Leveraging Data to Better Educate Our Youth
Promoting innovation in non-profits through the Databricks Lakehouse Platform
by Michael Berk
77% of organizations underutilize data, and nonprofits are no different. Recently, Databricks donated employee resources, premium accounts, and free compute resources to a fast-growing non-profit called Learn To Be (LTB), a U.S.-based organization that provides free online education to underserved students across the country.
Databricks' partnership with LTB is part of a broader effort at Databricks to help educate students. Over the past several years, the Databricks University Alliance has provided teaching faculty across the country with technical resources and peer connections via the Databricks Academy. Motivated students have free access to self-paced courses and can take accreditation exams at no cost. In addition, many Databricks employees have volunteered for initiatives focused on data for good, such as:
- Analyzing COVID-19: Can the Data Community Help?
- Fatal Force: Exploring Police Shootings with SQL Analytics
- Databricks and University of Rochester
LTB's mission directly aligns with that of the Databricks University Alliance, so to further our shared mission, Databricks is supporting LTB's migration to the Lakehouse Platform.
Currently, LTB uses a Postgres database hosted on Heroku. To surface business insights, the data team added a Metabase dashboarding layer on top of the Postgres DB, but they quickly discovered some problems:
- Queries are complex. Without an ETL tool, the data team has to query base tables and write complex joins.
- There is no ML infrastructure. Without notebooks or ML cloud infrastructure, the data team has to build models on their local computer.
- Semi-structured and unstructured data are not supported. Without key/value stores, the team can't save and access audio or video data.
These limitations prevent data democratization and stifle innovation.
The Databricks Lakehouse provides solutions to all of these issues. A lakehouse combines the best qualities of data warehouses and data lakes to provide a single solution for all major data workloads, supporting streaming analytics, BI, data science, and AI. Without getting too technical, the Lakehouse leverages a proprietary Spark and Photon backend, which helps engineers write efficient ETL pipelines – we actually hold a world record in speed in 100TB TPC-DS.
At LTB, performance isn't something the data team considers because most tables are extremely small (< 500 MB), so the data team is actually more excited about other Lakehouse features. First, Databricks SQL provides an advanced query editor with task-level runtime information, which will help analysts efficiently debug queries. Second, the team plans to productionize its first ML model using the DS + ML environment, a workspace packed with ML lifecycle tools managed by MLflow that greatly speed up the ML lifecycle. Third, through the flexible data lake architecture, we will unlock access to unstructured data formats, such as tutoring session recordings, which will be used to assess and optimize student learning.
A few exciting projects that Databricks will facilitate include a student-tutor matching ML algorithm, realtime tutor feedback, and NLP analysis of student and tutor conversations.
Later this year, we plan to implement the below architecture. The client-facing architecture will remain unchanged, but the data team will now control a Databricks Lakeouse environment to facilitate insights and data products such as ML algorithms.
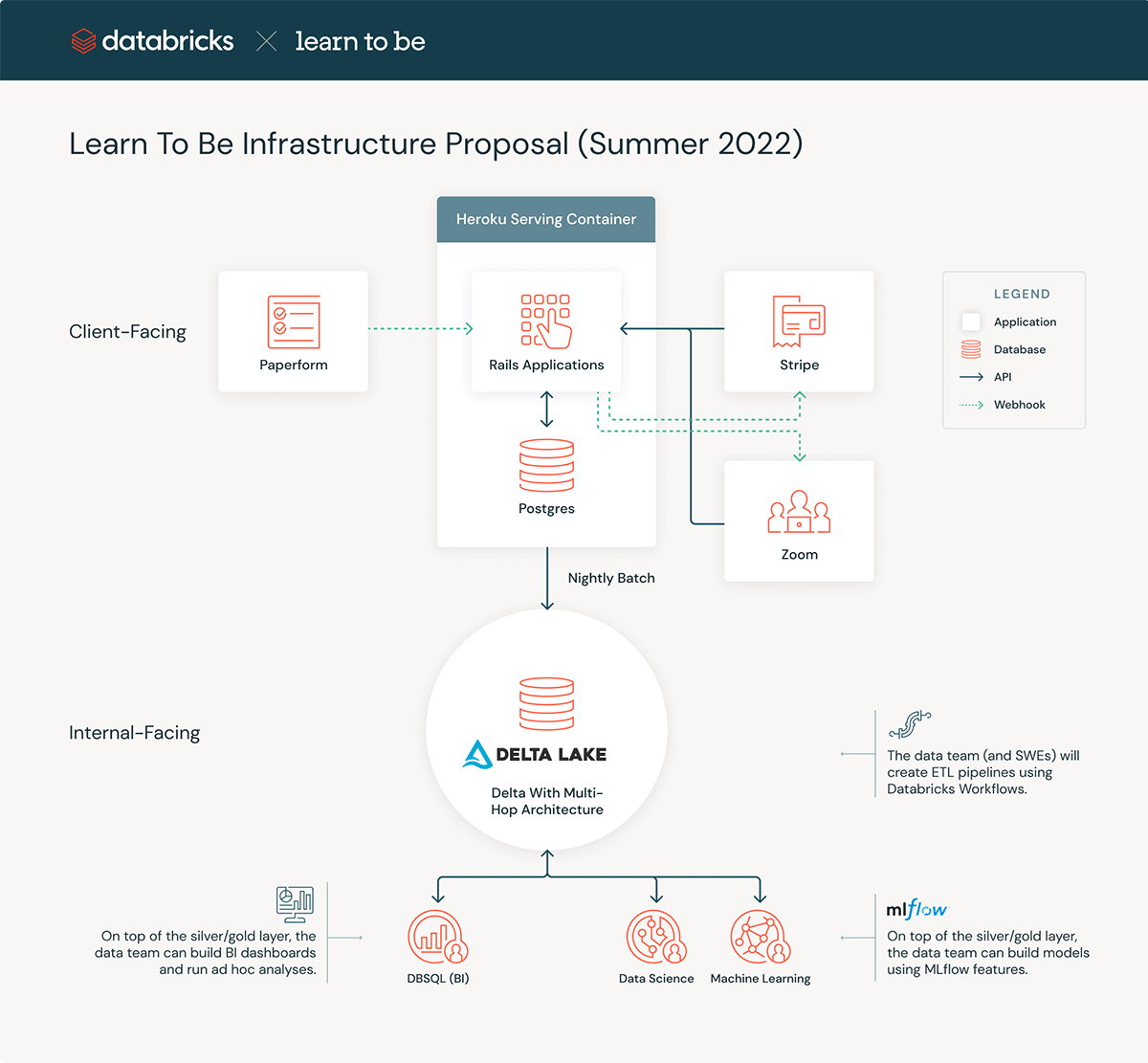
During this migration, there are a few core design principles on which we will rely:
- Use Auto Loader. When moving data from Postgres to Delta, we will create a Databricks workflow that writes our Postgres data to S3 via JDBC. Then, we will ingest that S3 data with Auto Loader and Delta Live Tables. This workflow minimizes cost.
- Keep the Medallion Architecture simple. In our case, creating "gold" tables for all use cases would be overkill – we will often query from silver tables.
- Leverage the "principle of least privilege" in Unity Catalog. We have sensitive data; only certain users should be able to see it.
If you're a relatively small organization using Databricks, these principles may help you as well. For more practical tips, check out this resource.
How to contribute
There are two ways you can contribute. The first is volunteering as a tutor with Learn To Be. If you are interested in directly helping kids, we would love to chat and connect you to some of our students! The second option is contributing in a technical capacity. We have lots of exciting data initiatives, ranging from ML to DE to subject-matter algorithms. If you're curious to learn more, feel free to reach out to michael.berk@learntobe.org.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.