Unlocking the Archives: Turning Unstructured Documents into a Searchable Database for Groundwater Discovery
How Databricks for Good helped MapAid leverage AI to transform static archives into an actionable search engine for Sudan’s water crisis
- MapAid partnered with Databricks for Good to classify and catalog nearly 700 scanned hydrogeological documents, transforming an unstructured collection into a searchable database.
- Using multimodal AI, the team built a serverless pipeline that classifies documents and extracts water-related information directly from scanned page images.
- Researchers can now locate relevant historical studies in seconds and access well records that feed directly into MapAid's groundwater prediction models, supporting improved drilling outcomes.
Introduction
Across Sudan, communities depend on groundwater for drinking, irrigation and survival, but drilling a productive well is far from guaranteed. The geology is complex, aquifers vary widely and a failed borehole can cost thousands of dollars. Decades of geological surveys and field reports contain the data needed to improve outcomes, but this information has been scattered across archives and never systematically organized, making it invisible to the people who need it most.
MapAid is a nonprofit founded at Stanford University whose mission is to empower humanitarian and development actors, primarily in Africa, to make data-driven decisions through AI-enhanced mapping. Their flagship tool, the WellMapr app (free to use), uses AI and geospatial data to identify shallow groundwater zones, guiding low-cost drilling for smallholder farmers' drinking water and irrigation. A critical input to these models is historical data on wells, boreholes, and aquifer geology.
The Sudan Association for Archiving Knowledge (SUDAAK) maintains one of the richest collections of this data: nearly 700 scanned PDFs, TIFFs, and JPGs totaling over 5,000 pages of geological surveys, well-drilling reports, and field studies, publicly available at wossac.com. However, availability is not the same as accessibility. A researcher looking for borehole data in a specific part of Sudan would need to manually sift through hundreds of documents. The data was digitized, but without a retrieval system, it remained untapped.
Classifying Scanned Documents with Multimodal AI
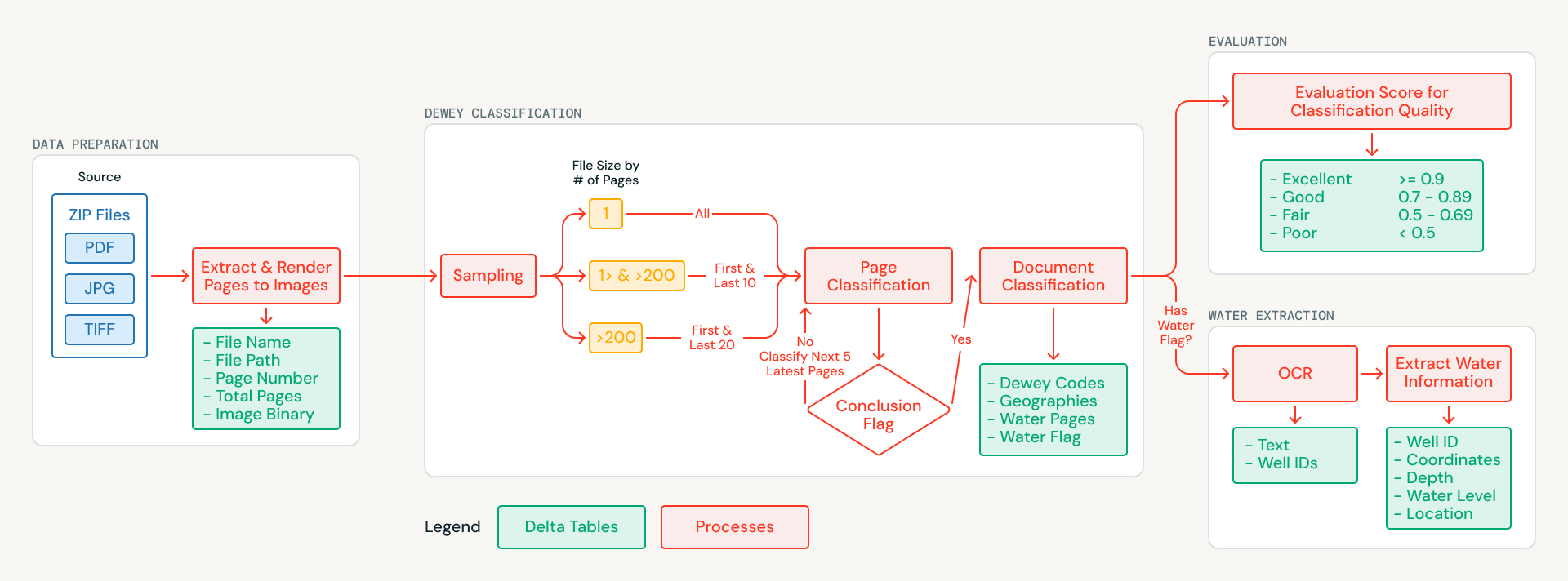
Databricks partnered with MapAid to build an AI-powered pipeline that classifies every document in the archive, tags it with geographic and subject metadata, and extracts structured well and borehole records from water-related documents. The system runs entirely on Databricks and is packaged for single-command deployment. This article walks through the technical approach and how it generalizes to any organization looking to extract structured knowledge from large collections of unstructured scanned documents.
The archive presented challenges that ruled out traditional text extraction. The documents are scans of physical reports, many decades old, with no embedded text layer. Some pages are skewed, others combine English and Arabic, and many include handwritten field notes. Rather than attempting OCR as a first step, the team reframed the problem as one of visual understanding: sending scanned page images directly to multimodal AI models that could interpret the content visually.
Each document's pages are rendered as images and stored in Unity Catalog Volumes, creating a clean, versioned foundational dataset. From there, an intelligent sampling strategy reduces processing costs: shorter documents are analyzed in full, while longer documents are sampled from their most informative sections (title pages, introductions, and conclusions). This reduced AI processing volume by more than 70% while preserving classification quality.
Each sampled page is analyzed using Databricks AI Functions (ai_query), which natively support multimodal inputs and structured JSON output. The model examines each page image and returns:
- Dewey Decimal classification codes, the universal library classification system
- Sudanese geographies referenced in the content
- A water-relevance flag indicating whether the page contains well, borehole, or aquifer data
Because AI Functions run directly within SQL, the team could iterate on prompts and output schemas without building separate model-serving infrastructure. Page-level results are aggregated into document-level classifications, producing a structured, searchable catalog where every document is tagged with what it covers and where it applies.
Extracting Structured Well and Borehole Records
Many of the water-flagged documents contain exactly the type of structured information that MapAid's WellMapr models depend on: well locations, drilling depths, water table measurements, and yield rates. This information is often distributed throughout a document, with coordinates appearing in one section, depth measurements in another, and yield data in a summary table several pages later. Extracting and linking this data was a central goal of the partnership.
For each water-relevant document, the pipeline processes every page rather than just the sampled subset used for classification. OCR is performed page by page using a multimodal model served through the Foundation Model API, which handles English, Arabic, and complex layouts including handwritten field notes, tabular data, and mixed-format pages. During OCR, the system also applies an entity recognition approach, identifying well and borehole identifiers as anchor entities so that records spanning multiple pages can be linked back to a single site.
The extracted text from all pages is merged into a unified document representation, which is then processed in a second pass to extract structured records in JSON format capturing site names, GPS coordinates, drilling depths, static water levels, and pump test yields. Databricks AI Functions enforce schema-constrained responses, ensuring these attributes are captured consistently even when they appear in different formats or sections across the document. The result is a set of structured well and borehole records ready for direct integration into MapAid's WellMapr prediction models.
Automated Quality Evaluation at Scale
Manually validating hundreds of specialized hydrogeological classifications would require significant resources and deep domain expertise. Rather than treating evaluation as a separate step to be done after the fact, the team built automated quality evaluation directly into the pipeline as a first-class stage. A separate AI model, also called via AI Functions, acts as a judge: scoring every classification on a structured rubric covering accuracy, completeness, and consistency. For each document, the evaluator compares the assigned Dewey Decimal codes and geographic tags against the sampled page content, checking whether the classifications are supported by what the model actually observed.
Each evaluation produces both a categorical rating (excellent, good, fair, or poor) and a written justification explaining the score, creating an auditable trail for every decision the pipeline makes. Documents scoring below a confidence threshold are flagged for manual review, directing limited human effort to the cases where it matters most. In the first full run, only a small fraction of classifications required human attention.
Deploying a Self-Contained Solution on Databricks
A project like this touches every layer of the data and AI stack: file storage, data engineering, AI inference, structured output parsing, quality evaluation, and governance. Databricks provided all of these within a single workspace. Raw archive files are stored in Unity Catalog Volumes, and all pipeline outputs are written to Delta Lake tables with ACID reliability, schema evolution, and full data lineage. The pipeline is orchestrated as a Lakeflow Job on serverless compute, so MapAid pays only for what each run consumes.
The entire system is packaged as a Databricks Asset Bundle, meaning it can be deployed, updated, and run with a single command. MapAid received a self-contained solution that can be maintained without expertise across multiple cloud services. Because the pipeline logic is decoupled from the specific archive it processes, the same system could be adapted to other water archives, other regions, or other domains where large collections of scanned documents need to be classified and made searchable.
What This Means on the Ground
In its first full run, the pipeline delivered:
- 654 documents and 5,570 pages classified
- Completed in under three hours
- 95% of classifications rated "excellent" or "good" by the automated evaluator
- ~50% of the archive identified as containing water-related data
- 299 structured well and borehole records extracted with location names, depths, and yield measurements
The pipeline reduced what would have taken domain experts weeks or months into a process that completes in hours. The archive can now be searched by classification, geography, or the presence of water data. Every extracted record with coordinates and depth data feeds directly into MapAid's groundwater predictions, supporting higher drilling success rates and faster delivery of water to communities in need.
As SUDAAK continues to digitize new documents, the pipeline can process each new batch with a single command, ensuring the catalog stays current as the archive grows. MapAid's work spans East Africa, including Ethiopia and Malawi, and similar unclassified archives exist across the continent. The methodology and infrastructure are ready to scale.
Rupert Douglas-Bate, Chief Executive Officer (CEO) of MapAid, shared the following perspective on the partnership: "Our evolving AI system, WellMapr, is intended to revolutionise the low-cost search and location of sustainable groundwater sources, but it needs well water data. Our mission to achieve that goal was greatly accelerated by our collaboration with Databricks for Good, who connected with us through Rotary International. The Databricks for Good project was fundamental in developing our Online Water Library (OWL) with the support of the Sudan Association for Archiving Knowledge (SUDAAK). The Databricks team helped transform a large disorganised archive of historical Sudanese water and soil data into a structured system using the Dewey Decimal classification. This allows us to rapidly identify sustainable groundwater well data at a low cost, which can now be used to help develop our WellMapr algorithm. MapAid is delighted to use OWL as a vital development tool to mitigate drought, proving that when the right partners align, we can achieve the 'impossible' for those who need it most."
Please read more about some of our other pro bono projects below:
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.