter dados distribuídos entre Unity Catalog, AWS Glue, Snowflake Horizon e Hive Metastore. Com o Iceberg Externo agora em disponibilidade geral, o Unity Catalog pode governar tabelas Iceberg gerenciadas em outros catálogos. Os clientes podem descobrir, proteger, consultar e compartilhar tabelas Iceberg externas através do Databricks, mantendo os dados e o catálogo de origem no lugar.
O Unity Catalog agora suporta um conjunto amplo e crescente de integrações de catálogo Iceberg, incluindo AWS Glue, Google Cloud Lakehouse Runtime Catalog, Snowflake Horizon, Palantir, Salesforce e Workday. Essas integrações permitem que as empresas tratem o Unity Catalog como o único ponto de visualização para seu patrimônio Iceberg, mesmo quando os dados são produzidos ou gerenciados em outro lugar.
3. Controle de Acesso Baseado em Atributos entre motores
Historicamente, controles de linha e coluna eram aplicados dentro de um único motor. No open lakehouse, a mesma tabela pode ser acessada por vários motores. Isso introduziu um problema difícil: a governança precisa funcionar onde quer que os dados possam ser acessados.
Com os controles de acesso baseados em atributos (ABAC) entre mecanismos agora em Beta, o Unity Catalog estende o controle de acesso baseado em atributos para clientes Iceberg usando as APIs de Scan do Catálogo REST Iceberg.
Como funciona: os administradores definem políticas uma vez no UC, incluindo máscaras de coluna, filtros de linha e políticas baseadas em tags. Quando um mecanismo Iceberg externo solicita acesso, o UC avalia as políticas aplicáveis durante o planejamento de scan no lado do servidor. O UC, então, retorna um plano de scan filtrado para que o mecanismo leia apenas os dados autorizados ao processar a consulta.
Isso traz governança granular para mecanismos Iceberg externos usando padrões abertos. Qualquer mecanismo, como Apache Spark ou DuckDB, que implemente o cliente de planejamento de scan do catálogo REST Iceberg (adicionado na versão 1.11 do Iceberg) pode acessar dados com ABAC aplicado. Os clientes podem usar o melhor mecanismo para cada carga de trabalho, mantendo um modelo de governança em todo o lakehouse.
O Unity Catalog e o Iceberg gerenciado nos dão o melhor dos dois mundos: performance nativa para nossos pipelines de IA e ML, e interoperabilidade aberta para todos os consumidores downstream. Um caminho de escrita, zero duplicação e uma camada de governança que todo mecanismo respeita, incluindo os produtos orientados por IA que estamos construindo para a Data Cloud da Rippling.—Tae Lee, Engenheiro Sênior, Plataforma de Dados na Rippling
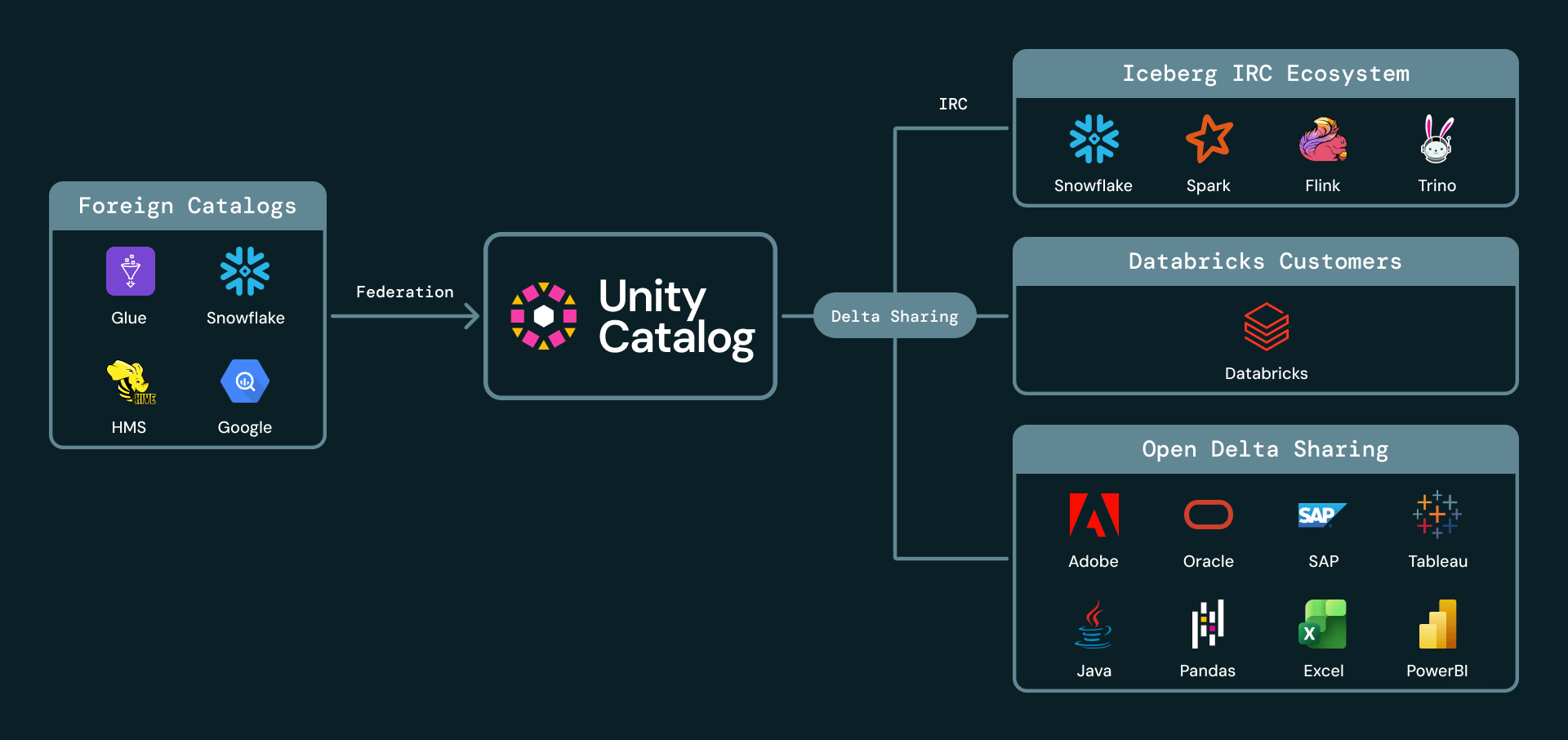
4. Compartilhamento seguro sem cópia para colaborações externas e entre domínios
O compartilhamento entre domínios frequentemente força os provedores de dados a fazerem escolhas ruins: copiar dados para outra plataforma, construir mecanismos complexos de autenticação externa ou exigir que cada destinatário use o mesmo ecossistema de fornecedor. A Databricks foi pioneira no compartilhamento seguro de dados abertos com o Delta Sharing, o protocolo de código aberto mais amplamente adotado para compartilhamento de Dados e IA - suportando compartilhamento Databricks-para-Databricks e Databricks-para-Abertos.
Estamos animados em anunciar que o Iceberg agora é um cidadão de primeira classe no Databricks Delta Sharing, tanto como formato de origem quanto como destino. Com o compartilhamento para clientes Iceberg agora geralmente disponível, os clientes Databricks podem compartilhar dados ao vivo externamente com qualquer destinatário que suporte a API do Catálogo REST Iceberg. Os destinatários podem consultar dados compartilhados de clientes compatíveis com Iceberg, como Snowflake, Trino, Flink e Spark, sem ingestão manual ou cópias. Os provedores continuam a gerenciar acesso, auditoria e governança através do Unity Catalog.
Também estamos anunciando a Pré-visualização Pública do compartilhamento de Iceberg estrangeiro. Os clientes podem compartilhar tabelas Iceberg que são gerenciadas ou catalogadas fora da Databricks, mas registradas e governadas no Unity Catalog. Isso significa que o UC pode servir como a camada de compartilhamento para tabelas Iceberg gerenciadas e estrangeiras, mantendo os dados no local e a governança centralizada.
5. Inovação em performance e formato: tabelas abertas mais rápidas sem ajuste manual
A interoperabilidade aberta só funciona se as tabelas permanecerem performáticas em escala de produção. O Unity Catalog é o único catálogo que usa IA para otimizar suas tabelas para consultas mais rápidas e menor sobrecarga operacional. O Otimizador Preditivo determina quais tabelas precisam de manutenção, quais otimizações executar, com que frequência executá-las e adapta o layout de dados da sua tabela com base nos padrões de carga de trabalho. Isso reduz o trabalho operacional necessário para manter as tabelas Iceberg rápidas e eficientes em termos de custo à medida que o uso muda, e essas otimizações beneficiam todos os mecanismos - por exemplo, técnicas de otimização de layout de dados melhoram o saltar de dados para consultas executadas fora da Databricks, como no Apache Spark. Estamos constantemente inovando na experiência do cliente – e somos o único catálogo que pode selecionar inteligentemente chaves de clusterização para performance ideal ou atualizar automaticamente tabelas abertas com as últimas inovações com base em padrões de acesso anteriores.
A Databricks também está avançando o próprio padrão Iceberg. Com o Iceberg v3 agora geralmente disponível na Databricks, os clientes obtêm suporte para vetores de exclusão, rastreamento de linhas e VARIANT em tabelas Iceberg gerenciadas, tabelas Iceberg estrangeiras e tabelas gerenciadas com UniForm ativado. Essas funcionalidades fecham lacunas importantes entre performance e interoperabilidade: vetores de exclusão aceleram atualizações, mesclagens e exclusões; rastreamento de linhas suporta processamento incremental mais eficiente; e VARIANT fornece uma representação padrão para dados semiestruturados. Esses recursos também funcionam perfeitamente entre tabelas Delta e Iceberg, permitindo interoperabilidade sem reescrever dados.
Esses investimentos apontam para o mesmo objetivo: tabelas abertas que não forçam os clientes a escolher entre a interoperabilidade do ecossistema e as capacidades de performance necessárias para cargas de trabalho de produção.
O Unity Catalog nos dá um lugar para governar dados entre equipes e sistemas, enquanto o Iceberg gerenciado entrega a performance que precisamos em nossa escala.—Kayvon Raphael, Head de Engenharia de Dados, Magnite
Tomadas em conjunto, essas cinco capacidades tornam o Unity Catalog o melhor catálogo para Apache Iceberg. O UC oferece aos clientes acesso aberto a tabelas Iceberg, uma visão unificada entre catálogos, governança granular entre mecanismos, compartilhamento seguro entre domínios e otimização automática para cargas de trabalho de produção.
A próxima fronteira: Iceberg v4
Com o Iceberg v4, estamos repensando a estrutura de metadados principal do zero para melhor performance, escalabilidade e interoperabilidade. Nosso objetivo é elevar continuamente o nível de performance e inovação de recursos, e fazer isso de uma forma que aproxime Iceberg e Delta Lake. É por isso que também estamos propondo que a próxima versão do Delta, Delta 5.0, adote a estrutura de metadados adaptativa em árvore.
O resultado é simples: todas as tabelas gerenciadas são otimizadas automaticamente no Unity Catalog, governadas através de APIs abertas e disponíveis para qualquer mecanismo. Enquanto outras plataformas fazem você escolher entre interoperabilidade e performance e capacidades avançadas. Com o Unity Catalog, você obtém ambos.
Saiba mais no Data + AI Summit
Junte-se a nós no Data + AI Summit para saber mais sobre Apache Iceberg, Unity Catalog, compartilhamento aberto, federação e a próxima fase de unificação dos formatos Delta e Iceberg.
- Co-evolução de Formatos: Como Iceberg v4 e Delta 5.0 Compartilham Metadados Unificados Aprofunde-se na árvore de metadados adaptativa do Iceberg v4 e como o Delta 5.0 adota a mesma estrutura de metadados de conteúdo, permitindo melhor performance e interoperabilidade em um ecossistema unificado.
- Seu Guia para Formatos de Tabela Abertos: Delta, Iceberg, Melhores Práticas e Próximos Passos Saiba o que há de novo no Delta Lake e Apache Iceberg, incluindo melhores práticas para trabalhar entre formatos hoje e uma prévia de nosso próximo roadmap para melhor atender às cargas de trabalho de IA/ML.
- A Jornada de Interoperabilidade da Magnite em um Petabyte de Dados Iceberg Ouça como a Magnite centralizou o acesso com o Unity Catalog, ao mesmo tempo em que melhorou a performance em vários mecanismos, incluindo Apache Spark, DuckDB e Snowflake.
- Como Acessar Dados com Segurança com Federação de Lakehouse entre AWS Glue, Snowflake, BigQuery e Fabric Veja como o Unity Catalog pode atuar como o catálogo de catálogos para governar, proteger e consultar dados em sistemas externos sem copiar dados.
- Interoperabilidade Apache Iceberg: Suporte Aberto de Primeira Classe na Databricks Delta Sharing
Veja o suporte de primeira classe ao Iceberg no Delta Sharing, incluindo como a Foot Locker usa o compartilhamento aberto da Databricks para interoperabilidade Iceberg multiplataforma.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.