Desbloqueando os Arquivos: Transformando Documentos Não Estruturados em um Banco de Dados Pesquisável para a Descoberta de Águas Subterrâneas
Como o Databricks for Good ajudou a MapAid a aproveitar a AI para transformar arquivos estáticos em um mecanismo de busca prático para a crise hídrica do Sudão
- A MapAid fez uma parceria com o Databricks for Good para classificar e catalogar quase 700 documentos hidrogeológicos digitalizados, transformando uma coleção não estruturada em um banco de dados pesquisável.
- Usando AI multimodal, a equipe construiu um pipeline serverless que classifica documentos e extrai informações relacionadas à água diretamente de imagens de páginas digitalizadas.
- Agora, os pesquisadores podem localizar estudos históricos relevantes em segundos e acessar registros de poços que alimentam diretamente os modelos de previsão de águas subterrâneas da MapAid, apoiando melhores resultados de perfuração.
Introdução
Em todo o Sudão, as comunidades dependem da água subterrânea para consumo, irrigação e sobrevivência, mas a perfuração de um poço produtivo está longe de ser garantida. A geologia é complexa, os aquíferos variam muito e um poço mal sucedido pode custar milhares de dólares. Décadas de levantamentos geológicos e relatórios de campo contêm os dados necessários para melhorar os resultados, mas essas informações estavam dispersas em arquivos e nunca foram organizadas sistematicamente, tornando-as invisíveis para as pessoas que mais precisam delas.
A MapAid é uma organização sem fins lucrativos fundada na Universidade de Stanford cuja missão é capacitar agentes humanitários e de desenvolvimento, principalmente na África, a tomar decisões baseadas em dados por meio de mapeamento aprimorado por AI. Sua principal ferramenta, o aplicativo WellMapr (gratuito para uso), usa AI e dados geoespaciais para identificar zonas de águas subterrâneas rasas, orientando a perfuração de baixo custo para água potável e irrigação de pequenos agricultores. Um insumo crítico para esses modelos são os dados históricos sobre poços, perfurações e geologia de aquíferos.
A Sudan Association for Archiving Knowledge (SUDAAK) mantém uma das coleções mais ricas desses dados: quase 700 PDFs, TIFFs e JPGs digitalizados, totalizando mais de 5.000 páginas de levantamentos geológicos, relatórios de perfuração de poços e estudos de campo, disponíveis publicamente em wossac.com. No entanto, disponibilidade não é o mesmo que acessibilidade. Um pesquisador em busca de dados de poços em uma parte específica do Sudão precisaria analisar manualmente centenas de documentos. Os dados foram digitalizados, mas sem um sistema de recuperação, permaneceram inexplorados.
Classificando documentos digitalizados com AI multimodal
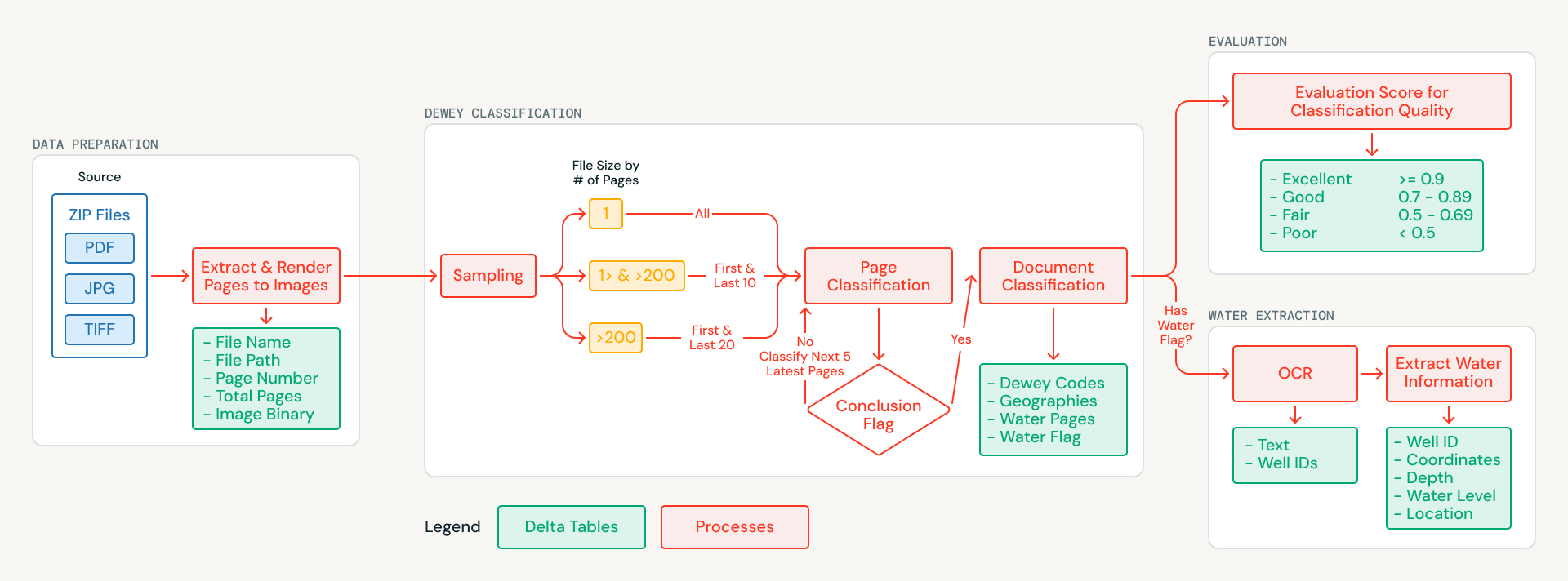
A Databricks fez uma parceria com a MapAid para criar um pipeline alimentado por AI que classifica cada documento no arquivo, adiciona tags com metadados geográficos e temáticos e extrai registros estruturados de poços e perfurações de documentos relacionados à água. O sistema roda inteiramente na Databricks e é empacotado para implantação com um único comando. Este artigo aborda a abordagem técnica e como ela se generaliza para qualquer organização que queira extrair conhecimento estruturado de grandes coleções de documentos digitalizados não estruturados.
O arquivo apresentou desafios que inviabilizaram a extração tradicional de texto. Os documentos são digitalizações de relatórios físicos, com muitas décadas de existência, sem camada de texto incorporada. Algumas páginas estão inclinadas, outras combinam inglês e árabe, e muitas incluem notas de campo manuscritas. Em vez de tentar o OCR como primeira etapa, a equipe reformulou o problema como um de compreensão visual: enviar imagens de páginas digitalizadas diretamente para modelos de AI multimodal que pudessem interpretar o conteúdo visualmente.
As páginas de cada documento são renderizadas como imagens e armazenadas em Unity Catalog Volumes, criando um conjunto de dados fundamental limpo e versionado. A partir daí, uma estratégia de amostragem inteligente reduz os custos de processamento: documentos mais curtos são analisados na íntegra, enquanto documentos mais longos têm amostras extraídas de suas seções mais informativas (páginas de título, introduções e conclusões). Isso reduziu o volume de processamento de AI em mais de 70%, preservando a qualidade da classificação.
Cada página amostrada é analisada usando as Databricks AI Functions (ai_query), que oferecem suporte nativo a entradas multimodais e saída JSON estruturada. O modelo examina a imagem de cada página e retorna:
- Códigos de classificação Decimal de Dewey, o sistema universal de classificação de bibliotecas
- Geografias sudanesas referenciadas no conteúdo
- Uma flag de relevância hídrica indicando se a página contém dados de poços, perfurações ou aquíferos
Como as AI Functions são executadas diretamente no SQL, dieferentes equipes puderam iterar em prompts e esquemas de saída sem a necessidade de criar uma infraestrutura separada de serviço de modelo. Os resultados no nível da página são agregados em classificações no nível do documento, gerando um catálogo estruturado e pesquisável onde cada documento recebe tags com o que aborda e onde se aplica.
{kind=link}
Extraindo registros estruturados de poços e perfurações
Muitos dos documentos marcados como relevantes para a água contêm exatamente o tipo de informação estruturada de que os modelos WellMapr da MapAid dependem: localizações de poços, profundidades de perfuração, medições do lençol freático e taxas de rendimento. Essas informações geralmente estão distribuídas por todo o documento, com coordenadas aparecendo em uma seção, medições de profundidade em outra e dados de rendimento em uma tabela de resumo várias páginas adiante. Extrair e vincular esses dados era um objetivo central da parceria.
Para cada documento relevante para a água, o pipeline processa todas as páginas, em vez de apenas o subconjunto amostrado usado para classificação. O OCR é realizado página por página usando um modelo multimodal servido por meio da Foundation Model API, que lida com inglês, árabe e layouts complexos, incluindo notas de campo manuscritas, dados tabulares e páginas de formato misto. Durante o OCR, o sistema também aplica uma abordagem de reconhecimento de entidades, identificando identificadores de poços e perfurações como entidades âncora para que os registros que abrangem várias páginas possam ser vinculados de volta a um único local.
O texto extraído de todas as páginas é mesclado em uma representação unificada do documento, que é processada em uma segunda etapa para extrair registros estruturados no formato JSON, capturando nomes de locais, coordenadas GPS, profundidades de perfuração, níveis estáticos de água e rendimentos de testes de bombeamento. As Databricks AI Functions impõem respostas restritas por esquema, garantindo que esses atributos sejam capturados de forma consistente, mesmo quando aparecem em formatos ou seções diferentes ao longo do documento. O resultado é um conjunto de registros estruturados de poços e perfurações prontos para integração direta nos modelos de previsão WellMapr da MapAid.
Avaliação automatizada de qualidade em escala
Validar manualmente centenas de classificações hidrogeológicas especializadas exigiria recursos significativos e profunda experiência no domínio. Em vez de tratar a avaliação como uma etapa separada a ser feita após o fato, a equipe incorporou a avaliação de qualidade automatizada diretamente no pipeline como uma etapa de primeira classe. Um modelo de AI separado, também chamado por meio de AI Functions, atua como juiz: pontuando cada classificação em uma rubrica estruturada que abrange precisão, integridade e consistência. Para cada documento, o avaliador compara os códigos Decimais de Dewey atribuídos e as tags geográficas com o conteúdo da página amostrada, verificando se as classificações são sustentadas pelo que o modelo realmente observou.
Cada avaliação produz uma classificação categórica (excelente, boa, razoável ou ruim) e uma justificativa por escrito explicando a pontuação, criando uma trilha auditável para cada decisão que o pipeline toma. Documentos com pontuação abaixo de um limite de confiança são sinalizados para revisão manual, direcionando o esforço humano limitado para os casos em que ele é mais importante. Na primeira execução completa, apenas uma pequena fração das classificações exigiu atenção humana.
Implantando uma solução independente na Databricks
Um projeto como este toca todas as camadas da pilha de dados e AI: armazenamento de arquivos, engenharia de dados, inferência de AI, análise de saída estruturada, avaliação de qualidade e governança. A Databricks forneceu tudo isso em um único workspace. Os arquivos de arquivo brutos são armazenados em Volumes do Unity Catalog, e todas as saídas do pipeline são gravadas em tabelas do Delta Lake com confiabilidade ACID, evolução de esquema e linhagem de dados completa. O pipeline é orquestrado como um Lakeflow Job em computação serverless, de modo que a MapAid paga apenas pelo que cada execução consome.
Todo o sistema é empacotado como um Databricks Asset Bundle, o que significa que ele pode ser implantado, atualizado e executado com um único comando. A MapAid recebeu uma solução independente que pode ser mantida sem a necessidade de especialização em vários serviços de nuvem. Como a lógica do pipeline é desacoplada do arquivo específico que ele processa, o mesmo sistema poderia ser adaptado para outros arquivos de água, outras regiões ou outros domínios onde grandes coleções de documentos digitalizados precisam ser classificadas e tornadas pesquisáveis.
O que isso significa na prática
Em sua primeira execução completa, o pipeline entregou:
- 654 documentos e 5.570 páginas classificados
- Concluído em menos de três horas
- 95% das classificações avaliadas como "excelentes" ou "boas" pelo avaliador automatizado
- ~50% do arquivo identificado como contendo dados relacionados à água
- 299 registros estruturados de poços e perfurações extraídos com nomes de locais, profundidades e medições de vazão
O pipeline transformou o que levaria semanas ou meses para especialistas do domínio em um processo concluído em horas. O arquivo agora pode ser pesquisado por classificação, geografia ou pela presença de dados sobre a água. Cada registro extraído com coordenadas e dados de profundidade alimenta diretamente as previsões de águas subterrâneas do MapAid, apoiando maiores taxas de sucesso de perfuração e entrega mais rápida de água para as comunidades necessitadas.
À medida que a SUDAAK continua a digitalizar novos documentos, o pipeline pode processar cada novo lote com um único comando, garantindo que o catálogo permaneça atualizado conforme o arquivo cresce. O trabalho do MapAid abrange a África Oriental, incluindo a Etiópia e o Malawi, e arquivos não classificados semelhantes existem em todo o continente. A metodologia e a infraestrutura estão prontas para escala.
Rupert Douglas-Bate, Chief Executive Officer (CEO) do MapAid, compartilhou a seguinte perspectiva sobre a parceria: "Nosso sistema de AI em evolução, WellMapr, tem como objetivo revolucionar a busca e localização de baixo custo de fontes sustentáveis de águas subterrâneas, mas precisa de dados de água de poço. Nossa missão de alcançar esse objetivo foi muito acelerada por nossa colaboração com o Databricks for Good, que se conectou conosco por meio do Rotary International. O projeto Databricks for Good foi fundamental no desenvolvimento da nossa Online Water Library (OWL) com o apoio da Sudan Association for Archiving Knowledge (SUDAAK). A equipe do Databricks ajudou a transformar um grande arquivo desorganizado de dados históricos de água e solo do Sudão em um sistema estruturado usando a Classificação Decimal de Dewey. Isso nos permite identificar rapidamente dados de poços de águas subterrâneas sustentáveis a um baixo custo, que agora podem ser usados para ajudar a desenvolver nosso algoritmo WellMapr. O MapAid tem o prazer de usar a OWL como uma ferramenta de desenvolvimento vital para mitigar a seca, provando que, quando os parceiros certos se alinham, podemos alcançar o 'impossível' para aqueles que mais precisam."
Leia mais sobre alguns de nossos outros projetos pro bono abaixo:
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.